面向密度分布不均数据的加权逆近邻密度峰值聚类算法
2024-04-09吕莉陈威肖人彬韩龙哲谭德坤
吕莉,陈威,肖人彬,韩龙哲,谭德坤
(1.南昌工程学院 信息工程学院, 江西 南昌 330099; 2.南昌工程学院 南昌市智慧城市物联感知与协同计算重点实验室, 江西 南昌 330099; 3.华中科技大学 人工智能与自动化学院, 湖北 武汉 430074)
聚类是数据分析中一种重要的无监督学习方法,致力于揭示看似杂乱无章的未知数据背后隐藏的内在属性和规律,为决策提供支持,并已成功应用于许多领域,如图像分析[1]、模式识别[2]、社会网络挖掘[3]、市场统计分析[4]和医学研究[5]等。
传统的聚类算法分为基于划分的[6]、基于层次的[7]、基于网格的[8]、基于模型的[9]和基于密度的[10]聚类算法。K-means[11]是最著名的划分聚类算法,通过多次迭代获得最优聚类中心。Kmeans收敛速度快,对大规模数据集的处理效率高,但该算法的性能依赖于初始聚类中心的选择,且对噪声点和异常值敏感。BIRCH(balanced iterative reducing and clustering using hierarchies)[12]是一种基于层次的聚类算法,利用聚类特征树自底向上进行聚类。BIRCH聚类速度快,能识别噪声点,但不适用于高维和非凸数据。CLIQUE(clustering in quest)[13]是一种基于网格的聚类算法,把数据空间分为不同的网格,将样本对应到网格中,并进行密度的计算。CLIQUE适用于高维和大规模数据集,但该算法聚类的准确度较低。EM(expectation maximization)[14]是一种基于模型的聚类算法,根据极大后验概率估计寻找样本的概率模型参数进行聚类。该算法计算结果稳定、准确,但对初始化数据敏感。DBSCAN(density-based spatial clustering of applications with noise)[15]是典型的基于密度的聚类算法,它将样本分为核心点和噪声点,根据密度可达将核心点聚合到同一个集群中。该算法可以识别任意形状的稠密数据集且对数据集中的异常点不敏感,但不能处理密度差异过大的数据。
2014年,Science发表了通过快速搜索和寻找密度峰值聚类[16](clustering by fast search and find of density peaks, DPC)算法。由于其新颖的设计理念和强大的性能,使得基于密度的聚类算法受到更广泛的关注和应用。DPC算法基于两点假设:聚类中心周围的样本的局部密度相对较低;不同聚类中心间的距离相对较远。DPC算法计算过程无需迭代,只需预先设定一个参数来识别聚类中心,但DPC算法仍有一些缺点:1)算法局部密度无法准确识别各类簇间样本的疏密差异,易造成类簇中心的误判;2)虽然DPC中的分配规则非常有效,但是当聚类过程出现某一个样本被错误分配,就会出现多米诺骨牌效应。
