改进的双流多模态信息融合坐姿识别方法
2024-03-22袁陆陶庆刘景轩裴浩
袁陆, 陶庆, 刘景轩, 裴浩
(新疆大学机械工程学院, 乌鲁木齐 830017)
物联网和人工智能的发展促进了智能教育教学和智能办公的普遍发展,智能教育教学不仅可以预防和控制课堂相关的健康问题(例如,肌肉骨骼疾病、脊柱侧弯、颈椎病、近视、心血管疾病等),同时还能减缓工作者或者学生们的心理压力,提高工作学习效率。如今,坐姿识别系统可以利用传感技术以及机器视觉等进行开发应用。
目前可穿戴设备[1-3]、压力传感器[4-6]、RGB或RGB-D相机[7-9]是坐姿识别常用的技术。Luna-Perejón等[4]通过放置在座椅上的力敏电阻器达到了识别6种日常会损害运动系统的不正确坐姿。Jeong等[5]开发了一种嵌入传感器的智能椅子系统,可用于预防与坐姿相关的肌肉骨骼疾病的实时姿势反馈系统。Vermander等[6]提出了一种基于多层神经网络的智能分类器,用于轮椅使用者坐姿的分类。周世源[7]研究了图像处理在坐姿识别方向的应用,使用CMU优化后的Open Pose网络,选取人体关键点作为坐姿识别的依据。
可穿戴设备能够持续监测,但它需要附着在用户的皮肤或衣服上才能收集数据,因此,在现阶段可能并不实用。相比于基于传感器的方法,利用机器视觉的识别的方法具有低成本、操作便利、信息丰富、部署智能、应用更舒适等优势。
2010年微软公司推出了一款Kinect体感设备,随后很多机构和学者都基于Kinect在计算机交互界面以及人体姿态识别进行了深入研究,并取得了良好的效果。Kinect深度相机的出现,极大地简化了人体三维建模的过程,有效提高了坐姿识别的可靠性与准确性。
就现有文献研究方法而言,大多数基于计算机视觉的坐姿识别研究仅使用RGB图像作为输入进行识别,将三维世界映射到二维空间的相机将不可避免地导致信息丢失,这导致在真实场景中难以获得高精度的识别效果,这种方法存在光干扰以及识别效果不显著等问题[10]。利用Kinect SDK 2.0传感设备,获取RGB图像和深度(Depth)图像,因为RGB 图像信息和Depth图像信息具有互补特性,RGB模态提供像素色彩信息以及纹理线索,Depth模态则包含了视点距离物体的距离信息、几何和形状线索,且不受光照条件和颜色变化的影响,所以深度信息的内容对于人体坐姿状态表征是非常有可鉴性的[11]。
