基于改进YOLOv8的高速公路服务区车辆违停检测
2024-04-23陈伟王晓龙张晏玮安国成江波
陈伟,王晓龙,张晏玮,安国成,江波
(1. 上海华讯网络系统有限公司行业数智事业部,上海 200127;2. 中国电子科技集团公司第三十二研究所,上海 201808)
0 引言
高速公路服务区作为城市交通的重要基础设施,在保障人们出行安全,促进城市经济发展方面发挥着重要作用。服务区数字化建设对于提升城市管理水平、民众幸福感影响较大。因此,加快服务区管理的数字化转型是当务之急,也是各个城市建设的重要目标,需要调动社会各阶层的力量,思考如何通过人工智能、大数据、数字孪生等技术提升服务区智能化水平。
随着科技的进步,视频监控相关设备越来越普及,从个人住户到城市建设,遍布大街小巷,视频监控已经完全能够进行昼夜24 h不间断监控,为服务区数字化建设提供了技术支持与现实基础。近些年,人工智能技术也有了长足发展,尤其是深度学习技术的突破与普及,为服务区人、车、物的智能识别提供了技术保障。通过大量人工智能技术的应用,服务区可以从之前的人工、纸质和被动管理逐渐转变为机器管理、电子管理、主动发掘、自动处置等。在服务区管理工作中,车辆违停监测是服务区日常管理工作中非常重要的组成部分,也是交通智能化的关键步骤。传统通过人工进行异常停车行为监控的方法费时费力,无法满足自动化、智能化违停监管需求。随着深度学习技术的长足进步,相关算力资源的逐步丰富,也使得人工智能技术的应用成本越来越亲民。利用深度学习、大数据等各类新型技术可以实现服务区车辆智能管控,例如剩余车位数量分析、车辆违停监测、特殊车辆监管、车辆特征分析等。
由于服务区车流量大、人员混杂,因此造成服务区车位数量不能及时统计,而且人员素质参差不齐,服务区违章停车事件频发,致使服务区管理难度大、风险发现不及时,无法为有困难人员及时提供帮助。为此,需要利用人工智能技术进行服务区动态分析,实时分析服务区车位占用情况、违章停车情况,提高整个服务区的管理效率,降低服务区运维成本,提升服务区的智能化水平。
在实际应用中,基于深度学习的车辆目标检测算法精度受天气、光照强度、摄像机架设高度和拍照角度等因素的影响,加上服务区实际场景复杂多变,致使违停检测精度受到限制。针对上述问题,本文提出一种复杂环境下的高速公路服务区违停检测算法,利用改进的YOLOv8网络模型进行实时车辆检测,并通过基于全局匹配的停车位分配策略有效降低车辆违停检测的漏报率与误报率。
1 服务区智能分析
在传统服务区车位管理的过程中,通常采用地磁传感器的方式进行车位管理[1]。这种方式虽然具有准确度高的优点,但是设备一旦损坏,后期维护成本高,而且设备更换会影响车位的正常使用,并且当周围出现金属制品时,电磁传感器会受到严重影响,从而产生误报或漏报。另外,对于停车不规范等问题,也需要人工现场查看,增加了工作人员的工作负担。
随着服务区视频监控的逐步普及,服务区车位管理的技术手段也越来越多,尤其通过视频分析技术对服务区内的车位、车辆状态进行实时分析,可提高服务区处理异常事件的效率。因此,采用视频分析进行服务区车辆违章识别、车位管理具有很好的技术优势,而且推广普及性强。目前,已有学者们对此进行了一些研究并且取得了一定的成果。
