轻量级空间移位MLP 用于指静脉分割
2024-04-02曾军英田慧明陈宇聪顾亚谨邓森耀尹永宏尤吴杭黄国林甘俊英秦传波
曾军英,田慧明,陈宇聪,顾亚谨,邓森耀,尹永宏,尤吴杭,黄国林,甘俊英,秦传波
(五邑大学智能制造学部,广东江门 529020)
0 引 言
近年来,手指静脉识别作为流行的第二代生物特征识别工具,相较于其他生物识别技术具有安全性高、准确率高、唯一性、非接触式采集、不易伪造和低成本等特点,因此受到越来越多的学者关注。在手指静脉的提取和识别应用中,图像分割是其中一项主要任务,直接影响到识别的准确率。但是这些主流网络模型[1-4]的主要工作都集中在开发高效和鲁棒性的分割方法上,对指静脉提取的实时性分割工作很难达到理想效果。此外,这些方法需要消耗大量的计算资源和存储空间,在嵌入式终端上很难达到运行的条件。相对于占用大量计算和内存资源、对设备要求较高的CNN 架构,以及需要大量数据进行训练、建立全局依赖的Transformer 架构[5-8],设计一种计算开销较小、参数数量较少、推理时间更快的分割网络模型,并保持其良好的分割性能是非常重要的。此外,探索局部性对模型体系结构的影响也同样具有重要意义。对于上述问题,本文提出了一种基于MLP的轻量级手指静脉分割网络模型——S-MLP。该网络模型采用带有编码器、解码器和跳跃连接的U 型5 层深度网络结构。同时,在每一个解码器和编码器中引用了一种新颖的标记化MLP,这种标记化MLP 能够将卷积特征映射到抽象的标记空间中,从而降低了计算量,并利用MLP 学习有意义的特征图信息以进行分割。使用逐深度卷积进一步减少网络模型参数,同时还能捕捉到重要的图像特征。为了将局部性引入所提出的方法中,该算法在特征图中采用窗口划分的方式,并在每个窗口中执行标记混合投影,以对特征像素点及其周围特征像素点之间的关系进行建模。在MLP 中引入了移位操作,通过水平和垂直两个方向空间移动,将来自不同位置的特征进行聚合,以提取对应轴向移位的局部信息,从而引入了局部性。由于标记化特征的维度较少,且MLP 相对于卷积和Transformer 更为简单,考虑到减小模型大小可能会影响分割性能,因此该算法在每个层后面添加一个参数量极少的注意力模块Triplet Attention[9],它可以使模型的注意力集中在指静脉纹路上,抑制网络模型提取无关信息。
