基于差分自回归移动平均模型、长短期记忆网络模型及相关模型的无人机俯仰角预测
2024-03-22严启华罗亮陈振宇张敏李书龙
严启华, 罗亮, 陈振宇, 张敏, 李书龙
(1.西南科技大学信息工程学院, 绵阳 621010; 2.清华四川互联网能源研究院能源大数据研究所, 成都 610200; 3.西南科技大学计算机科学与技术学院, 绵阳 621010)
科学预测飞机故障率可以对航空维修进行科学决策[1-2],是提高维修保障能力不可缺少的重要条件,对于提高航空维修保障工作的预见性、对策性和科学性,提高航空装备的完善和利用水平,具有十分重要的作用[3]。无人机故障包含“软故障”和“硬故障”[4],软故障指系统发生的缓慢变化,如控制系统参数变化或电路偏置漂移等[5-6]。硬故障指飞机突然发生某部分损坏或完全停止工作,这种故障容易识别[7]。
通过对无人机数据的分析,可以及早发现无人机可能出现的故障,如电池电量不足、电机异常、传感器故障等。这有助于在故障加重之前采取预防措施,避免无人机在飞行中出现事故或损坏。无人机在飞行过程中还可能面临各种风险,如碰撞、失控、坠毁等。通过分析无人机故障数据并做出预测,可以及早采取措施,避免潜在的安全事故发生,保护人员和财产的安全。
Yang等[8]利用真实的无人机飞行数据,提出了一种完整的基于信息的主成分分析(complete-information-based principal component analysis,CIPCA)-反向传播神经网络(back-propagation neural network,BPNN)故障预测方法,可以在无人机故障发生前9 s左右准确预测故障。杜金等[9]开发了一个基于YOLOv5s算法的模型,旨在实现对风机叶片故障的快速检测和识别,同时兼顾了较高的准确率。Wang等[10]提出了一种半监督聚类技术来对采样点进行自动模式识别,大大提高了在历史飞行数据中添加精确标签的效率和准确性。Yang等[11]提出了一种基于时间戳片和多可分卷积神经网络(time step-multi scale convolutional neural network,TS-MSCNN)的无人机异常状态检测方法,准确率高达97.99%。