跨模态注意力YOLOv5的PET/CT肺部肿瘤检测
2024-04-22周涛叶鑫宇赵雅楠陆惠玲刘凤珍
周涛,叶鑫宇*,赵雅楠,陆惠玲,刘凤珍
1.北方民族大学计算机科学与工程学院,银川 750021;2.北方民族大学图像图形智能处理国家民委重点实验室,银川 750021;3.宁夏医科大学医学信息与工程学院,银川 750004
0 引言
世界卫生组织指出癌症是全球第二大死亡原因,2020 年接近1 000 万人死亡,仅肺部癌症就造成221 万例(World Health Organization,2022),无论是良性还是恶性肿瘤被成功识别后,可以采用手术、放疗和化疗等治疗程序来降低死亡风险。计算机断层扫描(computed tomography,CT)是常见的肺部状况检查方式,通过解剖信息对病灶结构进行定位;正电子发射断层扫描(positron emission computed tomography,PET)通过检测葡萄糖代谢可以显示病灶的病理生理特征;结合两者的PET/CT 已被证明在常规成像不足的情况下是有效的(周涛 等,2023),可以确定病灶同时精准定位,有助于辅助医生进行更快速和更精准的诊疗,多模态研究具有较高准确性和临床价值。
人工诊断肺部肿瘤存在耗时且易失误问题,而计算机辅助诊断可以提高诊断性能和患者生存率,深度学习模型自动学习影像特征并实现优良的表达,在肺部肿瘤检测中已经成为研究热点,Xu 等人(2023)提出检测肺结节的多尺度Faster R-CNN(region-convolutional neural network),其中多尺度训练策略提高检测小结节的能力,可变形卷积改善视野和增强全局特征,使检测精度从76.4%提高到90.7%;Zhang 等人(2023)基于CT 影像提出利于小半径肺结节检测的三维特征金字塔(feature pyramid network,FPN),在LUNA16(lung nodule analysis 16)数据集上获得89.34%的精度。
PET、CT、磁共振成像(magnetic resonance imaging,MRI)、X 光片等单模态医学成像技术的不断发展和组合,Hermessi 等人(2021)指出疾病诊断中多模态技术不断地提升性能和精度。在疾病检测任务中一些多模态方法相继提出,Mokni 等人(2021)基于乳腺X 光片和MRI 成像方式的互补,提出多模态融合模型对乳腺肿瘤进行检测诊断;Ming 等人(2022)通过融合CT 和PET 图像获得解剖和功能信息丰富的多模态影像,在卷积神经网络(convolutional neural network,CNN)中获得较单模态6%的宫颈肿瘤检测精度提升;Qin 等人(2020)使用CNN架构结合PET 和CT图像的细粒度特征,进行肺部肿瘤检测和无创诊断;Zhou 等人(2023)融合PET 和CT多模态影像和病变特征,利用空间域、频域和通道注意力获得8.32%的肺部肿瘤检测精度提升;Groheux(2022)利用PET/CT 多模态影像进行肿瘤的初级分期和复发检测,并表明PET/CT 在检测局部或复发方面比常规成像更有效。结合多模态信息疾病诊断更准确,Cao 等人(2023)指出图像设备易发生交替或移动,所获取的多模态影像并不完全对齐。此外,成像机理不同的多模态影像之间,所对应位置的像素值意义不同,不一致信息的不合理使用会导致检测精度降低。
肺部肿瘤病灶发生的部位、大小、病理类型复杂,放射学特征也不典型,不合理的深度学习检测模型容易出现诊断精度低、效率低、稳定性差等情况。Liang 等人(2021)利用Faster R-CNN 检测全肺CT 图像中肺结节,获得98%的肺部肿瘤识别率,但检测速度较慢。单阶段方法并行处理检测网络中的生成和识别,Pan 等人(2020)以VGG16(Visual Geometry Group 16)为骨干,提出自上而下特征融合的单次检测器(single shot detector,SSD),融合包含语义信息的高级特征和包含边界信息的低级特征,以较高效率进行识别;Schwyzer 等人(2018)在标准剂量和低剂量PET/CT 下获得95.9%和91.5%的敏感性,表明检测结节可能受到结节大小和代谢水平的影响。Farhangi 等人(2020)结合CNN 和递归神经网络(recursive neural network,RNN),学习长期依赖性,获得1/8 假阳性和80%灵敏度的较好效果;Deng 等人(2020)设计扩张金字塔(atrous spatial pyramid pooling,ASPP)检测模型,将特征按通道进行分组提取特征,获得较好的识别能力,但各分支卷积核数较少,提取的特征可能不充分。
