局部和全局特征融合的太阳能电池片表面缺陷检测
2024-04-01陶志勇易廷军张尧晟
陶志勇,何 燕*,林 森,易廷军,张尧晟
1 辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125105;
2 沈阳理工大学自动化与电气工程学院,辽宁 沈阳 110159
1 引 言
太阳能[1-2]是绿色环保清洁能源,具有无污染和可再生特点。单晶硅太阳能电池片具有稳定性好、材料分布广、能量转换效率高的优势,在工业制造中电池片通过串联、并联焊接的太阳能电池组件作为太阳辐射能转换为电能的核心部件,能量转换效率的高低和太阳能电池片表面缺陷程度密切相关。为提高电池组件的良品率,避免隐裂、暗斑、瑕疵和黑心等缺陷电池片进入电池组件,需要对电池片进行表面缺陷类型和位置的长期监控,以剔除缺陷电池片并提高产品的合格率。
电池片表面缺陷的识别有传统的机器学习方法和深度学习方法。传统的机器学习方法[3]通过人工进行电池片表面缺陷特征提取,然后使用传统算法对图像纹理特征进行分类。经典方法有Juan 等人[4]提出的电致发光成像联合支持向量机(support vector machines,SVM)分类器的检测技术,它通过对太阳能电池片缺陷特征、发光特性和健康状况等缺陷识别,多角度分析缺陷电池片对光伏系统输出效率的影响;王超等人[5]通过分析光伏电池缺陷和扩散长度的关系,解决了隐裂缺陷的可视化识别;Firuzi 等人[6]利用定向梯度直方图(histogram of oriented gradient,HOG)结合局部二进制模式(local binary patterns,LBP)进行缺陷识别,取得了较好的效果;Kim 等人[7]利用K 最近邻(K-nearest neighbor,KNN)算法和图像处理技术进行光伏电池片缺陷自动识别,解决电池片缺陷识别速度慢的问题。尽管传统机器学习方法在电池片表面缺陷检测中具有识别效果好、算法成熟的优点,但仍有算法需要大量参数调整、模型鲁棒性差、模型泛化性能差、依赖工程师主观性经验判别和无法长时间人工作业等问题。
深度学习方法[8]的电池片缺陷识别技术包含缺陷分类和缺陷检测。针对电池片中单类别缺陷,部分研究者使用红外图片、电致发光图片的缺陷分类技术。Masita 等人[9]结合ResNet50 残差网络[10]来处理电池片热差,通过红外图像热差来判别电池片缺陷;Du等人[11]结合传统分类检测和深度学习智能分类检测进行电致发光隐裂缺陷识别;Chen 等人[12]利用卷积神经网络提取电池片图像光谱特征来分析缺陷图像的复杂纹理信息,实现了较好的缺陷图像分类准确率。尽管深度学习方法在电池片缺陷分类技术中取得了良好的识别效果,但对于电池片中的多类别缺陷,研究者们仍在不断努力。Su 等人[13]通过改进Faster RCNN 网络[14]的区域建议框结构,解决多晶硅电池片中断栅、隐裂缺陷平均检测准确率不高的问题;Zhang 等人[15]通过添加YOLOv5 网络[16]的多尺度检测头和聚类优化先验框的思路,解决电池片定位精度不高和检测速度不快的问题。尽管这些网络对电池片特定缺陷识别效果良好,由于缺陷特征相似度高、背景特征复杂,致使电池片细粒度缺陷特征提取不充分,以及网络加深时易出现特征丢失现象,从而导致检测精度低。
为解决网络对特征提取不充分和检测精度低的问题,结合深度学习先进技术,提出高质量融合局部和全局特征的卷积视觉自注意力网络(convolutional -vision Transformer networks,CViT-Net)。该网络拥有缺陷特征提取能力强、缺陷分类检测精度高等优势。本文主要贡献如下:
