基于异构图神经网络的半监督网站主题分类*
2024-04-23王谢中景永俊王叔洋
王谢中,陈 旭,景永俊,王叔洋
(1.北方民族大学计算机科学与工程学院,宁夏 银川 750000;2.北方民族大学电气信息工程学院,宁夏 银川 750000)
1 引言
近年来,随着互联网的迅速发展,全球网站数量已超过11亿,这增加了准确索引和搜索的复杂性。尽管有搜索引擎如百度和谷歌,但在海量网站中查找特定主题的网站仍具有挑战性。例如,要获取某国所有教育主题网站仍然不容易。传统搜索结果可能包含许多不相关的网站,因此,准确分类网站主题成为解决这一难题的关键途径。
为了准确分类网站主题,研究人员提出了许多基于机器学习和深度学习的方法。这些方法可以分为基于URL的网站主题分类和基于网页内容的网站主题分类[1]。基于URL的网站主题分类方法[2,3]主要通过提取URL的特征进行分类。通过分析URL中的字符序列,可以捕捉到网站之间的相似性和差异性,从而完成分类任务。而基于网页内容的网站主题分类方法[4-8],则需要理解网站的文本内容,并使用更多的参数增强模型的非线性能力。这种方法本质上可以看作是文本分类,通常利用自然语言处理技术,对网站文本进行特征提取和语义分析,以区分不同主题或领域的网站。
虽然这些方法都取得了一定的效果,但是也存在一些问题。例如,基于URL的网站主题分类方法虽然具有快速训练和对计算能力要求低的优势,但是当网站的主题信息未直接反映在URL中或者某些网站进行伪装时,这些分类方法的准确性会受到显著影响。此外,基于网页内容的网站主题分类方法在处理网页上的短文本内容时,会受到数据稀疏性和有限信息利用的限制,并且难以捕捉短文本中的多层次语义关系(如同义词、上下位关系等)。这些问题限制了网站主题分类的准确性。
为了解决上述问题,本文提出一种基于异构图神经网络的半监督网站主题分类方法HGNN-SWT(Semi-supervised Website Theme classification based on Heterogeneous Graph Neural Network)。该方法将图神经网络与网站主题分类相结合,构建包含网站文本和词语节点的异构图,利用网站文本的特征解决仅使用URL作为网站特征的缺陷。同时,通过建模网站文本和词语之间的直接和间接关系,HGNN-SWT能够解决网站文本内容数据的稀疏性限制,并能够理解网站文本中的多层次语义关系。此外,HGNN-SWT中融入自训练模块,目的是将计算得到的高置信度词语添加到训练数据集中作为伪标签数据,这些词语可以被视为网站文本中的关键词语。这种伪标签数据的引入有助于标签数据信息的传播。因此,HGNN-SWT能够充分利用关键词语来提高网站主题分类的性能。该研究对于准确实现网站主题分类任务具有重要意义。本文的主要工作如下:
(1)从站长之家采集网站数据,并构建名为Chinaz Website的网站数据集,其中包含16个不同的网站主题。为了处理网站中文本数据的稀疏性,并捕捉文本数据中的多层次语义关系,采用异构图对Chinaz Website数据集进行关系建模。
(2)提出一种基于异构图神经网络的半监督网站主题分类方法(HGNN-SWT)。在邻居节点采样阶段,提出基于随机游走的邻居节点采样方法来逐步扩展邻居节点,从而考虑节点的局部特征和全局图结构。在邻居节点融合阶段,提出一种特征融合方法来考虑邻居节点的综合特征。
(3)在Chinaz Website数据集上,将HGNN-SWT与基于机器学习、深度学习和图神经网络的方法进行对比实验,以检验HGNN-SWT在网站主题分类的准确性。
2 相关工作
本节将分别介绍网站主题分类和基于图神经网络的文本分类研究成果。
2.1 网站主题分类