他们还提出了一种基于无人机环内软件仿真环境的时间线建模(time line modeling,TLM)方法来获取和处理无人机的机载故障日志,GPS分类准确率最高达到85.63%。Masalimov等[12]提出了一种新颖的神经网络结构CompactNeuroUAV模型,实现了常见故障或故障前状态检测,准确率为93.36%。Cabahug等[13]将振动数据与K-means聚类算法结合,无人机飞行中故障检测准确度在89%~95%。Park等[14]提出了一种基于无监督学习的堆叠自编码器的故障检测模型。利用无人机安全状态数据对自编码器进行训练,并对其重构损失进行检测,以区分安全状态和故障状态,其准确率最高达到93.21%。Azarakhsh[15]提出了一种使用递归最小二乘法来检测飞机行为异常的实时方法,准确率为86.36%。
黄莉莉等[16]提出基于T-S(Takagi-Sugeno)模糊故障树的故障诊断方法,解决了实际仪表着陆系统下滑信标(glidepath beacon, GP)故障时无法快速定位故障点的难题。王康等[17]提出了基于贝叶斯网络的故障诊断方法,解决了飞机驾驶舱手轮故障诊断的不确定性和复杂性,为机务人员迅速做出判断和高效维修提供有力支持。何永春等[18]提出一种基于注意力机制的多尺度仪表检测方法,增强了特征的表达能力。王欣等[19]在LSTM中引入了注意力机制,提升了发动机寿命预测模型的精度。吴昉等[20]针对多类型、多特征的缺陷检测问题,提出一种新颖的并行残差注意力模块,可以自适应地选择缺陷特征。武东辉等[21]将注意力机制添加在时空网络模型中,解决了单一神经网络时序信息利用匮乏、局部信息把握不全等问题。
对无人机故障俯仰角数据集进行预测分析,可以及早检测出无人机可能出现的故障情况。如果预测模型能够准确地识别无人机俯仰角异常的模式或趋势,就可以在故障发生之前采取相应的措施,避免飞行事故的发生。通常,对无人机试飞故障的研究大多集中在事故分析和预警管理分析方面[22-23],且研究对象较为模糊。首先是数据获取难度较大,预测无人机故障需要大量的数据支持,包括无人机的传感器数据、飞行数据等。但是,获取这些数据需要安装相应的传感器和设备,这可能会增加无人机的重量和复杂度,影响无人机的飞行性能和安全性。其次,无人机试飞具有较高的复杂性和不确定性,无人机试飞时可能会受到环境、风力、天气等多种因素的影响,这些因素可能会使得无人机的飞行数据和传感器数据变得复杂和不确定,从而增加预测故障的难度。