李松江等[2]在主干网络的残差模块中嵌入通道注意力机制,提高YOLOv4[3]目标检测能力,通过对每个通道赋予不同的权重以获取跨通道的交互信息,增强遮挡目标的特征。杨露露等[4]提出改进的密集连接卷积网络[5],可增加对目标细节的感知能力,在特征提取的过程中重用并重建特征,以此缩减网络参数量,提升对小目标的检测精度。杨祖莨等[6]将深度学习与传统图像处理相结合,利用背景差分提取运动目标,使用卷积神经网络(CNN)[7]分类模型识别车辆目标,该方法可减少车辆目标误识别,但检测精度受差分算法固有缺陷限制。李国进等[8]提出改进的单次多盒检测器(SSD)[9]算法,均衡化融合浅层位置特征和深层语义特征,提高车辆目标识别率。SSD相比区域卷积神经网络(R-CNN)系列[10-13]等两阶段的深度学习目标检测算法检测速度更快,但精度不理想。近几年,YOLO系列一阶段目标检测算法以速度快、精度高等优势受到青睐,其中YOLOv3~8[3,14-16]、YOLOX[17]、YOLOR[18]系列检测模型在交通、电力等行业都有十分广泛的工程应用。
基于深度学习的服务区停车位检测算法首先采用目标检测算法对车辆目标进行检测与车型识别,其次通过计算车辆是否处于停车区域判断停车位是否被占用,最终根据停车位类型与车辆类型匹配结果,判断是否发生异常占用行为。虽然基于深度学习的检测算法摆脱了基于传感器的传统方法的限制,有效避免了物理位置限制和信号干扰问题,提升了系统可用性,但由于摄像头架设高度、拍摄角度、车辆遮挡因素,导致违停检测产生较多误报与漏报。本文提出一种改进的YOLOv8网络模型,优化空间金字塔池化(SPP)[19]特征融合层,并构建基于注意力机制[20]的膨胀空间金字塔池化(DSPP)模型,提高模型检测精度。在此基础上,提出一种基于全局匹配的停车位分配策略,降低车辆违停检测的漏报率与误报率。
2 改进的车辆违停检测算法
算法流程如图1所示。首先,利用改进的YOLOv8网络模型对视频监控画面中车辆进行定位和车型识别;其次,利用基于全局匹配的停车位分配策略将车辆与停车位进行绑定;最后,判断停车位状态是否为违停占用。
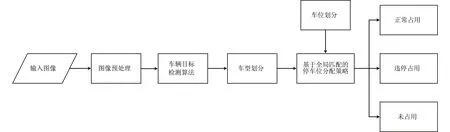
图1 车辆违停检测算法流程Fig.1 Procedure of vehicle violation detection algorithm
2.1 改进的YOLOv8网络结构
YOLO系列算法是端到端的一阶段目标检测算法,网络结构分为特征提取基网、特征融合颈部以及头部检测网络3个重要部分。通过控制深度和宽度2个参数,可调节网络深度和卷积宽度,从而衍生出不同尺寸的模型。图2为YOLOv8通用网络结构(彩色效果见《计算机工程》官网HTML版,下同)。以640×640像素输入图像为例,使用卷积神经网络对输入图像进行降采样和高维语义特征提取。在主干网络中,C2f模块为基于2个卷积层的跨阶段局部融合[21]模块,能够有效提取图像特征。SPP模块通过最大池化操作融合来自不同感受野的特征,并将任意大小的特征输入并转换为固定大小的特征向量,实现多尺度的特征融合。特征融合颈部采用特征金字塔网络(FPN)[22]和路径聚合网络(PAN)[23]进行不同尺度的特征融合,进一步提升对稠密目标的检测效果,网络最终输出80×80、40×40、20×20像素3种尺度特征图。在模型推理阶段,结合先验锚框使用非极大值抑制(NMS)去除冗余的检测框,保留置信度最高的预测框,从而完成目标检测过程。

