用于热成像数据的卷积神经网络特征图筛选方法
2024-04-23张雷沈国琛欧冬秀
张雷,沈国琛,欧冬秀
(同济大学交通运输工程学院,上海 201804)
0 引言
随着人工智能技术的发展,大量依靠人力完成的工作逐步被计算机自动化处理所代替。同时随着计算机处理能力的不断提升,原先人力无法实现的设想也逐渐成为了现实。此外,得益于互联网基础设施和移动互联技术的快速发展,以国家战略以及民间对便捷生活的自发追求为动力,诸如管理、服务、商贸等社会生活的交互也在向线上转移。这种全社会自动化和数字化的转变,离不开感知的全面数字化,由此也使多源数据得到极大丰富。多源大数据“涌现”的现象出现在各行各业,其中较为突出的就有交通行业。交通行业的研究和实践一直处于大数据的背景之下。在运输方面,轨道、航空、水路等运输方式很早就应用了自动化辅助技术,甚至部分实现了自动驾驶。随着近年来公路运输自动驾驶和车路协同的蓬勃发展,智能化和自动化成为了五大交通运输方式的共同现状。在管控和服务方面,近年来各地交管部门纷纷推出了智能交通云平台和交通信息发布应用软件,一些企业也将交通信息发布整合到应用软件产品中。而无论是交通运输还是交通管控与服务,产生的数据都具有非常明显的多样性,常见的有档案文本数据、业务记录数据、定位和轨迹数据,以及大量传感器数据。而传感器数据又包括一维的物理量时序数据、二维的图像/视频/雷达数据、三维的雷达/点云数据等。得益于图像处理算法的快速进步,由摄像设备采集的二维视觉数据得到了广泛的应用。
视觉数据具有视场大、信息量大、分辨率高等优势[1],同时在交通场景的布设率高。因此无论是在自动驾驶还是在交通管控中,视觉数据都是非常重要且普遍的一类数据。但是视觉数据也存在明显的局限性,如受天气、光照等条件影响较大、特殊情况下会受到物体颜色信息的干扰等[1-2],由此造成的识别和判断的失误甚至失灵,会降低交通管理与控制所需数据的有效性,也会给交通运输带来较大的事故风险。红外热成像数据也是一种二维数据,不同于视觉数据记录的场景物体发射和反射的可见光,红外热成像数据记录的是物体的热辐射,可以避免视觉数据存在的受环境条件干扰的缺点[3]。同时热成像数据的数据结构与图像、视频类似,非常适合移植现有的图像处理算法。
提取可见光图像数据的特征的算法,包括传统方法和深度学习方法,诸如VGGNet[4]和ResNet[5]的卷积神经网络(CNN)就是深度学习方法中具有代表性的一类,得到了广泛的应用。而同样是二维数据的红外热成像数据也可以利用常见的卷积神经网络提取特征。但是卷积神经网络的权重需要大量的数据训练才能得到。可见光图像数据有着丰富的训练数据集,这也是卷积神经网络能被大量图像处理算法采纳的原因之一,而红外热成像数据缺少这样丰富的训练集。红外热成像数据与可见光图像数据为不同的数据域,如果能通过域适应(DA)将学习自可见光图像数据的网络应用到红外热成像的特征提取上,就可以克服红外热成像数据缺少训练集的问题。
