基于用户权威度和多特征融合的微博谣言检测模型*
2024-04-23许莉芬曹霑懋郑明杰肖博健
许莉芬,曹霑懋,郑明杰,肖博健
(1.华南师范大学计算机学院,广东 广州 510631;2.华南师范大学人工智能学院,广东 佛山 528200)
1 引言
社交媒体是新闻传播、政治活动、科学发现或产品广告的流行媒介。由于社交媒体可以快速广泛地传播信息,总有人为了特定的利益,在网络上发布谣言信息,严重影响了网络的良性发展,甚至影响社会稳定。有效地检测谣言有利于净化网络空间和维护社会稳定,具有十分重要的现实意义。
为了进行谣言检测,一些研究对社交网络中的用户特征进行建模,从用户群体中提取特征,如用户信息[1]和用户历史行为[2,3]等,并结合机器学习和深度学习模型实现谣言检测。
Rieh[4]发现,信息的可信度由其来源的权威度所支配。微博用户作为信息发布和传播的主体,其权威度是传播影响因素中的一个重要评价指标。研究用户权威度,对于预测帖子的真实性具有积极的意义。
研究表明[5],信息的语言风格和语气有助于区分虚假陈述和真实陈述。说谎者在讲述虚假的故事时倾向于更频繁地使用负面情绪词,作为内疚的标志,同时也倾向于在文本中频繁使用感叹号和问号,表达发布者激动的心情。Li等人[6]验证了将发布的文本中的语境特征(如情绪和标点符号的使用特征等)视为传播谣言有关的线索是合乎逻辑的。
在谣言检测领域,研究人员在3个方面打下了坚实的理论基础:用户、语境和文本特征表示。但是,传统的用户特征强调用户属性和用户关联的关系,在谣言检测任务中还没有对社交网络中的用户权威度进行精确的定量表示,这使得量化用户权威度并将其与谣言识别相结合很难。
针对上述问题,本文提出基于用户权威度和多特征融合的谣言检测模型MRUAMF(Microblog Rumor detection model based on User Authority and Multi-feature Fusion ),主要工作如下:
(1)提出了一种用户权威度的计算方法并将其用于谣言检测。
(2)提出了一种基于用户特征、语境特征和文本特征融合的特征表示策略。使用BERT(Bidirectional Encoder Representations from Transformers)模型获得文本特征,并结合多模态适应门MAG(Multimodal Adaptation Gate)[7]将用户特征、语境特征与文本特征进行融合。
(3)本文在微博谣言数据集上进行了实验,以检验MRUAMF模型的有效性。
2 相关工作
现有的谣言检测方法大致可以分为2类:手工特征提取的方法和基于深度学习的方法。
传统的基于手工特征提取的方法主要从3个方面来设计谣言检测模型:(1)关注统计文本内容和用户信息的特征构造检测模型。如Liang等人[8]利用用户行为的手工特征进行建模检测,Castillo等人[9]提取用户信息和发表的微博内容特征来构造谣言检测模型。(2)关注传播路径和传播节点等特征的传播结构检测模型。 如Kwon等人[10]利用谣言传播结构的特征设计谣言检测模型。(3)关注文本信息随时间变化的统计特征的时间序列检测模型。如Ma等人[11]认为谣言文本和非谣言文本在时间序列上变化的模式不同,并抓取多种社会上下文特征随时间流逝的变化,以此设计谣言检测模型。然而,基于手工特征提取的方法依赖特征的选取,且缺乏一种标准和系统的方法来设计跨平台的通用特征和处理不同类型的谣言。
