面向高光谱异常检测的背景记忆模型
2024-04-17谢卫莹钟佳平李云松
谢卫莹,钟佳平,李云松
西安电子科技大学 综合业务网理论及关键技术国家重点实验室,西安 710071
1 引言
高光谱图像HSI(Hyperspectral Image)可以视为三维数据立方体,其中两维表示物体实际空间分布的空间信息,一维光谱波段表示每个光谱段的光谱属性信息。由于具有丰富的地物光谱特征信息,在提供地物空间维的纹理和位置等信息的同时,HSI在对地物识别能力上有相较于其他成像的独特优势(Xie等,2019;Tong等,2006;Liu,2021)。作为一种先进的地球观测和深空探测技术,包含分类、目标检测、异常检测等在内的高光谱遥感图像处理方式已经被广泛应用于如环境监测、资源探测、精准农业以及土地分类等领域(Han等,2020;Zhu等,2020;Yuan等,2020;Tu等,2018;Li等,2017)。其中,高光谱异常检测尝试定位空间或光谱域与周围像素显著不同、光谱特征明显、出现概率低并且目标空间尺寸较小的像素,在高光谱遥感图像的各个应用领域均具有重要研究意义。
在现有的众多高光谱异常检测方法中,使用较为广泛的是基于统计的方法。此类方法利用图像的统计特性建立异常检测模型,并通过统计差异区分异常与背景,例如RX(Reed-Xiaoli)算法及其各种变形版本(Reed和Yu,1990;Molero等,2013;Kwon 和Nasrabadi,2005)。RX 算法假设背景服从多元高斯分布,通过估计样本的平均值和协方差来构建背景统计模型(Reed 和Yu,1990),忽略不计具有稀疏性特性的异常像素对背景像素参数估计的影响。但在实际应用场景中,RX方法的检测性能比较有限,这表明假设多元高斯分布可能并不正确。与原始RX 基于全局统计数据不同,最具代表性的变形版本LRX(Local RX)通过建立滑动双窗口模型提高检测精度(Molero等,2013),但是该方法受两个窗口大小的影响,如果窗口过大,就会导致信息量过大,信息冗余量高,计算量呈旨数倍增长。如果窗口过小,则会使得检测结果因为缺失信息而不准确。为克服这些限制,KRX算法(kernel RX)在RX算法的基础上引入核函数(Kwon 和Nasrabadi,2005)。该方法将原始高光谱数据投影到高维特征空间中,充分挖掘数据的非线性特征并提高检测精度,但是核函数的选择和计算复杂度会导致计算成本高的问题。
非RX 类的算法主要包括协作表示、稀疏表示和低秩表示算法(Li等,2015a,2015b,2021;Zhang等,2016)。其中,基于协作表示的方法CRD(Collaborative Representation-based Detector)在没有目标光谱先验知识的情况下定位与邻域背景或全局背景存在明显光谱差异的异常点,这种方法容易受到背景噪声分布和异常点面积的影响,存在检测结果虚警率过高的问题,影响定位(Li等,2015a)。在基于低秩和稀疏矩阵分解马氏距离的异常检测算法LSMAD(Low-rank and Sparse matrix decomposition-based Mahalanobis distance for Anomaly Detection)中,高光谱数据矩阵被分解为低秩背景矩阵、稀疏异常矩阵和噪声(Zhang等,2016)。其中,低秩背景矩阵的协方差矩阵和均值向量被用于构造RX 算子,进而提取异常点,实现异常检测。此外,AED 方法假设在空间域中,与周围背景相比异常目标呈现出较小区域(Kang等,2017),此方法通过结合属性滤波和差分操作来去除背景,从而获得检测结果。
