藏医药文章信息知识图谱构建与可视化分析
2024-04-19陈颂斌高屹罗丽锦樊淼
陈颂斌 高屹,2 罗丽锦 樊淼
1.西藏民族大学,咸阳 712082;2.西藏光信息处理与可视化技术重点实验室,咸阳 712082
在信息化快速发展的时代,医药数据的存储以及共享方式变得极其简便,网络中有关医药的数据也随之增加,但是也伴随着很多问题,比如数据冗杂混乱,用户想在大量的医药数据中寻找有价值的数据变得十分困难。因此,探索医药数据之间的关系并且从大量医药数据中挖掘潜在价值成为了重要的研究任务。同时藏医药是一种传统的医学体系,主要流行于西藏和周边地区。它包括草药疗法、针灸、气功等多种治疗方法。研究藏医药文章信息知识图谱有助于发掘这一传统医学知识,同时也可以为现代医学提供有用的信息。
Google 公司提出的知识图谱这一概念,旨在优化其搜索引擎,以实现更高级的搜索功能。该概念的核心目标是从语义层面深刻理解用户的意图,从而为用户提供更为精准的搜索结果[1]。近十几年的发展,已经成为人工智能领域研究的热点之一[2]。知识图谱的出现为问题的探索提供了清晰的思路和结构,它在整理领域知识方面发挥了重要的作用,为研究领域探索的主题提供了有力的思路来源。知识图谱的本质是以语义网络的形式阐述不同实体之间的联系,以图的形式生动展示了实体之间的紧密联系。对于藏医药文章信息知识图谱,知识图谱的应用能够有效地建立不同期刊之间的多种关系,这对于深入研究藏医药热点具有重要意义。
1 国内外研究现状
大数据在医学领域的发展一直备受人们关注,而随着众多学者对该领域的研究,不同类型的数据可能采用不同的存储方式,使得很多医药领域的数据无法被直接使用,一定程度上限制了医学大数据的发展。近年来,随着领域知识图谱应用的发展,医药知识图谱在构建的过程和标准上也迈出了尝试性的探索。如邹艳珍,王敏[3]等人就如何在多源异构情况下,提出了以代码为核心的软件知识图谱模型,在国内外知名企业展开实践应用;曹倩,赵一鸣[4]介绍了知识图谱构建的整体流程,详细说明了如何通过知识库推理、求解;刘欢[5]等人提出了基于知识图谱驱动的图神经网络推荐模型;阮彤[6]等人探索了自动化构建中医药知识图谱的方法和标准化流程;王赫楠,孙艳秋[7]等人从应用的角度探讨了知识图谱在中医药领域的作用。
2 藏医药文章信息知识图谱构建
知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,和实体及其相关“属性-值”对。实体可以是具体事物或着抽象概念,关系可以是实体的属性或实体之间的关系[8]。实体间通过关系相互连结,构成网状的知识结构。知识图谱的构建使得概念化、语义化的知识管理模式的形成成为可能。借助知识图谱,可以实现准确和深度知识获取[9]。
