引入环境变量的香格里拉市高山松碳储量估测*
2024-04-12殷唐燕张加龙廖易王飞平曹军和云润陈朝情肖庆琳
殷唐燕,张加龙,廖易,王飞平,曹军,和云润,陈朝情,肖庆琳
(1.西南林业大学 林学院,云南 昆明 650224;2.西北农林科技大学 机械与电子工程学院,陕西 杨陵 712100)
森林作为生物圈中最大的陆地碳库,其储存着全球约80%的地上碳储量和40%的地下碳储量,在全球碳循环中发挥着不可或缺的作用[1-3]。森林地上碳储量能够对合理的森林资源保护与管理提供依据,是固碳能力的重要参考指标[4-5]。随着“碳达峰、碳中和”目标的提出,如何准确、有效地估算森林碳储量对于碳监测和降低大气CO2浓度具有重要意义。
相较于传统的森林碳储量测算方法[6],遥感估测森林碳储量因具有快速、成本低和大范围研究等优点被广泛应用于林业领域[7-8]。常用于森林碳储量估测的预测变量有纹理因子、植被指数和信息增强因子等[9-10],此外,部分学者在估测森林碳储量时还考虑了地形和气候等环境因素,并发现环境变量能在一定程度上提高模型的估测精度。蒋云姣等[11]研究发现海拔、坡度、亮度指数、湿度指数等是影响森林地上部分生物量的重要环境因素。何潇等[12]通过对比林分生物量基础模型和含气候变量的林分生物量模型的精度,发现气候变量能明显改善模型效果。选择合适的变量筛选方法可以提高模型精度、降低运算时间和模型的复杂性[13-14]。香格里拉市位于青藏高原横断山区,地形结构复杂,有着多种气候类型,区域内树木的生长状况及树种的空间分布容易受到环境因素的影响,从而影响到森林碳储量,因此,引入环境变量进行高山松碳储量估测尤为重要[15]。
高山松(Pinusdensata)在香格里拉分布广泛,具有重要的经济价值和生态价值,对该地区的碳收支平衡具有重要影响。目前,已经开展了较多遥感估测高山松生物量/碳储量的研究[16-17],王书贤等[18]对高山松生物量和遥感因子进行空间自相关和异质性分析,发现高山松变化主要受人为干扰、立地条件影响。曹军等[19]和廖易等[20]通过建立不同变量组合的高山松估测模型,发现引入地形可以显著提高高山松地上碳储量的估测精度。关于引入气候、土壤等环境变量构建高山松遥感估测的相关研究较少。基于此,研究以Landsat TM/OLI影像为遥感数据源,结合香格里拉市的森林资源连续清查数据、气象数据等,采用Pearson相关性法、Kendall’s τ相关性法、Spearman相关性法、距离相关性法和决策树法对预测变量进行筛选,构建随机森林模型,并在模型中引入环境变量(气温、降水、年日照时长、年均温、人口密度、地表温度和土壤湿度),以探究不同变量筛选方法及引入环境变量是否能提高地上碳储量建模精度,为高山松碳储量建模精度的提高提供新思路。
1 研究区与方法
1.1 研究区概况
香格里拉市位于云南省迪庆藏族自治州东部、青藏高原的东南端和横断山脉的东侧,地处26°52′~28°52′N,99°20′~100°19′E,平均海拔为3 459 m。受地形和西南季风影响,该区干湿季节分明,年均温为5.4℃,年均降水量为268~945 mm,无霜期为129~197 d。自然资源丰富,森林覆盖率达75%,区域内优势树种有高山松、冷杉(Abiesfabri)、云杉(Piceaasperata)、云南松(Pinusyunnanensis)等[21],见图1。

图1 研究区概况图
1.2 数据来源与处理
