基于多视角对比学习的隐式篇章关系识别*
2024-04-23吴一珩李军辉朱慕华
吴一珩,李军辉,朱慕华
(1.苏州大学计算机科学与技术学院,江苏 苏州 215006;2.美团,北京 100000)
1 引言
篇章关系识别作为篇章分析的子任务,可以解析出篇章中的逻辑特征,因此对翻译[1]、对话[2]等下游任务都有诸多益处。根据是否存在明确的逻辑线索,篇章关系识别任务通常被分为2个子任务:显式篇章关系识别EDRR(Explicit Discourse Relationship Recognition)和隐式篇章关系识别IDRR(Implicit Discourse Relationship Recognition)。由于IDRR缺少语言线索与明确的逻辑连接,仅能依据篇章间隐藏的语义进行分类,因此IDRR被视作一个更具挑战性的任务。
从直观的角度看,IDRR作为分类任务,其本质是找到来自不同类别的篇章单元DU(Discourse Unit)特征并加以区分,因此早期的研究主要集中在特征工程的应用上[3-5]。随着神经网络的快速发展,IDRR研究的重心转移到了设计合适的神经网络模型来挖掘篇章单元之间的潜在语义联系,这也是提升IDRR识别效果最有效的手段之一。以语言嵌入模型ELMo(Embeddings from Language Models)[6],双向Transformer编码表示模型BERT(Bidirectional Encoder Representation from Transformer)[7]和鲁棒优化的BERT预训练方法模型RoBERTa(Robustly optimized BERT Pretraining approach)[8]为代表的表征预训练模型具有强大的继承上下文语义的能力,如今相当多的研究表明,在表征预训练模型后堆叠合理的神经网络模块,能提升最终的IDRR分类性能[9-12]。对于IDRR任务而言,高质量的表征意味着不同类别的表征之间更易被区分。单纯复杂化神经网络模型虽然能有效地获取更高质量的篇章单元表征,但是,这种做法不仅会显著增加计算开销,还会引入大量额外的参数[12]。显然地,增加来自不同类别的表征之间的区分度对于分类结果有积极影响。受此启发,本文将对比学习CL(Contrastive Learning)引入IDRR,以更好地区分不同类别之间的表征。
对比学习基于锚点(Anchor)、正样例和负样例这3大元素构建。其基本思想是,将语义上邻近的正样例拉近锚点,将语义上远离的负样例驱离锚点[13],因此对比学习对获取高质量语义表征大有裨益[14,15]。依据构建正负样例的方式,对比学习可以分为自监督对比学习和有监督对比学习,其中有监督对比学习强调样例类别的影响。标签锚点对比学习[16]属于有监督对比学习的一个应用,与之前的方法不同,其考虑到类别标签本身已包含的语义信息,因而将锚点设置为类别标签的词嵌入表示,该方法已经在一些文本分类任务中取得了成效[17]。
