Re-YOLOv5:一种基于结构重参数化的钢材缺陷检测方法
2024-04-08游大朋焦喜香胡学进
游大朋,杨 静*,张 露,焦喜香,胡学进
(1.合肥学院人工智能与大数据学院,安徽合肥 230601;2.合肥综合性国家科学中心人工智能研究院,安徽合肥 230088)
目前国内的制造业发展迅速,但部分行业的技术并不先进,例如钢材生产行业。因钢铁的生产流程非常复杂,工序多,其现代化生产模式尚未完全普及,大部分工厂都还未实现完全的机械化,生产的方法也相对简单,这就导致钢铁的表面可能存在很多的缺陷,如裂纹(Crazing,Cr)、夹杂物(Inclusion,In)、斑块(Patches,Pa)、麻点(Pitted Surface,Ps)、氧化铁皮(Rolledin Scale,Rs)和划痕(Scratches,Sc)。在上述各种缺陷中,裂纹的形状比较复杂多样,大部分是鱼鳞状,其产生的主要原因是温度加热不均。Cr 对钢材的性能破坏极大,若未被及时发现和处理,其会造成钢材的破损和开裂;In是钢材表面出现的深灰色或棕色斑块,一般是在钢材生产的过程中混入了其他的非金属,其很容易导致钢材的开裂;Pa是钢材表面出现的参差不齐的形状,产生的主要原因是在冷却过程中没有均匀吸收冷却液,其会影响钢材的结构稳定性,缩短钢材的使用寿命;Ps是参差不齐的粗糙面,加热过程中产生的氧化物没有得到完全清除时,就会产生麻点,麻点对钢材的性能影响不大,但是会造成一定程度的厚度误差,从而影响精度;Rs是在加热时间过长时钢材表面产生的黑色或红棕色氧化物,如未及时清理,会在轧制过程中被压入钢材表面,降低钢材性能;Sc 是6 种缺陷里最常见的,其性状是明亮的细长白条,主要是因钢材生产或搬运过程中与坚硬的物体非正常接触造成的,划痕会降低钢材的强度,影响使用寿命。以上缺陷如图1 所示。由图1 可见,这些缺陷会导致产品性能下降和寿命缩短,且极易引发安全事故。

图1 钢材表面缺陷类型图片
随着我国经济的飞速发展和钢材市场供求新形势的影响,市场对钢材质量和价格的要求发生了改变,质量好的钢材在建筑方面起到了重要的作用,可以直接影响建筑工程的质量,竞争愈发激烈,因此,如何更高效地生产无缺陷的钢材成了工业生产中较重要的问题[1-2]。近年来,采用深度学习的目标检测系统得到了迅速发展。从目标检测方法的发展思路上来看,主要分为二阶段(Two-stage)目标检测方法和一阶段(One-stage)目标检测方法。Two-stage 目标检测方法主要以Faster R-CNN[3]算法为主,准确率更高;Onestage目标检测方法主要有YOLO系列算法和SSD[4],其中YOLO 系列算法包含YOLOv3[5]、YOLOv4[6]、YOLOv5 等,One-stage目标检测方法具有更快的速度。此外,还有一些经典的网络,如CenterNet[7]、DETR[8]和RetinaNet[9]。
国内外的很多学者将目标检测技术应用到缺陷检测中,谢景洋等[10]在YOLOv3 的主干网络中加入了MobileNets,在对织物的缺陷检测中,不仅减少了参数量,速度也得到了提升;谢黎等[11]在YOLOv4 的基础上增加一个用来检测小目标的检测框,使得对于电路板元器件的检测更加准确;闫彦辉等[12]改进了YOLOv5,对输电线路的检测中,不仅检测精度高而且推理速度快;Zeng等[13]在缺陷检测网络中引入了模板和上下文,更适用于对大目标进行检测,但对小目标检测的区域不太准确;Xu 等[14]在骨干网络的不同阶段采用了可变性卷积,细化和增强了获取骨干网络特征的能力,提高了平均精度,但是速度上没有优势;Liao等[15]改进了骨干网络中的激活函数,减少了参数量,但对精度的提升不明显。