通过域适应将原本从可见光图像数据集中学习到的卷积神经网络应用到红外热成像数据的研究非常丰富,其中,无监督的学习方法主要有利用域对抗的方式如域判别器训练特征学习网络[6-7]、利用多光谱知识转移的方式训练域编码器和共享域解码器[8-9]、利用注意力机制匹配不同域数据进行训练[10-11]、利用对比学习方法学习可见光和热成像数据的共同特征[12]、利用元学习范式改进无监督学习方法[13]。此外,还有利用目标域样本微调网络初始层后通过自顶向下的方式完成域适应[14-16]、将热成像数据转换到可见光域进行网络微调训练[17]、通过训练图像变换器实现域适应[18]、利用可见光-热成像数据对训练热成像数据识别网络[19]、利用深层次对抗网络将可见光特征转移到热成像数据进而训练热成像数据识别网络[20]等方法,还有在已有的神经网络的基础上训练特殊场景特殊样本实现域适应的方法[21-22]。尽管这些研究的方法各异,且有着较好的效果,但是还是离不开一定程度的训练。如果能直接获取从可见光图像数据集中学习到的域不变特征,用于构建适用于红外热成像数据的卷积神经网络,就可以避免再从本就为数不多的红外热成像数据中划分出一部分训练集,同时避免了训练的流程,对于硬件设备的要求也相应降低。
有研究者关注了图像在频率域的表现。HUANG等[23]分析得出图像频域的低频段和高频段主要包含随域改变的成分,包括颜色、风格等,而中频段主要包含域不变的成分,包括结构、形状等。XU等[24]利用这一发现,分离图像的不同频段,将域改变成分进行随机处理,再与原本的域不变成分一起还原成多样的样本,大大丰富了原来的数据集样本,也增加了随域改变的特征的多样性,从而用于域对抗学习,使得域不变特征能被更好地从随域改变的特征中分离。
在这一发现的启发下,本文提出一种基于离散余弦变换(DCT)和卡方独立性分数的卷积神经网络特征图筛选方法。使用离散余弦变换得到预训练的卷积神经网络浅层特征图的频域图,并借鉴卡方独立性检验的思想定义一种卡方独立性分数,根据特征图在频域的3个频段分量度量特征图的差异度。通过聚类的方法,根据这种差异度度量方法,卷积神经网络浅层特征图被分成若干类。根据这些类中的特征图共同表现出的3个频段分量的占比,这些浅层特征图可以被区分为主要包含域不变成分的特征图和主要包含随域改变成分的特征图。保留前者,将后者在卷积神经网络中剔除,即可得到更适用于与可见光图像数据具有不同数据域的红外热成像数据。基于交通场景中车辆与行人热成像数据的实验表明,本文所提方法能够将原本识别红外热成像数据效果较差的预训练卷积神经网络优化为可以较好预测红外热成像数据中目标类别的网络。
1 特征图筛选
1.1 问题描述
一个预训练卷积神经网络的浅层特征图F={F1,F2,…,Fn}∈n×h×w主要包含域不变成分的特征图I={FI1,FI2,…,FIk}∈k×h×w和主要包含随域改变成分的特征图V={FV1,FV2,…,FVl}∈l×h×w。其中,h和w为特征图的高和宽,n=k+l为特征图的数量。如图1所示(彩色效果见《计算机工程》官网HTML版,下同),本文研究的问题是找出特征图中主要包含域不变成分的特征图I,组成筛选后的浅层特征图F′=I,构建适合与训练集数据域不同的预测集的神经网络。
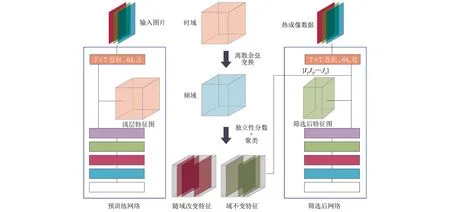
图1 特征图筛选流程Fig.1 Procedure of feature maps filtering
1.2 频域变换与频谱成分分离
二维离散余弦变换被用于将图像转换到频域,HUANG等[23]和XU等[24]使用二维离散余弦变换得到图像的频谱图,并分离随域改变成分和域不变成分。其中,频谱图的低频和高频成分被认为主要是随域改变的,而中频成分则被认为主要是域不变的。对于M×N图像矩阵F[x,y],经二维离散余弦变换得到的M×N频域矩阵D[u,v]定义为:
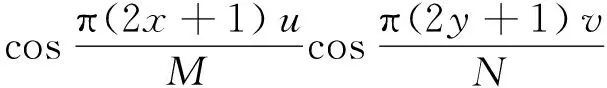
(1)