藏医药文章信息知识图谱的构建过程有数据获取、数据处理、知识获取、图谱设计和图谱存储与应用几个阶段,数据获取和处理就是从知网爬取数据,然后处理重复数据,异常数据和缺失值的过程。知识获取是通过实体识别、关系抽取和属性抽取获取藏医药文章信息知识图谱的三元组,图谱存储就是利用Neo4j图数据库对藏医药文章信息知识图谱节点的存储,实现藏医药文章信息知识的精确查询。本文构建藏医药文章信息知识图谱的具体流程如图1所示。

图1 藏医药文章信息知识图谱构建图Figure 1 Construction Map of Knowledge Graph of Tibetan Medicine Article Information
2.1 数据获取与处理
藏医药研究一直以来都备受学术界和医学领域的关注[10]。为了深入了解这一领域的热点问题和最新进展,利用计算机检索工具来分析大量文献资料。中国知网(CNKI)成为了研究藏医药文章信息的主要信息来源。通过使用CNKI的高级检索功能来精确获取本文的实验数据。首先,需要获取近6 年的藏医药相关文献。在CNKI 中,高级检索功能允许用户输入多个检索条件,以便更精准地定位相关的文献。对于藏医药研究,可以使用以下检索内容来获取相关文献:SU=“藏”AND(SU=“医”OR SU=“药”),通过这个检索条件可以将主题词中包含“藏”,并且同时包含“医”或“药”的文献检索出来。
利用爬虫技术获取到相关数据,其中包含了结构化、半结构化和非结构化的数据。对结构化的数据,可通过规则把藏医药文章信息相关实体映射到知识图谱中。比如文本数据中的“藏医论治新型冠状病毒肺炎探析”属于结构化的数据。对于非结构化数据,主要是从文本中抽取出实体及关系等信息。比如将爬虫获取到的不同排版格式网页和文件,首先对获取到的网页和文件进行预处理,包括去除重复数据、异常数据等,然后利用实体识别、关系抽取等技术得到需要的实体和关系。
2.2 知识获取
知识获取旨在通过非结构化文本和其他结构化或半结构化数据来构建知识图谱。本文的知识抽取包含实体识别、关系抽取和属性抽取这三部分。
实体识别是指在文本中识别出具体的名词或名词短语,如人名、地名、组织机构名称等。首先,通过正则表达式从爬取的文本数据中识别出题名、标签名、作者、数据库、文献来源等实体。比如一个html文件中获取期刊题名、标签名、作者等。