深度学习的迅速发展催生了许多基于深度学习的谣言检测模型。由于增强了自动表示学习的能力,基于深度学习的谣言检测模型的检测性能要优于传统手工特征提取的谣言检测模型。大多数现有的基于深度学习的方法主要侧重于从文本内容、用户评论和图像中提取文本特征和视觉特征。Ma等人[12]首先提出用循环神经网络RNN(Recursive Neural Network)进行谣言识别,他们基于谣言传播过程中的转发时间序列数据,使用门控循环单元GRU(Gate Recurrent Unit)学习时间和文本特征。Shu等人[13]提出了一种共同关注网络,利用新闻内容和用户评论进行谣言检测。Jin等人[14]提出了一种用于提取视觉、文本和社会背景特征的模型。此外,一些研究还采用了其它深度学习技术,如多任务学习[15]和对抗学习[16],来学习更丰富的内容感知特征。然而,有些谣言是故意通过模仿真实的新闻来撰写的。由于缺乏必要的领域知识,仅从内容特征方面构建谣言检测模型很难进一步提高检测性能。
一些研究人员意识到用户在谣言传播中发挥着重要作用。例如,Zhang等人[17]提出了一种名为Fake Detector的自动假新闻可信度推理模型。作者分析了多种属性,如用户个人资料特征、用户与假新闻创建者之间的联系,并使用深度扩散神经模型来学习文章内容、创作者和主题的特征。Dong等人[18]提出了一种用于谣言检测的具有用户和情感信息的分层注意网络。Chen等人[19]提出了用于谣言检测的具有注意力的用户方面多视图学习模型,有效地学习传播帖子的用户的个人资料视图、结构视图和时间视图表示,将学习到的用户特征与内容特征连接起来,用于检测任务。
尽管上述研究中提到的融合用户特征的方法在社交网络环境中检测谣言是有效的,但是也有一定的局限性。这些方法在用户级别上强调用户资料和用户关联的关系,但没有更进一步地挖掘用户资料。本文借助用户特征、语境特征与文本特征,并从用户权威度角度构建用户特征,通过深度学习来分析信息的真实性。
3 相关定义与模型准备
本节介绍用户权威度和语境的相关定义和计算方法,所涉及的重要符号如表1所示。
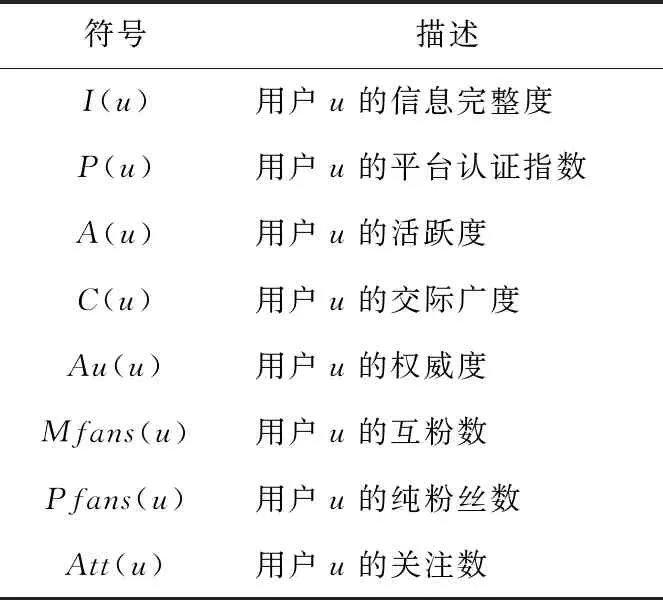
Table 1 Description of symbols
3.1 用户权威度
用户权威度[20]指用户在社交网络关系中具有的影响力与公众对其信服的程度。为了量化用户权威度,本文通过用户的交际广度(Commuication Span)来衡量用户的影响力,并从平台认证指数(Platform Authentication Index)、用户信息完整度(Information Integrity)和用户活跃度(Activity Degree)方面度量公众对其信服的程度。基于这些指标构建用户权威度。首先,考虑了用户信息完整度,完整的用户信息能够让公众更好地了解用户的背景和专业领域,从而更愿意信任用户的观点和意见。其次,考虑了用户的平台认证指数,认证身份能够提高用户在社交网络中的信誉度和影响力。第三,考虑了用户在微博上的活跃度,高度活跃的用户能够吸引更多的关注和互动,从而提高其影响力和信服程度。最后,鉴于广泛的社交网络关系能够提高用户的影响力和信服程度,本文考虑了用户的交际广度。
3.1.1 用户信息完整度
用户的信息能够反映用户的真实性,具有完整的、真实信息的用户会具有更高的权威度。用户信息包含昵称、性别、简介和地址信息。本文构建向量V=(v1,v2,…,vn)用以表示用户基本信息的填写情况。其中,vi表示序号为i的标签是否包含信息。当vi=1时,表示第i号的标签存在有效信息;当vi=0时,表示第i号的标签不存在有效信息。定义用户u的信息完整度I(u)为用户愿意公开的信息占所有信息标签的比例,如式(1)所示:
(1)
其中,n表示向量V的维度。
3.1.2 用户平台认证指数