预测俯仰角故障数据,一种情况是可以验证和确认已知故障类型的存在。将预测故障数据并与实际观测数据进行比对,可以验证和确认故障类型的准确性;另一种情况是通过预测俯仰角故障数据,可以提供关于故障程度和严重性的信息。此外,预测俯仰角故障数据可为故障校正和应对提供指导。预测故障数据可帮助判断是否需要进行实时调整或干预控制系统以纠正俯仰角异常,这对于保持飞行稳定性和避免潜在风险至关重要。
现以确定故障类型为出发点,添加并调整注意力机制的层级结构,在数据量有限的情况下搭建长短期记忆网络(long short term memory,LSTM)、差分自回归移动平均(autoregressive integrated moving average,ARIMA)、注意力机制+LSTM 3个故障数据预测模型,利用该类数据于模型方面进行创新融合,针对模型预测过程中梯度爆炸和梯度消失导致预测准确率下降的问题,在LSTM模型中加入了注意力机制,以实现预测数据尽量贴合真实数据的目的。将ARIMA和LSTM作为对比模型,以验证模型的优越性。以期对后续的无人机故障类型验证、实时调整或干预控制等方面提供可靠结果。
1 数据来源及处理
所使用的实验数据源自卡内基梅隆大学ALFA公开数据集[24-25]。目前,该数据集包括47次自主飞行的处理数据,其中包括23次突然的全发动机故障场景及其另外7个不同种类的执行器故障场景共计24次。在正常情况下,总共飞行了66 min,而在故障发生后的飞行时间为13 min。此外,还有数十个故障场景下的全自动、自动驾驶辅助和手动飞行的数小时原始数据[25]。如表1所示。

表1 飞行实验数据
选取发动机全功率损失故障类型,在此状态下预测无人机的实际俯仰角状态。首先将时间序列的时间戳变换成常用的时刻,然后选取表中80%数据作为训练集(前2 000条),20%数据作为测试集(后520条)。部分数据如表2所示。

表2 无人机试飞部分俯仰角数据
俯仰角表征如图1所示,plt.c为命令输入值,plt.m为实际测量值。
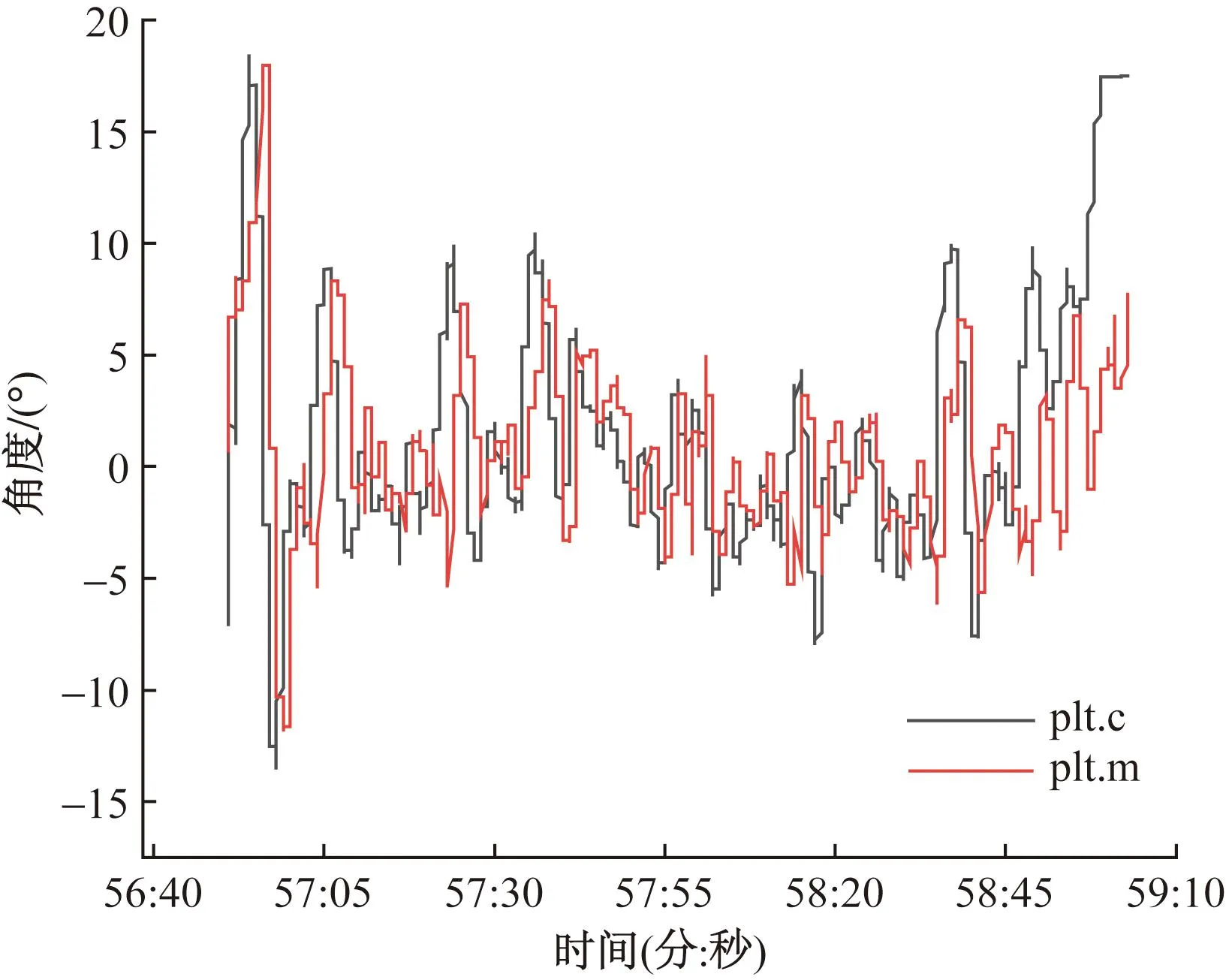