然而,由于高光谱遥感图像数据量大、波段间的相关性高且波段数量多,传统异常检测技术不能很好地与高光谱图像数据特征相适应,高层语义信息常常难以得到准确的表征。新兴的基于深度学习的方法,例如基于自编码器AE(Auto Encoder)(Makhzani等,2015)和生成对抗网络GANs(Generative Adversarial Networks)(Goodfellow等,2014)的方法,均具有强大的复杂数据表征能力,已在异常检测领域引起广泛关注并成功实现应用(Perera等,2019;Akçay等,2019)。其中,基于GAN 的无监督多元异常检测方法MAD-GAN(Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks)使用长期记忆递归神经网络LSTM-RNN(Long-Short Term Memory-RNN)作为基本模型(Gutiérrez-Gómez等,2020),在GAN框架中捕获时间序列分布的时间相关性。基于变换的异常检测方法进行基于人工先验的一组选定的转换变换操作(Ding等,2019),从输入数据中删除某些目标信息,并使用正常数据训练逆变换自动编码器,仅在重构原始数据的过程中嵌入相应的已擦除信息。因此,正常数据和异常数据可以根据重构误差进行区分。基于深度学习的异常检测方法大致可以分为3 类:有监督、半监督和无监督。大多数有监督方法尽管有出色的性能,但会受到有标签样本数量不足的限制,不能很好地对输入网络的向量建模,使得样本应用十分受限。基于半监督的异常检测研究往往需要人工标记样本,使用有限的标记数据和大量的未标记数据来训练深度神经网络。总体而言,尽管GANs适合应用于复杂高维数据的处理,但在高光谱异常检测领域的应用仍待提升,并且无监督异常检测方法很难在性能上取得突破(Li等,2020;Song等,2019;Zhang等,2019;Cui 和Li,2018;Del Giorno等,2016)。
为了解决以上问题,本文结合高光谱数据特性设计了一种面向高光谱异常检测的背景记忆模型。具体来讲,本文使用无监督的基于密度估计的粗检方式获取伪背景和伪异常,克服有标签数据人工标记成本高的问题。基于GAN的基本架构,在特征空间和图像空间同时进行对抗学习建立输入高光谱图像样本和生成样本之间的映射关系,构建对于背景重构能力强而对于异常重构效果差的高光谱异常检测模型。本文通过对于背景具有强记忆性的网络并在测试阶段重载,从而得到背景异常区分度更好的检测结果。同时在网络中施加正则项约束损失函数,从而增大同类向量距离,减小不同类向量间的距离,使得生成样本中背景与输入的相似度高,而异常有别于背景。此外,本文采用非线性背景抑制后处理技术,在[0,1]区间内对背景进行指数函数非线性抑制,重构相似度更高的背景,防止异常向量被误检,降低虚警率、提升检测结果的性能。
综上所述,本文设计的网络结构可以扩大背景与异常的可分离性,进一步提高检测精度。与现有技术水平相比,采用背景记忆模型的异常检测算法在定性和定量分析中均达到了优异的性能。