定义用户u的平台认证指数P(u)为平台对用户给出的认证评价。平台认证是微博官方认证平台对用户进行审查认证。P(u)的计算方法如式(2)所示:
(2)
3.1.3 用户活跃度
定义用户u的活跃度A(u)为用户在一定时间内发布帖子的频率。用户活跃度计算方法如式(3)所示:
(3)
其中,Num(u)表示用户在时间段t内发布的帖子数量,这里的t指从用户注册起到获取数据的这段时间的天数。
3.1.4 用户交际广度
在微博社交网络中,用户通过关注成为对方的粉丝。粉丝表明他人对用户的关注,是对用户微博评论转发的潜在用户。用户拥有粉丝越多,与粉丝的交互程度越高,用户的影响力越大,权威度越高。用户u的交际广度C(u)的定义如式(4)所示:
(4)
其中,Pfans(u)表示用户纯粉丝数;Mfans(u)表示用户互粉数;Fans(u)表示用户粉丝数,Fans(u)=Mfans(u)+Pfans(u);Att(u)表示用户关注数;ω1表示用户纯粉丝数的权重系数,ω2表示用户互粉数的权重系数,初始值ω1=0.7,ω2=0.3。
3.1.5 用户权威度模型的构建
基于上述4个指标,本文使用层次分析法确定权重系数,并利用特征向量法计算用户权威度评价特征的权值,求解步骤如下:
步骤1设用户权威度评价的判断矩阵为B,其中的元素bi,j表示特征i相比特征j对评价结果影响的重要程度的倍数。本文认为,最能体现用户权威度的首要因素是用户交际广度,其次是用户平台认证指数,第3是用户活跃度,第4是用户信息完整度。之所以将用户信息完整度置于第4,是因为用户信息中可能含有虚假的成分。按照四元组(I(u),A(u),P(u),C(u))为判断矩阵B赋值,如式(5)所示:
(5)
步骤2求解判断矩阵B的最大特征值的特征向量并进行归一化处理,得到各个指标的权重μ,如式(6)所示:
μ=(0.0439,0.0885,0.3286,0.5390)
(6)
本文构建的用户权威度定量计算模型的量化计算方法如式(7)所示。
Au(u)=(I(u),A(u),P(u),C(u))×μT
(7)
3.2 语境
语境对信息的传播有强大的影响力。情绪是语境的重要组成部分。谣言往往具有消极的情绪,具体来说,谣言的语气总是很强烈,感叹号的使用比较频繁[6],尤其是当情感是怀疑或惊讶时,问号和感叹号的出现次数较多,因此可以将情绪、问号与感叹号的数量作为区分谣言的特征。
3.2.1 情绪
本文提取用户发布的帖子和对应转发的帖子的文本进行情绪分析。调用中文情感分析库cnsenti,将情绪划分为好、乐、哀、怒、惧、恶、惊7种情绪,并统计7种情绪词的频数。本文选择其中频数最大的情绪词作为帖子的情绪代表。
3.2.2 问号和感叹号数量
本文统计源帖及其转发帖子中问号和感叹号的数量,并将其作为区分谣言的特征之一。
4 MRUAMF模型
4.1 模型结构
MRUAMF模型主要包括5个部分:用户特征提取、语境特征提取、文本特征提取、多特征融合和预测分类。在用户特征挖掘上,将用户权威度及其4项构成指标作为用户特征。在语境特征挖掘上,进行情绪统计分析,并统计符号数量。图1显示了MRUAMF模型的总体结构。

Figure 1 Structure of MRUAMF model
4.2 输入
按照第3节的描述收集用户信息,包括:(1)昵称;(2)简介;(3)性别;(4)粉丝数;(5)互粉数;(6)关注数;(7)是否经过微博认证;(8)地址信息;(9)历史发布的帖子数量。每条源帖下包含了其他用户转发的帖子,本文对源贴及其转发帖子的文本内容进行统计分析,获取文本情绪标记、问号和感叹号的数量。
4.3 特征提取与融合
4.3.1 用户特征提取