图2 YOLOv8网络结构Fig.2 Network structure of YOLOv8
YOLOv8网络模型中的特征融合模块沿用了YOLOv5中的SPP模块,如图3所示。SPP模块能将任意大小的特征图输出为固定大小的特征向量,从而融合不同的感受野特征图,但随着MaxPool采样核尺寸逐渐增大,MaxPool在增加感受野的同时会丢失更多深层语义信息,导致模型检测精度受限。

图3 SPP模块结构Fig.3 Structure of SPP module
2.1.1 改进的膨胀空间金字塔池化模块
SPP中的池化层本身不具备学习能力,最大池化操作本质上是选择池化窗口内特征图的最大值。因此,MaxPool并不关心特征在池化窗口中的具体位置。在分类任务中,MaxPool可以缓解模型对特征的位置敏感性,但在目标检测任务中,该操作会导致深层特征的位置信息损失。此外,在车辆目标检测任务中,货车、小型货车、危化品车等一些属于大目标的车辆类别的类间差异较小,MaxPool操作会在一定程度上丢失了部分可用于区分这些类别的细节特征。为解决SPP中最大池化层导致的语义信息丢失问题,提出一种改进的SPP模块,即DSPP模块。
在DSPP中,利用分组膨胀卷积代替最大池化,在参数量几乎没有增加的前提下,最大程度地保留各感受野分支的语义信息。图4为最大池化与分组膨胀卷积操作。DSPP模块设计受膨胀卷积[24]与分组卷积[7]的启发。膨胀卷积在普通卷积的基础上,通过控制卷积核采样间隔来改变感受野,在相同的计算条件下,膨胀卷积相比普通卷积能够获取更大的感受野。分组卷积则将输入特征图分为多组,每组特征独立进行卷积操作,再将各组卷积结果拼接起来形成输出,从而有效降低模型参数量。DSPP结合膨胀卷积与分组卷积进行多尺度特征图融合,模块结构如图5所示,其中,深度可分离卷积(DWConv)模块代表分组膨胀卷积,DWConv首先对输入特征图按通道分组,并将分组数设置为输入通道数,对每组特征图进行膨胀卷积,卷积核尺寸为5。对于不同尺寸的输入特征图,膨胀卷积率分别设置为1、2、3,对应感受野为5、9、13,与SPP感受野一致。DSPP兼具膨胀卷积与分组卷积优势,相比SPP在相同感受野的特征提取分支中,能更快速地提取特征信息。

图4 最大池化与分组膨胀卷积操作Fig.4 Maxpooling and group dilation convolution operation
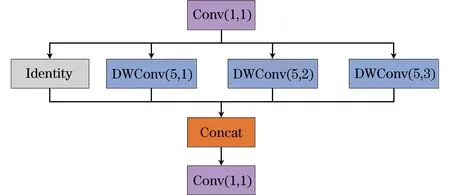
图5 DSPP模块结构Fig.5 Structure of DSPP module
2.1.2 基于注意力的膨胀空间金字塔池化模块
在目标检测中,深层特征具有更大的感受野,包含更多的全局信息,更适于大目标预测,而浅层特征更关注局部信息,更适于小目标预测。DSPP能有效融合浅层与深层语义特征,但由于不同感受野特征对于不同尺寸的目标预测贡献不同,因此为使模型学习到不同感受野的特征信息对目标预测的贡献,引入注意力机制,学习不同输入特征对输出的贡献程度。通过赋予不同注意力权重,使网络更关注那些对目标预测更为重要的特征,抑制无关的特征。在DSPP的基础上增加分支注意力(BA)机制,构建基于分支注意力机制的DSPP(DSPPA)模块,结构如图6(a)所示,分支注意力模块结构如图6(b)所示。在BA中引入通道注意力机制[25],其中,ci表示输入特征图通道数,经过全局平均池化和全连接操作,全连接层输出通道数为1,再经过Sigmoid归一化操作后得到分支的权重值,将权重与输入特征图相乘,输出带权重的特征信息。

图6 DSPPA模块结构Fig.6 Structure of DSPPA module
2.2 基于全局匹配的停车位分配策略
在服务区停车场景中,由于部分摄像机安装角度差异、车体高度差异以及摄像机拍摄图像本身不具备深度信息等因素使得基于交并比(IoU)、中心点等停车位匹配方法误匹配情况急剧增多,导致车辆违停误报率较高,如图7所示。为此,提出基于全局匹配的停车位分配策略,可在很大程度上缓解上述问题引起的车辆-停车位误分配问题,策略流程如图8所示。利用改进的YOLOv8目标检测算法获取车辆目标位置坐标以及车辆类别,同时将停车位划分为小型客车车位、货车车位、危化品车位等,将检测出的10类车辆按照停车位类型进行分组并得到待匹配的停车位与车辆目标。