本文使用的轻量级IDRR模型源自于Liu等人[12]提出的模型,同时本文基于不同的视角,探索3种可用于IDRR的对比学习方法。具体来说,本文方法基于有监督对比学习与标签锚点对比学习设计,并由3种不同视角的对比学习组成。在训练过程中,本文在预测层之前取出篇章单元对的表征,并使用该表征计算相应的对比学习损失,将其与通过预测层输出计算的分类损失相加并进行参数更新。
本文的主要工作如下:
(1)探索了基于多视角,即样例层级、批层级和群层级3种不同的对比学习在IDRR中的应用,并探索了不同视角对比学习融合之后的效果。
(2)提出的多视角对比学习方法使用简单,在简洁的基准模型上,仅需引入极少的额外参数,并在几乎不增加计算开销的情况下,即可达到最优性能。
2 相关工作
由于EDRR已经包含了可以表达特定逻辑关系的连接词,因此EDRR任务在四分类任务上已达到超过90%的正确率[18]。目前绝大多数的DRR研究集中在IDRR任务上。
篇章单元编码器一向是IDRR模型设计的重中之重,它直接决定了分类表征质量的高低。早期的IDRR研究主要集中在特征工程的应用上,例如基于句法依存树挖掘篇章单元对之间的关系[3]和基于单词对与动词类型对篇章单元对建模[4]。近年来随着机器学习的发展,神经网络模型层出不穷,长短时序神经网络、卷积神经网络都有作为IDRR的篇章单元编码器的应用[10,19]。
除此之外,篇章单元对之间进行语义交互也有助于表征学习,以此为出发点的IDRR工作主要集中在注意力机制的改进或者引进外部知识重新建模篇章单元对。例如,使用门控注意力机制解决篇章单元对彼此之间的特征融合问题[20];使用多层注意力模型解决编码器过长时底层网络与顶层网络所获取的特征偏向不同的问题[21],两者均取得了不错的效果;使用知识图谱挖掘出篇章单元对潜藏的语义特征[22],并构建出篇章单元对在语义空间中的几何关系;将篇章单元编码器中的注意力机制分为交互注意力和自注意力的特殊设计[11]。目前中文IDRR的研究大多数都遵循英语对应的方式,例如通过引入依存树特征[23,24]和语境特征[25]来增强篇章单元表征和信息交互。简而言之,IDRR研究工作的重心集中在编码器的构造上。
对比学习已经在自然语言处理领域的表征学习中获得了广泛的应用。对比学习可以分为有监督对比学习和无监督对比学习。无监督对比学习通常使用数据增强等技巧构造正样例。而有监督对比学习则充分利用标签,其思想是相同类别的样例相较于不属于该类别的样例在语义空间中彼此之间要更加接近[13],因此有监督对比学习非常适合应用于存在类别标签的文本分类任务中[26]。标签锚点对比学习是有监督对比学习的一个应用,其将标签嵌入技术引入对比学习,认为标签嵌入表示作为锚点有利于相同类别表征的语义对齐。借助标签锚点对比学习,多个文本分类任务的性能已经获得了很大的提升[16,26]。