针对DPC算法易出现类簇中心选取错误的问题,吕莉等[17]提出二阶K近邻和多簇合并的密度峰值聚类算法(density peaks clustering with second-order k-nearest neighbors and multi-cluster merging, DPC-SKMM)。DPC-SKMM算法提出最小二阶K近邻的概念,根据K近邻和二阶K近邻信息重新定义局部密度,凸显聚中心与非聚类中心的密度差异。Sun等[18]提出了基于最近邻优化分配策略的自适应密度峰值聚类算法(nearest neighbors-based adaptive density peaks clustering with optimized allocation strategy, NADPC)。NADPC算法提出了候选簇心和相对密度的概念,根据候选聚类中心的相对密度和高密度最近邻距离,计算聚类中心的可信度,从而选择聚类中心。赵嘉等[19]提出了K近邻和加权相似性的密度峰值聚类算法(density peaks clustering algorithm with knearest neighbors and weighted similarity, DPCKWS)。DPC-KWS算法从样本的K近邻信息出发,重新定义了局部密度,调整了不同类簇中局部密度的大小。
针对分配规则出现的问题,吴润秀等[20]提出基于相对密度估计和多簇合并的密度峰值聚类算法(density peaks clustering based on relative density estimating and multi cluster merging, DPC-RDMCM)。DPC-RD-MCM算法重新定义了微簇间相似性度量准则,通过多簇合并策略得到最终聚类结果,避免了分配错误连带效应。Ding等[21]提出了基于中心和邻居的社区检测算法(community detection by propagating the label of center, DCN)。DCN算法根据样本的邻居传播标签,提出了标签传播的多重策略,有效解决了DPC分配策略的多米诺效应。赵嘉等[22]提出面向流形数据的测地距离与余弦互逆近邻密度峰值聚类算法(density peaks clustering algorithm based on geodesic distance and cosine mutual reverse nearest neighbors for manifold datasets, DPC-GDCN)。DPC-GDCN算法将互逆近邻和余弦相似性相结合,得到基于余弦互逆近邻的样本相似度矩阵,为流形类簇准确分配样本。