图7 拍摄角度、车体高度等差异产生的误分配Fig.7 Mismatching caused by differences such as shooting angle and vehicle height

图8 基于全局匹配的停车位分配策略流程Fig.8 Process of parking space allocation strategy based on global matching
2.2.1 加权IoU停车位匹配
基于IoU的车辆-停车位划分算法,通过计算停车位面积占用率来确定将车辆目标划分到哪个停车位,停车位面积占用率是指停车位区域中被车辆矩形区域覆盖的面积与停车位区域总面积之比,计算公式如式(1)所示:

(1)
在实际停车位占用检测场景中,受摄像头安装高度、角度、车体高度差异等因素影响,对停车位占用检测识别造成不同程度的干扰。通过对多个不同拍摄角度图像进行观察发现,当车辆停放在停车位上时,不管从何种角度拍摄停车位,停车位中心区域与车辆矩形框的重合度很高,而停车位中边缘区域占用率会随摄像机拍摄角度变化而变化。基于以上分析,将停车位划分为不同区域,赋予中心区域较高权重,四周区域较低权重。通过计算各区域占用IoU的加权和得到加权停车位占用率。相比单纯IoU匹配,加权IoU停车位匹配能有效减少不同拍摄角度造成的匹配误差。图9为停车位区域划分,其中,wij停车位子区域对应IoU权重。

图9 停车位占用权重划分Fig.9 Weight division of parking space occupancy
加权停车位占用率的计算公式如式(2)所示:
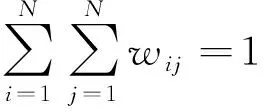
(2)
其中:Sij表示车辆矩形区域与对应停车位子区域重叠面积;Dij表示停车位对应子区域的图像面积。
2.2.2 全局停车位匹配
虽然基于加权IoU的停车位匹配策略可减少误匹配问题,但基于IoU匹配的策略始终存在同一停车位被分配给不同车辆的情况。为解决停车位重复匹配问题,在加权IoU停车位匹配的基础上,引入匈牙利分配算法,全局搜索最佳的停车位和车辆匹配组合。结合加权停车位IoU,构建匈牙利匹配算法所需的代价矩阵:
Cij=1-Cwaccuij
(3)
其中:Cwaccuij代表第i个车位和第j辆车匹配的加权停车位占用率,即匹配程度,通过设定占用率阈值t,将占用率低于t的元素设置为0,删除部分匹配度低的组合,从而降低匹配复杂度;C为匈牙利匹配所需的代价矩阵,代价矩阵中每一个元素Cij代表第i个停车位与第j辆车匹配所需的代价,代价越小,匹配程度越高。
利用占用率代价矩阵进行匈牙利匹配,计算出能够使总体代价最小的匹配组合:若停车位能匹配到车位,则该停车位状态更新为占用;若没有可与停车位匹配的车辆,则车位状态更新为未占用;结合停车位类型与占用该停车位的车辆类型,判断是否为违停。
3 实验与结果分析
3.1 数据集
为验证改进模型的性能,采用公开数据集PASCAL VOC2012(简称为PASCAL VOC)和COCO2017进行消融实验。PASCAL VOC数据集中包含20类标注目标,共包含11 540张图像,其中,训练集包含5 717张图像,验证集包含5 823张图像。COCO2017数据集包含80个类别标注目标,共包含123 287张图像,其中,训练集包含118 287张图像,验证集包含5 000张图像。此外,收集湖州市某高速公路及其服务区视频监控数据构建数据集,包含不同天气、拍摄角度以及昼夜的图像数据,并标注10类车型目标用于车辆目标检测,图10为各车型样本数量分布。自建数据集共有16 003张图像,包含75 811个车辆样本,其中,训练集包含12 803张图像,验证集包含3 200张图像。