其次,在对关键字处理时引入TF-IDF 方法,充分利用摘要内容进行关键字的抽取和筛选。TF-IDF是一种常用于信息检索和文本挖掘的统计方法[11],用来度量文本中每个词的重要性。它是融合了TF(词频)和IDF(逆文档频率)[12],从而更全面地评估一个词在整个文本集合中的重要性。TF-IDF 用计算公式如下:
其中TF 表示词条在文本中出现的频率,通常,这个数值会被进行归一化处理,以避免它对长文本文件产生偏向性。TF 可以通过用词在文中出现的次数除以整篇文章的次数得到,具体的计算公式如下:
IDF 反映了关键词的普遍性。当包含词汇的文档数量越少,IDF 值越大,表明这个词汇在文档中有良好的类型区分能力。IDF 值可以通过数据库里文件的总数量除以含这个词汇的文件数量,最后通过取对数得到,具体的计算公式如下:
例如计算“藏药”在一个文档中的TF-IDF,其中总词数为200,整个文档集合总文档数为1000,“藏药”在文档中出现3次,需要分别先计算TF和IDF。
TF(“藏药”)=3∕200=0.015
IDF(“藏药”)=log〔1000∕(出现“藏药”的文档数+1)〕=log〔1000∕(1+1)〕=log(500)≈2.7
TF-IDF(“藏药”)=0.015×2.7≈0.04
类似地,计算其他关键词在文章里的TF-IDF 值,与原文摘要关键字进行去重,获取8 个主要关键词作为期刊的特点。
关系抽取是指从文本中提取出实体之间的关系,例如可以将期刊文献中的作者、关键词、引用关系等信息作为实体、属性和关系来构建图谱。本文通过人工分析句子与句子之间的依存关系提取了文献题名与作者、数据库类型、发表年份、期刊类型、关键词之间的关系。
属性抽取的目标是识别并提取出与实体相关的属性信息,这些信息可以作为实体的补充描述,有助于对实体进行更全面和详细的理解。例如本文通过对照知网上第一行已经确定好的关键词表来搜索并抽取出文献发表时间用来描述文献的属性。这些属性都是与实体相关的信息,将各个实体的属性单独作为节点并与实体节点连接,最终构成实体的属性关系。
2.3 知识图谱设计
经过知识获取后,整理藏医药文章信息包含的题名、标签名、作者、数据库、文献来源、发表时间、关键词等实体。藏医药文章信息实体设计如表1所示,比如标签名实体包含了网络首发、北大核心、CSCD 等,数据库实体包含了期刊和硕士等。藏医药文章信息关系设计如表2所示,比如《藏药十一味金色丸的药对配伍规律研究》的发表年份是2023年,《藏药“解吉”的生药学研究进展》第一作者尕让甲,《藏药独一味的微性状与显微鉴别研究》的数据库类型是期刊。
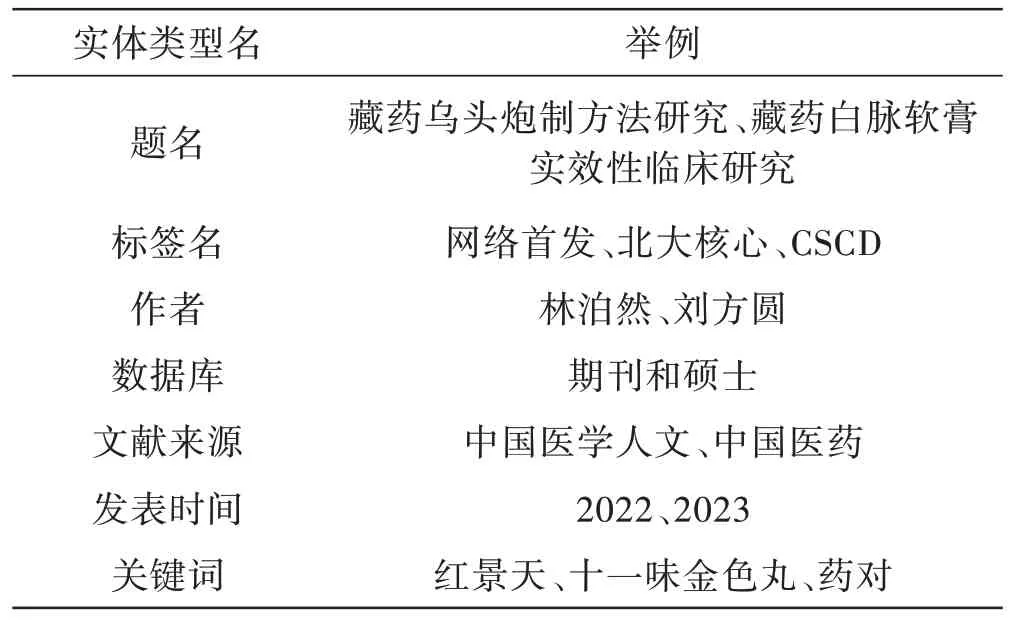
