基于光学影像的滑坡实时自动识别技术研究
2024-03-24王辉范硕超黄晓胤邱鹏于竞哲李进田
王辉 范硕超 黄晓胤 邱鹏 于竞哲 李进田
(1 国网冀北电力有限公司,北京 100054)
(2 国网冀北电力有限公司超高压分公司,北京 102488)
(3 国网冀北电力有限公司电力科学研究院,北京 100045)
(4 北京深蓝空间遥感技术有限公司,北京 100101)
0 引言
我国是世界上地质灾害最严重的国家之一,而滑坡作为三大主要地质灾害之一,在我国也是极为频繁的发生,其中大型和巨型滑坡影响最为突出[1]。我国大部分地区都发生过6 级以上的地震,导致大约有700 多个县、市长期受地质灾害的影响,其中崩塌、滑坡、泥石流等地质灾害隐患点25 000 处,影响范围约占国土面积40.8%。每年的地质灾害都会给人民和国家带来巨大的经济损失[2],因此对滑坡灾害的识别监测具有十分重要的意义。
基于遥感技术进行滑坡识别的研究已不胜枚举。目前基于像素的滑坡信息提取已克服了人工判读的缺点,其主要方法是基于遥感图像中每个像素值及其变化来确定其目标类别。文献[3]利用变化信息监测方法成功分离图像中滑坡与裸露的岩石和土壤;文献[4]基于纹理变化监测技术从地震前后影像中提取了滑坡灾害信息;文献[5]采用不同阈值选择方法对滑坡进行提取;文献[6]采用基于像素的震后滑坡测绘变化检测方法进行滑坡识别;文献[7]基于对象分类法结合植被指数和纹理特征对古滑坡和新生滑坡进行识别;文献[8]利用面向对象分类技术对不同地区进行滑坡检测;文献[9]基于影像分割结合对象不同特征进行滑坡识别;文献[10]对遥感影像进行多尺度分割并采用基于监督分类和规则分类两种方法进行滑坡识别;文献[11]将基于对象的图像分析技术与机器学习算法结合应用于滑坡识别;文献[12]将面向对象方法与深度学习和迁移学习相结合,精确提取了大型滑坡边缘与中小型滑坡。
以往,目视解译一直是滑坡识别常用的手段,准确率相对较高,但自动化程度低导致极其浪费人力。使用计算机对滑坡等地质灾害进行智能识别是地质、遥感类工作者一直以来所追寻的方式。上述研究中有采用不同阈值选择方法对单时像进行滑坡提取的方法,但滑坡的发生一般伴随着地物变化,当研究区存在较多与滑坡光谱特征相似的地物时,基于单时相的影像进行光学滑坡的识别存在较高的错误率。基于多时序光学影像探查这种变化是识别滑坡的有效途径之一。从地学原理分析可知,可通过两幅滑坡前后的光学影像进行变化检测,从而识别出滑坡的区域。基于像素的滑坡识别是一种高效、简单的滑坡识别手段,只需要两景光学影像就可以实现滑坡识别。上述研究中也存在使用多时序影像进行滑坡识别的方法,但大多不是基于像素进行的,存在时效性差的问题,而上述研究中基于像素的识别算法也由于处理过程需要人工参与,存在非自动化的缺陷。为了提高滑坡识别准确率,并有效增加滑坡应急的时效性,以多时序遥感影像的变化检测为基础,采用基于像素的滑坡识别算法,结合自动阈值选取算法和形态学技术进行滑坡区域提取,在保证遥感滑坡识别的准确性和可靠性的同时,还实现了实时性和自动化。
本文以北京门头沟区为研究区域,针对现有滑坡识别方法的自动化能力欠缺、识别效率低等问题,提出变化检测技术结合自动阈值算法、形态学等进行滑坡的快速自动识别技术,以实现实时、高效且低成本的滑坡识别技术的应用。本文的技术路线图如图1 所示。

图1 本文技术路线图Fig.1 Technical roadmap of this paper
其主要步骤包括:
1)基础数据准备与预处理。如两幅光学影像的准备与数据预处理,数字高程模型(Digital Elevation Model,DEM)数据准备与其衍生产品坡度数据和山体阴影数据的预处理等。
