优化聚类分簇结合自适应中继策略的双簇首WSNs路由算法
2024-04-22张晶,高翔,张宏
张 晶,高 翔,张 宏
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(云南枭润科技服务有限公司,昆明 650500) 3(昆明理工大学 云南省人工智能重点实验室,昆明 650500) 4(昆明理工大学 云南省计算机技术应用重点实验室,昆明 650500)
0 引 言
感知层作为信息物理系统(Cyber-Physical Systems,CPS)中的重要组成部分,主要是通过传感器获取环境中的信息.这些传感器节点通过无线通信方式可以在特定区域内形成分布式的自组织多跳感测网络,即无线传感器网络(Wireless Sensor Networks,WSNs).WSNs中的传感器节点具有体积小、成本低和易部署等特点.然而节点储能部件几乎不可能也没必要更换或二次供能,网络的工作时间取决于节点的能量效率,因此如何优化节点的能耗水平、平衡节点的负载始终是WSNs应用中的重要课题之一.针对WSNs网络层的节能和流量均衡问题,许多节能路由协议被提出,主要通过调整网络的拓扑结构、提高网络的能量利用效率延长网络的生命周期[1].
针对WSNs中的节点能耗问题,Heinzelman等人[2]提出了被公认为最原始的经典层次分簇路由协议LEACH(Low Energy Adaptive Clustering Hierarchy),算法周期性地按轮执行.每轮的簇建立阶段,节点随机竞选簇首来均衡作为簇首的高负载,节点基于最小距离原则来入簇.每轮的数据发送阶段,簇首负责收集簇内感测信息并单跳传输给基站,但随机当选的簇首存在能量和位置不合理的问题,不利于将整个网络的能量负载平均分配到每个传感器节点中,限制了网络的生命周期.随着WSNs应用的升级,LEACH协议的性能无法满足相应的需求,但是分簇路由方法因其能量利用效率、可靠性和可扩展性高等优点,得到了广泛的研究.Behera等人[3]提出了一种基于剩余能量的LEACH改进算法R-LEACH(Residual energy-based LEACH),该算法通过结合节点的初始能量、剩余能量以及最佳簇首数修改了LEACH协议中节点成为簇首的阈值,来选择合理的簇首,避免了节点过早死亡,但其没有考虑节点位置对传输能耗的影响.叶继华等人[4]提出了一种结合相对信息熵的改进LEACH协议,利用相对熵对数据集进行去冗余以降低传输数据量,并使用兼顾能量、距离和能耗比的多跳转发路由来均衡各节点的能耗速率,但其没有对成簇阶段进行进一步的优化设计,可能会导致簇分布的不均匀.Rajput等人[5]提出了一种半分布式分簇协议SDCP(Semi-Distributed Clustering Protocol),基于模糊C均值(Fuzzy C-Means,FCM)算法成簇将节点进行适当的聚类以减少簇内通信距离,并使用模糊逻辑进行簇首选择以解决WSNs中由环境噪声造成的不确定性,提高了网络的稳定性和可持续性,但是该协议未考虑多跳路由,导致与基站距离较远的簇首能量消耗很大.Panag等人[6]提出了一种双簇首静态分簇算法DHSCA(Dual Head Static Clustering Algorithm),初始化阶段节点根据位置被划分到静态的簇,避免了动态成簇的开销,该算法每个簇中选出两个簇首分别用于数据融合和数据传输,有助于平衡节点间的能量消耗,并通过轮换的传输簇首进行多跳,将传输负载分布到节点之间,但是该算法静态成簇是使用简单的网格划分,没有考虑到节点的分布特性.赵小强等人[7]提出了一种基于虚拟力的能量高效路由协议,从能耗角度对簇首数进行了理论设定,通过构建虚拟簇首和3种虚拟力模型来优化真实簇首的选择,并且分析了簇间多跳的使用条件,提高了数据传输效率,延长了对目标区域进行有效监测的时间,但是该协议中的簇首既负责收集、融合簇成员的感测数据,又负责与基站通信传输数据,导致簇首节点负载大、能耗高.
因此,基于以上分析并综合考虑如下3个方面:对感测区域进行能耗均衡的成簇划分,选举能量、位置和分布密度最合理的簇成员为簇首以及规划最优通信路径,本文在已有研究的基础上提出了一种优化聚类分簇结合自适应中继策略的双簇首WSNs路由算法(Dual Head WSNs Routing Algorithm Based on Optimized Cluster Analysis for Clustering Combined with Adaptive Relay Strategy,DRCR).该算法的主要内容如下:
1)成簇阶段,以通信能耗为依据设置最优成簇规模,使用算术优化算法(Arithmetic Optimization Algorithm,AOA)计算FCM算法的初始聚类中心,并引入最大最小距离积方法改进AOA的种群初始化,基于此进行集中式成簇可以稳定成簇规模、避免频繁成簇的广播能耗.
2)簇首选举阶段,设计了分布式动态双簇首选举机制进行簇首轮换.在感测区域已经划分成簇的基础上,对内外簇首的工作特性、影响簇首能耗的因素进行分析,分别为内外簇首设计独立的簇首评价函数,并根据节点能量水平实时调整因子的权重,使簇内的负载更加均衡.事先成簇以及低复杂度簇首评价函数保证节点可以分布式完成评价值计算,无需处理大量广播消息.
3)数据传输阶段,为了避免出现多跳中继比单跳直发能耗高的现象,对外簇首间中继转发策略的距离适用条件进行分析.为了避免节点提前过载,将能量消耗速率作为选择中继节点的依据.此外,令距离基站比距离内簇首更近的簇成员直接将感测数据发送给基站,以提高基站周围节点的能量利用效率.