表1 藏医药文章信息实体设计Table 1 Entity Design of Tibetan Medicine Article Information

表2 藏医药文章信息关系设计Table 2 DesignofInformationRelationshipinTibetanMedicine Articles
2.4 知识图谱存储
知识图谱存储方式有分为图数据库存储和三元组存储方式两种。相较于三元组的存储方式,图数据库存储适合表示实体间错综复杂的关系,处理大规模图结构数据,它还能高效的处理复杂的图查询,让用户能方便快捷的查询到自己想要的内容。由于以上这些优点,本文选择的是图数据库中常用的Neo4j 来存储数据,这使得处理关联数据变得更加明显优势,不需要进行复杂的关联操作,提高了数据存储和检索性能[13]。用户通过cypher 语句就能对图数据库中的节点和关系进行查询和操作,查询速度也更快。
根据藏医药文章信息资料来获取关于题名、标签名、作者、关键词等数据,将数据导入到Neo4j 图数据库以完成数据的存储。通过查询语句我们可以得到藏医药文章信息部分数据的展示,如图2所示,每一个圆形表示一个实体类型,颜色不同表示实体类型不同,两个圆形通过直线相连,直线表示不同实体直接的关系,红色表示期刊题目,绿色表示标签名,黄色表示文献来源,蓝色表示期刊类型,粉红色表示时间,棕色表示作者等等。
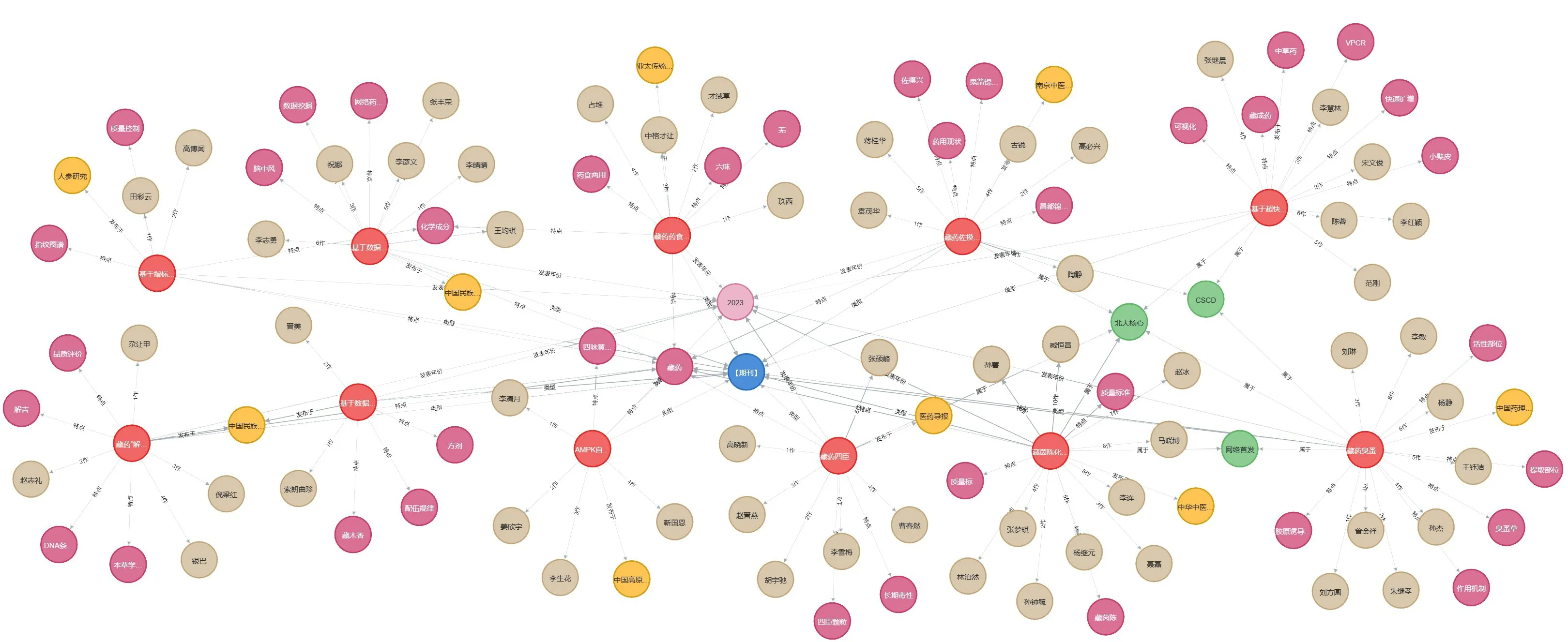
图2 Neo4j查询结果Figure 2 Neo4j Query Results
3 藏医药文章信息可视化分析
3.1 可视化平台的实现
藏医药文章信息知识图谱的可视化可以让人直观地了解到藏医药领域内的关联、趋势和研究热点。可视化平台的一个重要功能是知识展示,要支持用户对已有的数据进行搜索,并展示查询结果。这个功能使用户能够根据特定的关键词、主题或领域查找相关信息。用户可以通过输入查询条件来快速定位他们感兴趣的内容,并获取有关这些内容的详细信息。如图3 所示为《基于数据挖掘和网络药理学的脑中风与藏医“隆”功能调节机理研究》节点图。
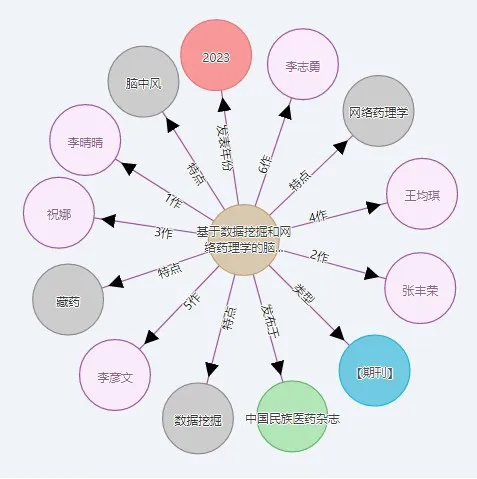
图3 节点图Figure 3 Node Diagram
知识展示功能的关键优势在于它将复杂的数据和信息以可视化的方式呈现出来,使用户更容易理解。这有助于研究人员、学生和决策者更深入地了解藏医药领域的关键概念、研究成果和趋势。同时,知识展示还可以促进跨学科的交流和合作,因为不同领域的专家可以通过这个平台共享他们的研究成果并进行讨论。