现使用RGB-D图像不仅可以提取RGB丰富像素特征信息,同时融入Depth图像,这能够有效克服光干扰,有效避免光照和复杂背景的影响,并改进一种混合神经网络——采用双流RGB-D图像作为双输入,将残差结构引入EfficientNetB0网络架构中,提出一种基于改进R-EfficientNet的双流RGB-D多模态信息融合的坐姿识别算法,以获得更高的识别准确性,识别的坐姿为人们日常的8类姿势。以期有效解决目前由于坐姿识别不精确导致的推广受限等问题,且识别结果有助于改进办公家具、课桌椅设计,同时也为人体工程学研究者或医疗保健专业人员的决策提供支持[12]。
1 数据采集和预处理
1.1 图像获取及预处理
由于目前没有公开的坐姿图像数据集,而且所需要的是RGB图像和Depth图像匹配对应的数据集,因此通过KinectV2传感器作为采集设备,获取坐姿RGB图像以及对应的Depth图像,采集30名学生(18名男、12名女)日常的8种坐姿数据:正确坐姿、趴着、上身左倾、上身右倾、前倾、后仰、左撑头和右撑头。将采集到的图像数据整合,形成自己的一套RGB-D坐姿数据集,在模型训练前,为了达到提高模型的准确性,实现模型的快速收敛及快速训练的目的,必须对RGB-D数据集进行预处理。由于Depth图像数据中每个像素点的灰度值代表着视点距离物体的位置信息,可以利用直方图均值化提高对比度,降低噪点数,使得更加突出人体坐姿像素,在增强整体图像对比度的同时不影响局部对比度的增强[13],从而更清晰地反映出深度信息。
由直方图可以得到灰度等级的离散概率分布函数,表达式为
(1)
根据灰度量化级数M得到各个等级的量化值为
(2)
然后对每一个F(k)重新进行等级划分:如果F(k)与G(j)最相近,就将所有原始灰度级为rk的像素转变为rj。按此规则对各个灰度等级的像素重新划分灰度级,达到均衡化的目标。接着选用核为3×3进行中值滤波操作处理[14],减少深度图像的噪声和填补部分小缺块,对比结果如图1所示。

图1 深度图像进行中值滤波操作前后对比图
1.2 图像校对
由于利用Kinect V2.0体感设备获取到RGB图像数据的分辨率大小为1 080×1 920,Depth图像数据的分辨率大小为424×512,RGB图像和Dpeth图像不仅在分辨率上存在差异,而且在包含可视范围的区域上也存在差异。因此,为了融合RGB-D图像特征,建立RGB-D数据库,需要对RGB图像数据和Depth图像数据进行图像配准校对。采用相机定标方法,将Depth坐标系中的像素点与RGB图像坐标系中的像素点进行一一校准,在后续生成RGB-D roi的过程中,获取Depth图像与RGB图像坐标点的相互映射关系。通过相机定标法[15]得到的RGB图像的本征参数矩阵为Krgb,深度图像的本征参数矩阵为Kd。RGB图像的外部参数矩阵为Rrgb和Trgb,深度图像的外部参数矩阵为Rd和Td。