1)提出了两个新颖模块分别为Ghost 聚焦(Ghostconvolution two fusion,G-C2F)模块和鬼影视觉(Ghost-vision Transformer,G-ViT)模块,G-C2F 旨在提取电池片缺陷局部特征,解决局部细粒度信息提取不充分的问题;G-ViT 旨在融合电池片局部特征和全局特征,解决模型对细粒度信息的特征丢失问题。
2)提出了融合局部特征和全局特征的CViT-Net网络,该网络具有特征表达能力强的优势;为适应不同工业场景,设计了CViT-Net-S 和CViT-Net-L,分别针对低和高检测精度,以满足太阳能电池缺陷检测的不同需求。
3) CViT-Net 在电池片缺陷分类和缺陷检测任务中具有良好识别效果,CViT-Net-S 结构和CViT-Net-L 结构相较经典轻量级分类模型具有特征提取能力强、分类准确率高的特性;相较先进YOLO 系列模型仍保持较好的缺陷检测能力和缺陷定位能力。
2 相关工作
2.1 轻量级图像分类模型
近年来,提高神经网络架构的检测精度成为计算机视觉的重要挑战,轻量化模型以较少的参数量成为视觉领域的研究热点。标准的卷积神经网络包含卷积层、池化层和非线性激活函数,由于计算成本大和空间复杂度高,很多网络通过改善标准卷积的计算方法来降低模型复杂度和计算成本。其中MobileNetV3[17]在反向倒残差结构中融合深度可分离卷积实现模型轻量化,ShuffleNetV2[18]结合组卷积和通道洗牌策略降低内存和模型参数量,EfficientNet[19]综合分析模型深度、宽度和分辨率实现少参数量的高精度网络,GhostNet[20]对输入特征图简单线性变换构成鬼影(Ghost)特征图后进行叠加降低模型复杂度,RegNet[21]融合组卷积和残差架构分支设计不同计算量的网络。这些网络可以高效地替换特定任务中骨干网络(如ResNet50),以减少模型规模并改善延迟。但模型存在特征空间信息提取局限的问题,不利于捕获图像的全局特征信息。
为高效捕获图像全局特征信息,将视觉Transformer(vision Transformer,ViT)[22]的特征提取网络应用在图像识别领域,对大规模数据集和高性能训练模式,ViT 在没有图像特定诱导偏差下可实现卷积神经网络同级别的识别精度。然而,ViT 本身具有缺乏归纳偏差的固有属性,使得模型难以在轻量和高精度之间取得平衡,为了提升模型的识别性能,在ViT 中引入卷积用于整合这种归纳偏差。CvT 模型[23]在ViT 模型的多头自注意力中引用深度可分离卷积;ConViT 模型[24]学习卷积神经网络的局部相关性来摆脱卷积的局部特征;MobileVit[25]将提取的局部特征进行全局表达以获取丰富的图像细粒度特征。
2.2 经典目标检测模型
在计算机视觉识别任务中,目标检测是一个重要的分支。模型根据特征提取方式,可分为一阶段检测和二阶段检测。基于回归预测的一阶段检测模型(如YOLO)拥有检测速度快、效率高的优势,二阶段检测模型(如Faster R-CNN)具有检测精度高、检测速度慢的特点。一阶段检测模型中,其原理是在模型训练之前进行聚类优化锚框来提高检测精度的有YOLOv5[16]、YOLOv7[26]、YOLOR[27];抛弃锚框采用锚点到目标边界框距离的有YOLOv6[28]、YOLOv8[29]、YOLOX[30];Faster R-CNN[14]等二阶段检测模型原理是通过生成区域建议框来提取图像特征,然后对这些提取的特征进行目标分类和目标预测。