为了追求精度,李鑫等[16]在原有的YOLOv5s网络中,用GhostBottleneck 结构代替C3 和局部卷积结构,该新网络的性能较原来的YOLOv5s网络提高了3.3%;张宇杰等[17]增加了3 个小尺寸锚框,并且借鉴了YOLT算法的方式,可以更好地选中小目标缺陷位置,提高整体精度;韩强等[18]利用特征融合和级联检测网络,对Faster R-CNN进行了改进,其准确率较原来的Faster R-CNN 提高了2.40%;Zhao等[19]重建了Faster R-CNN 的网络结构,提高了对小目标的检测能力,平均精度提高到了75.2%;Wan 等[20]在YOLOv5s 的基础上增加了注意力机制跟小尺度检测层,提高了表面缺陷的检测精度。Hao等[21]改进了残差网络,提出了基于特征金字塔与分散注意力网络的DF-ResNeSt50 模型来提高精度;Sharma等[22]引入了一种分层方法来对钢表面的缺陷进行分类和检测,在NEU 数据集上检测的精度高达77.12%;除此之外,为了追求速度,孙泽强等[23]采用CSPDarknet53 +FcaNet +Decoupled Head 的结构,检测速度达到了27.71 f/s;翁玉尚等[24]改进了Mask RCNN,去掉了掩码分支,用K-means聚类算法改进区域建议网络,检测速度提高到了5.9 f/s;李丹等[25]提出了一种可分离的局部深度混合网络,识别一幅图片平均仅需0.47 ms。
在已有的缺陷检测研究中,大多数学者会把侧重点放在精度或速度上,但由于涉及工业部署,算法应该在精度和速度之间达到一个平衡,因此本文提出了一种基于结构重参数化的钢材缺陷检测方法,主要特点如下。
①提出了Re-YOLOv5 架构,采用One-stage 方法的YOLOv5 算法,融入RepVGG模块,能在加深网络提升性能的同时提高推理速度,达到精度与速度的平衡。
②在网络模型中引入改进的SPP*层,增加感受野,加强网络特征融合能力,提升对于不同类型目标的检测精度;将CSP组件改进为CCBL组件,在保证检测速度的同时实现精度的提升。
③在公开的钢材缺陷图像数据集NEU-DET上进行了验证,对6 种缺陷的平均检测精度达到77.8%,比YOLOv5s 提升了6%,单幅图片的推理时间仅为8.9 ms,精度和速度均能满足工业部署的需求;在另一个公开的钢材缺陷图像数据集GC10-DET上也进行了验证,10 种钢材的缺陷平均检测精度超过原始的YOLOv5 算法。
1 Re-YOLOv5 模型结构
1.1 模型结构简介
在钢材的实际生产过程中,由于生产速度极快,很容易产生缺陷。各种缺陷都有其显著的特征,即缺陷之间的差异很大,会引发较大的数据波动,导致训练结果不够全面,网络在学习过程中出现过拟合,从而影响最终的检测准确率。此外,如何在保证缺陷检测精度的同时提升效率是一个急需解决的问题。基于此,本文提出了一种用于钢材缺陷实时检测的模型Re-YOLOv5,其网络结构如图2 所示。
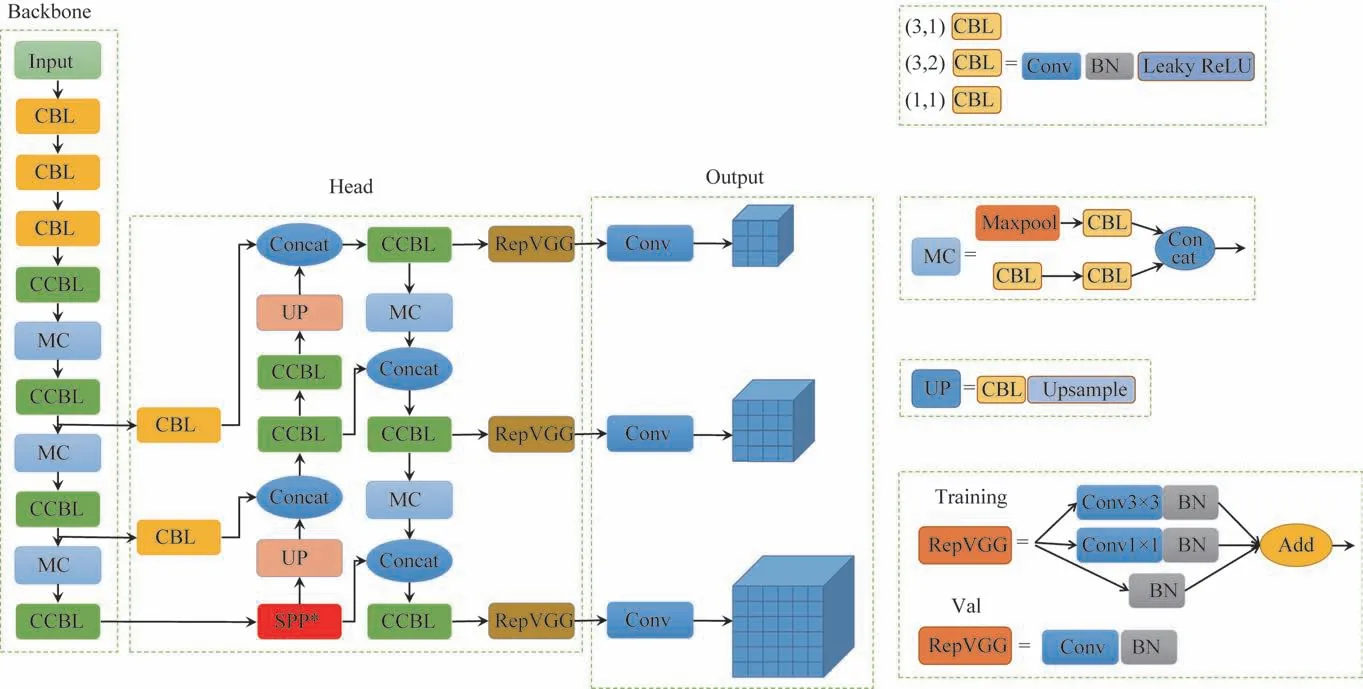
图2 Re-YOLOv5网络结构
YOLOv5 有5 个版本,分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,5 个版本的层数与深度不同,依次递增。本文提出的Re-YOLOv5 是在YOLOv5s 模型上进行改进,以达到精度与处理效率的提升与平衡。具体地,Re-YOLOv5由3 个部分组成,Backbone、Head 和Output。将YOLOv5 的Neck 层与Head 层合并为Head 部分,用作预测;Backbone用作特征提取。整个过程如下:首先对所输入的图像进行预处理,设定为640 px ×640 px的RGB 图像并对齐,然后将其输入到Backbone网络中进行特征提取,根据Backbone 部分中的3 层输出,经过Head 部分,输出3 层不同尺寸大小的特征图,再由RepVGG模块和卷积层输出,最终得到目标检测结果。
1.1.1 Backbone
Backbone部分主要用于对输入端接收到的图像进行特征提取,由若干CBL 层、CCBL 层和MC 层构成,如图3 所示。
