多模态交叉解耦的少样本学习方法
2024-04-08王思迪于云龙
冀 中,王思迪,于云龙
(1. 天津大学 电气自动化与信息工程学院, 天津 300072; 2. 浙江大学 信息与电子工程学院, 浙江 杭州 310027)
近年来,深度学习技术在人工智能领域取得了令人瞩目的成绩,例如图像分类[1-2]、目标检测[3-4]和行人重识别[5-6]等。这些方法大多都依赖于大量的标注数据。然而,人类可以通过少量的样本学习到新知识,这种“举一反三”的能力极大地启发了研究人员,少样本学习[7-8]就是其中一类有代表性的技术,其目的是从有限数量的标注数据中快速学习类别知识。
本文针对图像少样本分类技术展开研究,现有方法通常通过有限样本学习一个可迁移模型,利用少量视觉样本识别新的类别[9-10]。然而,现有方法更多地关注样本视觉表征较为单一的类别,当样本视觉表征多样化时,较难准确分类。
具体地,在少样本学习中由于可用于训练的标注样本数量极为有限,因此这些样本较难完全反映类别的多样性视觉表征。这本质是由于一些类别具有多元属性。例如“苹果”同时具有“红色”和“黄色”属性。属性多元化会造成视觉表征复杂度的提高,从而损害属性无关视觉特征的提取,本文将这种问题称为“多元属性问题”。如图1所示,当有限标注的样本都是红色苹果时,该类别特征将会突显其“红色”视觉表征,而当测试样本是黄色苹果时,此时由于香蕉常带有“黄色”表皮属性,因此少见的“黄色”苹果易被错分为香蕉。
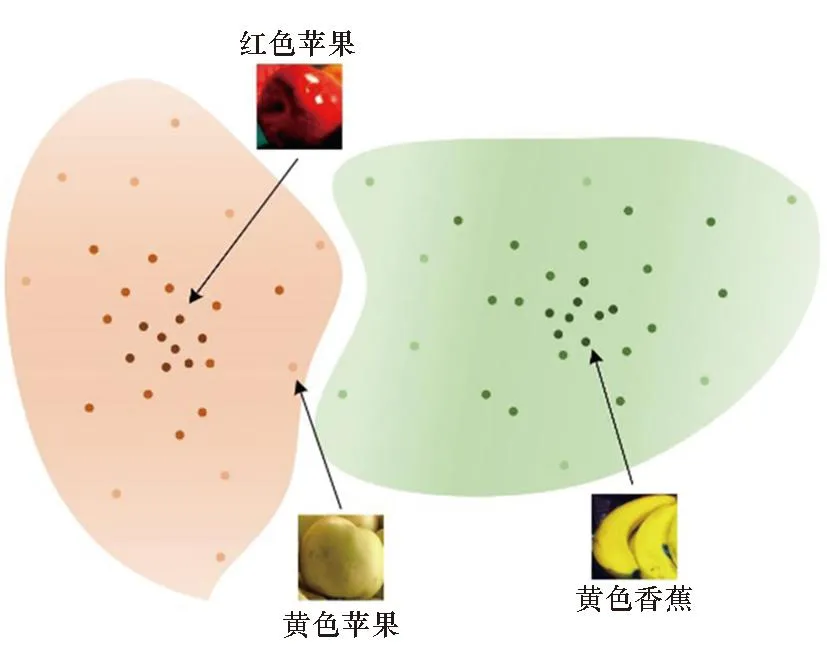
图1 多元属性样本分布Fig.1 Distribution of diverse attribute samples
如何从有限样本中提取到属性无关的类别特征是解决上述问题的关键所在。在少样本学习中,视觉特征往往受到对应属性的影响,容易偏向学习表层属性而忽略类别本质。相比之下,样本的类别和属性信息易于获取,并能指导视觉特征的提取。因此,一些少样本学习方法[11-12]借鉴多模态学习的思想,通过利用辅助模态如类别属性、文本描述等来帮助分类,在一定程度上可缓解多元属性问题的影响。例如,自适应跨模态(adaptive modality mixture mechanism, AM3)方法[11]自适应地将语义和视觉信息组合起来,通过语义中的类别信息指导视觉特征提取。属性引导注意力模块(attributes-guided attention module, AGAM)[12]使用类别语义信息引导特征提取,与视觉信息结合进行注意力对齐。然而,这些方法均侧重于使用单一的类别语义信息促进视觉特征的提取,忽视了类别中存在属性的多样性以及不同属性间的差异对正确识别样本类别作用的不同[11-12]。