肺部肿瘤PET/CT 图像中,由于部分肿瘤与周围组织粘连,导致病灶边缘模糊和对比度低,且肿瘤存在病灶区域小、大小分布不均衡的问题,此外,为充分考虑PET和CT多模态信息的互补,本文提出一种跨模态注意力YOLOv5(cross-modal attention you only look once v5,CA-YOLOv5)的肺部肿瘤检测模型,该方法的创新点包括:1)针对病灶存在边缘模糊、对比度低的问题,设计两分支并行的自学习注意力,利用实例归一化学习比例系数生成通道空间权重,同时利用特征值与特征平均值之间差值度量特征所包含信息量,生成逐像素权重并与通道空间权重相加,增强肿瘤特征和提高对比度。2)为充分学习多模态影像的多模态优势信息,设计跨模态注意力对多模态特征进行交互式学习,其中Transformer用于建模深浅层特征的远距离相互依赖关系,学习关键的功能和解剖信息以提高肺部肿瘤识别能力。3)针对肺部肿瘤病灶区域小、大小分布不均衡问题,设计动态特征增强模块,使网络充分高效挖掘肺部肿瘤特征的多尺度语义信息,并采用残差连接减少计算开销,同时使网络更易于优化。
1 相关工作
1.1 通道空间注意力
注意力机制就是使神经网络聚焦于局部信息的机制,随着任务的变化,注意力区域往往会发生变化,实现对信息的增强或抑制。Xu 等人(2022)为解决目标特征差异性较大的问题,结合注意力在非小细胞肺部肿瘤中取得较好效果;Shen 等人(2023)提出两阶段弱监督肺部肿瘤检测网络,利用交叉注意力机制对结节之间的相关性进行建模,获得88.63%曲线下面积的较好性能。
通道注意力就是在通道维度获取特征图的每个通道的重要程度,用这个重要程度去给每个特征赋予一个权重值,从而让神经网络重点关注某些特征通道,提升对当前有用的特征图的通道,并抑制对当前任务用处不大的特征通道。Wang 等人(2023b)基于卷积神经网络和通道注意力设计的3D 长方体注意力,自动检测肺结节并获得96.15%准确率;Choi 和Lee(2023)在VGG 基础上应用高效通道注意的光注意连接模块,获得92.81%精确度的较好性能,并利用热力图分析肺部疾病识别的原因。
空间注意力就是在空间维度提升对特征图中关键区域的表达,增强感兴趣区域同时弱化不相关背景区域。Basu 等人(2023)提出Transformer 学习全局空间特征,并组合局部特征图在肿瘤检测中获得了较高的检测精度。通道空间注意力就是从空间维度和通道维度同时进行增强。Gu 等人(2022)基于空间通道注意机制提出交叉注意力捕获相似特征图的重要特征和融合结果,然后利用三维空间金字塔池化学习不同尺度的结节特征实现,减少肺结节检测中的假阳性并在LUNA16数据集获得84.8%的准确性。Xiao等人(2023)结合捕获高级语义信息的多尺度空间通道注意和增强小病变区域感知的多特征融合全局局部注意,缓解了病灶尺寸小和背景相似导致识别准确率低的问题,获得较好的识别性能。
通道、空间和混合注意力机制可以较好地增强CNN 特征提取能力,其中空间通道注意机制已得到广泛应用,曾文健等人(2022)利用卷积注意力模块(convolutional block attention module,CBAM)优化分配权重和突出目前特征信息;Liu等人(2021)提出归一化注意力(normalization-based attention module,NAM),采用CBAM 集成方式并重新设计各子模块,在注意力模块上应用稀疏的权重惩罚,保持性能同时使权重进行更加高效的计算;Liu等人(2021)还提出GAM(global attention mechanism)通道空间注意力,通道注意利用多层感知机放大跨通道的空间特征,利用两个卷积层进行空间信息融合和选择性加权空间特征。
