基于深度学习的唐卡边缘检测技术研究
2024-04-19于翔宇樊瑶
于翔宇 樊瑶
西藏民族大学信息工程学院,咸阳 712082
唐卡是一种传统的藏族绘画艺术,具有深刻的宗教、文化和艺术意义。它用于传达佛教和印度教的宗教教义,装饰寺庙,祈祷和保护信徒,同时代代传承藏族文化和艺术传统。这些作品不仅在视觉上传达了宗教故事,还是藏族社会中的重要文化遗产,具有出色的绘画和色彩技巧。但是唐卡作品通常绘制在布料或纸上,使用天然颜料,这些材料随着时间的推移会受到风化和退色的影响。此外,唐卡通常会在寺庙或家庭中悬挂,因为经常接触光线、尘土和湿气等环境因素,也可能导致其褪色和腐蚀。为了维护宗教、文化和艺术遗产的完整性,应该加强对唐卡的数字化保护。
数字化唐卡可以保存每件作品的详细信息,同时可以通过互联网和数字媒体进行虚拟展览,向全国观众传播。此外,数字化备份可以确保其文化和宗教价值的长期保存。现有的深度学习模型更是可以对唐卡图片进行相关的图像处理,比如边缘检测有助于分析唐卡的绘画技巧和线条,可以更好地理解唐卡的构图和绘画风格,这对于研究和鉴定唐卡的制作者和时代很有帮助。而图像修复则能够修复一些受损的唐卡图像,使它们恢复原貌。这样既可以避免唐卡的二次损害,又能进一步为非物质文化遗产保护与传承提供帮助。
边缘检测是图像处理中的基础任务,它提供了有关图像中结构和信息的重要线索,有助于使图像数据更容易分析和理解,为各种领域的图像处理任务提供基础,同时对于许多计算机视觉应用和研究都具有关键意义。
早年传统的边缘检测[1]方法一般以图像的梯度信息(如一阶和二阶梯度)为原理来进行计算和工作,如:Canny 算子、Prewitt 算子以及Sobel 算子等。但是它们存在着很多问题,如噪声敏感、边缘的不连续、参数选择困难、非旋转不变性、不适应复杂背景等等。
近年由于深度学习的兴起,边缘检测方法也得到了进化。自适应特征学习、高鲁棒性、高精度等优点使得深度学习模型能够处理更加复杂的图像,提取到更加细致的边缘。比起传统方法,基于深度学习的网络模型在图像的边缘检测方面取得了更好的效果,也成为未来发展的一大趋势。
2015 年,Xie 等提出了HED 框架,它是一种整体嵌套边缘检测框架,采用端到端的网络架构,解决了传统方法的缺陷。2021 年,Su 等[2]为了进一步解决现有方法存在的缺陷,采用像素差分卷积的方式将传统的Canny 算子与卷积神经网络相结合,提出了PidiNet 模型。这段时间内,研究者们进行了不断的探索,出现了不少如CED、RDS[3]和DSCD[4]等 不 错 的 模 型。2017 年,Liu 等首先利用对象多尺度和多级信息,对标注进行处理,构成RCF 模型。2021 年,Xuan等[5]提出了FCL-Net 模型,增强了多尺度模型对细小目标的识别率。