图1 在引擎异常情况下无人机俯仰角表征
2 3种模型预测方法
2.1 ARIMA模型
ARIMA模型又称整合移动平均自回归模型,是时间序列预测办法之一[26-27]。此模型可以应对非平稳时间序列的建模问题,且当前时刻的值可以由过去若干时刻的值、误差来预测,所以搭建ARIMA模型对试飞俯仰角数据进行分析。
ARIMA的搭建基本分为3个部分:序列平稳化、模型识别、模型检验。试飞数据俯仰角ARIMA模型详细流程图搭建如图2所示。
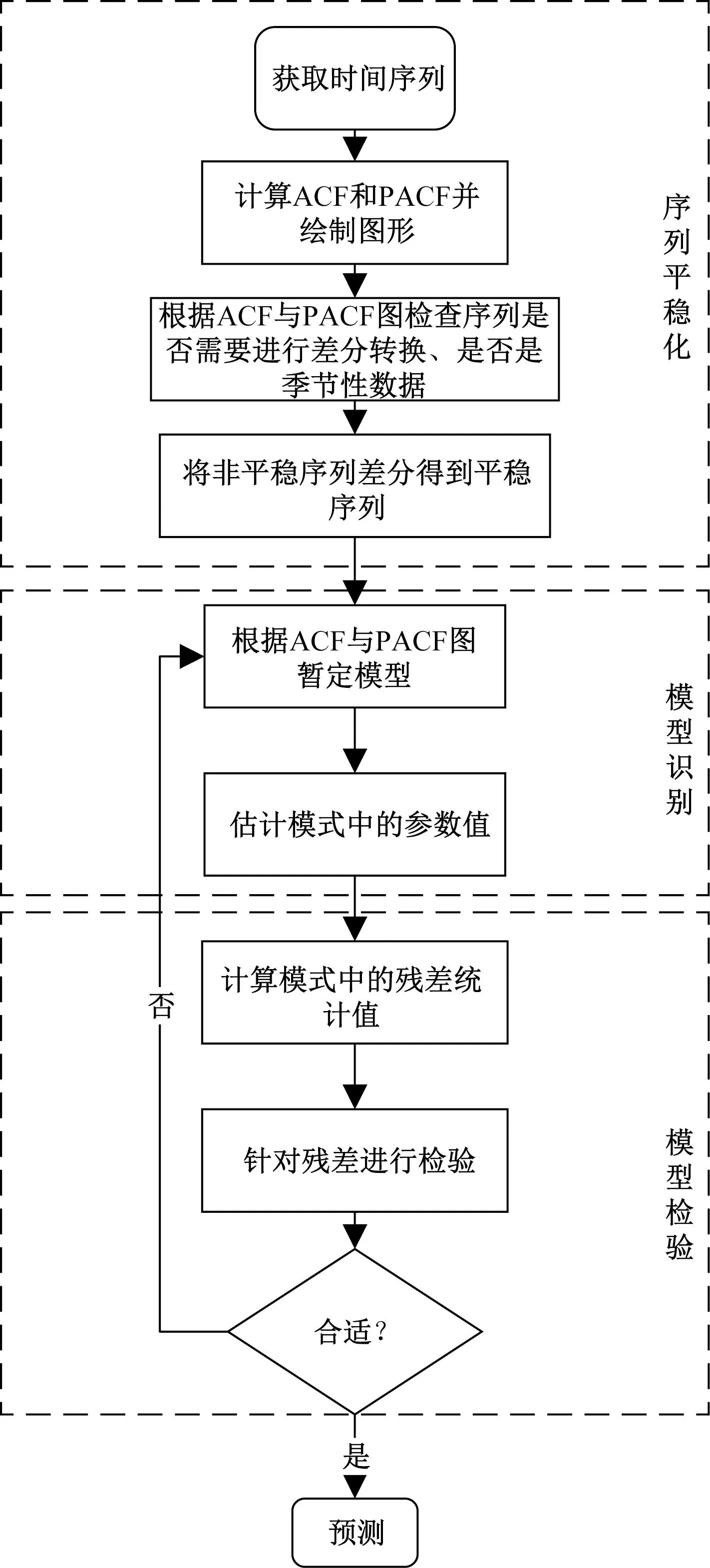
图2 ARIMA模型流程图
ARIMA(p,d,q)模型中,AR表示自回归(autoregressive),其中p表示自回归项的数量;MA表示滑动平均(moving average),其中q表示滑动平均项的数量;d表示使时间序列成为平稳序列而进行的差分操作的次数(阶数)。可表示为

(1)
式(1)中:L为滞后算子(lag operator);Li为滞后操作符;Xt为时间序列的观测值;Φi为自回归系数;θi为移动平均系数;εt为白噪声误差;d∈Z,d>0。
当时间序列消除了非平稳时间序列的局部水平和趋势,某些部分与其他部分相似,时间序列出现一定的同质性。之后进行差分处理,将其转化为平稳时间序列。转化后的序列称为齐次非平稳时间序列,差分次数即为齐次阶数[28]。
对于差分算子∇,有
∇2yt=∇(yt-yt-1)=yt-2yt-1+yt-2
(2)
式(2)中:yt为差分的时间序列。对延迟算子B,有
yt-p=Bpyt,∀p≥1
(3)
得
∇k=(1-B)k
(4)
设有d阶其次非平稳时间序列,那么∇dyt是平稳时间序列,将其设为ARMA(p,q)模型,即
λ(B)(∇dyt)=θ(B)εt
(5)
式(5)中:λ(B)=1-λ1B-λ2B2-…-λpBp;θ(B)=1-θ1B-θ2B2-…-θpBp。
2.2 LSTM模型+LSTM及注意力机制
2.2.1 注意力机制
