一种建立在GPT-2模型上的数据增强方法
2024-04-09张小川陈盼盼邢欣来杨昌萌滕达
张小川,陈盼盼,邢欣来,杨昌萌,滕达
(重庆理工大学 两江人工智能学院, 重庆 401135)
句子分类[1](sentence classification,SC)是最基本和常见的自然语言处理(natural language process,NLP)任务之一,广泛应用于NLP的很多子领域,如意图识别、情感分析、问题分类等。当给定一个句子作为输入时,其任务是将其分配给一个预定义标签。深度神经网络往往需要大规模的高质量标记的训练数据来实现高性能,然而在特定领域,由于人工标注数据集代价昂贵,常常只有少量样本可供使用。本文研究在数据匮乏情况下的句子分类任务准确率较低的问题,训练数据的不足使得句子分类任务模型无法得到有效的训练,从而导致泛化能力差。为解决这一问题,数据增强是一种有效的方法。
通常,数据生成的语义一致性和多样性对目标任务至关重要[2],语义保留即前后语义保持一致是数据增强最基本的要求,训练样本的丰富表达能使神经网络更好地学习权重。一些学者的研究工作已经开始注重数据的多样性和质量。如在计算机视觉中,文献[3]使用代理网络来学习如何增强多样性。孙晓等[4]利用生成对抗网络生成同一个人的不同面部表情实现数据增强。NLP中的一些研究[5]对原句进行随机替换、随机交换、插入和删除操作实现增强数据的多样性,为了避免简单数据增强方法(easy data augmentation,EDA)方法引入过多噪声,一种更简单的数据增强方法(an easier data augmentation, AEDA)[6]将随机插入token改为随机插入标点符号,一定程度上缓解了噪声引起的语义偏差问题,然而随机插入标点符号可能会不恰当地断句,语义保留和多样性仍无法同时有效控制。随着大规模预训练语言模型的问世,一些研究将其应用于数据增强,Anaby等[7]提出基于语言模型的数据增强方法(language-model-based data augmentation, LAMBADA),采用训练数据微调GPT-2模型[8],在训练过程中将相应的标签拼接到每个样本,以便为该类生成新数据,在句子分类方面取得了显著的改进。然而,该方法采用top-k和top-p采样的方式增加多样性,这种方式很有可能会导致累计误差的产生,使得生成句子质量低下。
从本质上讲,语义一致性和多样性的目标其实是相互冲突的,即生成多样性高的样本更可能导致语义发生变化,因此,需要同时考虑多样性与语义一致性,对生成数据进行控制,得到较为平衡的数据。本文提出一种引入惩罚项的数据增强方法(punishing generative pre-trained transformer for data augmentation, PunishGPT-DA),用于生成增强数据来改进句子分类任务。此方法的数据增强过程建立在预训练语言模型GPT-2基础上,通过设计惩罚项、超参数,使用双向编码器表征模型(bidirectional encoder representations from transformers,BERT)[9]作为过滤器完成数据增强。实验结果表明了该方法的有效性。
1 数据增强相关工作
从增强数据的多样性来看,数据增强方法可以大致分为基于复述的方法、基于噪声的方法和基于采样的方法3类。
基于复述的方法包括在词汇、短语、句子层面的重写。Zhang等[10]首先利用词库(a electronic lexical database, WordNet)替换句子中的同义词应用于数据增强;条件BERT(conditional bert, CBERT)[11]掩盖句子的部分字符,由BERT生成替换词;Jiao等[12]使用数据增强来获得特定任务的蒸馏训练数据,利用BERT将单词标记为多个单词片段,并形成候选集;回译以生成的方式重写整个句子,被应用于低资源句子分类[13],使用不同的二级语言提高了分类精度,Hou等[14]通过L层变换器对串联的多个输入话语进行编码,利用重复感知注意和面向多样性的正则化生成更多样化的句子。Kober等[15]使用对抗生成网络(generative adversarial network, GAN)生成与原始数据非常相似的样本。