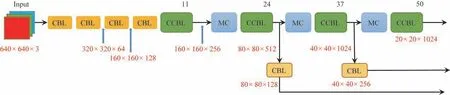
图3 Backbone部分的构成
CBL 层主要由卷积层、BN 层和Leaky ReLU 激活函数构成,其中CBL层有3 种不同的大小和步长:(3,1)表示卷积核大小为3,步长为1;(3,2)表示卷积核大小为3,步长为2;(1,1)表示卷积核大小为1,步长为1。CCBL层主要由多个卷积层、BN层和Leaky Re-LU激活函数构成,其输入和输出的特征大小保持不变,仅是刚开始时候的2 个CBL 的通道不一致,之后的几个输入通道和输出通道均保持一致,在经过最后一个CBL后,输出为所需要的通道。MC 层主要由最大池化层Maxpool 和CBL 层构成,一共有5 层。输入端的图片首先经过4 层CBL 层,此时特征图变成160 px×160 px×128 px,随后经过CCBL层,此时特征图变成160 px ×160 px ×256 px,接着经过MC 层和CCBL层,此时特征图变成80 px×80 px×512 px,分出一条分支经过CBL层,此时特征图变成80 px ×80 px×128 px,接着与Head 部分的模块进行张量拼接,另一条分支继续经过MC 层和CCBL 层,特征图变为40 px×40 px×1 024 px,依然分成2 条分支,其中一条分支经过CBL层,特征图变为40 px ×40 px ×256 px,与Head 部分的模块进行张量拼接,另外一条分支继续经过MC层和CCBL层,特征图变为20 px×20 px×1 024 px,融入到Head部分。整个Backbone部分共计50 层,交替长宽减半,通道增倍,用于特征提取。
1.1.2 Head
Head部分主要用于特征融合。本文将YOLOv5的Neck 层与Head 层合并为Head 部分,采用CIOU Loss做Bounding box的损失函数,CIoU 损失函数如式(4)所示。在式(1)中:IIoU为交并比,ρ2(b,bgt)为预测框与真实框中心点的欧氏距离,c 为可以同时包含预测框与真实框的最小闭包区域的对角线距离。式(2)计算的是生成的锚框和目标框之间的相似程度。式(3)为权重函数,由式(3)可知损失函数是通过增加真实框与目标框之间的重叠度来优化的。由此可见,CIoU损失函数的优势是可以使目标框和真实框的距离最小化,加快损失函数的收敛速度。
如图4 所示,Head 部分由SPP*层、若干MC 层、若干CCBL 层、张量拼接和RepVGG 模块层组成。SPP*层首先把通道分为5 路,其中1 路经过3 层CBL层,然后跟其中的3 条分支张量拼接在一起,之后再经过2 层CBL层,与最后1 路经过CBL层的分支张量拼接在一起。UP 层是上采样操作。RepVGG 模块在模型的训练和推理中有区别。在训练中,RepVGG 模块由3 ×3 Conv和BN层、1 ×1 Conv和BN层再增加BN分支,3 个分支的组合相加输出;而在推理中,则将各分支的参数重参数化到主分支上,再通过主分支的卷积来进行运算。
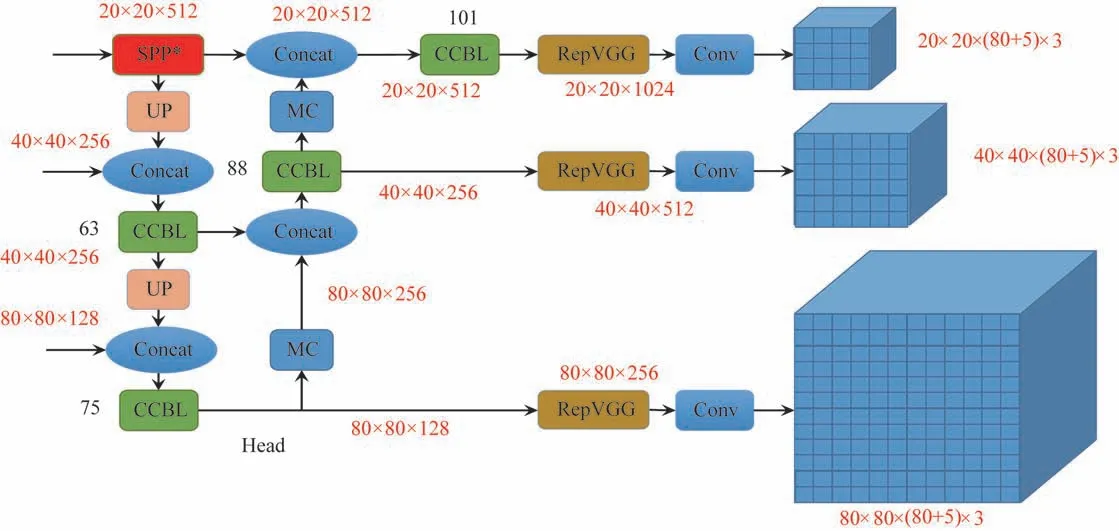
图4 Head部分的构成
输入端的图片经过Backbone 的特征提取后到达Head,Head是一个PAFPN结构,即路径聚合网络加特征金字塔网络,经过上采样后进行张量拼接。具体地,首先得到3 个特征图,大小分别为20 px ×20 px ×1 024 px、40 px ×40 px ×256 px 和80 px ×80 px ×128 px。20 px×20 px ×1 024 px 大小的特征图首先经过SPP*层,随后分成2 条分支,其中一条经过上采样,与从Backbone输出的40 px×40 px×256 px特征图进行张量拼接,再经过CCBL层,此时层数为63。然后,再次分成2条分支,一条为40 px×40 px×256 px大小,经过上采样,与Backbone 输出的80 px ×80 px ×128 px大小的特征图进行张量拼接,再经过CCBL 模块,此时为75 层,继续分成2 条分支。