1 系统模型与设定
1.1 网络模型
本文设定的WSNs分簇路由网络模型如图1所示,感测区域内的节点被划分成簇,簇内有选举出的内、外两簇首,感测数据通过节点间的转发到达基站.同时考虑网络模型中涉及的约束为以下几点:
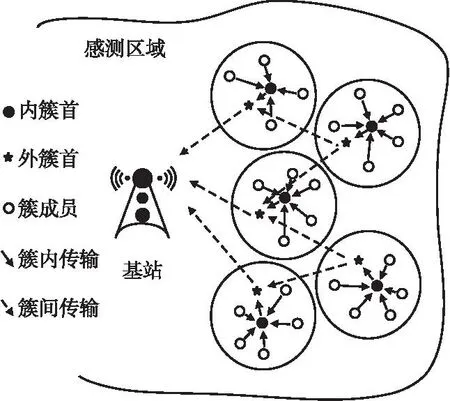
图1 WSNs分簇路由网络模型Fig.1 Network model for WSNs clustering routing
1)N个节点在面积为M×M的感测区域内随机静态分布,基站位置处于区域中心且资源不设限.
2)所有节点同构,初始能量相同,且具有专属的编号.
3)每个节点都可独立地运作以进行分布式处理,运行期间不发生故障.
4)节点可以通过计算得到自身的相对位置[8],并且通信功率可调.
5)周期性执行时间驱动的数据采集,一次完整的数据采集过程记为一轮,网络中首个节点能量用尽的轮次定义为网络的生命周期[9].
1.2 能量模型
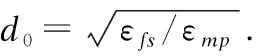
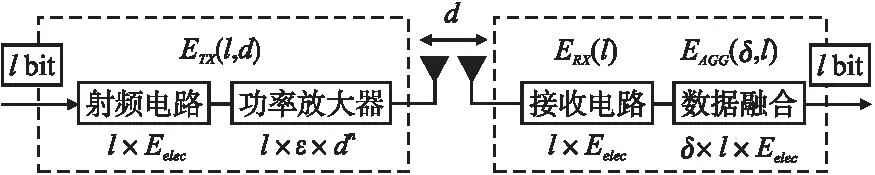
图2 无线通信模型Fig.2 Wireless communication model
(1)
节点接收lbit数据和将δ个lbit的数据包融合为一个消耗的能量分别为:
ERX(l)=lEelec
(2)
EAGG(δ,l)=δlEda
(3)
其中,Eelec为设备运行能耗系数,Eda为节点融合1 bit数据所需能耗.
本文仿真实验中设定能耗模型参数如表1所示.

表1 能耗模型参数Table 1 Parameters of the energy consumption model
2 DRCR
本文提出的DRCR算法将时间离散为轮,网络工作轮次决定网络寿命.如图3所示在算法运行的第1轮,基站将收集所有节点信息进行集中式成簇,在之后的轮次中只有当网络中的存活节点数改变导致最优成簇规模改变时才会重新成簇;每轮数据传输前都会分布式动态更新簇首,簇首选举前的状态广播可以让节点获取并存储所属簇内节点的状态信息[11].本节将对DRCR中簇的形成、簇首选举和数据传输的具体实现细节进行阐述.
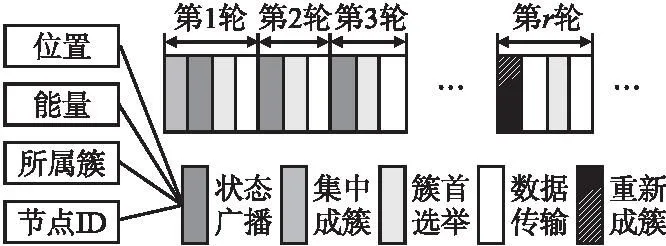
图3 DRCR按轮工作流程Fig.3 DRCR round-by-round workflow
2.1 集中成簇
网络初始化完成后,首先通过分析成簇规模与网络能耗之间的对应关系,设置最优成簇规模以最小化网络总能耗.成簇初始阶段,节点将自身的实时状态信息编码进控制信息广播数据包发送给基站,基站接收所有节点的数据包后按照约定的格式解码,然后利用基站强大的处理能力集中运行下述成簇步骤.成簇时,将AOA个体编码为聚类中心组合,并基于最优成簇规模使用最大最小距离积方法改进AOA的种群初始化,然后AOA以FCM算法的目标函数作为适应度函数计算聚类分析前的初始聚类中心,再将其带入FCM算法进行集中式成簇,最终将整个网络划分为C个簇.基站计算完成后,将成簇结果在整个感测区域内广播.以上成簇过程不需要每轮都重新计算,只在最优簇数发生改变时才重新成簇,可以避免频繁成簇的广播能耗.同时,在簇首选举前先成簇,可以使得簇首选举只在簇内分布式进行,避免了簇首随机分布有时会过于集中、簇成员与簇首距离较大的问题.
2.1.1 最优成簇规模
为给FCM算法指定聚类数目,本小节利用簇数与网络能耗之间的对应关系,以最小化网络总能耗为目标来设置最优成簇规模,可以得到更加合理的分簇以改善簇数过多导致的分簇效率及簇首利用率较低、控制信息广播泛滥问题和簇数过少导致的簇首负载增大问题[7].设定的网络模型中,N个节点在面积为M×M的感测区域内被均匀地划分为个C簇,则每个簇内约有N/C个节点,包括2个簇首节点和N/C-2个簇成员节点.假设基站处于感测区域的中心,在分簇和簇首选举合理的情况下,外簇首到下一跳外簇首(或基站)距离dON、节点到内簇首距离dtoICH、内外簇首之间的距离dIOCH均小于d0.
