高性能异构加速器MiniGo算子优化方法
2024-04-08贺周雨李荣春姜晶菲
乔 鹏,贺周雨,李荣春*,姜晶菲
(1. 国防科技大学 计算机学院, 湖南 长沙 410073; 2. 国防科技大学 并行与分布计算全国重点实验室, 湖南 长沙 410073)
目前,卷积神经网络(convolutional neural networks,CNNs)在人工智能典型应用领域取得了令人印象深刻的效果[1-6]。结合深度学习和强化学习,深度强化学习(deep reinforcement learning,DRL)被认为是处理决策类问题的有效方法之一。DRL网络模型的推理和训练需要大量的计算和外部存储访问,再加上智能体和仿真环境交互中存在复杂的计算过程,这导致得到一个合格的智能体需要巨大的算力。计算模式复杂、对算力需求高的特点,使得DRL算法适合作为大规模计算平台的系统性能评测应用。因此,MLPerf[7]机器学习基准测试应用集中包含了强化学习分区。MLPerf是一套测量机器学习训练和推理在特定软硬件上性能表现的基准测试应用集,其中强化学习分区基准测试应用是MiniGo。MiniGo训练过程中,需要收集大量自我博弈的样本,因此需要面向大规模计算集群进行部署和优化。通过分析提交结果和代码,在单结点对MiniGo中策略网络进行推理和训练优化是十分重要的。因此,本文研究了MiniGo与自研高性能异构加速器的定制化适配。①结合加速器系统特性对MiniGo算子进行定制化汇编优化,在多核、多向量处理单元(vector processing element, VPE)、多寄存器、多指令间实现并行计算。②在中央处理器(central processing unit, CPU)和数字信号处理器(digital signal processing, DSP)的异构计算层次,提出一种设备间共享内存编码模式,有效减少片内数据搬运开销。同时,在设备间实现流水并行。③提供一个易使用的面向TensorFlow的高性能算子计算库。高性能算子计算库包含了DSP驱动和CPU-DSP异构执行引擎。
1 相关工作
1.1 MiniGo
强化学习普遍对算力需求高,适合应用于高性能异构加速器定制化适配的测试。2013年DeepMind提出深度Q-Learning网络[1],融合深度学习与传统强化学习Q-Learning方法,在Atari中取得了突破性进步。随后AlphaGo[2]、AlphaStar[3]、OpenAI Five[4]、AlphaFold[5]等在围棋、即时战略游戏等领域取得里程碑式的突破。围棋在很长一段时间被认为是人工智能领域最具挑战的经典游戏之一。围棋第一手有361种下法,第二手有360种,第三手有359种,依次类推,一共有 361! 种下法,考虑到存在大量不合规则的棋子分布,合理的棋局约占1.2%,约为2.08×10170[8]。由于搜索空间巨大,围棋存在难以落子的问题。AlphaGo开创性地结合神经网络和蒙特卡罗树搜索(Monte Carlo tree search, MCTS),通过近似估值函数估计对弈结果降低了搜索深度,利用基于策略函数的采样动作降低了搜索广度。经过有监督学习训练、自我博弈强化学习,以99.8%胜率打败所有围棋程序,以5局完胜的成绩打败围棋冠军选手。MLPerf选择MiniGo作为基准测试应用。MiniGo是根据AlphaGo Zero[9]编写的开源围棋智能体训练代码。