在现有的网站主题分类研究中,研究人员主要关注没有内容的分类方法。例如,Shawon等人[2]使用N-Gram和多项式朴素贝叶斯分类器对URL进行分类。Faroughi等人[3]提出一种基于同构图的半监督学习方法,该方法以域名作为节点,从域名中提取N-Gram特征,从而进行分类。然而,当网站的主题信息未直接反映在URL中或者当某些网站进行伪装时,该分类方法的准确性会受到显著影响。在这种情况下,研究人员考虑采用网站的其他特征信息(如网页内容)进行分类。López-Snchez等人[4]提出一种基于网站数据的分类方法,该方法采用卷积神经网络CNN(Convolutional Neural Network)模型。Buber等人[5]提出一种基于元标签信息的网站主题分类方法,该方法采用循环神经网络RNN(Recurrent Neural Network)模型。除了使用单一特征的网站主题分类方法外,研究人员还提出多种特征的网站主题分类方法。例如,Suleymanzade等人[6]提出一种利用网页文本和图像数据的分类器方法,通过考虑整个网页内容来获取更加丰富的网站表示。然而,该方法存在模型复杂度高和训练成本高等问题。Dalvi等人[7]首先将网站主题分为预定义的几个类型,然后使用多种机器学习分类模型进行网站主题分类,包括多项式朴素贝叶斯、随机森林和支持向量机等。最终,他们选择了准确率最高的支持向量机作为网站主题分类的方法。Siddiqha等人[8]提出一种基于预定义领域(体育、政治和教育)的层次分类和层次索引模型,并且在包含这3个类别的数据集上进行实验,取得了较好的效果。
2.2 基于图神经网络的文本分类
基于图神经网络GNN(Graph Neural Network)的文本分类方法将文本数据视为图结构,其中词语和文本作为节点,它们之间的关系表示为边。Defferrard等人[9]首次在文本分类任务中采用图卷积网络GCN(Graph Convolutional Network),并在性能上超过了传统的CNN模型。Yao等人[10]也采用GCN对文本进行分类。他们在包含了词语节点和文本节点的文本图中引入带权边。该方法在文本分类任务中取得了较好的分类结果。这些方法采用整个语料库构建单个图,并使用具有固定权重的边,这在很大程度上限制了边的表达能力。为了解决这个问题,Huang等人[11]提出一种新的基于图神经网络的文本分类方法,该方法为每个输入文本生成一个文本级别的图,并且共享全局参数。然而,现有的深度学习方法和基于GNN的多标签文本分类方法[12,13]在捕捉标签之间的关联性方面存在不足。于是Pal等人[14]提出一种基于注意力的图神经网络方法,旨在充分捕捉节点之间的关联性,通过自动学习特征矩阵中标签之间的关系实现更准确的多标签文本分类。Nikolentzos等人[15]将文本表示为词共现网络,并提出一种用于文本理解的消息传递注意力网络方法,以捕获文本的层次结构。为了更深入地研究词语对文本分类结果的影响,Liu等人[16]采用了图注意力机制,将每个文本建模为一个词语-词语图进行分类。此外,针对文本分类任务中潜在的隐私泄露问题,Igamberdiev等人[17]基于差分隐私梯度训练方法,提出一种基于GCN的隐私保护文本分类模型。最近,Zhao等人[18]引入一种多头池化GCN模型,用于短文本分类,通过保留文本图的一阶和二阶相似性来保持结构信息。Cui等人[19]提出一种基于GCN的半监督短文本分类方法,该方法加入自训练模块,最终取得了不错的效果。此外,为了探索短文本之间的内部和外部相似性,Cao等人[20]提出一种自监督的短文本分类模型,用于学习短文本的嵌入表示。
3 HGNN-SWT方法
HGNN-SWT方法的整体结构如图1所示。HGNN-SWT方法主要包括6个步骤:构建网站异构图、基于随机游走的邻居节点采样、特征融合、特征转换、网站主题分类和自训练。

Figure 1 Overall structure of HGNN-SW method

Figure 2 Word-website text graph using HGNN-SWT
3.1 构建网站异构图
本文通过异构图对Chinaz Website数据集中的实体关系进行建模。该异构图被定义为G_Web={V,E,A,R},其中,V表示G_Web中所有节点的集合,E表示G_Web中所有边的集合,A表示G_Web中所有节点类型的集合(包括网站文本和词语),R表示G_Web中所有边类型的集合(包括网站文本节点和词语节点之间的关系,以及词语节点之间的关系)。每个节点v∈V与一个节点类型的映射函数ψ:V→A相关联,每条边e∈E与一个边类型的映射函数φ:E→R相关联。网站异构图中包含词语节点和网站文本节点。首先,本文使用Jieba分词对网站文本进行分词处理,然后去除停用词。然后,利用点互信息PMI(Pointwise Mutual Information)计算词语节点之间的权重,若PMI值大于0,则表示它们之间存在一条连接边。最后,通过将词频-逆文档频率TF-IDF(Term Frequency-Inverse Document Frequency)和词语置信度相乘计算网站文本节点和词语节点之间的权重,并建立它们之间的连接边。如图2所示。