在本文的网络和能耗模型中,节点将感测数据发送给内簇首,内簇首接收簇成员数据并融合后将其转发给外簇首,外簇首接收内簇首传来的数据、接收TR组中继数据后与自身感测数据融合并继续中继转发至基站.那么内簇首、外簇首、簇成员节点每轮的能耗分别约为[12,13]:
(4)
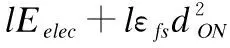
(5)
(6)
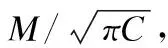
(7)
由文献[14]可知对于半径为R的圆内任意两点间距离r的概率密度函数为:
(8)
从而数学期望(r的均值)为:
(9)
则dIOCH的期望值可以按照式(10)计算:
(10)
所以网络运行一轮,单个簇所需能耗ECluster和整个网络所需能耗ETotal=CECluster分别为:
(11)
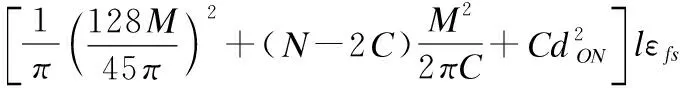
(12)
令ETotal对C求偏导为0,可以求得最优成簇规模为:
(13)
2.1.2 模糊C均值算法
FCM算法是一种软聚类算法[15],通过优化目标函数来获得所有节点对每个聚类中心的隶属度矩阵,再根据隶属度值对节点进行聚类.FCM算法对于嘈杂环境中的非确定信号参数具有稳定性,因此适用于为WSNs聚类[5].在本文网络模型中,记被随机部署在感测区域内的N节点集合为X={x1,x2,…,xN},FCM就用以这N个节点的地理位置信息作为数据集进行聚类分析,将其划分为C个簇(2≤C≤N),记V={v1,v2,…,vC}为C个簇的聚类中心集合,根据节点位置聚类可以减少簇成员的簇内通信距离.
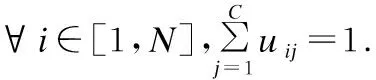
(14)
m为控制成簇模糊重叠程度的指数,m越高最终成簇结果越模糊.U=uij,i=1,…,N,j=1,…,C(uij∈[0,1])为隶属度矩阵.FCM聚类分析过程中的步骤如下:
1)确定C、m的值,初始化隶属度矩阵U.
2)计算聚类中心集合V:
(15)
3)更新隶属度矩阵U:
(16)
4)根据式(14)计算目标函数值Jm(U,V).
5)重复步骤2~步骤4,直到连续两次迭代之间的目标函数值改进小于给定的最小阈值或达到最大迭代次数.
当迭代停止时,可以得到使Jm(U,V)取到最小值的隶属度矩阵U和聚类中心集合V.本文中FCM算法的参数设置如表2所示.

表2 FCM算法的参数设置Table 2 Parameter setting of FCM algorithm
2.1.3 算术优化算法
AOA是由Laith Abualigah等人于2021年提出的元启发式搜索算法[16],该算法模拟加减乘除4种基本算术运算的分布特征进行模型优化,具有收敛快、复杂度低等特性,已被用于解决一些现实世界的优化问题.本文中AOA的参数设置如表3所示.
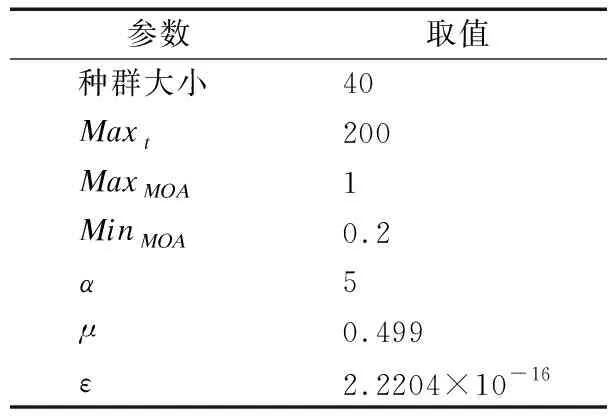
表3 AOA的参数设置Table 3 Parameter setting of AOA
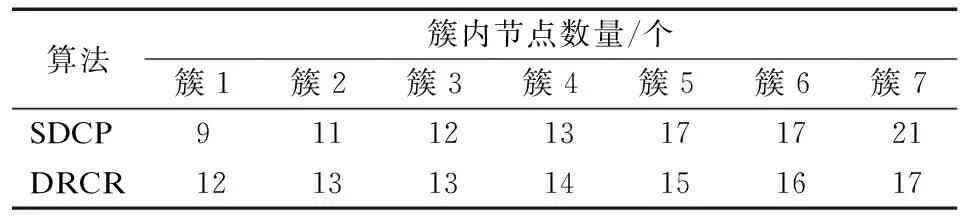
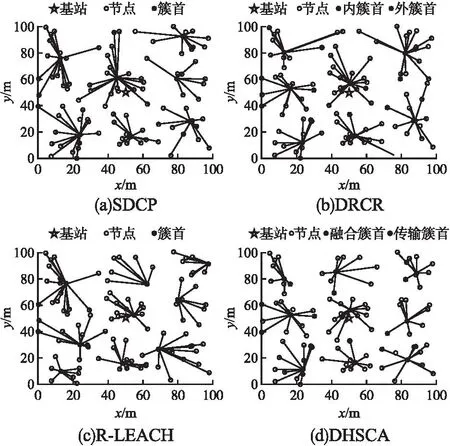
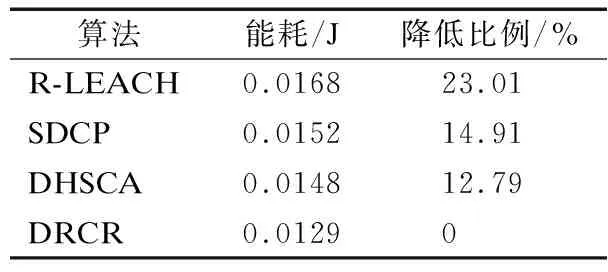
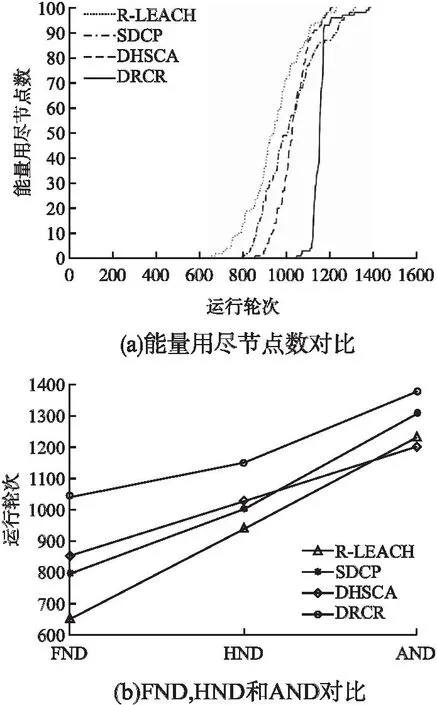
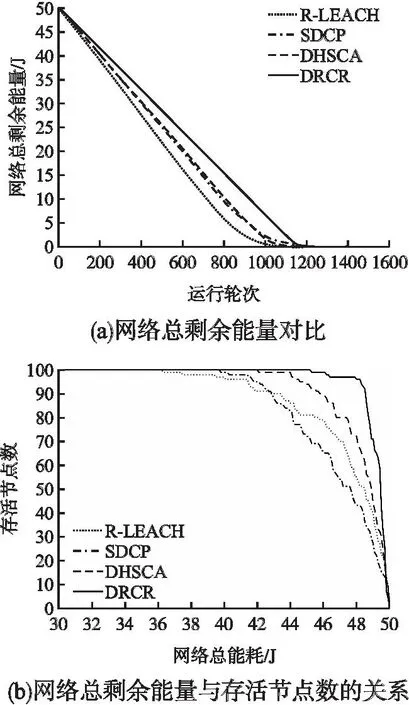
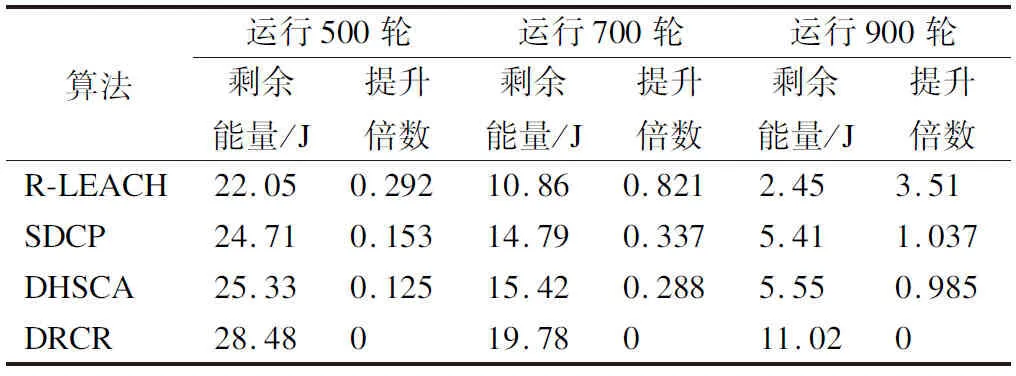
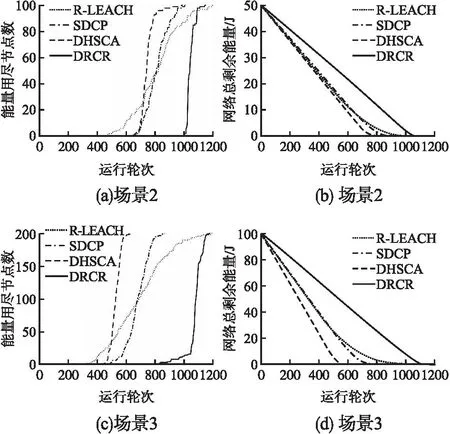
设r1、r2、r3为值域[0,1]上均匀分布的随机数,如式(17)所示,该算法定义了加速系数MOA,在每轮迭代过程中,当MOA (17) 全局探索阶段,利用除法和乘法运算符的高分布决策值进行探索,提高解的分散性,实现全局寻优.在此阶段,当r2<0.5时执行除法搜索策略,当r2≥0.5时执行乘法搜索策略,搜索代理i在第j维的位置更新公式如式(18)所示: τj=((UBj-LBj)×μ+LBj) (18) (19) (20) 其中,α是一个敏感参数,定义了迭代过程中的开发精度. 局部开发阶段,利用减法和加法运算符的高密度决策值进行开发,在密集区进行深入探索以实现局部寻优.在此阶段,当r3<0.5时执行减法搜索策略,当r3≥0.5时执行加法搜索策略,搜索代理i在第j维的位置更新公式如式(21)所示: (21) 2.1.4 改进AOA优化FCM算法成簇 FCM算法的聚类分析过程简单、收敛快,但传统的FCM算法会对隶属度矩阵U进行随机初始化,导致计算得到的初始聚类中心也是随机的,存在容易陷入局部极小值和对初始化敏感的缺点[17].