1.2.1 森林资源连续清查数据
样地数据来源于1987、1992、1997、2002、2007、2012、2017年香格里拉市的森林资源连续清查数据,共136个高山松样地数据,样地按照6 km×8 km的网格分布,面积为(28.28 m×28.28 m)0.08 hm2。
首先利用样地平均树高和胸径计算平均生物量(t),再根据样地平均生物量和样地高山松株数计算样地总生物量,高山松单木异速生长方程[22]见公式①。根据推算得到的每公顷生物量(t/hm2)乘以含碳率得到样地碳储量[23],具体见公式②。高山松的含碳率将根据《森林生态系统碳储量计量指南》中推荐的高山松含碳率(0.501)确定。
W=0.073×D1.739×H0.880
①
C=W×CF
②
式中:W代表高山松地上生物量,D代表胸径,H代表树高,C代表碳储量,CF代表含碳率。
在得到高山松碳储量数据后,通过剔除碳储量过小以及离群值后,剩余124个样地用于构建高山松地上碳储量模型,详情见表1。
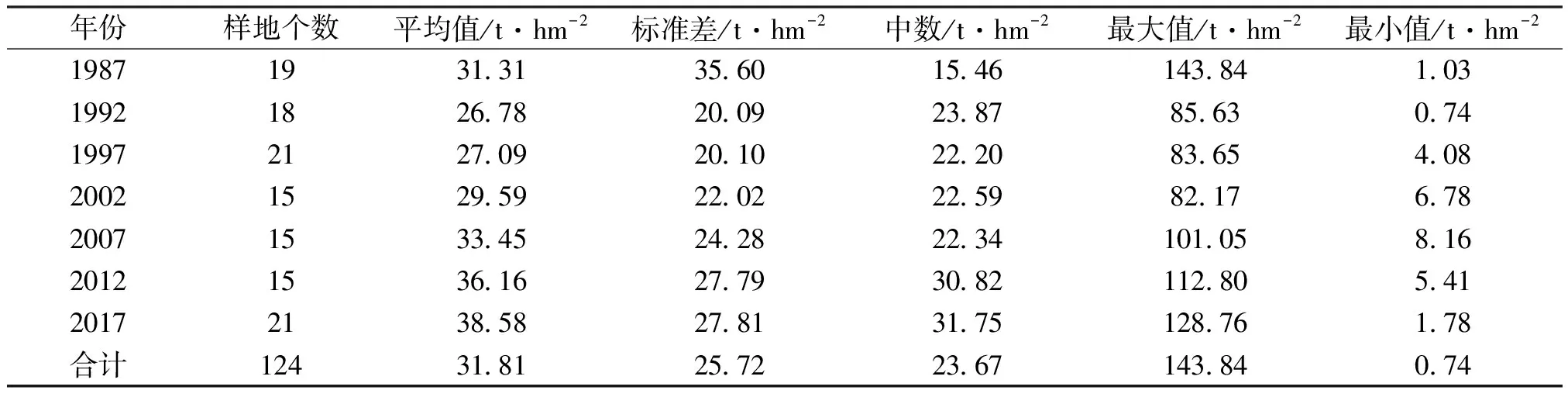
表1 样地碳储量统计结果

表2 预测变量
1.2.2 Landsat数据
从http://glovis.usgs.gov/收集了1987、1992、1997、2002、2007、2012、2017年的Landsat TM/OLI遥感影像,条带号分别为131/041、132/040、132/041,共7期21景,影像分别经过辐射定标、大气校正、镶嵌、裁剪等预处理。
1.2.3 环境变量数据
研究所选择的环境变量包括气象数据(年均降水、气温、干燥度、潜在蒸散发)、人口密度、地表温度和土壤湿度。
气象数据来源于国家青藏高原科学数据中心(http://data.tpdc.ac.cn)。人口密度数据来源于官方网站(https://www.WorldPop.org/),数据集只有2002、2007、2012和2017年的人口密度数据,1987、1992和1997年的人口密度数据将通过《云南省统计年鉴》和《中甸县志》计算得到人口密度。为统一数据格式,将气象数据通过重采样至30 m分辨率。地表温度采用单窗算法[24]反演得到,土壤湿度使用简化后的温度植被干旱指数(TVDI),利用地表温度和归一化植被指数(NDVI)得到[25],与土壤水分状况直接相关[26]。
1.2.4 地形数据
从地理空间数据云平台(http://www.gscloud.cn/)下载分辨率为30 m的DEM数据,处理后提取海拔、坡度和坡向数据作为地形变量加入到预测变量进行筛选。
1.3 研究方法
研究基于连清样地数据、Landsat TM/OLI影像数据和地形数据进行相关处理后提取预测变量,从Landsat TM/OLI影像数据和环境数据提取七种不同环境变量,使用五种变量筛选方法对预测变量进行筛选,确定最优的预测变量组合直接引入环境变量建立随机森林模型并评价精度,选择引入环境变量后最优的模型进行高山松碳储量反演制图。技术路线见图2。

图2 技术路线图
1.3.1 预测变量选择
研究使用的预测变量包括原始单波段、波段组合、植被指数、纹理因子、信息增强因子和地形变量,其中纹理因子提取了影像第1、2、3、4、5、7波段的3×3、5×5、7×7、9×9、11×11、13×13、15×15、17×17、19×19窗口的9种纹理。详见图2。采用Pearson、Spearman、Kendall’s τ、距离相关性法以及决策树法分别选取与碳储量显著相关的前10的预测变量。使用ArcGIS软件以样地中心点为基础,提取该点与Landsat影像对应位置的像元值。