1.2 YOLO检测模型
单阶段检测网络YOLO(you only look once)将检测问题转化为回归问题,不直接提取感兴趣区域,而是通过回归方法生成每个类的边界框坐标和概率,提高了推理实时性和检测精度。YOLO 模型可以分为3 部分:主干网络、特征增强颈部和预测头部。主干网络用于提取图像特征,首先,聚焦(focus)模块学习输入特征,不丢失细节同时减少计算量;然后,CBS(conv BN silu)和CSP(cross stage paritial)特征提取模块将特征映射分成两部分,以较高计算效率提高模型特征提取能力,最后,空间金字塔池化(spatial pyramid pooling,SPP)模块扩大感受野和丰富特征表达能力,辅助上下文特征的识别。特征增强颈部构建特征金字塔结构和路径聚合网络增强特征的语义信息和空间信息。预测头部用3 个1×1 卷积层进行预测,并通过非极大值抑制获得最终肺部肿瘤检测结果。
Huang 等人(2022)提出特征融合注意机制的YOLOv3模型,并在LUNA16数据集中获得90.5%的肺结节检测准确性;曾文健等人(2022)基于通道空间注意力YOLOv4,传递浅层信息到深层进行特征融合,提高网络对小目标的检测能力;黄健宸等人(2022)基于YOLOv5 设计高效轻量特征提取模块,并跳跃连接中层特征实现多尺度特征加权融合,最终以降低15.5%参数量获得3.9% 平均精度均值(mean average precision,mAP)的性能提升。
Zhu 等人(2021)集成Transformer 到YOLOv5 以准确定位高密度场景中目标,利用全局学习能力和大尺度提升了1.81% 精度;Ge 等人(2021)在YOLOv3 的基础上提出YOLOx 模型,对检测头1×1卷积同时回归框和置信度进行解耦,以提升网络的收敛速度,为每个正样本分配一个中心先验并拟合,其他全部归为负样本实现无锚框,较最优方法获得3.0%精度提升;Wang 等人(2022a)集成模块重参数化和动态标签分配策略到YOLOv5,提出YOLOv7 利用通道扩展、混洗和基数合并不破坏原有梯度路径,增强网络学习能力,最终检测器实现了较优的速度和准确度;YOLOv5 团队提出YOLOv8l(Li 等,2023)模型,利用通道拆分和拼接设计更轻量化的特征提取模块并应用于上采样阶段,使用无锚框思想和替换交并比(intersection over union,IoU)匹配方式为任务对齐分配器,较YOLOv5l获得了7.96%的性能提升。
2 跨模态注意力YOLOv5模型
本文基于YOLOv5 提出CA-YOLOv5 模型,整体架构如图1 所示,主干网络充分提取多模态特征,利用Transformer 增强后传递到特征增强颈部,预测头部通过1×1 卷积层和非极大值抑制进行肺部肿瘤预测与分类。本文在主干网络中全部3 个CSP 模块末端引入自学习注意力模块,对各个模态的肺部肿瘤特征进行增强;设计Transformer,充分学习深浅层特征的远距离相互依赖关系,此外,在不同模态Transformer 的特征之间,利用跨模态注意力对多模态特征进行交互式学习;设计动态特征增强模块,充分挖掘肿瘤的多尺度语义信息。

图1 CA-YOLOv5整体架构图Fig.1 CA-YOLOv5 overall framework
2.1 自学习注意力
通道空间注意力从空间和通道维度,同时对信息进行增强或抑制。为解决病灶存在边缘模糊、对比度低的问题,本文设计了两分支并行的自学习注意力,具体结构如图2 所示。一个分支利用实例归一化(instance normal,IN)对每个通道与空间的特征图进行计算,然后线性变换得到比例系数,由比例系数占比得到通道和空间注意力权重。根据图像中包含信息更多的特征会有更高数值的特点,另一分支利用特征值与特征平均值之间差值,赋予每个特征不同的重要性实现三维权重。不同于卷积、池化和全连接操作,三维权重不引入额外参数,通道和空间权重仅采用实例归一化进行计算,最终仅利用不到1%的参数量,即可提高特征的表达能力。

图2 自学习注意力结构Fig.2 Structure of self-learning attention