对于得到的频谱图,为了分离不同频率成分,构造滤波器:

(2)
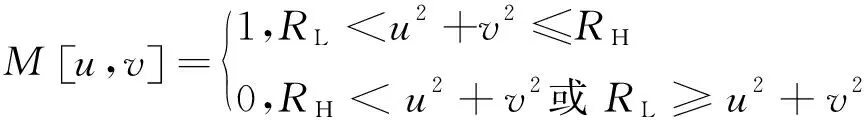
(3)

(4)
分别提取低频、中频、高频的成分,其中,RL和RH分别为低频截止频率和高频截止频率。
1.3 特征图分类与筛选
在卷积神经网络提取的某一层特征图集合中,一部分特征图保留较多的域不变特征,另一部分保留较多的随域改变特征。表现在频域上,一部分特征图的频谱含有更多的中频成分,另一部分特征图的频谱含有更多的高频和低频成分。对于M×N特征图的频域矩阵A=(aij),计算三频分量占比:
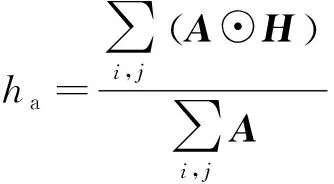
(5)

(6)
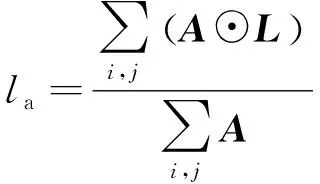
(7)
为了提取出保留较多域不变特征的特征图,一种方法是直接筛选中频成分占比较高的特征图。但是这样的方法势必需要设定一个阈值,比较依赖经验。为此,本文构造了一种卡方独立性分数,根据特征图频域的3种频率分量占比,计算不同频谱图之间的相似度(距离),最后通过聚类分离特征图集,找到主要保留域不变特征的特征图。
1.3.1 卡方独立性分数
为了计算特征图频谱之间的相似度,根据卡方独立性检验的思想构造卡方独立性分数。图像的频谱分为高频、中频、低频3个部分,对于2张特征图的频域矩阵A和B,他们的高频占比为ha和hb,中频占比为ma和mb,低频占比为la和lb。
假设三频占比与特征图无关,作为零假设,可以得到各个特征图在3个频段上占比的期望。而备择假设则是三频占比与特征图有关,这意味着特征图之间在三频上的占比有明显的统计差异。令:
Sa=ha+ma+la
(8)
Sb=hb+mb+lb
(9)
S=Sa+Sb
(10)
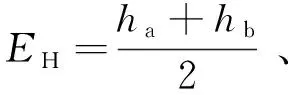
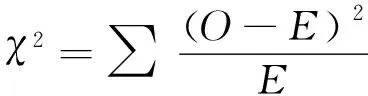
(11)
其中:O为观测值;E为理论期望值。代入特征图的实际三频占比和期望三频占比,计算得到式(12):
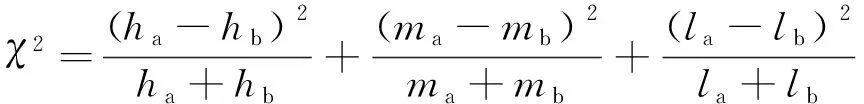
(12)
2个特征图频段分量样本的自由度为(2-1)×(3-1)=2,根据卡方值和自由度,进一步得到对应的p值。
在卡方独立性检验中,p值如果小于设定的阈值,则认为应推翻零假设而接受备择假设,这意味着2张特征图在三频上的占比有明显差异。由于本文拟构造的卡方独立性分数需要作为聚类分析的距离度量,距离越小说明特征图的三频占比差异越小,因此定义基于卡方独立性检验的独立性分数为:
D=1-p
(13)
1.3.2 基于聚类分析的特征图分类与筛选
定义了卡方独立性分数以后,可以得到每一张特征图与其他特征图之间的独立性分数矩阵,这个矩阵作为特征图之间的距离度量矩阵,就可以对特征图进行分类。通过无监督机器学习方法进行聚类,可以将样本划分为若干类别,保证同一类别内的样本更加接近,并保证不同类别的样本有足够的差异。使用聚类分析的方法,以独立性分数作为特征图样本的距离,可以在没有较多先验知识的前提下找出中频成分占比较大(也即保留更多域不变特征)的特征图。
聚类分析算法有非常多的类别,章永来等[25]将聚类算法分为小样本聚类和大样本聚类,又将小样本聚类分为传统聚类和智能聚类2类。传统聚类又被分为划分聚类和层次聚类。划分聚类中有基于划分的k-means算法、基于密度的DBSCAN算法、近邻传播算法等。层次聚类包括自底向上的聚合型聚类和分裂型聚类,其中较为常见的是聚合型聚类。由于特征图样本量不大,分类任务也较为简单,因此可以使用传统聚类方法。