图10 各车型样本数量分布Fig.10 Distribution of number of samples for different kind of vehicles
3.2 数据增强与模型训练
为满足复杂环境下的服务区车辆目标检测任务,使用多种数据增强策略,通过随机色彩空间变换、亮度变换、尺寸缩放、水平翻转、随机Mosaic等对训练数据进行增强操作。
在训练过程中,在公开和自建数据集上均采用相同的训练参数。图像输入尺寸为640×640像素,训练迭代轮次为200,Batch Size为32,优化器为Adam,初始学习率为0.001,学习率余弦更新因子为0.01,权重更新动量为0.923,衰减系数为0.000 4,使用分布焦点损失(DFL)计算目标损失,将二元交叉熵损失作为类别损失,将IoU损失作为位置损失。
3.3 结果分析
采用准确率、召回率、mAP@0.5、mAP@0.5∶0.95作为模型性能评估指标。准确率是指正确预测的样本数量与预测总样本数量的比值;召回率是指正确预测的样本数量与实际正样本数量的比值;mAP@0.5是指IoU阈值设为0.5时所有类别预测的平均精度均值;mAP@0.5∶0.95是指当IoU阈值设定为0.5~0.95时所有类别预测的平均精度均值。
为比较DSPP、DSPPA、SPP模块的性能差异,对这3个模块进行消融实验,如表1所示。由表1可以看出:在不同输入特征图尺寸下DSPP相比SPP模块的参数量和每秒浮点运算次数(FLOPS)几乎没有变化,当输入特征图尺寸为(32,1 024,20,20)时运行速度从35帧/s提升到63帧/s,当输入特征图尺寸为(32,1 024,40,40)时,运行速度从24帧/s提升到29帧/s;DSPPA相比SPP参数量有少量增加,但运行速度相比SPP仍有显著提升。由此可见,与SPP相比,DSPP与DSPPA具有更高的运行效率。