2)进行植被覆盖指数(Normalized Difference Vegetation Index,NDVI)计算,并计算扰动变化参数I。
3)滑坡预选区生成。基于统计分析原理,使用循环分割算法完成植被扰动分类规则的阈值选取工作,进行滤波等操作生成滑坡预选区。
4)滑坡参数计算与设定。基于滑坡预选区陶粒,计算其形态学参数、去除山体阴影(分割阈值由最大类间方差法自动设定),设定滑坡预选区陶粒的质心坡度阈值,保留滑坡陶粒。
5)滑坡结果生成。二值化滑坡陶粒,生成滑坡二值化栅格图,用于分析制图。
1 研究区与数据处理
1.1 研究区概况
门头沟区位于北京城区正西偏南,介于东经115°25′00′′~116°10′07′′,北纬39°48′34′′~40°10′37′′之间,地处华北平原向蒙古高原过渡的山地地带,全区以山地为主,地势由西北向东南倾斜。由于地形地貌与气候、矿产的影响,导致门头沟区成为北京市区域内发生滑坡灾害较为密集的地区。结合门头沟区历史滑坡分布和实时监测的特点,选取门头沟西部历史滑坡较为密集的区域作为本次的研究区,如图2 所示,选取的影像几乎无云量覆盖,且监测时间间隔恰好为相差一年时间的同一时期,此时的气候等环境影响一致,识别准确率更高。
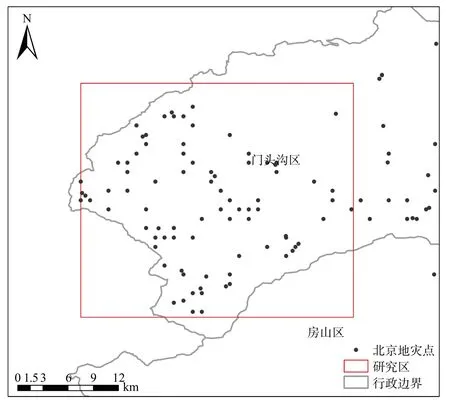
图2 研究区地理位置Fig.2 Geographical location of the study area
1.2 数据与处理
PlanetScope 陆地观测小卫星系统属于美国Planet 商业遥感卫星公司,第一批卫星于2014 年发射,截至目前已经有170 余颗卫星,是全球最大的卫星星座。该卫星系统每天以3 m 的分辨率重访全球任何地区以获取海量的全球卫星影像数据,可提供大多数地区的近乎实时图像的服务,相较于当下众多高空间分辨率卫星数据,PlanetScope 卫星数据有高频次重访的独特优势,为陆地监测和土地利用监测提供了完美的方案。
本研究得到覆盖研究区的两幅3 m 高分辨率Planet 数据,监测时间分别为2021 年9 月7 日和2022年9 月7 日,整个研究区尺寸为9 191 像素×8 177 像素,面积约676.39 km2,如图3 所示。
基于获取的Planet 数据,进行基础光学数据处理,如影像校正、辐射定标、大气校正、镶嵌与裁剪等步骤完成两幅影像的预处理工作,步骤如图4 所示。

图4 Planet 数据处理流程Fig.4 Planet data processing flow
获取覆盖监测区的12.5 m 空间分辨率的DEM 数据,该数据由日本对地观测卫星 ALOS 搭载的L 波段合成孔径雷达(PALSAR)采集。基于地学软件ARCGIS 的坡度提取工具和山体阴影提取工具分别获取覆盖研究区的坡度数据和山体阴影数据,山体阴影需要指定太阳在天空的位置,然后根据每一个DEM的像素值计算表面的假定的高度值,太阳的位置是利用太阳方位角与太阳高度值来描述的,这两个参数可通过Planet 卫星数据的头文件中查询。对获得的坡度数据和山体阴影数据进行投影转换、重采样、影像配准、影像裁剪等处理,获得与光学影像同行列、同分辨率的配准坡度网格数据和山体阴影网格数据,如图5 所示。

图5 辅助数据Fig.5 Auxiliary data
2 基于光学影像的滑坡实时自动识别
2.1 自动阈值选取