在构建网站异构图过程中,由于PMI可以反映词语在上下文中的相对频率,衡量词语之间的共现关系,因此,为了更好地捕捉2个词语节点之间的关系,本文使用PMI计算2个词语节点之间的边权重,这样可以使得相关的词语节点连接得更紧密,不相关的词语节点之间的连接更稀疏。PMI的计算公式如式(1)~式(3)所示:
(1)
(2)
(3)
其中,PMI(wi,wj)表示词语wi和词语wj之间的点互信息值;p(wi)表示词语wi在所有滑动窗口中出现的概率;p(wi,wj)表示词语wi和wj同时在所有滑动窗口中出现的概率;W(wi)表示词语wi在所有滑动窗口中出现的次数;W(wi,wj)表示词语wi和wj同时在所有滑动窗口中出现的次数;|W|表示滑动窗口的总数。PMI(wi,wj)值越大,表示2个词语之间的语义相关性越强。
为了更好地捕捉网站文本节点和词语节点之间的关系,本文通过将TF-IDF和词语置信度相乘计算网站文本节点和词语节点之间的权重。在TF-IDF中,词频TF(Term Frequency)反映词语在文档中的重要程度,而逆文档频率IDF(Inverse Document Frequency)反映词语在整个文档集合中的独特性。TF-IDF的计算公式如式(4)~式(6)所示:
(4)
(5)
TF-IDFwi,tj=TFwi,tj*IDFwi
(6)
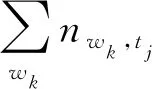
然而,在某些情况下,有些词语可能具有不确定性,例如同义词和多义词等。如果简单地使用TF-IDF计算边权重,可能会给这些不确定的词语分配过高的权重,从而影响HGNN-SWT方法的分类结果。因此,通过使用词语置信度调整词语的权重,可以确保在计算边权重时更准确地反映词语的重要性。词语置信度通过基于有标签的网站文本进行计算,其中包括训练网站文本和带有预测标签的测试网站文本。这种计算边权重的方法可以更好地反映网站文本节点和词语节点之间的关系,从而提高HGNN-SWT方法预测的准确性。
在初始阶段,只有训练的网站文本数据会被用来计算词语的置信度。在进行第1轮自训练后,带有预测标签的测试网站文本数据会被加入到训练网站文本数据中,一起参与词语置信度的计算。词语置信度的计算公式如式(7)所示:

(7)
其中,Conwi表示词语wi的置信度;Cc表示包含词语wi的标签网站文本中属于第c类的网站文本的数量;N表示类别总数;Max表示求最大值的函数。简单来说,当词语出现在有标签的网站文本中时,它的置信度取决于包含该词语的标签网站文本中最多的网站文本类别数和该词语出现在所有标签的网站文本中的频率。而当词语没有出现在有标签的网站文本中时,由于缺乏相关信息,只能按照类别数来计算其置信度。虽然这样可能会导致一定误差,但是这种计算方式也能够在一定程度上反映出词语的重要性。因此,该词语的置信度被设定为一个与类别数相关的常数。邻接矩阵A可以定义为式(8):
(8)
其中,m和n表示图中的节点,可以是词语或网站文本。如果m和n都是词语,并且它们之间的PMI(m,n)值大于0,则它们之间就有一条边相连,并且Am,n等于它们之间的PMI(m,n)值。如果m是词语,n是网站文本,则它们之间也有一条边相连,并且Am,n等于该词语m在网站文本n中的TF-IDFm,n值乘以词语m的置信度Cm。其他情况下,Am,n都被设为0,表示没有边相连。
3.2 基于随机游走的邻居节点采样
在构建完网站异构图之后,为了更深入地探索图的结构和节点之间的关系,需要一种有效的方法同时考虑节点的局部特征和全局的图结构信息。因此,本文提出一种基于随机游走的邻居节点采样方法。该方法不仅可以获取节点的一阶邻居信息,还能进一步扩展到更高阶的邻居,从而获得更全面的邻居节点信息。具体而言,首先,以当前节点为起点进行一定步数的随机游走,在每一步的游走中,从当前节点的邻居节点中随机选择g个节点作为采样结果。然后,以采样结果中的每个节点作为新的起点,按照相同的过程继续进行采样,直至达到指定的邻居阶数L为止。