为了提高聚类准确率和鲁棒性,本文引入智能寻优算法AOA来优化初始聚类中心,同时使用最大最小距离积方法改进AOA种群初始化.此问题可以描述为:基于最优成簇规模使用改进的AOA在感测区域这整个解空间内寻找最优的C个初始聚类中心组合,使得FCM算法基于优化的初始聚类中心进行成簇可以避免陷入局部最优并得出最优聚类结果,AOA中的每个搜索代理表示一个潜在的最优初始聚类中心集合,FCM算法最终输出的每个聚类代表一个簇. 下面对利用最大最小距离积方法改进种群初始化的AOA优化FCM算法成簇的关键环节进行详细阐述: 1)编码:使用基于聚类中心的地理位置信息格式对AOA中的搜索代理进行编码.由于共有C个初始聚类中心,每个聚类中心有D维的参数,则每个搜索代理的位置可以用一个C×D的矩阵表示: (22) 本文中每个节点维度D=2,即感测区域为二维平面.矩阵中的值Posij∈[LBj,UBj],表示第i个聚类中心在第j维的值.对AOA种群中的每个个体的位置矩阵解码可以得到一个合法的聚类中心集合. 2)种群初始化:如果初始化种群时随机设定每个个体的位置矩阵,会使得其距离最优聚类中心集合有较大的差距,而且会导致AOA的收敛速度较慢,因此将AOA种群按个体数量2∶1的比例分为2个子群,对第1个子群中的个体依然采用在感测区域上随机初始化以保证种群的多样性;对第2个子群中的个体按照最大最小距离积方法初始化[18],用一些局部密度较大并且相距较远的点组成初始集W来初始化个体位置矩阵,使其尽可能代表解空间的分布特性,具体步骤如下: 1.随机初始化节点集X={x1,x2,…,xN},设初始集W=Ø. 2.从节点集X中随机选取点w1作为初始点,同时令W=W+{w1},X=X-{w1}. 3.计算X中所有点与w1的距离Dxw(j,1)=‖xj-w1‖,其中j=1,…,N-1,令j*=argmax(Dxw(j,1)),w2=xj*,则w2为W中与w1距离最大的节点. 4.将该点加入初始集W并从节点集X中删除. 5.计算X中每个点xj到W中各个点的距离Dxw(j,i),其中i=1,…,C*,j=1,…,N-C*.C*表示初始集W当前的元素个数. 6.对于每个点xj记录maxv(j)=max(Dxw(j,i)),i=1,…,C*和minv(j)=min(Dxw(j,i)),i=1,…,C*.然后计算Vx(j)=maxv(j)×minv(j),表示xj与W中所有节点的最大距离和最小距离乘积,令j*=argmax(Vx(j)),wC*+1=xj*,则xj*为X中令Vw(j)取得最大值的点. 7.若C* 8.得到具有C个节点的初始集W. 3)适应度函数的确定:本文用改进AOA来优化初始聚类中心,是为了将节点更合理的划分成簇.而FCM算法中聚类结果越好时目标函数值Jm(U,V)越小,所以适应度函数的值应为Jm(U,V),即fitnessAOA=Jm(U,V).本文中的适应度函数将AOA种群中个体的位置矩阵解码为C个初始聚类中心集合V,把其带入公式(16)得出隶属度矩阵U,最后将U和V带入公式(14)求出目标函数值作为适应度值来更新最优搜索代理位置. 4)解码:将表示AOA种群中个体位置的C×D矩阵(矩阵中的每一行对应一个D维的聚类中心)解码为C个初始聚类中心集合V={v1,v2,…,vC}. 综上所述,利用最大最小距离积方法改进种群初始化的AOA优化FCM算法的具体步骤如下: 1.设置AOA和FCM算法各参数,结合最大最小距离积法初始化AOA种群. 2.将AOA种群中个体的位置矩阵解码为C个初始聚类中心集合V. 3.根据式(16)计算该聚类中心集合对应的隶属度矩阵U. 4.将步骤2中的聚类中心集合和步骤3中的隶属度矩阵带入式(14)得到对应的目标函数值Jm(U,V),并将其作为AOA种群中当前个体的适应度值. 5.重复步骤2~步骤4,直到遍历完AOA种群中所有个体,并记录最优解. 6.根据式(17)和式(20),更新AOA加速系数MOA和概率系数MOP. 7.根据式(19)和式(21),更新AOA种群的搜索空间. 8.判断是否达到AOA最大迭代次数,如果没有达到则返回步骤2,如果达到则执行步骤9. 9.解码AOA迭代的最优解来代替FCM算法随机设置的初始聚类中心. 10.执行FCM算法得到使Jm(U,V)取到最小值的隶属度矩阵U和聚类中心集合V. 考虑到内外簇首的能耗普遍高于成员节点,需要综合评估节点的能量、距离和节点的中心度等影响因子设计分布式动态双簇首选择机制进行簇首轮换.在第2.1节成簇划分的基础上,该机制根据当前轮次簇内节点状态信息,以不同簇首评价函数选举负责簇内数据收集、融合的内簇首和负责簇间传输的外簇首,使簇内通信距离得到降低、负载更加均衡.