MiniGo智能体训练主要分为训练和自我博弈。训练任务中,使用最近的训练得到的模型和其自我博弈产生的样本进行训练,得到新的模型。自我博弈任务中,使用最新模型进行自我博弈,产生新的样本,作为下一次训练的训练样本。两个任务互相依赖,交替进行。训练阶段主要包括数据传递、网络层调度、网络的前向推理和反向更新。自我博弈阶段通过MCTS计算落子位置。MCTS分为选择、扩展、评估、回溯四个部分,其中选择、扩展、评估需要训练模型的推理结果。在自博弈的评估阶段会进行前瞻,通过假想对局来估计当前动作的价值。以1 000个对局为例,平均每1个对局执行前瞻101 884次,1个对局内最大前瞻次数为225 318。其中每次前瞻都会执行1次模型的推理。在1个8核的i7-9700K训练智能体。实验结果显示,在训练阶段,网络的前向推理和反向更新占总时间的71.3%。在自博弈阶段,网络的前向推理占总时间的83.26%。由此可见,模型训练中计算热点在于神经网络算子的计算。它的算子构成如表1所示。
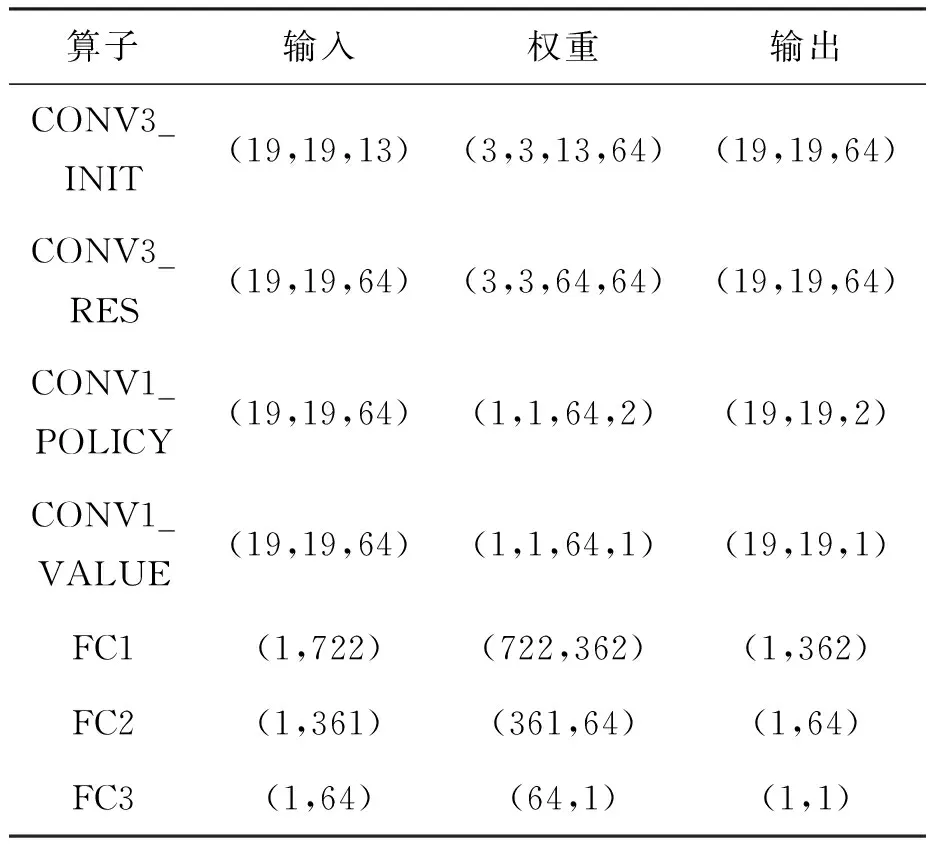
表1 MiniGo网络结构
目前,向MLPerf榜单提交MiniGo训练结果的机构有NVIDIA和INTEL。NVIDIA设计了一个自研CPU-GPU异构计算系统(DGXA100-NGC20.06)训练MiniGo。NVIDIA提供的方法在单结点上的优化主要是卷积神经网络的低精度计算。INTEL设计了一个自研的纯CPU计算系统(4socket-per-node-CPX-6UPI)。INTEL提供的方法在训练时采用单精度浮点计算以保证训练收敛,推理时采用INT8精度计算以保证推理速度。
加速器上的计算资源和存储容量是有限的,优化算子计算映射过程能够有效地提高资源利用率[10]。此外,芯片内外通信的高成本是实现更高性能的另一个主要障碍。大量数据移动和内存访问相关的能量消耗可能会超过计算的能量消耗[11-12]。
结合以上分析,本文方法在异构设备间计算任务分配、异构设备间数据通信、加速器算子计算三个方面进行了优化。
1.2 加速芯片
面对日益增加的算力需求,将计算密集和数据密集的网络计算卸载到加速器处理是一个有效的解决方法。常用的加速器有图形处理器(graphics processing unit, GPU)、张量处理器(tensor processing unit, TPU)、现场可编程门阵列(field programmable gate array, FPGA)、DSP等。它们各自拥有不同的优势。例如,FPGA相对于传统专用集成电路(application specific integrated circuit, ASIC)具有更强的可操作性,在相同功耗效率下可以达到比多核GPU更低延迟的推理。GPU具有可用于较好的软件优化生态环境以及高功耗下的高性能优势。TPU是专为张量(Tensor)计算而设计的加速器。相对于FPGA的低计算能力和GPU的高功耗,基于DSP的矢量处理器取得了性能和功耗的平衡。近年来,加速器的并行计算能力、内存容量、内存速度等都得到了极大的增强。除了硬件设备的改进,相应的面向加速器的算子计算方法也在改进[13-17]。