总之,为了获得更具区分度的篇章单元表征,绝大多数的IDRR研究重心都放在了网络结构的设计上,通过拥有更强语义捕捉能力的神经网络提取出质量更高的语义信息和逻辑特征。本文针对不同类别中篇章单元表征区分度不强的问题,直接使用对比学习对表征学习进行约束。
3 方法
本节主要介绍模型结构与多视角对比学习的细节。
3.1 模型总览
由于隐式篇章关系识别任务难度较高,因此目前普遍的做法是在预训练上下文编码模型之后接入各种复杂神经网络模块。本文的研究目标为多视角对比学习在简单模型上取得优异的效果,因此直接使用了Liu等人[12]提出的模型中的基础特征抽取层,并去掉了原模型中起关键作用的多视角匹配层。本文从以下4个组件对模型结构进行详细介绍。
3.1.1 RoBERTa
本文使用RoBERTa将篇章单元从文本转化为高维表征。为了尽可能地利用预训练模型的上下文语义建模能力,本文将篇章单元对进行拼接。如图1所示,长度为M与长度为N的2个篇章单元H0,S0与〈SEP〉,〈CLS〉连接后送入RoBERTa层,其中〈SEP〉与〈CLS〉是RoBERTa放置在句子起始与结束的特殊符号[8]。RoBERTa舍弃了NSP(Next Sentence Prediction)任务,因此其不存在段嵌入向量(Segment embedding),然而篇章单元对内部存在前后顺序,为了能体现出篇章单元对之间的逻辑性,本文额外增加了可训练的段嵌入向量。篇章单元对经过RoBERTa层如式(1)所示:

Figure 1 Baseline model of IDRR
(H1,S1)=RoBERTa([H0,〈SEP〉,S0])
(1)
其中,H1∈R(M+1)×d,S1∈R(N+1)×d为RoBERTa层的计算结果,d为段嵌入向量维度。
3.1.2 门控多头注意力层
经过RoBERTa编码之后的篇章单元嵌入表示已经充分融合了相邻篇章单元的信息,但是对于自身语义信息的挖掘还不够深入。考虑到模型既不能破坏原有表征中已包含的上下文语境信息,又要新增自身的语义信息,因此本文使用门控多头注意力层对单个篇章单元进行进一步编码。
门控多头注意力机制的结构与普通Transformer层结构的区别在于少了归一化,并用门控机制替代残差连接。这种设计使得门控注意力层具备足够强的信息挖掘能力,同时减少了对原本文本表征的影响。具体的推导过程如式(2)所示:
Q=K=V=H1
(2)
H2=GatedMultiHead(WQQ,WKK,WVV)
(3)
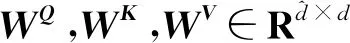
3.1.3 卷积层
本文使用的卷积层包含J种卷积操作、最大池化和高速网络(Highway Network)。卷积操作的主要目的是利用大小为1,2,…,J的卷积核捕捉篇章单元中的1-gram,2-gram,…,J-gram信息,同时使用最大池化获得固定维度的表征为最后的预测层做准备。高速网络是跳层连接(Shortcut)的一种应用,使用高速网络与门控多头注意力机制有着相似的好处,两者都起到了保护原有信息的作用。具体的推导过程如式(4)~式(6)所示:
oj=ReLU(maxpool(Convj(H2)))
(4)
o=Flatten([o1,…,oJ])
(5)
H3=Highway(o)
(6)
其中,oj∈Rdj为卷积操作Convj的计算结果,共有卷积核大小分别为1,2,…,J的J个卷积操作,且每个卷积操作的输出维度均为dj。maxpool(·)表示最大池化,Flatten(·)表示将特征拉平为一维,o∈R(J×dj)为[o1,…,oJ]经Flatten(·)处理之后的结果,H3∈R(J×dj)为卷积层的最终计算结果。获取S3的计算流程与H3完全相同,推导过程在此省略。
3.1.4 前馈神经网络层
前馈神经网络层即预测层,其本质为一个分类器。若该任务为C分类任务,则预测过程如式(7)所示:

(7)
3.2 多视角对比学习
多视角对比学习由3种不同视角的对比学习组成。3种视角基于对比学习作用对象的粒度进行划分:(1)样例层级对比学习的作用对象为单个样例及标签嵌入表示。(2)批层级对比学习的作用对象为一个批(Batch)中相同类别与其它类别的样例。(3)群层级对比学习的作用对象为来自同一类别的样例群体与来自其它类别的样例群体。其中,涉及到标签锚点对比学习的部分均使用相同的标签嵌入表示。
3.2.1 样例层级
样例层级对比学习ICL(Instance-level Con- trastive Learning)[16]如图2a所示,其中,实线表示锚点与正样例之间的关系,虚线表示锚点与负样例之间的关系,相同的颜色对应相同的类别。对于输入的样例及其标签(xi,yi),ICL将xi视作锚点,xi对应的标签嵌入表示为正样例,xi不对应的标签嵌入表示为负样例。ICL的目的是使得篇章单元表征语义上靠近对应的标签嵌入表示,而驱离不对应的标签嵌入表示。本文使用余弦相似度来衡量语义上的相似性。ICL的构建需要一个正样例和多个负样例。标签嵌入表示为随机初始化参数并进行训练。
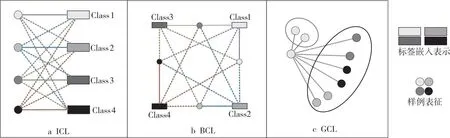
Figure 2 Three contrastive learning approaches (4-way classification)
假设当前分类任务包含C种不同的类别,则创建标签嵌入词典如式(8)所示:
L=lookup([1,2,…,C])
(8)
其中,L∈RC×(J×dj)为可训练的模型参数。其具体使用方法为,对于当前分类任务中的某一类别p,通过查询其索引从词典中L获得类别p的标签嵌入表示Lp。
ICL的损失函数定义如式(9)和式(10)所示:
μ=W([H3,S3])
(9)
(10)
其中,W∈R(J×dj)×(2×J×dj)为模型参数,其作用为融合篇章单元特征对,sim(·)为余弦相似度计算,|D|表示当前批中样例的总数量,τ是一个温度超参数,较低的τ会增加对比损失对难以区分样例的影响,并对最终结果造成影响。