图2中第1条分支采用先通道后空间注意力,这是由于计算通道权重所需参数少,对关键通道增强后有利于提高信息处理效率。通道注意力的计算是利用实例归一化计算每个通道的比例系数αi和βi,每个通道的输出yi计算为
式中,i=1,2,···,C,输入特征xi是由空间分辨率为H×W的C个通道构成的特征图,为单个通道上空间中全部特征的平均值,σi为第i个特征通道上特征值的标准差,比例系数αi和βi通过模型迭代优化得到,与通道的重要程度正相关,利用αi计算每个通道的权重占比,获得通道注意力权重。同理,可以计算在空间域中感兴趣区域的重要程度,空间注意力是利用实例归一化对空间特征进行归一化,计算每个特征空间的比例系数,然后通过比例系数的权重占比,获得空间注意力权重。
图2 中第2 条分支计算每个特征所包含的信息量,并赋予其不同的重要性。本文计算每个通道上特征值的平均值,然后计算每个特征值与平均值之间的差,由于部分特征与平均值之间差值不明显,使用平方可以产生更大的差值,更好的特征区分使网络易于优化训练,最终每个通道进行依次计算生成三维权重Wi的表达式为
式中,xi为输入特征图的当前通道上第i个空间特征值,H和W分别为输入特征图的高度和宽度,λ是一个常数,本文设置为0.5。如图1 所示,本文将自学习注意力模块添加至主干网络的CSP 模块末端,可以在保持轻量化和较高计算效率前提下,提升网络的信息捕获能力和识别性能,更好地聚焦于肿瘤特征。
2.2 跨模态注意力
CNN 通过卷积核对局部信息进行学习和提取,但卷积局部性限制了其学习全局上下文信息的能力。CNN 结合RNN 可获得较好性能,但RNN 需要依赖先前隐藏层的输出,这种长期依赖性会有冗余信息传递而导致性能降低。Transformer 能对全局信息进行学习,实现整幅图像特征之间相互依赖关系的建模,还能保留足够的空间信息以方便肺部肿瘤检测。为此,本文针对CNN 捕获全局信息时的不足,设计Transformer,采用最大池化(MaxPool)和深度卷积(DWConv)对主干网络中深浅层特征进行特征提取和融合。
成像机理不同的三维多模态影像之间存在很多不一致的信息,自学习注意力对特征通道或空间进行重新校准,然而在肺部肿瘤识别中若使用不合理的特征融合,会导致PET、CT 和PET/CT 多模态影像中包含肿瘤信息的关键特征难以有效提取和增强。此外,深层语义信息可以辅助不同模态的浅层定位信息,需要考虑不同模态深层特征和浅层特征之间信息传递的必要性。为获取多模态丰富的细节和语义信息,本文设计如图3(c)所示的跨模态注意力,对不同模态的深层或浅层特征进行学习和交互,利用Transformer 充分学习跨模态图像的语义相关性,学习多模态特征的远距离相互依赖关系并进行重新校准,交互式增强多模态影像中肿瘤特征。

图3 跨模态注意力结构Fig.3 Structure of cross-modal attention((a)cross-modal stacking;(b)cross-modal enhancement;(c)cross-modal co-attention)
为充分学习浅层特征所包含的信息,浅层特征利用两分支结构向深层传递特征,一个分支是2×2最大池化以计算局部最大值,另一分支是3×3深度卷积以提高计算效率,双分支特征与其他层特征进行拼接,利用Transformer学习肿瘤特征的全局特征。Transformer 对1×1 卷积获得的查询(Q)和键值(K)进行计算,生成注意力得分图并应用于输入特征的值(V),最终输出Y计算为
式中,dk是指键值(K)的维度,softmax 是归一化指数函数,此外,对PET/CT 多模态特征之间的Transformer 进行交互。多模态融合包括像素级融合、特征级融合和决策级融合,像素级融合是将数据类型转化一致后进行拼接,特征级融合是将多模态数据经过各自的特征提取后进行拼接,决策级融合是将特征提取后融合全部分支,由于本文识别对象仅为肺部肿瘤,决策级融合操作与特征级融合相同。像素级融合和特征级融合只对多模态数据融合一次,为此,将PET 和CT 特征图拼接为PETCT 特征图,并在4 个不同尺寸特征图上设计如图3 所示的3 种融合方式。