不同于基站收集所有节点信息进行统一处理后任命簇首,由节点在本地分布式竞争簇首可以避免处理大量控制数据包的能耗. 由第2.1.1节中对节点每轮能耗分析可知,内簇首的工作任务是接收簇成员的感测数据并融合然后转发给外簇首,外簇首的工作任务是接收内簇首传来的数据、接受其它外簇首的中继数据以及将数据融合后中继转发至基站,内外簇首的主要能耗由其工作任务决定.显然,不论内外簇首,均需要剩余能量较高的节点担任. (23) (24) (25) (26) (27) (28) 在内外簇首评价函数中加入各影响因子的均值,是为了使得各因子的整体权重大致相当.下面对α1、β1、α2、β2的取值进行自适应设计.在网络运行的前期,节点的能量充足,此时剩余能量因子的权重应该较小.节点的能量随着通信轮次的增加而减少,若剩余能量小的节点被选为簇首,则会降低网络的能源利用效率,此时应增加剩余能量因子的权重.经过实验验证,可以让剩余能量因子的权值随着能量的减小从0.4线性增长至0.6,具体计算方法如式(29)所示: (29) 其中,Einit为节点的初始能量,则β1、β2的值从0.6下降至0.4. 相较于文献[19]中使用元启发式算法选举簇首或者文献[5]中使用模糊逻辑选举簇首的方式,本文中簇首评价函数复杂度低而且节点事先成簇,节点可以用微量的运算开销在本地直接计算簇内所有节点的内外簇首评价值,评价值大的节点直接当选为对应的内外簇首.而且本文这种处理方式相较于文献[11]中节点需要与邻节点频繁交流决策值依次进行竞争当选簇首的方式,减少了选举簇首时需要广播和接收的大量消息.接下来,内外簇首广播当选成功的控制信息包.外簇首广播范围覆盖3倍簇半径以使得周围其余外簇首节点能够接收到.内簇首广播范围覆盖本簇并为簇成员节点安排簇内通信的TDMA(Time Division Multiple Access)调度,簇内成员节点根据广播消息中的簇编号匹配入簇,簇内成员节点按照内簇首划分的TDMA时隙,在自己的时间槽内将感测数据单跳发送给内簇首. 本文中的簇内通信采用单跳直发的方式,簇间通信则在文献[4]和文献[7]中关于单簇首模型研究的基础上,针对双簇首多跳模型进行分析:首先计算了外簇首间中继转发策略的距离适用条件,避免出现多跳中继比单跳直发能耗高的现象;在满足上诉距离条件的基础上给出外簇首分布式选择中继节点的依据,即能量消耗速率,来避免出现外簇首过载的现象.除此之外,为了减轻基站附近簇首的能耗负担,使其可以将更多的能量用于中继数据转发,簇成员如果距离基站比距离内簇首更近则将感测数据直接发送给基站,否则仍然传输给内簇首. 2.3.1 簇间多跳策略的距离适用条件 在较大规模的网络模型中,与基站距离较远的外簇首与基站通信时将使用多径衰落模型通信,产生高额能耗.然而盲目采用多跳通信,而不考虑转发过程带来的成本,有可能会导致多跳策略能耗高于单跳的情况.针对这一问题,对外簇首采用多跳中继和直接与基站通信的能耗进行分析,进而讨论簇间多跳策略的适用条件. 对于分簇路由协议而言,中继多跳路由仅与簇间通信有关,与簇内通信无关,所以在分析多跳中继策略时仅针对外簇首进行分析,而且仅考虑节点在传输数据时的能耗.由对外簇首在第2.1.1节的分析可知,外簇首的能耗分为接收能耗、融合能耗、转发能耗3个部分. 以某一外簇首向基站传输lbit数据为例,设外簇首直接向基站通信的能耗为ENon_Relay、外簇首通过下一跳中继转发的总能耗为ERelay(包括当前外簇首向下一跳外簇首的发送能耗和下一跳外簇首的接收、融合能耗),而中继策略对能耗产生的主要影响可以表示为上述两者的差值ENon_Relay-ERelay.设dBS和dR分别表示外簇首与基站距离、外簇首到下一跳外簇首距离,则dBS和dR的大小有式(30)中所示的4种情况: (30) 则ENon_Relay-ERelay的值也对应4种不同的情况: (31) 显然,当ENon_Relay-ERelay>0时说明本次传输通过其余外簇首多跳转发可以使能耗被减少,对此不等式求解得出对应情况下dR的取值即为簇间多跳策略的适用条件.需要注意,对于第2种情况,即当dBS≤d0,dR>d0时: (32) 可见,该式大于0时无解,说明此情况下不适合使用多跳.其余3种情况下解出的dR的取值如式(33)所示: (33) 在上述距离条件下通过其余外簇首多跳转发,不仅可以降低簇间通信能耗,还可以将能耗分摊在外簇首之间. 2.3.2 中继节点选择 采用MATLAB R2017a平台对本文设计的算法DRCR进行仿真实验,以评估其有效性.