针对这一问题,本文提出一种多模态交叉解耦(multimodal cross-decoupling, MCD)的少样本图像分类方法,通过学习样本的视觉特征、类别语义特征和属性语义特征,解耦出样本的多元属性,来减少属性多样化带来的分类差异,缓解多元属性问题对分类的影响。
现有的少样本学习方法大致可以分为三个类别:基于优化的方法、基于生成的方法和基于度量的方法。
基于优化的少样本学习方法通过学习一个元学习器和调整优化算法的参数来适应少样本分类任务。这些方法通常在基类样本上进行训练,得到一个学习模型,然后在新类样本的少样本任务中进行微调。与模型无关的元学习(model-agnostic meta-learning, MAML)方法[2]通过在元训练阶段让模型学习一个较好的初始化参数,并在新类少样本任务上经过几步梯度更新优化模型参数。具有潜在嵌入优化(latent embedding optimization, LEO)的元学习方法[13]改进了MAML方法,通过编码器将特征表达映射到低维隐空间,并使用解码器将隐向量转化为高维模型参数,通过优化隐向量来进行参数更新。
基于生成的少样本学习方法,其思路是通过对样本进行变换以达到数据增强的目的,或是使用生成对抗网络来扩大样本空间,从而弥补类别样本数量少的不足。Chen等[14]提出的图像变形元网络(image deformation meta-networks, IDeMe-Net)使用网络学习生成不同的变换图形来扩充数据,并提取特征信息。Li等[15]提出的对抗性特征幻觉网络(adversarial feature hallucination networks, AFHN)利用生成对抗网络(generative adversarial networks, GAN)生成多样性样本,并引入分类和反崩溃正则项。
基于度量的少样本学习方法通过将支持集和查询集的特征映射到一个新的度量空间,并学习可迁移的距离度量来进行分类。原型网络(prototypical networks, PN)[7]将同类别样本特征均值作为类原型,并使用欧氏距离计算查询样本与类原型之间的距离来分类。关系网络(relation network, RN)[8]通过神经网络学习动态的度量模型,并利用该模型计算查询样本与支持样本之间的相似度。Li等[16]提出的深度最近邻网络(deep nearest neighbor neural network, DN4)方法通过使用局部描述子来比较查询图像与支持集之间的相似度。
多模态学习研究不同模态数据的机器学习问题,通过挖掘模态间的互补性或独立性来表征多模态数据。多模态表示学习应用于编码不同模态数据中的语义信息,并学习各模态的特征与映射关系,其在跨模态检索[17-18]、图文匹配[19-20]、零样本学习[21-22]等任务中都有着较为重要的作用。
