拉曼光谱结合机器学习对植物油的分类鉴别
2024-04-03苏东斌秦嘉桧李开开
苏东斌,秦嘉桧,李开开*
1(中国人民公安大学 侦查学院,北京,100038)
2(中国人民公安大学 研究生院,北京,100038)
植物油是每日膳食摄入的必需成分,也是食品质量安全的重要监管对象。由于产量不同和营养价值不同,不同种类植物油的价格差异较大。因此针对植物油种类鉴别开展研究,不仅有利于在第一时间获取相关线索信息,可以在涉植物油的案件中为公安机关提供侦查方向,而且也有助于提升监督部门的植物油分析效率,具有重要意义及应用价值[1]。
气相色谱法[2-3]、液相色谱法[4-5]、质谱法[6-7]和核磁共振波谱法[8-9]常被用于测定植物油中的脂肪酸、甘油三酯等成分。然而这些方法普遍存在分析过程繁琐、耗费时间长、对样本具有破坏性的缺点。相比于以上分析方法,光谱分析法具有操作简单、检测速度快、样品用量少等优点,被广泛应用于食品的检测分析。目前采用紫外可见光谱法[10-11]、拉曼光谱法[12-13]、红外光谱法[14]等对植物油的分析检验已有报道。由于植物油的光谱具有极高相似性,仅通过目测光谱很难将其区分。机器学习方法与光谱分析的结合可以使油脂的分类识别率得到很大提升。VARGAS等[15]使用拉曼光谱仪对19种植物油和9种精油进行了检测,并通过线性判别分析达到了100%的分类准确率。黄平捷等[16]在研究饮用水的有机污染物时,引入连续投影法(successive projections algorithm,SPA)处理紫外-可见光光谱。结果表明SPA可以有效地对有机污染物的紫外-可见光光谱进行特征提取。聂黎行等[17]在剔除异常样本后,应用竞争性自适应重加权法(competitive adaptive reweighted sampling,CARS)筛选相关变量,建立了偏最小二乘法(partial least squares,PLS)校正模型,为光谱的重叠问题提供了解决思路。