最佳变量组合是提高建模精度的关键。Pearson相关性法能够描述变量X与变量Y之间的线性相关性,是特征变量筛选最常用的方法,适用于正态分布的连续变量。Spearman相关性法[27]和Kendall’s τ相关性法[28]都是利用非参数的思想描述两个有序变量之间的相关性强弱,对非线性关系更为敏感。距离相关性法[29]是描述任意变量间独立性的度量关系数越大,越能说明预测变量越重要[30]。决策树法能利用平方误差对分裂变量进行选择[31],并生成二叉树,将目标变量区分出来,具有运算速度快、结果易理解和解释等优点。
1.3.2 模型构建
研究采用随机森林(random forest,RF)方法进行高山松碳储量模型的构建,将124个样本中的80%(99个)用于模型的拟合,20%(25个) 用于模型的检验。
随机森林是改进后的决策树算法,适用于多数分类与回归的问题,是由一系列的决策树组成[32]。通过Python语言的Sklearm工具包中的“Random forest”算法进行建模分析,在构建过程中需要对运行参数进行调整,最终确定参数范围:最大迭代次数为50~300,最大深度为15~20,叶节点最少样本数以及内部节点再划分所需最小样本数采用默认值,分别为1和2。
1.3.3 模型精度评价
使用决定系数(R2)、均方根误差(RMSE)、相对均方根误差(rRMSE)、预测精度(P)作为模型精度评价指标。
③
④
⑤
⑥

2 结果与分析
2.1 预测变量筛选结果
通过对预测变量等进行筛选,结果见表3。各方法选择的变量组合各不相同,Pearson和距离相关性法所选择的变量都为纹理因子,并且有7个相同的变量,相关性最高的为15×15窗口第7波段的角二阶矩(0.285**);Spearman和Kendall’s τ相关性法所筛选的变量相同,其变量包含9个纹理因子和1个植被指数,相关性最高的变量为ND54,其相关性分别为-0.303**和-0.203**;决策树法筛选的变量则包含了多种类型的变量,包含7个纹理因子、1个波段组合因子、1个植被指数和1个信息增强因子,重要性最高的为19×19窗口第5波段的偏度(13.04%)。
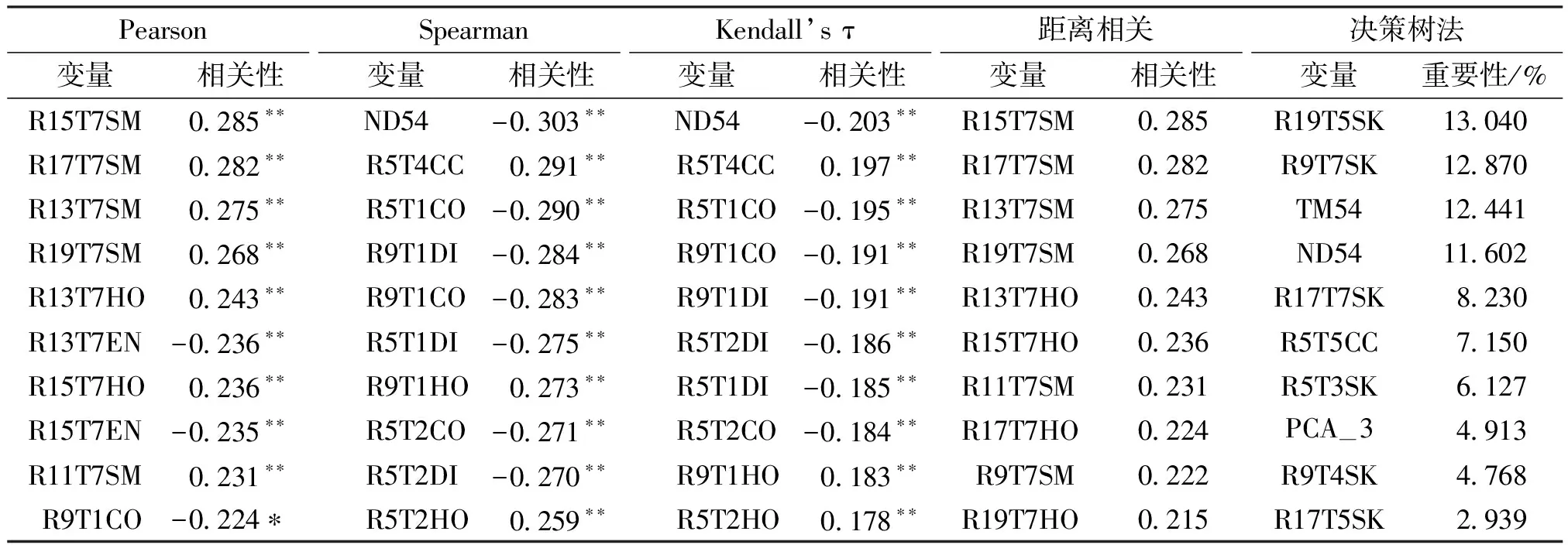
表3 不同变量选择方法及其相关性(重要性)

表4 不同变量组合模型建模效果
通过分析发现纹理因子相较于其他因子是较为重要的因子,通过相关性发现,第1、5和7波段的信息随高山松碳储量具有重要影响,纹理信息中的偏度(SK)、角二阶矩(SM)、均一性(HO)和相异性(DI)的占比较多。
2.2 高山松碳储量估测模型构建
2.2.1 基于不同变量组合的建模结果
经过5种筛选方法得到的变量组合分别进行RF建模。不同变量组合的RF建模结果如图4所示,基于决策树法选择的变量组合建立的RF模型精度(R2=0.845,RMSE=10.076 t/hm2,rRMSE=29.251%,P=0.747)明显优于其他变量组合,相较于Pearson相关性法,R2提高了4.20%,RMSE降低了11.31%,rRMSE降低了1.92%,P提高了0.02%,其预测得到的高山松碳储量与连清样地的计算得到的碳储量更为接近(图3)。基于决策树法的选择的变量组合建模精度最高,其余变量组合建模精度依次为Spearman、距离相关、Kendall’s τ、Pearson相关性法。