多模态少样本学习方法通过引入语义信息,联合训练文本和视觉特征,提升少样本分类任务性能。例如,AM3方法[11]利用语义表征提供先验知识来补充视觉信息,通过凸组合将视觉和语义表征结合起来进行分类。模态交替传播网络(modal-alternating propagation network, MAP-Net)[23]利用图传播指导语义图更新,通过计算视觉特征相似性弥补缺失的语义特征。属性指导特征学习(attribute-guided feature learning, AGFL)方法[24]通过属性相关表示建立联系,增强相同属性在不同类别的表达。
本文所提方法是一种基于度量学习的多模态少样本学习方法。与以往方法不同,本文方法针对少样本多元属性问题,能够识别带有相似属性的同类样本,同时还能够具备识别出有不同属性的该类样本的能力。
1 方法实现
1.1 问题定义
假设存在一个给定数据集D={Dtrain,Dtest},其中训练集Dtrain和测试集Dtest在样本空间中不相交。训练集样本Dtrain包含了大量的类别,其标签空间为Cbase={c1,c2,…,cn},n表示总类别数量。标准的少样本分类任务(每一个任务包含N个类别、每个类别包含K个样本)被称作N-wayK-shot任务,一般K是比较小的整数,如1或5。
在少样本分类任务中K值较小导致训练样本不足,元学习方法通过使用大量训练集数据Dtrain合理解决这一问题。常见的基于度量学习的少样本分类方法基于episode的形式实现元学习的训练与测试,并通过episode随机采样形成上述的N-wayK-shot任务。通常情况下,每一个episode包含一个支持集XS和一个查询集XQ。在支持集XS中所有样本x都是标注数据,通过特征提取器f得到样本特征f(x),同时可以利用原型网络[7]计算类别原型P作为支持集类别的样本特征。而在查询集XQ中每个样本都是无标注数据。
1.2 整体框架
针对多元属性问题提出的多模态交叉解耦的少样本分类方法整体框架如图2所示。模型方法由多模态交叉解耦和特征重建两个部分组成。在元训练阶段,多模态交叉解耦模块将样本的视觉特征、多种语义特征进行解耦,以得到解耦后的类别特征和属性特征。为保证解耦出来的特征能够准确地表示原样本,利用特征重建模块将解耦后的特征重新进行融合,并与原本的全局视觉特征进行约束。在元测试阶段,因为查询集没有语义信息,所以使用自解耦来代替交叉解耦,并与支持集样本解耦后的类别特征进行分类损失判别。
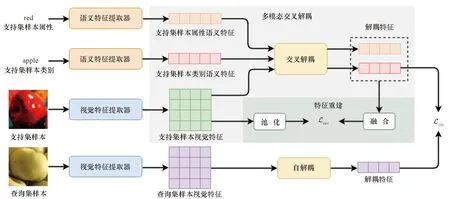
图2 所提多模态交叉解耦的少样本分类方法框架Fig.2 Proposed framework of multimodal cross-decoupling few-shot classification
1.3 多模态交叉解耦
为了缓解多元属性问题,提出利用信息交叉解耦的思想,从多模态信息中学习有效的类别信息,弱化属性特征对分类效果的影响。

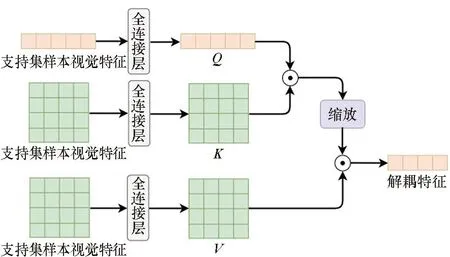