面对日益增加的算力需求,结合人工智能应用和计算平台特点进行高效适配是一个有效的解决方法[18]。实验显示,计算设备对于不同人工智能应用展现出的利用率不同。一些实验[19-20]表明,面向特定硬件的特定算法的协同优化设计能表现出更好的性能。
目前,面向加速器的算子加速方法研究得到了瞩目的发展。但依然存在一些挑战。首先是针对卷积神经网络的核心计算单元(如通用矩阵乘)在计算过程中如何合理使用特定加速器的多计算资源;然后是如何减少数据在加速器中传输占据的计算时间;最后是如何利用异构设备进行设备间并行计算。本文提出了面向高性能异构加速器的算子优化方法以解决上述问题。
1.3 自研原型系统
本文方法所依托的计算系统为FT-M7032,如图1所示。该系统是国防科技大学面向E级计算自主研发的一款异构计算系统,由大容量片外存储、CPU、DSP簇、内存双倍数据速率(double data rate, DDR)和其他外设组成。计算设备包含1个16核 ARMv8 CPU和4个DSP簇。16核 CPU是裁剪版的Phytium FT-2000+Processor[21-22]。CPU和DSP簇之间共享内存空间。大容量的片外存储和片内内存通过高速网络连接。

图1 原型系统架构图Fig.1 System architecture diagram of prototype system
FT-M7032拥有4个DSP簇,每个簇包含8个DSP核,1个6 MB的片上全局共享存储(global shared memory,GSM)。GSM片上带宽大约为307.2 GB/s,内部包含4个子通路,可作为数据或指令的片上内存使用。单个DSP核在1.8 GHz工作主频下可以提供345.6 GFLOPS的峰值性能。
DSP核主要由标量处理单元(scalar processing unit,SPU)、向量处理单元(vector processing unit,VPU)、直接存储器(direct memory access,DMA)、取指单元和超长指令字控制器组成。VPU 负责向量计算,主要由16个向量处理部件(vector processing element,VPE)与768 KB向量存储(array memory,AM)构成。每个VPE有64个64 bit的寄存器和3个浮点乘累加(float multiply accumulate, FMAC)单元。16个VPE一次可以处理32个单精度浮点数据。AM与向量寄存器之间的带宽为921.6 GB/s。标量存储(scalar memory,SM)与寄存器之间的访问带宽为28.8 GB/s。AM、SM的数据可以通过DMA搬出或搬入。
2 MiniGo算子加速方法
传统算子加速方法通常具有以下问题:①未对不同尺寸算子进行定制化优化,导致资源的浪费;②数据在设备间传递消耗大;③没有考虑异构设备的特性。针对上述问题,提出了一种高效的并行计算策略。在DSP端进行算子计算优化,为MiniGo的算子进行定制化汇编实现。结合原型系统具有异构计算设备、设备间具有共享内存段、MiniGo算法流程的特性实现了异构设备间的高效并行计算。提供了面向TensorFlow的一种类英伟达统一计算架构(compute unified device architecture, CUDA)的高性能算子库,高效调用上述优化的计算。
2.1 DSP端算子计算