表1 改进的特征融合模块性能对比Table 1 Comparison of improved feature fusion modules
表2显示了改进的YOLOv8模型在PASCAL VOC数据集上的性能对比。由表2可以看出:
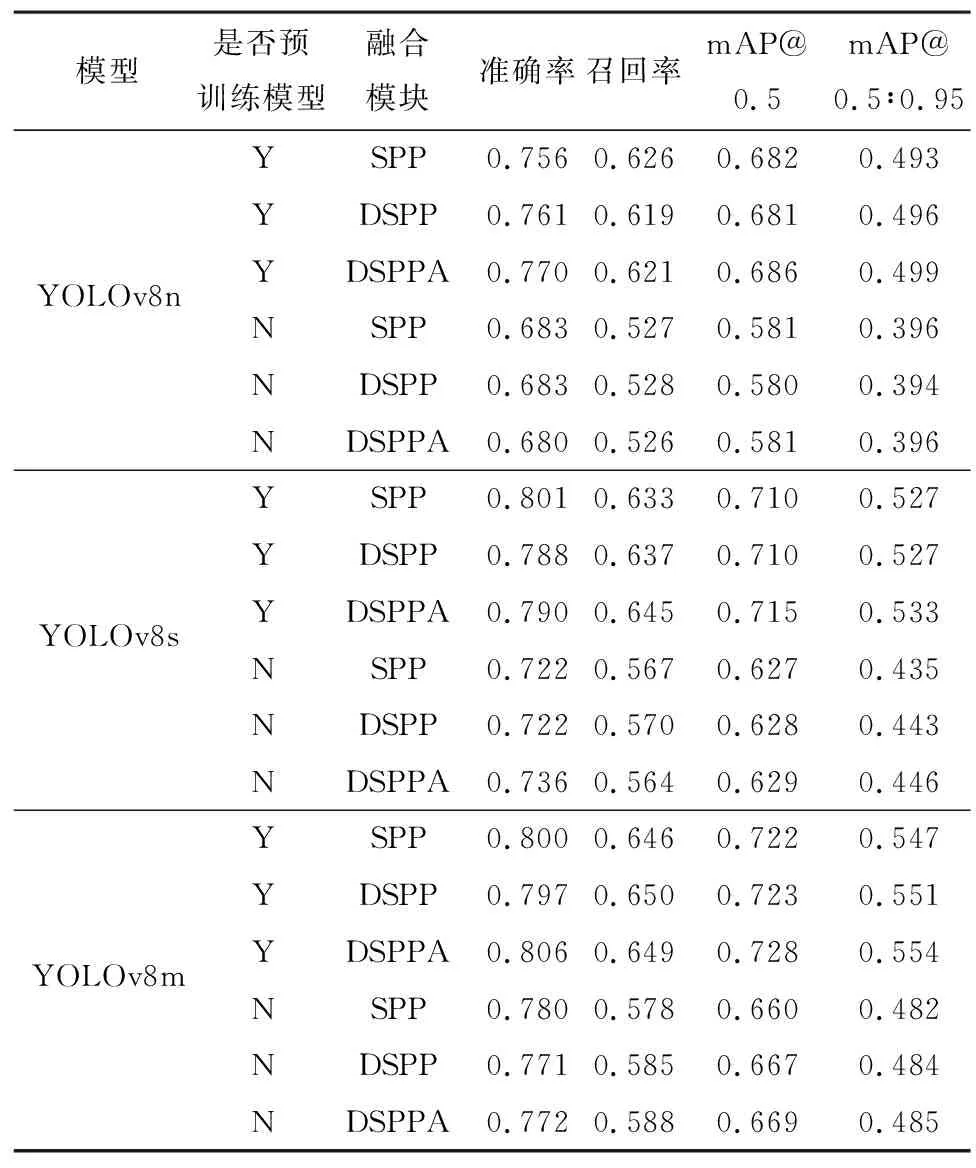
表2 改进模型在PASCAL VOC数据集上的性能对比Table 2 Comparison of performance of improved models on the PASCAL VOC dataset
1)当使用预训练模型时,使用DSPP与DSPPA后,3种不同尺寸的YOLOv8(n, s, m)模型均有不同程度的性能提升,其中以YOLOv8s和YOLOv8m最为显著。在使用预训练权重进行迁移训练时,基于DSPPA的YOLOv8s模型在mAP@0.5上的模型精度提升0.005个百分点,在mAP@0.5∶0.95上的模型精度提升0.006个百分点,YOLOv8m在mAP@0.5上的模型精度达到72.8%,相比原模型提升0.006个百分点,在mAP@0.5∶0.95上的模型精度提升0.007个百分点。
2)当不使用预训练模型时,基于DSPPA的YOLOv8s模型在mAP@0.5∶0.95上达到44.6%,相比原模型提升0.011个百分点,YOLOv8m在mAP@0.5上的模型精度达到66.9%,相比原模型提升0.009个百分点。
为进一步验证改进模型的泛化性能,在COCO2017数据集上进行消融实验。表3为在不使用预训练权重的前提下,改进的3种不同尺寸的YOLOv8模型在COCO2017数据集上的精度对比。由于COCO2017数据集相比PACAL VOC数据集体量更大,目标类别更多,图像场景更复杂,改进模型在COCO2017数据集上的性能提升虽不如PASCAL VOC数据集明显,但仍能看出基于DSPPA的改进YOLOv8n等模型性能有不同程度的提升,其中,YOLOv8s在mAP@0.5、mAP@0.5∶0.95上精度均提升0.005个百分点。

