FCM 数据细胞亚群分类和标注的自动化研究
2024-04-08摆文丽农卫霞李智伟郭玉娟张向辉芮东升
摆文丽,农卫霞,李智伟,雷 伟,郭玉娟,张向辉,芮东升,王 奎
(1.石河子大学医学院预防医学系,新疆 石河子 832000;2.石河子大学医学院第一附属医院血液风湿科,新疆 石河子 832000;3.新疆维吾尔自治区人民医院临床检验中心,新疆 乌鲁木齐 830001)
流式细胞术(flow cytometry,FCM)是一种能够精确、快速地对生物细胞或微粒的理化特性和生物学特性进行定量分析的技术[1]。随着精准医疗和基因生物学的发展,FCM 已经成为恶性血液病诊断的重要依据[2]。FCM 数据在人工分析中最关键和最耗时的步骤是识别数据中的同质细胞群,这个过程为“设门”[3]。数据传统的分析方法是通过不同参数组合进行人工设门,随着检测参数成倍增加,产生了多组合、高维度的流式数据,而FCM 数据分析成为FCM 中最具挑战性和最耗时的诊断步骤[4-7]。自动设门是基于细胞群荧光强度分布的数学建模,可以使用有监督和无监督的方法来执行,用于解决人工设门所面临的问题。目前常见的自动化分析方法包括FlowMeans[8]、SPADE[9]、Citrus[10]、FlowSOM[11]以及PCA[12]等,其中最常用的是FlowMeans,其是一种无监督聚类方法,通过合并多个聚类以获得最终细胞亚群[13,14],但只能将FCM 数据中相似的细胞聚成亚群[15,16],不能实现亚群的标注,因此需要工作人员去一一识别,存在一定局限性。基于此,本研究旨在分析FlowSOM 与有监督分类模型[17](混合正态分布模型)联合应用于FCM 数据自动化分析中的效果,现报道如下。
1 资料与方法
1.1 数据来源 数据来源于实验室2021 年1 月-12 月同一面板急性白血病骨髓检测数据,共528例,包括412 例正常人、68 例AML、9 例T-ALL 以及39例B-AL。本研究经当地政府伦理委员会批准。
1.2 数据分析 FCM 数据细胞亚群的自动分类和自动标注可以分成4 个阶段进行:①预处理:通过读取数据、补偿和转换、去粘连完成FCM 数据预处理;②细胞聚类:使用FlowSOM 方法对预处理的数据进行细胞聚类,聚类的结果以宏细胞的方式可视化;③亚群分类:利用混合正态分布模型,训练有监督分类模型对细胞亚群进行分类;④亚群标准:对③得到的有限个数的细胞亚群类进行识别和标注建立多对多映射,完成细胞亚群的标注。
1.2.1 数据预处理 通过补偿、转换和去粘连完成FCM 数据的预处理。①首先应用补偿矩阵对数据进行补偿,补偿矩阵采用流式fcs 格式数据自带的补偿矩阵,通过读取荧光抗体名称与提取荧光通道的数据矩阵,对荧光抗体做补偿[5];②接着对FCM 数据做转换,对前向散射光FSC 进行线性变换(除以100 k),侧向散射光SSC 进行Log10对数转换,对抗体做双指数变换;③最后使用百分位法在FSC-A 和FSC-H 平面对数据做去粘连处理,具体步骤如下:首先选取FSC-H 大于0.5 且FSC-A 小于2 的细胞子集,计算其在全体细胞中的占比;当子集占比小于等于0.75 时,使用子集计算变量FSC-A 与FSC-H的百分位点P5和P75,否则计算P5和P90;以两个对子为端点做基准线段,将连线垂直上移和下移0.225单位做两条平行线;两条平行线之外的点即为粘连细胞;FSC-H 小于0.2 的点对应于细胞碎片,其余的为进入后续分析的细胞,包括正常细胞和凋亡细胞。上述切割点的选择用试错法确定。