FT-M7032的1个DSP簇包含8个DSP核,可以通过DSP核间并行、核内并行、DSP指令集并行加速算子计算。结合性能分析工具,发现MiniGo应用的计算热点集中在神经网络推理和训练过程,即全连接、卷积算子、批量规一化(batch normalization, BN)和修正线性单元(rectified linear unit, ReLU)等算子。为了降低MiniGo应用执行时间,针对这些算子进行了汇编优化,卸载到DSP中高效执行。
本节中数据格式采用TensorFlow默认格式NHWC和NHWK进行说明。其中,I表示输入张量,W表示权重张量,O表示输出张量,N是批大小,H是张量高,W是张量宽,C是输入张量的通道数,K是输出张量的通道数。
2.1.1 全连接算子
针对MiniGo的算子大小、自研系统的特性进行了定制化设计。
以MiniGo中的FC2为例。原始全连接算子的伪代码如算法1所示,本文全连接算子的伪代码如算法2所示。如算法1所示,在原始全连接算子中,内存访问操作数为4NCK次。其中,NCK为循环次数,4为矩阵O读取内存操作、计算后存储到内存操作以及IW的内存读取操作。完成一次全连接算子计算操作为NCK次乘累加操作。本文方法通过结合自研系统的软硬件特性,设计出针对性的优化方法。分析可并行性:对于前向计算,N维度批次之间无计算相关性;输入的一行和权重的一列做乘累加时,在K维上无计算相关性;输入的一行可以进一步划分为多个块,并行地与对应权重相乘,保留中间结果,后续再累加。原型系统拥有多个DSP核,可以实现N维的并行。原型系统拥有多个VPE和寄存器,可以实现K维的并行、块划分的并行和指令向量化寄存器的并行。如算法2所示,在本文方法中,全连接算子的内存访问操作数为4,分别是IWO的内存读取和O的内存写入操作。最内循环计算是(1,19)和(19,64)的矩阵乘法,使用向量化和寄存器化后将原本的1×19×19×64个乘累加指令缩减为19个。经过二次维度拆分并行化、矩阵乘向量化后,原始全连接算子串行的NCK次操作转换为并行的N(C/19)个19次操作。

算法1 原始全连接算子前向计算伪代码

算法2 本文方法全连接算子前向计算伪代码Alg.2 Pseudo code for this method′s fully connected operator in forward calculation
本文方法在片上的具体映射如图2所示,流程为:将I[N][C]在N维进行划分,划分后的矩阵以标量的方式从DDR加载到DSP核的SM中。对W[C][K]进行广播,以向量的形式从DDR加载到DSP核内的AM中。对SM中的数据根据块尺寸进行划分,划分后一组数据大小为(1,19)存入寄存器R中,后续广播到向量寄存器(vecter register, VR)中。将一组数据与权重进行乘累加,得到一组结果放入VR中等待累加,如此循环19次完成N维上的1组数据,放入AM中,后续再通过DMA传回DDR。如此在N维循环8次,得到全连接算子前向计算的结果O[N][K]。反向过程类似,在N维并行地在多核计算。每个核中处理一组数据,循环19次乘累加。在最后一次累加后将结果传入GSM中。由此得到8组数据,对位相加得到权重的更新值。

图2 全连接计算片上映射示意图Fig.2 Schematic diagram of on-chip mapping for fully connected computation
2.1.2 卷积算子