给定一个图G_Web={V,E,A,R}。假设从节点v∈V开始采样,Bl表示存放l层采样后的邻居节点的集合,Wl表示存放l层采样后的邻居节点与目标节点之间的边的权重矩阵。首先,创建一个集合B0(v)=v。然后以节点v为中心采样g个v的一阶邻居节点,并将这些节点添加到集合B1(v)中,同时将这些采样得到的邻居节点B1(v)与v的边权重添加到W1中。接下来,继续按照上述步骤进行采样,从B1(v)中的每个节点u1∈B1(v)采样g个一阶邻居节点,并将这些节点添加到集合B2(v)中,同时将这些采样得到的邻居节点B2(v)与u1∈B1(v)的边权重添加到W2中。最后,重复进行上述采样过程,直到采样到指定的邻居阶数L为止。在每一步中,采样得到的一阶邻居节点及其与当前节点的边权重被添加到相应的集合和权重矩阵中。所有节点进行等概率采样,采样过程如式(9)~式(12)所示:
(9)
Bl(ul-1)~Categorical(g,{pul-1(t)}t∈N(ul-1))
(10)
Bl(v)=∪ul-1∈Bl-1(v)Bl(ul-1)
(11)
Wl[ul-1][ul]=W(ul-1,ul)
(12)
其中,pul-1(t)表示节点ul-1的一阶邻居节点t被采样到的概率,N(ul-1)表示ul-1的所有一阶邻居节点集合,|N(ul-1)|表示ul-1的所有一阶邻居节点数量。Categorical(·)是一个概率分布函数,用于从多个离散的选项中选择一个选项。具体来说,式(10)表示从N(ul-1)中以{pul-1(t)}t∈N(ul-1)为各自出现概率,随机选取g个一阶邻居节点,得到Bl(ul-1)。ul-1是上一层Bl-1中采样的邻居节点。式(11)表示节点v的第l层的邻居节点集合Bl(v)是由它的所有第l-1层邻居节点的第l层邻居节点Bl(ul-1)的并集组成的。Wl[ul-1][ul]表示第l-1层采样的节点ul-1与其一阶邻居节点ul∈Bl(ul-1)之间的边的权重。
3.3 特征融合
邻居节点的采样过程旨在获取每个节点周围的信息,而邻居节点的融合则是为了将这些邻居节点的特征进行整合,从而形成一个新的、更全面的节点表示。通过融合操作,节点的表示能力得到提升并能使HGNN-SWT方法充分捕捉节点在其局部邻域中的上下文信息。通过采样和融合的过程,模型能在多层邻域中获取和整合信息,进一步提升对节点在全局图结构中的上下文关系和特征交互的理解和表达能力。
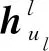
∀ul∈Bl(ul-1)})
(13)
(14)
(15)
(16)
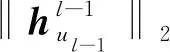
为了有效整合邻居节点的特征信息,本文采用平均池化作为AGGREGATE(·)函数的融合方式。在HGNN-SWT方法中,平均池化起着核心的作用,它能够将多个邻居节点的特征进行融合,生成新的融合特征表示。这种特征表示能够更好地捕捉节点在图结构中的上下文关系和特征交互,从而有效捕捉邻居节点特征的总体趋势和分布情况。具体过程如式(17)所示:
(17)
其中,Wmean和bmean表示平均池化操作的参数。
3.4 特征转换
对邻居节点进行特征融合操作后,会得到一个包含丰富邻居信息的网站文本特征表示zv。为了更有效地提取和转化这些特征,本文采用全连接层进行特征转换。它通过学习一系列参数化的非线性映射函数,将输入特征转换到一个新的高维特征空间。这种转换可以捕获更复杂的特征交互和抽象关系,从而为后续的网站主题分类任务提供具有较高鲁棒性和较强判别能力的特征表示。特征转换过程如式(18)所示:
fv=RELU(Wf·zv+b)
(18)
其中,zv表示融合后的节点特征;Wf表示权重矩阵;b表示偏置向量,RELU(·)表示是非线性激活函数。通过式(18),zv被映射到一个新的特征空间,从而得到转换后的特征表示fv。
3.5 网站主题分类