1 方 法
1.1 网络结构
S-MLP 整体结构如图1 中的A 部分所示,由沙漏状的深度可分离卷积为基础模块组成编码器、解码器和跳跃连接的U 型结构。图1 中的B 部分显示了结构的处理过程:首先,通过3×3 逐层卷积提取深度方向特征,从而得到具有较强表达性的特征图;接下来,利用沙漏状的双层1×1 的点卷积层将特征维度先压缩再扩展,从而在提取到充足的通道特征信息的前提下减少卷积带来的巨大开销;最后,通过一层3×3 的逐层卷积来补充在点卷积过程中丢失的空间特征信息。在沙漏状深度可分离卷积中间使用由文献[10]提出的标记MLP 模块。

图1 S-MLP 总体网络结构
1.2 Shifted MLP
Shifted MLP 利用通道投影、垂直偏移和水平偏移来提高局部信息的提取能力。通过对特征图的维度进行轴向移动,可以获得来自不同维度的信息流,从而捕获局部依赖关系。特征图轴向移动方法具体步骤为:
1)通道投影将特征映射为线性层;
2)分别在水平和垂直上进行空间移动特征,将不同位置的特征转移至同一位置。
当特征重组时,将不同空间位置的信息组合在一起,从而获取更多的局部特征以提高性能。在移动中引入基于窗口的注意,以向全局模型添加更多的局域性,使得MLP 更加关注特征的局部细节。
1.3 标记MLP
如图1 中的C 部分所示,标记MLP 包括两个移位操作层、一个GeLU 层、一个特征编码层、一个归一化层(LayerNorm, LN)和一个重投影层。值得注意的是,该算法使用GeLU[11]和LN 来代替常用的ReLU 激活函数和BN 层,这两种在Transformer 中被广泛使用,GeLU 相较于ReLU 激活函数性能表现更好,LN 沿着特征向量序列进行规范化。