其中一条80 px ×80 px ×128 px 大小的分支经过RepVGG 模块和卷积层,输出为80 px×80 px×(80 +5)px×3,用来预测输入图片中的大目标。另一条分支经过MC 层,与之前的一条CCBL 的输出分支做张量拼接,再经过CCBL层,此时为88 层,之后分成2 条分支,其中一条特征图大小为40 px×40 px×256 px,经过RepVGG模块和卷积层,输出为40 px×40 px×(80 +5)px ×3,用来预测输入图片中的中等目标。另一条分支经过MC 层,与之前的20 px ×20 px ×512 px 特征图做张量拼接,随后经过CCBL,此时为101 层,特征图大小为20 px×20 px×512 px,随后经过RepVGG模块和卷积层,输出为20 px×20 px ×(80 +5)px ×3,用来预测输入图片中的小目标。
1.2 RepVGG模块
目前,卷积网络的研究大多集中在卷积网络的结构上,大部分都是简单和复杂2 种。对于复杂构造,如添加残差块等,ResNet 是其中最具代表性的。由于该模型具有多个分支结构,因此其计算精度高,但也会降低计算效率。在简单结构中,VGG 是最具代表性的一种,其是一种直线结构,训练和推理速度都很快,但其结果并不理想。VGG 在出现的最初的几年中已经被广泛地用于骨干网络,但是随着新网络架构的提出,产生了较多精度更高的网络。
ResNet和RepVGG[26]之间的网络体系结构如图5所示。在图5 中,原始的ResNet网络如图5(a)所示,其中的蓝色部分表示卷积层,橘色部分表示ReLU 激活函数,而带有弧线部分的代表含有1 ×1 卷积残差结构和Identity 残差结构以及ReLU 激活函数。由于ResNet包含了残差结构,深层网络的梯度弥散和消退问题得以改善,使得网络易于收敛。图5(b)为RepVGG网络的训练阶段,其中包含1 ×1 的卷积残差结构和Identity残差结构和ReLU激活函数。图5(c)为RepVGG网络的推理阶段,其中仅包含3 ×3 的卷积和ReLU激活函数。由于训练和推理采用的是2 种结构,在训练中注重精确性,推理时注重速度。因此RepVGG可以在不增加运算量的前提下,提高运算速度,且不会降低精度。

图5 RepVGG模块示意图
1.2.1 卷积层和BN层融合
BN(Batch Normalization)被广泛用于卷积神经网络,它可以改善网络的泛化性能、加速收敛、减轻梯度扩散等问题。本文在网络推理的过程中,将BN 层的操作直接嵌入到卷积层中,从而大幅降低了计算工作量,提高了网络的运行速度。该卷积层的计算公式如下:
式中:x为每一层输入;w为权重;b为偏置。
BN层主要包括归一化和缩放2 部分,BN 层输出的具体计算方法如下:
式中:γ为缩放参数;μ 为样本均值;σ 为标准差;ε 为一个极小值(防止分母为0);β 为偏移参数。将卷积层和BN层合并,将式(5)代入式(6)可得:
BN层的输出y2变形可得:
在推理过程中,BN层的样本均值和标准偏差源于训练样本的分布,而尺度和偏差则与其他模型的参数结合起来,即μ、σ、γ、β 均为固定常数值。令w′ =
由此可见,将BN层与卷积层的计算结合在一起,相当于将卷积核按一定的比例放大,并且在一定程度上改变了偏移,减少了BN层的计算量,从而可以加快推理的速度。
1.2.2 RepVGG 模块
将卷积层与BN层进行融合之后,可以得到3 ×3卷积、1 ×1 卷积、Identity分支和3 个偏置向量。假设输入信道数目与输出信道数目相等,并且各类型的卷积都有相同的步长,1 ×1 和3 ×3 的卷积处理流程如图6 所示。由图6 可见,RepVGG模块将1 ×1 卷积核中的数值等价转移到3 ×3 的卷积核中央,而Identity分支则可以等价为单位矩阵的1 ×1 卷积,再用3 ×3卷积的形式来表示。在此基础上,1 ×1 卷积、Identity分支最终均可填充为3 ×3 卷积,利用卷积的可加性,对1 ×1 卷积分支和Identity 分支进行等值变换,可以与3 ×3 卷积相结合。最后的偏置向量可以通过3 个偏置向量的相加获得。