卷积是MiniGo中最耗资源的运算,将卷积计算卸载到DSP进行,能够有效加速计算。常用的卷积计算并行方案有im2col、傅里叶卷积、winograd、直接卷积。im2col会导致输入矩阵膨胀,恶化访存。傅里叶卷积增大了输入和卷积核大小,从而增加了内存带宽的需求。傅里叶卷积计算更复杂,涉及复数乘法,不适用于小卷积核。winograd中转换映射的矩阵越大,计算精度的损失越大。结合DSP结构设计和MiniGo网络设计,本文方法选择了直接卷积的实现方法。
直接卷积涉及输入特征图和核权值的三维乘积累加运算,计算过程如图3所示。其中,图3(a)为前向计算过程,图3(b)为反向计算权重值过程。根据卷积计算的特性,分析可并行性。通过分析前向计算过程可知,N维度批次之间无计算相关性。可利用这个特点实现DSP内多核并行。对于每个批次为N/8的直接卷积,输出通道K维度之间无计算相关性,可实现DSP计算单元的硬件并行。对反向计算过程进行分析。根据对其计算过程进行拆分,可以分为2个部分:①批次之间无计算相关性的,利用DSP多核、核内多计算单元并行;②批次之间存在数据交互的,则使用直接累加归约和二分累加归约。

(a) 前向计算过程(a) Forward computation process
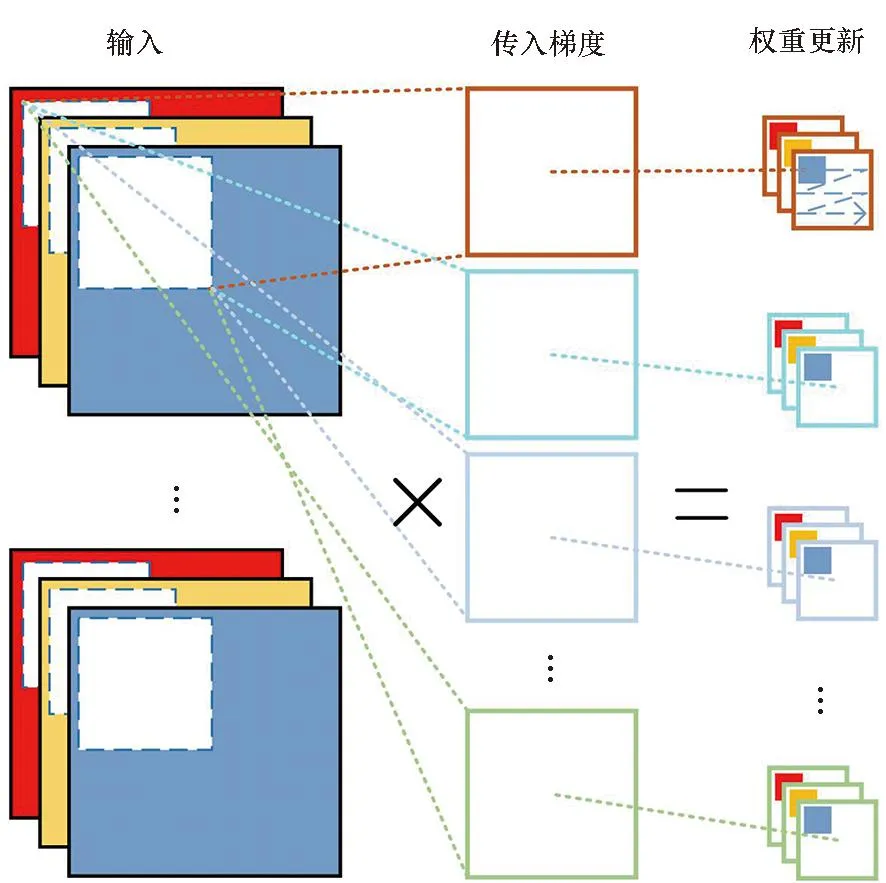
(b) 反向计算过程(b) Backward computation process
MiniGo中的卷积算子根据数据规模可分为CONV3_INIT,CONV3_RES,CONV1_POLICY,CONV1_VALUE。以CONV3_INIT为例,卷积前向计算在原型系统中的伪代码如算法3所示。在N维上划分I,将数据均匀分到8个核上并行计算。复制8份W广播到各个核内的AM中。在K维和C维上做循环,将一组大小为(3,3)的W放入VR中等待计算。在H和W维做循环,确定I的中心点,将中心点坐标放入R1和R2中。判断当前中心点是不是边界,如果是,则进行padding。取中心点周围9个数据,存入VR中。
在VR中进行矩阵乘,得到O的1个值。将输出从VR存入GSM。如此进行循环,得到O。
把O通过DMA输出到DDR中。分析上述计算过程的并行性。在算法3的步骤2利用8个核在N维上实现并行。在步骤5利用多VPE和多寄存器,在K维实现并行。在步骤11,乘累加需要6个指令周期,跳转指令需要7个指令周期,同时进行这2个指令,从而覆盖部分进行边界判断的消耗。本文方法的卷积算子在汇编过程中利用多核、多VPE、多寄存器、指令周期重叠实现了并行计算。

算法3 CONV3_INIT前向计算伪代码Alg.3 Pseudo code for CONV3_INIT operator in forward calculation
2.1.3 BN+ReLU
BN有助于训练更快地收敛并防止网络过拟合。对于1个批次的输入X=[x(1),x(2),…,x(m)],μ是X的均值,δ2是X的方差。输出Y=[y(1),y(2),…,y(m)]。BN前向计算公式为:
(1)
式中,γ和β分别是通道尺度和偏差。在MiniGo中激活函数是ReLU,如式(2)所示。
(2)
其中,a等于0。当x大于0时,不变;当x小于等于0时,x置0。