基于噪声的方法添加微弱噪声,使其适当偏离原始句子。EDA[5]通过随机插入、删除、替换、交换操作得到增强数据。Peng等[16]通过删除对话语句中的槽值来获得更多的组合;Sahin等[17]通过依赖树变形对句子进行旋转。Sun等[18]将混合技术应用到基于Transformer的预训练模型中进行数据增强(Mixup-Transformer),将Mixup与基于Transformer的预训练结构相结合,进行数据增强;Feng等[19]在提示部分随机删除、交换和插入文本字符,用于微调文本生成器;Andreas[20]提出了一种简单的数据增强规则,通过采用出现在一个类似环境中的其他片段替换真实的训练样本的某个片段,来合成新的样本。Guo等[21]提出一种序列到序列模型的混合方法(sequence-level mixed sample data augmentation,SeqMix),通过组合训练集中的输入输出序列来创建新的合成样本。丁家杰等[22]通过对原始数据集中的噪声进行处理扩充数据集,在问答任务上实现了良好效果。
基于采样的方法掌握数据分布,并在其中采样新的样本。大型语言模型(large language models, LLMs)的出现为生成类似于人类标注的文本样本创造了新的条件。LLMs的参数空间允许它们存储大量知识,大规模预训练使得LLMs能够编码用于文本生成的丰富知识。如生成式预训练语言模型(generative pre-trained transformer, GPT)系列,GPT~GPT-3[8,23-24]采用预训练+微调的方式,其中预训练阶段通过大规模的无标注数据对模型进行训练,使其学习到通用的语言表示和语义理解能力,微调阶段利用有标注数据进行监督学习,使模型能够适应特定的任务要求,提高性能和准确度。GPT系列目前已经发展到4.0, 聊天生成预训练转换器(chat generative pre-trained transformer, ChatGPT)遵循指导生成预训练转换器(instruct generative pre-trained transformer,InstructGPT)[25]的训练方式,利用带有人类反馈的强化学习(reinforcement learning from human feedback, RLHF),使其在对话领域能够对输入产生更丰富的响应。这些最先进的模型也被广泛地用来进行数据增强,Abonizio等[26]通过连接样本中的3个随机token作为GPT-2模型生成阶段的前缀生成样本。Kumar等[27]研究了不同类型的基于Transformer的预训练语言模型,表明将类标签处理到文本序列为微调预训练模型进行数据增强提供了一种简单有效的方法;Bayer等[28]设计了一种基于GPT-2的方法,通过设计不同的前缀分别处理短文本和长文本的生成,在短文本任务和长文本任务上都取得了很好的改进。类似的,Claveau等[29]使用特定于类的数据微调GPT-2模型,并从原始文本中输入一个随机单词进行生成。然后应用分类器对生成的数据样本进行过滤。Liu[30]冻结GPT-2模型softmax之前的层,采用强化学习对softmax之后的层进行微调。随着ChatGPT的问世,Dai等[31]提出了ChatAug,利用ChatGPT为文本生成增强数据,获得了显著提升。
引入噪声的方法可以有效提升数据的多样性,利用预训练语言模型的数据增强方法可以更好地学习到语言规律和语义信息,因此,基于上述工作,本文提出惩罚生成式预训练语言模型的数据增强方法(punishing generative pre-trained transformer for data augmentation, PunishGPT-DA),通过设计损失函数微调预训练语言模型GPT-2,有效保证增强数据的质量。
2 PunishGPT-DA
2.1 方法概述