本文采用拉曼光谱结合机器学习对食用植物油进行分类识别。采用拉曼光谱技术,获取六类常见的植物油光谱数据,分别采用SPA和CARS提取各样本的光谱数据特征,使用正交偏最小二乘判别法(orthogonal partial least squares-linear discriminant analysis,OPLS-DA)和基于网格搜索和交叉验证的支持向量机(support vector machine,SVM)对食用植物油种类以及品牌进行分类识别。
1 材料与方法
1.1 实验材料
共从市场上收集了六类(包括38个品牌)的植物油样本,其品牌、编号等详细信息如表1所示。

表1 植物油信息
1.2 仪器及工作条件
共聚焦显微拉曼成像光谱仪,德国WITec科学仪器公司。主要由半导体激光器单元、光谱仪、拉曼光学探头、激发光纤、采集光纤、计算机、样品池和数据处理系统组成。其基本参数如表2所示。

表2 仪器参数信息
1.3 研究方法
基于拉曼光谱的食用植物油快速鉴别方法具体流程如图1所示。主要包括:拉曼光谱获取、光谱数据预处理、特征波长优选与类别判断等步骤。

图1 光谱数据处理
1.3.1 光谱数据预处理
在实际测量过程中,光谱采集易受到放置环境及仪器状态的影响。在分析光谱数据前使用光谱校正方法消除该因素引起的光谱变异是十分必要的。Savitzky-Golay算法和多元散射校正(multiplicative scatter correction,MSC)是多波段建模常用的数据处理方法,能够在一定程度上消除光谱数据产生的基线漂移问题[18-19]。