如图3(a)跨模态堆叠所示,在同一尺寸多模态特征图中,利用PETCT 对PET/CT 进行增强。如图4(b)跨模态增强所示,利用深层PET 和CT 对不同尺寸的PET/CT 特征图进行增强。如图4(c)跨模态协同注意力所示,在同一尺寸多模态特征图中,利用PETCT 和PET/CT 特征图进行交互式的协同增强。利用Transformer 来编码PETCT 特征和PET/CT 特征,主分支将特征映射为Q,再与另一分支映射的K和V进行全局特征学习,通过在不同模态特征图内学习和交互,并结合深浅层特征学习更多可区分的特征,提高语义判别能力和缓解类别混淆,更好地捕获多模态影像中肺部肿瘤特征。

图4 动态特征增强结构图Fig.4 Structure of dynamic feature enhancement
2.3 动态特征增强
YOLOv5 基于主干分类网络提取的特征,实现图像特征点的预测和检测。然而,分类网络更倾向于平移不变性而忽略位置信息,扩张卷积可学习更丰富的语义信息,而扩张率增长过快可能会忽略一些有用的细节,尤其是肺部肿瘤存在病灶区域小、大小分布不均衡问题。此外,肿瘤区域通常是不规则形状,采用正方形卷积核获取边界框的有效性欠缺。为此,本文设计如图4 所示的动态特征增强模块,扩张率r为1、2和3,分组数g为4的3×3扩张卷积,与分组数g为4 的5×5 可变形卷积,并行实现四分支结构,分组方法保持模块计算复杂度,扩张卷积增强网络表达能力,可变形卷积可以有效地提取不同形状目标的特征,从而充分挖掘多尺度语义信息。本文采用相加方式来减少计算开销和提高模块优化能力,同时避免了ASPP拼接下各分支卷积核组数较少造成特征提取不足。
为进一步增强可变形卷积对空间区域的调控能力,本文在可变形分支中引入比例系数,调控偏移量和不同空间位置幅度,可以让网络学习更大范围的空间区域,改进后输出YD的计算式为
式中,P0是第(0,0)个特征的坐标,w(P(i,j))为第(i,j)个特征的卷积核权重系数,Δm(i,j)代表第(i,j)个位置的比例系数,由卷积和Sigmoid函数生成。
为避免不同分支k对输出贡献不一样,每个分支引入额外权重wk进行平衡,wk计算为
式中,∑xk为第k条分支的全部特征值之和,∑xj为4 条分支的全部特征值之和,ε为常数,本文设置为10-4以保持训练的稳定。利用动态特征增强优化CSP 模块,将多个残差块堆叠结构缩减为单个残差块,然后利用动态特征增强学习残差块特征,最终应用在整个特征增强颈部。
3 实验和讨论
3.1 肺部肿瘤PET/CT数据集与参数设置
本文选用从宁夏某三甲医院2014 年—2020 年期间收集的104例肺部肿瘤临床患者,患者通过Discovery MI 仪器进行肺部及躯干部图像采集,获取已配准的PET、CT 和PET/CT 二维肺部肿瘤图像,如图5 所示,CT 图像肿瘤和正常组织密度差异很难区分,而PET 图像中肿瘤区域代谢旺盛,呈高亮,因此多模态肺部肿瘤图像可以更好地识别和定位病灶。肺部肿瘤PET/CT 多模态数据集样本数为各模态1 147幅,其中训练集684幅、验证集222幅和测试集241 幅。每个样本有两种类型文件,3 种模态JPG 图像文件,具有多样性的大小、角度、辐射计量和背景;XML 标签文件,根据医生建议通过Labelimg 软件标注,指定了图像中肺部肿瘤的精确位置。
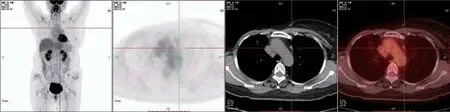
图5 已配准的PET、CT和PET/CT图像Fig.5 Registered PET,CT and PET/CT images
本次实验环境为内嵌Ubuntu18.04 LTS 的64 位Windows11 系统,内存为40 GB,搭载AMD 3500X 的处理器,并采用英伟达2070 super 加速图像处理,Pytorch 框架进行网络搭建。使用随机梯度下降(stochastic gradient descent,SGD)优化器进行优化,学习率采用每10周期乘以0.95的衰减策略,初始采用0.01,每次训练和梯度更新后的权重衰减值设置为0.000 1,为加快模型收敛和减缓模型找到局部最优点时的震荡现象的动量减缓梯度设置为0.9,训练周期为300,训练批处理大小为16。