RGB图像的非齐次像素坐标为Prgb=[Urgb,Vrgb,1]T,Depth图像的非齐次像素坐标为Pd=[Ud,Vd, 1]T。将Depth图像坐标映射到RGB图像坐标的旋转矩阵R和平移矩阵T,表达式分别为
(3)
(4)
旋转矩阵R和平移矩阵T通过彩色图像与深度图像本参数矩阵与其转置矩阵相乘得到。计算出Depth图像与RGB图像像素坐标点的相互映射关系,公式为
Rrgb=(RZdPd+T)/Zrgb
(5)
通过得到深度图像的坐标值Pd及其像素值Zd,以及记录距离Zrgb,得到对应于点映射的RGB图像的坐标Prgb。Kinect V2.0校准后得到的R和T为固定的常值矩阵,这便于在后续融合中将该算法处理后的图像输入改进的双流R-EfficientNet多模态信息融合的坐姿识别算法中。
1.3 数据增强
为了进一步防止模型过拟合,增强模型训练的鲁棒性及泛化能力,需要对预处理后的RGB-D训练数据集进行数据增强处理。使用Pytorch工具箱对图像在训练过程中对数据集中每一对图像进行动态缩放。并将RGB-D图像进行0.85倍的随机裁剪,裁剪后的图像需要重新插补为224×224大小的图像。随机调整RGB图像亮度、对比度、饱和度,将图像转换为张量格式,然后对张量图像进行归一化[16]。增强后的数据,将原训练集扩大3倍,得到1 952对(3 904张)RGB-D图像用于训练模型。
2 R-EfficientNet算法模型搭建
2.1 RestNet18网络模型结构
为了提高识别精度,神经网络结构的层数也在不断优化加深,但网络的加深导致梯度消失以及梯度爆炸等问题,使得该模型收敛困难,造成准确率低的问题。含有残差结构的网络模型在层间引入浅层特征,增加残差连接,能够有效地防止梯度消失和缓解模型退化问题,从而让神经网络的层次数量的增加变得更为高效,具有强大的表征力。残差结构[17]如图2所示。

x为输入;H(x)为输出;F(x)为残差
残差单元在接受输入数据之后,若一个浅层网络的精度已经达到了一个极限,那么在其之后加入多个恒等映射层,使其输出与输入相等,并且对每个层的输入加入一个x,使其得到更易于优化的残差函数,神经网络的层次能够超过先前的限制,从而提升了辨识精度。在残差块结构中有含有两层,表达式为
F(x)=W2σ(W1x)
(6)
式(6)中:σ为非线性激活函数,经过一个shortcut和第二个ReLU函数,即可得到输出结果y,即