2 弱监督高光谱异常检测算法
2.1 背景记忆生成对抗网络
如上文所述,异常检测不仅要求确保同类的背景点样本能够被很好地表示,而且需要保证不同类的异常点样本不能被很好地表示,这在实际操作中往往难以实现,因为网络会对异常点也不加区分地以相似性高的生成能力实现重构。GAN获取输入数据分布的能力强,对复杂数据的表征更准确,因此在异常检测方面也激发了广泛的研究兴趣。基于先前GAN 的工作,本方法的主要目的是在无充足先验信息情况下,通过弱监督伪标签的方式训练背景记忆型生成对抗网络,约束伪背景和伪异常光谱向量之间的距离,如图1 所示。本方法学习从原始HSI空间到重构空间的背景记忆模型,通过少样本弱监督的方式,使背景能够从不可观察或者未知的异常样本中被分离并确定,算法流程图如图2所示。

图1 面向高光谱异常检测的背景记忆模型框图Fig.1 The flowchart of the background memory model for hyperspectral anomaly detection
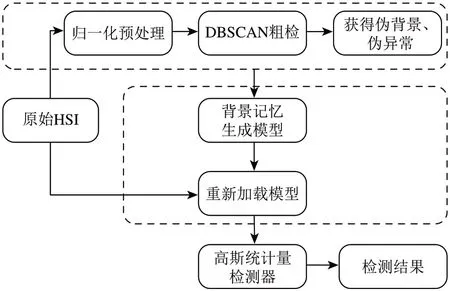
图2 面向高光谱异常检测的背景记忆模型流程图Fig.2 The algorithm flowchart of the background memory model for hyperspectral anomaly detection
式中,ω,b为网络的权重和偏差,g,r,f,a分别代表生成器、视觉判别器、特征判别器和自编码器。此外,网络学习过程中对于输入的编码和解码过程表示如下:
式中,Sg(·)表示激活函数Leaky Relu,z是编码器的输出向量。
式中,gθ(z)是解码器的输出。
2.1.1 数据准备
实现突出异常、抑制背景的步骤主要包括:无监督基于密度估计的粗检,背景记忆生成对抗网络模型训练,输入HSI 测试并抑制背景。其中,粗检的目的是准备作为输入的高光谱数据,从而获得伪背景点向量和伪异常点向量,具体过程如下。
2.1.2 无监督密度估计粗检
由于背景像素所占比例大,而异常像素产生的可能性低,本文设计一种粗检方法,对于分类为背景的簇,保留属于背景的可能性较高的像素,而拒绝属于异常的可能性较高的像素,该方法可获取干净的背景,用于背景和异常初步分离。受到基于密度的带噪声空间聚类DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法启发(Ester等,1996),本文采用基于密度估计的无监督显著图提取算法进行初步检测,能够发现不同大小和形状的簇,而无需事先指定簇的数量。首先,通过使用密度估计进行聚类,即分离高密度区域和低密度区域。然后将所有相互密度连接的点分组以组成簇,同时将低密度区域中单独存在的点标记为噪声,以噪声为特征的点也称为异常。HSI中的异常也在低密度区域中,依据密度粗检获得伪背景和伪异常,对划分为异常的类标记为1,划分为背景的类标记为0,从而得到初步检测图。
2.2 异常突出正则项约束网络训练
2.2.1 隐藏层对抗损失
本文使用隐藏层对抗损失来生成与给定输入样本相似的潜在样本,提高学习背景生成的能力。编码器Enc和特征判别器Df在隐藏层空间中形成GAN,经过对抗训练使得潜层特征遵循多元高斯分布。通过最小化G和最大化Df实现下述目标