特征图经过平移操作后,在标记化MLP 模块中,首先将特征通过嵌入投影操作转换成特征向量并将它们映射编码成“标记”信息;接着,采用3×3 的卷积核对这些标记进行卷积操作,然后,将这些“标记”跨越宽度传递给一个移位的MLP;接下来,这些特征“标记”通过深度可分离卷积层(DW-Conv)进行处理,重复上述操作,将“标记”再次跨越高度传递给一个移位的MLP;最后,将这些特征“标记”再次传递给深度可分离卷积进行层处理,使用残差连接并将原始标记作为残差添加到输出的移位特征中,补充特征信息,应用层归一化(LN)并将输出特征传递给下一个模块。
标记MLP 块中特征图的计算可以总结为:
式中:X表示输入特征图;T表示标记化;W 表示宽度;H 表示高度;DWConv 表示逐深度卷积;LN 表示归一化层。
1.4 轻量型注意力模块Triplet Attention
SE[12]和CBAM[13]注意力模块在CNN 模块中被证实是有效的。但是,它们引入的额外参数量不能被忽视。Triplet Attention 模块可以在不涉及任何降维的情况下对注意力进行建模,并且用一种参数极小的注意力机制来模拟通道和空间注意力。如图1 中的D 部分所示,在前两个分支中,旋转操作对输入的张量X分别沿高度(H)和宽度(W)两个轴逆时针旋转90°。然后通过映射变换操作,由标准卷积层和批归一化层生成形状为1 ×H×C和1 ×C×W的中间输出张量,这些中间输出将被用于计算通道和高度(宽度)的跨维度交互。再经过顺时针90°旋转,恢复特征向量。对于第三个分支,与前面不同的是输入张量X的通道通过Z-pool 输出。最终,通过简单平均将三个分支的输出张量汇总。
2 实验与结果分析
2.1 评估数据集
本次实验采用了三个数据集。其中,山东大学MLA 实验室创建的SDU-FV 数据集共采集了106 个人的左右手食指、中指和无名指的指静脉图像,每个手指采集6 张图片,共计636 类、3 816 张图片,大小为320×240。香港理工大学指静脉数据集HKPU包含来自156个人的3 132 张手指图像,分别采集了每个人的食指和中指,大小为513×256。