1.3.2 拉曼光谱特征波长优选
利用特征优选算法对原始数据进行优选,可以选取少量的特征波长进行分析,能够从严重重叠的光谱信息中提取有效信息提高模型运行效率。连续投影法是将各波长特征向量投影到其他特征波长上,以投影向量最大的波长作为待选的特征波长,然后根据迭代特征向量与待选变量个数回归模型的均方根误差(root mean squared error,RMSE)来确定候选特征数量[18]。它可以从严重重叠的光谱信息中提取有效信息,提高建模效率。竞争性自适应重加权采样法是一种结合蒙特卡洛采样与PLS模型回归系数的特征变量选择方法。蒙特卡洛采样法每次随机从校正集中选择一定数量的样本进行建模,剩余的样本作为预测集。然后利用指数衰减函数去除回归系数绝对值权重较小的波长[17]。在每次采样时都会计算所选变量的交互验证均方根误差(root mean square error of cross validation,RMSECV),利用交互验证选出RMSECV值最低的子集可有效寻出最优变量组合。
1.3.3 植物油的分类研究
PLS能够将回归结果转换为一组可用于预测因变量的中间线性潜在变量,具有降低噪音、特征提取、参数结构简单及稳定性优良等优点。OPLS-DA是PLS的扩展,利用正交信号校正的思想增强了PLS-DA的可解释性,常用来处理分类和判别问题。支持向量机是利用区间最大化的原理寻找一个超平面分割样本,最后将分类问题转换为凸二次规划问题来解决[19]。网格搜索(Grid Search)是一种穷举方法的参数调优手段,可以保证所得的搜索解是划定网格中的全局最优解,避免出现重大误差。