本文使用2层全连接网络提取与用户权威度相关的指标作为用户特征,包括:(1)平台认证指数;(2)活跃度;(3)交际广度;(4)信息完整度;(5)权威度。
将用户特征用向量Vu=(vp,va,vc,vi,vr)表示,向量中的每个值分别对应上述5种特征,即平台认证指数、活跃度、交际广度、信息完整度和权威度的数值。本文使用2层全连接网络对用户特征进行学习和融合,2层全连接网络的计算过程和输出如式(8)和式(9)所示:
U′=ReLU(Wu1Vu+bu1)
(8)
U=ReLU(Wu2U′+bu2)
(9)
其中,Wu1和Wu2分别表示第1层和第2层全连接网络的权重矩阵,bu1和bu2表示相应的偏移项。U′表示相应的第1层全连接网络输出的中间向量,U表示相应的第2层全连接网络输出的用户融合特征向量,U∈R768。本文使用修正线性单元ReLU(Rectified Linear Unit)函数作为激活函数。
4.3.2 语境特征提取
根据第3节的描述,本文选取以下语境特征:(1)情绪;(2)问号的数量;(3)感叹号的数量。
对情绪标签进行预处理,对情绪的分类标签使用数值代替,将7种情绪映射到0~6的整数。用向量Vc=(vs,vq,ve)表示语境特征,向量中的每个值分别对应上述语境特征的数值。本文使用2层全连接网络对语境特征进行学习和融合,2层全连接网络的计算方法和输出公式如式(10)和式(11)所示:
C′=ReLU(Wc1Vc+bc1)
(10)
C=ReLU(Wc2C′+bc2)
(11)
其中,Wc1和Wc2分别表示第1层和第2层全连接网络的权重矩阵,bc1和bc2分别表示相应的偏移项。C′是第1层全连接网络输出的中间向量,C是第2层全连接网络输出的语境融合特征向量,C∈R768。
4.3.3 文本特征提取
本文使用BERT提取文本特征。BERT模型能够联系上下文语义进行学习,结合自注意力机制考虑每个词语对其他词语的重要程度,预训练出来的向量表示效果比word2vec的更好。BERT模型主要包括2个阶段:编码阶段和生成向量表示阶段。使用BERT模型在数据集上进行微调,获得文本特征Z∈R768。
4.3.4 特征融合
受多模态适应门(MAG)的启发,本文将3种特征即文本特征、用户特征和语境特征通过MAG进行特征融合,如图2所示。MAG单元接收3个特征作为输入。令三元组(Z,U,C)表示文本特征、用户特征和语境特征输入。Z表示文本特征,U表示用户特征,C表示语境特征,其维度均为768。将文本特征分别与用户特征和语境特征拼接得到[Z;U]和[Z;C],并利用它们生成2个注意力门控向量gu和gc:

Figure 2 Structure of MAG combining user feature and context feature
gu=ReLU(Wgu[Z;U]+bu)
(12)
gc=ReLU(Wgc[Z;C]+bc)
(13)
其中,Wgu和Wgc分别表示用户和语境的权重矩阵,bu和bc表示相应的偏移向量。
然后,分别将U和C与各自的注意力门控向量相乘获得向量H,如式(14)所示:
H=gu·(WuU)+gc·(WsC)+bH
(14)
其中,Wu和Ws分别表示用户信息和语境信息的权重矩阵,bH表示偏移向量。

(15)
(16)
其中,β表示通过交叉验证过程选择的超参数,‖Z‖2和‖H‖2分别表示Z和H的L2范数。
4.4 预测分类
本文使用Softmax分类器进行谣言检测,预测结果如式(17)所示:
(17)
其中,Wz表示权值矩阵,bz表示偏置向量,Softmax(·)激活函数用于判断目标是否为谣言。
5 实验与结果分析