1.2.2 细胞聚类 细胞聚类采用无监督分析方法,在操作中不需要任何标签,任何预定义的类作为引用。聚类算法识别同一聚类中的事件,将相似的细胞保留在同一个集群中,不同的细胞保留在不同的集群中。FlowSOM 具有节点网格,每个节点代表多维空间中的点[17]。自组织映射(the self-organizing map,SOM)将数据中的单元格分配给最近的节点,该节点以及周围的节点向新单元格更新,以此类推,节点被分配到数据空间中的高密度区域,节点网格中相近的节点比较远的节点更相似[18]。因此,所有的单元格将会分配到距离他们最近的节点,从而将FCM 数据中相同的细胞聚类在一起形成细胞亚群。为便于观察聚类结果,FlowSOM 聚类结果以亚群中心点展示,下文中把亚群中心点称为宏细胞。聚类的目标是将FCM 数据分为若干个类群,并保证类群内的样本尽可能密集,不同类群之间尽可能离散。FlowSOM将FCM 数据中相似的节点聚在一起形成无标签的细胞亚群,以宏细胞的形式展示。当比较5×5、10×10和15×15 网格时,发现节点数量越多对应的纯度越高,但是聚类结果很混乱;根据经验,前4 管使用12×12 网格,第5 管使用10×10 网格,因此前4 管的每管有144 个宏细胞,第5 管有100 个宏细胞。
1.2.3 亚群分类 聚类分析后得到细胞聚类结果,但由于FlowSOM 是无监督学习方法,不同抗体组合的样本得到的亚群构成不一致,导致亚群次序混乱缺乏统一标签,需要对细胞亚群进行分类[19]。把标本分为训练集和测试集,训练基于混合正态分布的有监督分类模型对所有的宏细胞进行分类,也就是对细胞亚群进行统一分类,混合正态分布模型的类别数设置为20。有监督的混合正态分布模型对FlowSOM生成的宏细胞结果进行分类。具体步骤如下:为了避免数据过少导致训练集分类结果代表性差,选择60%~70%的数据作为训练集,30%~40%作为验证集,因此从AML、T-ALL、B-ALL 数据中分别随机挑选41、9、39 例数据作为训练集;正常人数据有412例,如果随机选择60%的数据作为训练集,这样使得训练集中正常人数据远远多于患者数据,正常人细胞亚群特征覆盖异常细胞亚群,造成分类不准确,因此选择100 例正常数据作为训练集。训练集170 例数据,共97 920 个宏细胞;测试集358 例数据,共206 208 个宏细胞,为了使分类结果清晰明了,从两个数据中随机选取25 000 个宏细胞来显示。
1.2.4 亚群标注 为使细胞亚群分类更加精确,分类模型中亚群数目的设置通常高于常规使用的细胞类型数。因此在亚群标注过程中,通过提取细胞聚类信息以及各类细胞的细胞数,将宏细胞映射到9 个细胞类别并进行命名标注。
2 结果
2.1 粘连细胞的识别去除 以FSC-A 和FSC-H 为坐标绘制散点图,基准线上下移动0.225 个单位产生两条平行线将粘连细胞去除,见图1,经检查去粘连结果,发现粘连细胞划分均合理。

图1 预处理结果
2.2 聚类分析 各类细胞的宏细胞分布是有规律可循,服从特定的概率分布,见图2。
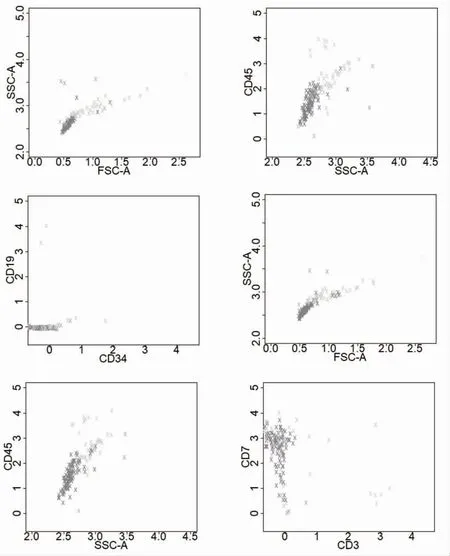
图2 FlowSOM 聚类结果
2.3 亚群分类与标注 共有20 个类别,且各类宏细胞位置合理,未见异常,见图3;另对20 个细胞类别进行一一识别和标注,得到9 种已知细胞类,分别是淋巴细胞、单核细胞、中性粒细胞、嗜酸粒细胞、原始细胞、幼稚细胞、有核红细胞、凋亡细胞、其他细胞,见图4。