为了提取保留了较多域不变特征的特征图,本文分别使用了DBSCAN算法、近邻传播算法。DBSCAN算法通过预设半径定义样本邻域,将邻域内样本数量不少于预设最少相邻样本数量的样本定义为核心样本,将邻域内的样本和邻域中心样本的关系定义为直接可达,将直接可达的传递定义为可达,将互相可达的核心样本以及与它们可达的非核心样本归为一类(簇),与任何簇的任意核心样本均不可达的样本则为异常样本。近邻传播算法定义了相似性、吸引度和归属度,通过不断迭代更新吸引度、归属度以及决策判断,最终确定聚类中心和归属。
考察聚类结果中每一类特征图频域样本的频段分布,选取中频成分占比较高的类别作为需要保留的特征图,标记其他频段占比较高的特征图,从原先的网络中剔除这部分特征图,完成特征图的筛选。
1.3.3 算法的伪代码表示
算法1特征图频谱成分分离
输入预训练特征图张量F
输出特征图三频分量矩阵S
D←dct(M)∥得到特征图频域张量
l←leftCut∥得到低频到中频的截止频率
r←rightCut∥得到中频到高频的截止频率
∥以下构建三频滤波器
L←zeros(shape(M)[1], shape(M)[2])
M←zeros(shape(M)[1], shape(M)[2])
H←zeros(shape(M)[1], shape(M)[2])
for i=0 to shape(M)[1]-1 do
for j=0 to shape(M)[2]-1 do
L[i,j]←1
M[i,j]←1
else
H[i,j]←1
∥以下计算特征图三频分量
S←zeros(shape(M)[0], 3)
for i=0 to shape(M)[0]-1 do
S[i,0]←sum(D[i]⊙L)
S[i,1]←sum(D[i]⊙M)
S[i,2]←sum(D[i]⊙H)
算法2特征图分类(以DBSCAN聚类为例)
输入特征图三频分量矩阵S
输出特征图类别向量Ic
∥以下计算卡方独立性分数矩阵
C←zeros(shape(S)[0], shape(S)[0])
for i=0 to shape(S)[0]-1 do
for j=0 to shape(S)[0]-1 do
C[i,j]←l+m+h
Ic=DBSCAN(eps, minSamples).fit(C)
2 实验
2.1 实验数据
本文实验所使用的数据是由红外热成像仪采集的热成像影像。红外热成像仪型号是Fotric 618C,分辨率为640×480像素,镜头视场角水平29°,垂直21°,空间分辨率为0.78 mrad,响应波段为7.5 ~14 μm,测温范围为-20℃~650℃。由于仅测试所提出的特征图筛选方法对于卷积神经网络目标预测的提升效果,因此截取影像中的感兴趣目标,例如车辆、人物等。实验数据采集自户外道路场景,包括了车辆目标和人物目标,采集环境包括日间和夜间。
2.2 基准网络
为了测试所提出的特征图筛选方法对于卷积神经网络目标预测的提升效果,本文选择ResNet50作为基准网络,同时使用基于ImageNet 1000训练的预训练网络。使用ImageNet预训练网络,没有为热成像数据做针对性训练,也可以保证训练集与验证集来自不同的域,用以更好地测试域适应的效果。
2.3 预验证
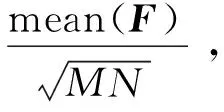