注意力机制(attention mechanism)是一种在人工神经网络中常用的技术,用于处理序列数据。将输入序列中相关信息选择性地聚焦,以便网络能够在处理过程中更加关注重要的部分,从而提高模型的性能[29]。其基本思想是模拟人类在处理信息时的注意力分配过程[30],允许模型根据输入序列中不同位置的重要性来动态地调整注意力权重[31],从而使模型能够在处理过程中更加关注一些重要的位置或词汇。对无人机俯仰角故障数据的处理正是运用了这一特点和思想。
在注意力机制中,有如下3个关键的要素。
查询(Query):用于表示当前需要关注的位置或词汇,通常由网络的中间层输出作为查询输入。
键(Key):用于表示输入序列中的位置或词汇,通常由网络的输入层输出作为键输入。
值(Value):用于表示输入序列中的位置或词汇的特征,通常由网络的输入层输出作为值输入。
通过计算查询与键之间的相似度,并将其用作权重,从而在值上计算加权和[32]。这样,模型可以根据查询的重要性来聚焦于键和值的不同部分,从而在不同位置上分配不同的注意力权重。这使得模型可以根据任务的需要动态地调整对输入序列的关注度,从而更好地处理序列数据。在attention计算过程如图3所示。
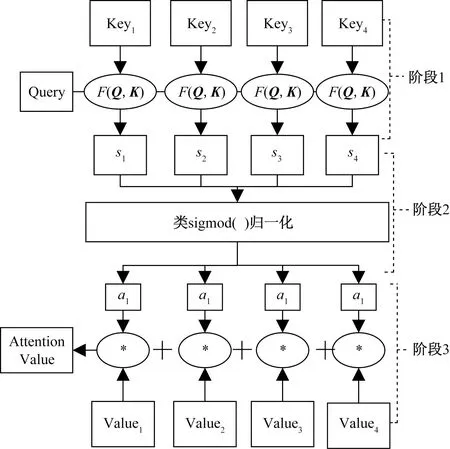
图3 Attention计算过程
具体过程如下。
步骤1输入序列编码。输入序列(如文本、图像等)经过编码器(Encoder)处理,生成一组特征向量(Key)。这些特征向量可以通过不同的方式生成,如循环神经网络(RNN)、卷积神经网络(CNN)等。
步骤2生成查询(Query)、键(F)和值(Value)。从编码后的特征向量中生成查询、键和值向量。通常可以通过对特征向量进行线性映射得到查询、键和值向量,键F(Q,K)中Q为query,K为key。
步骤3计算注意力权重(s)[33]。以计算的方式,查询向量和键向量之间的相似度,得到一组注意力权重。常用的计算相似度的方法有点积(dot product)、缩放点积(scaled dot product)、加性注意力(additive attention)等。
步骤4权重归一化。对注意力权重进行归一化,使得权重之和等于1,以确保注意力的有效性。
步骤5加权(a)求和。将归一化后的注意力权重与对应位置的值向量相乘并求和,得到最终的上下文向量。
步骤6输出处理。将上下文向量用于后续的任务,如生成文本、分类、回归等。