上述算法均有效提高了DPC算法的聚类效果,但忽略了样本间的分布特征,无法对密度分布不均等特定数据集取得较好的聚类效果。因此,本文提出了面向密度分布不均数据的加权逆近邻密度峰值聚类算法(density peak clustering algorithm based on weighted reverse nearest neighbor for uneven density datasets, DPC-WR)。DPC-WR算法充分利用了逆近邻和共享逆近邻信息,算法的主要创新点如下:1)结合sigmoid函数及逆近邻思想重新定义了局部密度,平衡了样本间疏密程度的差异,提高了类簇中心的识别率;2)在样本分配策略中,引入逆近邻及共享逆近邻信息,避免了稀疏区域样本的错误分配,提高了聚类效果。
1 DPC算法
DPC是一种高效的密度峰值聚类算法,可以快速找到聚类中心,对多种聚类任务具有良好的适应性。该算法基于聚类中心密度大于邻域密度,聚类中心间的距离相对较远的思想,提出了两种描述样本xi的密度和距离的方法,即局部密度ρi和相对距离δi。
设有数据集X={x1,x2,···,xn}。对数据集X中的每个样本,样本间的欧氏距离为
局部密度ρi有两种定义方式:
式(2)为截断核,式(3)为高斯核。相对距离δi的定义如下:对于每个样本xi,找到所有比样本xi密集的样本xj,选择最小的dij;如果情况相反,则选择最大的dij。δi的计算公式如下:
类簇中心由决策图确定,以局部密度ρi为横坐标,相对距离δi为纵坐标,建立决策图。理想情况下,聚类中心选取为密度较高且相距较远的样本。定义如下:
最后,选取前n个 较大的值作为聚类中心,n为最终类簇数。
2 DPC-WR算法
在聚类算法中,K近邻和逆近邻在表征密度时起着重要作用。K近邻能准确反映样本在空间中的局部分布特征。而逆近邻基于全局视角检查它的邻域,数据分布的变化会对样本的逆近邻造成影响,使得算法更容易识别聚类中心和提升算法聚类性能。因此,本文引入逆近邻和共享逆近邻信息,重新定义了局部密度,设计了样本相似度策略,充分考虑了样本的总体分布,使样本的局部一致性和全局一致性得到较好的均衡。
2.1 加权逆近邻的局部密度