为了验证MRUAMF模型的有效性,本节在同一个微博数据集上将其与其它基线模型进行比较,并设计一系列实验验证MRUAMF模型的合理性。
5.1 实验设置
5.1.1 实验数据集
数据集来源于Ma等人[21]构建的微博谣言数据集,该数据集包含4 664个源帖,每条源帖下有若干条转发的帖子,同时还包含了用户的信息。
本文分别选取60%的微博数据集组成训练集,30%组成测试集,10%组成验证集。数据集的统计信息如表2所示。
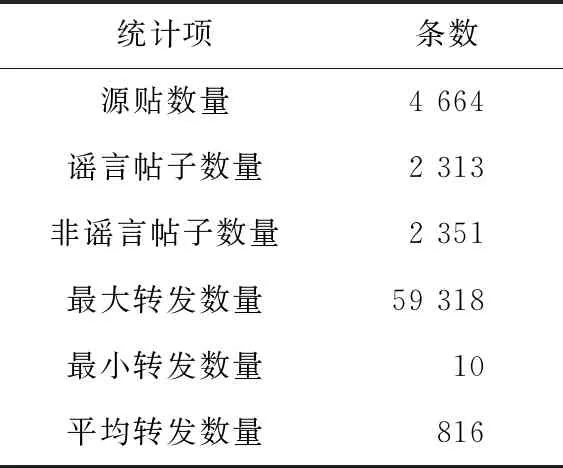
Table 2 Statistic of dataset
5.1.2 实验参数设置
本文使用PyTorch深度学习框架编码模型,使用Adam优化器进行训练,学习率为5e-5;使用交叉熵损失函数;设置BERT网络的随机失活率为0.1,批大小为16。
5.1.3 评价指标
本文采用准确率(ACC)、精确度(P)、召回率(R)和F1分数(F1)作为评估指标来衡量模型的性能。
5.1.4 基线模型
在微博数据集上,本文提出的MRUAMF模型与下列基线模型进行对比实验:
(1)DTC(Decision Tree Classifier)[22]:基于用户行为特征,使用决策树分类器DTC进行谣言识别的模型。
(2)SVM-RBF(Support Vector Machine using Radial Basis Function)[23]:使用径向基函数RBF作为核函数的支持向量机SVM模型。
(3)GRU[14]:基于RNN的谣言识别模型,用于捕获谣言识别输入的上下文信息。
(4)TD-RvNN(Top-Down tree-structured Recur- sive Neural Network)[24]:一种基于RNN的树结构模型,该模型在树结构中嵌入隐藏的指示信号,并探索帖子内容对谣言检测的重要性。
(5)PLAN(Post-Level Attention Network)[25]:一种用于谣言检测的分层令牌和后级注意力模型。
(6)GCAN(Graph-aware Co-Attention Network)[26]:一种图感知共同关注网络,利用源帖的内容及其基于传播的用户来检测信息的真实性。
(7)UMLARD(User-aspect Multi-view Learning with Attention for Rumor Detection)[19]:一种用于谣言检测的用户端注意力多视角学习模型,该模型学习传播帖子用户的不同视图表示,并将学到的用户方面特征与内容特征连接起来。
所有模型在测试集上的实验结果如表3所示。

Table 3 Experimental results of different models (R:rumor,N:non rumor)
5.2 实验分析
5.2.1 与基线模型的比较与分析
表3的实验结果表明,传统的基于手工特征提取的模型如DTR、SVM-RBF的效果均不佳。这些模型基于帖子的统计数据使用手工提取的特征,不足以捕捉文本的可概括性特征,无法形成文本特征间的高级交互。
基于深度学习的模型优于基于手工特征提取的模型。GRU和TD-RvNN均是基于RNN的模型,PLAN使用自注意力机制用于模拟帖子之间的交互,其效果比GRU和TD-RvNN的要优。但是,上述3种模型主要关注文本信息而忽略了其他类型的特征。
GCAN从用户相似度建模,提取传播帖子的用户特征和源帖文本特征。UMLARD通过对用户的信息进行建模丰富了谣言检测的工作主体。GCAN和UMLARD的检测效果比PLAN的性能更佳,这个结果也验证了用户特征在传播谣言的过程中起着重要的作用,用户是错误信息的主要传播者。