图4 细胞亚群标注前后比较
3 讨论
由于FCM 具有高通量、高灵敏度、高精确度以及多参数检验的特点[20],被广泛的应用于生物学研究及临床诊断中[21-23],同时会产生高维度、多组合的FCM 数据。而传统人工分析具有分析效率低、主观性高的问题。近年来不断有学者提出FCM 数据的分析需要自动化分析方法的帮助[5,24]。
针对以上问题,本研究提出无监督聚类方法与有监督分类方法共同用于FCM 数据分析,模拟人工分析过程,获取临床流式实验室的原始检测数据,预处理过程通过补偿、转换、粘连细胞以及细胞碎片的去除,使得FCM 数据规范化,检查发现每例数据的粘连细胞去除均合理;之后将无监督聚类方法与有监督分类方法结合起来用于FCM 数据聚类、亚群分类与标注,显著优点是其既能够快速分类又能够提高分类数目的准确度。
无监督聚类方法FlowSOM 作为分析的起点,将FCM 数据中相似的细胞聚在一起形成无标签的细胞亚群,通过设定的参数,FlowSOM 将FCM 数据中相似的细胞聚在一起形成无标签的细胞亚群,以宏细胞的形式展示。从聚类结果看出,FlowSOM 具有良好的性能以及快速的运行时间,是对FCM 数据进行快速探索性分析的理想工具。但是将宏细胞进一步聚类时会出现不同细胞类型合并的现象,不能通过FlowSOM 模型的元聚类对亚群进一步聚类与特征提取。因此,使用有监督分类模型混合正态分布模型对FlowSOM 生成的宏细胞进行分类,有监督学习算法可以达到这样一种状态:在提供足够的信息数据前提下,它能够预测未见数据的正确标签;混合正态分布模型对亚群进行分类时,首先将数据集分为训练集和测试集,使用训练集训练有监督分类模型过程中,对亚群类别参数进行设定,发现随着亚群数的增加,分类精确度会提高,但是不利于对亚群进行标注;反之,亚群数减少,精确度降低,但是会出现将不同细胞亚群分到一起的现象。故根据经验,将细胞亚群设置为20 个,接下来使用测试集对模型进行测试,检查训练集与测试集的分类结果,未见异常,可以认为有监督分类模型能够准确地对训练集和测试集进行分类。最后通过设定标签的形式将20 个类别依次识别并用已知的细胞类别进行标注,即将宏细胞映射到9 个细胞类别,对这9 个细胞类别进行命名标注,检查所有数据标注前与标注后的可视化结果图,亚群标注结果清晰,未见异常。
总之,通过将基于本研究方法的亚群分类与标注结果与传统人工分析结果进行对比,成功验证了自动化分析方法在FCM 数据分类与标注中的可行性和高准确性,具有较好的应用前景,可以为下游FCM 数据自动化诊断提供参考,并且能够保留原始数据更多的特征信息,为下游诊断结果的质量控制提供依据。本研究也有不足之处:作为流式数据全程自动化分析的重要组成,而且分类结果较难用评价指标进行评价,因此利用分类结果进行特征提取和疾病诊断,诊断结果与专家人工分类结果基本相同,从而反推证明本研究提出的FCM 数据自动化分类方法可靠;自动化分析FCM 数据时假设流式实验室在样本准备、荧光染色、仪器校准和调整阶段均正常,在实际情况中,可能出现数据大幅度偏移,建立在分布规律基础上的亚群标注结果可能会出现偏差。目前,本研究提出的自动化分析方法已经在公共数据库Flowrepository.orgAML 项目提供的数据以及本地实验室急性白血病骨髓检测数据进行过测试,效果良好。