图2 预训练网络浅层特征图Fig.2 Low-level feature maps from pre-trained network
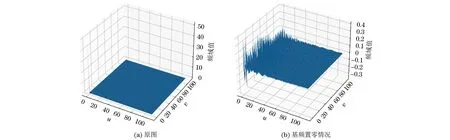
图3 特征图频域基频置零前后对比图Fig.3 Comparison of the original frequency domain diagram of the feature map and the frequency domain diagram with the base frequency been set to zero
典型特征图的频域图见图4。将基频置零后,部分特征图的频率成分主要集中在低频处[如图4(b)和图4(d)所示],另一部分特征图的频率成分相对平均地分布在3个频段内[如图4(a)和图4(c)所示]。观察特征图的频率图,人为筛选出中频成分占比较高的特征图,将其他特征图置零(如图5所示)。
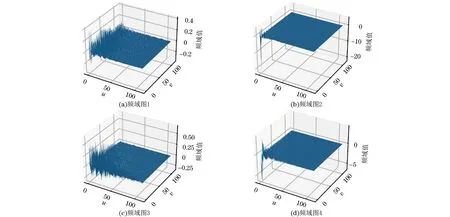
图4 典型特征图的频域图Fig.4 Frequency domain diagrams of typical feature maps

图5 人工置零后的浅层特征图Fig.5 Low-level feature maps after manual zeroing
在理想情况下,得分越高的类别应该更接近实际目标的类别,反之则类别与目标的实际类别应更无关。因此,根据网络输出得分最高的类别是否符合图片中目标的真实类别,可以检验网络的预测效果。ResNet网络原文[5]中即使用网络的top-5预测检验网络的效果,因此本文也选用了前5位预测输出考察预测结果。比较热成像影像的预训练网络的预测输出前5位和筛选后网络的预测输出前5位,并将可见光图像数据的预训练网络和筛选后网络的预测输出进行对比,结果见表1。可以看到,针对可见光图像数据训练的预训练网络在预测热成像数据时,前5位预测中识别为车辆的比例为0。但是经过特征图筛选后,预测结果更接近对可见光图像数据的预测结果,识别为车辆的比例达到了60%。此外,前5名预测结果中的“轮胎”和“格栅”虽然不是车辆的类别,但也是车辆的组件(格栅是指车辆前部进气口位置的格栅)。由此可以看出,筛选后的网络对可见光图像数据和热成像数据的车辆预测效果均较好。

表1 筛选前后目标预测结果对比Table 1 Prediction results comparison between original network and filtered network
2.4 特征图筛选
利用二维离散余弦变换对ResNet第1次卷积后提取的特征图进行频域变换,再将基频处置零。根据HUANG等[23]提出的3个频段的截止频率,计算特征图的频域图在低、中、高3个频段的分量,得到频段分量向量。然后根据所提出的独立性分数定义,计算64个频段分量向量之间的独立性分数,作为聚类的距离度量。使用近邻传播算法得到的聚类结果如图6所示,其中,第1类样本(图中右下)的低频分量占比较高,第2类样本(图中左上)的高频分量占比较高,第3类样本(图中左下)的高频和低频分量占比均相对较低,因此选择第3类样本作为需要保留的特征。
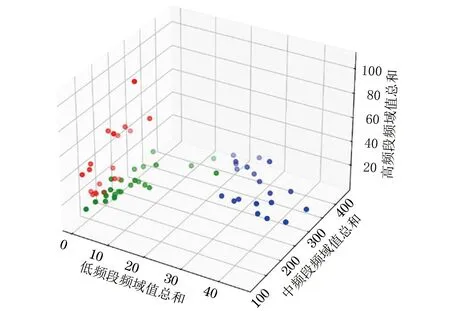
图6 近邻传播算法聚类结果Fig.6 Clustering result using affinity propagation algorithm
使用DBSCAN算法得到的聚类结果如图7所示,其中,第1类样本(图中左下)的高频和低频分量占比均较低,第2类样本(图中右部中间)的低频分量占比较高,其余样本(分布在左上、中后和右下)为离群样本,其中既有低频分量占比较高的样本,又有高频分量占比较高的样本,因此不做进一步区分,并将第1类样本作为需要保留的特征。
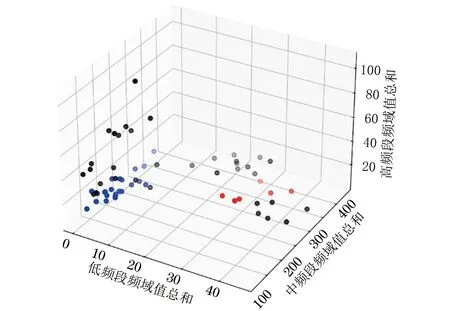
图7 DBSCAN算法聚类结果Fig.7 Clustering result using DBSCAN algorithm
使用近邻传播算法聚类后需要保留的特征图序列为[0,2,4,6,8,18,21,23,24,30,31,32,36,38,40,41,42,45,47,51,55,56,57,58,63],使用DBSCAN算法聚类后需要保留的特征图序列为[0,2,4,6,8,15,17,19,23,24,30,31,32,36,40,41,45,47,51,56,57,61,63],2种聚类方法保留的特征图序列的交集为[0,2,4,6,8,23,24,30,31,32,36,40,41,45,47,51,56,57,63],并集为[0,2,4,6,8,15,17,18,19,21,23,24,30,31,32,36,38,40,41,42,45,47,51,55,56,57,58,61,63]。
2.5 网络预测结果
2.5.1 车辆预测结果
将车辆的可见光图像数据与热成像数据分别输入经过筛选的网络进行预测。
当选用较为严格的聚类结果,保留2种方法的特征图序列交集时,预测结果如表2所示。由表2可见,虽然热成像数据预测结果相对较好,识别为车辆的比例为60%,但是可见光图像数据预测结果相比预训练网络的预测结果明显下降。

表2 保留特征图序列交集的车辆预测结果Table 2 Vehicle prediction result of filtered network which kept the intersection of feature map sets
当选用较为宽松的聚类结果,保留2种方法的特征图序列并集时,预测结果如表3所示。由表3可见,选用较为宽松的聚类结果,既能保证热成像数据预测的效果(识别为车辆的比例达到了90%),又能保证可见光图像数据的预测效果。