UTFVP 数据集是由荷兰特文特大学创建,共包含60 个人的两张左右手食指、中指、无名指图像,数据集包含1 440 张PNG 格式图像,大小为672×380。
2.2 实验设置
本文将各个数据集随机选取80%作为训练集,剩余20%作为测试集。本文PC 端实验环境配置为NVIDIA RTX A4000 显卡,对NVIDIA 嵌入式终端JETSON NANO、JETSON TX2、JETSON XAVIAR NXJETSON 进行了相关实验,验证了提出算法的结构和思想,以及在终端上实现的可行性。
2.3 消融实验
为了研究每个模块的具体作用,本文方法在SDUFV数据集中设置了如下实验:
1)不使用任何模块;
2)仅使用位置嵌入操作(PE);
3)添加标记MLP 模块;
4)添加只对水平转移的操作;
5)添加先对垂直进行转移操作,再对水平进行转移操作;
6)最终的S-MLP 模型。
消融实验结果如表1 所示,通过表中数据可以得出结论:S-MLP 模型的高效性受益于每个模块的贡献,在使用了标记MLP 后,Params 仅增加了6.177K,但是Flops 和Mult-Adds 分别减少了0.51G 和3M,Dice 提高4.1%、AUC 提高了0.15%、Acc 提高了0.08%。
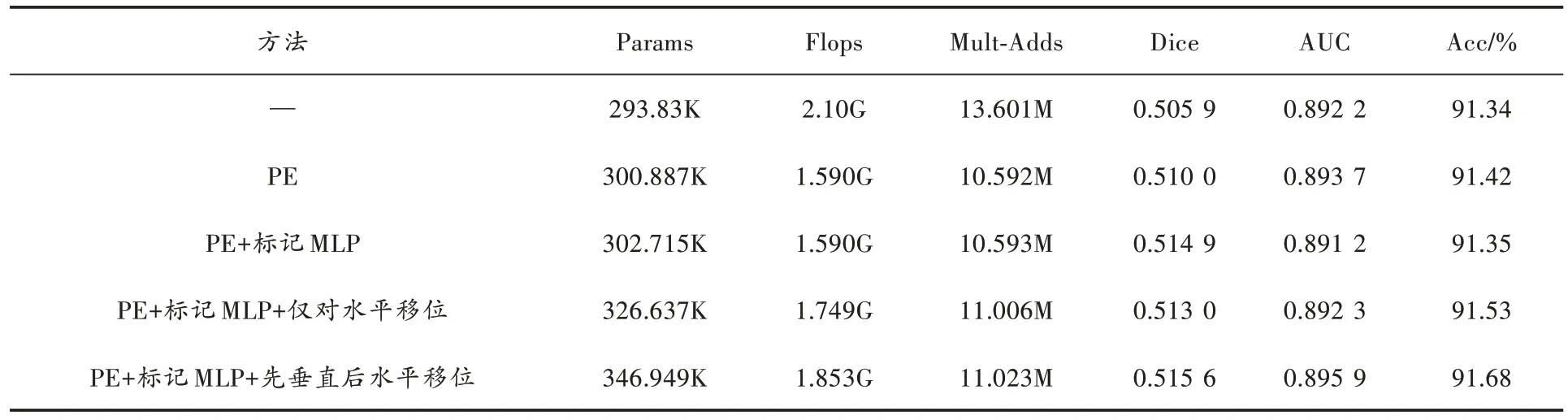
表1 各模块消融后评价指标对比
2.4 与其他网络模型实验对比
观察表2 与表3 的实验数据可以发现,与所有的卷积结构和Transformer 结构模型相比,S-MLP 模型取得了更好的分割性能。S-MLP 模型的Params 仅有346.949K、Flops 仅有1.853G、Mult-Adds 仅有11.023M,相较于参数大小为31.042M 的UNet,Params 仅有其1.09%,Flops 和Mult-Adds 分别占其0.42%和0.31%。在模型参数大幅下降的情况下,S-MLP 模型Dice 指标达到了0.515 6,比UNet 提高了4.19%,AUC 提升了1.49%,Acc 提升了0.21%。