一、二阶段检测模型的网络结构主要由骨干、颈部、头部网络三部分组成。骨干网络用于提取图像特征,为满足不同检测需求和提高检测精度,研究人员微调DenseNet[31]和MobileNetV3[17]模型后作为检测模型的骨干网络,以增强特征提取能力;颈部网络用于提取整理骨干网络提取的丰富特征信息,采用FPN[32]和PANet[33]两种方式来聚合图像的细粒度特征;头部网络则负责预测目标类别和目标边界框,主要分为二阶段检测方法(Faster R-CNN)和一阶段检测方法(YOLO)两种形式。
3 卷积视觉Transformer 网络
3.1 坐标注意力
坐标注意力(Coordinate attention,CA)[34]是一种增强模型特征提取能力的计算单元,在不增加网络复杂度的情况下突出特征信息。压缩激发(Squeeze-andexcitation,SE)[35]注意力利用全局池化进行全局空间信息编码,编码后的空间信息被压缩到通道信息中,位置信息难以保存。空间注意力(Convolutional block attention module,CBAM)[36]通过考虑特征图空间和通道维度之间的语义相互依赖性来建立跨通道和跨空间的信息,但由于引入大尺度卷积增加计算开销。通道和空间兼有的多尺度注意力机制(efficient multiscale attention,EMA)[37],由于其较高的参数量和计算复杂度,无法满足行业实时检测的需求。坐标注意力不仅考虑了特征间不同位置的相关性,也分析特征位置之间的距离和方向信息,结构如图1 所示。
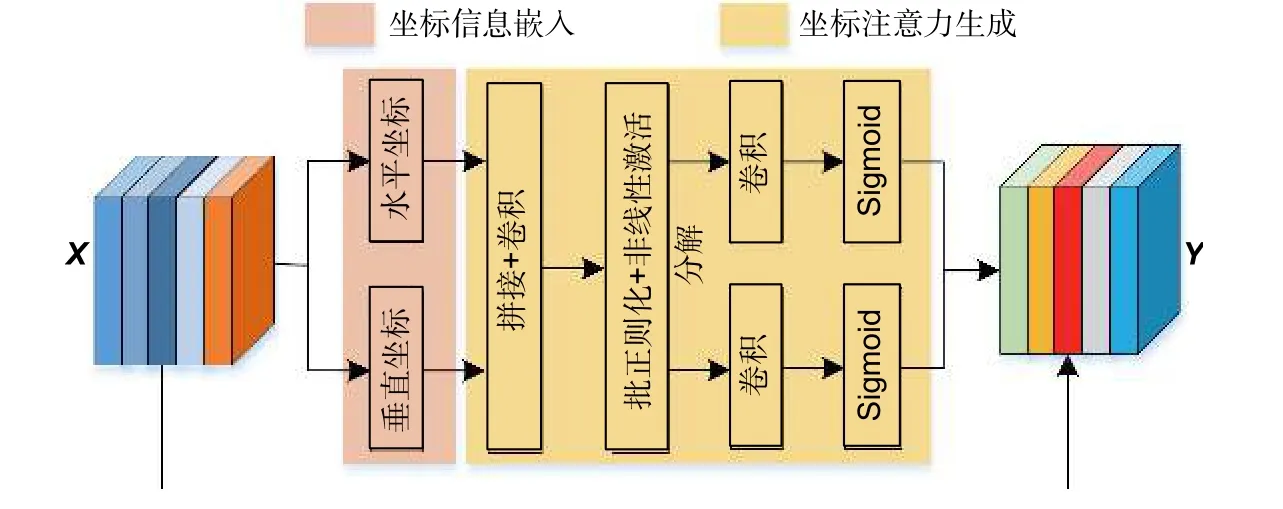
图1 坐标注意力Fig.1 Coordinate attention
坐标注意力对输入X分别使用尺寸为(H,1)或(1,W)的全局平均池化核,H是特征图高度,W是特征图宽度。沿着水平坐标和垂直坐标对每个通道进行编码,高度为h的第C通道输出(h)表示为式(1),XC(h,i)表示输入特征XC在(h,i)坐标上的数值。
宽度为w的第C通道输出表示为式(2),XC(j,w)表示输入特征XC在(j,w)坐标上的数值。
f沿着空间维度分别分解为两个独立的张量fh∈RC/r×H和fw∈RC/r×W,fh和fw分别经过卷积核大小为1×1的卷积函数Fh和Fw,卷积函数生成与X同样尺寸的特征张量gh和gw,如式(4)和(5)所示,σ表示Sigmoid 激活函数。
gh和gw作为坐标注意力权重与原始输入特征X进行点乘,输出第C通道上坐标(i,j)的增强特征Y可写为式(6)。
3.2 Ghost 聚焦模块
卷积神经网络(Convolutional neural networks,CNN)参数共享和并行计算对计算机视觉任务提供了友好发展,但模型参数量和复杂度会随着网络层数的加深出现非线性增加,高参数量和高复杂度模型不利于工业进行实时检测,因此,同时兼备轻量级和高时效的网络对工业检测具有重要应用价值。该文网络受到轻量级MobileNetV3[17]和GhostNet[20]模型启发,构建了能提取丰富特征表达能力的Ghost 聚焦(Ghost -convolution two fusion,G-C2F)模块,结构如图2 所示,G-C2F 模块对特征X分别输入CNN 分支和C2F分支提取缺陷信息。

图2 鬼影聚焦模块Fig.2 Ghost focus module
G-C2F 模块对输入特征X∈RH×W×C分别经过CNN分支和C2F 分支得到纹理特征XGC和XC2F,然后将XGC和XC2F进行融合叠加得到输出特征Y∈RH×W×C,过程如式(7)所示:
CNN 分支旨在实现模型轻量化和高精度,输入张量X利用Ghost3×3卷积提取电池片缺陷特征,提取后的特征通过CA 强化缺陷信息,最后是一个卷积核大小为1×1的点卷积层学习输入通道的线性组合并将张量投影至高维空间;同时,考虑到太阳能电池片纹理信息复杂、类内差异大和类间差异小的特点,模块引入ResNet50 模型[10-11]残差架构思想来避免CViTNet 网络梯度消失问题。请注意,本文引入的残差分支和ResNet50 模型的残差分支存在差异,在层与层之间,采用池化核大小为3×3的最大池化层替代ResNet50 残差模块的本体分支,这样做的优势可降低模型过拟合及获取缺陷高频特征,最后融合最大池化残差分支后的输出张量为XGC。
C2F 分支旨在用卷积层提取丰富的局部细粒度特征,该分支灵感来于YOLOv8 网络[29]。为实现网络轻量化和丰富的局部图像编码信息,C2F 分支首先对输入张量X采用卷积核大小为1×1的点卷积调整缺陷特征编码维度;其次对缺陷特征在空间维度进行细致划分,借鉴了ELAN[26]架构的方式来捕捉丰富的梯度流信息。然后采用了将模型获取的特征图在通道上进行拼接的方法,以降低参数量和计算量。最后将获取的层级特征进行通道叠加后送入卷积核大小为1×1的点卷积得到输出特征张量XC2F。尽管C2F 分支中N有多种取值(如2,3,4,5,...),但从模型参数量和复杂度考虑,发现N=3 时CViT-Net 模型可实现最佳效果。
3.3 鬼影视觉模块
卷积神经网络强归纳偏置对临近像素的局部相关性拥有友好关注度,相比之下,利用自注意力机制捕获全局语义信息的Transformer 模型[22]最小化图像内的归纳偏差,但在全局表征学习中它的长距离依赖关系对特征信息提升效果显著。因此,为获取丰富的图像局部纹理特征和全局语义信息,融合CNN 局部强归纳偏置优势和Transformer 长距离依赖强项构造了鬼影视觉(Ghost-vision Transformer,G-ViT)模块,结构如图3 所示。

图3 鬼影视觉模块Fig.3 Ghost vision module
G-ViT 模块旨在对较少输入参数的输入张量进行局部信息和全局信息建模,结构上,对于给定输入张量X∈RH×W×C首先在空间维度上通过分解操作得到两个相同的独立张量X1∈RH×W×C/2,H表示特征图高度,W表示特征图宽度,C是通道数;然后将独立张量X1分别经过CNN 分支编码局部空间信息得到局部特征XGC,Transformers 分支进行全局信息建模得到全局特征XViT;最后利用拼接实现局部特征和全局信息聚合得到输出特征Y∈RH×W×C,过程如式(8)所示。请注意,G-ViT 模块和G-C2F 模块的CNN 分支架构相同,输出特征依然是用XGC表示。
Transformer 分支旨在实现长期建模的非局部依赖关系,同时获取有效的感知域H×W。首先利用卷积核大小为1×1 的点卷积,对输入张量X1的张量维度进行调整;其次利用多头自注意力Transformer 模块捕获丰富的全局缺陷特征,由于Transformer 重量级因素不利于模型优化,因此,考虑到模型复杂度特点,模块采用N=3 和头部数量为8 的Transformer 结构获取全局信息表示;最后将获取的全局信息再次通过1×1的点卷积进行局部空间编码,得到张量XViT。
3.4 CViT-Net 结构
CViT-Net 网络为不同工业实践场景提供了2 种型号的结构,分别定义为CViT-Net-S 和CViT-Net-L,CViT-Net-S 网络是针对低检测精度(如移动端),模型参数量和计算量分别是5.6 M 和1.52 G;CViT-Net-L网络主要用在高检测精度(如云端),模型参数量和计算量分别是21.9 M 和6.49 G,CViT-Net 网络结构图如图4 所示。
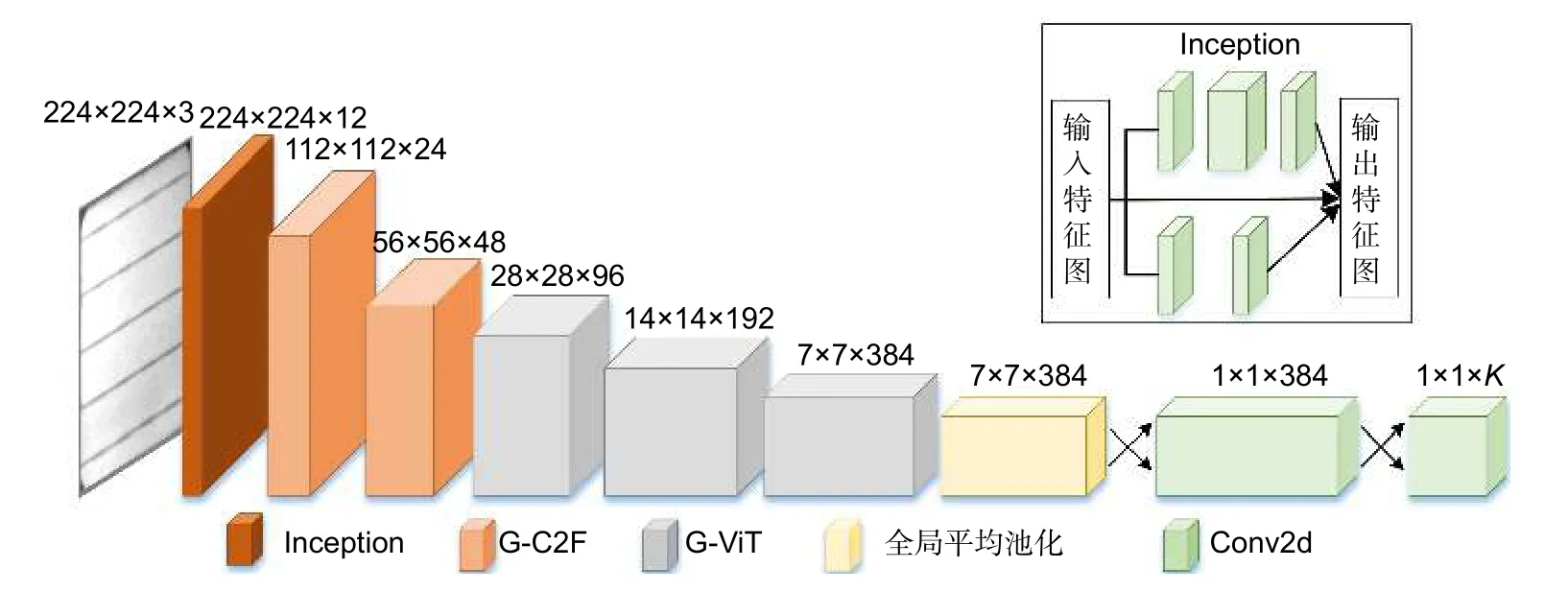
图4 CViT-Net 网络结构图Fig.4 CViT-Net network structure diagram