充分利用纯注意力机制的优势,即可以进一步优化纯注意力机制,显著提高预测性能[34]。
2.2.2 LSTM模型
长短时记忆网络(LSTM)模型,其本质是一种循环神经网络(recurrent neural network,RNN)。LSTM模型在RNN模型的基础上通过增加门限(gates)来解决RNN短期记忆的问题,使得循环神经网络能够真正有效地利用长距离的时序信息。
在传统的RNN中,训练算法使用的是BPTT,当时间跨度较大,需要回传的残差会指数下降,导致神经网络权重更新速度变慢,无法展现循环神经网络(RNN)具备的长期记忆效果。所以引入一个存储单元,用于存储网络中的记忆信息。并帮助网络捕捉长期依赖关系,确保网络在处理长时间序列时能够有效地保留和使用过去的信息[35],因此LSTM模型被提出,利用其优势搭建LSTM模型,LSTM细节图如图4所示。
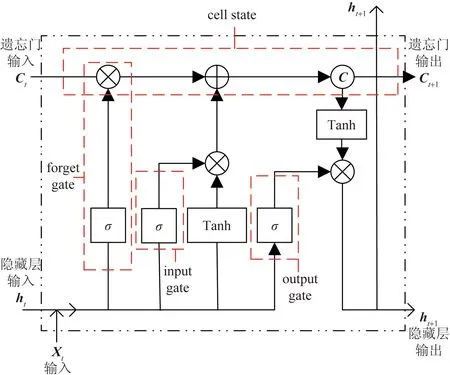
图4 LSTM细节图
(1)输入门(input gate):通过一个Sigmoid激活函数来控制是否更新细胞状态(cell state)。Sigmoid函数的输出范围在0~1,表示更新的权重。输入门根据当前输入和上一个时刻的隐藏状态来决定是否更新细胞状态。
(2)遗忘门(forget gate):通过一个Sigmoid激活函数来控制是否遗忘之前的细胞状态。遗忘门根据当前输入和上一个时刻的隐藏状态来决定哪些信息应该被遗忘,哪些应该被保留。
(3)输出门(output gate):通过一个Sigmoid激活函数来控制是否输出细胞状态。输出门根据当前输入和上一个时刻的隐藏状态来决定输出的细胞状态。
(4)细胞状态(cell state):用来存储网络中的记忆信息,可以在不同时间步之间传递。细胞状态的更新由输入门、遗忘门和输出门共同控制。
(5)隐藏状态(hidden state):作为LSTM的输出,也可以作为下一个时间步的输入。隐藏状态通过输出门和细胞状态进行更新。
2.2.3 模型融合
在搭建LSTM神经网络模型的基础上,通过添加注意力层,计算注意力权重来调整LSTM模型的输出,从而提升模型预测的精度。注意力层即是在每个时间步骤上,根据当前输入和前一个隐藏状态计算出一个向量表示,并利用该向量与所有历史隐藏状态进行相似性比较。然后,将相似性得分转换成概率分布,并使用该分布加权平均所有历史隐藏状态得到最终的上下文向量,如2.2.1节所介绍。Attention-LSTM框架如图5所示,注意力层的计算和搭建过程如下。