表3 筛选后网络保留特征图序列并集的车辆预测结果Table 3 Vehicle prediction result of filtered network which kept the union of feature map sets
表4对比了预训练网络和筛选后网络的预测结果。预训练网络预测热成像数据的前5位类别与实际目标完全无关。经过严格筛选的网络,对于热成像数据的预测效果得到了提升,但是会一定程度降低可见光图像数据的预测效果,而经过宽松筛选的网络则可以有效预测热成像数据的类别,同时仍具有对可见光图像数据的预测有效性。

表4 预训练网络及筛选后的网络对车辆预测结果对比Table 4 Vehicle prediction result comparison between pre-trained network and filtered network %
上述对比结果表明,本文提出的特征图筛选的这种域适应方法,可以将由可见光图像数据训练的网络应用于热成像数据。
2.5.2 人预测结果
预训练网络对于人的可见光图像数据和热成像数据的预测结果如表5所示,预测类别主要是人物身上的小饰品或衣物,并未将人作为整体而预测,这是因为预训练数据集的标注侧重于这些物品,而缺少人这个整体的分类;而热成像数据预测则与图像内容大多毫无关系。

表5 预训练网络的人预测结果Table 5 Human prediction result of pre-trained network
将人的可见光图像数据与热成像数据分别输入经过筛选的网络进行预测。保留2种聚类方法的特征图序列交集网络,预测结果如表6所示。由表6可见,在预测结果中,对人的图像可以预测出许多人物身上的配饰,但是更多的是与图像内容毫无关系的类别。保留2种聚类方法的特征图序列并集网络,预测结果如表7所示。由表7可见,预测结果与前一种筛选标准得到的预测结果类似,对人的检测结果较差,但是会预测人身上的配饰。

表6 筛选后网络保留特征图序列交集的人预测结果Table 6 Human prediction result of filtered network which kept the intersection of feature map sets

表7 筛选后网络保留特征图序列并集的人预测结果Table 7 Human prediction result of filtered network which kept the union of feature map sets
表8对比了车辆和人的可见光图像数据和热成像数据分别由预训练网络和筛选后网络的预测结果。当预训练网络对可见光图像数据的预测效果较好时,本文提出的特征图筛选的域适应方法能有效将网络用于热成像数据的预测,但是当预训练网络对可见光图像数据的预测较差时,本文提出的域适应方法并不能提升网络的预测效果。对比结果说明了训练用的数据集和预训练网络本身对于预测准确度的重要性。筛选特征图的域适应方法能使本身就具备较好预测能力的网络更好地迁移到不同的数据域中,但是不能改变网络从训练集中学习到的预测能力。

表8 预训练网络及筛选后网络整体预测结果对比Table 8 Overall prediction result comparison between pre-trained network and filtered network
3 结束语
本文提出了一种基于离散余弦变换和卡方独立性分数的卷积神经网络特征图筛选方法,直接提取出在可见光图像数据样本基础上得到的预训练网络中主要成分为域不变特征的特征图,从而实现网络的域适应,预测热成像数据。其中:离散余弦变换将特征图转换到频域,以便分离出特征图中随域改变和域不变成分;卡方独立性分数是根据卡方独立性检验的原理设计的一种根据特征图频段分量判断特征图相似性的指标。最后通过聚类算法,将特征图按频域特性分类,从而得到主要成分为随域改变特征的特征图和主要成分为域不变特征的特征图。对车辆图像的预测实验结果表明,该方法无需大量样本进行重新训练,就可以使基于可见光图像数据训练的网络同时适应可见光图像数据和热成像数据。筛选后的网络对热成像数据的前5位预测结果与目标相关的比例最高可达90%。但是对人的图像的预测实验结果表明,这种优化方法不能改变网络在预训练时的学习目标。
后续的研究可以考虑优化划分特征图频段的方法,寻找比凭经验设置三频截止频率更合理且有效的算法。同时,卡方独立性分数是受卡方独立性检验的启发而定义的,在卡方独立性检验中,只有当p值小于设定的阈值,如0.05时,才可以推翻原假设。这意味着在判断特征图频段分量相似性的时候,只有独立性分数大于0.95时,才能认为2个特征图差异较大。而根据统计学原理可知,这样的标准无法避免差异性较大的特征图被认为差异较小的错误,因此也值得进一步研究。此外,聚类分析的算法并未体现卡方独立性分数的统计学原理,后续也需要进一步研究和优化。