但是多尺度方法仍然存在缺陷,为了弥补它的不足,一些研究者[6-14]开始对侧面特征提取模块进行探索和创新。2019 年,He 等[15]提出了一种新的单向模型——双向级联网络结构(BDCN)。2018 年,Deng 等[16]发现使用深度卷积神经网络进行边缘检测时,有时会导致产生边缘较粗或模糊的边缘图。这是因为深度学习模型可能倾向于生成某种程度的边界模糊或平滑化的输出。Kelm 等[17]结合ResNet 和RefineNet[18]语义分割方法,提出RCN 算法。2020 年,Soria 等[19]基于Xception[20]和HED 模型,提出了DexiNet 方法。他们对BIPED 数据集进行了标注预处理,并引用引入上采样模块进行进一步优化,使得不同尺度的输出层能够产生精细边缘。从研究者们进行的实验和尝试来看,多尺度模型依旧是效果最佳、拓展性最强的模型,在未来仍是热门研究方向。
为了避免梯度消失,获取更多特征信息,得到更加清晰的边缘图像,本文提出了DMSCNN(Deep Multi-scale Convolutional neural network)网络模型。比起一般的多尺度模型,它通过构建更深层的网络结构,能够提取更多的特征信息。同时引入全局注意力模块,使神经网络能够在处理输入数据时将局部信息与全局信息相结合,从而提高模型的性能。最后,将不同尺度的特征信息进行融合,得到边缘特征更加高效、特征信息更加明显的边缘图像。实验证明该模型比起传统的Canny 算子和RCF 模型能够得到更加清晰的唐卡边缘图像。
1 边缘检测方法
1.1 Canny算子
Canny 算子是一种经典的边缘检测算法,它的主要目标是识别图像中的边缘,通常用于计算机视觉和图像处理任务。Canny算子的主要步骤包括:
(1)高斯滤波:图像会经过高斯滤波,以减少噪声的影响。这一步会平滑图像,使边缘检测更加稳定。
(2)计算梯度:在平滑后的图像上,通过计算得到每一个像素点的梯度方向和强度。
(3)非最大抑制:在梯度计算后,只保留局部梯度最大的像素,以细化边缘线。
(4)双阈值检测:Canny算子使用两个阈值来分辨图像真正的边缘。一般认为,如果像素点的梯度值比高阈值高,那么它就是强边缘。反之如果像素点的梯度值比低阈值低的话,就是弱边缘。而位于两者之间的像素被标记为弱边缘。接下来,通过连接强边缘像素,形成一条边缘路径。
(5)边缘跟踪:最后,通过连接强边缘像素和与之相邻的弱边缘像素,形成完整的边缘线。
Canny 算子在图像边缘检测中被广泛使用,因为它能够有效地找到图像中的细节边缘,并且对噪声有一定的抵抗能力。使用Canny算子对唐卡进行边缘检测,其效果如图1所示。

图1 Canny算子输出Figure 1 Canny operator output
1.2 RCF模型