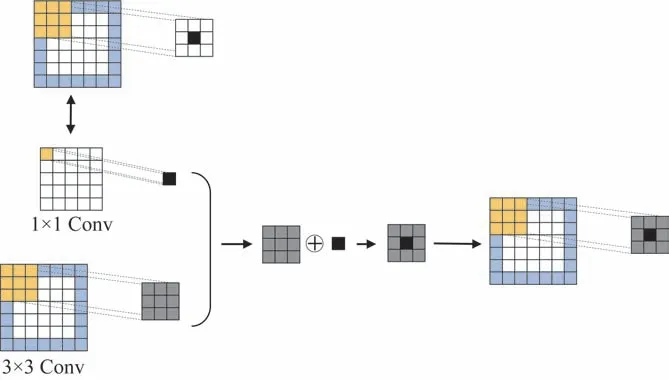
图6 1 ×1和3 ×3卷积处理流程
1.3 SPP*模块
SPP结构是空间金字塔池化模型,功能是将任意大小的特征图转换为具有一定大小的特征向量,SPP的基本结构如图7 所示。
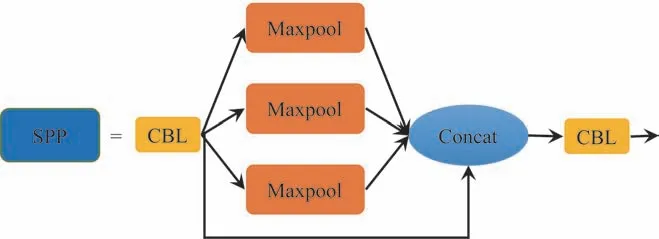
图7 SPP基本结构
但由于在工业钢材缺陷的检测过程中,钢材的种类较多,而且每种钢材缺陷检测的难度也不尽相同,为了提取各种尺度大小的图像特征信息,本文对空间金字塔池化模型SPP 进行改进,将改进后的SPP 称为SPP*。SPP*模块结构如图8 所示。首先将其划分为5 个分支,其中一路经过3 层CBL模块,接着跟其中一路经过最大池化层的分支进行张量拼接,结果分支与最初的2 路经过最大池化层的分支再进行张量拼接,其后再经由2 个CBL模块,与最初经过CBL模块的分支进行张量拼接,最终合并成一路。由此可见,改进后的SPP*采用的是局部信息结合全局信息的方式,增加了感受野和网络特征融合能力,因而可以提升模型对于不同类型目标的检测精度。

图8 SPP*模块结构
1.4 CCBL模块
YOLOv5 中发挥最主要功能的是CSP 模块,CSP模块结构如图9 所示。在YOLOv4 中只在Backbone中使用了CSP 模块,而YOLOv5 的Backbone 和Neck中均用到了CSP 模块。CSP 模块可以在特征图中综合反映梯度的变化,降低模型的参数量和维度,从而增强模型的推理速度和精确度。另外,由于YOLOv5 的网络深度比较高,因此可以利用CSP模块来解决梯度消失的问题。

图9 CSP模块结构
为了进一步提升推理速度和精确度,本文将CSP模块替换为CCBL模块,CCBL模块结构如图10 所示。CCBL模块中包含了多个CBL 模块,主要包含2 个分支:第一个分支经过CBL 模块后分成两路;第二个分支经过2 个CBL模块,接着分成两路,其中一路经过2个CBL模块,与第一个经过CBL模块的分支和另一路进行张量拼接,拼接后的结果经过最后一个CBL 模块,用来获取不同的感受野的信息。改进后的CCBL模块更有助于模型的加深。在之后的消融实验中,也证明了CCBL模块的有效性。
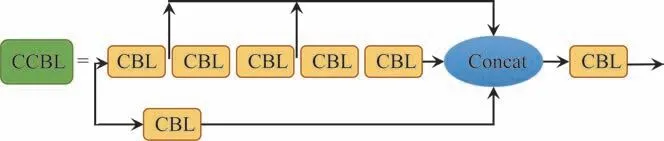
图10 CCBL模块结构
2 实验
2.1 实验数据集
本文使用的2 个数据集分别为东北大学(NEU)发布的热轧带钢表面缺陷数据集NEU-DET[27]和工业生产中的焊接件表面缺陷数据集GC10-DET[28]。NEU-DET共收录了1 800 幅图片,并标注了每幅图片的缺陷范围和缺陷部位数据。数据集中以xml文档形式记录缺陷类型的信息,用图片的名称记录缺陷的类别。缺陷类型包括6 种,每种类型约有300 幅图片。6种缺陷分别为:Cr、In、Pa、Ps、Rs、Sc。在本文使用NEU-DET的实验中,将原始数据集按照8∶2 的比例随机划分为训练集和验证集,即1 440 幅训练集图片,360 幅验证集图片,并采用不同的算法对数据集进行测试与验证。
GC10-DET是在工厂实际生产过程中采集到的焊接件表面缺陷图片数据集,包含10 种不同缺陷的图片。分别为冲孔(Punching,Pu)、焊缝(Welding_line,Wl)、新月形缝隙(Crescent_gap,Cg)、水斑(Water_spot,Ws)、油斑(Oil_spot,Os)、丝斑(Silk_spot,Ss)、夹杂物(Inclusion,In)、轧坑(Rolled_pit,Rp)、折痕(Crease,Cr)和腰部折痕(Waist_folding,Wf),共收录了2 300 幅灰度图像,修正了一些错误信息后,得到数据集图像共2 294 幅。