y=f(x,{Wi}+x)
(7)
在shortcut中,对x进行Ws的线性变换处理,以实现输入和输出维数的变化,即
F=(x,{Wi})+Wsx
(8)
为保证坐姿图像分类任务的高准确率和实时性,选取网络层数适中,收敛速度快,能够平衡训练速度和网络深度的ResNet18作为第一层主干网络,在保证RGB-D特征提取能力的同时,该网络有较快的训练和推理速度,不需要过多层次的残差结构,且要求样本数据量较少,也不容易产生过拟合现象。
ResNet18的网络结构内含17个卷积层以及一个全连接层,如图3所示。
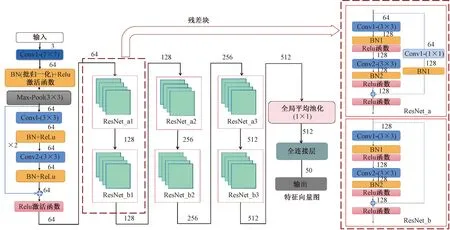
Conv为卷积操作(括号中数据为卷积核大小尺寸);BN为批量归一化操作;ResNet_a、ResNet_b为残差结构;Relu为激活函数
将224×224的三通道RGB坐姿图像数据输入到该网络中,通过ResNet18进行特征提取和降采样,得到了一个大小为N×50×8×8(N为一个mini-batch大小)的特征图,输出的特征图(feature map)维数为50,同理将Depth图像也送入ResNet18中进行第一步的特征提取,将这两个提取到的特征矩阵进行融合,组成一个新的特征矩阵X1,作为下一层网络的输入。
2.2 EfficientNet网络结构
使用EfficientNetB0基线模型作为第二步网络模型入口点,它接收一个尺寸为224×224×3的输入图像。使用EfficientNetB0的原因是由于其平衡的深度、宽度和分辨率,可以产生一个可伸缩的、精确的、易于部署的模型。目前已经有11个系列的版本,以满足各种需求[18]。
EfficientNetB0[19]网络综合了MBConv和squeeze and excitation方法,在网络模型中进行特征提取时,经过一个3×3的卷积核后,通过16个移动翻转瓶颈卷积(MBConv)模块的反复堆叠,最终添加了一个全局平均池化层和一个线性层,以整合全局空间信息并降低参数量,对每个权重在测试阶段对其进行高斯分布的采样。将各层特征映射进行平均池化获得每一层的全局信息,然后通过线性层再去与特征映射相乘,这样在反向传播的时候就能通过梯度更新学到各层的权重。其结构如图4所示。

Conv为卷积操作(后方为卷积核尺寸);MBConv为移动翻转瓶颈卷积操作;k为核参数;stride为步长;Dropout为丢弃层;p为丢弃率
MBConv结构主要添加了两个1×1卷积操作,并使用了SE层、Depwise Conv(深度可分离卷积)以及drop_connect方法来代替传统的drop方法。每个MBConv卷积块具体结构如图5所示。