本文方法将BN和ReLU合并为1个算子,能够有效减少数据在片上的频繁读写。BN+ReLU计算的输入数据大小为NHWC。在N维可以使用多核并行计算。N维之间存在数据交互,使用直接累加归约和二分累加归约。单个DSP核内,在C维进行VR级并行。C是64,是VR处理数据能力的倍数。将单核内拆分后的数据组累加后保存在AM中,再把每个核的累加结果存储到GSM中。在BN计算后进行ReLU计算。对于正向计算,直接对BN的输出进行判定,当前值小于0则赋值为0,反之不变。反向计算时,如果当前位置的正向ReLU的结果为0,则将该位置上对应的传入梯度赋值为0,反之不变。
2.2 异构设备间并行
原型系统由1个16核CPU、4个DSP簇、1个异构设备共享的DDR构成CPU-DSP异构计算节点,如图1所示。因此,可以依托CPU-DSP异构计算整合计算资源完成一个任务,以适配MiniGo的复杂计算需求。
2.2.1 流水并行
异构设备流水并行操作重叠了CPU数据处理和DSP算子计算时间。CPU数据处理包括网络构建、节点间通信、规约计算、蒙特卡罗树搜索。以自我博弈任务为例,智能体下一步行动根据蒙特卡罗树搜索结果确定。蒙特卡罗树搜索分为选择、扩展、推理、回溯,其中选择和推理需要训练模型的推理结果。因此,本文方法将复杂的计算任务分割,将网络算子计算卸载到DSP进行,其余在CPU进行,实现了异构设备间的流水并行。流程为:DSP完成算子计算后将结果返回给CPU进行蒙特卡罗树搜索。CPU进行蒙特卡罗树搜索的同时,DSP开始下一批次的算子计算。
2.2.2 共享内存编码
在CPU-GPU异构计算系统中,CPU侧内存数据首先通过CPU调度经过总线和接口标准(peripheral component interface express, PCIE)总线传输到GPU侧显存中。GPU计算后,将结果从显存再经PCIE总线传输到内存,完成一次计算卸载。为了减少数据搬运,TensorFlow等框架一般会把所有的算子参数都放到显存,只在数据预取有一次CPU-GPU的搬运。但对于增量式搬运,则需要更多的CPU-GPU数据搬运,或者通过重叠减少数据搬运的影响。原型系统中,DDR中存在CPU-DSP共享的物理地址空间。因此,根据原型系统这一特性设计了共享内存编程。张量中权值变量、输入输出等内存管理全周期都在共享物理地址空间,既无数据搬运的问题,也无复杂的流水调度重叠通信和计算。根据原型系统的共享内存体系结构设计了共享内存编码模式。对于整个神经网络的前向、反向计算过程,可以减少数据在CPU和DSP之间的拷贝,从而减少了计算时间。
2.2.3 高性能算子库
为了让TensorFlow等深度学习框架使用DSP实现高性能的神经网络推理和训练,设计了类英伟达CUDA的高性能算子库,如图4所示。高性能算子库包含了DSP驱动和CPU-DSP异构执行引擎。高性能算子库将优化后的底层算子实现封装,给TensorFlow等深度学习框架提供统一的接口,供上层应用灵活使用。如图4所示,左边是调用TensorFlow库实现网络构建,右边是调用本文方法算子库实现网络构建。

图4 算子库调用示例Fig.4 Example of calling the operator library
3 实验
本节通过实验测试本文方法的性能。如无特别说明,输入数据的大小均为(96,19,19,13),数据类型为单精度浮点数。
3.1 DSP端算子优化
3.1.1 卸载算子计算