定义1逆近邻[23]。设样本xi,xj∈X,xi在xj的K近邻集中,那么xj是xi的逆近邻,具体定义如下:
定义2隶属度。样本xi和xj的隶属度µij定义如下:
其中:k为样本的近邻数;|R(i)|表示样本xi的逆近邻数,该值越大,该点的隶属度越大。
定义3加权逆近邻的局部密度。局部密度定义如下:
权重系数:
类簇密度不同时,数据稠密区域与数据稀疏区域的样本对聚类中心选取的贡献程度是不同的。因此,处理密度分布不均数据时,通过引入权重对样本的贡献进行处理,可以达到良好的均衡效果。本文以样本的逆近邻数作为衡量密度的重要指标,引入sigmoid函数,对不同类簇中的样本进行权重调整。
式(9)中λij为权重系数,它在sigmoid函数的基础上进行重构,分母部分以样本的逆近邻数替代了原函数的变量x值,分子部分采用逆近邻代替实数值,使密度分布不均数据在不同区域具有辨识度。从函数可知,随着逆近邻数逐渐增加,其函数值趋近于1,说明位于高密度区域的样本所加的权重近似于1。对于较高密度的样本,被选为聚类中心的概率较大,此时逆近邻数起到关键的作用。当逆近邻数不断减少直至为0时,样本的权重将会从1发生非线性变化减少到0.5,这不仅考虑到各样本间细微的影响,还提高了聚类中心与非聚类中心的区分,使式(7)的隶属度定义更为合理。
2.2 逆近邻和共享逆近邻的分配策略
定义4共享逆近邻。设样本xi的逆近邻集为RN N(xi),xj的逆近邻集为RNN(xj),样本xi与xj的共享逆近邻定义如下所示:
定义5逆近邻和共享逆近邻的样本邻近度。通过样本间的逆近邻信息,定义了邻近度ωij,其定义如下:
其中max(d)表示数据集X中样本间欧氏距离的最大值。
式(11)中第一行表示当样本xj位于样本xi的逆近邻范围内时所赋予的邻近度;第二行表示当样本xj不处于样本xi的逆近邻范围时,由于样本间的紧密程度低,若将值赋0,易忽略未在范围内的样本的细微影响,故其邻近度在逆近邻范围的基础上除以最大距离所得。
定义6样本相似度。基于逆近邻和共享逆近邻,得到样本xi和xj的相似度:
β(xi,xj)反映了样本所处空间的紧密程度,分子部分为每个样本的相似度之和,分母部分为归一化参数。式(12)考虑了样本本身及其共享逆近邻样本在定义样本间相似度方面起着重要的作用,因此,只有当样本之间存在逆近邻或共享逆近邻时,才存在相似性。
2.3 算法步骤
输入数据集X=,近邻数k
输出聚类结果C
1)数据归一化;
2)计算数据集样本间的欧氏距离;
3)根据式(8)和式(4)分别计算各样本的局部密度ρi和相对距离δi;
4)根据式(5)计算各样本的决策值γi并选取聚类中心;
5)根据式(12)计算基于逆近邻和共享逆近邻的样本相似度并构建相似度矩阵;