由于每个网站文本是从对应的网站中爬取的,因此对网站文本进行分类即相当于对网站主题进行分类。Softmax函数能够将网站文本节点的特征表示映射为每个类别的概率,使得每个类别的概率值介于0和1之间,并且所有类别的概率之和为1。因此,为了对网站文本节点进行准确分类,本文使用Softmax函数对转换后的特征表示fv进行处理,如式(19)所示。通过这种方式,可以获得v属于每个类别的概率分布,并将概率最大的类别作为v的分类结果。

3.6 自训练
为了提高HGNN-SWT方法的性能和鲁棒性,本文引入自训练模块。自训练作为一种半监督学习方法,能够利用未标记的数据来提升性能[21,22]。然而,传统的自训练方法存在一些不确定性,可能引入错误的伪标签数据,从而增加噪声并影响HGNN-SWT方法训练的结果。
为了解决这个问题,本文采用一种新的自训练方法[19]来处理测试集网站文本。在该方法中,仅将置信度大于某个指定阈值的词语作为伪标签数据添加到训练集中(见图1)。这样可以避免引入错误的伪标签数据,减少训练过程中的噪声。这些被添加的词语是网站文本中的关键词,它们有助于扩散标签数据的信息,并提高网站文本分类的性能。这种自训练方法能够在保持标签数据准确性的同时,引入更多有价值的信息,从而增强HGNN-SWT方法的学习能力和表达能力。
此外,PMI和TF-IDF的计算只需要进行1次,这有助于提高计算效率。在每轮的自训练中,需要计算词语的置信度,并将置信度较大的词语添加到训练集中。然后,利用这些新增的数据进行训练,逐步提升HGNN-SWT方法的网站主题分类能力。算法1详细描述了HGNN-SWT的训练过程。其中,当自训练轮数R=1时,HGNN-SWT开始自训练。

算法1 HGNN-SWT训练过程输入:网站文本语料库;词语置信度阈值M;模型自训练轮数R;模型训练轮数E;每阶采样的邻居节点数量g;采样深度L。输出:分类标签、节点嵌入和关键词语。步骤1 根据式(1)计算PMI;步骤2 根据式(6)计算TF-IDF;步骤3 For 模型自训练轮数 from 0 to R do步骤4 根据式(7)计算词语置信度;步骤5 将置信度大于M的词语添加到训练集中;步骤6 根据式(8)构建网站异构图;步骤7 For 模型训练轮数from 1 to E do步骤8 根据式(9)~式(12)对图中的每个节点进行L阶的邻居节点采样,并且每阶采样的邻居节点数为g;步骤9 根据式(13)~式(17)融合采样后的邻居节点;步骤10 根据式(18)将融合后的节点通过一个全连接层进行转换;步骤11 根据式(19)对网站文本节点进行分类;步骤12 End for步骤13 更新分类结果;步骤14 End for步骤15 输出分类结果,包括标签、节点嵌入和关键词语。
4 实验
本节将分别介绍Chinaz Website数据集的采集过程以及特征选择、对比实验、消融实验和参数设置比较。
4.1 Chinaz Website数据集
Chinaz Website数据集源自站长之家网站(https://top.chinaz.com/hangye)。站长之家是一个汇集大量网站信息和统计数据的综合性平台,涵盖了多种主题和领域。本文选择其作为数据来源,是因为它提供了丰富的网站信息。此外,此选择也是受到杨晨[23]和魏佳代[24]在他们的研究中同样采用站长之家数据的影响。
网站数据采集流程如下:首先,采用Scrapy工具访问站长之家网站,随后通过Requests库发送GET请求以获取页面内容。然后,使用XPath(XML Path language)选择器从页面中提取所有网站链接,对每个链接进行访问,并利用BeautifulSoup库爬取网站的名称、网址和主题。在此过程中,每个网站的网址都会被访问,并从元标签中的description属性提取网站内容描述。所获取的所有数据通过CSV(Comma Separated Values)文本库进行存储,这一流程持续进行,直到所有页面都被爬取完毕。通过这个流程,获得了涵盖不同主题和领域的Chinaz Website数据集,为本文的实验提供了丰富的样本。这个数据集能够较好地模拟真实世界的网站分类场景,并验证HGNN-SWT方法在广泛网站样本上的有效性和鲁棒性。从站长之家爬取的最终数据格式如图3所示。