通过最小化ICL损失函数,篇章单元表征与标签嵌入表示在同一语义空间中对齐,这样做的好处是模型能够为不同的类别学习到更具代表性的词嵌入表示。
3.2.2 批层级
批层级对比学习BCL(Batch-level Contrastive Learning)[16]如图2b所示。对于输入的样例及其标签(xi,yi),BCL将类别的标签嵌入表示Lp视作锚点,定义如式(11)和式(12)所示:
A(p)={xi|yi=p}
(11)
B(p)={xi|yi≠p}
(12)
其中,A(p)为正样例集合,B(p)为负样例集合。假设当前批中共有|P|个类别,BCL的损失函数定义如式(13)和式(14)所示:
P={p|1≤p≤C∧A(p)|>0}
(13)
(14)
使用BCL的好处是可以促使特定类别的篇章单元表征比来自其他类别的表征更加相似。与ICL不同的是,BCL包含有多个正样例和多个负样例。
3.2.3 群层级
群层级对比学习GCL(Group-level Contrastive Learning)如图2c所示。GCL将属于类别p篇章单元表征视作正样例,不属于类别p的表征视作负样例。GCL将非当前样例的所有正样例视作一个正样例群(Positive Group),将所有负样例视作一个负样例群(Negative Group),为方便计算,使用当前样例与群中所有样例表征相似度的均值作为锚点与群的相似度。假设当前批中共计有|D|个样例,GCL的损失函数定义如式(15)所示:
GCL=
(15)
其中,avg(·)表示均值操作。GCL的目的是使得属于同一类别的篇章单元表征在语义空间中更加相似,同时远离非同一类别的表征。
3.2.4 多视角对比学习融合
(16)
L=CE+λ1*ICL+λ2*BCL+λ3*GCL
(17)
其中,λ1、λ2和λ3为权重系数,用于控制各种对比学习损失对最终损失的影响程度。
4 实验与结果分析
4.1 实验数据集与评测标准
数据集:发布于2008年的宾夕法尼亚大学篇章树库PDTB 2.0(the Penn Discourse TreeBank 2.0)[27]为篇章关系识别任务中最大的语料库,它为篇章关系定义了一个多层的语义关系,并完善了标注体系。PDTB 2.0根据连接词中心法对近2 500篇来自华尔街日报WSJ(Wall Street Journal)的新闻报道进行标注,其将数据集划分为00~24这25个章节,共标注了40 600个篇章关系实例,其中隐式篇章关系实例16 224个。为了与前人的工作保持一致,本文使用的数据集为PDTB 2.0[27],并汇报四分类(PDTB-4)任务,十一分类任务(PDTB-11)和Temporal(Tem.),Contingency(Con.),Comparison(Com.)