RCF 引入了多尺度特征分支,允许模型同时考虑不同尺度的特征。这有助于检测图像中各种尺度的边缘,使得RCF在处理复杂图像场景时更具优势。它作为深度学习模型,RCF 可以通过端到端的训练学习适用于边缘检测任务的特征表示。这使得它能够从提供的丰富的数据集中不断的学习、能够提高自己提取特征信息的能力。相对于传统方法需要手工设定特征值、参数值更具有优势。同时RCF使用结构相似性损失函数来保持生成的边缘图像的结构和细节,从而减少噪声和不必要的细节。这有助于提高边缘图像的质量。
此外,RCF 在多个数据集上经过了充分的实验验证,并在边缘检测任务中取得了出色的性能。它通常能够提供高质量的边缘检测结果,特别是在复杂的图像中。使用RCF模型对唐卡进行边缘检测,其效果如图2所示。

图2 RCF模型输出结果Figure 2 The output results of the RCF model
1.3 ResNet模型
随着网络深度的加深,在神经网络的深层层次中梯度值会变得非常小,接近于零,从而使权重参数几乎不发生更新。这会导致网络在训练过程中无法学习到有效的表示或特征,因为梯度太小,不能推动权重更新,网络的性能停滞不前。它通常在深度神经网络中的激活函数中出现,特别是在使用sigmoid 或tanh 激活函数时更为明显,因为这些函数在输入较大或较小的情况下梯度接近于零。
ResNet 模型通过引入残差模块(residual block),允许网络跳过一定数量的层,直接传递信息到后续层,从而防止梯度消失。残差块包含了恒等映射和残差映射两部分,它们分别表示从输入到输出的路径和差异。这个残差映射被添加到恒等映射上,从而产生了残差块的输出。
ResNet非常适合构建非常深的神经网络,它的架构由残差块组成,可以使我们设计出避免出现梯度问题深层网络。目前具有ResNet-18、ResNet-34、ResNet-50 等不同的深度版本存在,可以根据任务的需求选择合适的模型。ResNet 在计算机视觉和图像处理领域取得了显著的成功。ResNet 中的残差块结构如图3所示。
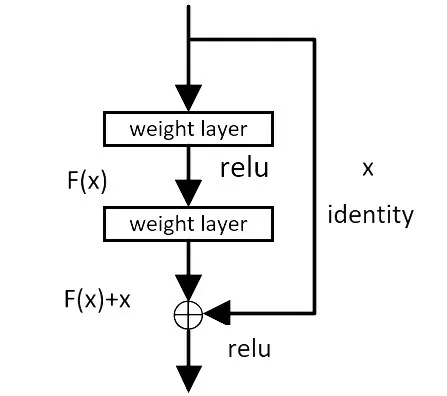
图3 ResNet中的残差块结构Figure 3 Residual block structure in ResNet
2 DMSCNN模型
2.1 模型概述
与自然图像相比,唐卡图像的内容更丰富、色彩更鲜明、纹理更细致,具有更复杂的特征信息。针对上述问题,提出了一种具有全局长程上下文信息的、网络深度比起一般模型深的、多尺度的深度学习模型。
在模型中分阶段输出特征图,并将不同尺度下的特征图像进行融合。这样就提取出了多个尺度不同的特征图,提高了模型的精度,得到了更加精准的边缘图像。并且为了能够使模型每个阶段提取到的边缘图像特征性更强,引入自注意力机制模块,将局部信息和全局特征相结合,融合上下文信息,改善通道之间的相关性,以增强边缘图像的特征性。最后,网络结构由残差块堆叠而成。残差结构的引入可以解决模型网络退化等问题,让我们得到更加深层次的特征信息。