式中,Enc(x)是编码器即生成器G的输出。输入x是服从给定先验分布px的背景样本。训练判别器Df,根据输入数据判别输出值为0 或1,在平衡状态下,服从给定分布的样本在潜层空间的投影将遵循相同的高斯分布。
2.2.2 图像域判别器损失
为了最大化网络对于背景光谱向量的重构能力,建立模型的过程中,本文使用图像域对抗损失约束。解码器旨在从潜在样本生成图像,而视觉判别器Dv则试图区分给定的图像和从解码器Dec重建的图像。当Dv被欺骗时,随机选择的生成的重构图像通常看起来类似于给定的输入。
同样的,训练图像域判别器时,通过最小化解码器输出,将训练输入判别为0 或1,当达到平衡时,认为重构图像和输入图像更逼近。正如式(5)中表示的,此损失函数保证了生成网络生成的背景向量和模型重构的光谱向量更相似,与异常向量的区分度更高。
2.2.3 生成器损失
GAN 模型由生成器和判别器组成,在两者之间进行对抗学习。生成器网络在给定实际高斯分布的条件下,尝试根据以下信息生成样本,即错误样本,并且学习给定背景样本的分布。
生成器与判别器进行单独交替训练,使得生成样本更逼真,背景分布估计更准确。
2.2.4 异常突出正则项约束
为了约束背景与异常之间的距离并扩大其区分程度,本文在损失函数中加入了异常突出正则项约束,然后训练网络获取和保存参数。对于作为模型输入的每个背景光谱向量,期望背景和异常之间的差异尽可能明显。如前所述,通过使用伪背景向量对网络进行训练,AE 将很好地重建背景光谱向量,而在测试期间无法很好地对异常向量进行重建。此外,为了获得更好的性能,本文在设计网络时考虑以下约束条件,提出异常突出正则项约束损失函数来增强背景和异常之间的区分度,用式(7)表示:
式中,给定训练伪背景x,该损失函数旨在使x与输出之间的重构误差最小化的同时,使重构向量与伪异常之间的重构误差最大化,λ是可调节参数。为了最小化异常突出正则项约束损失函数,第1项须最小化,第2项须最大化。各部分损失函数构成总损失函数,共同发挥对目标函数的影响。
2.3 输入HSI测试
测试阶段加载的模型与训练阶段模型是一致的。给定测试高光谱数据作为输入,将训练好的模型重新载入,由于网络是由背景向量作为输入训练得到的,因而能够得到对于背景向量重构好而对异常向量重构不好的输出图像。此外,本文使用高斯统计量在网络输出的基础上区分背景和异常,表示如下:
式中,开操作Ko(U)带有小面积区域的暗连通区域,闭操作Kc(U)移除具有小面积的亮连通区域。因此,|U-Ko(U)|操作能够保留暗连通分量并且|U-Kc(U)|操作能够保留亮的连通分量,从而获得移除了背景的类别显著性图U。
接着,使用简单而有效的非线性背景抑制方法对此结果进行进一步的优化,利用指数函数在正半轴的变化趋势,使背景更大程度上趋于0,表示如下过程如下
式中,S′是抑制S背景后通过本文方法得到的检测结果图,K是通过式(9)得到的类别显著性图。
与原始图像相比,通过模型建立的图像包含更多的区分背景和异常的信息,在空间和光谱域都能表现出更丰富的信息,扩大了异常与背景的区分程度,更有效地检测出抗背景干扰的异常。
3 数据结果处理与分析
3.1 数据集