6)对于所有已分配的样本,找到相似度最高的未分配样本并将其分配到已分配样本所在的簇中;
7)若所有已分配样本与未分配样本间的相似度为0,转至步骤8),否则转至步骤6);
8)若还存在未分配的样本,则按DPC算法分配策略分配;
9)输出聚类结果。
2.4 算法复杂度分析
设样本规模为n,k为近邻数。DPC算法的时间复杂度为O(n2)[24]。DPC-WR算法的时间复杂度主要由以下6个部分组成:1)计算样本间距离矩阵的复杂度O(n2);2)计算样本的局部密度,包括计算样本间的K近邻和样本间的逆近邻与逆近邻数,前者复杂度为O(n),后者为O(kn)和O(n2);3)计算样本相对距离的复杂度O(n2);4)计算样本决策值的复杂度O(n2);5)计算样本的共享逆近邻与邻近度的复杂度O(n2);6)计算样本最坏分配情况的复杂度O(n2logn)。综上,DPC-WR算法的时间复杂度为O(n2logn)。
3 实验结果与分析
3.1 实验设置
为验证DPC-WR算法的性能,本文在密度分布不均数据集、复杂形态数据集和UCI真实数据集上进行实验。将DPC-WR算法与IDPC-FA[25]、FNDPC[26]、FKK-DPC[20]、DPC[16]和DPCSA[27]算法进行比较。其中,IDPC-FA、DPCSA和DPC算法由原作者提供,FNDPC和FKNN-DPC算法参照原文献编程实现。除了DPCSA和IDPC-FA无需对参数调优外,其余算法均需要调整参数。DPCWR和FKNN-DPC算法参数k值的选取是1~50之间的最优值;DPC算法的截断距离dc的选取在0.1%~5%,步长为0.1%;FNDPC算法参数ε的选取在0.01~1,步长为0.01。实验环境为Win10 64 bit操作系统,AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz处理器,16.0GB内存。
本文采用调整互信息(adjusted mutual information, AMI)[28]、Fowlkes-Mallows指数(fowlkesmallows index, FMI)[28]和调整兰德系数(adjusted rand index, ARI)[29]对聚类效果进行评价,其中,3个指标的最佳结果都为1,各指标值接近1的程度越高,表明聚类结果越好。
3.2 密度分布不均数据集的实验结果与分析
本文选取了6个不同规模的密度分布不均数据集进行实验,其基本特征如表1所示。

表1 密度分布不均数据集的基本特征Table 1 Basic characteristics of datasets with uneven density distribution