2.2 模型结构
DMSCNN模型主要由100个卷积层组成。为了将图像的特征信息更适用于边缘检测,选择将这一百个卷积层分成5 个stage,分别学习和提取不同尺度下的图像特征信息,然后将不同阶段下得到的特征图像进行融合,最终得出边缘预测图。
Stage0 的作用是对原图像进行预处理,方便后续对图像进行特征提取操作。它不包含残差块,由一个大小为7×7、深度为64 的卷积层和一个3×3 的池化层组成。接下来四个阶段结构相似,都包括一个Block 块、一个1×1-21 的卷积层、一个亚像素卷积和一个loss 损失函数。其中Block1-4 包含的残差块数分别为3、4、23 和3,作用是对图像进行逐步的特征提取,每一个阶段的特征图像都会得到输出。在利用不同Block 的输出前,需要使用一个1×1-21 的卷积层对上一步得到的特征信息进行针对通道的降维操作,然后再利用亚像素卷积(Sub-pixel Convolution)对其进行针对尺度的上采样操作。亚像素卷积能够设置不同倍率的上采样因子,从而将特征图放大为不同的倍率。利用亚像素卷积可以使不同Block得到的多尺度特征图变为相同的尺度,便于后续的特征拼接。然后在每一个stage 的最后添加了一个loss 层以计算损失,更新参数。
本文在融合不同阶段的特征图像时使用了concatenate方法。在深度学习中,concatenate方法也常用于在指定的维度上连接张量,通常在处理神经网络中的不同层或分支时使用。该算法将不同特征图作为某一通道进行合并,不改变每一张特征图本身包含的信息,仅仅增加特征图的通道数,完好的保留了原特征图的信息。此处使用它将多个尺度下,具有相同尺度的图像连接在一起,以构建更加精确的特征图像。
不同尺度会输出含有不同特征信息的图像,浅层含有较少的特征信息,而深层含有较多的特征信息,但是深层也存在着特征信息提取不完全的可能。所以选择融合从浅层到深层的多个尺度的特征图像信息,综合全局的边缘特征,最终会得到一个细节更完备的特征图像。DMSCNN的网络结构如图4所示。
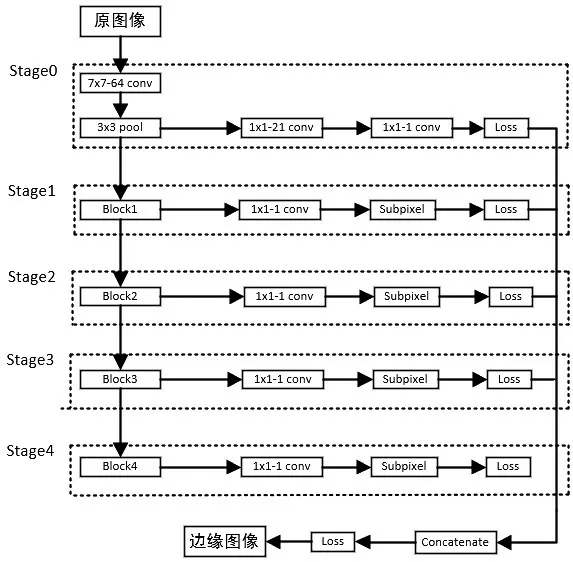
图4 DMSCNN模型结构Figure 4 DMSCNN model structure
2.3 Block模块的结构
残差结构(residual block)使深层网络具有了更好的收敛效果和更快的收敛速度,解决了梯度爆炸的问题,让模型可以提取到更加复杂丰富的特征信息。通过堆叠残差块来构造深层次的网络结构。