机场—海滩—城市(ABU)数据集:此数据集由AVIRIS传感器捕获。实验使用了机场,海滩和城市场景中异常类型有所不同的3个城市场景,参考图像尺寸为100×100×224。原始图像的参考图在可视化图像环境(ENVI)软件的帮助下手动标记。由于飞行高度的不同,图像的空间分辨率互不相同。
Cuprite数据集:内华达州铜矿开采区的AVIRIS传感器于1997年采集到Cuprite 数据。在实验中使用了尺寸为125×90×188 的Cuprite 数据的子集,去除了低SNR和吸水波段。
HYDICE 数据集:由高光谱数字图像采集实验(HYDICE)传感器记录的美国加利福尼亚州的一个城市地区数据,该数据的标注中包括有21 个汽车和屋顶的异常像素。图像大小为80×100×175,其中噪声带已被去除。
以上数据集的伪彩色图和真实值参考图分别如图3—5所示,其中图3—5(a)为伪彩图,图3—5(b)为检测参考图。

图3 ABU数据集Fig.3 ABU data set

图4 Cuprite数据集Fig.4 Cuprite data set

图5 HYDICE数据集Fig.5 HYDICE data set
3.2 评价标准
接收机工作特性ROC(Receiver Operating Characteristic)曲线和ROC 曲线下面积AUC(Area Under ROC)是最常用的直观评估异常检测性能的标准。ROC 的(Pd,Pf)曲线通过将这两个概率分别作为横纵坐标绘制曲线,说明真实检测率Pd和错误检测率Pf之间的关系。ROC 曲线在相同的虚警情况下检测概率高时,异常检测器的性能会好于其他检测器。类似地,(Pd,Pf)的AUC值是一种定量评估检测性能的指标,(Pd,Pf)的AUC 值越接近1,检测器就越出色。(Pf,τ)的AUC 值表示由Pf和τ包围的曲线下的面积值,反映检测器错误检测可能性,当虚警率为0时,表示没有背景像素被错误地检测为异常。
3.3 对比实验
为了验证所提算法的有效性,本文将异常检测领域具有较为出色性能的算法与所提算法进行比较,包括AED、ADLR、FrFE(Fractioanl Fourier entropy-based detector)(Tao等,2019)、LSMAD、AAE(Adversarial autoencoder)(Xie等,2019)、LSDM_Mog(Low-Rank and Sparse Decomposition with Mixture of Gaussian)(Li等,2021)。基于空间的异常检测算法AED 在真实的高光谱数据集上表现良好。ADLR 方法通过解混获得丰度矩阵,并在丰度矩阵上利用低秩表达完成异常检测。AAE 方法通过使用AE 和对抗性潜层判别器,在特征层学习正常的背景分布,而AE 尽可能学习具有判别性异常目标和抑制性背景的重建,从而产生初始检测图像,即原始图像和重建图像之间的残差图像,并突出显示异常目标并抑制背景样本。
3.4 参数分析
实验中,我们将最后一层的隐藏节点数设置为30。随着深度的增加,不同数据集关于(Pd,Pf)的AUC值有所变化。在综合考虑所有HSI关于(Pd,Pf)的AUC 值和运行时间的情况下,将网络深度设置为3。此外,批量大小、学习率和衰减率是背景记忆模型中的重要参数,它们对检测精度的影响较小,但对训练速度的影响较大。为了加快收敛,我们根据经验将批次大小设置为2000,将学习率设置为10-4,将衰减率设置为0.9。此外,本文主要网络参数包括可分离性约束损失函数的权重参数和网络的隐藏层数,具体参数设置说明如下。