详细参数如表1 所示。这些模型首先通过Inception[38]模块进行多尺度特征聚合;然后通过多层级G-C2F 模块和G-ViT 模块提取电池片表面缺陷特征,CViT-Net 网络首先通过G-C2F 模块获取丰富的局部细粒度特征,G-ViT 模块融合局部特征和全局信息;最后为避免模型过拟合和缺陷局部结构信息丢失,受到MobileNetV3 网络[17]启发,利用卷积核大小为1×1的卷积层和池化核为7×7的全局平均池化取代全连接层(fully connected layers,FC),并进行缺陷特征分类。分类使用的卷积层不带偏置项和激活函数,从而最大限度减少参数量和降低计算成本。
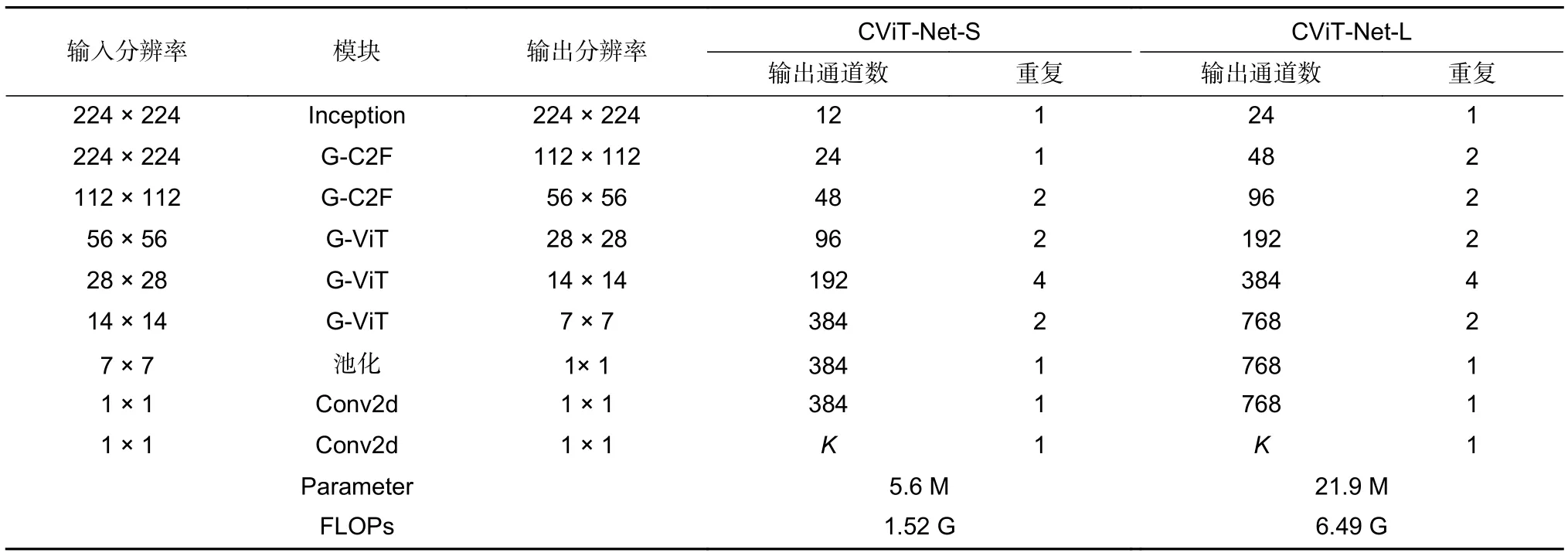
表1 CViT-Net 模型参数表Table 1 CViT-Net model parameter table
CViT-Net-S 网络和CViT-Net-L 网络输入分辨率都是224×224,层级间相同模块输出分辨率的缺陷特征大小保持尺寸一致,它们在池化后经过2 个卷积核大小是1×1的点卷积进行缺陷识别分类。然而,针对不同资源用例的工业场景,CViT-Net-S 网络层级间模块输出通道数和模块重复数与CViT-Net-L 网络存在差异,最后经过K值实现缺陷特征分类。
4 数据集和缺陷检测流程
4.1 数据集
自建的太阳能电池片数据集采用电致发光(EL)成像技术[39],通过CCD 相机采集6×10的电池组件,进行切割、汇编、标注后构建太阳能电池片图像数据库。本文重点对工业常出现的无缺陷、黑心、暗斑、瑕疵和隐裂5 类进行研究,所有检测图像分辨率为540×540,类型如图5 所示。无缺陷表现出电池片正常完好无损;黑心表现出电池片是整体黑色的图片;暗斑表现为图像中呈块状型深暗色或黑色的电池片;瑕疵表现为电池片中微小的斑点状或小黑点;隐裂表现为电池边缘与栅线附近的延伸裂开状缺陷。
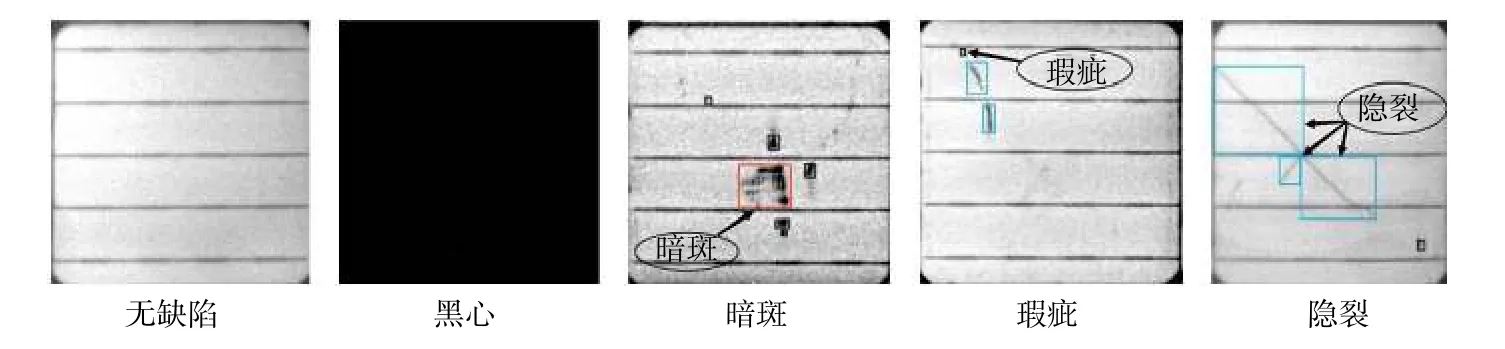
图5 太阳能电池片种类Fig.5 Solar cell types
4.2 缺陷检测流程
电池片图像包含多种类型缺陷、缺陷背景纹理特征复杂、类内差异大和类间差异小的问题。因此将数据库中的电池片种类图像划分为分类数据集和检测数据集。分类数据集有三个类别,分别是无缺陷、黑心和多类缺陷图像(隐裂、暗斑、瑕疵),数据集中图像均为原始图像,未做任何清晰化等图像预处理,总计包含数据量是9790 片,利用分类模型(CViT-Net)识别出无缺陷、黑心和多类别缺陷;检测数据集是在分类数据集的基础上存在的多类缺陷图像(隐裂、暗斑、瑕疵)进行边界框的定位检测,总计数据量是4970 片,利用定位模型YOLOv5(CViT-Net)定位出图像内隐裂、暗斑和瑕疵缺陷的位置,YOLOv5(CViT-Net)表示采用CViT-Net 为检测模型骨干网络,YOLOv5 为检测框架。详细的缺陷检测流程图如图6 所示。为保证网络合理的训练和测试,将电池分类数据集和检测数据集分别按照6:2:2 比例划分为训练集、验证集、测试集。

图6 太阳能电池片缺陷检测流程Fig.6 Solar cell defect detection process
5 实验与分析
5.1 实验平台
所有模型的训练环境和测试环境皆在Ubuntu18.0.4系统上搭建深度学习检测框架Python3.8、Pytorch1.10,硬件配置为CPU Xeon-4210,GPU RTX3090。模型分类实验和检测实验均选取随机优化算法(Adam)优化网络参数,初始学习率选取0.01,同时利用余弦(Cosine)函数调整学习率下降,此外,分类实验和检测实验不同参数如表2 所示。
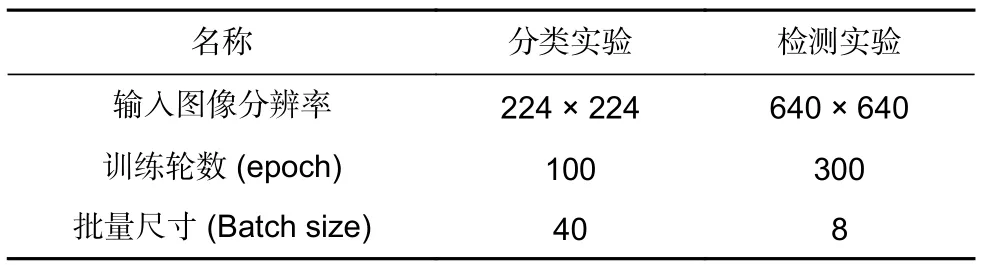