在本节对比了DSP端算子优化前后性能。优化前实验设置为使用TensorFlow算子库在纯CPU上进行计算。根据使用核数的不同分别记为CPU-1、CPU-4、CPU-8、CPU-16。优化后实验使用8个DSP核进行计算,记为DSP-8。
实验结果如图5所示。算子优化后各个算子计算速度有不同程度的提升。其中CONV3_RES的计算速度提升最为明显。以CPU-8作为Baseline对比DSP端算子计算优化性能。卷积算子的计算速度均有较大提升。CONV3_RES的一次前向计算耗时从38.38 ms降至4.02 ms,反向计算耗时从178.05 ms降至4.2 ms。加速比分别为9.54和42.29。CONV3_INIT的前后向加速比分别是2.31和11.53。CONV1_POLICY的前后向加速比分别是6.19和11.53。CONV1_VALUE的前后向加速比分别是1.94和9.63。FC性能提升不理想。原因在于MiniGo中FC2维度尺寸小,在DSP上计算快,申请内存和数据搬运操作相对慢。
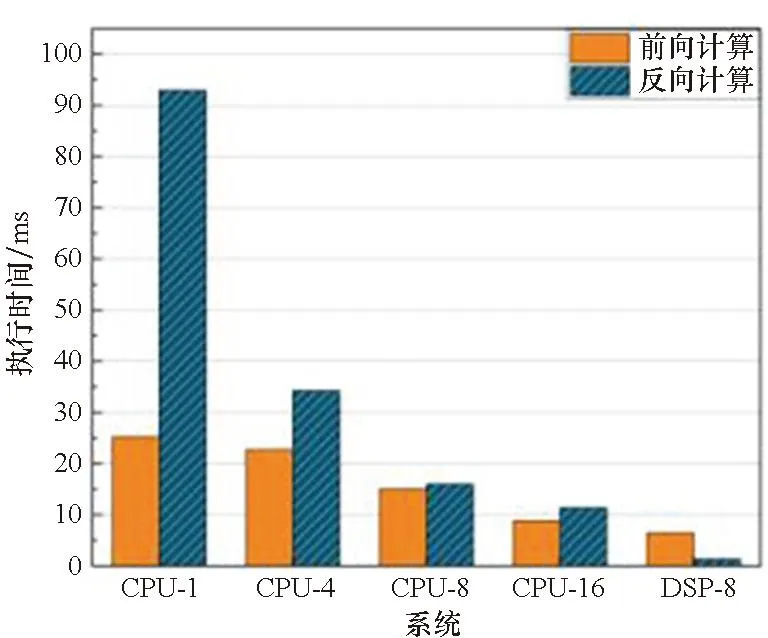
(a) CONV3_INIT
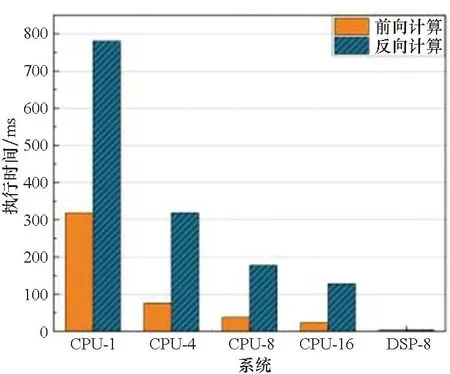
(b) CONV3_RES
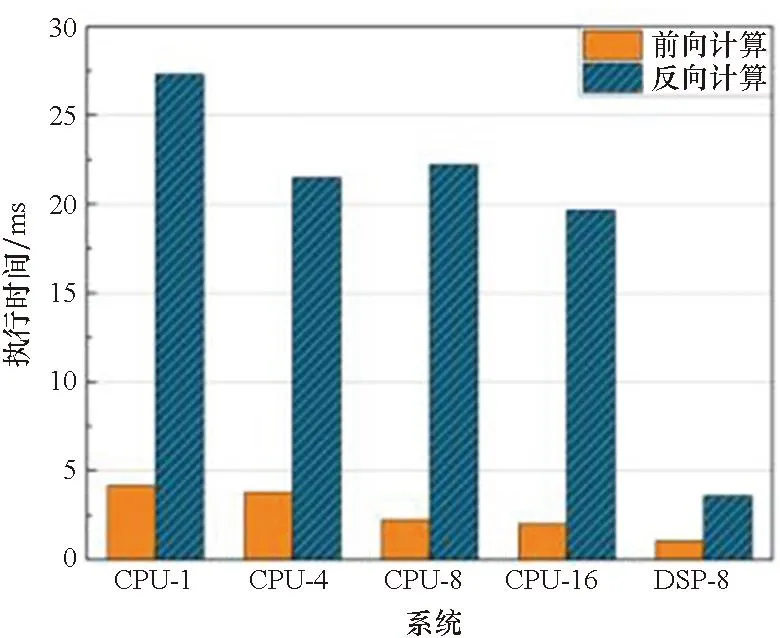
(c) CONV1_POLICY

(d) CONV1_VALUE
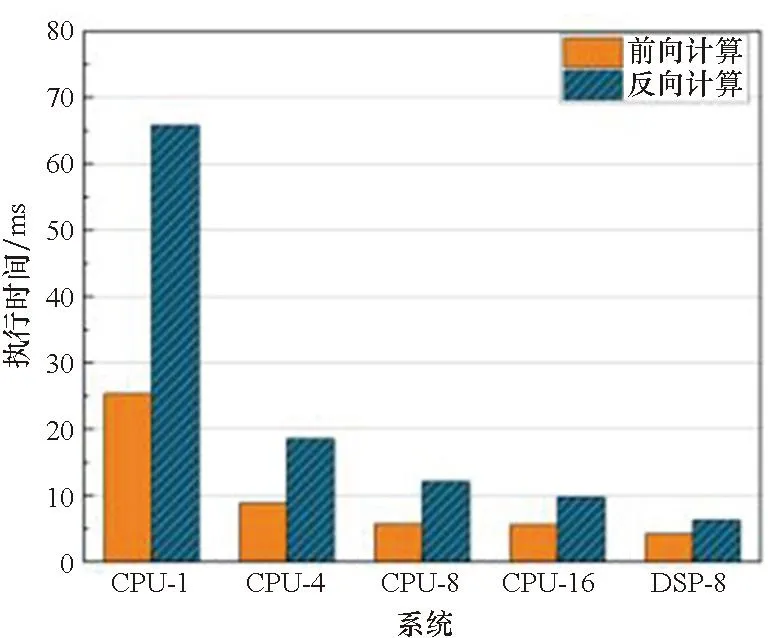
(e) BN+ReLU
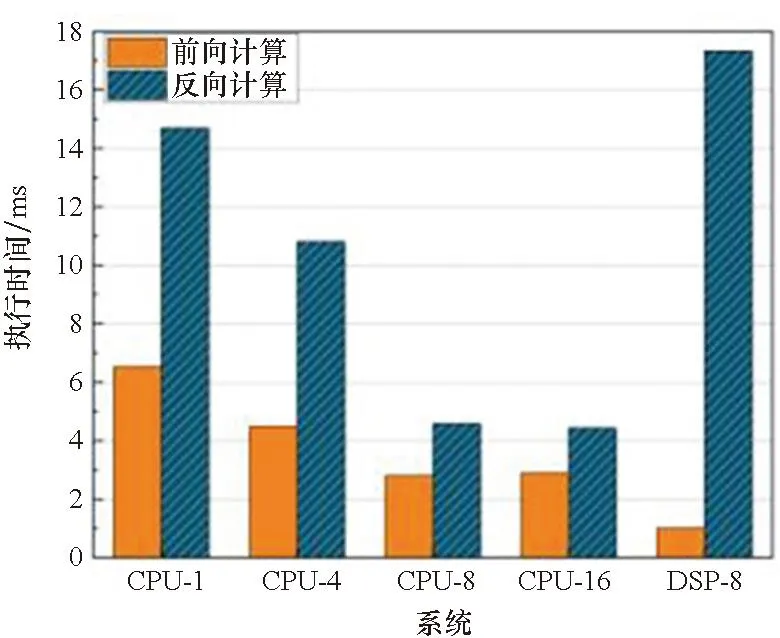
(f) FC1

(g) FC2

(h) FC3
3.1.2 扩展性
扩展性是验证并行计算方法性能的有效方法。扩展性为固定计算规模、增加计算资源得到的并行效率。在本节讨论了算子计算优化后的扩展性。实验设置为,固定使用的DSP核数为8,输入数据的批大小,分别在数据批大小为96和768上进行训练,记录1步中各算子耗时。重复进行多组实验。该实验以在单核计算的算子计算耗时为基准,记录在8核计算的算子计算耗时相对于基准的加速比。实验结果显示,CONV3_RES算子多核并行后加速比提升最大。当批大小分别是96和768时,CONV3_RES的加速比分别是16.22和24.69。CONV3_INIT的加速比分别是4.40和4.44。BN+ReLU也有明显的速度提升。FC3加速比提升最小。原因是MiniGo中FC算子计算量小。受限于带宽,内存申请、数据传输时间大于计算时间,导致收益不高。实验结果证明,实现算子的多核计算能有效提升计算速度。当一次计算数据规模扩大8倍时,能保持大约一致的加速比。
3.1.3 计算效率
为了验证所提方法在自研原型系统上的有效性,以计算量最大的CONV3_RES为例,分析了其计算量、计算性能和计算效率,如表2所示。
由表2结果可知,在相对小的计算量的情况下,计算效率达到23%左右。主要原因是计算量小,计算时间相对于数据传输时间占比降低。随着计算量增加,本文实现的计算性能和效率在提升。说明本文方法有效利用了硬件结构特点,能够有效发挥其计算性能。
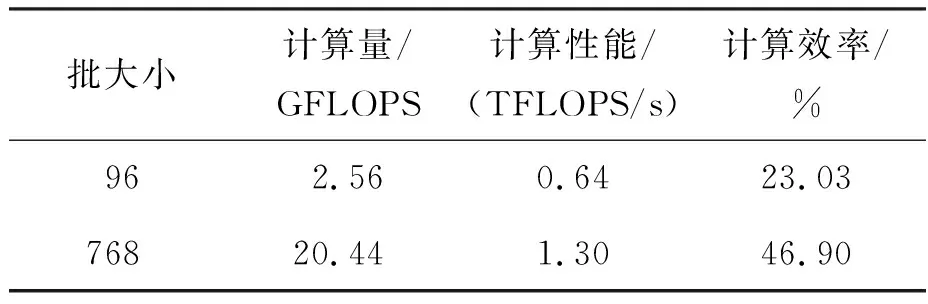
表2 DSP-8下的CONV3_RES的 计算量、计算性能、计算效率
3.2 异构设备间的共享内存编码优化