Block模块由多个网络层组成,每一层包括一个残差块(residual block)、一个1×1-21的卷积层和一个自注意力机制(Self attention module)。不同Block模块中含有不同数量的残差块,其中残差块也具有不同数量的卷积核。网络越深,卷积核的数量越多,从而可以提取到更加丰富的特征信息。Block1-4中所包含的残差块数量以及卷积核的大小和数量如图5所示。
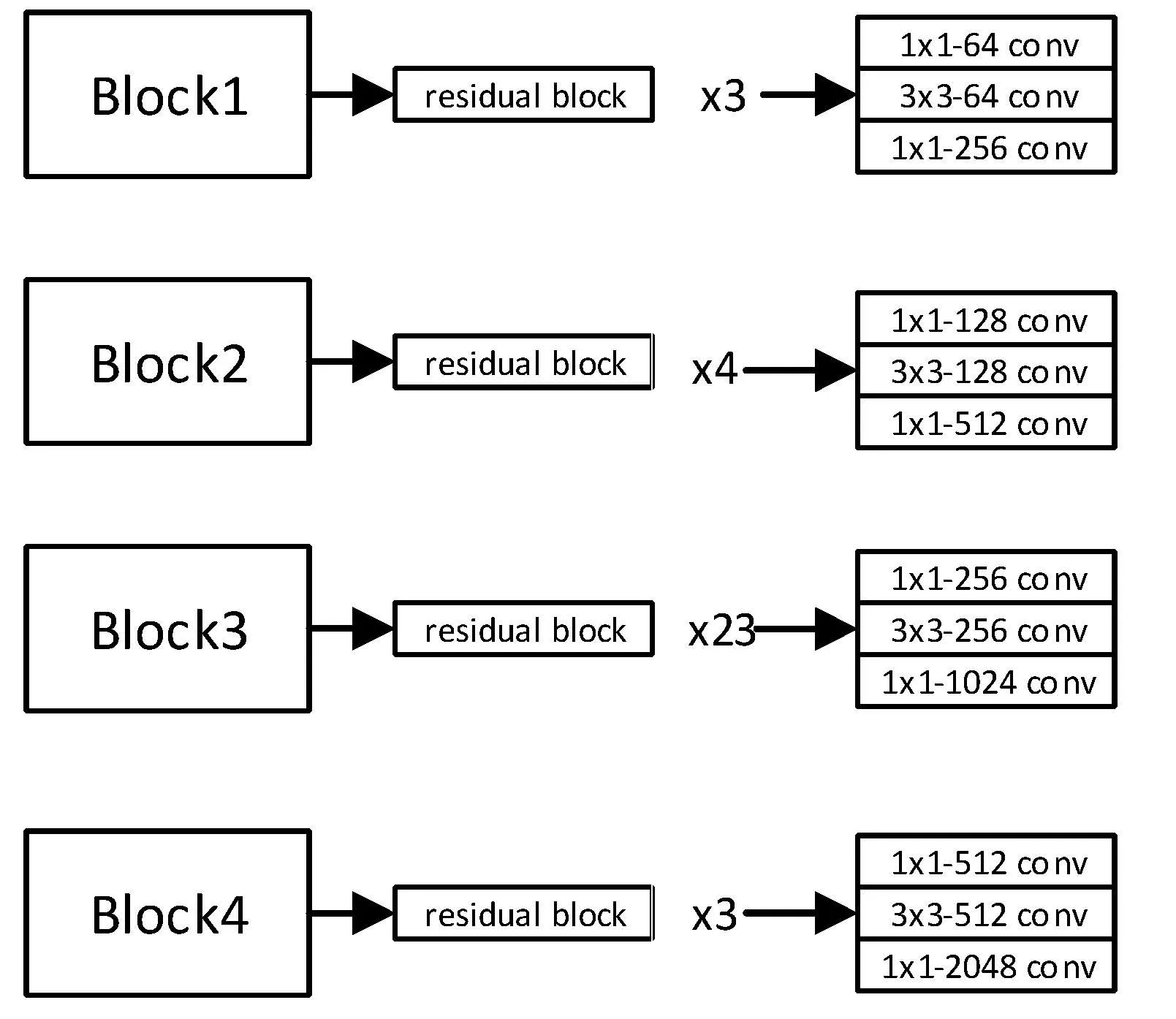
图5 不同Block中残差块和卷积核大小与数量Figure 5 The size and number of residual blocks and convolution kernels in different blocks
每个残差块(residual block)都会输出对应的特征图像。然后对同一个Block 下的不同残差块输出的特征图进行处理,以Block1 中的三个残差块为例。
首先利用一个1×1-21 的卷积层进行升维,然后充分利用自注意力机制(Self attention module),提高模型的上下文感知能力,捕捉重要信息,降低位置敏感性,使每层输出的图像特征性更强,提高模型的性能。再使用cancatenate 方法将不同残差块得到的特征图像进行通道上的叠加,得到该Block 模块最终输出的特征边缘图。Block1 模块的结构如图6 所示。
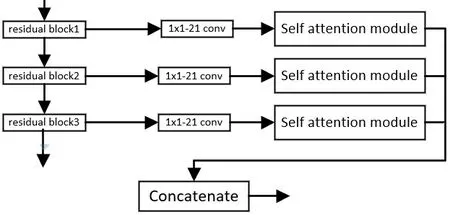
图6 Block1模块结构Figure 6 Block1 module structure
2.4 残差结构
为了减少残差模块的参数,从而减少计算量,与一般的残差块不同,文中模型使用了瓶颈结构的残差块。具体原理是:通过1×1 和3×3 的卷积核来调控特征图像的通道维度,卷积核的数目既不受上一层输出的影响,又不会对下一层的输入造成干扰。由于本模型的主干结构由残差块堆叠形成,所以使用瓶颈结构可以极大的提高模型的性能。在短路连接上同时也存在着一个1×1 的卷积层,它的作用是用来调控底层输入和高层输出的通道数,只有具有相同的维度,两者才可以正常进行叠加操作,所以这一步不可避免。DMSCNN 中所使用的瓶颈残差结构如图7 所示。
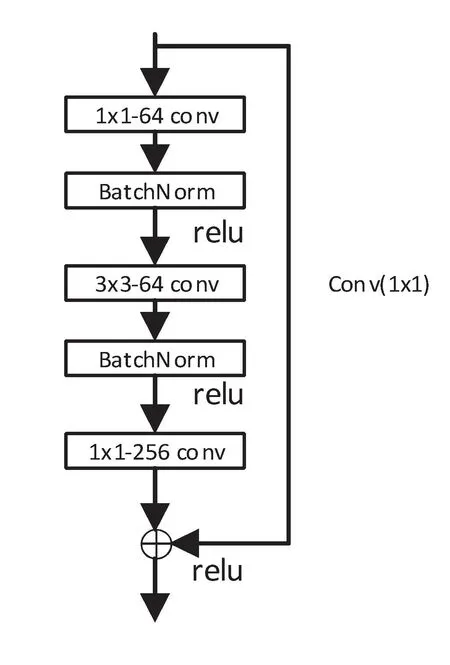
图7 DMSCNN中的瓶颈残差结构图Figure 7 Structure of bottleneck residuals in DMSCNN
2.5 全局通道自注意力机制
在深度学习中,全局长程上下文信息是指模型能够考虑输入数据的广泛范围或全局性信息,而不仅仅局限于局部细节。这种全局上下文信息对于理解复杂关系、长距离依赖关系和整体语境非常重要。
如果缺少了全局长程上下文信息,会导致模型缺乏对整体的理解、局部化错误、性能下降、长距离依赖关系问题以及难以应对多层次特征等问题。