本节将在3个网络模型场景中,根据成簇结果、簇内节点数量、平均簇首能耗、网络生命周期、能量效率等不同性能评价指标分析DRCR与文献[3]中的R-LEACH、文献[5]中的SDCP和文献[6]中的DHSCA 3种对比算法的性能差异,并讨论导致性能差异的原因.由于R-LEACH作为对经典分簇路由协议LEACH的改进,显著提升了LEACH的性能,所以考虑与其对比;SDCP使用原始的FCM算法成簇,为验证本文使用改进AOA优化FCM算法成簇的效果,考虑与其对比;DHSCA针对分簇路由的各个阶段进行了完整的优化设计,是一种高效的双簇首静态分簇算法,所以考虑与其对比. 3.1.1 网络模型设置 如表4所示,本文设置了3组不同的网络模型场景.其中,场景1与场景2的区域面积和基站位置不同,记为对照组1;场景2与场景3的节点密度不同,记为对照组2. 表4 网络模型参数Table 4 Parameters of the network model 3.1.2 最优成簇规模确定 由式(13)可知,最优成簇规模与dON和TR的取值有关.根据3个场景的参数设定可知,在场景1、2、3中dON取值范围分别为0~71、0~141与0~141m.假设TR取值范围为1~5次,基于式(13)可计算出3种场景下的最优成簇规模C的取值范围分别为3~13、4~19与6~25个.如图4所示,通过在上述区间内对C的取值进行尝试,统计3种场景中首个节点能量用尽前平均每轮的总能耗值,可以得出3种场景下的最优成簇规模分别为7、10与12.从图4中还可以看出,成簇数量较少导致簇首承担任务过重、成簇数量较多导致簇间通信增多,都会增加每轮的能耗. 图4 成簇规模对能耗的影响Fig.4 Effect of the number of clusters on energy consumption 以场景1为例,随机初始化AOA个体位置的结果如图5(a)所示,使用最大最小距离积方法初始化个体位置的结果如图5(b)所示,可以看出使用最大最小距离积方法能够使得个体初始位置更合理,以提高迭代寻优过程的效率和解的精度. 图5 AOA个体的不同初始化方式Fig.5 Different initialization methods for AOA individuals 如图6所示,图6(a)和图6(b)分别为使用SDCP中的原始FCM算法单簇首成簇方式和DRCR中的改进AOA优化FCM算法双簇首成簇方式在场景1中运行至第200轮时的成簇结果,对比两者发现,图6(b)中成簇结果在簇分布和簇规模方面都更合理.此外,图6(b)中的内簇首处于接近簇质心的位置、外簇首处于更靠近基站的位置,这是因为图6中的成簇轮次较小、网络剩余能量较多,节点能量对簇首评价值影响较小,所以簇首选举结果符合两者工作特性和预期要求.如表5所示,统计上述两种成簇结果中每个簇的节点数量,结合图6(a)和图6(b)可以发现DRCR的成簇结果更均匀,簇内节点数目更稳定,有效地优化了原始FCM聚类的准确性,更有利于实现簇首负担的均衡. 表5 簇内节点数量对比Table 5 Comparison of the number of nodes in the cluster 图6 成簇结果对比Fig.6 Comparison of clustering results 图6(c)和图6(d)分别是R-LEACH和DHSCA在场景1中运行至200轮时的成簇结果.从图6(c)中可以看出,由于R-LEACH没有优化成簇设计,导致簇首位置不合理、成簇结果不均匀.从图6(d)中可以看出DHSCA成簇结果较合理,但是其成簇基于静态网格划分,按照节点数的10%来确定分区个数,此个数并不一定是使网络通信能耗降低的最优解,并且DHSCA不能根据节点分布特性动态成簇,导致当节点死亡或网络拓扑发生改变时有可能出现孤立节点现象,而DRCR基于最优成簇规模的动态成簇可以有效避免上述问题. 表6为4种算法的簇首在前500轮中平均每轮的能耗.其中DRCR内外簇首平均每轮的能耗是最低的,并且相较于R-LEACH、SDCP和DHSCA分别降低了23.01%、14.91%和12.79%.综上所述,DRCR中的成簇方式可以显著优化成簇效果;为簇首选举设置的簇首评价函数符合内外簇首的工作特性,保证了选出的簇首能量、位置和中心性更合理,从而有较小的工作能耗;基站集中成簇、节点间分布式簇首选举的策略可以进一步降低决策成本、均衡簇首负载. 表6 簇首能耗对比Table 6 Comparison of energy consumption of cluster heads 定义FND表示首个节点能量用尽轮次、HND表示半数节点能量用尽轮次、AND表示全部节点能量用尽轮次,并使用这3个指标来衡量网络的工作时间[20].网络在首个节点能量耗尽后,会出现对感测区域的覆盖空洞,使得感测数据有效性降低.