与Expansion(Exp.)4个类别的二分类任务结果。十一分类数据集实际由四分类数据集经更细粒度地划分得到;二分类任务数据集由四分类任务数据集经一对多(One-versus-all)处理之后得到。本文遵循最流行的数据集切分方式PDTB-Ji[28],将2~20章节作为训练集,0、1章节作为开发集,21、22章节作为测试集。四分类数据集详细统计数据如表1所示;十一分类数据集详细统计数据如表2所示。
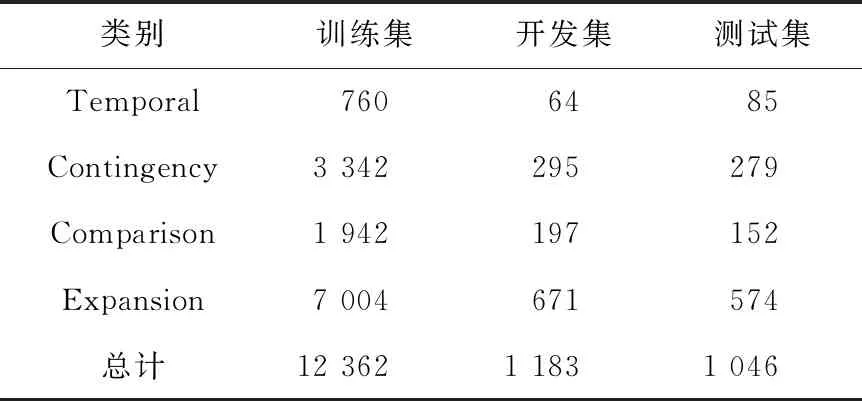
Table 1 Dataset of 4-way classification

Table 2 Dataset of 11-way classification
评测标准:与目前绝大多数IDRR工作汇报的评测标准保持一致。本文使用宏平均F1分数(Macro-averagedF1)和正确率ACC作为四分类任务的指标;正确率ACC作为十一分类任务的评测指标,F1分数作为二分类任务的评测指标。
4.2 超参数设置
本文使用的模型与算法均由PyTorch实现。RoBERTa层使用的是RoBERTa-base(https://huggingface.co/roberta-base)。使用下限为0.1,上限为1,步数为0.1的网格搜索确定λ1,λ2和λ3。表3给出了本文模型的维度设置。本文使用AdamW作为优化器,学习率为0.001,批大小batch-size大小为24,模型最大输入长度为512,使用RoBERTa开源的词表对篇章单元文本进行分词。所有的实验都在一个32 GB NVIDIA®V100 Tesla Core GPU上完成。
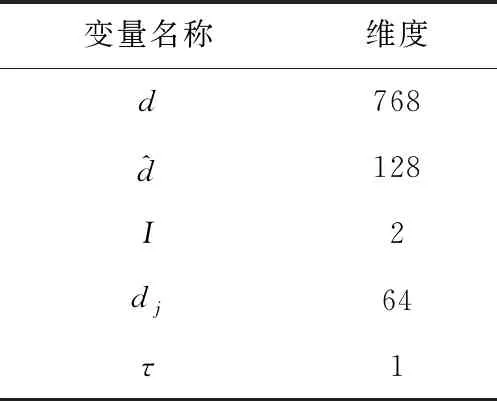
Table 3 Dimensions of the proposed model
4.3 实验结果
本文选择以下6种方法进行实验对比:
(1)Dai等人[19]方法:该方法对整个篇章进行建模并编码,并对篇章中的所有篇章单元对同时进行分类。
(2)Bai等人[10]方法:该方法对篇章单元进行包括子词粒度、词粒度和句子粒度的混合编码,并且首次引入连接词分类任务和IDRR进行联合学习。
(3)Zhang等人[29]方法:该方法基于图注意力模型对整个篇章进行上下文建模,并设计了篇章单元间与篇章单元内部2种粒度的注意力交互机制。
(4)Varia等人[30]方法:该方法提出了一种针对篇章单元对中词对编码的卷积神经网络,并基于门控机制融合篇章单元对的表征,联合EDRR和IDRR进行学习。
(5)Wu等人[31]方法:该方法利用层级篇章关系的特性,结合条件随机场与卷积神经网络对篇章单元建模。它也是第一个将BERT作为词嵌入层的IDRR模型。
(6)Jiang等人[32]方法:该方法联合了文本生成任务。利用预训练模型的先验知识,该方法输出包含篇章类别具体描述的文本序列和各个篇章类别的概率。