句子分类是一种基于句子数据进行分类的任务,属于监督学习问题的一个实例。给定训练集Dtrain=,包含N个训练样本,其中xi是由{xi1,xi2,···,xip}组成的文本序列,包含p个字符,li∈{1, 2, ···,q}表示在含有q个标签的集合中,样本xi对应的标签。xi∈X,X代表整个样本空间,假设对于所有N,存在函数f,使li=f(xi),监督学习的目标是在仅给定数据集Dtrain的情况下在整个X上近似f,从Dtrain的域推广到整个X,即在Dtrain上训练分类算法F,使其能够近似f,然而如果Dtrain非常小,将显著地影响算法F的性能。数据增强试图通过合成额外的训练数据来解决这个问题,给定训练集Dtrain和算法F,本文的目标是生成Daug=,Daug=Dtrain∪Dfilter,其中Dfilter是方法每次迭代后生成的数据,Daug是最终数据集,包含T个样本,yj是由{yj1,yj2,···,yjm}组成的文本序列,包含m个字符,对应标签为lj。
为此,本文提出了一种面向句子分类的数据增强方法PunishGPT-DA。PunishGPT-DA由生成器Gθ和过滤器F2个模块组成。图1说明了本方法的步骤:1)通过改进的损失函数微调生成器的语言模型,训练生成器学习在原始句子的基础上合成新样本,得到参数被微调之后的生成器Gθ。2)对Dtrain进行处理作为Gθ的输入生成数据Dsyn,Dsyn相较于原损失函数训练出的生成器生成的数据拥有更高的多样性,但也不可避免地引入了噪声。3)针对此问题,采用原始数据Dtrain微调过滤器F,将每次迭代生成的样本Dsyn由F过滤,丢弃低质量的样本,得到过滤后的增强样本Dfilter,Dfilter并入原始数据集中作为新的Dtrain进行下一次迭代,经过一定次数的迭代后得到最终的数据集Daug。
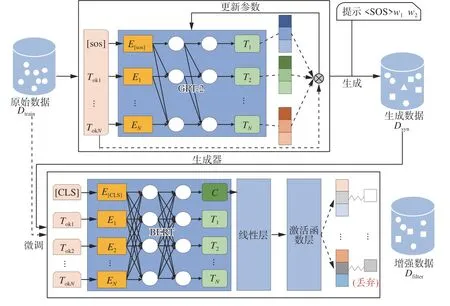
图1 PunishGPT-DA数据增强过程Fig.1 PunishGPT-DA data augmentation process
2.2 生成器
PunishGPT-DA采用预训练语言模型GPT-2生成数据,GPT-2是一个在海量数据集上训练的语言模型,采用“预训练+微调”的二段式训练策略,它利用庞大的语料库进行预训练,语料库被处理成由token组成的长序列,由U=w1,w2,···,wj,···,wT表示,生成模型采用无监督自回归训练的方式,以最大化生成目标序列的概率为目标,根据极大似然估计,可以最大化目标序列U出现的概率,即最大化P(U),根据条件概率的链式法则,可以将生成目标序列的概率表示为条件概率的乘积:
将式(1)取对数并加上负号,得到负对数似然损失函数为
在数据增强任务中,同预训练一致,以句子自身指导模型的微调,即以最大化生成目标序列的概率为目标,因此,以负对数似然函数作为损失函数的生成模型鼓励生成与原数据相似的句子,使生成的文本趋于重复和“枯燥”,当以此为目标训练得非常好时,甚至会生成与输入句子完全一致的样本数据。
为了关注生成数据的多样性,本文引入惩罚项来中和现有的损失函数,同时为了平衡多样性与语义一致性,引入超参数α,改进后的损失函数为
式(3)是一种加权损失函数,由Jθ和exp(-Jθ)2部分组成。其中Jθ,即式(2)是负对数似然损失,用于衡量生成的序列和目标序列之间的差距;exp(-Jθ)将其视为惩罚项,用于惩罚过度相似的生成结果,这意味着,如果生成器产生与目标序列中过于相似的token,它将受到惩罚。本文拟通过添加exp(-Jθ),使模型会在给定上下文条件下,根据语言的语法和语义规则,更加关注可能性较小但仍然有一定意义与合理性的输出。这些输出可能是预测概率较小但仍然合理的单词、短语、句子结构等,在某些情况下可能会提供更有趣、更具创造性的文本。α是一个用于控制Jθ和exp(-Jθ)2部分在损失函数中重要程度的超参数,当α较小时,exp(-Jθ)的影响更大,从而鼓励生成多样性更高的样本。相反,当α较大时,Jθ的影响更大,从而鼓励生成语义一致性更高的样本。因此,式(3)可以看作在保证生成序列准确的基础上,通过惩罚过度自信的生成结果来鼓励生成更多的多样性,通过调整α的值,可以在一致性和多样性之间进行平衡,获得高质量的生成结果。