图3 交叉解耦示意图Fig.3 Illustration of cross-decoupling
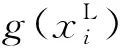
(1)
(2)
(3)
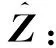
(4)
(5)
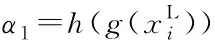
(6)

通过上述过程,模型将重点关注视觉特征中与语义特征相关性较高的部分,通过交叉注意力机制提取视觉特征中与类别相关的特征和与属性相关的特征,并分别与原类别语义特征和原属性语义特征进行融合,从而进一步强化语义信息对视觉特征的指导作用,实现了视觉特征中类别与属性的解耦。
与支持集样本不同的是,查询集样本xq不具备语义信息,因此采用自解耦的方法对查询集的视觉特征进行训练得到解耦后的类别特征。具体地,在利用交叉注意力机制时对于计算查询集样本的Q′、K′和V′分别表示为:
(7)
(8)
(9)

(10)
(11)
1.4 特征重建
在此阶段,为保证支持集解耦后的类别特征与属性特征仍可准确表示原样本,采用特征重建的方式,通过将解耦后的特征进行融合得到重建后的特征,与原样本的全局特征进行约束。
(12)
式中,β=h(ZSA)同样是一个可学习的参数。
同时,原样本的全局特征由f(xi)池化得到:
(13)
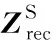
(14)
因此模型学习特征信息时将继续朝着贴近样本本质的方向进行优化。
冬天,感冒几乎是宝宝们最常得的疾病了。感冒的症状一般有流涕、咳嗽、发烧、喉咙疼等,爸爸妈妈对症做好家庭护理很重要。另外,如果病情较重,需要就医用药,爸爸妈妈也需要知道一些用药误区,以减轻对宝宝的伤害。
1.5 少样本训练
对于一个N-wayK-shot的少样本分类任务,当K值不为1时,每个类别的支持集样本均采用原型网络[7]的方法,计算每个类别样本视觉特征、解耦后的类别特征和属性特征的向量均值作为对应的特征原型。以样本解耦的类别特征为例,对于类别c,其解耦类别特征原型为:
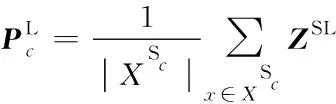
(15)
式中,XSc表示支持集样本中属于类别c的数据,|XSc|代表属于类别c的样本数量。
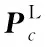
(16)
这里,p(y=c|xq)表示查询集样本xq属于类别c的概率值,c′表示任一类别,d(·)为欧氏距离的相似度度量。
利用交叉熵损失作为其分类损失函数进行训练:
Lcls=-lgp(y=c|xq)
(17)
合并所有损失函数得到最终的目标函数:
Lobj=arg minLcls+γLrec
(18)
式中,γ为超参数,用来平衡最终的损失函数。
2 实验
2.1 实验设置