(7)Liu等人[12]方法:该方法包含了多个对篇章分析有帮助的匹配组件与信息融合组件,并探索了预训练模型的使用方法。
本文标明了各比较方法使用的预训练模型。本文的基准方法(Baseline)包括RoBERTa、门控多头注意力层、卷积层和前馈神经网络层这4层结构。为了表格简洁易读,B,I和G分别表示BCL,ICL和GCL。
由于预训练词嵌入模型和预训练表征模型对文本表征的质量有着直接的影响,因此本文在表4与表5中标明了比较方法所使用的预训练模型。本文从2个角度对实验结果进行分析。
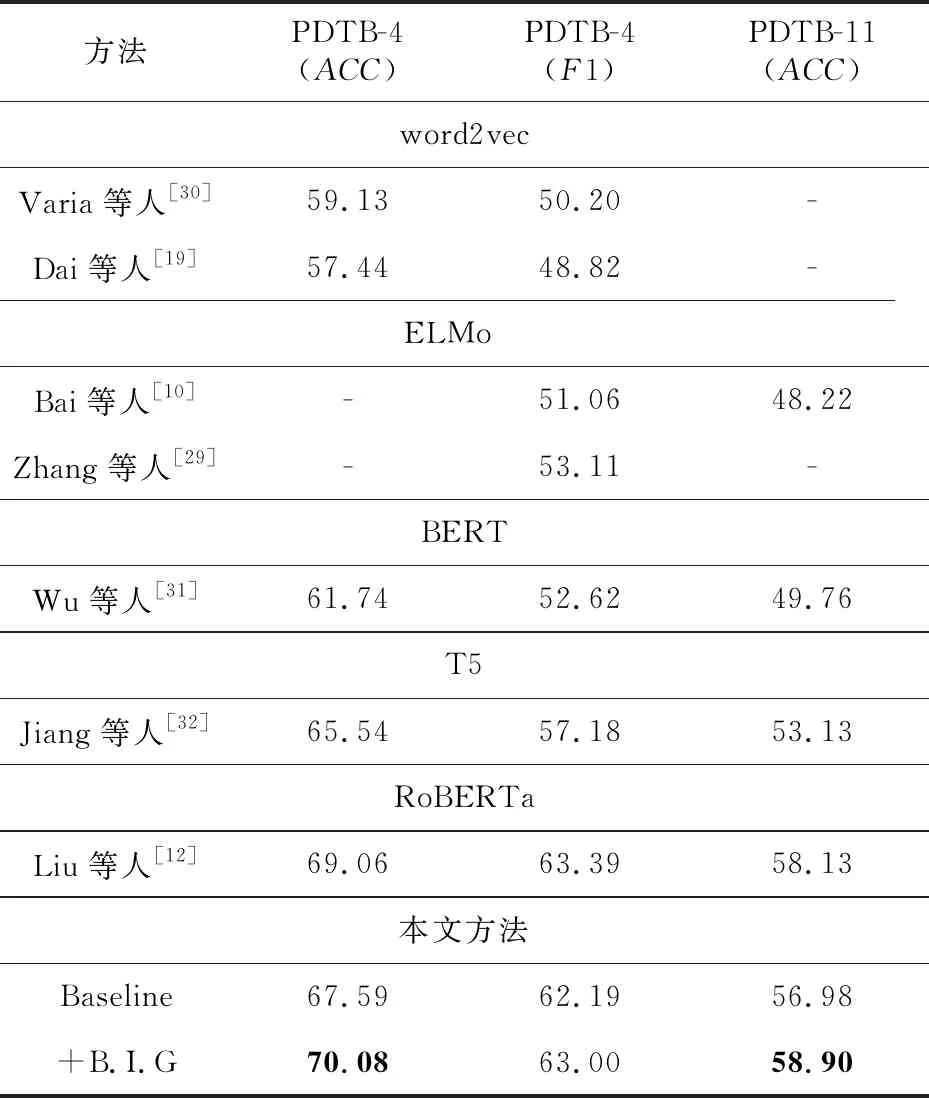
Table 4 Results of PDTB 2.0 multi-classification task

Table 5 Comparison of FLOPs and parameters
(1)多分类任务。
表4展示了多分类任务实验结果。
首先,加入了多视角对比学习方法(+B.I.G)与基准方法(Baseline)相比,四分类任务正确率提升了2.49%,十一分类正确率提升了1.92%。可以认为多视角对比学习的加入使得本文方法的性能取得了实质性的提升。
其次本文方法与使用word2vec或者ELMo的方法相比,在正确率与宏平均F1分数上基本都有超过10%的提升;与使用T5与BERT方法相比,也有相当的差距。Liu等人[12]的方法是目前最先进的模型之一,为达到最优性能,其分别从整体、最大池化、注意力和最大注意力4个角度对篇章单元对进行编码,表5所示为本文方法与其FLOPs、模型参数量的比较结果。由于Baseline仅仅是Liu等人[12]方法的基础特征抽取层,因此性能相较更低。本文方法(+B.I.G)不仅在参数量和计算速度上与Baseline几乎没有差别,并且在参数量只有Liu等人[12]方法约80%的情况下,就能在四分类与十一分类任务中超越其约1%正确率。
(2)二分类任务。
表6给出了二分类任务中每个类别的实验结果。

Table 6 Results of PDTB 2.0 binary classification task
首先,加入了多视角对比学习方法(+B.I.G)与基准Baseline相比,在每个类别中几乎都有提升。其中针对Temporal和Contingency的二分类任务改善效果最明显,分别提升了1.28%和2.21%的F1分数。由表1可知,Tem.与Con. 2个类别在数据集中占比较低,这可以说明本文提出的对比学习方法对数据规模不敏感。
其次,本文方法(+B.I.G)与使用word2vec或者ELMo的方法相比,在Tem.与Com. 2个类别中有超过10%F1分数的进步;与使用T5的方法相比,在4个类别上的F1分数上都占据绝对优势;与使用RoBERTa的方法相比,在3个小数量类别(Tem.,Com.,Con.)上都有明显提升。特别地,基准方法Baseline在Con.类别上已经超越了Liu等人[12]方法2.15%的F1分数。