2.2 实验环境
本文实验在Windows系统上进行评估。实验使用深度学习框架Pytorch和编译器Pycharm。Python版本为3.7,硬件环境为CPU Intel®CoreTMi7-10750H处理器,内存大小16 G;NVIDIA GeForce RTX 2060 显卡。在网络参数设置方面,训练时输入图像设置为640 px×640 px,epoch 设置为120,Batch-Size 为16,训练环节的IoU阈值设置为0.5。
2.3 评估指标
本文主要以平均精度均值(mean Average Precision,mAP)和时间效率作为评定钢材缺陷的方法。一般地,每个分类的识别准确率评估指标由平均精度(Average Precision,AP)来代表。mAP 是各个类型AP的平均值,它是一个整体的衡量指标,反映了目标检测的能力。
mAP、AP指标与准确率(Precision)、召回率(Recall)有关。准确率和召回率的计算方式如下:
式中:σTP为一个被模型预测为正类的正样本;σFP为一个被模型预测为正类的负样本;σFN为一个被模型预测为负类的正样本。
将所获得的准确率与召回率进行比较,得出了一条以R 为横坐标、以P 为纵坐标、表示特定类型的正确率与召回率的关系曲线,并将此曲线进行积分,获得AP值,如式(12)所示。对于含N 种类别的测试集,mAP是单类目标平均准确率除以类别总数N,计算方法如式(13)所示:
mAP数值越大,说明该模型的综合表现越好。
2.4 实验结果与分析
为了验证本文所提模型的可行性和有效性,主要在NEU-DET钢材缺陷数据集上进行了测试,实验结果如表1 所示。YOLOv5 系列模型采用了YOLOv5s、YOLOv5m和YOLOv5l。这3 个模型的区别是网络的层数与深度不同,其中YOLOv5s网络最小,速度最快,精度最低;YOLOv5m 在YOLOv5s 的基础上不断加深网络的宽度,随着网络宽度的提升,速度变慢,精度提高;YOLOv5l在YOLOv5m 的基础上进一步增加网络宽度,提高了精度。实验中,用于对比的参数分别有mAP值、参数量、GFLOPs(模型的计算量,是一种用于评判模型复杂度的标准)、模型大小、训练时间和推理时间。由表1 的数据可以看出,YOLOv5l的mAP值最高,达到了78.2%,但是耗时最久,参数量也最大。Re-YOLOv5 的mAP值略低于YOLOv5l,但参数量缩减了86.9%,模型也减小了80.6MB。YOLOv5s 所用时间最少,训练时间只消耗了0.968 h。Re-YOLOv5 比YOLOv5s的耗时稍有增加,YOLOv5s单幅图片的推理时间为5.5 ms,Re-YOLOv5 单幅图片的推理时间为8.9 ms,但其精度上实现了6.0%的提升,对应的参数量和模型更小。具体地,在Re-YOLOv5 中,SPP*模块增大了感受野,提升了特征融合能力,CCBL模块可以更好地获取感受野的信息,提高模型的精度,更有助于模型的加深,RepVGG 模块能够在模型加深的同时减少所用时间,实现了推理时间的缩短,体现了本文所提模型的优势。

表1 在NEU-DET钢材缺陷数据集上的实验结果
消融实验结果如表2 所示。“√”表示网络中对应模块的添加。本文考虑了用CCBL 模块替换YOLOv5s中的CSP 模块,添加改进的SPP*、RepVGG模块这3 个因素对模型性能的影响,共进行了8 组实验。
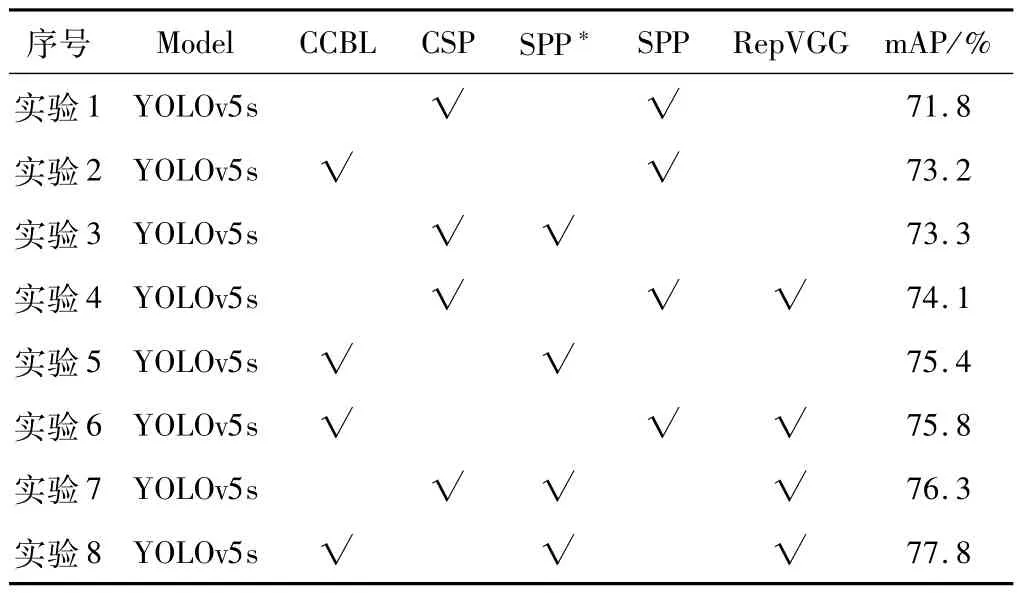
表2 消融实验结果