2.1.1 数据集
本文所提方法在MIT-States[25]和C-GQA[26]两个数据集上进行实验。MIT-States数据集[25]由53 155张现实世界图像组成,其中每个图像都包含它的形容词属性和名词类别,例如“黄色的苹果”。对该数据集按名词进行划分后,一共有243个名词类别,其中160个名词用作训练、40个名词用于验证、43个名词用来测试。此外,一共有115种形容词属性。同时,由属性和类别组成的词共1 761对,分别用在训练集、验证集和测试集的对数分别为1 179、271和311。
C-GQA[26]数据集源于Stanford GQA数据集[27],具备更清晰的标签和更大的标签空间,挑战性更大。该数据集共有27 062张图像,按名词划分后得到训练集、验证集和测试集的图像数量分别为20 786、3 511和2 765。相应地,其名词类别数量分别为120、30、31。C-GQA的训练集包含153种形容词属性。这里,由属性和类别组成的词共931对。数据集MIT-States和C-GQA的具体信息见表1。

表1 数据集划分
2.1.2 实验细节
在实验中,数据集MIT-States和C-GQA的图像均调整为224×224的尺寸,其类别和属性的语义向量通过word2vec[28]得到,维度为600。并且,在两个数据集上训练并测试了5-way 1-shot和5-way 5-shot任务的准确率。首先,使用Adam优化器进行预训练,在训练集样本上训练60个批次。这里初始学习率设置为0.001。之后,采用元训练的方式进行微调。在微调时,利用随机梯度下降(stochastic gradient descent, SGD)优化器[29]训练30个批次,每个批次随机采样1 000个episode;初始学习率设置为0.000 1,并且每隔10个批次学习率减小至原来的1/10;此时动量参数设置为0.9,权重衰减率为0.001。在训练和测试时,视觉特征的提取均采用ResNet18[30]作为主干网络,特征提取器的输出维度为512;语义特征的提取则采用多层感知机(multilayer perceptron,MLP),其输出维度也为512。对于超参数γ,在5-way 1-shot的任务中取0.4,在5-way 5-shot任务中取0.3。所有对比方法都使用相同的视觉和语义特征,并且调整参数达到其最优性能。
2.2 实验结果
与常见少样本分类工作的测试设置不同,将测试集分成两个部分:与支持集属性相同的查询集样本和与支持集属性不同的查询集样本。首先,在测试集中随机采样2 000个episode,每个episode中的每个类别包含2个无标注的查询样本用来测试,即与支持集属性相同的测试样本(same support attribute, SSA)和与支持集属性不同的测试样本(different support attribute, DSA)各一个。然后,对2 000个episode上的SSA和DSA分别求平均准确率。最后,求所提方法对多元属性样本准确率,即求两种准确率的调和平均数(harmonic mean, HM)作为最终评价指标:
(19)
本文选取了7种对比方法,包括3种不使用语义信息的方法(ProtoNet[7]、RelationNet[8]和MatchingNet[31])以及4种使用语义信息的方法(AM3[11]、AGAM[12]、MAP-Net[23]和SGAP[32])。表2和表3为本文方法在2个数据集上的实验结果。可以明显地看出,本文方法性能均较为显著地优于所有对比算法。另外,在SSA上的分类性能整体较DSA上的分类性能高,这表明多元属性问题确实会影响模型的分类性能。
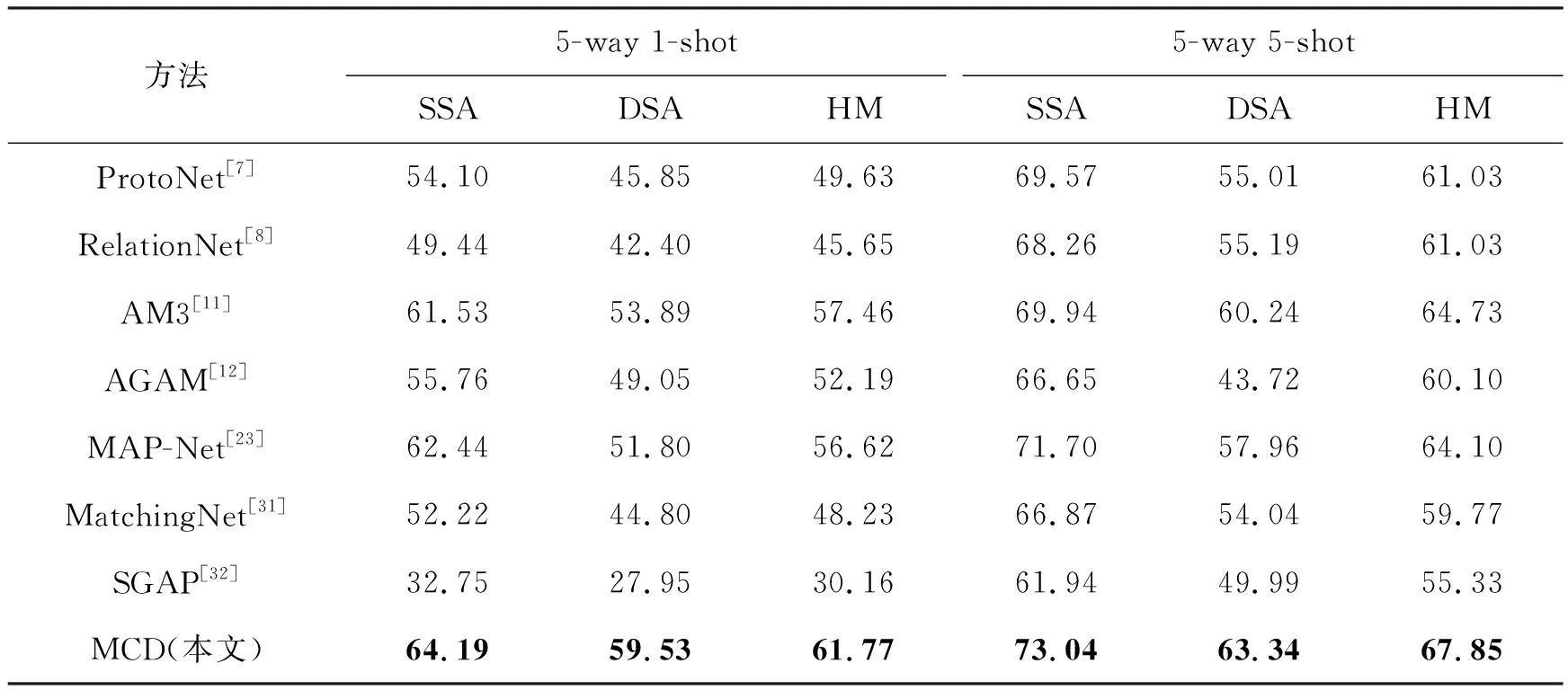
表2 在MIT-States数据集上的测试结果
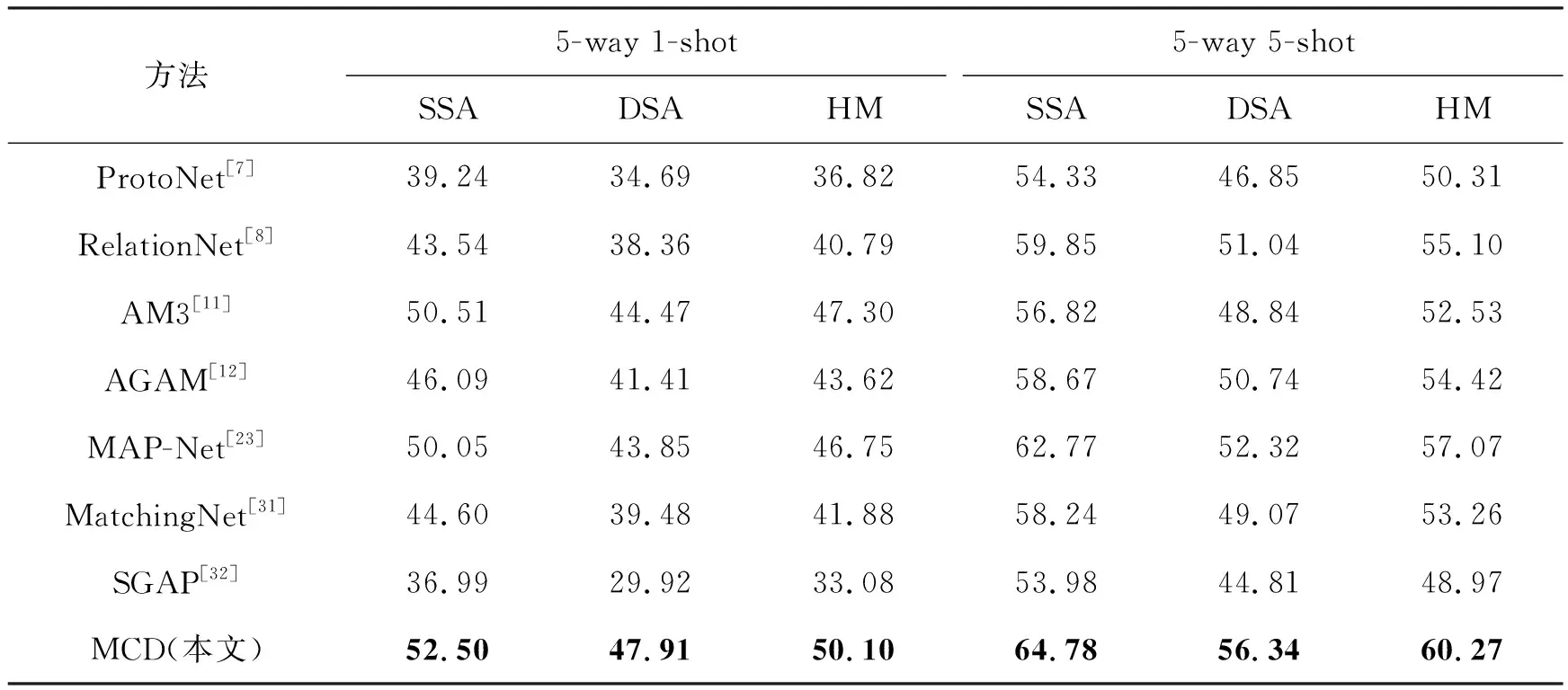
表3 在C-GQA数据集上的测试结果
具体地,在MIT-States数据集上,与结果第二高的比较方法AM3或MAP-Net相比,对于5-way 1-shot少样本分类任务,本文方法在SSA的结果上提升了1.75%,在DSA上的测试结果提高了5.64%,并且调和平均数HM也有了4.31%的提升效果;在5-way 5-shot任务中,本文方法在SSA上比方法MAP-Net提高了1.34%,在DSA上比方法AM3提高了3.10%,在HM上也有3.12%的提升效果。在C-GQA数据集上,针对5-way 1-shot的分类结果,本文方法比结果第二高的方法AM3均有明显的提高,在SSA上提高1.99%,在DSA上有3.44%的提升,并且在HM上也有2.80%的提升效果;而在5-way 5-shot任务中,本文方法仍比结果第二高的方法MAP-Net有较高的提升,其中在SSA上提升了2.01%,在DSA上提高了4.02%,在HM上也有3.20%的明显提升。
通过实验结果还可以发现,本文方法在DSA上较对比方法的提升效果明显比在SSA上显著,这说明对比方法难以很好地对具有未见属性的同类样本进行准确识别,本文方法在一定程度上有效地缓解了这一问题。同时,与5-way 5-shot提升结果相比,5-way 1-shot的分类任务中,DSA的提升效果在两个数据集上都更为明显。主要的原因在于当支持集样本极少时,模型更难学习样本的类别表示信息,并且当属性差异较大时,更容易因属性不同混淆本质的类别表征,加剧识别类别错误的情况。本文方法能够有效地解耦出无关的属性信息,保留样本本质的类别特征,提高样本极少情况下的分类性能。
2.3 消融实验