3.2 评价指标
在目标检测中,IoU 是检测物体准确率的标准,即计算真实区域与预测区域的交叉面积比上整体面积。检测框和真实框均预测为真,IoU 大于阈值0.5标记为真阳性(ture positive,TP),否则,标记为假阳性(false positive,FP);同理得到假阴性(false negative,FN)和真阴性(true negative,TN)。精确率(precision,P)为正类且预测正确占所有正类的比例,召回率(recall,R)为预测出的正类占所有正类的比例。平均精度(average precision,AP)是指0到1内平均召回率,即肺部肿瘤类精确率—召回率(precision-recall,PR)曲线下面积。
每秒传输帧数(frames per second,FPS)代表每秒可以检测的图像数量,用于评估物体检测的速度。
3.3 不同模态融合实验与分析
通过7 组实验来验证学习多模态特征中跨模态语义相关性的优势,不同模态之间采用拼接方式融合特征,7 组实验均在YOLOv5s 模型的基础上进行,实验结果如表1 所示。设计3 组实验直接对两分支均输入单模态图像,然后采用网络提取多模态特征后再进行拼接的特征级融合,同时输入CT与PET 三模态,最后,使用3 组实验对本文设计的3 种跨模态交互方法进行实验。
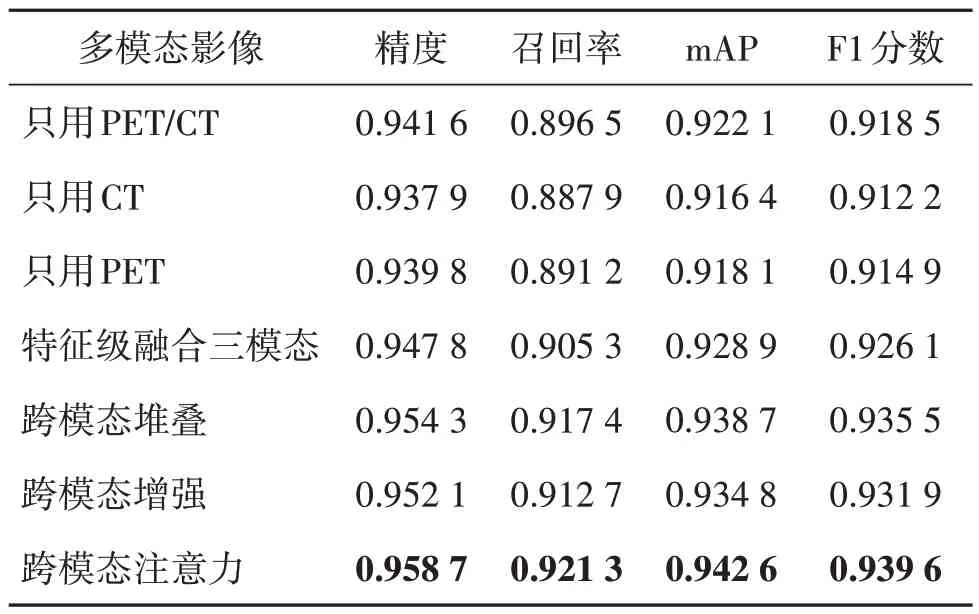
表1 不同模态融合结果Table 1 Fusion results of different modes
从表1 前3 组可看出,只使用CT 的性能最差,PET 功能信息在肿瘤识别上较CT 解剖信息更具有优势,PET/CT 已对两种影像融合,从而取得了最佳性能。从表1第4组与第1组整体性能对比,mAP 和F1 分数提升0.74%和0.83%,可看出提取多模态特征的整体性能更优,说明利用CT、PET 和PET/CT 已配准影像的多模态信息对检测肺部肿瘤具有较大作用。
基于表1 第4 组的结论进一步研究本文所设计的3种跨模态交互方法。从表1第5组和第6组对比可以看出,在同一尺寸多模态特征图中利用PET 和CT 对PET/CT 进行增强的跨模态堆叠方法,相比于利用深层PET 和CT 对不同尺寸的PET/CT 特征图进行增强的跨模态增强方法,性能更好。为此,本文将单方向增强扩展为双向的交互式增强,在同一尺寸多模态特征图中相互进行增强,从而得到跨模态注意力方法。第7 组跨模态注意力方法获得了最高的性能提升,mAP 和F1 分数进一步提升1.47%和1.46%,表明相互增强交互式的跨模态注意力性能最佳。
3.4 消融实验与分析
为了评估本文模型结构的有效性,进行3 组实验来说明自学习注意力、特征级融合三模态、跨模态注意力和动态特征增强模块对于实验结果的影响,消融实验具体结果对比如表2所示,主要从mAP、F1分数和训练总时间进行分析。
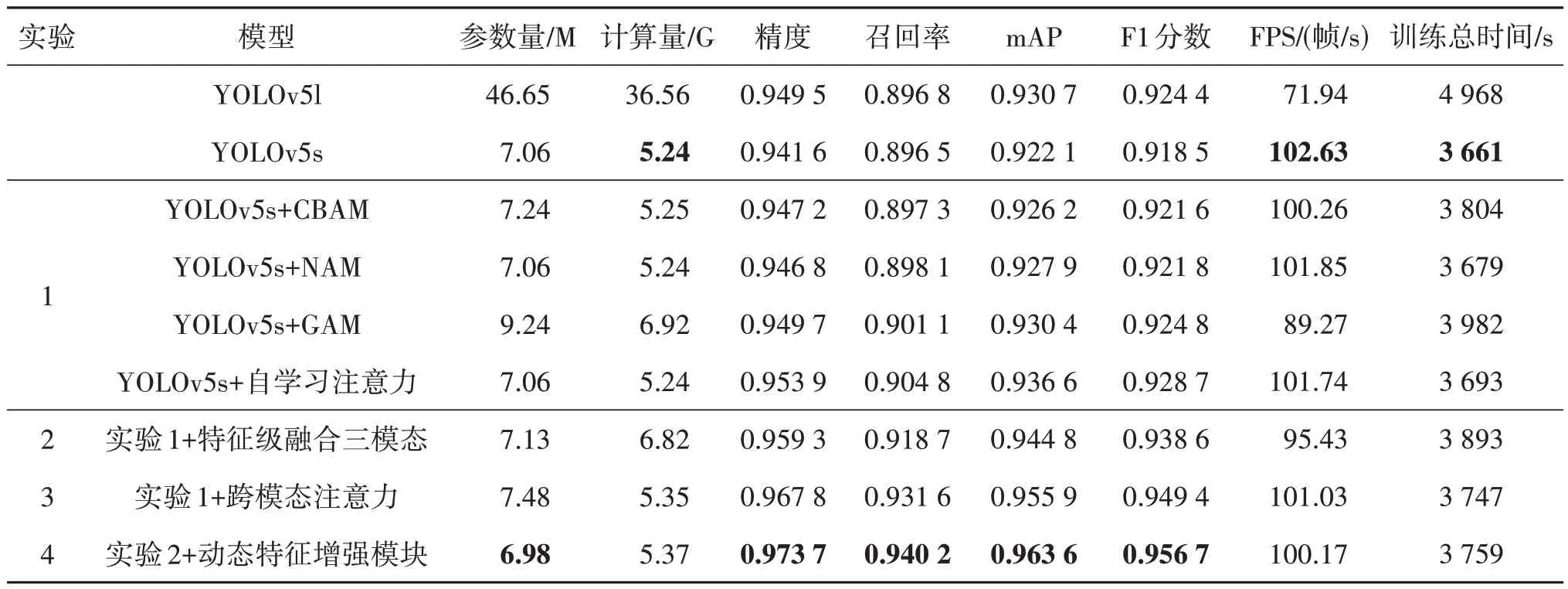
表2 消融实验结果对比Table 2 Comparison of results of ablation experiments
实验1 添加自学习注意力,参数量未发生变化,计算量和总时间略微增加,mAP 和F1 分数各上升0.83%和0.65%,自学习注意力的计算效率和性能均优于CBAM、NAM 和GAM 注意力,其比例系数学习和特征信息量度量,可以几乎无需额外的资源消耗,保持轻量性同时增强肿瘤特征和提高对比度,缓解部分肿瘤与周围组织粘连、边缘模糊、对比度低的问题。
实验2 的mAP 和F1 分数提升0.88%和1.07%,PET、CT和PET/CT 多模态三维图像进行跨模态语义信息的特征互补,三模态进行特征级融合可以较好地增强模型对病灶的聚焦能力。
实验3 较实验2 的mAP 和F1 分数提升1.17%和1.15%,以更少的资源代价获得了更高的性能提升,跨模态注意力对不同模态的深浅层特征进行学习和交互,通过Transformer 建模多模态特征的远距离相互依赖关系,可以充分利用多模态影像的功能和解剖信息,利用其语义相关性实现对包含肿瘤信息的特征进行有效增强,可以有效提高模型识别能力和检测精度,进一步缓解了肿瘤区域的对比度低的问题。