Figure 3 Final data format crawled from Chinaz Website
根据预先设定的主题,筛选出与研究相关的网站数据,并将其保留,同时排除与研究主题无关的网站数据。本文共筛选了16个网站主题,分别是漫画、购物、交通旅游、教育文化、求职招聘、社交聊天、生活服务、视频电影、搜索引擎、体育、小说、新闻媒体、医疗健康、音乐、游戏和政府机构。这16个网站主题共涵盖了26 680条网站数据。图4展示了各主题网站数量的分布情况。

Figure 4 Distribution of the number of websites by topic
为了满足研究需求,本文从筛选后的数据中提取和选择相关特征以捕捉关键的网站主题信息,以备后续的分类任务使用。本文将网站文本内容作为网站文本节点的特征。首先,对网站文本内容进行分词处理,然后移除停用词和无关的字符,以保留有意义的词语。接着,利用预训练的FastText词向量来表示每个词语。针对整个网站文本内容,将所有词语的词向量进行求和操作,得到网站文本节点的初始特征。通过求和操作,可以从稀疏的网站文本内容中捕捉更多的信息,因为每个词语都可能包含重要的语义信息。对于词语节点的特征,直接采用其对应的FastText词向量作为初始特征。
4.2 对比方法
为了评估HGNN-SWT方法的效果,本文选取一系列在网站主题分类和短文本分类领域已经取得显著成果并被广泛引用的方法进行比较。这些对比方法涵盖了基于机器学习、深度学习以及图神经网络的方法。这些方法被选择作为对比对象,是因为它们在过去的研究中已经证明了自己的性能,并且在设计思路或方法框架上与HGNN-SWT方法有一定的相似性或可对比性。因此,通过这样的比较,本文能更准确地评估HGNN-SWT方法的性能和创新之处。对比方法如下所示:
(1)支持向量机SVM(Support Vector Machine)[25]:针对网站主题分类任务,本文采用2种SVM模型进行分类。第1种模型SVM_url利用从域名中提取的N-Gram特征进行分类。第2种模型SVM_wdt使用网站文本内容作为特征进行分类。
(2)朴素贝叶斯NB(Naive Bayes)[26]:针对网站主题分类任务,本文采用2种NB模型进行分类。第1种模型NB_url利用从域名中提取的N-Gram特征进行分类。第2种模型NB_wdt使用网站文本内容作为特征进行分类。
(3)TextCNN[4]:TextCNN使用卷积神经网络来提取网站文本中的语义信息,从而对网站主题进行分类。
(4)LSTM(Long Short-Term Memory)[6]:由于Chinaz Website的数据集中没有图像数据,因此无法使用CNN模块来提取图像特征,只能使用LSTM模块来提取网站文本中的上下文信息,并进行网站主题的分类。
(5)AttBiLSTM[27]:AttBiLSTM在BiLSTM (Bidirectional Long Short-Term Memory)的基础上增加了注意力机制,通过注意力机制识别出网站文本中的关键信息,从而提高了对网站主题的分类效果。
(6)Text-GCN[11]:Text-GCN首先将Chinaz Website数据集构造成图,然后用GCN从图中提取语义信息,并最终对网站主题进行分类。
(7)MPAD(Message Passing Attention network for Document understanding)[15]:MPAD首先将网站文本表示为词共现网络,然后将消息传递框架应用于网站主题分类。
(8)ST-Text-GCN(Self-Training Text method based on GCN)[19]:ST-Text-GCN首先将Chinaz Website数据集构建为一个图结构,然后利用GCN从图中提取语义信息,最终通过自训练模块逐步提升ST-Text-GCN的分类能力。