阈值分割是图像处理的基本问题,在图像分析和识别中起着重要作用。有关图像阈值自动选取方法已多达数十种[13-14],并仍有新的图像阈值选取方法被陆续提出,对于不同的图像分割要求,寻找计算简单且适用性强的图像阈值自动选取方法尤为重要。
图像阈值选取方法的选择应该依据具体的需求及应用场景来确定,其选取的方法性能受到目标大小、对比度、均值差、目标和背景方差以及噪声等因素的影响。各方法的性能与所处理的特定图像有关,而定量性能的比较取决于所用的性能准则,并不能使用一种算法就能将所有的测试图像与性能准则做到最佳。有研究表明,针对于一般的实时应用,可选用简单统计法与最大类间方差法。
由于现下判定一种图像阈值选取方法的优劣暂无公认的统一标准,因此针对实验中可能需要进行图像阈值分割的步骤采用每种阈值选取方法均进行了试验,最终根据分割的情况,粗略的给了一个“不行、差、中、好”的评判,认为“不行”的一般产生不出适当的阈值,而标为“好”的对大多数图像都能产生出好的阈值。基于此选择最“好”的自动阈值选取算法,对自动化过程中的参数阈值进行设定。
通过对不同的阈值自动选取算法的适用性及优点进行研究分析,将不同算法应用于本文中的阈值选取过程,经过反复试验,本文中最终使用到了两种阈值自动选取算法,分别为循环分割算法和最大类间方差法,以下对两种方法进行简要的介绍。
(1)循环分割算法
该方法基于图像灰度级分布。使用单个全局阈值来分割图像的直方图。基本方法是逐像素扫描差值图像,并将像素标记为目标或背景,以实现图像分割。可通过以下步骤获得最佳阈值:计算影像灰度级最值Tmin和Tmax,计算初始阈值T=(Tmin+Tmax)/2,使用初始阈值T对影像进行第一次分割,以灰度值大于T的像素即为目标G1,灰度值小于或等于T的像素即为背景G2,然后分别计算目标G1和背景G2中所有像素的均值x1和x2,按式(1)计算新的阈值T1
使用每次生成的新阈值对图像进行分类并重新计算阈值,直到两个值之间的差值小于0.01(可根据需要设置该值),所得到的阈值T1即为最佳阈值。
循环分割算法的优点是实现起来非常简单,并且很容易提取灰度值有明显差异的变化像素,且会省略掉灰度值相对较小变化像素。该方法满足植被扰动分类规则的阈值选取的统计分布特点,因此在该过程中被采用[15]。
(2)最大类间方差法
最大类间方差法具有抗亮度变化和对比度变化的特点,因此非常适合于实时图像处理。利用类间方差可以确定不同阈值的类别分离性能,并基于此导出自动阈值选择方法[16-17]。可通过以下步骤完成最佳阈值的获取:1)对影像进行直方图归一化;2)给定像素灰度值t=1, ···, 254 ,并利用t将影像划分为目标C0和背景C1;3)计算目标C0部分比例w0、背景C1部分比例w1、目标C0均值 µ0、背景C1均值 µ1和全图总均值 µ;4)计算图像阈值g;5)将阈值g反变换至原影像值域,以完成影像值域确定。上述步骤涉及式(2)
式中n和m表示影像的行列像素数;N为灰度级;p(i)=f(i)/(nm) 表示灰度值为i的频率;f(i)表示灰度值为i的频数,i表示随机取值。
Otsu 在1979 年提出的最大类间方差法(又称大津方法)被认为是目前自动阈值选择的最佳方法[18-19]。这类算法是面向均匀性的算法,所得到二值图像比较均匀且目标性状较好。该方法在本文中的山体影像阈值自动选择中被采用。
2.2 滑坡预选区提取
基于光学影像的多波段数据,基于波段计算提取两幅光学影像的归一化植被指数(Normalized Difference Vegetation Index,NDVI)影像,如式(3)
式中N1和N2表示两幅前、后时相光学影像对应的NDVI 影像;Bnir表示近红外波段;Bred表示红波段。