Conv为卷积操作(括号中数据为卷积核尺寸);BN为批量归一化;Swish为Swish非线性激活函数;SE Module为自注意力机制模块;stride为步长;Drop_connect为丢弃层
2.3 R-EfficientNet模型架构
经过图像采集以及预处理后,将数据集送入R-EfficientNet模型中,该模型第一层搭建的是ResNet18网络架构,分别对RGB图像以及Depth图像进行第一轮特征提取,并将提取到的特征矩阵(记作X1)作为下一层的输入。第二阶段采用改进EfficientNetB0网络架构将RGB图像以及Depth图像作为双输入,进行第二轮的特征提取,输出的特征矩阵(记作X2)作为这一层的输入,随后将这两个提取到特征矩阵X1及X2(特征量为50维)进行特征融合,经过两个全连接层(FC1、FC2),FC1将200维的特征通道变为50维,FC2将FC1的50维通道数转变为输出,输出的数值为8类标签(对应着8种坐姿状态),最后将提取到的坐姿特征输入Softmax分类器计算坐姿类别并预测概率。R-EfficientNet模型架构如图6所示。

ResNet18为残差网络结构;EfficientNetB0为EfficientNet网络结构中B0类型的算法结构;Conv为卷积操作(后方数字表示特征维度);BN为批量归一化处理;ReLu为激活函数;Max-Pool为最大池化;ResNet_a、ResNet_b为两类残差结构;MBConv为移动翻转瓶颈卷积(k为核尺寸);2x、3x、4x为循环迭代次数
3 评估指标及参数设定
对于图像多分类问题,为加快模型的收敛速度,选用Adam[20]自适应学习优化算法。使用批量大小为32的Adam优化器进行训练和验证,该算法既有AdaGrad[21]擅长求解稀疏梯度,又有RMSprop[22]擅长求解非稳定问题的优势,而且其收敛速度远超SGD优化器。Adam优化器算法利用指数滑动平均来估计梯度中每个成分的一阶矩和二阶矩,从而获取每一步的更新量,并进一步提供自适应学习率,将各层次的网络由线性组合改为非线性逼近能够改善模型的预测精度。采用10-3的初始化速率,利用引入交叉熵损失函数,解决传统方法中存在的学习效率较低的问题,从而有效地提升了坐姿识别的准确度,交叉熵损失函数公式为

(9)
式(9)中:y为预期输出;α为实际输出,α=σ(z),z=Wx+b。