本节的基准测试记为DSP-SMP。使用TensorFlow框架的默认异构计算接口,数据在CPU和DSP之间显式搬运,在DSP上进行MiniGo训练。优化后实验记为DSP+SMP,使用共享内存编码优化后,在DSP上进行MiniGo训练。采用算子计算时间来衡量共享内存编程优化带来的性能提升。
表3和表4展示了共享内存编码优化前后各个算子计算时间对比。各算子在前向和反向计算中,共享内存编码均表现出一定的性能提升。其中,卷积计算的速度提升最为明显。CONV3_INIT反向计算的加速比是11.88。CONV3_RES前向计算耗时从16.85 ms降到4.02 ms,加速比是4.19。相应地,反向计算平均耗时从35.59 ms降到4.21 ms,加速比是8.45。BN+ReLU前向计算和后向计算的加速比分别是4.42和5.56。从实验结果可知,共享内存编码大大地缩减了计算时间。
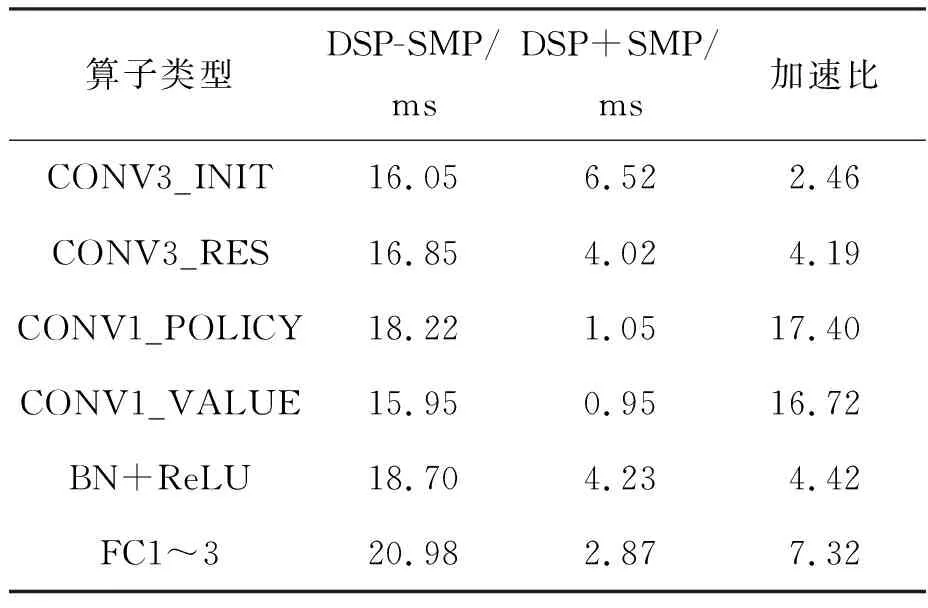
表3 共享内存编码优化前后前向计算平均时间对比Tab.3 Comparison of forward calculation time before and after shared memory programming optimization

表4 共享内存编码优化前后反向计算平均时间对比Tab.4 Comparison of backward calculation time before and after shared memory programming optimization
3.3 耗时与加速比
在本节中,展示了本文方法在训练阶段和自博弈阶段的整体加速效果。Baseline实验为CPU-8,设置见3.1.1节。
智能体训练阶段和自博弈阶段耗时对比如表5和表6所示。在训练阶段中,1步中前向计算总耗时从606.18 ms降至236.79 ms,反向计算总耗时从1 642.00 ms降至350.62 ms。加速比分别为2.56和4.68。1步训练时间从2 248.18 ms降为587.41 ms,加速比为3.83。由于1次对局中行动长度波动较大,在自博弈阶段选取前瞻次数为10 000进行分析。在CPU-8中执行10 000次前瞻的自博弈推理时间为1 185.87 s,在DSP-8中为816.48 s。DSP-8在自博弈推理阶段的加速比达1.5。综上,本文方法能够实现MiniGo算子加速。
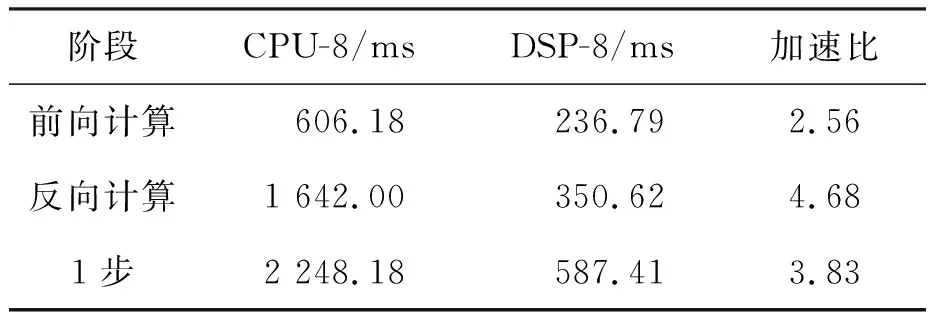
表5 1步内训练耗时对比

表6 自博弈推理耗时对比
4 结论
本文结合MiniGo计算过程特点和高性能异构加速器特性,主要针对传统算子加速方法没有实现定制化汇编导致的资源浪费、片上数据传输消耗大和异构计算资源分配的问题进行了优化。首先,针对算子计算-访存特性和计算平台资源定制了算子计算,在多核、多VPE、指令集方面实现了并行计算。然后,结合计算平台拥有设备间共享存储段的特性,设计了共享内存编码模式,减少数据传输消耗。最后,结合算法计算流程在CPU-DSP间实现了流水并行,合理分配任务和资源。同时,面向TensorFlow实现了一个易于使用的高性能算子库。实验部分对比了本文方法的算子计算在多核并行化的性能提升、共享内存编码模式带来的性能提升。本文方法实现了面向高性能异构加速器的MiniGo算子加速。