此外,在预测阶段,通常采用序列的前i个字符作为前缀提示后续词语的生成,然而,Dtrain中存在多个序列前i个字符相同,以相同的前缀作为提示会导致原本不同标签的2个句子对应的增强样本可能相同,使得增强样本语义标签不明。因此,本文为每条训练数据添加了数字序号作为该数据的唯一标志,数字序号随训练数据一起参与训练。在预测阶段,数字序号与前i个字符一起作为前缀,确保了前缀的唯一性,并为生成器提供了额外的上下文,形式为(〈SOS〉,w1,w2,···,wi),其中〈SOS〉是数字序号,(w1,w2,···,wi)是样本的前i个字符。这种操作确保了增强样本彼此不同,但仍然基于实际数据。
2.3 过滤器
使用增强样本的一个障碍是它可能引入的噪声和误差。虽然在微调生成器时同时考虑了语义保留和丰富表达,避免了模型过度生成低频词,但自然语言具有复杂性,有可能微小的改动便会影响句子的语义,导致增强数据集中的低质量样本对下游任务模型的性能产生影响。为此,如图1所示,本文使用基于BERT的过滤器F对其进行过滤选择,过滤器F包括BERT层、线性层、ReLU激活函数层。输入数据首先经过BERT层获取特征表示,其次通过Dropout技术进行正则化处理,以减少过拟合风险,然后将Dropout层的输出输入到一个具有786个输入特征和类别数量输出特征的线性变换层,将特征表示映射到分类标签的空间,最后经过ReLU激活函数得到最终的分类结果。对于生成的样本 (y,l),验证是否F(y)=l,若分类正确则保留,不正确舍弃。因此,每一次完整的迭代后会得到增强数据集Dfilter,Dfilter并入原始集作为新的训练集。
3 实验结果与分析
3.1 数据集
本文共使用了3个公开的句子分类数据集,分别是由法国公司SNIPS在人机交互过程中收集的数据集SNIPS,包含7个意图类别共14 484条数据。由文本检索会议(text retrieval conference, TERC)标注的细粒度问题分类数据集TREC,包含6种问题类型共5 952条数据。由斯坦福大学自然语言处理组标注的情感分析数据集(stanford sentiment treebank v2, SST-2), SST-2属于电影评论情感分类的数据集,用2个标签(positive和negative)标注,共8 741条数据。
3.2 实验设置
根据先前工作[25]模拟用于句子分类少样本场景的设置,本文针对每个任务的训练集进行子采样,每个类随机选择10个样本,每个数据增强模型均对其进行16倍扩充。为避免数据集的随机性带来误差,本文一个任务下的对比实验均采用相同的子数据集。为更好地测试模型的性能,本文的验证集和测试集采用完整的数据集。
在微调GPT-2阶段,设置批量大小为2,迭代次数为100,学习率设定为1×10-5,样本最大长度为20,超过则截断;生成数据时每条句子的提示为“i w1w2”。BERT在大量数据上进行预训练,并在几个句子分类任务上表现出最先进的性能。因此,本文使用BERT模型构建过滤器及句子分类器,本文使用“BERT-Base-Uncased” 模型,该模型有12层,768个隐藏状态和12个头。PunishGPT-DA使用BERT模型第1个特殊字符([CLS])的输出作为句子的特征表示,在传入下一层进行分类之前,以0.1的dropout设置应用于句子表示。训练过程采用自适应矩估计算法(adaptive moment estimation,Adam)进行优化,学习率设置为4×10-5,本文对模型进行100个epoch的训练,并在验证集上选择表现最好的模型进行评估。
所有的实验均在Intel Core i5-9 500 3.00 GHz处理器,GeForce RTX 2028 SUPER显卡,Ubuntu 20.04.4 LTS,python 3.8.0下进行。
本文实验将与以下模型进行对比:
1) GPT-2[7]:为验证本文提出损失函数的有效性,本文以GPT-2作为基准模型,该模型以式(1)为损失函数,其余条件与PunishGPT-DA保持一致。
2) EDA[4]:以词替换、交换、插入和删除为基础的数据增强方法。
3) AEDA[5]:在句子中随机插入标点符号实现数据增强。
4) GPTcontext[25]:采用文献[6]中的方式,将标签与序列连接起来构造训练集:y1SEPx1EOSy2, ···,ynSEPxnEOS。在此基础上以yiSEPw1, ···,wk作为生成阶段的提示,生成增强数据。