图4 不同海拔范围内地表温度对碳储量的影响
由此可知不同变量筛选方法能够影响模型精度,使用决策树法筛选的变量组合的建模精度明显优于其他方法。因此,采用决策树法选择的变量组合进行引入环境变量的建模。
2.2.2 引入不同环境变量的建模结果
引入环境变量后模型效果见表5。从建模结果看,引入地表温度的模型R2提升效果最好,为0.893,RMSE为8.371 t/hm2,rRMSE为22.863%,P为0.812。其余依次为降水量、土壤湿度、潜在蒸散发和干燥度,引入人口密度的模型提升效果最低,R2为0.863,RMSE为9.516 t/hm2,rRMSE为27.396%,P为0.761。相较于决策树法筛选的变量组合模型效果,引入地表温度后模型R2提高了4.80%,RMSE降低了1.71 t/hm2,rRMSE降低了6.388 %,P提高了6.5%。

表5 引入不同环境变量建模效果
将海拔分为1 500~3 000 m、3 000~3 200 m、3 200~3 400 m、3 400~3 700 m、3 700~3 900 m共5个梯度探究范围内高山松碳储量和地表温度的关系(图4)。在1 500~3 000 m、3 000~3 200 m、3 400~3 700 m和3 700~3 900 m海拔范围内,地表温度和高山松碳储量呈明显正相关关系,地表温度增加,高山松碳储量也随之增加,在3 200~3 400 m内地表温度对高山松碳储量的影响不明显,可以忽略地表温度对高山松碳储量的影响。总体而言,地表温度对高山松碳储量的影响呈正相关。
引入环境变量后,各模型效果都有不同程度的提升,能够在一定程度上减少模型的误差。因此选择基于决策树法筛选的变量组合并引入地表温度进行香格里拉市高山松碳储量反演。
2.3 引入地表温度的高山松碳储量反演结果
通过引入地表温度的RF模型结合已有的香格里拉市高山松分布范围对1987—2017年共7年的高山松碳储量进行反演制图(图5)。高山松在香格里拉市的分布范围较广,碳储量变化呈现“增加—减少—增加”趋势,1987—2002年碳储量逐渐增加,2002—2012年碳储量出现下降,2012—2017年碳储量出现大幅增加。最终得到1987、1992、1997、2002、2007、2012、2017年香格里拉市高山松碳储量估测值分别为3 375.823×104t、3 500.993×104t、3 563.118×104t、3 610.929×104t、3 555.959×104t、3 628.858×104t和4 027.089×104t,与岳彩荣[33]基于遥感估测香格里拉市高山松碳储量估测结果(4 895.30×104t)具有可对比性。30年间森林碳储量是处于上升趋势,共增加了651.266×104t。将1987和2017年的碳储量变化数值分为四个等级,分别为显著减少(<-20 t/hm2)、少量减少(-20~0 t/hm2)、少量增加(0~20 t/hm2)和显著增加(>20 t/hm2),从下图可以看出碳储量变化整体呈现少量增加。
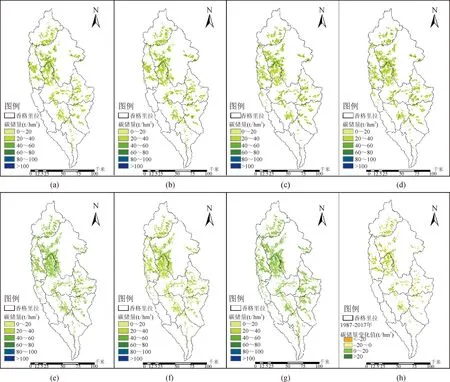
图5 各年份高山松碳储量分布
3 讨论与结论
3.1 讨论
(1)决策树法筛选变量组合的可行性
