人力资源管理数智化——追求最优方案
2024-04-17肖樱丹
肖樱丹
随着信息技术的快速发展,各行各业都在不断探索以数据驱动业务和决策的管理方式,人力资源管理领域中的数智化概念也应运而生。数智化可帮助人力资源从业者从“后知后觉”转变为“预测先见”,为企业开展人才选、育、用、留、汰提供可测量的决策依据。人力资源管理数智化一改以往以现有数据、经验和直觉做决策的方式,真正用技术算法的数智化为未来做决策。
人力资源数智化的基础是人力资源大数据
提及数智化就不得不提到大数据,我们先来帮人力资源大数据与人力资源数智化做个区分。人力资源大数据是指在人力资源管理中使用大数据技术,从人力资源相关数据中得出有效信息、挖掘价值,实现精细化管理,提高管理质量和效率。而人力资源数智化是指将人力资源数据智能化、自动化、预测化,通过算法或模型分析找出隐含的问题和规律,为决策提供科学依据,提高人力资源管理的针对性和决策能力。根据以上对两个概念的解析,我们在表1中列出二者的主要不同。
人力资源大数据分为三个层级:第一层是描述性数据,如历史的、部门性的活动数据,主要是对组织内部已经发生和正在发生的事情进行描述;第二层是预测性数据,可转换成有价值、可实操的信息数据;第三层是变化性数据,也称为最优化数据,即利用预测性数据得出建设性的决策信息。而人力资源数智化的发展正是源于预测性数据与变化性数据。预测性数据可以帮助预测性分析,变化性数据可以进行变化性分析,而变化性分析则“超越”预测性分析,强调决策选择和劳动力优化,常被用来分析更复杂的数据,进而预测结果,提供决策选择,并展示可能带来的影响。
人力资源数智化的应用
人力资源数智化是一个全新的领域,与传统的人力资源管理模式有很大不同。传统模式下,人力资源管理主要基于经验和直觉;而数智化模式下,人力资源管理则基于数据和分析结果。要了解人力资源数智化如何帮助人力资源管理,能解决哪些棘手问题,我们首先要分析企业人力资源管理需要解决的问题。
●用工计划管理
在用工计划方面,一些企业存在“营养不良”的问题,表现为因用工编制的限制,部门劳动力不足。我们发现导致以上问题的原因有三点:其一,定编分解依据不足,人力资源投放效率受影响;其二,增员计划依据单一,战略、业务与增员计划结合不足;其三,减员计划受限于数据统计能力,预测精度欠缺。以上三点在部分大中型企业里常态化存在,而解决相关问题的抓手便是“人岗匹配”。人力资源数智化可通过数据与算法技术建立模型,然后通过变化性数据指导人岗匹配。在配置管理上,人力资源数智化可解决招聘工作未结合用工计划及人才画像进行精准录用、人员配置没有适合的人岗匹配评价工具可用等问题。
●人才培养与发展
在人才发展模块中,量化人才评估、开展针对性的有效培训,是人力资源管理要重点解决的问题。一些企业虽然围绕业务需求开展了知识、技能、综合素质等方面的培训,但没有考虑岗位业务与人员能力的匹配,培训需求主要来源于技术技能考试、上岗考核、综合素养课程等,忽略了员工个体差异,导致培训针对性不足。同时,受限于分析技术能力,培训工作未能深度挖掘员工的潜在偏好和个体能力缺陷,无法实现课程的个性化设置和匹配。而通过数智化的算法与模型,企业可以找出人岗位匹配中的错位情况,进而锁定培训方向,制订人才培养计划。
●薪酬绩效的激励管理
在绩效管理模块中,部分企业始终在探索员工工作业绩量化评估,以及将业绩评估结果与薪酬挂钩的最优方案,但相关方案的制定需要有一定的数据积累来支撑。同時,很多企业想解决的重点问题是如何动态评估绩效管理制度或激励制度对企业业绩的推动作用,实现薪酬激励效用最大化的管理目标。目前,这块管理工作的数智化多以工作流程切入,将工作动作与工作效能进行强关联,如“滴滴”“美团”等平台通过变化性数据积累,不断优化与调整员工接单与服务的时间和效率,并将接单和服务情况与薪酬激励关联在一起,以达到薪酬激励效用不断提升的管理目标。
人力资源数智化的实现路径
人力资源数智化的实现需要通过三个阶段推动实施。
●存量数据挖掘阶段
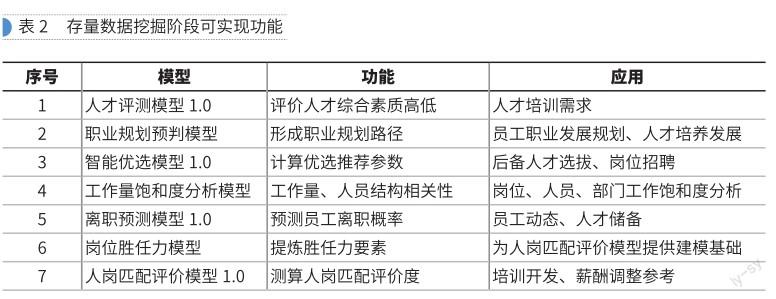
该阶段为第一阶段,主要通过建立存量数据的概要数据层,进行基础建模;通过综合分析和动态分析,实现对数据、模型的综合化、动态化管理。一般情况下,大中型企业在运营过程中会积累大量数据,包括业务方面、日常运营方面的信息,以及人事基础信息和评价评级信息。所以,在此阶段,我们需要对这些存量数据进行盘点,挖掘出这些数据间的基本关系,再结合数据分析技术,通过算法解决人力资源日常管理中的问题和痛点。如运用综合分析法整合多个单一指标维度,通过构建复合指数实现对管理现状的直观监测;运用动态分析法将静态数据基于时间序列进行动态联系,以实现对数据的动态监测,为管理智能化预测提供技术铺垫。在该阶段,根据企业数据种类与形态的不同,可设计实现的模型与应用功能参见表2。
●亚数据层挖掘阶段