异常突出约束参数:本文对具有可控变量的不同数据集进行实验,即每个实验仅更改异常突出约束,同时保持其他超参数和网络结构不变。通过对不同损失函数下不同数据集的检测结果进行实验分析,可以得出当λ设置为0.05时,实验数据集可以获得更好的实验结果。
隐藏层数:基于先前GAN 的工作,通过调整超参数(即AE 的网络层数),并将完全连接的层数从1 层增加到5层,获得最适合用于高光谱异常检测的背景记忆生成对抗网络体系结构。实验结果表明当层数设置为3时,即对于所有编码器,解码器和鉴别器,存在3个完全连接的层时,网络的检测性能较好。编码器由具有与输入HSI相同单元数量的输入层,具有20 个单元的输出层和具有500个单元的隐藏层组成。
3.5 实验结果
3.5.1 定量实验
表1 和表2 显示了在5 个高光谱数据集上采用不同方法得到结果(Pd,Pf)的AUC 值和(Pf,τ)的AUC值,分别从客观角度反映检测结果的精度和虚警率。
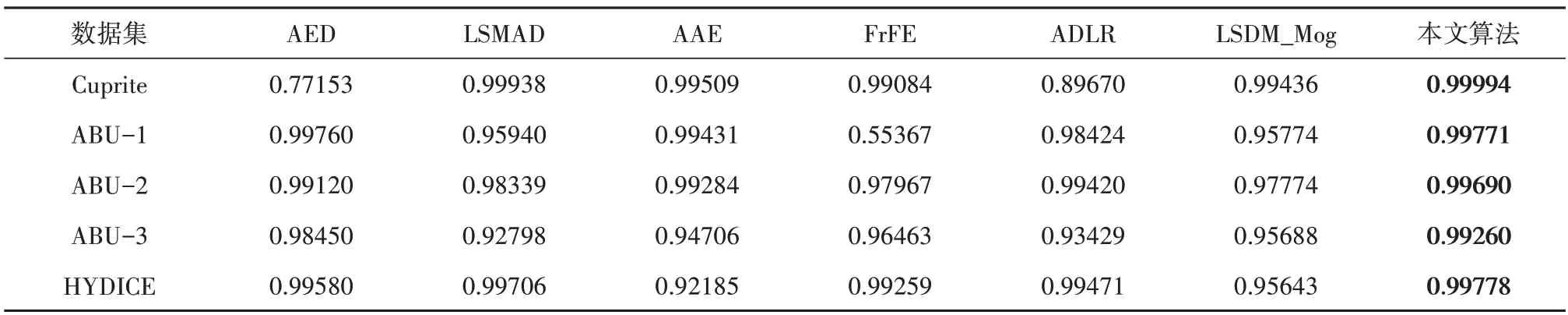
表1 不同方法在各数据集上检测结果的(Pd,Pf)的AUC值Table 1 AUC scores of(Pd,Pf)on different data sets for compared methods
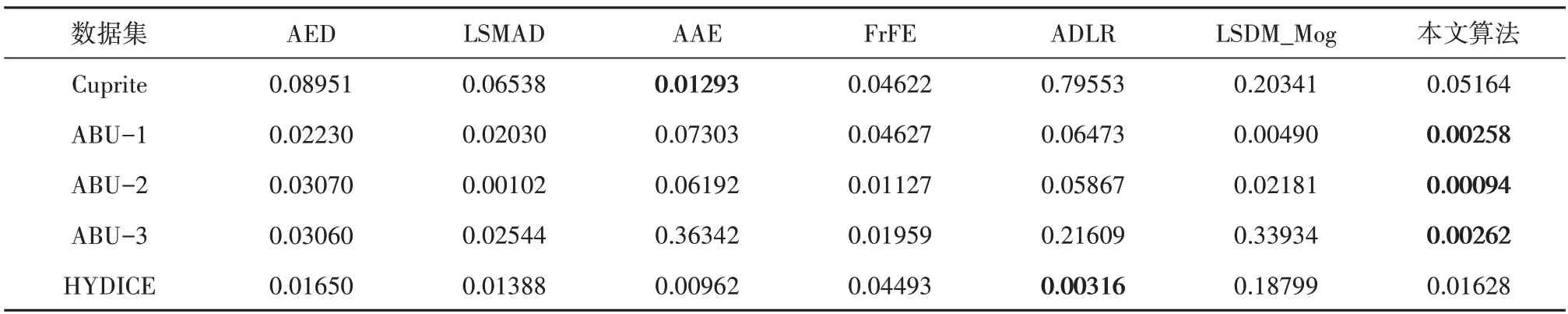
表2 不同方法在各数据集上检测结果的(Pf,τ)的AUC值Table 2 AUC scores of(Pf,τ)on different data sets for compared methods
对于Cuprite 数据集,从检测结果可以看出,AED 和LSMAD 方法(Pd,Pf)的AUC 值均较高,本文方法获得的(Pd,Pf)的AUC 值为0.99994,与其他6 种方法相比性能达到最优。而本文方法(Pf,τ)的AUC 值为0.05164,略高于AAE 方法,可能是由于在提升精度的同时将背景误判为异常。
另外,从检测结果可以看出,AED、AAE 和FrFE方法中虚警的异常情况相对较多。对于ABU-1,所有方法几乎都接近理想值,即异常情况已被很好地检测到并满足检测要求。通过本文方法获得的(Pd,Pf)的AUC 值为0.99771,优于其他算法。对于ABU-2,通过本文方法获得的(Pd,Pf)和(Pf,τ)的AUC值分别为0.99690和0.00094,与其他6 种方法相比是最佳的检测结果。对于ABU-3数据集和HYDICE 数据集,本文方法检测精度为0.99260和0.99994,这意味着表示它能够以较低的误报率检测更多的异常,对于评估异常检测的性能至关重要。为了定量研究并直观地表示检测性能,本文在不同数据集上绘制了不同方法相应的ROC 曲线,如图6(a)—(d)分别是不同算法在Cuprite、ABU-1、ABU-2、ABU-3 和HYDICE 数据集上检测结果的ROC曲线。

图6 不同算法在不同数据集上检测结果的ROC曲线Fig.6 ROC curves for compared methods on different data sets