表2 分类实验和检测实验不同参数值Table 2 Classify and detect experimentally different parameter values
5.2 分类实验分析
为验证CViT-Net 模型在太阳能电池片缺陷分类上的优势,与先进卷积神经网络ResNet50、DenseNet121、EfficientNet-B0、RegNet、MobileVit、MobileNetV3、ShuffleNetV2 和GhostNet 等对比实验如表3 和图6 所示,所有模型未采用预训练参数。模型对电池片测试采用精确度(Precision)、召回率(Recall)和准确率(Accuracy)等评价指标,它们的计算公式分别为:
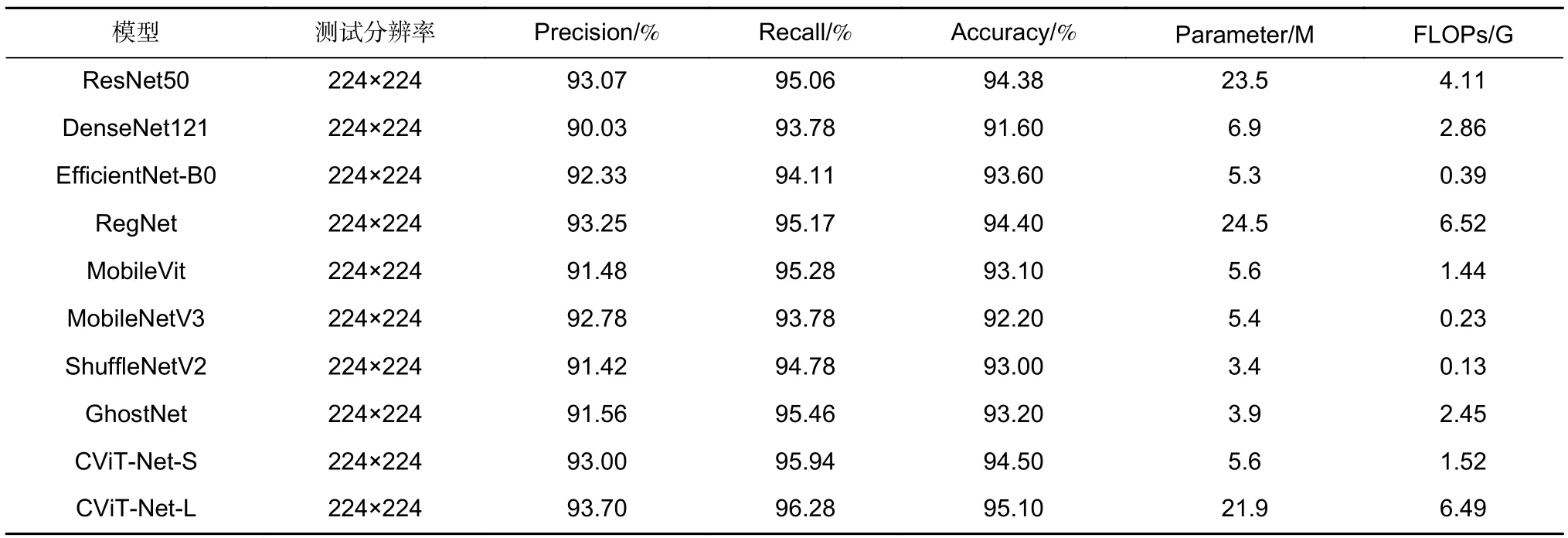
表3 先进卷积神经网络算法对比Table 3 Comparison of advanced convolutional neural network algorithms
其中:YTP表示正类样本被模型正确识别为正类的数量;YTP+FP表示模型预测的正类样本数量;YTP+FN表示真实的正类样本数量;YTP+FN+FP+FN表示总样本数量,此外,模型参数量(Parameter)和计算量(FLOPs)亦至关重要,它们共同反映了模型复杂度。
由表3 和图7 的实验结果可知,相较同参数量和计算量的经典卷积神经网络,CViT-Net-S 和CViTNet-L 模型分别实现了最优准确率94.50%和95.10%,模型参数量分别为5.6 M 和21.9 M,模型计算量分别为1.52 G 和6.49 G。与专注于移动网络的MobileVit和MobileNetV3 相比,CViT-Net-S 网络参数量和计算量表现不友好的原因是模型融入了Transformer,但在缺陷识别精确度指标上显著提升了1.52%和0.22%,召回率提升了0.66%和2.16%。ShuffleNetV2模型FLOPS 为0.13 G,但相比于CViT-Net-S 模型缺陷检测精确度、准确度和召回率显著提升了1.8%、1.5%和1.16%。
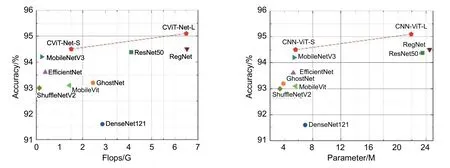
图7 模型准确率相较计算量和参数量对比图Fig.7 Comparison chart of model accuracy compared to calculation amount and parameter amount
CViT-Net 具有高精确、高召回率和轻量特点。CViT-Net-L 精确度和召回率高达93.70%和96.28%,相较于DenseNet121,精确度、召回率和准确度分别提升了2.97%、2.16%和2.9%,参数量和计算量分别减少43.8%和46.8%;CViT-Net-L 与参数量相近的RegNet 相比,精确度、召回率和准确度分别提升了0.45%、1.11%和0.7%,参数量和计算量分别降低了2.6 M 和0.03 G;CViT-Net-S 与DenseNet121、EfficientNet、ShuffleNetV2、GhostNet 等轻量级网络相比,最优精确度、召回率和准确度高达93%、95.96%和94.5%。参数量和计算量分别为5.6 M 和1.52 G。综上所述,CViT-Net 网络模型在低参数量和计算量的同时具有优秀的缺陷识别性能。
5.3 不同注意力应用于CViT-Net 的性能比较
为验证CA 注意力机制的有效性,在保证其它模型参数量一致的情况下,分别将SE、CBAM、EMA和CA 注意力机制嵌入到CViT-Net 模型中,实验结果如表4 所示。