实验4添加动态特征增强模块,可变形卷积的应用使得计算量略微增加,整个模块采用分组方法使得参数量更少,mAP和F1分数各上升0.92%和0.77%,多分支扩张卷积和可变形卷积的多分支设计,可以充分高效挖掘肺部肿瘤特征的多尺度语义信息。
3.5 对比实验与分析
为了验证CA-YOLOv5 模型的良好性能,将本文与其他目标检测模型进行比较。为了保证公平性,本文使用统一的输入尺寸512×512 像素、训练超参数和训练平台。本文方法和其他10 种方法的具体实验结果如表3 所示,通过计算各模型参数量和计算量,以及其识别精度和时间,探究其在肺部肿瘤PET/CT数据集上的识别率和效率。
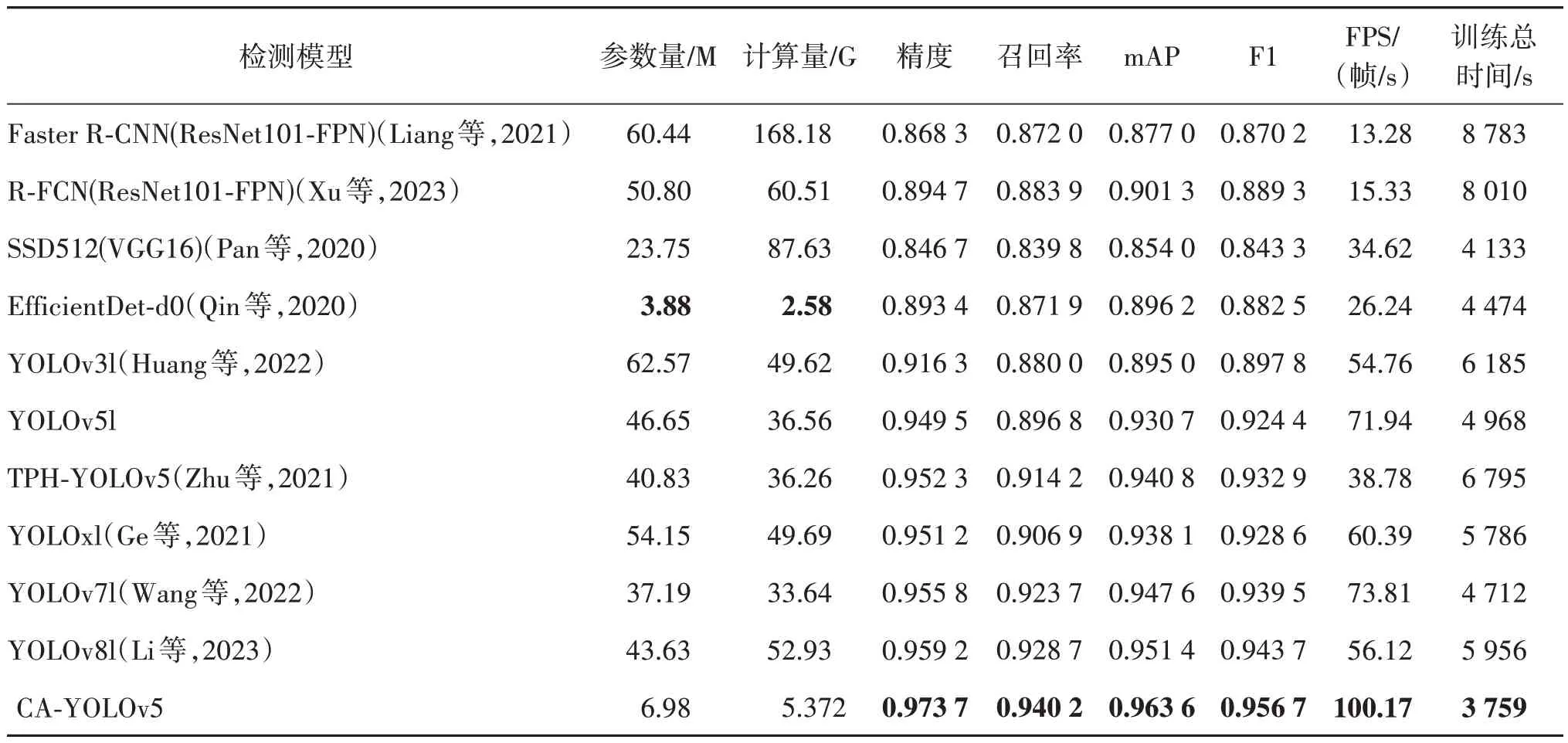
表3 各模型在肺部肿瘤PET/CT数据集中的结果Table 3 Results of each model on lung cancer PET/CT dataset
单阶段方法EfficientDet-d3、YOLOv4l、YOLOv5s、YOLOv5l、YOLOxl 和本文的CA-YOLOv5 在mAP、F1分数、精度和召回率均优于两阶段方法Faster RCNN(ResNet101-FPN)、R-FCN(ResNet101-FPN)和单阶段方法YOLOv3l、EfficientDet-d0、SSD512(VGG16)。两阶段方法的训练总时间和FPS 明显差于单阶段方法,基于Faster R-CNN 改进的R-FCN 的参数量、计算量各下降了15.82%和64.02%,这是因为使用特征提取的方式计算候选框需要一定时间,R-FCN 在每个输出之间完全共享计算以提升速度,利用位置敏感分数图解决分类部分的平移不变性与检测部分的平移可变性之间的矛盾,使mAP和F1分数也提升了2.77%和2.19%。单阶段方法计算效率更高,尤其是YOLOv5s 和本文的CA-YOLOv5 模型,训练总时间和FPS 最好,完全可以达到实时检测的效果,这是由于它们通过回归方法生成类的边界框坐标和概率,大幅提高了实时性;EfficientDet-d0 以最小参数量和计算量获得0.896 2的mAP和0.882 5的F1分数。
YOLO 将候选区和对象识别两个阶段合并以同时检测和分类,YOLOv3l 检测精度和速度得到有效提升,错误背景检测率明显降低,mAP 较SSD 提高6.91%;YOLOv5l 增加了自适应锚框计算和Focus 切片结构,采用新的金字塔结构和路径聚合网络改善低层特征传播,检测精度更高并获得1.58%和1.07%的mAP 和F1 分数提升。在高密度场景中准确定位目标的TPH-YOLOv5,通过Transformer 集成,获得了更高的整体精度;YOLOv7l 将模型重参数引入获得了不错的性能,mAP和F1分数较YOLOv5l提升了1.82%和1.63%;YOLOv8l 将主干每层以拼接方式在末端进行聚合,保证轻量化的同时获得更丰富的梯度流信息,获得了较高的性能。本文CAYOLOv5 方法,在肺部肿瘤PET/CT 数据集中取得0.973 7的精度、0.940 1的召回率、0.963 6的mAP和0.956 7 的F1 分数,优于其他检测算法,较YOLOv5l的各项指标提高了2.55%、4.84%、3.53%和3.49%。
目标检测模型的置信度越大表示检测准确的概率越大,置信度过高会使检测标准太严格,过小会使标准太宽松。为此,在每个置信度上进行分析,由于每个置信度级别上计算出的精确率和召回率不一样,设定以精确率为横轴、召回率为纵轴的PR 曲线如图6所示,对精确率和召回率之间进行权衡。
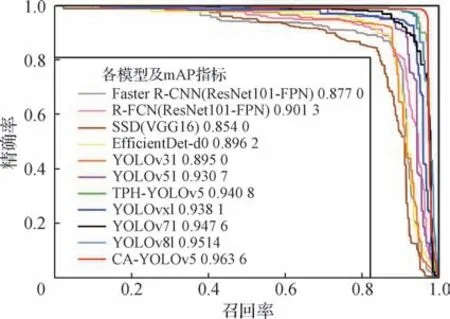
图6 各模型的PR曲线Fig.6 PR curves of each model
从图6可以看出,精确率越高,召回率就越低,向右上方凸出、包围面积更大的曲线代表模型更好,本文CA-YOLOv5模型mAP值最大,性能明显最优。
图7 显示了各个检测网络的肺部肿瘤F1 指标训练过程,随着置信度的增加,F1 分数趋于0,较高的置信度是可取的,通过F1曲线在高置信度下的F1分数对模型进行对比,可看出本文CA-YOLOv5模型明显最优。