因此将FND作为网络生命周期标准,在此标准下需要让流量均匀分配,使数据在所有路径上均匀地传输,从而避免因部分节点负载过高导致的网络寿命缩短[9]. 在场景1中,本文算法DRCR和对比算法的能量用尽节点数与网络运行轮次的关系如图7(a)所示.可以发现,4种算法的能量用尽节点数都随着网络的运行而增加,但是DRCR的首个能量用尽节点出现轮次最晚,R-LEACH、SDCP、DHSCA和DRCR的FND分别为647、793、852和1045,DRCR相较于前三者将网络生命周期分别延长了61.51%、31.78%与22.65%.此外,在第1045轮DRCR中首个节点能量用尽时,R-LEACH、SDCP和DHSCA已经分别有79、64和61个节点能量耗尽,这已经超过了三者对应的HND,充分表明DRCR能够对感测区域进行更持久的有效感测. 图7 网络生命周期对比Fig.7 Comparison of the network life cycle 如图7(b)所示,对4种算法的3种工作时间指标FND、HND和AND进行对比,其中R-LEACH、SDCP、DHSCA和DRCR的AND分别为1228、1309、1202和1378,DRCR比前三者分别延长了12.21%、5.27%与14.55%.相较于DRCR对FND的延长比例,DRCR对AND的延长比例并不高,这是因为AND的值要结合FND的值一起观察,单独考虑AND的值没有意义,因为在出现能量耗尽的节点之后会出现网络覆盖空洞.值得注意的是,算法的FND值越大并且FND与AND差值越小,说明在首个节点能量耗尽后其余节点的剩余能量也无法支撑过多的轮次,从而证明节点能量得到了更均匀的利用,此情况对应图7(a)的曲线也应越陡峭[6].计算R-LEACH、SDCP、DHSCA和DRCR的FND与AND差值分别为581、516、350和333,结合FND和图7(a)中的曲线斜率,可以得知DRCR能够在延长网络生命周期的同时实现更均衡的节点能量消耗,这是因为DRCR基于最优成簇规模使用改进AOA优化FCM算法成簇可以均衡簇内能耗,而双簇首和自适应多跳路由策略可以均衡簇间能耗,从而避免了节点提前过载.DHSCA由于合理的双簇首轮转策略也有较好的能量均衡效果,但是其将传输簇首的下一跳限定在自身所在列,导致了不必要的传输能耗,缩短了网络寿命.R-LEACH和SDCP由于没有多跳路由设计,导致传输能耗高、能耗均衡效果较差. 图8(a)为在场景1中,DRCR和对比算法的网络总剩余能量与网络运行轮次的关系.由图8(a)可知,4种算法的网络总剩余能量都随着网络运行轮次的增大而降低,但是DRCR的网络总剩余能量在相同轮次下相较于对比算法更高,即DRCR每轮消耗能量最少.从图8(a)中还可以得到一个值得注意的信息:SDCP的网络总剩余能量在第913轮之前比DHSCA低,但是在第913轮之后比DHSCA高,甚至在第1155轮~第1233轮比DRCR还要高,这是由于SDCP成簇效果较差、没有优化传输路径导致部分节点提前过载造成的,不利于对目标区域的长时间有效感测. 图8 能量效率对比Fig.8 Comparison of energy efficiency 如表7所示,统计在网络运行至第500、700和900轮时,R-LEACH、SDCP、DHSCA和DRCR的网络总剩余能量,以及DRCR相较于前三者的提升倍数.可以看出,随着网络的运行,DRCR的网络总剩余能量相较于对比算法的提升越来越大.在第900轮时,DRCR的网络总剩余能量甚至比R-LEACH提升了3.5倍,几乎比SDCP和DHSCA提升了1倍. 表7 网络总剩余能量统计Table 7 Total remaining network energy statistics 由此可以得知,DRCR相较于对比算法具有最高的能量利用效率,这是因为:DRCR的优化集中成簇方式缩短了簇内、簇间的通信距离,降低了数据传输成本;分布式动态簇首选举进一步降低了决策成本;簇间中继基于能量最小化条件,避免了数据回传以及多跳能耗高于单跳的情况. 如图8(b)所示,统计随着网络总能耗值的增长网络中剩余的存活节点个数.可以看出,场景1中网络初始总能量为50J,DRCR在出现首个能量耗尽节点时,网络总能耗已经达到45.3J,而R-LEACH、SDCP和DHSCA分别在网络总能耗达到36.3J、39.8J和42.1J时出现首个能量耗尽节点,进一步证明了DRCR有较高的能量效率.此外,当网络消耗了45.2J的能量后,4种算法的存活节点数量分别为81个、71个、93个与100个,可知当网络总能量即将耗尽时,DRCR仍可保持更多的存活节点数,保证了感测能力的稳定性,与第4.3节中关于DRCR可以延长网络生命周期和具有较好的能耗均衡效果的结论相符. 