表2给出了6种算法在密度分布不均数据集上的聚类结果,其中最优结果以粗体表示,“Arg-”表示各算法的最优参数取值。“—”表示不含参数。DPC-WR算法在6个数据集上均获得最佳的聚类效果。IDPC-FA算法对Jain和LineBlobs具有较好的聚类效果,对其他数据集的聚类效果较差。FKNN-DPC算法对Cmc和LineBlobs数据集聚类效果较好,对其他数据集聚类效果不佳。DPCSA算法仅对LineBlobs数据集具有较好的聚类效果。FNDPC和DPC算法在6个数据集上的聚类性能均低于DPC-WR和FKNN-DPC算法。
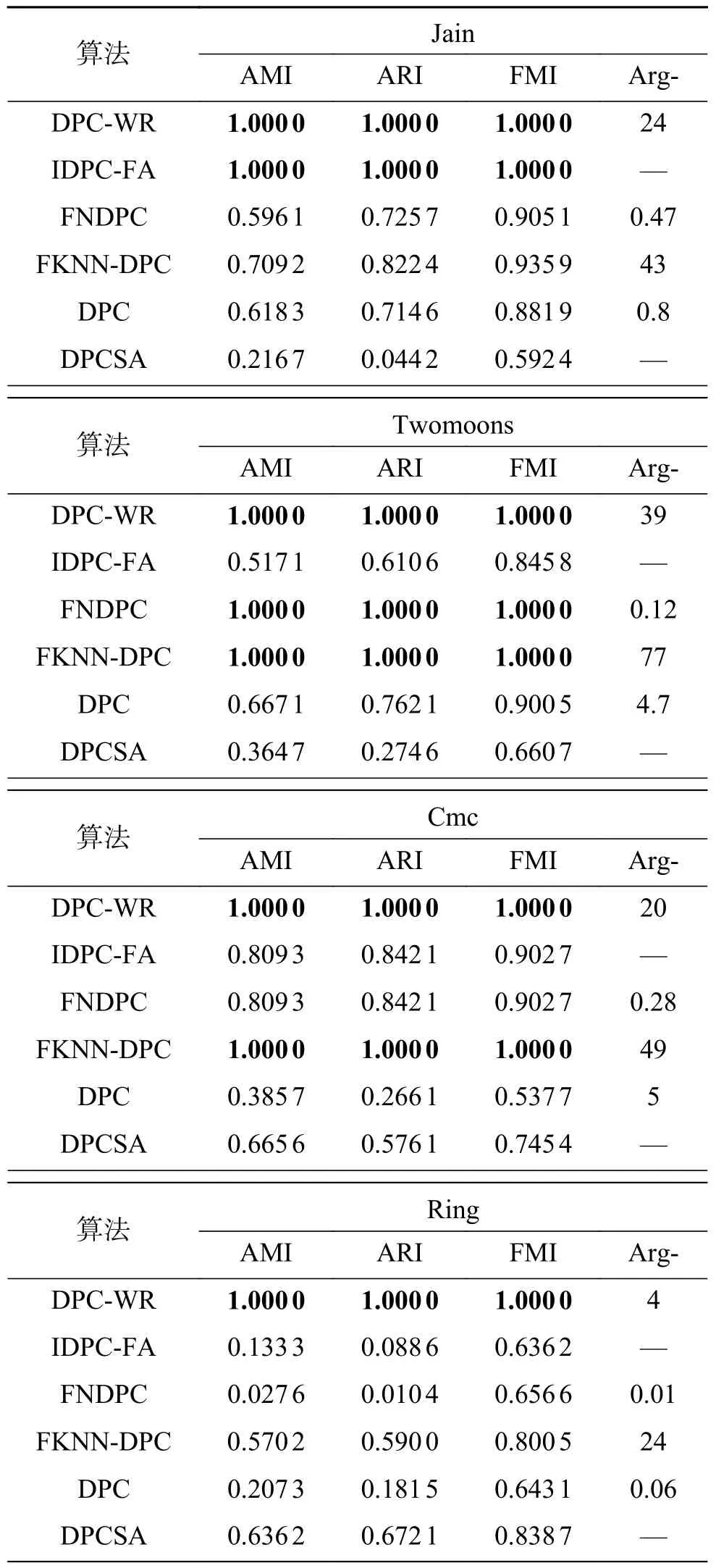
表2 6种算法在密度分布不均数据集上的聚类结果Table 2 Clustering results of six algorithms on datasets with uneven density distribution
Friedman检验[30]是利用秩实现对多个总体分布是否存在显著差异的非参数检验方法。将对比算法进行检验可以更准确地反映算法间评价指标的差异,秩均值越高则算法的聚类效果越优。从表3可以发现,在密度分布不均数据集上聚类评价指标AMI、ARI和FMI的秩均值排名中,DPCWR算法都位列第1,且秩均值都大于5.4。
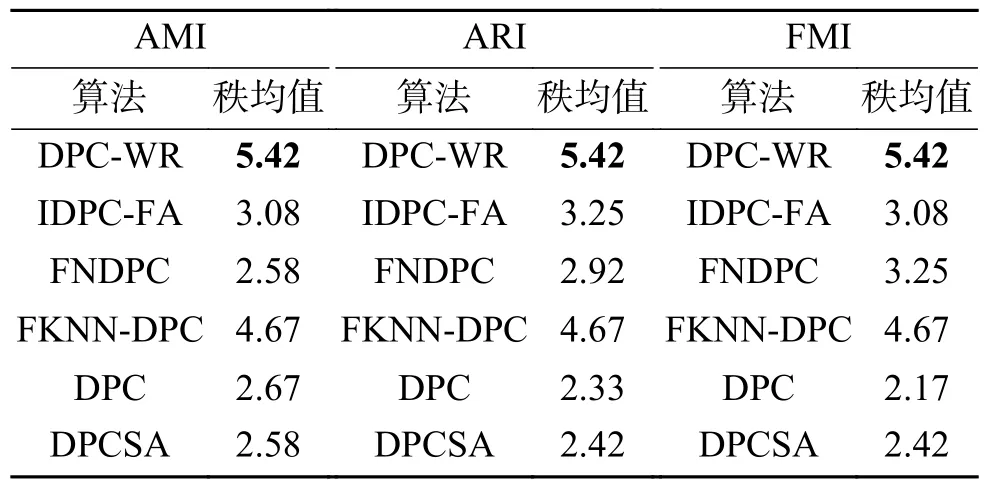
表3 6种算法在密度分布不均数据集上的秩均值Table 3 Rank mean of the six algorithms on the unevenly distributed density datasets
由于篇幅所限,本文选取了1个典型的密度分布不均数据集。图1给出了DPC-WR、IDPCFA、FNDPC、FKNN-DPC、DPC和DPCSA算法在Jain数据集上的聚类结果。图中不同的颜色代表不同的类簇,类簇中心用“六角星”表示。

图1 6种算法在Jain数据集上的聚类结果Fig.1 The clustering results of 6 algorithms on Jain dataset
Jain数据集由2个稠密程度不同的新月形类簇构成。从图1可知,DPC-WR和IDPC-FA算法充分考虑了样本间的密度差,能准确地找到类簇中心;FNDPC和FKNN-DPC算法虽然找到了正确的类簇中心,但样本分配策略存在错误,导致稀疏类簇样本的错误分配;DPC和DPCSA算法没有找到正确的聚类中心,导致聚类效果不佳。
3.3 复杂形态数据集的实验结果与分析