如前所述,本文方法通过交叉解耦和特征重建两个关键模块提升多元属性少样本分类性能。接下来,为了探究每个模块对实验结果的影响,在MIT-States和C-GQA数据集上进行消融实验研究,结果如表4和表5所示。采用原型网络作为基准即第一行结果,第二行为仅增加支持集类别语义特征(support category features, SCF),第三行的结果为在此基础上增加支持集属性语义特征(support attribute features, SAF)形成交叉解耦模块,第四行为继续增加特征重建模块形成本文最终方法。从表中结果可以发现交叉解耦与特征重建两个模块分别对少样本的分类性能起到促进作用。
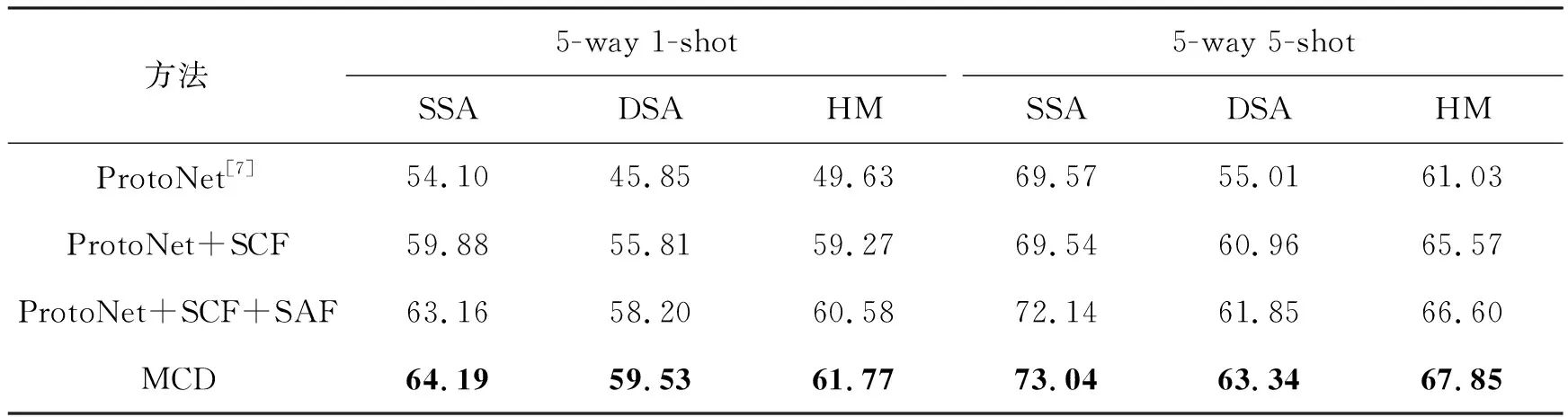
表4 在MIT-States数据集上的消融实验结果
具体地,当仅引入类别语义信息时,与基准原型网络方法相比,测试结果几乎都有显著的提升,这表明增加类别语义特征能够弥补模型学习视觉特征的不足,对模型学习准确分类起到了积极的指导作用。
当加入属性语义信息使用交叉融合模块时,可以发现交叉融合的方法在SSA、DSA和HM上的分类性能大部分都比仅加入类别语义特征SCF时有较明显的提升,其提升效果能达到0.84%~3.28%。特别地,当测试样本的属性特征与支持集样本相同时,SSA的结果反映出交叉解耦模型可以更好学习出解耦后的类别特征和属性特征,分离出正确的类别特征用以分类,有效地提高少样本任务分类的准确率,其性能能够达到0.84%~3.28%的提升。同时,即使在测试样本的属性特征与支持集样本不同时,模型也能学习出未见属性特征并解耦出类别特征。在此基础上当继续引入特征重建模块时,SSA、DSA和HM的性能均存在进一步的提升。通过结果可以发现,在解耦过程中,可能会出现解耦出来的特征偏离原样本真实特征的情况。因此,特征重建模块将解耦后的类别特征和属性特征重新融合,并利用原样本视觉特征进行约束,使模型学习特征信息时沿着样本类别内在特征的方向进行优化。
2.4 进一步分析
2.4.1 参数实验
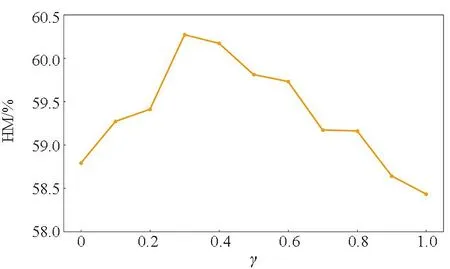
在此部分,研究超参数γ对模型性能的影响。不同γ值在MIT-States数据集和C-GQA数据集的结果如图4所示,其中图4(a)和图4(c)表示MIT-States数据集的结果,图4(b)和图4(d)表示C-GQA数据集的结果。蓝色和黄色折线分别代表5-way 1-shot和5-way 5-shot少样本分类任务,采用调和平均数HM作为判别指标。
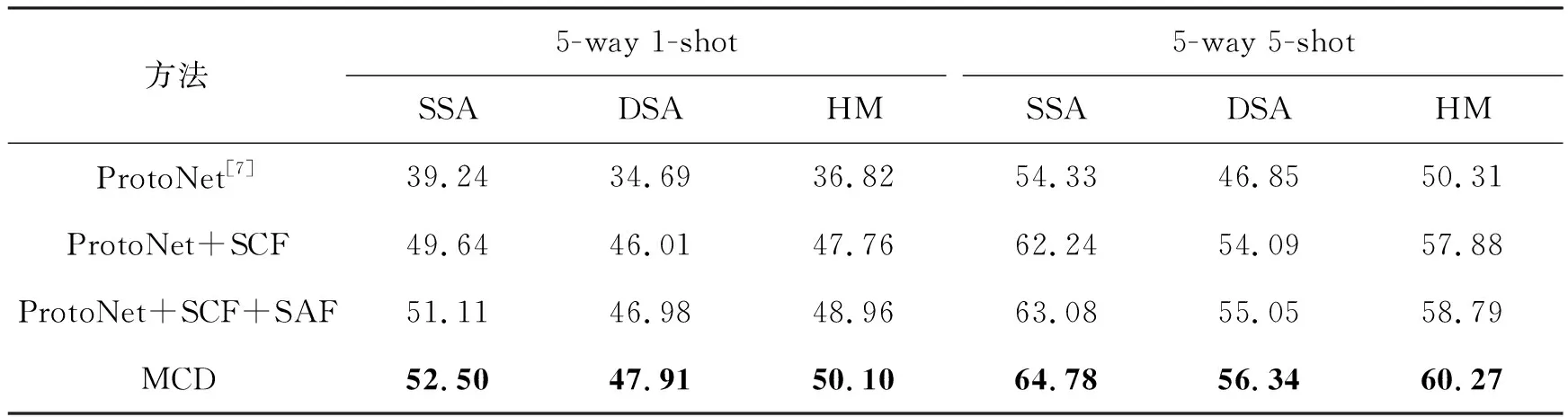
表5 在C-GQA数据集上的消融实验结果
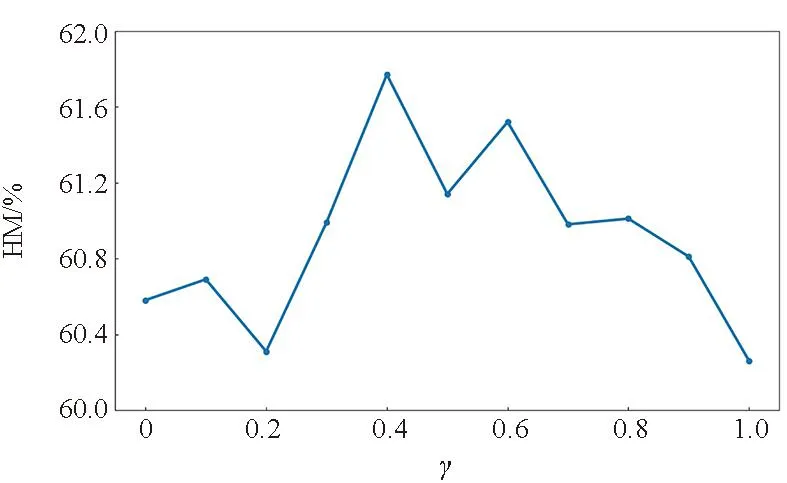
(a) MIT-States数据集在5-way 1-shot的结果(a) Results of 5-way 1-shot on the MIT-States dataset
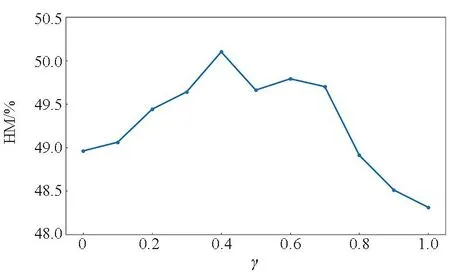