从ROC 曲线可以得出结论,本文方法对于在不同数据集所得检测结果非常有效,曲线位于左上角附近,对于不同数据集,在相同虚警率情况下精度最高,即本文方法能够获得较高的检测概率和较低的虚警率,具有较好的检测性能。
3.5.2 定性分析
图7 展示了根据对于不同数据集的检测结果进行的背景异常分离性分析。从图7 可以看出,本方法的异常点数值分布范围更加集中,而背景点数值得到了较好的抑制,背景与异常之间的区分度更高。总体而言,本文方法可以更好地区分异常数据和背景数据,性能上优于其他检测方法。

图7 本文算法及对比算法背景异常区分度分析Fig.7 The discrimination analysis of the proposed and compared methods
图8的第一行到第五行分别展示了不同方法在Cuprite、ABU-1、ABU-2、ABU-3 及HYDICE 数据上检测结果的视觉图。从图8 可以看出,对于Cuprite 数据集,与AAE、AED、LSMAD 和FrFE方法相比,本文方法检测结果在视觉上与参考图像较为相似,可以保留异常的基本形状结构。本文方法及LSDM_Mog 方法均能够检测到不同大小和结构信息的异常。LSMAD 算法具有与本文算法接近的检测能力,但更容易受到背景干扰,导致虚警率较高。RX、AED 和AAE 方法能够大致识别异常位置,而异常的形状模糊,其余异常则被漏检,FrFE方法在视觉上丢失较多异常。
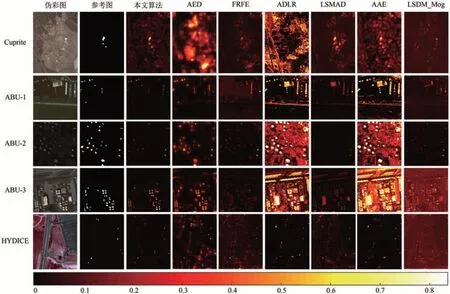
图8 本文算法及对比算法检测结果图Fig.8 Detection results obtained by the proposed and compared methods
对于ABU-1 数据集,从LSMAD 和FrFE 方法的检测结果可以看出,大多数异常与背景在视觉上混合在一起。AED、AAE和ADLR方法可以检测大多数强度高的异常,但不能很好地抑制背景干扰。本文方法能够实现较为完整的异常提取,而LSMAD 和FrFE 并不能完整检测到所有的小异常,LSDM_Mog 算法检测结果具有较为明显的光谱失真。AAE 具有鲁棒性,并且在简单场景下具有良好的检测效果,但由于异常对于背景估计的污染,区分性较差,检测精度较低。
对于ABU-2数据集,图8第3行显示了视觉上的检测结果。具体而言,LSMAD、AAE、ADLR和FrFE 方法仅能检测到一部分异常,本文方法仍然能够较为准确地检测到异常点及边缘,且相比LSDM_Mog 算法更好地保留了光谱信息。相比之下,AED方法混合更多低质量的来自背景的异常。
ABU-3 数据集有许多不同大小和形状的异常对象,AAE 和ADLR 方法与本文方法相比,背景和异常更容易混淆、不易于区分。AED 检测结果较好,和本文方法的检测结果图均包含更多背景和更少异常,表明本文方法可以有效地抑制背景并检测目标异常。综上所述,本文方法在突出异常和抑制背景方面性能优于其他算法,检测图与参考图更接近,视觉结果与定量分析结果一致,检测效果更好。
对于HYDICE 数据集,LSDM_Mog和AED异常形状保留得不是很好,部分异常存在漏检的情况。本文方法可以提供更好的检测结果,但会产生虚警。虽然FrFE 方法结果包含了过多的背景,但是它的性能最接近本文方法,能有效地突出异常,抑制背景。