为让被评估的模型更加准确可信,本研究在网格搜索中应用K-fold交叉验证法对每组参数的性能进行综合评价。基于Python选择线性核(linear kernel)、多项式核(polynomial kernel)以及径向基函数核(radial basis function kernel,RBF),采用十折交叉验证法进行参数寻优。分别建立SVM分类模型对植物油的种类和品牌进行分类。参数网格范围设定见表3。

表3 不同核函数的参数设定范围
2 结果与分析
2.1 光谱预处理结果
植物油的原始光谱以及经过Savitzky-Golay平滑、MSC、Savitzky-Golay+MSC预处理后的光谱如图2所示。对原始光谱进行平滑、MSC不仅能够增强光谱的吸收特性,还可以减少光谱曲线的离散性。
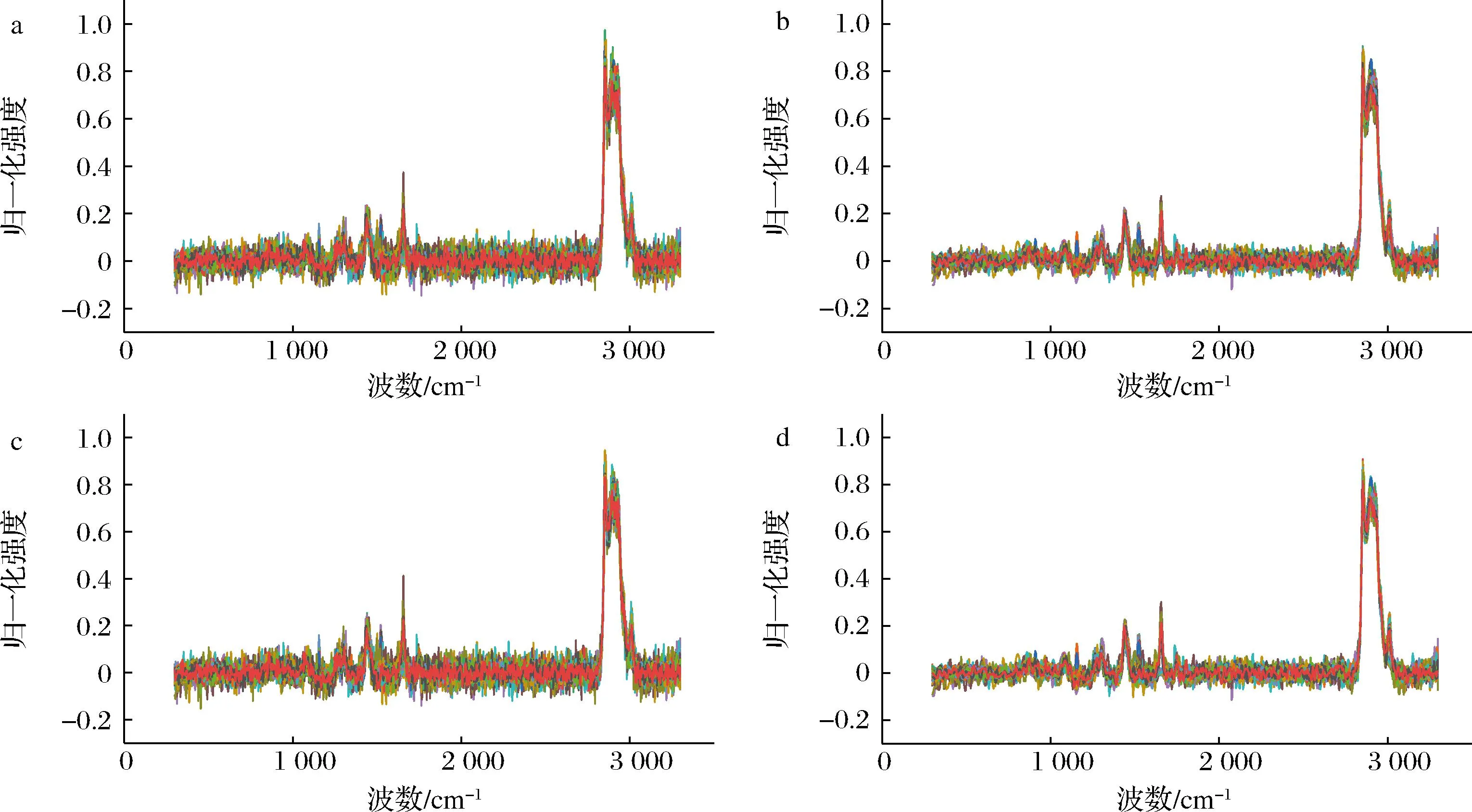
a-原始光谱;b-Savitzky-Golay平滑;c-多元散射校正;d-Savitzky-Golay平滑+多元散射校正
2.2 拉曼光谱特征波长优选
2.2.1 SPA特征波长优选结果
在298~3 300 cm-1的拉曼位移范围内,每一个光谱样本共采集779个数据点。随着迭代次数的增加,SPA模型中所包含的特征变量数量逐渐增加。RMSE随变量个数变化以及光谱特征提取结果如图3所示。最终通过SPA模型的建立与提取,所得到的特征波长共计249个。
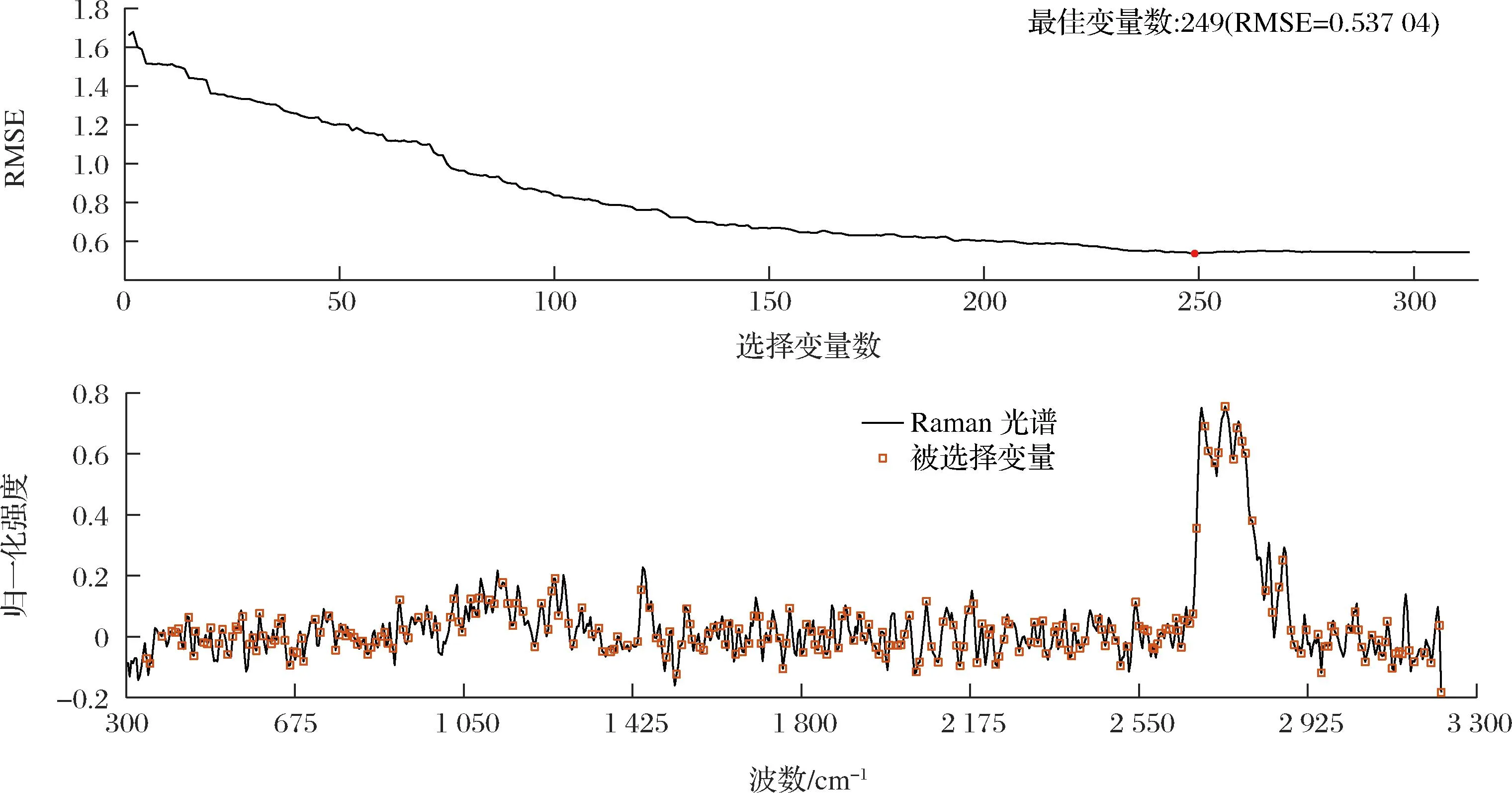
图3 SPA光谱变量筛选
2.2.2 CARS特征波长优选结果
利用CARS算法采用十折交叉验证,最大迭代次数为50次。光谱特征波长优选过程如图4所示。由图4可知,被选择的特征波长数量随着迭代数量次数的增加而减少。在迭代次数为13时,RMSECV值达到最小,所得到的特征波长共计146个。
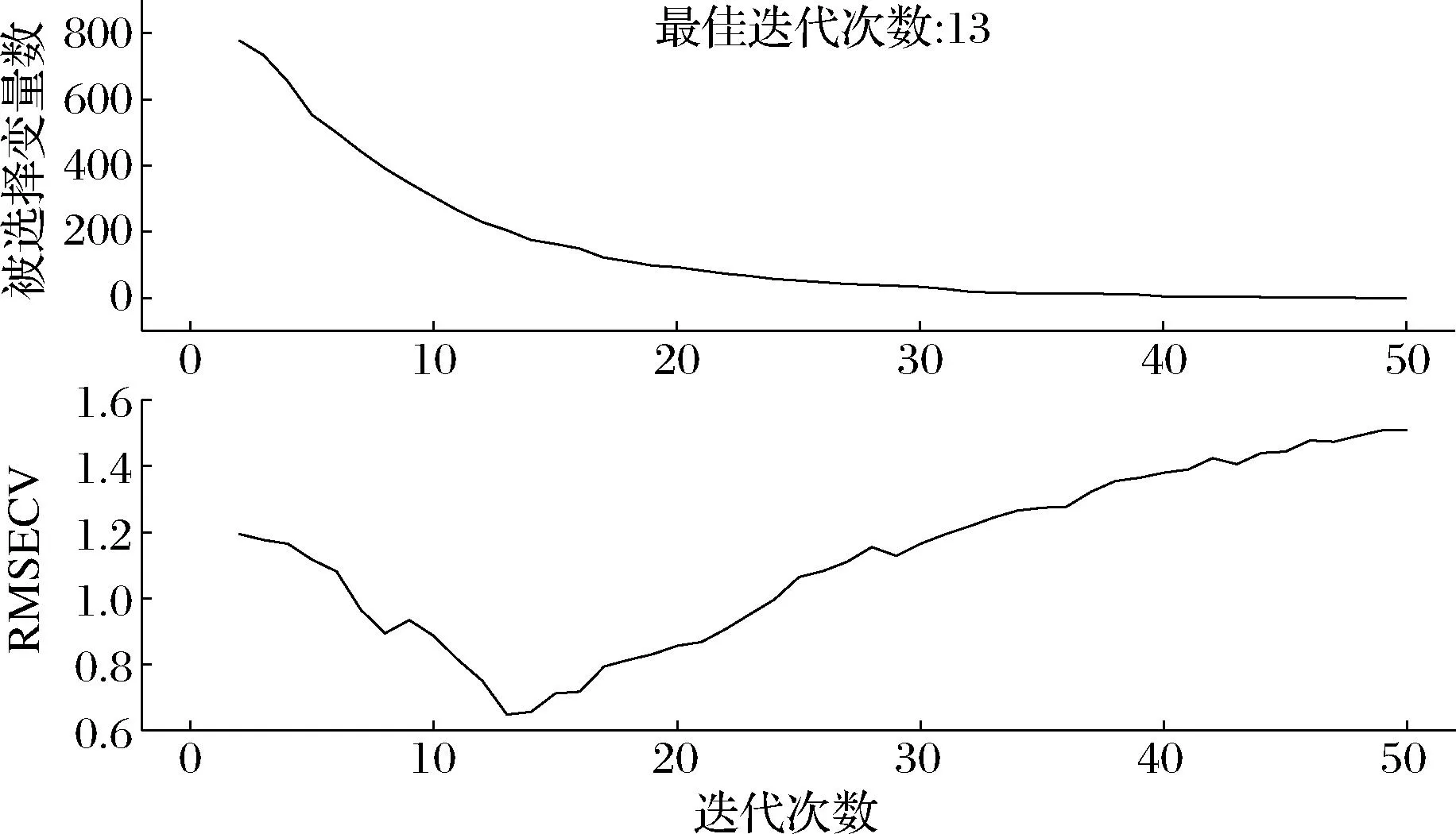