5 消融实验
本文从2个角度对实验结果进行分析。
(1)多分类任务。
表7给出了多分类任务中消融实验的结果。
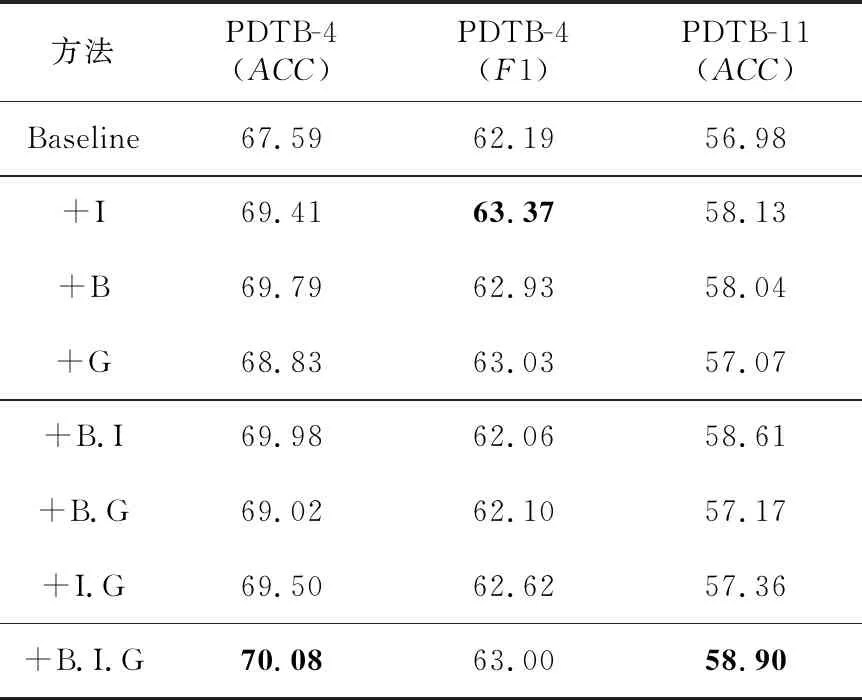
Table 7 Ablation results of PDTB 2.0 multi-classification task
首先,对仅使用单个对比损失函数进行分析。3个对比损失函数都对分类结果有着积极的影响,其中,ICL和BCL对结果的影响最大,ICL提升了四分类任务1.18%的F1分数,BCL提升了四分类任务2.2%的正确率。在十一分类任务上,ICL与BCL的提升不相上下,约为1%。ICL与BCL作为标签锚点对比学习,效果比与GCL组合更优,本文推测是得益于标签嵌入表示。标签嵌入表示本身具有语义,因此能在语义空间中更有效地对齐对应类别的表征,而GCL没有标签的指引,受样例自身的影响更大。
其次,对同时使用2个对比损失函数进行分析。在四分类与十一分类任务中表现最好的均为BCL联合ICL。两者联合的优势尤其体现在正确率上,四分类正确率几乎达到了70%,十一分类正确率相较基准方法提升了1.63%。结合表4中比较方法的结果,可以认为此时方法已经达到了最先进的性能。然而,GCL与BCL结合之后的实验结果略逊一筹。本文推测是因为GCL与BCL设计的出发点均为聚类相同类别的篇章表征,造成两者使用时出现冗余,导致最终分类效果不佳。
(2)二分类任务。
表8给出了二分类任务中消融实验的结果。
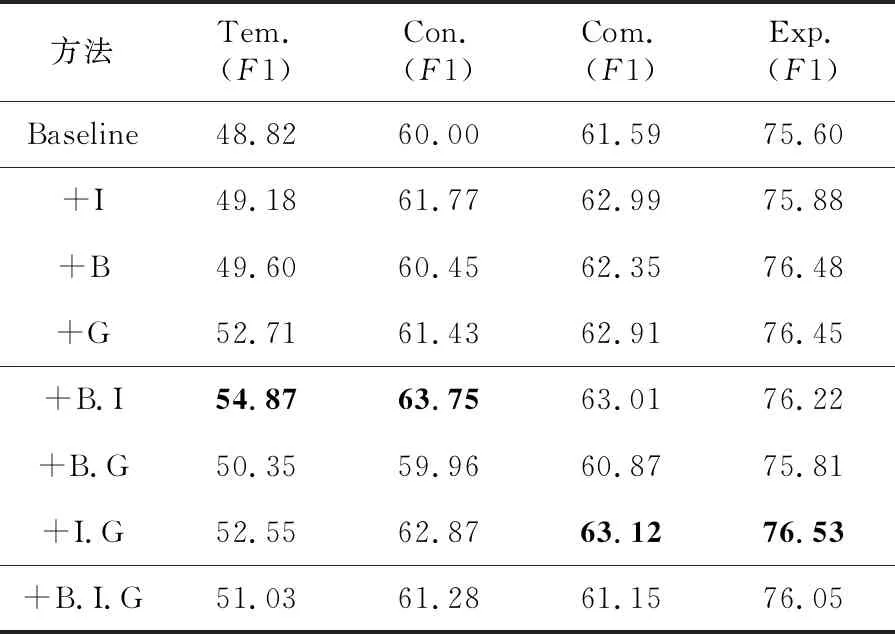
Table 8 Ablation results of PDTB 2.0 binary classification task
首先,二分类任务受到BCL与GCL冗余的影响更明显,使用单个对比损失函数的结果要优于同时使用3个对比损失函数,这与多分类任务的结果完全不同。
其次,在二分类任务中,Tem.与Con.分类结果的最高值出现在BCL与ICL联合使用,Com.与Exp.分类结果的最高值出现在ICL与GCL联合使用;结合表4中比较方法的结果,可以看出在Tem.,Con.和Com. 3个类别上的最高值,要远高于目前的最先进方法,这也表明了本文方法受训练样例数量的影响很小,也暗示了方法参数的增加不一定对二分类任务有好处。与前文中的推测相符合,GCL与BCL联合使用效果不佳,主要体现在Con.与Com. 2个类别的F1分数低于基准方法。
6 结束语
本文利用对比学习在表征学习中的优势,提出了一个基于多视角对比学习的方法。该方法可以在训练过程中对表征进行约束,使相同类别的篇章单元表征在语义空间中更加接近,不同类别的表征更加疏远。本文的方法计算简单,无需增加额外参数。实验结果表明本文的方法在PDTB 2.0上达到了最先进的性能。