3.2 藏医药文章信息知识分析
通过可视化平台分析近5 年的文献发表情况,可以揭示出藏医药热点领域的发展趋势和研究重点。从已获取到的数据可以看出,与藏医药相关的记录有2249 项,从图4 中我们可以看到藏医药文章的发文量随着时间的增加逐渐减少。根据学科领域生命周期的划分阶段来看(一般分为萌芽期、发展期、成熟期和衰退期∕转型期)[14],2018—2019 年文献发表量缓慢增长,学科领域发展到成熟区,2019 年成为转折点,从2020—2023 年文献发表量越来越低,研究主题固定,藏医药领域出现新研究主题量变少。
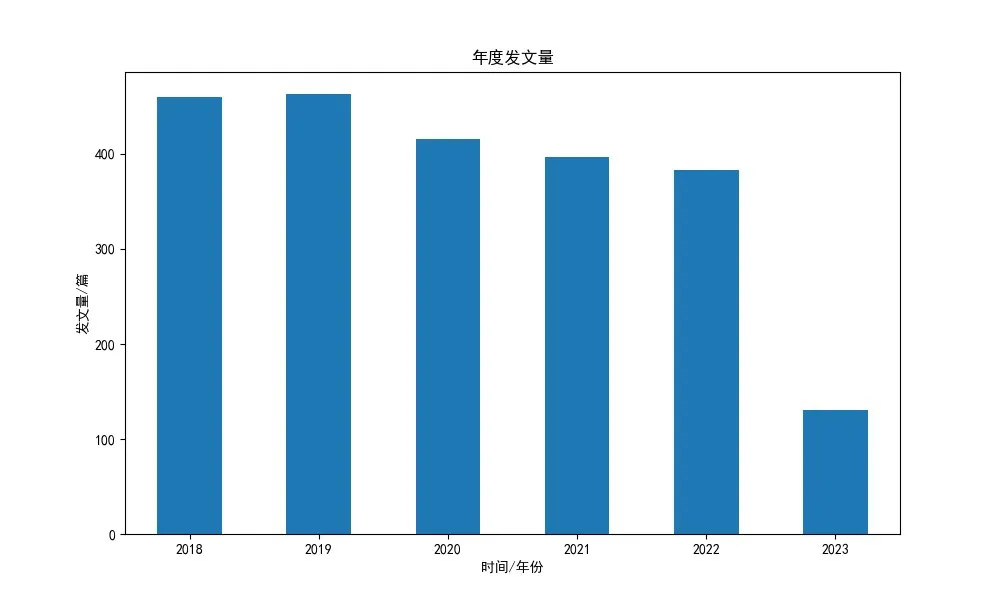
图4 年度发文量Figure 4 Annual Number of Publications
发文量前10的作者有张艺、青海大学、才让南加、陈静、贡保东知、米玛、贡却坚赞、文成当智、李啟恩、尼玛次仁,如图5 所示。其中发文量最高的张艺现今已发表相关领域论文57篇,成为藏医药研究领域贡献程度最大的研究人员之一。
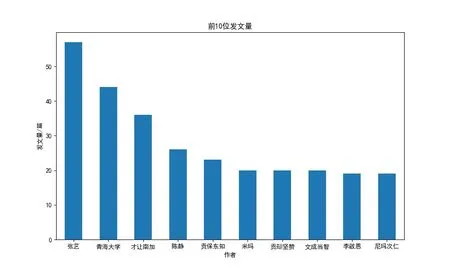
图5 前10位作者发文量Figure 5 Number of Papers Published by the Top 10 Authors
藏医药文章信息数据库种类中报纸类43条,博士类45 条,国际会议类6 条,辑刊类9 条,科技成果类70条,期刊类1830 条,硕士类188 条,特色期刊类41 条,图书类1条,中国会议类19条,如图6所示。期刊类文章在藏医药文章占比最大,其次是硕士类文章,但相比其他学科领域的文献发表量,藏医药文章的发表量相对较少。这可能反映了目前在藏医药领域的研究和发表相对较少,尚有较大的发展空间。
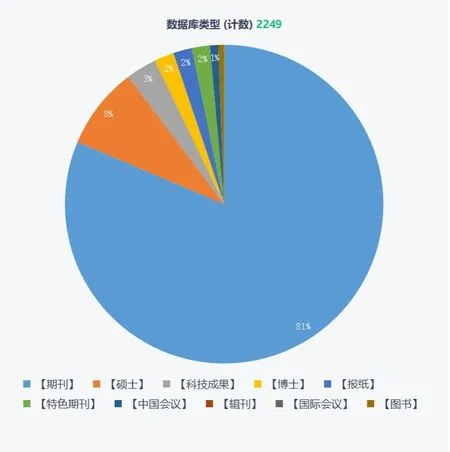
图6 藏医药文章各类数据库发表量Figure 6 The Number of Tibetan medicine articles published in various databases
藏医药文章发文量排名前15 的机构分别为中国民族医药杂志、中国民族民间医药、世界最新医学信息文摘、中西医结合心血管病电子杂志、青海大学、亚太传统医药、西藏科技、世界科学技术-中医药现代化、临床医药文电子杂志、中华中医药杂志中药材、中国药房、中草药、中医药号报、成都中医药人学,如图7所示。中国民族医药杂志、中国民族民间医药发表藏医药相关领域文献最多,占比分别为42%和6%.