本模型采用全局通道自注意力机制,它是一种自注意力机制的变种,目标是在通道之间建立权重,以捕获全局上下文信息,并改善特征表示。全局通道自注意力模块的结构如图8所示。
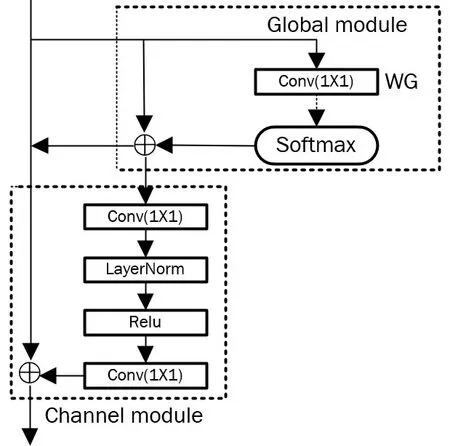
图8 全局通道自注意力机制结构图Figure 8 Structure of the self-attention mechanism of the global channel
该结构分为全局模块和通道模块。全局模块利用一个1x1 的卷积层WG 和一个Softmax 函数对全局特征进行池化操作,可以得到特定于每一个位置的全局上下文注意力图。然后经由该全局上下文注意力图将所有位置的特征信息加权聚合,从而得到特定于每一位置的全局上下文特征。然后将特定于每一位置的全局上下文特征聚集到每个位置,使网络能够获得全局长程上下文信息,通过聚集来自其他位置的信息来增强每一位置的特征。
通道模块的作用是为了计算每个通道的重要性,重新校准通道响应。通过两个1×1的卷积层进行特征变换,从而获取通道的相关性。由于两层瓶颈变换增加了算法的复杂度,所以选择在Relu之前加入一个归一化层进行优化,同时也起到了调节的作用,有利于性能的提升。这两个卷积层分别表示瓶颈模块的两次卷积运算,LN表示归一化运算,Relu表示Relu激活函数。
因为优化后的算法复杂度比较小,成本较低,所以选择在每一个残差块后都加入该注意力机制。
3 实验结果与分析
3.1 实验结果
本文除了选取BSDS500 进行测试外还选取了三百张经过预处理的唐卡图片进行测试,图像主要为佛像图片,分辨率均为256×256。
本实验提出的模型以及其他方法是在Win10 系统下利用pycharm 编程实现,显卡型号是RTX 3060。分 别 用Canny 算 子、RCF 模 型、HED 模 型 以 及DMSCNN 这模型对测试图像进行边缘提取,检测结果如图9所示。

图9 其他方法与DMSCNN结果对比图Figure 9 Comparison of other methods with DMSCNN results
根据实验可以看出,相比于传统的Canny 算子和目前效果比较好的HED、RCF 模型,本文提出的DMSCNN 模型得到的边缘图像效果更好,富有更多的特征信息和细节纹理。具有更好的视觉表现。为后续对唐卡文物的保护以及图像处理工作提供了良好的保障。
3.2 结果分析
当从客观上评估边缘检测方法的性能时,有两种常见的方法:ODS(Optimal Dataset Scale)和OIS(Optimal Image Scale)。
(1)ODS(Optimal Dataset Scale):这是一种全局性能评估方法,它要求在整个数据集上使用相同的阈值进行边缘检测。目标是找到一个固定的阈值,使整个数据集上的F1 分数最大化,从而确保在不同图像之间的比较具有一致性。