在消融实验中可见CCBL、SPP*和RepVGG 模块的引入对于基线YOLOv5s 模型的精度提升均有一定程度的帮助。实验1 是原始的YOLOv5 模型用于钢材缺陷检测任务,mAP 为71.8%。实验2 是在原始的YOLOv5s模型中用CCBL模块替换CSP模块,mAP提高了1.4%。结合实验4 和实验6 可见,本文设计的CCBL模块更能加强YOLOv5s的特征提取能力。实验3中,将改进后的SPP*模块引入YOLOv5s中,mAP比原始模型提高了1.5%。综合分析实验4 和实验7,结果表明改进后的SPP*可以增加感受野,有效地提高特征融合的能力,进而实现精度的提升。在实验4 中,融合RepVGG 模块至原始模型中,实现了2.3%的mAP提升。结合实验5 和实验8,表明使用RepVGG 可以提高模型的特征融合能力和对不同尺度目标的检测准确性。
由于6 种钢材缺陷的复杂程度不同,各类算法对其检测准确度也存在较大区别和波动。本文对目前主流算法进行了测试,得到各类算法的AP及mAP 值如表3 所示。本文构建的Re-YOLOv5 模型,由于Head推理端融入了RepVGG模块,并且采用改进后的SPP*模块对候选框进行分类和修正,获取了多尺度特征信息,最终在钢材缺陷数据集取得的mAP为77.8%,相比于原始的YOLOv5s 算法提高了6%。此外,作为经典的两阶段算法Faster R-CNN 模型的检测结果高于YOLOv5s 2.6%,但仍比Re-YOLOv5 低3.4%。RetinaNet、CenterNet 和DETR 的Backbone 均采用Res-Net50。对于NEU-DET数据集,RetinaNet 的准确率为65.4%,对于Ps类别检测结果较好,但是对于Sc 类别的检测效果较差;CenterNet 的准确率为67.9%,对于Cr的检测效果较差;DETR 的准确率为69.5%,对Sc的检测效果较好。对于Cr类别,目前已知的算法均不能获得较高的准确率。分析其原因:由于Cr是细小的目标,且相互交叠,较难进行特征提取,并且其和无缺陷钢材的差别很小,因此导致对于该类别的检测精度较低。但从整体模型准确率来看,本文提出的Re-YOLOv5 性能最佳。

表3 不同算法在NEU-DET数据集上的准确率对比
混淆矩阵是表示精度评价的一种形式,用于可视化算法的性能。由式(12)和式(13)可以计算出mAP。Re-YOLOv5 在NEU-DET数据集上的混淆矩阵实验结果如图11 所示,横坐标代表数据的真实类别,纵坐标代表预测的类别。在目标检测中,判断一个检测结果是否准确是通过计算检测框与真实框的交并比决定的,并根据交并比来判断是否匹配。假设检测框预测的信息正确,并且与真实标注框的交并比大于设定的阈值,代表检测正确(TP);假设检测框预测的信息错误,但是与真实标注框的交并比大于设定的阈值,代表分类错误(FP);假设检测框预测的信息正确,但是与真实标注框的交并比小于设定的阈值,没有跟真实标注框匹配上,则代表定位错误(FP);如果没有检测框,则代表漏检(FN)。
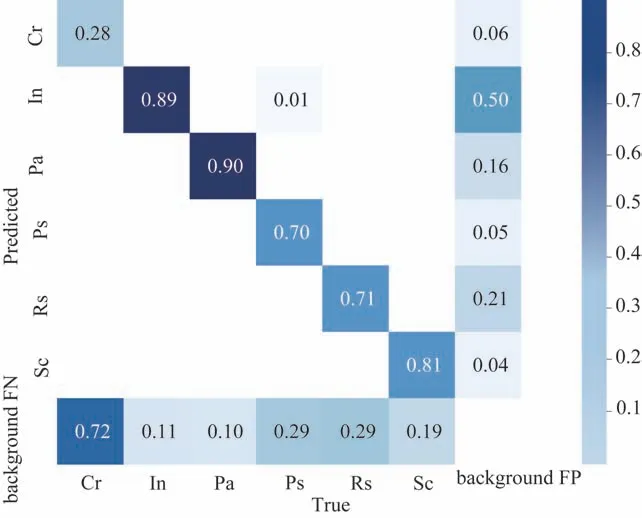
图11 混淆矩阵
由图11 可见,对角线代表的是准确率,颜色越深代表准确率越高。最右边一列代表误检率,In 误检率达到50%,说明Re-YOLOv5 会把一部分不属于In 的缺陷检测为In,主要原因是In 缺陷跟背景比较相似。最下面一行代表漏检率,在已检测到的候选框中,Re-YOLOv5 对于NEU-DET数据集中的Cr缺陷检测准确率为28%,漏检率高达72%。原因是Cr 缺陷目标较小,且相互交叠,较难进行特征提取。虽然Re-YOLOv5 对于Cr检测的正确率不高,但是对于其他5种缺陷的检测准确率均有提升;Re-YOLOv5 也有预测错误的类别,对于Ps,有70%的概率被正确检测,29%的概率漏检,有1%的概率会被错误地检测为In类别,因为数据集里部分Ps 跟In 缺陷较为相似。整体上,Re-YOLOv5 对6 种复杂的缺陷检测正确率较高,误检率和漏检率都相对较低。
图12(a)~图12(d)分别为模型的F1曲线图,P曲线图,PR 曲线图和R 曲线图。通过式(10)和式(11)可以计算出P 和R 的值,通过式(12)和式(13)可以计算出PR的值,并以曲线记录。F1分数是分类的一个衡量标准,介于[0,1]之间,越大越好。图12(a)为F1分数与置信度之间的关系,F1的计算公式为