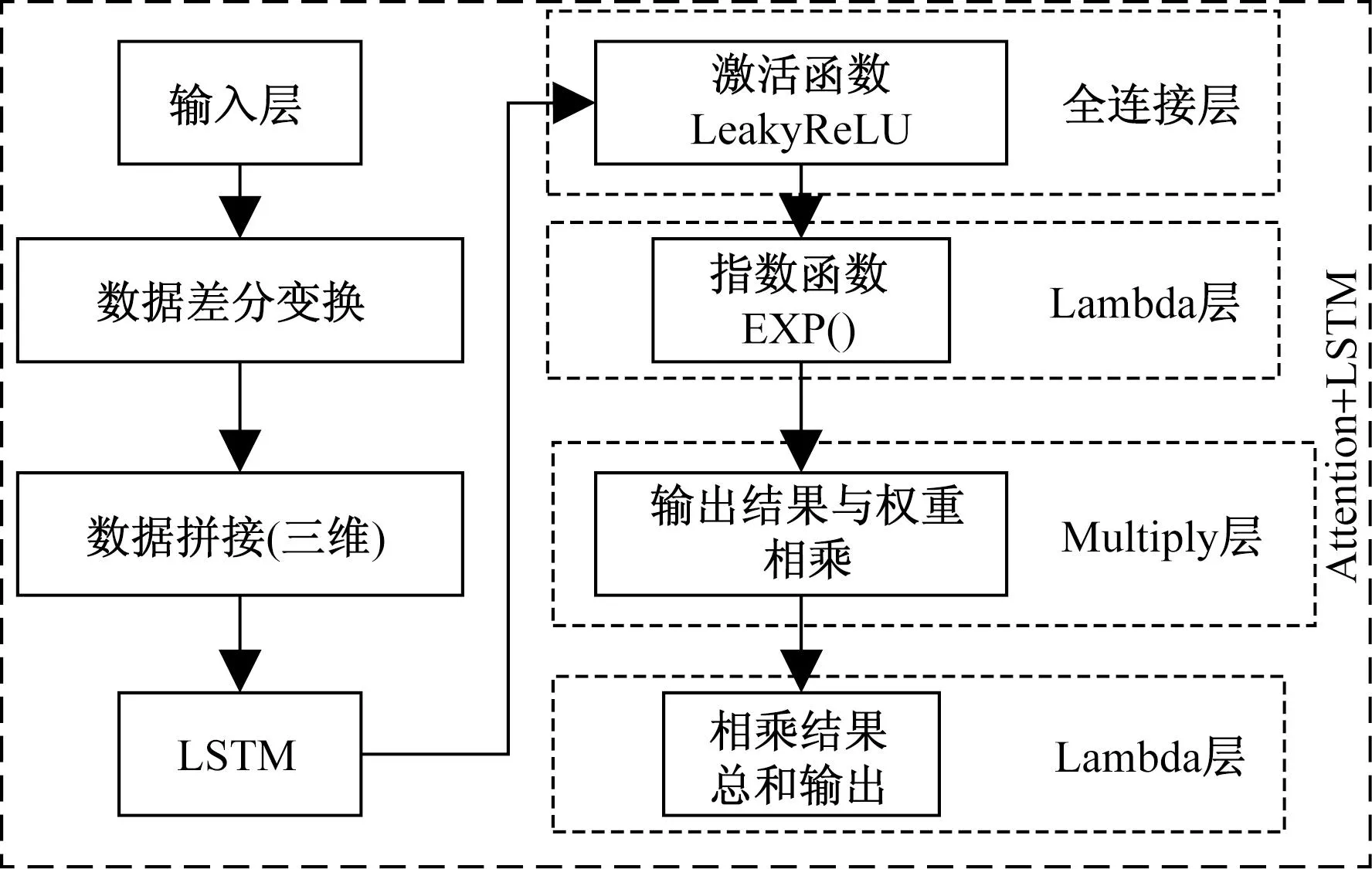
图5 Attension-LSTM模型结构
首先输入数据并区分数据对,便于模型训练。将数据拼接升为三维数据输入LSTM模型中,其形状为N×1×1。
通过一个Dense层将LSTM模型的输出降维,使用LeakyReLU激活函数,限制输出范围。
通过Lambda层将输出转换为注意力权重,使用relu函数,转换输出数据。
通过Multiply层将LSTM模型的输出和注意力权重相乘,得到加权后的输出。
最后通过Lambda层对加权后的输出求和,得到一个新的特征向量,作为最终的输出。
3 模型预测及结果
3.1 评价指标
选取3种主要的回归算法评价指标对模型效果进行评价[36],分别为平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)、平均绝对百分比误差(mean absolute percentage error,MAPE),其计算公式如下。

(6)
平均绝对误差(MAE):预测值与真实值之间绝对误差的平均值,用于衡量预测值与真实值之间的平均偏差。MAE 的解释性很直观,它表示模型的平均预测误差,值越小越好。

(7)
均方根误差(RMSE):均方误差的平方根,用于衡量预测值与真实值之间的平均偏差,且具有与原始单位相同的量纲。因为RMSE对预测误差的较大值更加敏感,误差平方后会放大,从而能够更好地评估模型的预测准确性。

(8)
平均绝对百分比误差(MAPE):其值越小,表示模型的预测性能越好,越接近0表示模型的预测非常准确。MAPE具有百分比的形式,可以直观地了解模型在相对误差方面的表现。
3.2 ARIMA模型
根据俯仰角数据的数据特征,搭建与其相适应的ARIMA模型:p=2,d=1,q=2。预测效果图如图6所示。

图6 ARIMA预测效果图
预测结果:MAE=0.35,RMSE=0.73,MAPE=23.80%。
可以看出,由于无人机试飞数据的小样本性,预测结果中存在梯度爆炸[37]问题,ARIMA模型预测该种类型数据效果不是很理想。