复杂形态数据集是指具有多尺度、簇类形状多样等结构的数据集。本文选取了6个复杂形态的数据集,其基本特征如表4所示。表5给出了6种算法在复杂形态数据集上的聚类结果。从表5可知,DPC-WR和IDPC-FA算法比其他对比算法的聚类结果更优,都存在4个聚类效果较好的数据集。从整体来看,DPC-WR算法的聚类效果最佳,具体表现在Flame、R15、Sticks和Pathbased数据集。

表4 复杂形态数据集的基本特征Table 4 Basic characteristics of complex

表5 6种算法在复杂形态数据集上的聚类结果Table 5 Clustering results of six algorithms on complex morphological datasets
表6为6种算法在6个复杂形态数据集上评价指标的秩均值。从表6可以发现,DPC-WR算法在AMI、ARI和FMI评价指标的秩均值中位列第一,其次是IDPC-FA算法,然后是FNDPC算法。
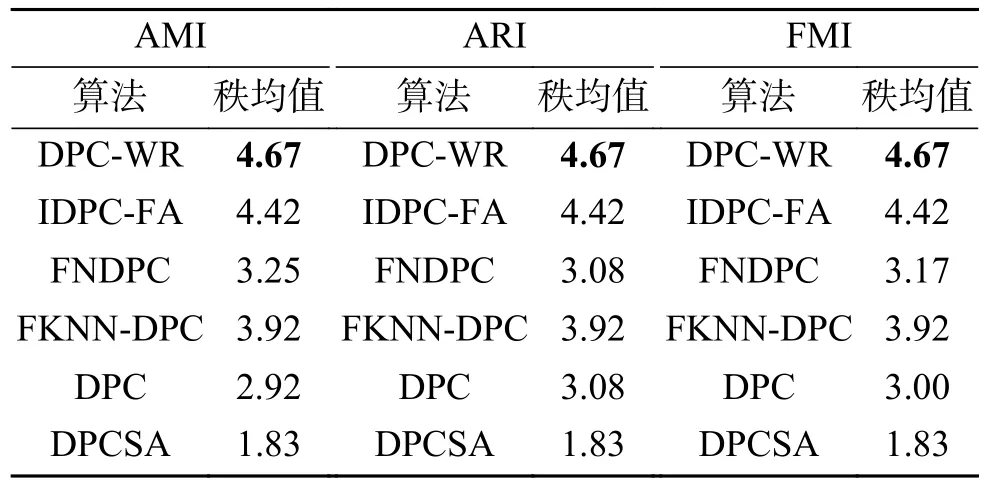
表6 6种算法在复杂形态数据集上的秩均值Table 6 Rank mean of 6 algorithms on complex morphological datasets
3.4 UCI数据集的实验结果与分析
UCI数据集又称真实数据集,它是一个常用的标准测试数据集。为了进一步验证DPCWR算法的有效性,本文选取了8个真实数据集,对6种算法进行实验。其中测试的数据集包括Iris、Wine、Seeds、Ecoli、Inonsphere、Libras、Dermatology和Wdbc。表7给出了各数据集的基本特征。表8为6种算法在UCI数据集上的聚类效果。从表8可以发现,处理Seeds数据集时,DPC-WR算法的聚类效果不及IDPC-FA、FKNN-DPC和DPC算法。处理Inonsphere数据集时,DPC-WR算法的聚类效果低于FKNN-DPC算法。处理Dermatology数据集时,DPC-WR算法的聚类效果比DPCSA算法好,但略逊于其他算法。剩余的Iris、Wine、Ecoli、Libras和Wdbc数据集,DPC-WR算法的聚类效果都优于其他算法。
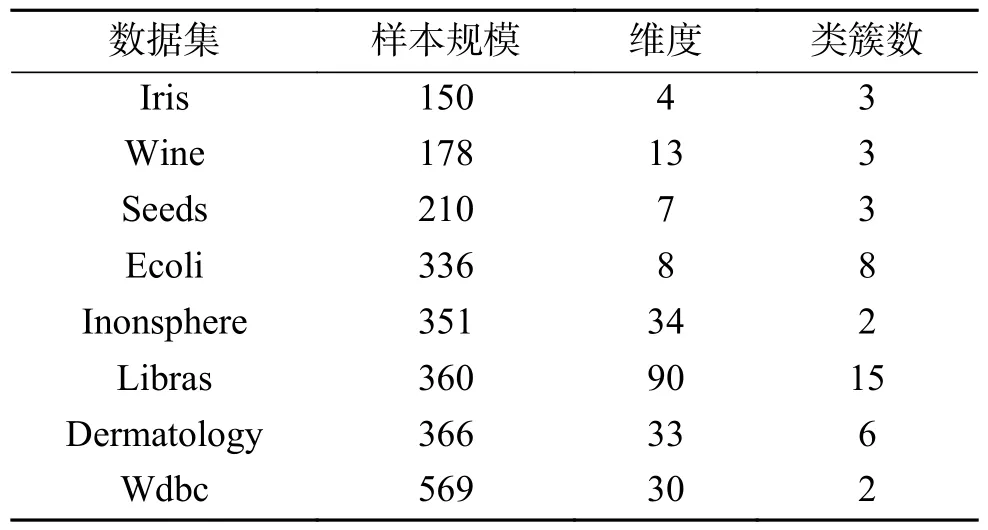
表7 UCI数据集的基本特征Table 7 Basic characteristics of UCI datasets

表8 6种算法在UCI数据集上的聚类结果Table 8 Clustering results of six algorithms on UCI datasets