为了进行客观比较,本文将上述所有方法的原始设置和参数保持不变,使用相同的训练集、验证集和测试集进行分割。选取18 676(70%)个节点作为训练集,5 336(20%)个节点作为验证集,以及2 668(10%)个节点作为测试集。并对HGNN-SWT的参数进行如下设置:词语置信度阈值M为0.9;添加到训练集的词语的最小频率f为2;自训练轮数R为3;采样的邻居阶数L为3;采样的邻居节点数量g为5。此外,采用Accuracy和Macro-F1作为评价指标,它们在多分类问题中已得到了广泛应用。
4.3 对比实验
本节通过对比实验比较不同方法在网站主题分类任务上的性能,实验结果如表1所示。
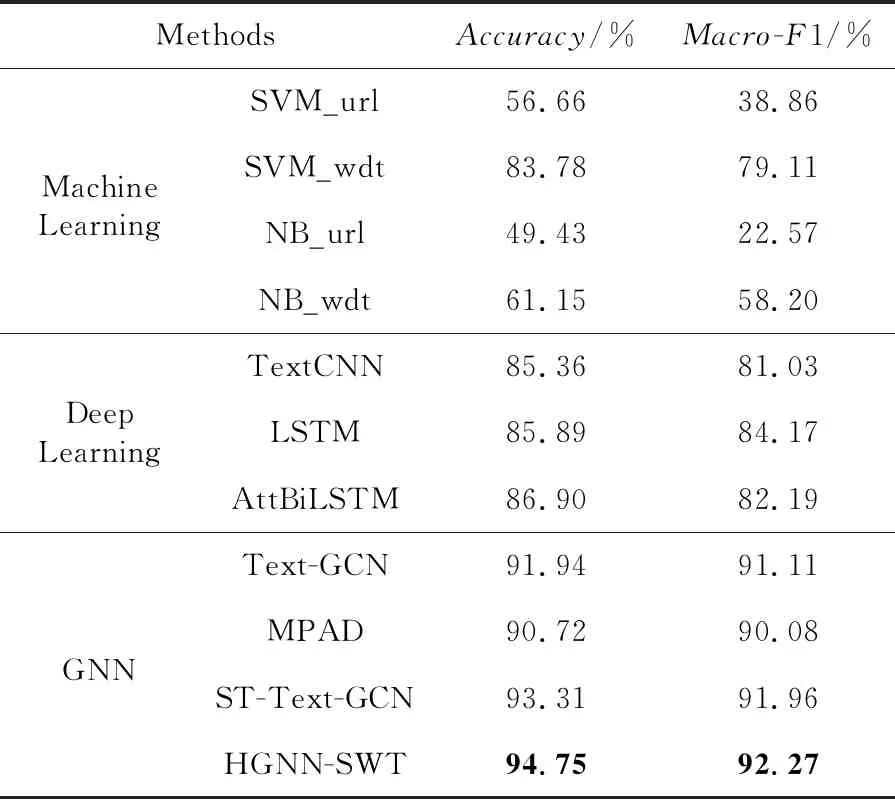
Table 1 Results of each method on website topic classification task表1 各方法在网站主题分类任务上的结果
从表1中可以明显看出,使用网站URL作为特征的SVM_url和NB_url分类方法的评价指标明显低于其他9种采用网站文本内容作为特征的分类方法。这表明,如果网站的主题信息并未直接体现在URL中,或者有些网站存在伪装现象,那么这类基于URL的分类方法的准确性将会受到较大影响。其他9种分类方法中,NB_wdt的性能最差,主要是因为朴素贝叶斯假设特征独立,而在网站文本分类任务中,这个假设通常不成立,因为词语之间具有关联性,而朴素贝叶斯分类器这种关联性无法有效捕捉,导致其性能受限。虽然本文使用FastText词向量得到的网站文本特征表示具有良好的语义信息和区分性,使得SVM_wdt在这些特征上表现较好,但其效果仍无法超越HGNN-SWT方法。在网站主题分类任务中,基于图神经网络的分类方法的效果优于TextCNN、LSTM和AttBiLSTM等深度学习方法。这表明,在处理稀疏的网站文本数据和捕捉短文本中的多层次语义关系时,将文本数据构造成图,并使用基于图神经网络的方法是一种有效的策略。Text-GCN的评价指标值远低于HGNN-SWT,主要是因为Text-GCN在构建图时仅通过TF-IDF考虑词语和文本节点之间的关系,忽视了同义词、多义词等语言特性,可能导致不确定词权重过高,从而对预测结果产生不利影响。相比之下,HGNN-SWT结合TF-IDF和词语置信度计算权重,反映节点关系更准确,从而提升预测性能。此外,HGNN-SWT还通过基于随机游走的邻居节点采样和特征融合学习了高阶邻居的特征,而Text-GCN并未进行高阶邻居的特征学习。MPAD的评价指标值也低于HGNN-SWT,这是由于MPAD将网站文本表示为词共现网络,在构图时并没有没有考虑文本和词语之间的关系,这会导致学习到的节点特征丢失许多信息。ST-Text-GCN的评价指标值均低于HGNN-SWT,这是由于ST-Text-GCN使用GCN对低阶邻居进行特征学习,而HGNN-SWT可以对节点的高阶邻居进行特征学习,学习到的语义信息和结构信息远比ST-Text-GCN的丰富。
4.4 消融实验
本节针对HGNN-SWT进行消融实验,旨在验证其各个步骤的可行性。HGNN-SWT作为参考方法。第一,为了验证构建网站异构图步骤的可行性,采用HGNN-SWT_ed方法,该方法仅基于TF-IDF和词语置信度来计算词语与文本节点之间的关系权重,并仅根据这条边构建图网络。第二,为了验证基于随机游走的邻居节点采样步骤的可行性,采用HGNN-SWT_sa方法,该方法仅对当前节点的一阶邻居进行采样,不进行高阶邻居的采样。第三,为了验证特征融合步骤的可行性,采用HGNN-SWT_mp方法,该方法使用最大池化替代特征融合模块中的平均池化。第四,为了验证特征转化步骤的可行性,采用HGNN-SWT_fe 方法,该方法在实验中直接将特征转化步骤移除。第五,为了验证自训练步骤的可行性,采用HGNN-SWT_se方法,该方法在实验中将自训练步骤移除。在上述方法中,除了特定需要验证的步骤,其他各步骤的设置均与HGNN-SWT保持一致。实验结果如表2所示。
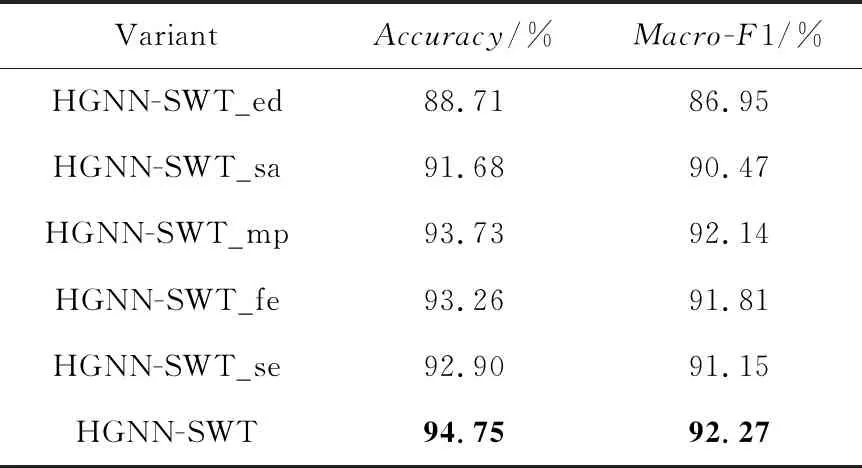
Table 2 Experimental results of different methods on website topic classification task