表3 改进模型在COCO2017数据集上的性能对比Table 3 Comparison of performance of improved models on the COCO2017 dataset
以上实验结果证明,DSPP、DSPPA模块能够有效提升模型精度。
在自建数据集上进行消融实验,使用英伟达A30 GPU进行模型推理速度验证。由表2可知,在预训练模型的情况下,YOLOv8n、YOLOv8s、YOLOv8m模型性能均有提升,且PASCAL VOC数据集中包含车辆目标的图像多为道路交通场景,与高速公路服务区场景有相似之处,因此使用PASCAL VOC数据集上的预训练模型作为初始化权重进行模型训练,实验结果如表4所示。由表4可以看出,虽然YOLOv8m模型参数量相比YOLOv8n、YOLOv8s更大,但准确率、召回率、mAP@0.5以及mAP@0.5∶0.95远高于YOLOv8n和YOLOv8s,其中mAP@0.5达83.6%,且当模型推理Batch Size设为16时,YOLOv8m的模型运行时间为4.2 ms(包含图像前处理、模型推理和后处理),完全满足高速公路服务区违停识别场景的实时性要求。实验结果表明,在高速公路服务区车辆数据集上,YOLOv8m模型参数量适中,精度相对较高,推理速度满足实时需求,能达到速度与精度的平衡,因此选择YOLOv8m模型作为高速公路服务区目标检测任务的基础模型。
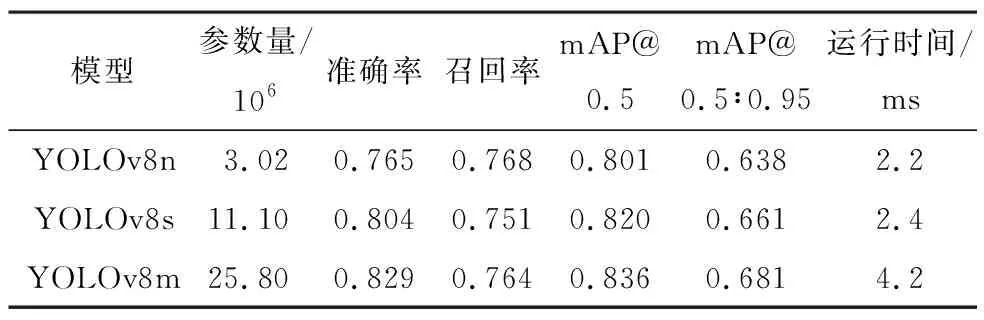
表4 改进模型在自建数据集上的性能对比Table 4 Comparison of performance of improved models on self-built dataset
为进一步验证改进的车辆违停检测算法有效性,连续14 d采集湖州市某高速公路服务区16个视角的视频监控画面,包含日间、夜间、晴天、雨天等不同环境图像数据,共统计375个违停事件。在使用原YOLOv8模型并使用中心点匹配方法进行违停检测时,共计检测出441个违停事件。由图11可以看出,改进前漏报事件数量为28,漏报率为7.5%,违停误报事件数量为66,误报率达15%。经统计发现:部分误报是由于检测模型将小型客车识别为小型货车,在某些监控视角下货车箱体过大,车辆目标框与多个停车位产生交集,导致车位错误分配,应用改进的YOLOv8检测模型以及基于全局匹配的停车位分配策略,违停漏报率下降为6.1%,相比改进前下降0.014个百分点,验证了改进的YOLOv8模型的有效性,违停误报率下降到8%,相比改进前下降近0.07个百分点,进一步说明了改进的车辆违停检测算法的有效性。

图11 改进前后的车辆违停检测算法的漏报率与误报率对比Fig.11 Comparison of false-negative and false-positive rates between pre- and post-improvement vehicle violation detection algorithms
改进的车辆违停检测算法在高速公路服务区的部分视频检测可视化结果如图12所示。由图12可以看出,改进的车辆违停检测算法在具有视角倾斜、遮挡、夜间等多种复杂环境的高速公路服务区停车场景中均有良好检测性能。

图12 高速公路服务区车辆违停检测可视化结果Fig.12 Visualization results of vehicle violation detection in highway service areas
4 结束语
本文提出一种适用于高速公路服务区复杂环境的车辆违停检测算法,改进YOLOv8网络模型中的特征金字塔池化层,构建DSPP与DSPPA模块,使得目标检测网络能够保留更多深层语义信息,同时设计基于全局匹配的停车位分配策略,解决了拍摄角度偏差、车体过大、车辆重叠等情况下停车位误分配问题。实验结果表明,该算法能有效降低高速公路服务区车辆违停检测的漏报率与误报率,具有较好的场景适应性与环境鲁棒性,为高速公路服务区停车智能化管理提供了一种切实可行的解决方案。