图4 CARS光谱变量筛选
2.3 植物油OPLS-DA分析
2.3.1 样本异常值排除
使用Kennard-Stone方法将光谱数据集中70%样本划分为训练集(385个光谱),其余为验证集(166个光谱)。图5和图6分别表示以经过SPA和CARS特征波长优选后的训练集数据的二维OPLS-DA得分图、DModX(distance to the model X)检验图、Hotelling′sT2检验图和置换检验结果图。
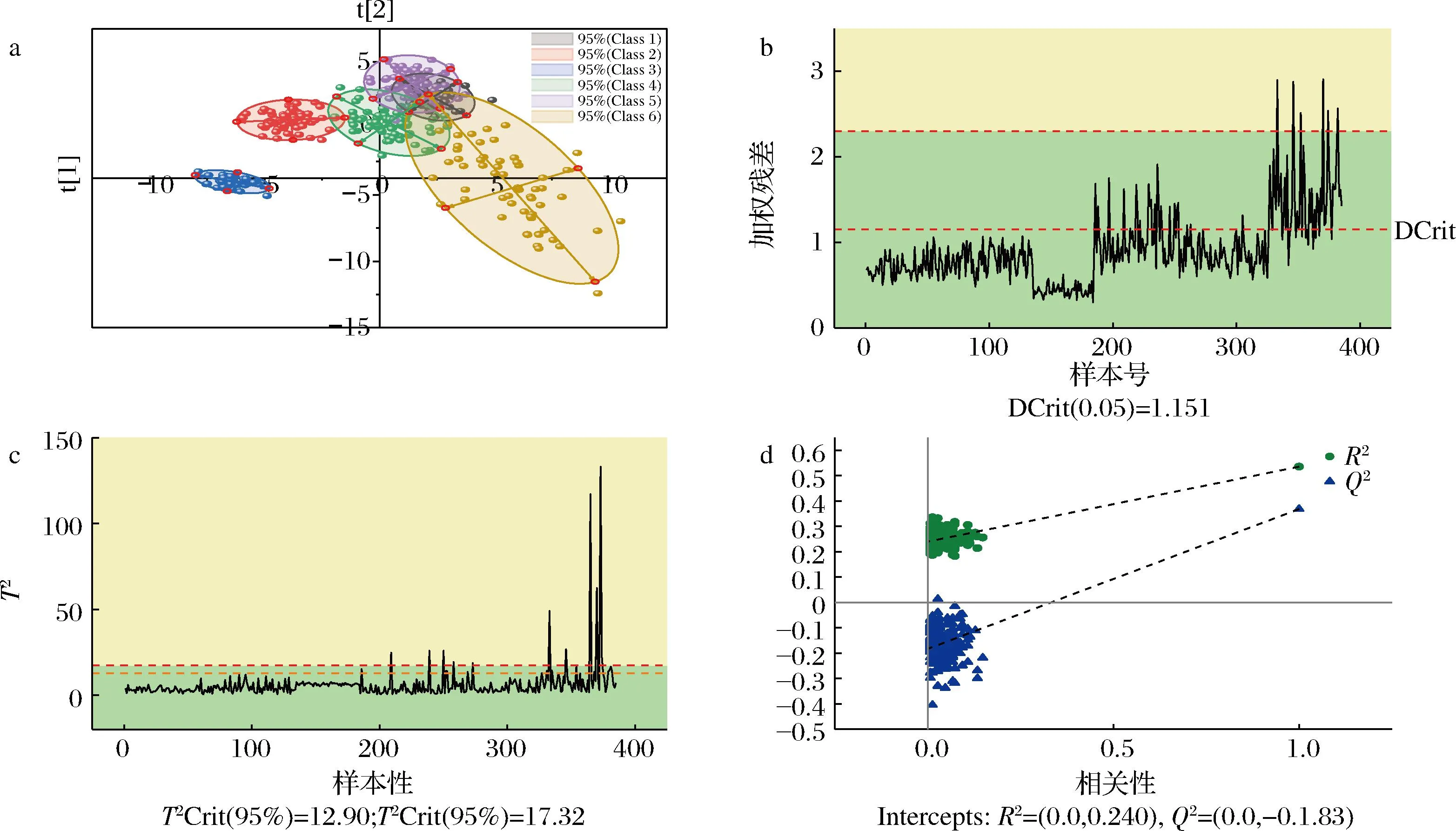
a-偏最小二乘判别分析得分图;b-DModX检验结果;c-Hotelling′s T2检验结果;d-置换检验结果
对于已知真实分类的数据集,得分图可以显示训练集样本中可能存在的异常值。根据变量分数,通过HotellingT2检验绘制95%置信椭圆,通常认为距离椭圆较远的样本观测值可能是异常值。而DModX统计量指的是给定样本观测值与模型平面的距离,同样可以反映样本偏离模型的程度。Dcrit值是由F分布计算的DModX临界值。当样本DModX值为Dcrit两倍时可认定其属于中等异常值。将HotellingT2与DModX两种统计量相互结合、综合分析,训练集中被排除于建模外的样本汇总于表4。

表4 建模时被排除的样本
2.3.2 置换检验
置换检验是将样本观测值的顺序随机排列,而变量矩阵顺序保持不变,可以用于评估当前模型是否过拟合。置换检验的结果分别如图5-d、图6-d所示。横坐标表示置换模型中观测值与原始模型观测值的相关性,横坐标最大值为原始模型与其自身相关性。将原始模型的拟合度(由R2和Q2表示)与数据置换后模型的拟合度进行比较,原始OPLS-DA模型的R2和Q2值(最右侧)均大于置换模型中所有R2和Q2值,同时Q2点回归线的纵截距低于零点。这表明原始模型没有过度拟合,对新样本具有较好的预测能力。