3.5.3 消融实验
为了分析图像域、特征域判别器以及异常突出正则项约束对最终检测结果的影响,我们对5个真实HSI数据集进行了消融研究,并计算了其关于(Pd,Pf)的AUC 值和关于(Pf,τ)的AUC 值。本文方法在不同数据集不同场景上的消融实验结果如表3 和表4 所示。具体来说有4 种分析情况,在第1种情况中,我们在网络架构中删除图像域判别器;在第2种情况下,在网络结构中删除特征域判别器,系统性能略有提高;在第3种情况下,在原有网络中删除异常突出正则项约束损失函数,检测结果更好,说明引入抑制函数是有效的。最后一种场景是完整的背景记忆模型,性能进一步提高。
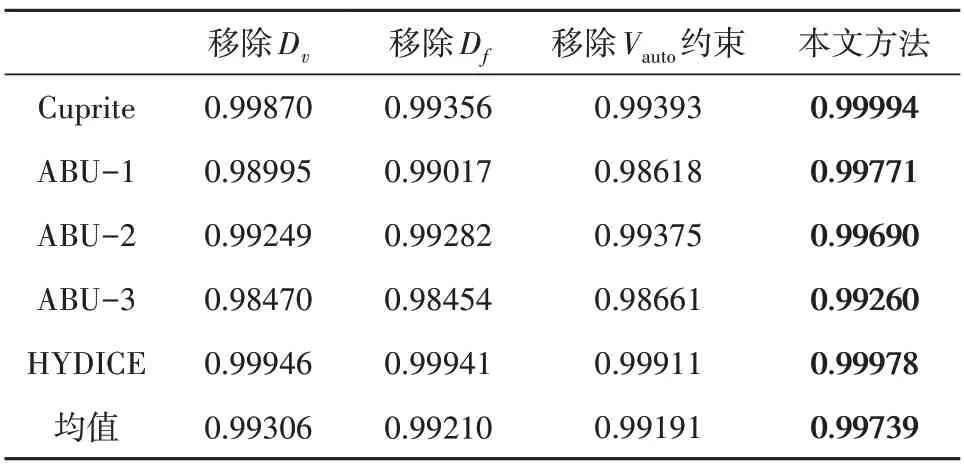
表3 不同数据集消融实验(Pd,Pf)的AUC值Table 3 AUC scores of(Pd,Pf)on different data sets for ablation study
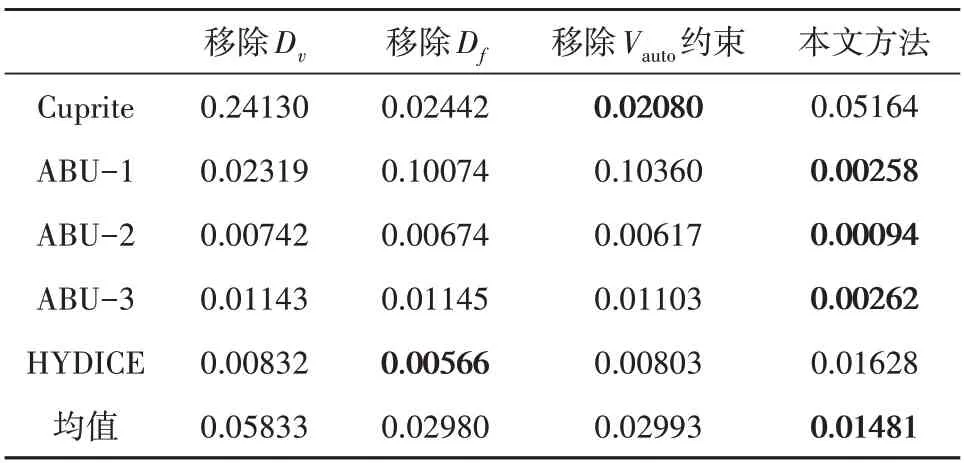
表4 不同数据集消融实验(Pf,τ)的AUC值Table 4 AUC scores of(Pf,τ)on different data sets for ablation study
结果表明,异常突出正则项约束确实有助于异常检测。分别移除图像域判别器、特征域判别器以及异常突出正则项约束获得的关于(Pd,Pf)的AUC值均小于本文方法。
以Cuprite 数据集为例,本文方法的检测精度为0.99994,当本文方法分别移除判别器Dv、移除判别器Df及移除Vauto约束时,检测精度降低,分别为0.9987、0.99356、0.99393,这说明了添加判别器和约束函数提升检测准确度方面的有效性。
此外,为了评估计算复杂度,如表5所示,本文评估了不同方法在不同数据集上的运行时间,其中AED 方法的运行时间最短,本文方法相比于其他方法也有更快的运行时间。
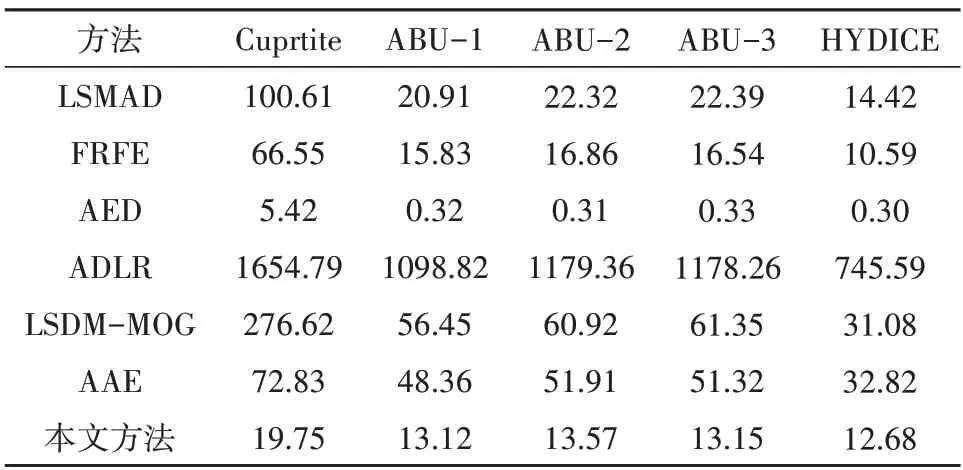
表5 不同对比方法在不同数据集上的运行时间Table 5 Running time of different compared methods on different data set/s
4 结论
本文构建背景记忆生成对抗网络模型,对具有高维性质的背景和异常向量进行重构。不同于传统高光谱异常检测算法,本文以无监督方式自适应地获取伪背景和伪异常向量,解决先验信息缺失的问题。基于弱监督—伪标签学习对高光谱异常向量和背景向量进行建模,不仅对背景数据重构效果好,而且对异常向量重构效果不好,增强了背景和异常之间的区分程度。突出异常正则项约束通过二范数表示异常样本和背景样本二者之间的距离差异,参数调节了背景与异常之间的距离,相对于仅使用重构损失的传统自编码器网络,异常和背景的重构差异性更大。最后采用非线性背景抑制后处理技术,使得相同检测精度下虚警率更低。
定量和定性的实验结果及分析表明,本文算法与其他几种先进算法相比,能够在解决无充分先验信息问题的同时,有效地增大背景和异常间差异,提高检测精度。然而,模型对于多样化数据集的泛化性能较差。如何改进网络结构,提升对于不同传感器采集数据的泛化性,并且在实际场景中合理应用本文算法将是我们未来工作的重点。