MRUAMF模型在微博数据集上优于所有对比基线模型。与最佳基线模型UMLARD相比,MRUAMF模型通过用户权威度构造用户特征,并融合了语境特征,从而提高了检测效果。
5.2.2 不同输入特征对预测结果的影响
本文在特征提取部分介绍了文本、用户和语境融合特征。本节介绍基于不同特征组合的消融实验。设置了4种特征组合,第1组为文本特征,第2组为文本特征+用户特征,第3组为文本特征+语境特征,第4组为文本特征+用户特征+语境特征。消融实验结果如图3所示。
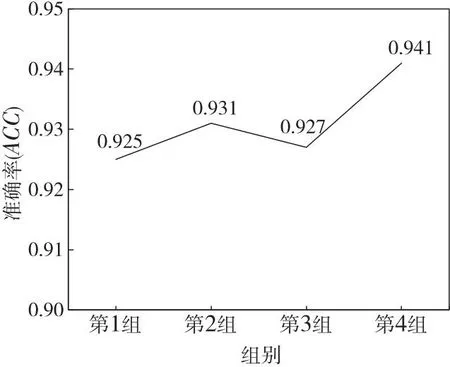
Figure 3 Results of ablation experiment
图3表明,相较于第1组,其余3组在该数据集上表现更好,这说明增加用户特征或语境特征作为辅助特征可以丰富谣言语义信息,从而提高检测效果。在ACC指标上,第4组的测试结果相比第2组和第3组均有所提高,这证实了本文使用文本、用户和语境3种类型的特征对提高谣言检测能力有积极的影响。通过从用户信息和语境信息这2个不同的角度提取特征,引入多特征融合,使模型能够更好地实现分类预测。
5.2.3 不同特征融合方法对预测结果的影响
本文使用MAG处理特征融合,本节将其与其它常用的特征融合方法进行对比,以探索它们对性能的影响,结果如表4所示。
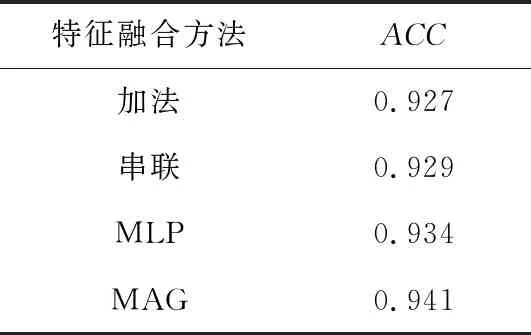
Table 4 Results of different feature fusion methods表4 不同特征融合方法结果
表4中的融合方法包括:(1)加法:Z+U+C;(2)串联:[Z;U;C];(3)MLP:Z+tanh(W1U+b1)+tanh(W2C+b2),其中,W1和W2表示权重矩阵,b1和b2表示偏移项,tanh(·)是激活函数。
从表4可以看出,使用MAG的融合方法在ACC指标上均优于另外3种方法,这表明了使用MAG进行多特征融合的有效性。
5.2.4 用户权威度分析
令标签UR和UN分别表示发布谣言的用户和发布非谣言的用户。图4和图5分别是间隔为0.1的权威度区间上UR和UN的数量分布图。
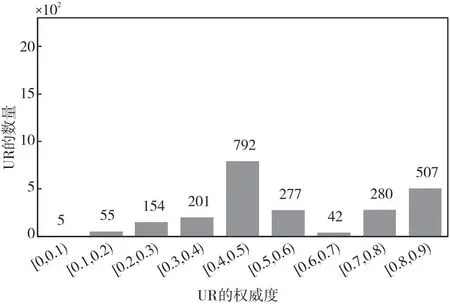
Figure 4 Distribution of UR based on authority interval
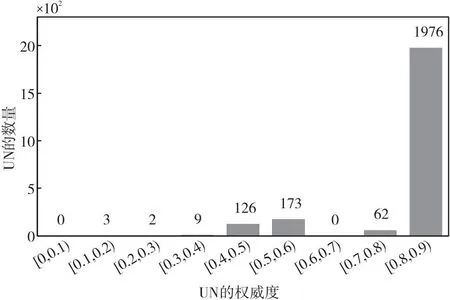
Figure 5 Distribution of UN based on authority interval
图4表明发布谣言的用户,权威度主要集中在[0.4,0.5)和[0.8,0.9)。图5表明发布非谣言的用户,权威度主要集中在[0.8,0.9)。由此可见,总体上发布谣言的用户权威度较发布非谣言的用户权威度低,这也证实了权威度是谣言检测的一个重要的评价指标。通常来说,权威度较低的用户更容易散布谣言。
6 结束语
本文提出的MRUAMF模型实现了对微博帖子的谣言识别。首先,考虑到用户权威度对谣言检测的积极作用,本文通过级联用户权威度及其相关指标,使用2层全局连接层网络提取特征,有效量化和压缩用户特征。其次,对帖子中的语境信息进行挖掘,这有助于提高谣言的识别能力。使用BERT预训练文本获得文本特征表示,并结合多模态适应门将用户特征、语境特征与文本特征融合。实验结果表明,本文提出的模型能有效地实现谣言检测。未来,将探索更有效的谣言检测模型,如利用社交网络的拓扑结构来提升谣言分类器的性能。并将在更具有差异性的数据集上进行深入探索。