当验证损失函数Loss不提升时则减少学习率,每次减少学习率因子为0.2,Batch size设置为30,将数据集分割为训练集(70%)、测试集(30%),对每个R-EfficientNet网络进行了50和300个epoch的训练,从0.001的学习率开始,并使用步进衰减学习率调度器每20个周期将其降低0.5倍。对于RGB-D坐姿数据集,提出的R-EfficientNet网络模型框架的识别准确率从87.1%提高到了98.5%。本文方法流程图如图7所示。
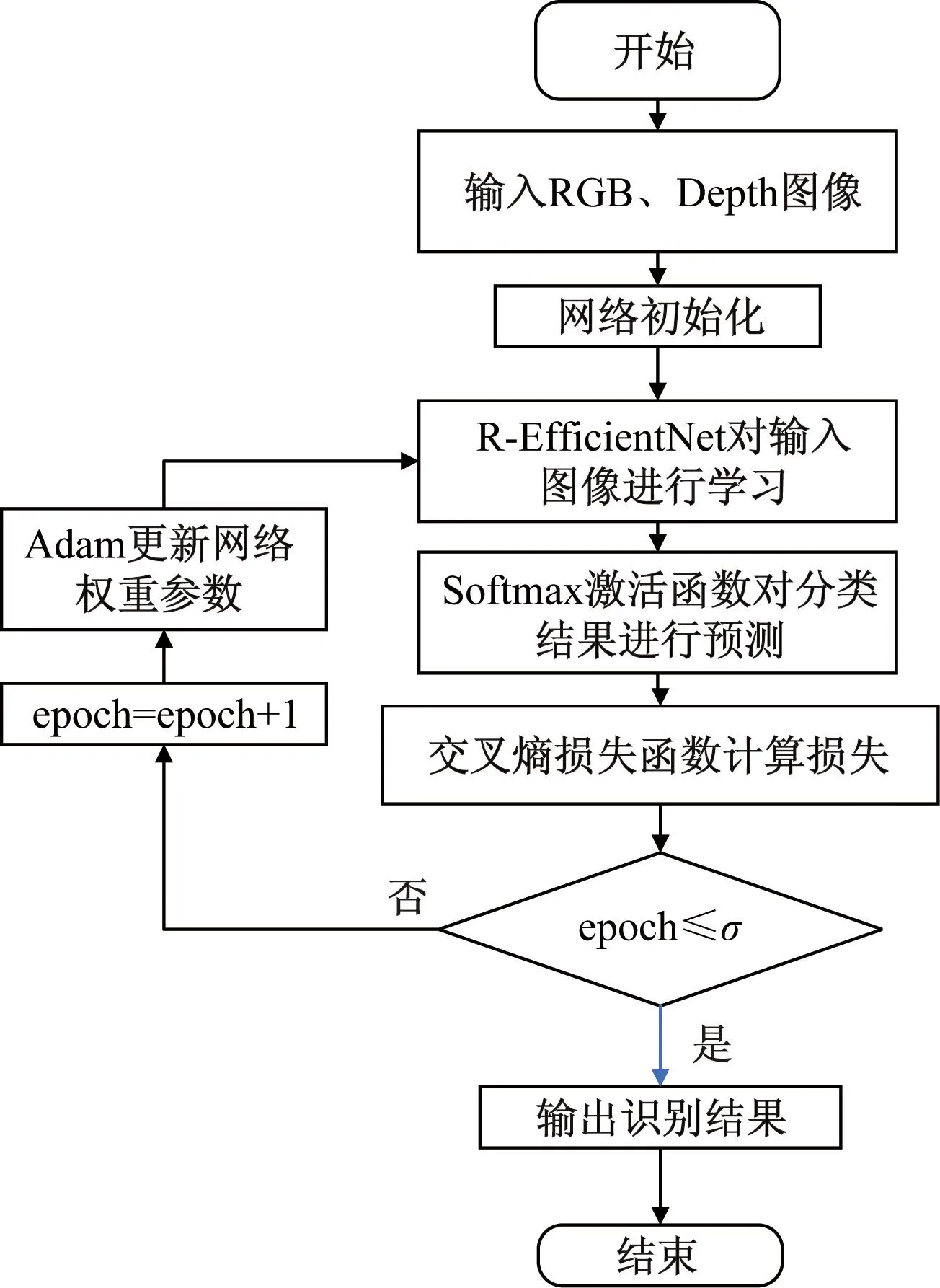
图7 R-EfficientNet方法流程图
接着对所有对比模型进行300次独立重复训练,以保证实验精度的准确性,取这300次实验结果的中位数作为最终训练结果。通过精确率(precision,P)、召回率(recall,R)、F1(F-Score)、准确率(accuracy,A)来评估模型性能,计算公式如式(10)~式(13)所示。
(10)
(11)
(12)
(13)
式中:TP为真阳性;TN为真阴性;FP为假阳性;FN为假阴性。
4 实验结果与分析
在R-EfficientNet模型训练了300次的过程中,记录模型的损失值,比较训练损失和测试损失的变化曲线,判断模型的拟合效果,如图8所示。

图8 R-EfficientNet模型训练集及测试集损失变化曲线
模型训练结果显示,loss仅为0.015%。同时表明R-EfficientNet模型具有更好的收敛性,分类结果如表1所示,识别均值平均精度(mean average precision, mAP)达到了98.5%。由于利用了RGB图像提供丰富的像素信息基础上,加入了Depth图像的位置距离信息,扩充了提取的特征内容,降低了模型的泛化程度。
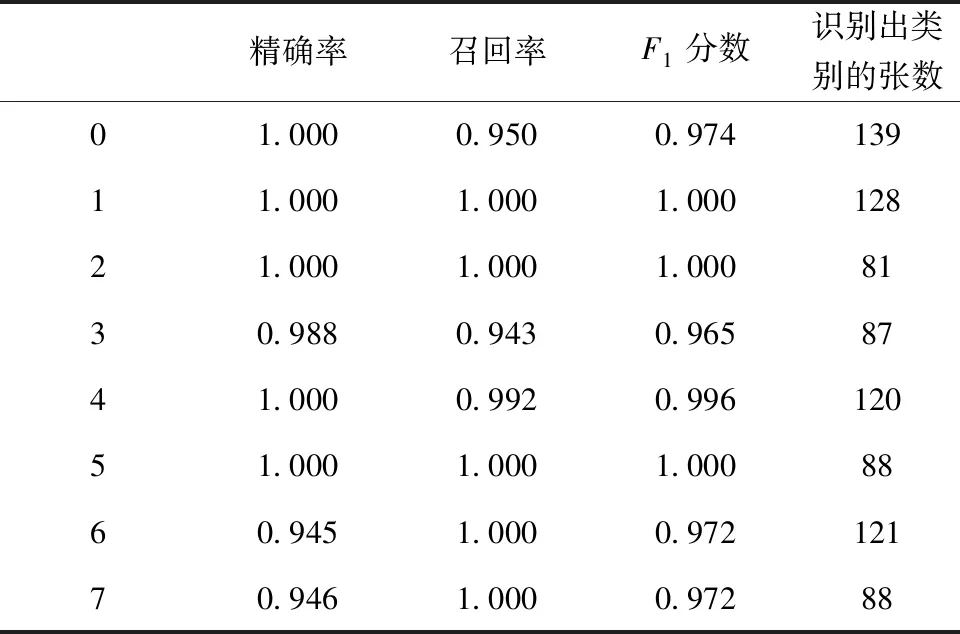
表1 训练分类结果
实验中常常用P-R曲线作为衡量值来比较模型的性能好坏,P-R曲线中的P是精确率,R即是召回率,其代表的是精确率与召回率之间的关系,一般呈现负相关。同时,引入F1作为综合指标,为了平衡准确率和召回率的相互造成的影响,F1的数值越大说明模型质量越高。为了更好地比较R-EfficientNet模型在人体坐姿识别领域的能力,选取常用于动作分类的VGG16、CNN网络模型、ResNet18、EfficientNet与之比较。
从图9中的P-R曲线的性质可以得出,R-EfficientNet模型包住了其他几类模型,则可以说明模型R-EfficientNet的性能要优于其他几类模型,但由于有个别模型发生了交叉,可以选用F1值来衡量模型性能优劣。