(b) C-GQA数据集在5-way 1-shot的结果(b) Results of 5-way 1-shot on the C-GQA dataset
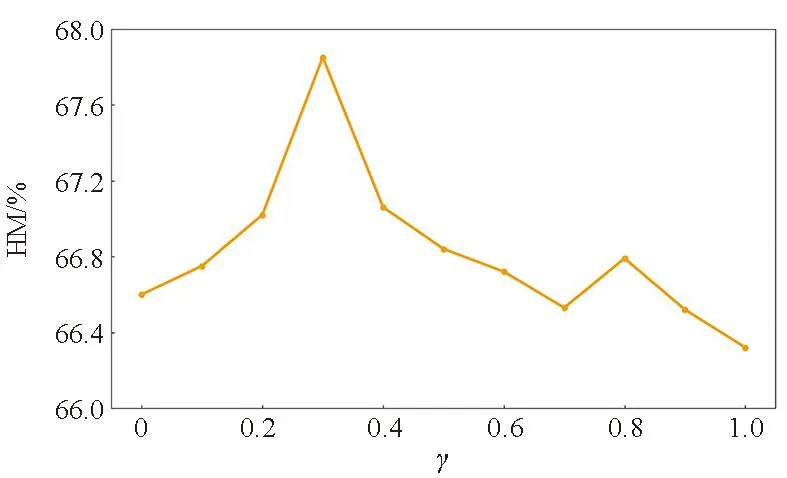
(c) MIT-States数据集在5-way 5-shot的结果(c) Results of 5-way 5-shot on the MIT-States dataset
(d) C-GQA数据集在5-way 5-shot的结果(d) Results of 5-way 5-shot on the C-GQA dataset
通过实验发现,两种数据集上的超参数γ均是先升后降。在5-way 1-shot分类任务中,当γ=0.4时,网络性能达到最优,HM的结果最佳;而在5-way 5-shot少样本任务中,当γ=0.3时,模型能达到最佳性能,此时HM的值为最高。这表明特征重建模块能够在一定程度上有效地提升分类性能,但是当参数γ的值过大时,分类性能反而会下降,其原因可能在于重建约束较强时会影响属性解耦的效果,加重了属性对类别特征的影响。
2.4.2 可视化实验
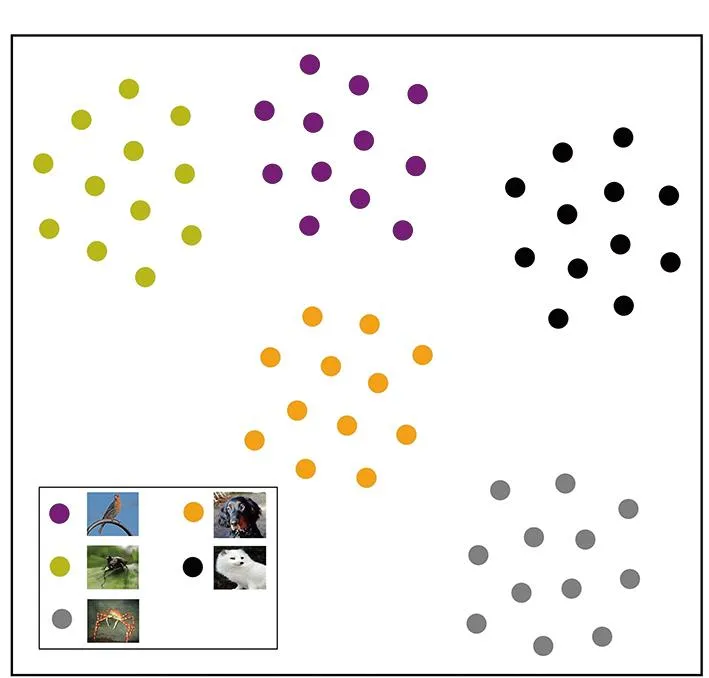
为了验证本文方法的效果,采用t-SNE[33]方法在MIT-States数据集的嵌入空间进行可视化实验,结果如图5所示。随机可视化一个测试任务,这个任务包含5个类别共60个样本,每个类别的样本数为12。不同颜色的圆点代表不同的类别。这里,选用原型网络(ProtoNet)作为基准方法进行比较,结果如图5(a)所示;为了验证本文方法的可行性,图5(b)为仅引入类别语义信息的方法结果,图5(c)为本文方法结果。
从t-SNE的可视化结果可以看出,增加类别语义信息,能够有效地提高类别辨识的能力,使测试样本按照预测类别整齐规则分布。本文方法进一步增强了同类别样本的分布密度,使类内样本分布更加紧凑,同时提高类别间的距离,可降低多元属性问题带来的识别误差。

(a) ProtoNet
(b) ProtoNet+SCF
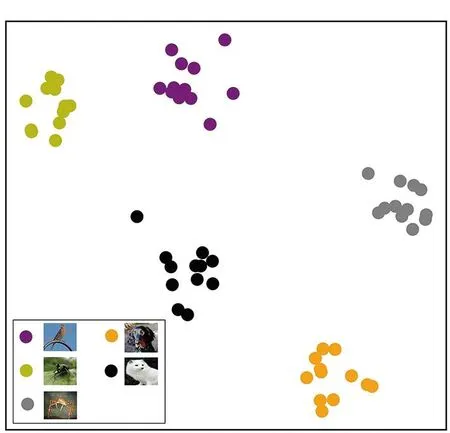
(c) MCD
3 结论
本文针对少样本学习中的多元属性问题,提出一种多模态交叉解耦的方法,可有效解耦出样本类别特征和类别属性语义特征,并能利用特征重建保留样本内在的类别特征信息,极大地缓解了多元属性问题对少样本分类造成的识别错误。所提方法也提出一种特征重建方法,将解耦后的类别特征和属性特征重新融合,通过原样本的视觉特征进行约束,使模型学习特征信息时沿着贴近样本本质类别的方向进行优化。在两个类内属性差异较大的标准数据集上的大量实验验证了所提方法的有效性和先进性,结果显示本文方法能够有效提升少样本分类任务的准确性,即使在属性未知的待测样本中也具有良好的分类性能。