a-偏最小二乘判别分析得分图;b-DModX检验结果;c-Hotelling′s T2检验结果;d-置换检验结果
2.3.3 OPLS-DA分析结果
根据原始波长数据以及提取波长分别建立OPLS-DA模型,测试集样本的分类识别结果如图7所示。
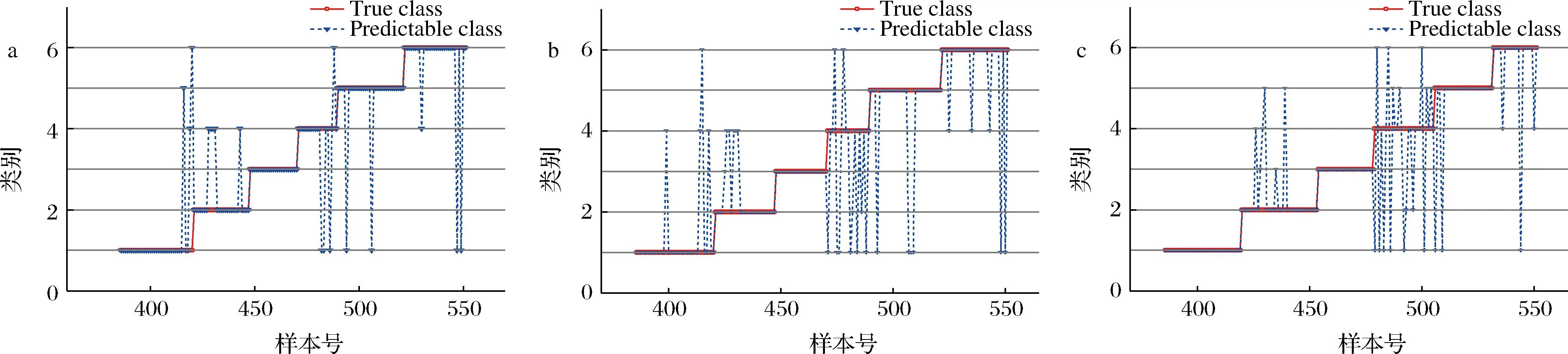
a-OPLS-DA分类结果;b-SPA-OPLS-DA分类结果;c-CARS-OPLS-DA分类结果
由图7可知,根据原始光谱数据建立的OPLS-DA模型对各样本预测识别总体准确率为89.76%。模型对椰子油的种类预测正确率达到100%;对花生油的种类预测错误最多,正确率为78.95%。相比于原始光谱数据建立的OPLS-DA模型,基于SPA和CARS改进OPLS-DA对各样本预测识别的总体准确率稍有下降,分别为82.53%、83.13%。
特征波长优选算法的优势在于减少建立分类模型所需的变量数目,通过使用少量变量使得建立模型所需计算资源极大降低。对于二分类问题或者类别较少的多分类问题,特征波长优选导致的部分信息丢失对模型预测能力的影响小于变量间共线性的影响,最终使得模型预测能力得到提升。然而本研究结果显示波长优选导致模型预测正确率有所下降。选取少量光谱波长代替全光谱,不可避免地会导致信息丢失。对于类别较多的多分类问题,特别是样本类别区分度较低的多分类问题,信息丢失对于预测结果影响较大。因而基于SPA和CARS改进OPLS-DA模型的预测正确率均低于全光谱模型。
2.4 基于网格搜索和交叉验证的SVM模型