(2)OIS(Optimal Image Scale):与ODS 不同,OIS是一种基于每张图像的性能评估方法。对于每个图像,它会选择不同的阈值,以获得每张图像上的最佳F-sore分数。
F-score 是一种用于衡量分类模型性能的指标。它结合了模型的精确度(Precision)和召回率(Recall),通常用于评估二元分类问题中的性能。F-score 的计算方式如下:
F-score=2×(Precision×Recall)/ (Precision +Recall)边缘检测中一般使用ODS值和OIS值作为检验边缘检测方法性能的指标。
本文提出的模型加深了网络深度,并通过使用残差结构,解决了随着网络深度的增加而造成的梯度爆炸的问题。使得模型能够从原始图像中提取出更具代表性的、越来越高级的特征。这些特征可以帮助模型更好地理解图像中的复杂信息,从而得到效果更佳的边缘图像。
同时本文在网络模型中添加了全局通道自注意力机制,将局部信息和全局长程上下文信息进行融合。通过考虑全局信息,算法可以更容易区分对象的边缘与背景的边缘,可以更好地理解对象之间的相对位置和边界,能够准确地定位边缘,从而改进边缘检测的性能。即使面对唐卡这种比较复杂的图像,该模型也能得到比较完好的边缘图。
通过上述两方面的改进,使得本文提出的DMSCNN模型相比于其他模型在公共数据集和自建数据集上都取得了更好的效果,实验结果如表1、表2所示。
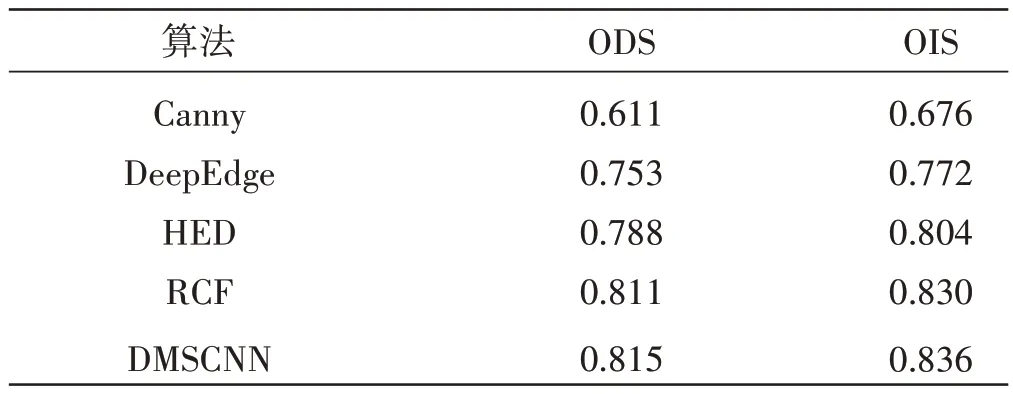
表1 在BSDS500上的性能指标比较结果Table 1 Comparison results of performance metrics on BSDS500
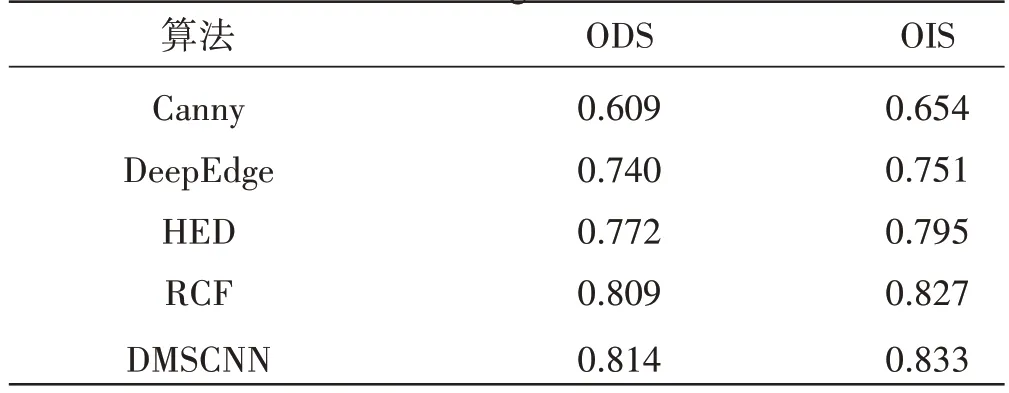
表2 在唐卡图像上的性能指标比较结果Table 2 Comparison results of performance metrics on Thangka images
4 结语
在本研究中,我们探讨了唐卡数字图像的边缘检测,以提高对这些宝贵艺术品的数字分析和保护。采用了先进的边缘检测方法,结合唐卡图像的独特特点,实现了有前景的结果。本文给出了一种多尺度的深层边缘检测模型,它既使用残差结构解决了梯度爆炸的问题,又通过多尺度输出,配合自注意力机制,将局部特征和全局特征相结合,使输出的边缘图片含有全局上下文信息,得到了特征信息更丰富、细节更显著、视觉效果更好的唐卡边缘图片。
尽管本研究取得了不错的成果,但也承认存在一些局限性。唐卡图像具有独特的挑战,例如复杂的颜色和纹理,这些问题需要更深入的研究。希望未来能够有更多的研究者加入到相关研究中,为保护和传承唐卡的宝贵文化遗产提供帮助。