图9 P-R曲线图
结果证明,仅使用单独的RGB或Depth图像作为输入进行识别,识别率较低,判别不准确,本文模型不仅利用了深度图像特征引起的定位误差小的优势,同时借助了RGB通道的信息进行融合,达到了较高的识别准确度。由于本研究的目标为单独的人,检测对象比较大,仅使用深度图像特征信息就可以准确地确定目标的位置信息,该方法大大降低了识别误差。这些结果证实了使用RGB-D融合特征信息是可行的,同时证明了本文模型的优势,可以达到人体可以在任何光照条件下正确定位并判别坐姿状态。
从图10的模型对比矩形图可以看出,与其他方法相比,纯深度方法的识别效果不好,收敛性能较差,主要原因是深度图像会有一定的噪声和孔洞的干扰[23],且包含的信息量较少。
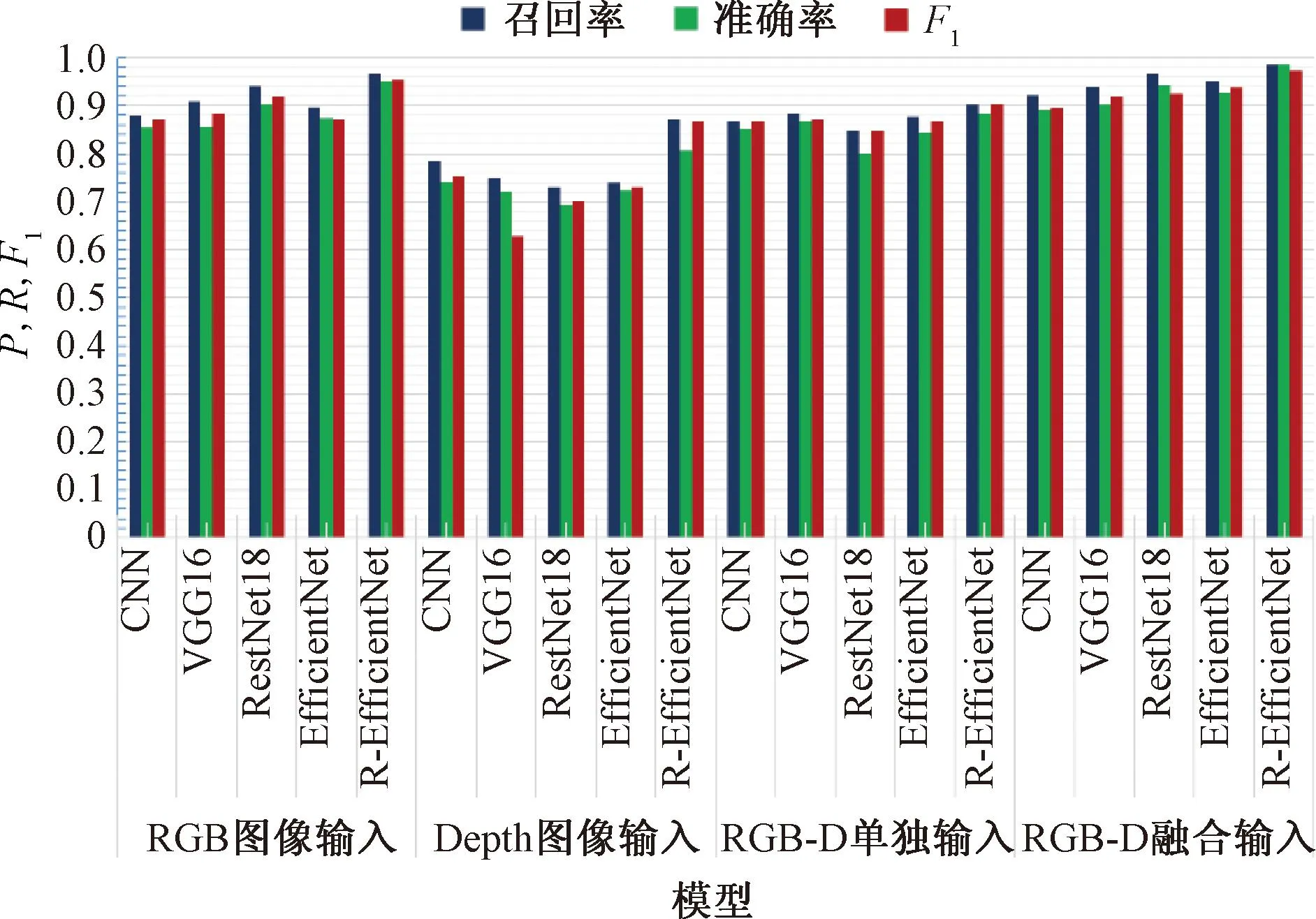
图10 模型性能对比矩形图
混淆矩阵在判断分类模型的优劣和分类效果方面表现良好,能清晰地显示判定的8种常见坐姿识别中正确和错误识别的数量,使用RGB-D数据集来训练本文模型并进行可视化和分析。
可以从混淆矩阵中看出,该方法的误差主要是由于人体身形的差异性以及姿势的多样性,具有高度相似性有时会被错误地识别出来。具体来说,分类错误显示在图11中,混淆矩阵主要发生在姿势6、姿势7之间的相互误判,主要是由于与相似类别混淆造成的。因为,在正常光照条件下,由于正确坐姿和前倾坐姿以及后仰坐姿相似,位置信息差异性较小,造成一定的误差结果。此外,该方法也会受到光线变化的影响,从而导致识别错误,由于阴影和光线不均匀对RGB图像的影响,部分姿态被错误识别,例如左撑头以及右撑头。

横纵坐标0~7为坐姿的8个类别
5 结论
提出了一种改进双流多模态信息融合坐姿识别方法,实现了高精度的人体坐姿识别,不仅充分利用了RGB图像特征,同时引入了Depth图像来解决彩色图像信息干扰导致的识别精度不高的问题,同时改进了一种深度学习模型算法,达到快速识别人体不正确坐姿的目的。
提出仅根据Kinect传感器获得RGB-D图像数据,不再需要复杂的接触式传感设备仪器进行采集识别,有效降低了识别成本,提高了识别精度。以Pytorch作为深度学习框架进行训练,对8种常见坐姿状态分类识别率可达98.5%;对比不同网络模型的训练效果,所提出的R-EfficientNet在模型稳定性和准确性方面具有显著优势。实现了对不同坐姿快速、高效、低成本的分类识别,识别结果可以运用于医疗监护等领域,同时为各类家具生产提供有效的创新方案。