基于获取得到的两幅时相的NDVI 影像,进行基于像素的变化检测,并设定一个扰动变化参数I,如式(4)
式中I表示植被扰动变化指数,它主要反映了两幅光学影像的植被变化情况。比如,对于植被覆盖越茂盛的地区,其NDVI 值越大,但当该区域发生了滑坡,此时植被势必会遭到滑坡破坏而裸漏出其植被下覆盖的土层,这时后一时相的NDVI 值相较于前一时相则会明显降低,此时I值较大。若未发生滑坡,由于两幅光学影像月份一致,植被覆盖情况相差不大,所以两幅影像的NDVI 值也变化不大,此时I值较小。利用此特点可以排除I值较小的区域,以降低非滑坡像素的干扰,再基于Behling 方法[20-21]中的植被扰动分类规则(分割阈值由循环分割算法自动设定)对整个区域进行分类,分类方式如表1 所示。

表1 Behling 方法中植被扰动分类规则Tab.1 Classification rules of vegetation disturbance in Behling method
依据表1 的分类规则,将整个研究区分为10 类(表1 中的9 类加上I值较小的1 类),将同一类别用相同数字表示,生成研究区分类图。对分类图进行一些必要的处理工作可以改善识别提取的可靠性和合理性,使用滤波矩阵对图像进行去除“毛刺”、填补“空洞”或“凹陷”、删除“斑点”等一系列处理,生成去除噪声干扰的分类图[22]。I值较小的区域(0 类)不在滑坡预选区的考虑范围,剩下的9 类结果结合目视分析,选定其中很准确表达滑坡分布的类别,并将其作为滑坡预选区。
2.3 滑坡自动精细识别
在确定了滑坡预选区之后,一些影响滑坡选取精度的误判区域也应予以剔除,如后时相中存在的一些低NDVI 区域(道路、山体阴影)等。为了去除这些区域的影响,以提高滑坡识别精度,可以根据这些地物的几何特征和光谱特征,借助形态学、山体阴影阈值等对这些地物进行识别然后去除。
基于MATLAB 软件,将滑坡预选区内像素定义为1,其它像素定义为0,生成滑坡预选区二值图像。基于山体阴影网格数据设定阈值(分割阈值由最大类间方差法自动设定)去除山体阴影,并将二值图像中对应位置像素值设为0 值。基于二值图像生成每个滑坡预选区的陶粒并提取滑坡边界线,然后计算每个陶粒对象的圆度和伸长率并设定实验阈值以剔除道路。道路的圆度一般较低,而伸长率较大。
圆度指的是正比于多边形的面积与多边形最长直径平方的比率,圆的圆度为1,正方形的圆度为4/π,圆度M的计算公式为
式中A为陶粒对象的面积;Pmax表示陶粒对象的最小外接矩形的长轴长。
伸长率指的是陶粒对象的最小外接矩形的长轴与短轴的长度比率,正方形和圆形的伸长率为1,矩形和椭圆的伸长率大于1,伸长率E为
式中Pmin表示陶粒对象的最小外接矩形的短轴长。
滑坡区域一般具有一定的坡度,故设定坡度阈值,基于坡度网格数据,计算每个陶粒对象的中心像素的坡度值,若大于坡度阈值则认为是滑坡对象,否则认为是非滑坡对象,至此完成所有陶粒对象的筛选工作。
将最后保留的陶粒对象的边界线叠加至后一时相光学影像上,以完成最终的滑坡提取与专题图的制作。
3 结果与分析
3.1 实验参数设置
依据以下具体步骤进行研究区的滑坡自动识别:
1)基于两幅不同时相的Planet 光学卫星影像,依次计算生成每幅影像的NDVI 图,见图6(a)和图6(b)。

图6 滑坡识别中间过程图Fig.6 Intermediate Process Diagram of Landslide Identification
2)基于两幅NDVI 影像计算植被扰动参数I,见图6(c)。