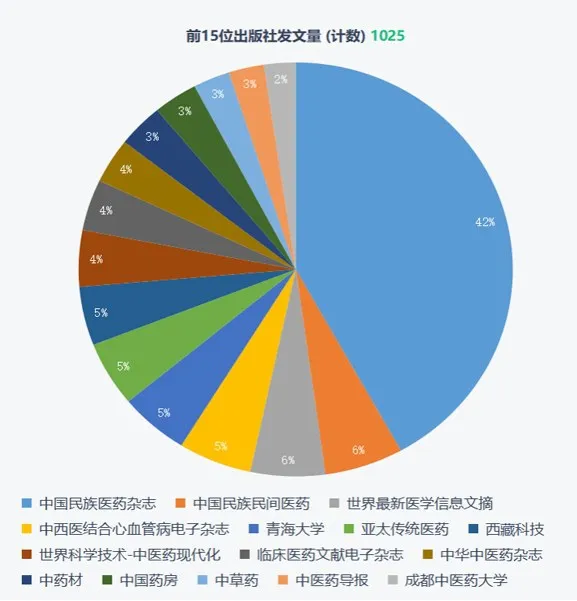
图7 前15位出版社发文量Figure 7 The Number of publications by the top 15 publishers
近5 年来,藏医药领域的研究文献涉及15 个主要类别:藏药、藏医、临床疗效、化学成分、藏红花、藏医药、网络药理学、疗效、含量测定、质量标准、临床效果、作用机制、高效液相色谱法、药理作用、数据挖掘,如图8所示。
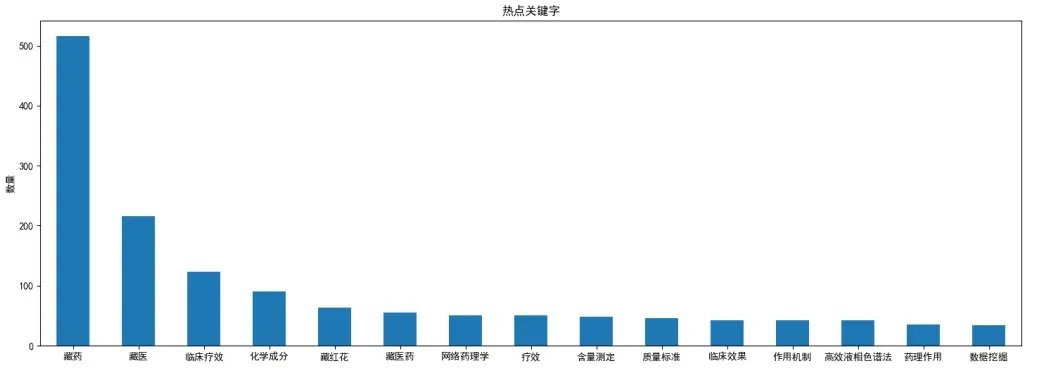
图8 近5年藏医药领域热点关键字Figure 8 HotkeywordsinthefieldofTibetanmedicineinthepast5years
4 结语
知识图谱技术正成为人工智能领域的热门研究方向。随着藏医药文章信息数据逐渐积累。建立藏医药文章信息的知识图谱,有助于从大量数据中提炼出有关藏医药的关键知识,对现代医药领域具有重要意义,也是众多研究机构的研究重点。本文创建了一个包含题名、标签名、作者、数据库、文献来源、发表时间、关键词等相关实体的藏医药文章信息知识集。借助命名实体识别、关系抽取和属性抽取技术,将藏医药文章信息知识中的半结构化和非结构化信息转化为结构化数据。使用Neo4j图形数据库构建了藏医药文章信息的知识图谱。在未来的研究中,我们计划结合知识图谱的推荐系统,以实现对藏医药文章信息的智能推荐,这也将成为我们的研究重点。