与经典分割网络模型DenseUNet、R2UNet、ResUNet 和AttentionUNet 相比,S-MLP 在参数量、Dice 系数和AUC 指标中同样表现出了优异的性能。相较于所有卷积结构的网络模型,它是最轻量的网络模型。由于Transformer 特有的网络结构,SwinUNet 与TransUNet的Params 达到惊人的108.496M 和116.922M。此外,SwinUNet 的缺陷在于需要提供大量的数据进行训练,否则模型容易发生过拟合现象。SDU-FV 数据集明显没有达到这种需求,所以导致Dice、AUC 和Acc 表现的非常差。TransUNet 的编码和解码结构部分是卷积层,在一定程度上弥补了数据不足问题,但在参数量和性能指标上依然要低于S-MLP 模型。
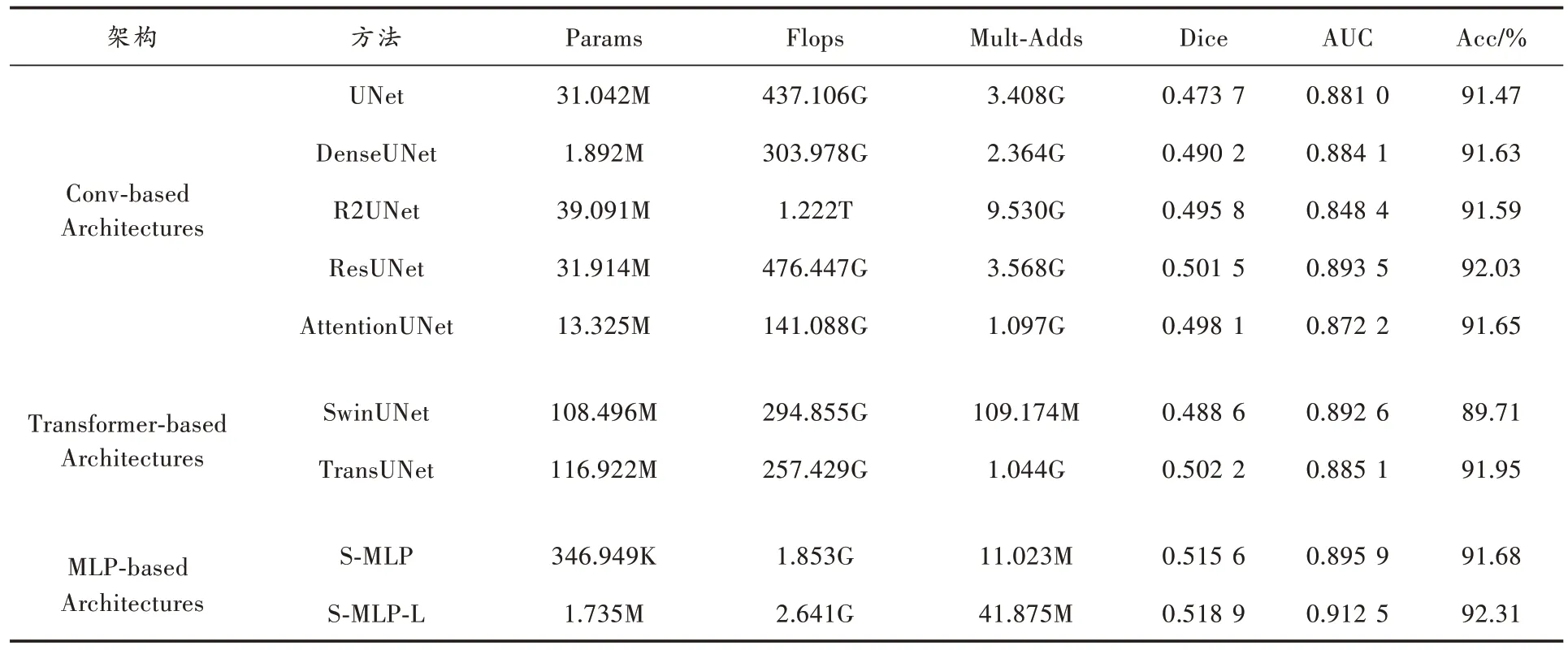
表2 S-MLP 模型在SDU-FV 数据集与其他模型效果对比
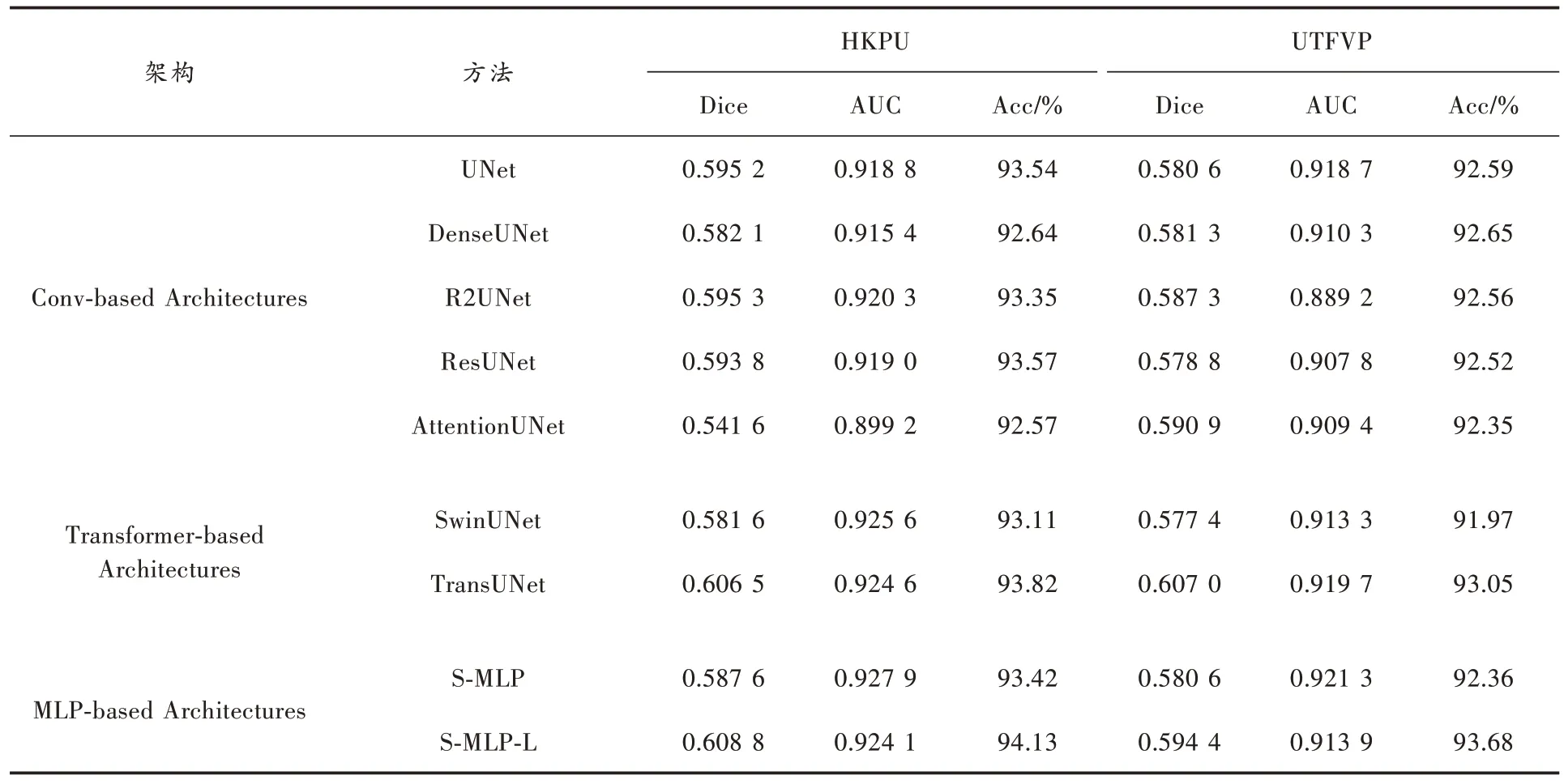
表3 S-MLP 模型在HKPU 数据集和UTFVP 数据集与其他模型效果对比
由此可见,标记MLP 将特征信息投影到更高的维度,极大减少了计算量,使得S-MLP 模型在参数量和计算复杂度上已经超越了基于CNN 和Transformer 结构的网络模型。S-MLP 模型的整体结构和对特征图的移位操作既有UNet 的将底层特征的位置信息和深层的语义信息相融合的能力,又有SwinTransformer 结构在窗口中建立特征像素与局部像素的依赖关系,并且计算复杂度更低。轻量级注意力模块Triplet Attention 的加入,使得本文方法更加专注于指静脉区域,抑制背景区域的影响,进一步提高了分割性能。
2.5 在嵌入式平台实验
在三个NVIDIA 嵌入式平台中,从算力的角度来看NX>TX2>NANO。