从表2可以看出,HGNN-GSE_ed的评价指标值在整个消融实验中取得的效果最差,这主要是因为缺少表示词语和词语节点之间关系的边,无法有效地捕捉和表示2个词语节点间的联系,导致图中的结构信息和语义信息丢失。这进一步证明了构建网站异构图的方法在捕捉和表示信息方面的有效性。HGNN-SWT_sa与HGNN-SWT相比,HGNN-GSE_sa的评价指标值较差,这主要归因于HGNN-GSE_sa只对当前节点的一阶邻居进行采样,而HGNN-SWT还采样了高阶邻居。相比之下,HGNN-SWT的特征融合模块能够学习更多的邻居节点信息。相比于HGNN-SWT,HGNN-SWT_mp的效果差一些,主要原因在于特征融合模块中,mean-pooling操作侧重整体特征信息,而max-pooling操作更关注局部特征信息。因此,mean-pooling在信息传递中往往能获得更好的效果。与HGNN-SWT相比,HGNN-GSE_fe的性能较低,主要原因是其移除了特征转换模块。相反,HGNN-SWT通过特征转换模块能够提升模型的非线性,并学习到更为有效的特征表示,从而增强模型对节点的表达能力和学习能力,这进一步提升了HGNN-SWT在分类任务上的性能。相较于HGNN-SWT,HGNN-SWT_se的表现较差,主要是因为其移除了自训练模块。相比之下,HGNN-SWT通过自训练模块不仅增加训练集样本数量还能通过扩散标签数据的信息来提升模型性能,从而提升模型的鲁棒性,经过多轮训练进一步优化模型的分类性能。经过上述实验分析,可以证明HGNN-GSE各步骤的可行性。
为了直观比较,本文将上述消融实验结果进行可视化,如图5所示。通过各变体方法学习网站文本节点嵌入,然后使用t分布随机近邻嵌入t-SNE(t-distributed Stochastic Neighbor Embedding)将测试集中的2 668个网站文本节点嵌入映射到二维空间,并根据网站主题的类别对节点进行着色。从图5f可以看到,HGNN-SWT学习到的节点具有较强的表示能力,可以将不同类别的节点边界进行较好的区分。

Figure 5 t-SNE embedding visualization of test set website text in the Chinaz Website
4.5 参数设置比较
为了确定合适的自训练轮数,本文使用随机种子确保在每次实验中,训练集、验证集和测试集的划分保持一致。然后,对不同的自训练轮数进行实验,并在其他参数设置保持不变的情况下,计算每轮自训练后方法的准确率。如图6a所示,当自训练轮数为2时,本文方法的性能有显著的提升。但是,随着自训练轮数的继续增加,准确率的提升较为有限,这说明HGNN-SWT的收敛速度很快,能在较少的轮数内达到优秀的结果。
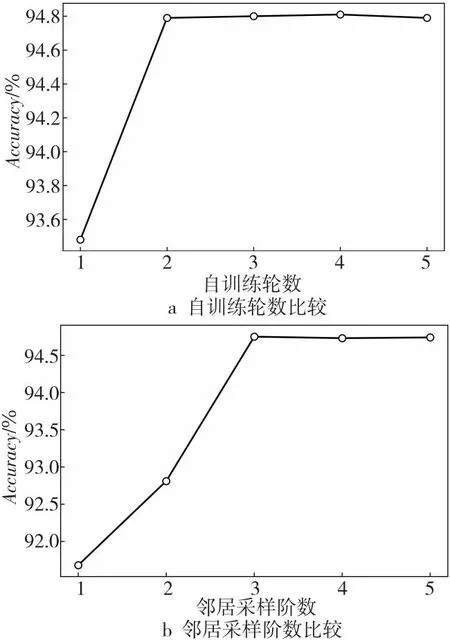
Figure 6 Comparison of parameter settings
为了更直观地理解自训练轮数对HGNN-SWT方法分类效果的影响,本文利用Heatmap对测试集的分类结果进行可视化。如图7所示,HGNN-SWT方法在不同类别上的分类表现可以被直观地展示出来。明亮的对角线表示HGNN-SWT方法对该类别的分类效果良好,而较暗的非对角线区域表示HGNN-SWT方法在这些类别上可能存在一些分类混淆或错误。值得注意的是,在自训练轮数为2时,购物这个网站主题的分类效果相较于第一轮有所下滑,但是其他的网站主题的分类效果都优于第一轮。

Figure 7 Classification results of different numbers of self-training rounds
此外,本文也探究了不同邻居采样阶数对本文方法性能的影响。如图6b所示,当邻居采样阶数为3时,本文方法的性能比阶数为1时有了显著的提升。然而,随着邻居采样阶数的进一步增加,准确率的提升幅度逐渐变小。
5 结束语
本文提出一种基于异构图神经网络的半监督网站主题分类方法HGNN-SWT。该方法将图神经网络与网站主题分类相结合,旨在解决现有方法在准确分类和搜索特定主题网站上的挑战。利用异构图来建模网站文本内容与词语间的关系,并通过处理图中节点和边的关系来提升分类性能。这一研究为网站主题分类领域提供了一种新的方法和视角,为实际应用中的网站主题分类和搜索提供了有益的参考。