表5为各方法模型的参数寻优结果。线性核是最简单的核函数,具有参数少、操作简单、计算方便的优势,但只能用于解决线性可分问题,在相似样本的多分类问题中表现不佳。而径向基函数核在三类模型中均有良好表现。

表5 模型的参数寻优结果
根据三类模型的最佳参数组合,以70%数据集作为训练集,30%数据集作为测试集分别建立SVM模型。SPA+SVM、CARS+SVM以及全光谱SVM模型的测试集预测结果如图8所示。三类模型的测试集正确率均为100%,运算时间分别为9.699、9.001、14.481 s。根据CARS建立的植物油类别模型的预测能力与根据SPA算法所建立的模型没有明显差异。运算时间与模型所包含变量数量相关,全光谱SVM模型包含变量数最多,因而其所需运算时间也最长。
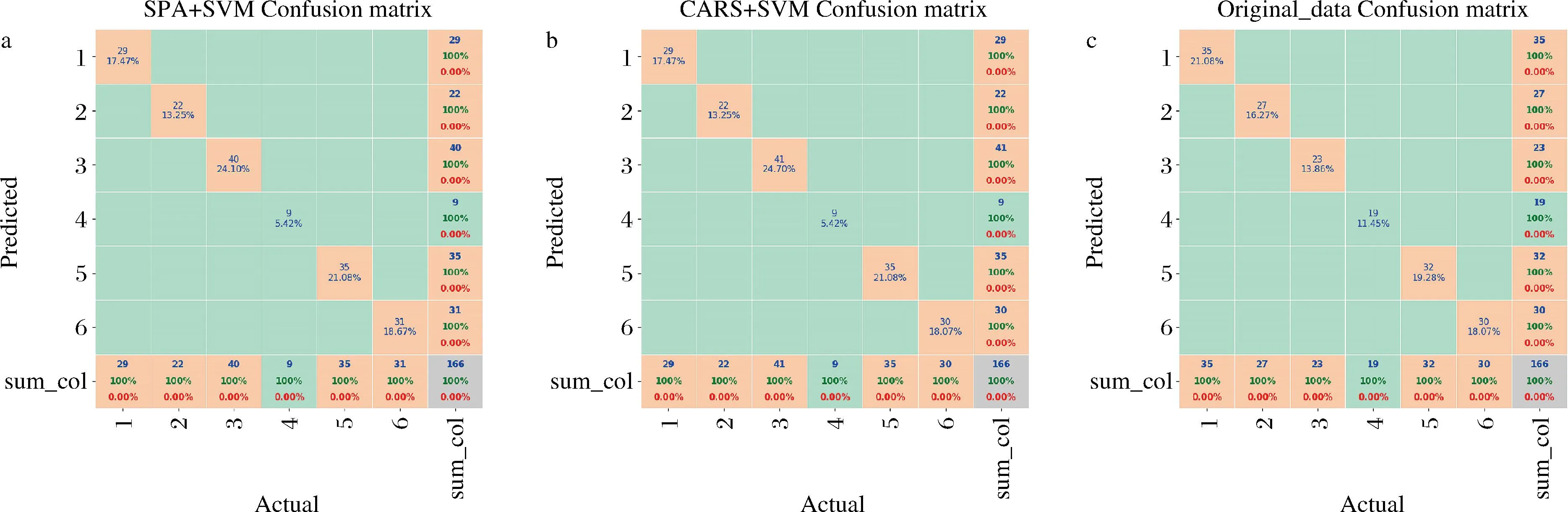
a-SPA+SVM预测结果;b-CARS+SVM预测结果;c-全光谱SVM预测结果
2.5 同种类植物油的品牌分类
在植物油种类预测中,CARS+SVM达到100%的测试集正确率且所需运算时间最短。因此在原有光谱预处理的基础上利用CARS-SVM模型对同一类别的植物油进行品牌分类。按照7∶3的比例采用五折交叉验证法进行训练和验证,最终得到植物油同一类别中不同品牌样本预测正确率如图9所示。不同种类植物油的SVM模型的参数寻优结果如表6所示。
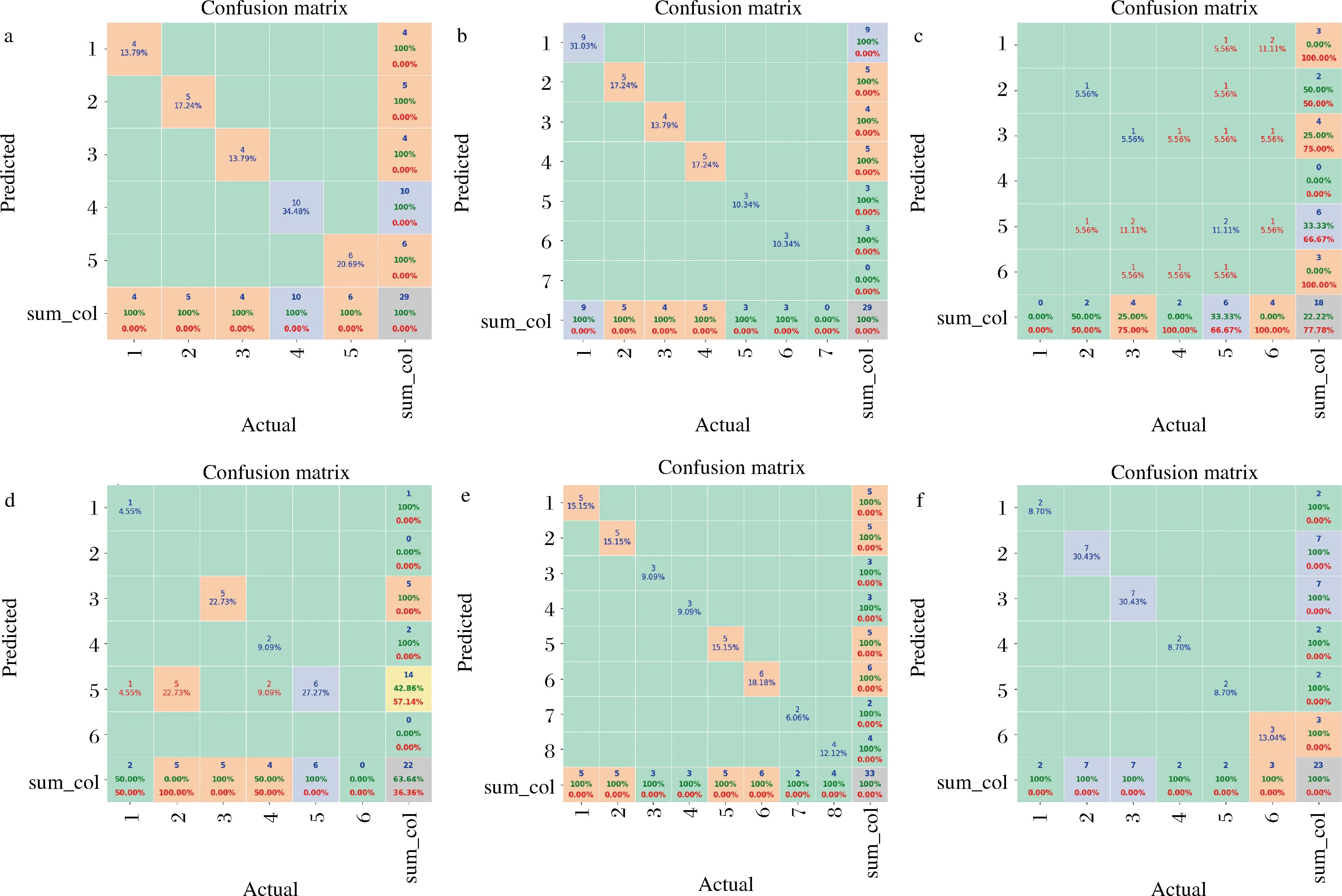
a-玉米油预测结果;b-橄榄油预测结果;c-椰子油预测结果;d-花生油预测结果;e-葵花籽油预测结果;f-芝麻油预测结果
CARS-SVM模型对玉米油、橄榄油、葵花籽油和芝麻油的品牌分类识别的效果最佳,测试集正确率均达到100%;对椰子油和花生油品牌分类识别的准确率较差,测试集正确率分别为22.22%、63.64%。不同种类植物油的正确率差异可能与植物油原材料相关。本研究所使用的椰子油,除品牌5(椰来香SUPERCOCO)外,其余椰子油产地均为海南省,所用原料也全部产于海南省。不同产品所使用的制作工艺和原材料的高相似度使得SVM模型无法很好地将椰子油按照产品品牌分类。