变量筛选的结果好坏会直接影响模型的质量,选择合适的建模变量是准确估测碳储量的关键步骤。本研究基于5种变量筛选方法选择预测变量,从不同的变量筛选方法来看,发现决策树法筛选出的变量组合模型精度优于其他筛选方法,这与Jiang等[34]和王迪等[35]的研究结果一致,机器学习算法在变量筛选中具有可解释强、使用方便和准确率高的优点。在实际运用中,没有最好的方法,只有最合适的方法。决策树法筛选的变量结果包含7个纹理因子,1个植被指数因子,1个信息增强因子和1个波段组合因子,纹理因子中有6个为纹理信息中的偏度(SK),纹理因子普遍表现出与高山松碳储量较高的相关性,这与相关学者的研究[36-37]一致,纹理因子相较于其他变量能够较为准确的描述高山松的形态特征,对提高高山松的建模精度具有积极影响。
(2)光学遥感在估算森林碳储量方面的局限性
研究利用RF模型进行高山松碳储量估测,结果表明,RF模型预测碳储量与样地实测碳储量结果较为接近,已有大量学者研究[38-39]证明,RF模型在高山松的资源估测方面具有很强的适用性。但与相关学者的研究[40-41]出现相同问题,在碳储量预测中存在低值高估和高值低估的现象,主要是由于Landsat数据为光学数据,空间分辨率较大,相较于高分辨率数据在区域尺度上的建模精度较低,罗洪斌等[42]以LiDAR和Landsat8 OLI对橡胶林地上生物量进行估测,发现联合LiDAR和Landsat8 OLI的模型估测精度较高,且Landsat8 OLI数据的模型精度低于单一的LiDAR数据。
(3)建模过程中引入环境变量的必要性
在本研究中,引入不同的环境变量后建模效果都得到了提升,特别是在引入地表温度后,建模效果提升最为显著。这主要是由于地表温度影响了土壤中的有机质分解速率,从而影响了树木的生长,已有研究发现,随着海拔的增加,温度逐渐降低,有机质的分解速率也随之降低[43-44],地表温度、湿度等环境变量与生物量之间存在密切关系[45],香格里拉地区位于低纬度、高海拔地带,地势复杂,山地纵横,因此地表温度对高山松的碳储量的影响更为明显。之前的研究也表明,气候变量和植被指数等因子相较于反射率等因子对于森林生物量的估测更为重要[15],在构建高山松生物量模型的过程中引入气候变量,高山松生物量模型的R2和P均有所提高[46]。在本研究中,仅选择了部分环境变量进行分析与高山松碳储量之间的关系,在未来的研究可以进一步探究更多环境变量对高山松碳储量的影响。
3.2 结论
研究从Landsat TM/OLI遥感影像和地形数据中提取预测变量,结合样地数据,建立RF模型估测香格里拉市高山松碳储量,并引入环境变量,对比模型精度,通过最优模型反演高山松碳储量。结果表明:(1)在筛选出的变量中,纹理因子与高山松碳储量显著相关,其相关性最高;(2)不同变量筛选方法所选择的变量组合对建模效果有较大影响,其中通过决策树法筛选的变量组合模型表现最好,预测得到的高山松碳储量与连清样地计算得到的碳储量更为接近,相较于精度最低的Pearson相关性法,R2提高了4.20%,RMSE降低了11.31%,rRMSE降低了1.92%,P提高了0.02%;(3)引入地表温度的RF模型效果明显优于引入其他环境变量的RF模型,其R2为0.893,相较于基于决策树法选择的变量组合的模型拟合精度提高了4.80%;(4)高山松碳储量在30年间的变化十分明显,共增加了651.266×104t,其变化呈现为“增加—减少—增加”趋势。