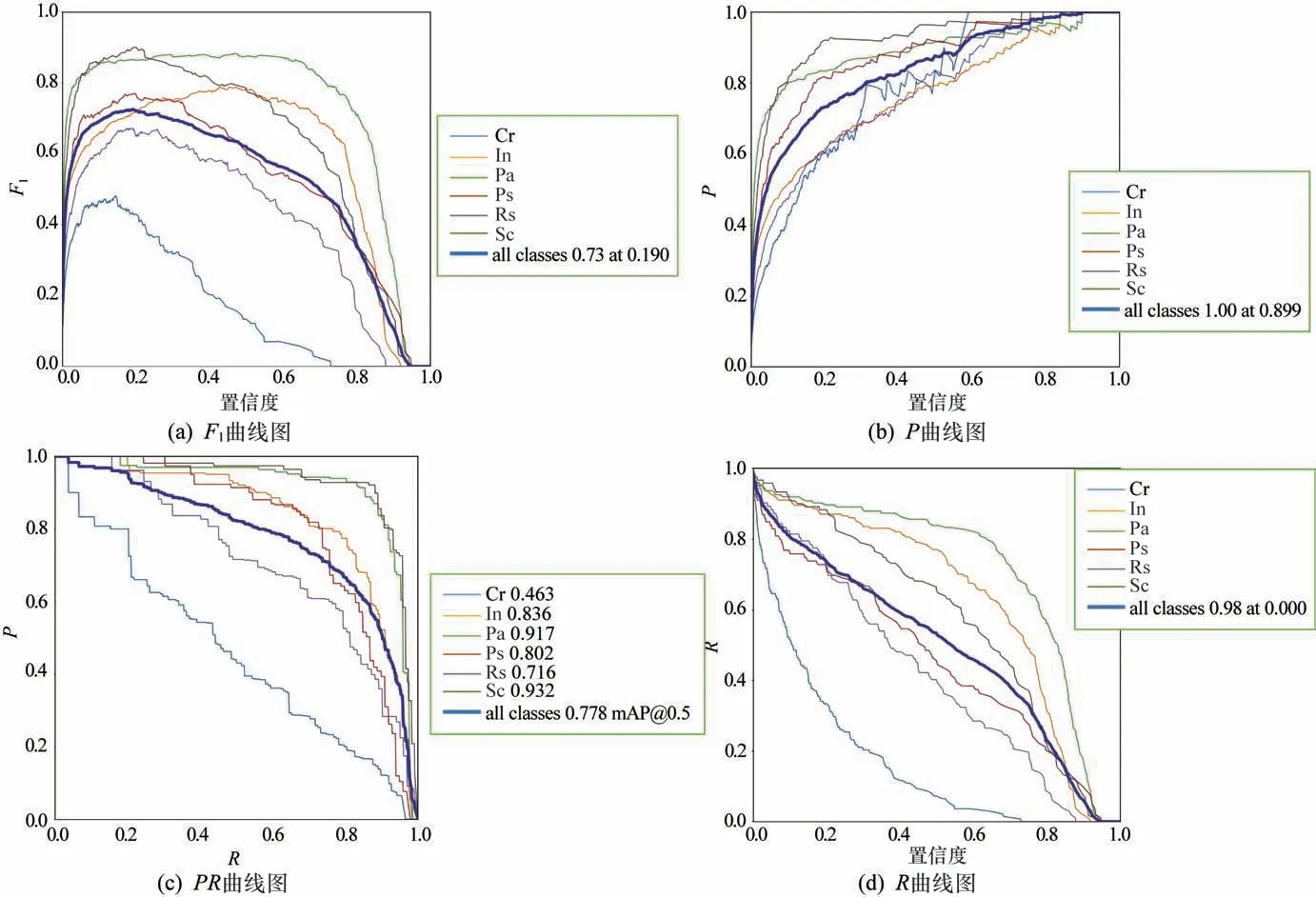
图12 Re-YOLOv5模型评估指标曲线图
由图12(a)可见每个类别的F1值相差比较大,Cr的F1值最低,因此总类别F1值最高,为0.73。图12(b)为准确率与置信度的关系曲线,横坐标为置信度,纵坐标为准确率,由图12(b)可见,所有类别的置信度越高,准确率越高。图12(c)为准确率与召回率的关系曲线,P 与R 所围成的面积即mAP 值,所有类别的平均mAP值为77.8%。Cr的mAP值最低,为46.3%,Pa 和Sc 的mAP 比较高,分别达到了91.7%和93.2%。图12(d)为召回率与置信度之间的关系,可以看出所有类别的平均召回率为98%,表明可以检测出绝大部分的钢材缺陷。图13 为各阶段的Loss曲线图,最终经过120 轮epoch,模型达到了收敛。

图13 Loss曲线图
图14 展示的是YOLOv5s 与Re-YOLOv5 对NEUDET验证集的一些推理结果。从左往右依次为:Cr、In、Pa、Ps、Rs 和Sc。由图14 可见,Re-YOLOv5 对于6 种不同类型的缺陷的检测效果与YOLOv5s 相比,目标检出更多,准确率更高,整体性能有明显提升。

图14 YOLOv5s与Re-YOLOv5对NEU-DET验证集的推理结果
但Re-YOLOv5 仍存在一些检测效果不佳的案例,如图15 所示。第一列是包含Cr 的图片,Re-YOLOv5和YOLOv5s均没有检出。第二列和第三列为Rs和Sc的检测结果。可以看出Re-YOLOv5 对于检测一些有少量的Rs和Sc的图片细化程度没有YOLOv5s高,准确率还有待提升。但是从上述表格中的实验数据总体进行分析,本文提出的Re-YOLOv5 模型的缺陷检测精度整体高于基线模型YOLOv5s。

图15 NEU-DET数据集检测效果不佳案例
此外,为了验证Re-YOLOv5 的有效性,本文在GC10-DET 图片数据集上进行了相应的测试。将GC10-DET数据集按照8∶2 的比例随机划分为训练集和验证集,与基线模型YOLOv5s 进行对比,准确率如表4 所示。

表4 GC10-DET数据集上的准确率对比
如表4 所示,本文提出的Re-YOLOv5 模型对于GC10-DET图片数据集的整体检测准确率依然高于基线模型YOLOv5s。该数据集的10 类缺陷Pu、Wl、Cg、Ws、Os、Ss、In、Rp、Cr 和Wf,大部分图片均包含两种及以上的缺陷,每种缺陷的个数分别为:265、422、227、293、431、701、270、73、60 和117。但由于GC10-DET图片数据集缺陷种类较多,且各类缺陷包含样本数量极不均衡,导致部分检测精度欠佳。
YOLOv5s 与Re-YOLOv5 在GC10-DET 数据集上的检测效果如图16 所示。Re-YOLOv5 的检测准确率整体高于YOLOv5s;YOLOv5s对于一些小目标的检测能力不如Re-YOLOv5,会产生漏检,并且标注检测框的准确度偏低。

图16 在GC10-DET数据集上的检测效果
3 结束语
针对工业钢材缺陷数据集存在的背景复杂、缺陷目标小、类内差异小、类间差异大等问题,为了进一步实现工业钢材缺陷的快速准确检测,本文提出了一种基于结构重参数化的工业钢材缺陷检测方法Re-YOLOv5。在公开的钢材缺陷图片数据集上进行了测试,实验结果表明了本文方法的有效性。得益于RepVGG、SPP*及CCBL模块的特征整合能力、模型加深能力,本文的方法可以在提升网络性能的同时加快推理速度,达到精度与速度的平衡,满足工业部署的需求。在未来的工作中考虑针对类似Cr等不显著缺陷,加入图像增强技术;改进网络的Backbone 部分,并引入自注意力机制,将结构重参数化与DETR 中表现较好的Transformer结合实现结构与性能的整体优化。