为验证本文算法DRCR的性能稳定性,本小节进一步地在场景2和场景3中进行对比实验,得到图9. 图9 不同场景下的性能对比Fig.9 Comparison of performance in different scenarios 结合图7(a)、图8(b)与图9(a)、图9(b)考察对照组1发现,当感测区域面积增大而节点数量不变时,由于节点间传输距离的增加,4种算法在场景2中的能量消耗速率都比在场景1中更快、网络生命周期也更短.结合图9(a)、图9(b)与图9(c)、图9(d)考察对照组2发现,当感测区域面积不变而节点数量增多时,由于需要传输数据包数量的增加,4种算法在场景3中的能量消耗速率都比在场景2中更快、网络生命周期也更短.但是在不同场景中DRCR相较于R-LEACH、SDCP和DHSCA仍有更好的能量利用效率以及更长的网络生命周期.这得益于DRCR的最优成簇规模可以根据不同的网络参数以能量最小化为依据进行确定,从而优化了对应场景下的成簇效果,并且DRCR的自适应中继策略在通信距离改变时,仍然可以根据簇间多跳策略的距离适用条件选择对应距离下的能耗最低路径,所以DRCR拥有较好的鲁棒性. 时间复杂度是体现算法运行效率的重要指标,为探索以及验证DRCR的时间代价,对于节点数为N、最优成簇规模为C的网络,将算法按照流程进行如下分析:1)种群规模为S、迭代次数为IT1的AOA:种群初始化中最大最小距离方法的时间复杂度为Ο(SNC2),更新适应度的时间复杂度为Ο(SNC),更新种群位置的复杂度为Ο(SC);对于迭代次数为IT2的FCM算法,时间复杂度Ο(IT2NC2)[21].所以集中成簇的复杂度为:Ο(IT1SNC+IT2NC2).2)记单个簇中平均存活节点数为K,分布式动态双簇首选举的时间复杂度为Ο(K2).3)自适应中继数据传输的时间复杂度为Ο(C).所以,DRCR在需要成簇的轮次里时间复杂度为Ο(IT1SNC),在大部分不需要成簇的轮次里时间复杂度为Ο(K2+C)=Ο(K2).需要注意,集中成簇是由基站收集数据集中处理再将结果广播给节点,此部分复杂度由基站承担.而分布式动态双簇首选举、自适应中继数据传输由节点分布式完成,且其复杂度较低,显著节省了计算时间. 对比算法R-LEACH和DHSCA的时间复杂度均为Ο(N2)[6,7],与之相比,DRCR的时间复杂度在需要成簇的轮次里稍显劣势,在其余大部分轮次里存在优势,并且DRCR的性能得到了明显提升.对比算法SDCP在成簇阶段时间复杂度为Ο(IT2NC2),在簇首选举阶段时间复杂度为模糊逻辑系统运行复杂度[5],与之相比,DRCR时间复杂度在簇首选举时存在优势、在需要成簇的轮次复杂度相当.综上所述,DRCR在性能得到优化的同时,没有显著增大算法的时间复杂度. 为了提升节点能量利用效率并延长网络生命周期,本文提出了一种优化聚类分簇结合自适应中继策略的双簇首WSNs路由算法DRCR,针对成簇结构、簇首选取和通信路径选择分别进行优化设计.DRCR使用改进种群初始化的AOA优化FCM成簇的方法保证了簇分布的均匀性;基于节点位置、能量和中心性动态选举出的双簇首符合其工作特性,在最大化节点能量利用效率的同时显著平衡了节点间的负载,并且分布式选举方式降低了决策成本;自适应中继策略优化了数据传输路径,使得首个节点能量用尽的轮次被推迟,实现了对目标区域更持久有效的监测.由于DRCR中的成簇规模是在不同网络参数下以节点总能耗最小化为目标设定的最优值,并且DRCR可以根据通信距离以及节点能量消耗速率自适应地选择能耗最低的传输策略,使得DRCR面对不同网络场景拥有较好的鲁棒性. 经实验验证,在不同感测区域面积和节点密度的网络场景中,DRCR相较于对比算法R-LEACH、SDCP和DHSCA更有效地均衡了节点能耗、提升了能量利用效率并延长了网络生命周期.由于未考虑到传输链路的端到端丢包率和延时问题,因此今后工作将围绕满足WSNs中的路由服务质量展开.
2.2 分布式动态双簇首选举
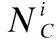
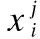
2.3 自适应中继数据传输
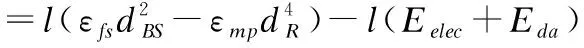
3 仿真测试与分析
3.1 实验参数设定
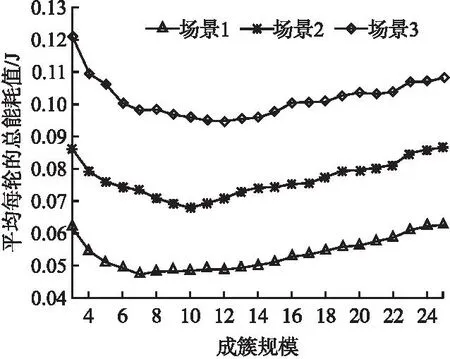
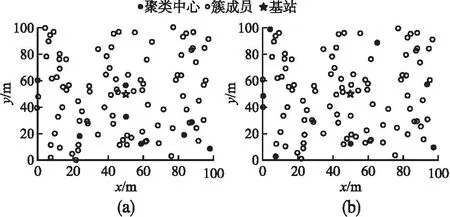
3.2 成簇结果和簇首选举的优化效果
3.3 网络生命周期
3.4 能量效率
3.5 不同场景下的比较
3.6 时间复杂度分析
4 结束语