3)依据统计分析方法确定Behling 方法中的植被扰动分类规则中分类阈值(见表1),基于Behling方法中的分类规则将研究区共分为10 种类型,其使用数值0~9 表示,生成的分类图见图6(d)。
4)设定7×7 窗口,设置滤波矩阵,对分类图进行滤波处理以减少噪声干扰。通过多次对比实验,对滤波后图像进行处理分析,最终确定将类别值为1、2、7、9 共4 类区域选取为滑坡预选区,见图6(e)。
5)滑坡预选区选定之后,引起滑坡误判的因素主要是道路与山体阴影区域,通过程序提取滑坡预选区的陶粒对象及其对应边界,继而计算每个陶粒对象的圆度和伸长率,圆度和伸长率计算结果见图6(f)和图6(g),设定0.19<圆度<0.7、1<伸长率<3.5 的形态约束定为非道路对象,将不在范围内的陶粒对象剔除从而消除道路影响。山体阴影分割阈值由最大类间方差法自动设定,认为像素灰度值低于91 的部分为山体阴影区域。
6)最后基于坡度数据,设定陶粒对象的质心像素坡度值大于30°的为滑坡对象。至此完成滑坡的精细自动识别过程,见图6(h)。
对比光学影像图与图6(e),可以看出预选滑坡陶粒中大部分为道路与山体阴影区域,需要对每个陶粒进行可表示其形态学特征的圆度和伸长率的计算,以剔除道路影响,然后再根据地形计算剔除山体阴影影响,又因为滑坡区域一般具有一定的坡度,所以通过设置陶粒中心的坡度阈值以进一步实现滑坡的精确识别,图6(h)中的白线围成的区域即为自动识别的滑坡区域。
3.2 结果验证与分析
为了验证自动滑坡识别结果的准确性,由于研究区范围不大,故针对整个研究区进行了专家目视解译工作,基于两幅不同时相影像进行目视解译,并结合坡度阈值最终生成了人工目视解译的滑坡提取结果。将目视解译的结果作为正确识别的标准,并将本文的自动识别结果与人工目视解译结果进行绝对验证,使用与Behling 方法相同的检测指标,以评估本文方法的有效性和准确性。经过统计,基于2021 年和2022 年两幅时相光学影像,研究区内目视解译获得的滑坡个数为26 个,本文方法自动识别的滑坡个数为29 个,其中重合的滑坡个数为24 个,图7 为研究区的两种方法的滑坡识别结果,图8 为本文识别的部分滑坡区域效果展示。

图7 两种方法的滑坡识别结果Fig.7 Landslide identification results of the two methods

图8 滑坡识别效果示例Fig.8 Example of landslide identification effect
通过将本文的自动识别结果与目视解译结果进行对比,可以看出,本文的自动识别方法可以很好的剔除道路和山体阴影的影响,且能够很好的提取滑坡边界,相比人工解译,工作时长大幅度缩短。
以目视解译结果为正确识别的标准,采用Behling 方法中的检测率(Detection Percentage,DP)、质量百分比(Quality Percentage,QP)、错分误差(Commission Error,CE)三个监测指标对本文方法进行精度评估[23-25],三个指标的公式如下
式中 TP 为正确检测到的滑坡;FN 为漏检的滑坡;FP 为误检的滑坡。
表2 展示了本文方法的检测信息,可以看出本文方法在整个研究区的滑坡检测率达到了92.31%,质量百分比为82.76%,错分误差仅为11.11%,进一步证明了本文方法的有效性和准确性。

表2 本文滑坡检测方法的检测指标计算Tab.2 Detection index calculation of landslide detection method in this paper