表4 记录了所提方法与其他网络模型的实验结果,需要注意的是,由于NANO 平台算力较低,显存仅有4 GB,因此在此平台上无法运行参数量和计算复杂度巨大的UNet、SwinUNet 和TransUNet 网络模型。从三个NVIDIA 嵌入式平台的实验结果来看,本文方法在Dice和AUC 两个重要性能指标中都取得了最优结果,证明了轻量化的S-MLP 网络模型以极少的参数量不仅在PC端超越了基于CNN 和Transformer 结构的网络模型,在NVIDIA 嵌入式平台同样取得了优秀的性能表现,这是另外两种结构所不具备的。
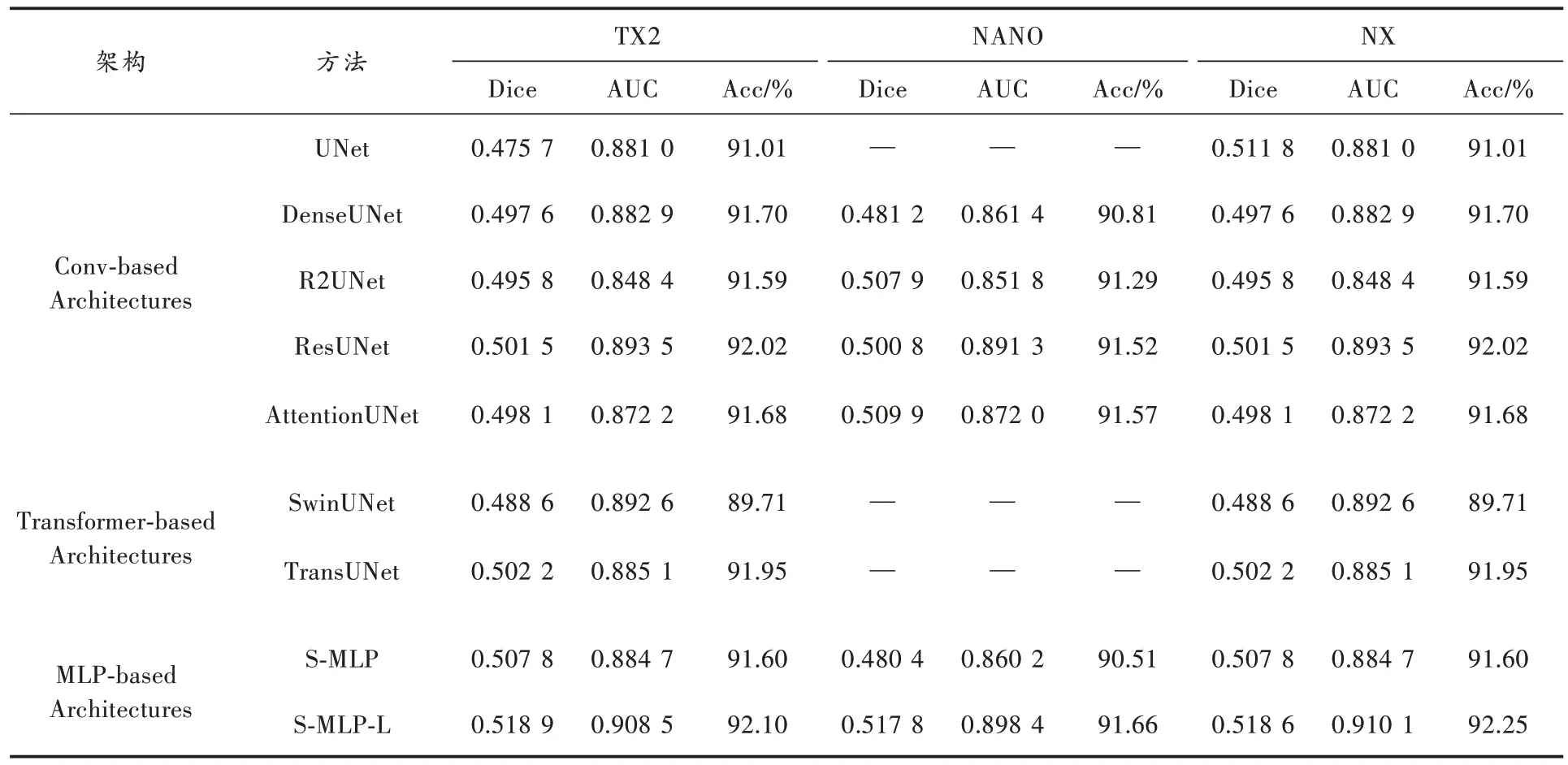
表4 S-MLP 网络模型与其他网络模型在NVIDIA 嵌入式平台实验结果对比
2.6 可视化分割效果
图2 展示了SDU-FV、HKPU 和UTFVP 三个指静脉数据集在各种网络模型下的分割结果可视化图。从图中可以观察到UNet 网络模型的分割效果并不理想,部分指静脉的细节部位并没有很好的分割出来;TransUNet 在性能指标上虽然优于基于卷积结构的网络模型,但是在可视化图中依然存在血管分割断裂的情况;S-MLP 网络模型不仅在分割性能指标上表现出色,在可视化分割效果图中分割出的血管形态更平滑,符合人体指静脉血管特点。

图2 各个网络模型在SDU-FV、HKPU 和UTFVP数据集上的实际分割效果图
3 结 语
本文提出的算法能够有效地解决现有基于CNN 和Transformer 结构模型的内存资源占用问题,并在嵌入式平台上表现出色。S-MLP 是一种轻量级指静脉纹路分割网络模型,采用Shifted MLP 对特征图进行轴向移位使网络模型更关注特征图局部位置信息;使用标记MLP块标记和投影特征信息;最后在每一层之间添加轻量级的注意力模块Triplet Attention,分别在三个分支上对空间维度和通道维度进行跨维度交互,建立起空间注意力,解决了模型轻量化导致性能下降的问题。S-MLP 在三个指静脉分割数据集上都取得了最优的分割性能并且参数量最少,在算力有限的嵌入式终端中仍能取得先进的性能。
注:本文通讯作者为秦传波。