表9为6种算法在UCI数据集上评价指标的秩均值。从表9可知,DPC-WR算法相较于其他对比算法评价指标的秩均值都是最高的,其次是FKNN-DPC和IDPC-FA算法。由此可以得出,在UCI真实数据集上,DPC-WR算法的聚类效果明显优于IDPC-FA、FNDPC、FKNN-DPC、DPC和DPCSA算法。
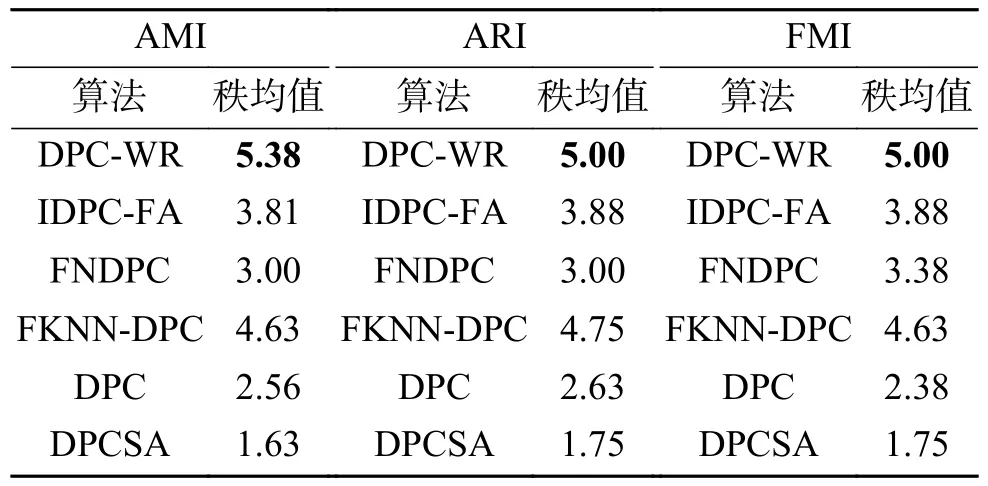
表9 6种算法在UCI数据集上的秩均值Table 9 Rank mean of six algorithms on UCI datasets
3.5 算法的仿真时间与分析
本文中,仿真时间指完成单个数据集聚类所花费的时长,是评价算法聚类性能的重要指标。为计算聚类算法的聚类时间,本文针对前述3类数据集进行了相应的实验,结果详见表10。
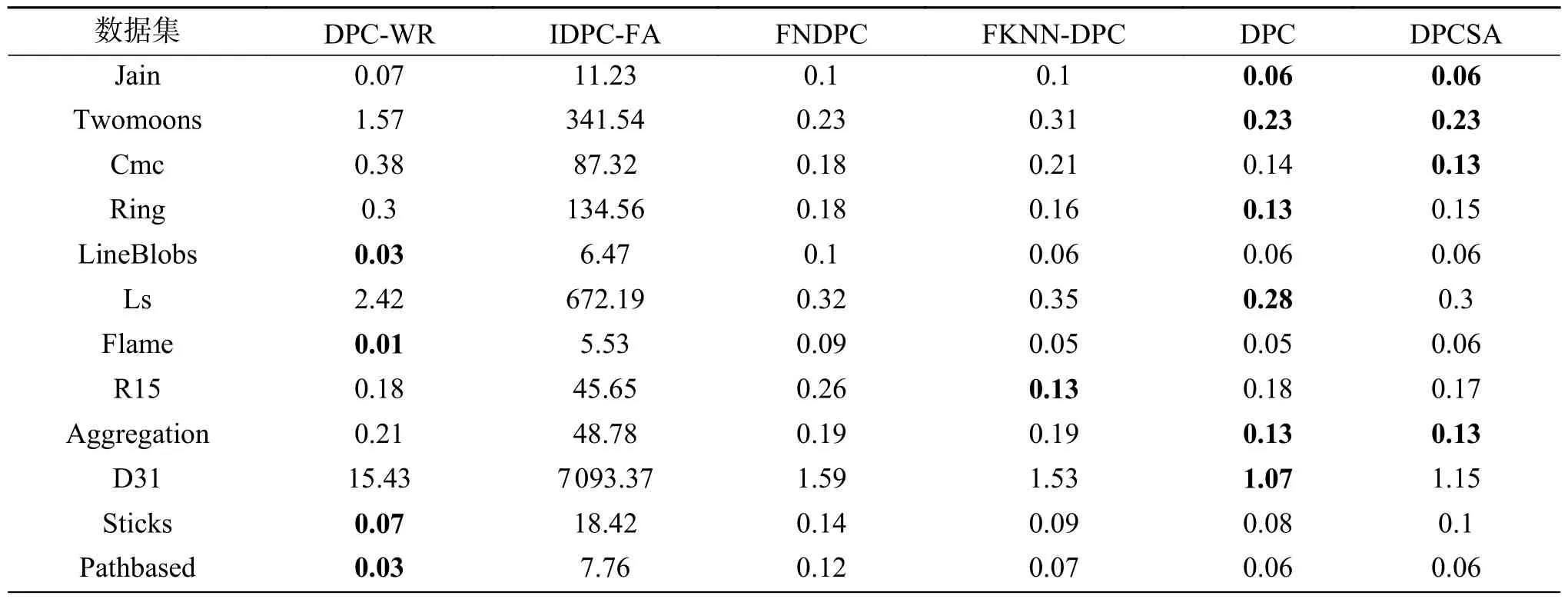
表10 6种算法在3类数据集上的仿真时间Table 10 Simulation time of six algorithms on three types of datasetss
从表10可以发现,对于样本规模较小的数据集,如Jain、LineBlobs等,DPC-WR算法可以与对比算法相媲美或者更优;对于样本规模较大的数据集,如Twomoons、Cmc等,DPC-WR算法弱于FNDPC、FKNN-DPC、DPC和DPCSA算法,但是,相较于IDPC-FA算法,DPC-WR算法加速效应明显。这主要是由于DPC-WR算法的时间复杂度为O(n2logn),样本规模的增大,logn的影响将变得更加明显。
4 结束语
针对DPC算法在面对密度分布不均数据集时易出现误选类簇中心以及样本分配错误的问题,本文提出了一种面向密度分布不均数据的加权逆近邻密度峰值聚类算法。DPC-WR算法首先引入基于sigmoid函数的权重系数及逆近邻思想,重新定义样本的局部密度;随后,利用逆近邻和共享逆近邻计算样本相似度;最后,按照样本相似度将剩余样本进行分配。实验结果表明,DPC-WR算法有效改善了类簇间样本疏密差异导致误判聚类中心以及稀疏区域样本错误分配的问题,在密度分布不均数据集、复杂形态数据集和UCI数据集上的聚类效果明显优于其对比算法。由于DPC-WR的聚类结果往往取决于参数k的选择,如何快速选择k的最佳值是下一步的研究重点。同时,群体智能[31-32]的引入有望进一步提升聚类算法的性能,特别是借助群智能进化[33-35]的途径将使得聚类算法的自适应性更加趋于完善。