分析本文检测方法与目视解译的错分区域共有3 个,通过对比分析,发现3 个误报滑坡均是由于噪声影响,由于原始影像提取的NDVI 需要进行填补空洞而将部分零星噪声组合形成了滑坡预选区,从而导致最终的误判;而未检测到的漏检滑坡有2 个,均是由于DEM 误差导致,由于所使用的DEM 分辨率为12.5 m,在重采样到3 m 的过程中导致生成的坡度存在误差,致使提取的陶粒区域质心坡度小于30°而最终被剔除。
为进一步证明本文方法的有效性与泛化能力,将本论文方法直接应用于四川成都都江堰市的中部某块区域,四川省作为我国地质灾害频繁地区之一,历史地灾分布密集,该方法的有效应用将有利于该地区的实时滑坡检测工作。选取该区域两幅时间分别为2020 年8 月25 日和2021 年8 月3 日的3 m 高分辨率Planet 数据,整个研究区像素尺寸为6 870 像素×6 794 像素,面积约420.07 km2,图9 是本文方法的整个研究区滑坡识别结果,图10 是部分滑坡识别结果展示。
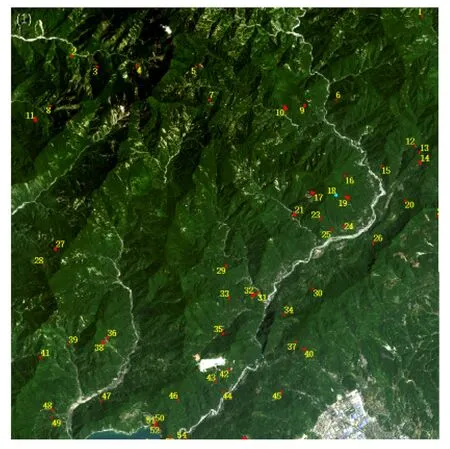
图9 整个研究区滑坡识别结果Fig.9 Landslide identification results for the entire study area

图10 滑坡识别结果Fig.10 Landslide Identification Results
该区域本文方法检测出滑坡共计55 个,目视解译的滑坡个数为49 个,重合的滑坡个数为44 个。同样与目视解译结果对比,对检测结果进行精度评估,经过计算得TP、FN、FP、DP、QP、CE 分别为45、4、6、91.84%、81.82%、11.76%。可以看出滑坡检测准确率仍达到90%以上,错分误差仅为11.76%,我国南北地域地形地貌差异明显,通过对南北地域进行方法实验,证明了本文方法的有效性和泛化能力。
4 结束语
基于遥感影像的变化检测在灾害监测领域发挥了重要作用,利用遥感影像进行变化检测实现的滑坡自动识别有着非接触、远距离、大范围的监测优势,它较之传统的地质勘察手段克服了天气,区域等环境因素,为研究滑坡灾害提供了新的途径。通过计算机技术实现变化检测技术在滑坡自动识别领域的应用,充分利用了计算机的智能、高效的数据处理能力,相较于影像的人工判读大幅度提升了工作效率。
本文以北京市门头沟区西部某块历史地质灾害分布较为密集的区域为研究区,采用两幅3 m 高分辨率光学影像,基于变化检测技术、自动阈值选取算法和形态学技术对该研究区进行滑坡的实时自动识别,并为了验证该方法的泛化能力,对都江堰市中部区域进行本文方法的应用,得出以下结论:
1)基于两幅光学影像的NDVI 变化检测技术,提取研究区的坡度、山体影像、圆度、伸长率等参数,采用自动阈值选取算法可实现研究区的滑坡自动快速识别,且相较于人工判读具有高效性和智能化的显著优势。
2)基于滑坡自动识别技术,以目视判读结果为正确标准,得出本文方法在门头沟区整个研究区的滑坡检测率达到了92.31%,质量百分比为82.76%,错分误差仅仅为11.11%,证明了本文方法的有效性和准确性。基于本文方法在都江堰市的应用,滑坡检测准确率仍达到90%以上,错分误差仅为11.76%,进一步证明了本文方法的有效性和泛化能力。
3)本文采用了两幅仅仅间隔一年时间的光学影像进行的滑坡识别,其检测结果更具实时性,自动阈值选取算法的使用避免了识别过程中的一些人为干预,使得滑坡识别更加智能高效,滑坡的自动识别是地灾风险评估的重要前提工作,它不仅大幅度减轻了地灾风险识别的工作量,而且大部分识别结果均具有可信度,该技术可以很大幅度提升滑坡自动识别的效率,是一条切实可行和十分有效的途径。