3.3 实验结果与分析
本文对比了在意图识别、问题分类及情感分析任务少样本情景下的数据增强策略,表1总结了多种数据增强方法下同一模型在不同数据集中的分类准确率。

表1 不同增强策略下的模型准确率Table 1 Model accuracy under different augmentation strategies%
如表1所示,与基线模型GPT-2相比,本文提出的数据增强方法在3个数据集上的准确率相对提升了1.1%、4.9%和8.7%,这说明本文提出的损失函数能有效提升增强数据的质量;相较于EDA、AEDA和GPTcontex方法,本文提出的数据增强方法在3个数据集上的准确率均有提升,表明了本文增强方法的普遍性。
本文对比了不同超参数α设置下PunishGPTDA的性能,采用SNIPS 的子采样后的数据集,每个类别包含10个样本,对其进行16倍扩充。如图2所示,α=0.3之前模型准确率较低,这是因为在超参数控制下增强数据多样性较强,为数据集引入了过多的噪声;随着α增大,曲线逐渐上升,直到α=0.45时下游任务模型准确率达到最高,此时生成模型能够很好地控制数据多样性和一致性之间的平衡,使模型准确率达到最好的效果;随着α继续增大,一致性占据优势,使得生成数据相较于原数据只有微小的改动,致使模型准确率下降,趋于平缓。这表明,本文提出的损失函数能够同时控制语义和多样化的表达,有效平衡数据的一致性和多样性。

图2 不同超参数下模型准确率Fig.2 Model accuracy under different hyperparameters
本文研究了过滤机制对PunishGPT-DA性能的影响,分别在3个子采样后的数据集上进行了消融实验。实验结果如表2所示,删除了过滤机制后,模型准确率均有下降。这表明过滤器对整个增强过程至关重要。
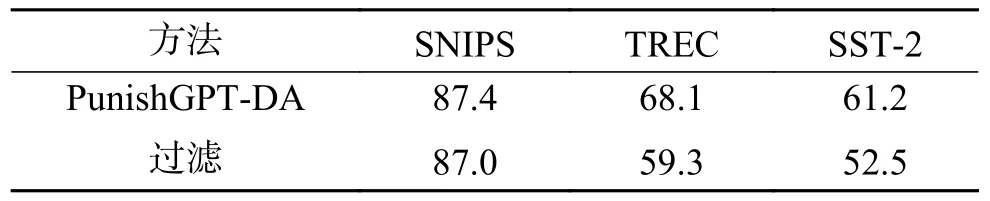
表2 过滤机制对PunishGPT-DA的影响Table 2 Influence of filtering mechanism on PunishGPT-DA%
此外,本文还研究了在不同数据集大小情况下PunishGPT-DA对下游任务模型性能的影响。表3为模型在SNIPS 数据集上进行实验的结果,每种意图类别分别取为5、10、20、50、100条数据作为训练样本,构成少样本数据集,并进行16倍扩充。如表3所示,随着训练数据的增多,本文的数据增强方法对下游任务模型性能的提升作用越来越弱。这表明在少样本情境下,本文所提出的数据增强方法可以有效提升句子分类任务模型性能,当训练数据较为充足时,已经能为下游任务模型提供较为丰富的信息,数据增强带来的效益也就随之减弱。

表3 PunishGPT-DA在不同数据集大小下的准确率Table 3 Accuracy of PunishGPT-DA under different dataset sizes%
为了更加明确损失函数的作用机制,本文分别对采用2种损失函数生成的数据进行了探索,如表4所示,本文分别摘取了部分数据。通过观察损失函数式(3)生成的数据及过滤后的数据可以发现,数据较原始数据有较大的多样性,但大体上符合标签语义;采用损失函数式(2)生成的数据较原始数据只有个别单词的变化,多样性引入不足。由此可以发现本文提出损失函数的有效性。

表4 生成数据示例Table 4 Generate data samples
4 结束语
针对少样本句子分类任务中训练数据不足的问题,本文提出一种平衡语义一致性和多样性的数据增强方法PunishGPT-DA,与当前主流方法相同,此方法建立在大规模的预训练语言模型的基础上,同时又区别于当前主流方法修改提示指导生成模型生成阶段的做法,本文提出的方法从训练角度指导模型生成数据。实验结果表明,在小样本情景下,本文方法可以更有效地保证数据质量,有效提高句子分类模型的分类准确率。尽管本文解决了增强样本质量不高的问题,然而通过损失函数控制数据的生成,可能会导致语法不可控地变化,不符合人类正常的阅读习惯,因此,在句子结构多样性方面还有一定的提升空间。下一步将探索句子结构方面的改进,使其更加自然流畅。