3 结论与讨论
采集多个植物油的拉曼光谱数据,采用连续投影算法和竞争性自适应重加权算法分别优选光谱波段,建立了OPLS-DA和SVM分类模型并与全光谱数据所建立模型进行对比。SPA-OPLS-DA和CARS-OPLS-DA的测试集总体正确率分别为82.53%、83.13%均低于全光谱数据建立的OPLS-DA模型。SPA-SVM和CARS-SVM的测试集正确率均可达到100%。CARS-SVM模型对玉米油、橄榄油、葵花籽油和芝麻油的品牌分类识别的效果最佳,对椰子油和花生油品牌分类识别的准确率较差。
a)在植物油种类识别中,SPA和CARS都可以作为特征提取的处理方式,对模型测试集正确率无显著差异。特征波长优选算法可以极大减少建立分类模型所需的变量数目,减少光谱变量之间的共线性影响,使得建立模型所需计算资源极大降低。但同时通过算法选取特征波长,以少量光谱数据代替全光谱数据,不可避免地会导致部分信息丢失,可能会导致模型识别正确率下降。
b)在解决样本类别区分度较低的多分类问题时,支持向量机优于正交偏最小二乘判别模型。SVM以引入核函数的方法可以更好地解决线性不可分问题。CARS-SVM模型对植物油分类识别效率高,为植物油的无损快速检验提供一定的参考与借鉴。在依据品牌对各种类植物油进行分类时,玉米油、橄榄油、葵花籽油和芝麻油的品牌分类识别的效果最好,椰子油和花生油的分类正确率较低。原因可能与生产商的生产工艺以及原料来源相关。对于进一步研究,深入调查各生产商的原料来源以及生产工艺的必不可少的。