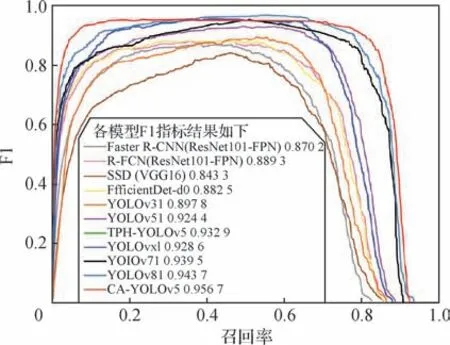
图7 各模型的F1曲线Fig.7 F1 curves of each model
3.6 可视化验证实验
本文CA-YOLOv5 模型对肺部肿瘤的识别结果如图8 所示,识别框上方数字是置信度分数,可以看出本文对肺部肿瘤样本的识别能力明显较优。
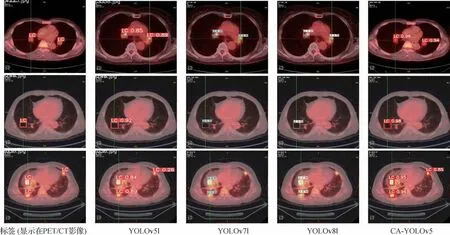
图8 CA-YOLOv5模型对肺部肿瘤的识别结果Fig.8 Recognition results of CA-YOLOv5 for lung cancer
利用病灶区定位的热力图,对模型的有效性进一步验证。图9(a)为一幅肺部肿瘤患者影像及标签,在YOLOv5l和CA-YOLOv5模型上分别生成热力图。用伪彩表示网络对图像不同区域的关注程度,红色程度越深表示网络对该区域的关注度越高;反之,蓝色程度越深表示网络对该区域关注度越低。图9(c)是CA-YOLOv5模型上生成的热力图,可以看到,其不仅识别出全部标签,网络所关注的病灶区域也更为精准。
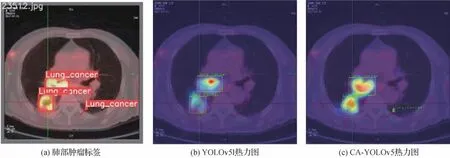
图9 肺部肿瘤标签和热力图Fig.9 Lung cancer label and heatmaps((a)lung cancer label;(b)YOLOv5l heatmap;(c)CA-YOLOv5 heatmap)
3.7 公共肺结节检测实验
为了进一步验证本文所提CA-YOLOv5 模型对肺部肿瘤检测识别的鲁棒性和泛化能力,肺部肿瘤PET/CT 数据集具有稀缺性,使用888名患者CT影像组成LUNA16公开数据集(Setio 等,2021),将本文方法 与Faster R-CNN、EfficientDet-d3、YOLOv5l 和YOLOxl 方法进行对比。LUNA16 数据集包括1 186 个肺部肿瘤标签,由4 位经验丰富的胸科放射科医生手工标注。但LUNA16 数据集为三维图像,为了使本文模型和对比模型可以输入LUNA16 数据集的三维图像,本文随机在888 名患者中对每个患者提取2~3 幅CT 二维切片图像。各模型在LUNA16 数据集的1 477 幅CT 图像中进行训练和296 幅CT 图像中进行验证,各模型在519 幅CT 图像中进行测试的具体实验结果如表4所示,从LUNA16数据集中可看出本文模型的各项评价指标最高,图10 所示PR 曲线中本文模型在坐标轴上整体覆盖范围最大,更加直观地显示出本文模型CA-YOLOv5的有效性。

表4 各模型在LUNA16数据集中的结果Table 4 Results of each model on LUNA16 dataset
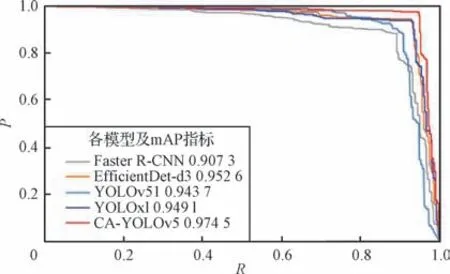
图10 各模型在LUNA16数据集中的PR曲线Fig.10 PR curves of each model on LUNA16 dataset
4 结论
本文提出了跨模态注意力YOLOv5 的肺部肿瘤检测模型,旨在解决肺部肿瘤对比度低和区域小导致病灶提取困难的问题,同时充分学习PET 和CT 的多模态互补信息。检测模型主要由两部分组成:1)轻量高效的自学习注意力机制,增强肺部肿瘤特征和提高对比度,动态特征增强模块挖掘肿瘤特征的多尺度语义信息;2)设计跨模态注意力对多模态特征的优势信息进行交互式学习。在多模态的多尺度特征、局部和全局语义特征的共同增强下,本文算法对肺部肿瘤具有更强的检测能力。对模型中各个模块进行了消融实验,结果证明了网络中各个模块的有效性。此外,在多模态肺部肿瘤PET/CT 和LUNA16 公共数据集上的实验结果表明,本文模型均达到先进性能,学习多模态影像的功能和解剖信息更多,可视化也说明了其肺部肿瘤识别能力。
但是,本文提出的模型仍然存在一些需要改进的问题。后续需要设计更轻型结构同时学习多模态特征,如注意力机制。此外,本文使用通道空间的局部注意力,但缺乏同时局部和全局注意力对肺部肿瘤的增强,而使用全局注意力并行会增大网络学习的负担。如何保持轻量化的学习多模态局部和全局特征提取,是接下来工作需要优化的方向。