3.3 LSTM模型及注意力机制+LSTM模型
搭建LSTM模型进行预测,预测效果如图7所示。

图7 LSTM预测效果图
预测结果:MAE=0.49,RMSE=0.74,MAPE=45.20%。
可以看出,LSTM模型对无人机俯仰角试飞数据梯度预测比较准确,但是精确度相比于ARIMA模型MAE下降了0.14,RMSE下降了0.01,MAPE下降了21.4%。
在LSTM模型中添加注意力机制以改善模型数据输入的权重,预测效果如图8所示。

图8 注意力机制LSTM预测效果图
在LSTM模型中添加注意力机制后,预测结果与原数据基本吻合。
预测结果:MAE=0.17,RMSE=0.53,MAPE=18.93%。
针对无人机俯仰角试飞数据,相比于传统的ARIMA、LSTM模型,在LSTM中添加注意力机制有一个更加优异的表现,如表3所示。
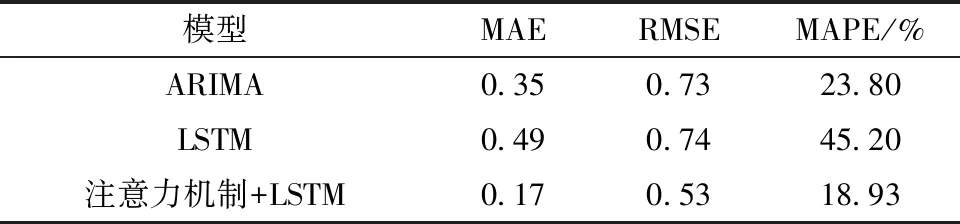
表3 无人机试飞数据俯仰角预测结果
传统的LSTM模型在处理时间序列数据时可能会面临梯度消失或梯度爆炸等问题,导致难以捕捉依赖关系。而引入注意力机制后,通过对序列中不同位置的注意力权重进行建模,使模型能够更加灵活地关注到不同位置的信息,从而更好地处理时间序列数据;当模型输入数据的权重得到不同分配、在不同的时间步或位置上集中注意力时,就会提高模型的建模能力和预测准确性;同时生成的对不同位置的注意力权重,使模型的预测结果更具解释性和可解释性,在实际应用中更容易解释和理解模型的预测结果。
4 结论
搭建ARIMA模型和LSTM模型用于无人机俯仰角试飞数据的预测,并在LSTM模型中添加了注意力机制以提升其预测准确性。利用预测结果来判断是否需要实时调整或干预控制系统,以便纠正俯仰角异常,或者将预测结果应用于故障验证等方面。实验结果表明添加了注意力机制的LSTM模型预测效果要优于ARIMA模型和一般的LSTM模型。对于ARIMA模型,还可以通过引入一些创新性元素,如非线性趋势、异方差性等,来改进模型的预测能力;同时还可以将多个ARIMA模型进行集成,例如通过模型平均、模型堆叠等方式,利用各个模型的优点,降低模型的偏差和方差,从而提高预测分析的准确性。