表4 注意力机制性能比较Table 4 Attention mechanism performance comparison
实验结果表明,CViT-Net 模型在融入CA 注意力的情况下,取得了最优的精确度、召回率和准确度,分别达到93%、95.94%和94.5%,其参数量和计算量分别为5.64 M 和1.52 G。虽然CA 注意力的参数量略高于SE 和CBAM,但在精确度、召回率和准确度方面均取得了显著提升,较SE 分别增加了12.26%、15.36%和6.82%,较CBAM 分别增加了 6%、8.34%和2.26%。相较参数量相同的EMA,精确度、召回率和准确度分别提升了5.1%、9.54%、1.3%,计算量降低了0.2 M。综上所述,将CA 嵌入CViT-Net 模型显著提升了检测效果。
5.4 消融实验
为验证CViT-Net 模型在太阳能电池片缺陷检测的优越性,分别对G-C2F 模块、G-ViT 模块、CA 模块进行消融实验。为满足工业检测需要的高精度和高效率,在CViT-Net 系列中选择CViT-Net-S 网络所做消融实验如表5 所示。Baseline 表示卷积层和全连接层组合的缺陷识别方法。

表5 CViT-Net-S 网络消融实验Table 5 CViT-Net-S network ablation experiment
“-”表示没有使用该模块,“√”表示使用该模块,加粗字体表示最优项。实验结果表明,基于卷积层和全连接层作为Baseline 依次改进的CViT-Net-S 网络在保持低参数量、低计算量的同时实现最优识别准确率、参数量和计算量分别为94.50%、5.6 M 和1.52 G。G-C2F 模块旨在提取电池片缺陷局部纹理细粒度特征,相较原始Baseline 基线在准确率上提升了5.37%,参数量和计算量分别减少了39.8%和67.8%;G-ViT 模块是用于融合电池片缺陷局部特征和全局特征,由于Transformer 融入使得参数量提升至12.6 M,但丰富的缺陷纹理特征促进CViT-Net-S 在缺陷检测准确率高达92.31%;通过CA 注意力强调缺陷特征,抑制不相干的背景特征,使得缺陷检测准确率达到了93%;为平衡参数量,CViT-Net-S 最终相较Baseline的参数量和计算量分别减少了62.1%和63.8%,准确率提升了7.72%,参数量降低了9.2 M。
5.5 检测实验分析
由表6 可知,一、二阶段模型中YOLOv5 在分类实验表现最优,mAP50 最高为89.4%,为验证CViT-Net 网络在电池片缺陷检测具有优越性,选择YOLOv5 作为基础检测框架,更换不同骨干网络进行实验验证。结果如表7 所示,采用Precision、Recall和平均精度均值(mean average precision,mAP)作为评价指标。其中mAP50 是真实目标框面积与预测目标框面积的交集与并集之比大于50%的平均精度均值;mAP 是真实目标框面积与预测目标框面积的交集与并集之比大于50%且小于95%的平均精度均值,它们有相同计算公式如式(12)所示,m表示缺陷类别数,APi表示第i个类别的平均精度 。
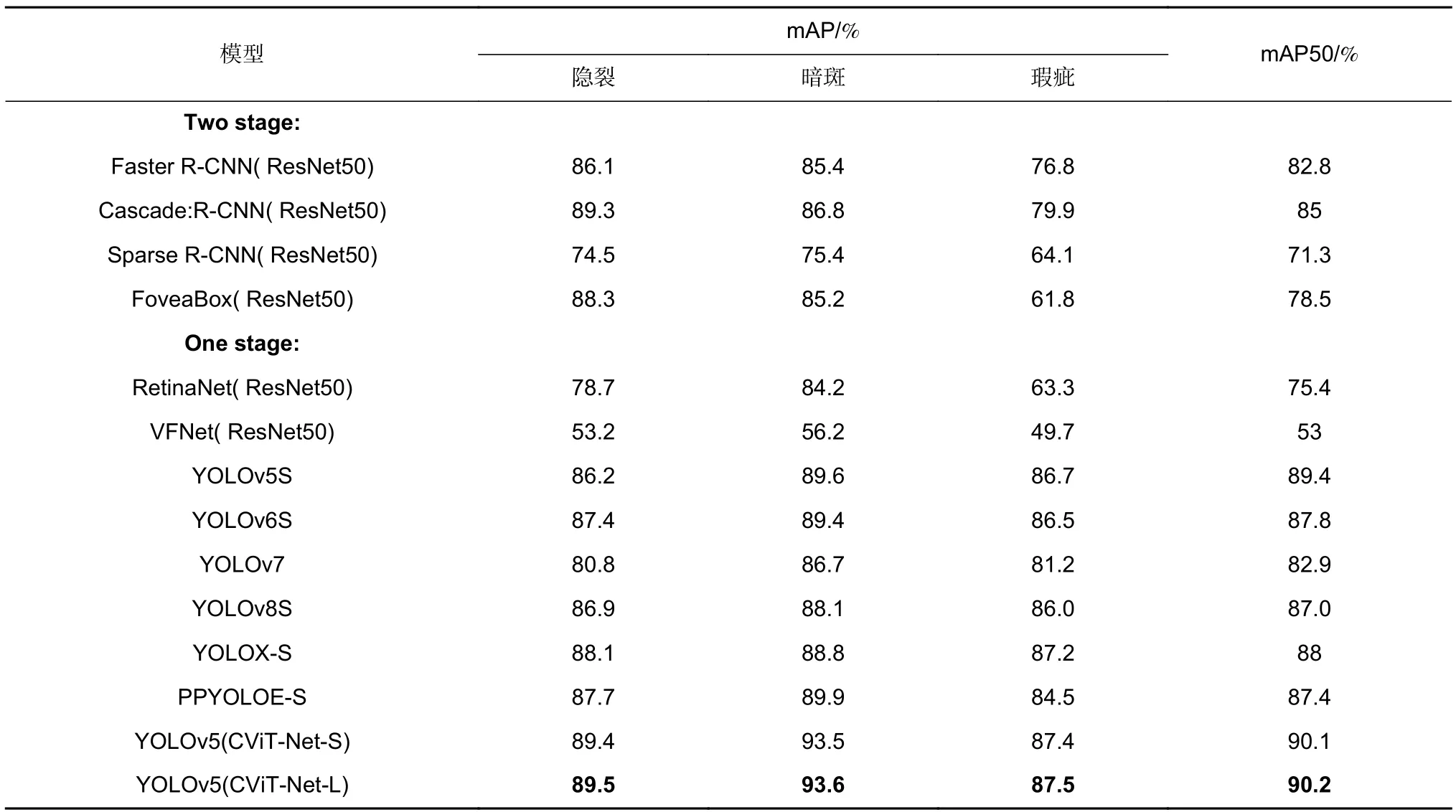
表6 不同目标检测算法实验对比Table 6 Experimental comparison of different target detection algorithms

表7 YOLOv5 检测框架下的骨干网络对比实验Table 7 YOLOv5 backbone network comparison experiment