该阶段为第二阶段,主要通过整合增量数据和存量数据,提高基础模型的精准度;通过对数据、模型进行聚类、关联、相关性等分析,实现多维度的人力资源分析。经过上一阶段,我们通过系统已经完成了多个复核指数的拟合,同时也建立了一些可用于各类管理决策的数据模型;在此基础上,为引入复核指数,我们就可以在这一阶段构建适用于智能化管理的亚数据层。为什么要进行亚数据层的构建呢?大中型企业在日常运营中生成的基础数据量往往非常庞大,而亚数据层中的复核指数其实就是经过拟合处理的指数,可对评价模型所需要的基础数据信息进行拟合,即用一个指数代替几个指数的信息,企业只需记录这个复核指数的信息,从而为数据库减负,大大提高运算效率。该阶段功能除了建立亚数据层,还包括进一步完善原有应用模型,提高原有分析应用模型的全面性和精确性,以及实现模型新增数据基础磨合,新建应用模型。第二阶段可设计实现的模型与应用功能参见表3。
●数智化管理阶段
该阶段为第三阶段,主要通过整合结构化数据和非结构化数据,全面优化升级基础模型,实现人力资源智能化分析。在这个阶段,数据量和数据处理方法会全面扩充,除了收集各类结构化数据,还包括图片、音频、视频等非结构化数据;可通过整合结构化数据和非结构化数据,引入新型匹配算法,进一步优化前两个阶段所建立的模型,实现人岗动态匹配、培养全景实施、激励智能推选、资源量化投入、人才流失预警的人力资源智能化管理,具体功能参见表4。

人力资源数智化未来的思考
之前,一篇题为《外卖骑手,困在系统里》的文章曾刷屏网络。文章指出,在外卖平台系统的算法与数据驱动下,外卖骑手必须争分夺秒,为此个别骑手甚至违反交规,导致该职业成为高危职业。由于系统算法的不断精确,相同距离的配送时间不断被压缩,如在美团外卖平台上,相同距离的订单,配送时间从几年前的50分钟变成现在的35分钟。
这不禁让我想到企业的目标管理。有时候,部分员工就算能够完成目标也会选择“留一点不完成”。为什么呢?因为他知道,一旦今年完成了目标,那么明年的目标一定会增长,但如果不完成的话,明年目标可能会保持今年的水平,或仅小幅度增长。
企业中的这个现象和外卖系统基于算法不断优化配送时间有异曲同工之处。外卖系统通过算法来测算骑手用多少时间可以完成多少公里数的配送,完不成就扣錢,完成率达97%便开始加钱,如此一边扣钱一边奖励,迫使骑手不断提高能效。需要注意的是,系统计算的是600万人的人效,通过深度计算把人“用到极致”,将人的效能“发挥到极致”。写字楼电梯间里,美团的广告语不断传出:“美团外卖,送啥都快!”但我们一定要知道,外卖系统的设计基础不是技术也不是算法,而是人、是思维,这个系统的基础是企业决策的方向。那么,在数智化的算法面前,我们究竟怎样才能把握有关工作的平衡呢?是通过人力资源数智化来追求人力效能的极致,还是通过人力资源数智化在不断优化人力效能的同时也关注为员工们带来工作的幸福体验?相信这个答案不在于算法,而在于我们自己,在于我们一开始用怎样的思维去定义系统算法。

关注技术变革,更关注思维变革;推进科技创新,但不模糊人本情怀,这才是人力资源管理的初心。永不停滞的探索是人力资源从业者向人、向科技的最高敬意——追求最优化的方法,而不是追求最优化的人。
未来,人力资源管理数智化将会进一步赋能于企业,使企业不断优化管理用人的方法,不断提高人效。
作者单位 澳门科技大学商学院广州锐库企业管理咨询有限公司