表中所有模型未采用骨干网络预训练参数和YOLOv5 颈部及头部预训练参数,初始学习率为0.01,使用Adam 优化器进行300 轮训练,数据集采用多类缺陷图像(隐裂、暗斑、瑕疵)数据集,共计4970 片缺陷图像。
实验结果由表6 可知,YOLOv5 检测框架,骨干网络采用CViT-Net-S 和CViT-Net-L 实现的最优mAP50 值分别是90.1%和90.2%,mAP 值是56.2%和61.1%。与MobileVit、MobileNetV3、ShuffleNetV2等骨干网络相比,CViT-Net-S 在召回率和mAP 均达到了最优效果;与ResNet50、DenseNet121、RegNet等网络相比,CViT-Net-S 和CViT-Net-L 骨干网络在精确度、召回率、mAP 和mAP50 值上保持最优,其中提升效果明显的是CViT-Net-L 骨干网络相较ResNet50 在精确度和召回率上分别提升了6.2%和2.2%,mAP 和mAP50 上分别提升了12.7%和3.9%。同时所有骨干网络在YOLOv5 检测框架下的可视化定位结果如图8 所示,CViT-Net 网络在保持隐裂、暗斑、瑕疵缺陷高定位精度时可避免模型漏检和误检,保证了模型对缺陷的定位准确度。综合而言,采用GC2F 模块提取电池片缺陷局部细粒度特征、G-ViT 模块融合电池片缺陷局部特征和全局特征的CViT-Net模型,该模型作为骨干网络能充分提取电池片表面缺陷特征。
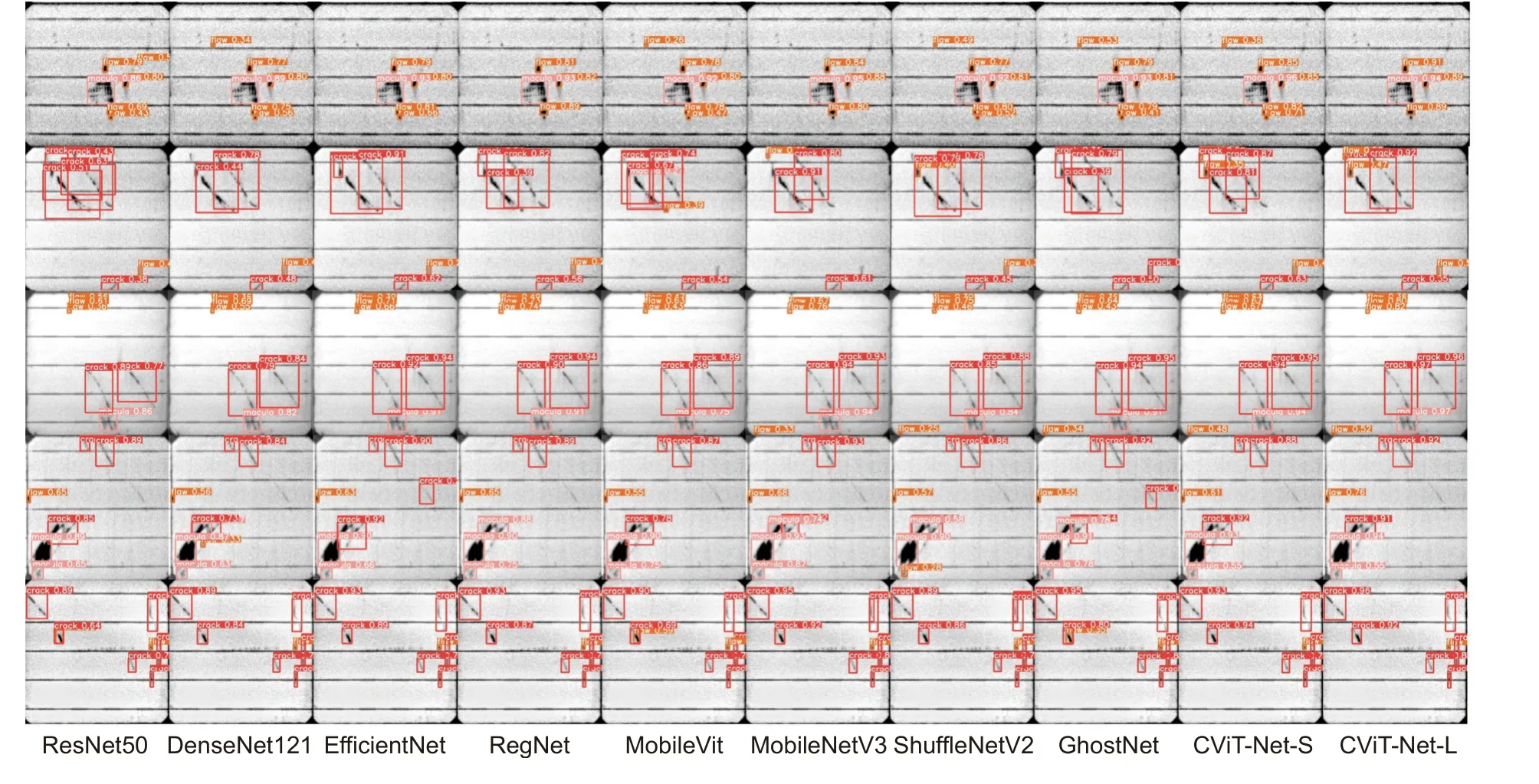
图8 YOLOv5 检测框架下的可视化定位结果Fig.8 Visual positioning results under YOLOv5 detection framework
5.6 不同目标检测算法实验对比
为验证CViT-Net-S 和CViT-Net-L 作为骨干网络融合YOLOv5 算法在太阳能电池片缺陷检测中具有高效性和泛化性,与当前流行的一阶段、二阶段网络进行对比实验,不同目标检测算法实验对比结果如表7 所示。在太阳能电池片多类缺陷图像(隐裂、暗斑、瑕疵)数据集上进行对比实验。模型在没有预训练参数情况下重新训练300 个epoch,图像训练和测试尺寸皆是640 pixels×640 pixels,Faster RCNN (ResNet-50)表示采用Faster RCNN 为主体框架,ResNet-50 为骨干网络。
由表6 可知,YOLOv5(CViT-Net)、YOLOv5(CViTNet-L)模型与一阶段、二阶段网络模型相比,最优mAP50 分别为90.1%和90.2%,利用G-C2F 模块和G-ViT 模块组合的特征提取网络CViT-Net-S、CViTNet-L,在融合YOLOv5 检测框架后可高效进行太阳能电池片表面缺陷检测,相较经典YOLO 和R-CNN系列算法在精确度、召回率、mAP 和 mAP50 等多个评价指标上皆占据优势。
6 结 论
本文基于深度学习先进技术,提出了一种能够高质量识别太阳能电池片表面缺陷的CNN-ViT 模型。相较于经典的轻量级网络分类模型,CNN-ViT 模型在电池片缺陷分类精确度、召回率和准确度上都表现更优。同时,为满足工业检测需求,分别提出了参数量为5.6 M 的CViT-Net-S 结构和参数量为21.9 M 的CViT-Net-L 结构。此外,采用CViT-Net 作为骨干网络,结合YOLOv5 检测框架对太阳能电池片缺陷进行定位。与经典的轻量级骨干网络或先进的YOLO系列模型相比,CViT-Net 在结合YOLOv5 检测框架后实现了出色的缺陷检测精度和缺陷定位精度。在后续工作中,将深入拓展CViT-Net 模型,以应用于其他实物的缺陷分类检测,满足不同实物缺陷识别的需求。
