基于欠采样和多层集成学习的恶意网页识别
2024-03-21王法玉于晓文陈洪涛
王法玉,于晓文,陈洪涛
(天津理工大学 计算机病毒防治技术国家工程实验室,天津 300384)
0 引 言
在开展恶意网页识别的研究过程中,受限于恶意网页体量小生命周期短等特点,恶意网页和良性网页样本往往是不平衡的,尤其是在关注少数类问题的时候,分类结果不均衡会更加的突出,检测结果会更倾向于样本数量大的类别,导致模型的分类效果下降。因此,对不平衡数据集的恶意网页识别进行研究是很有必要的。
目前,恶意网页检测技术主要有3种:①黑名单技术,将恶意网页的域名,IP地址等信息保存到数据库,通过检索来判定是否是恶意网页;②启发式检测技术,对大量恶意网页进行分析并提取不同恶意网页之间的相似特征,创建模板,作为启发式规则去检测未知的恶意网页;③基于机器学习的检测技术,提取恶意网页和良性网页存在差异的特征,运用机器学习中的分类聚类算法(如SVM、KNN、逻辑回归、决策树等)对网页进行检测[1-7]。随着网页规模迅速变大,数据集的不平衡性日益明显[8],黑名单技术和启发式检测技术受限于恶意网页的收集和时效差的缺点难以再胜任恶意网页检测任务,而数据的不平衡性对传统机器学习模型的准确率也提出了严峻的挑战。
针对上述问题,结合处理不平衡数据集分类问题的方法,本文设计了基于欠采样、代价敏感和多层集成学习的恶意网页识别模型。使用欠采样处理数据样本,达到局部数据平衡;使用代价敏感学习调整构建第一层集成学习模型,通过权重和阈值的调整确保模型的检测精度;使用投票方式构成第二层集成学习模型,保证全局信息的完整性。
1 相关知识
1.1 处理不平衡数据集的方法
现有的恶意网页检测模型基本上都是基于平衡分布的样本,如果数据存在严重的不平衡,分类结果会更加倾向于样本数据量大的类别,导致分类结果不均衡。
提升不平衡数据分类问题准确度的常用做法有3种:重采样技术、代价敏感学习、特征选择[9]。重采样技术对数据进行平衡化处理主要有两种思路,一种是过采样,通过复制少数类,使少数类样本与多数类样本平衡;另一种是欠采样,按照少数类样本数量随机选取同等数量的多数类样本,从而平衡两种样本。采样技术近几年被广泛用于处理数据不平衡问题[10,11]。代价敏感学习是为了解决实际应用问题中训练数据不足、数据不平衡而提出的一种自己定义的损失函数模型,通过增加约束和权重条件,使最终输出结果向一个特定的方向偏移[12]。特征选择则是选取合适的特征子集,来增加样本间的区分度。
1.2 基本分类模型
1.2.1 逻辑回归
逻辑回归(logistic regression,LR)是线性模型的一种,实质上是在线性回归的基础上,构造的一种分类模型。常用Sigmoid函数δ(Z)=(1+e-Z)-1来展示,样本x所属类别y1的可能性可以表示为
p(S=1|H)=δ(w*H+b)
(1)
1.2.2 支持向量机
支持向量机(support vector machine,常简称为SVM)作为一个比较复杂的分类算法,通过找到一个分类平面,将数据分隔在平面两侧,从而达到分类的目的,是解决二分类问题的常见分类算法,可以解决线性可分和不可分问题[13]。
本文使用的SVM算法采用的核函数是径向基核函数(radial basis function,RBF),又叫高斯核
(2)
RBF可以将一个样本映射到高纬度空间,决策边界更为多样化,与多项式核相比,参数更容易选择。
1.2.3 K近邻算法
K近邻(K-nearest neighbor,KNN)是一种最经典的有监督学习方法,原理是通过寻找与新样本最邻近的K个样本判断该样本属于哪一类(根据K个样本中的多数进行划分)。本文的K近邻算法使用曼哈顿距离
(3)
1.2.4 决策树
决策树分类算法(decision tree,DT)由于它具备便于了解、结构可视化、训练样本需求少、更灵活等特点被广泛应用于机器学习领域。决策树学习采用分而治之的策略,通过贪婪搜索来识别树中的最佳分割点。决策树学习通常由特征选择、决策树的生成、决策树的修剪构成。本文使用C4.5算法,该算法选取节点的依据是最大信息增益率,计算公式为


(4)
C4.5算法相较于ID3算法,用信息增益率来选择划分特征,克服了用信息增益选择的不足,能够处理具有缺失属性值的训练数据,通过剪枝技术消除噪声和孤立点。
1.2.5 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种有监督学习算法,通过衡量标签和特征之间的概率关系来对样本进行预测,是由基于概率论和数理统计的贝叶斯理论演化而来。通过条件概率和先验概率可以推出公式
(5)
朴素贝叶斯,是在贝叶斯的基础上,对条件概率分布做了条件独立性的假设。
2 特征选取
特征值的选取是机器学习领域的关键点,很多时候,分类器之间的差异性对最终任务的影响是要远远小于选择良好特征对最终结果的影响[14]。因此我们在选取特征值上了做了充足的准备,包括查阅多方相关文献并总结、分析恶意和良性网页的特征分布等。下面是本文选取特征的详情。
为了更好训练模型,特征选取应该具备:①特征与特征之间要尽可能的相互独立,因为模型构建时大多假设特征之间是相互独立的;②特征覆盖面要广泛,从多个维度对恶意样本进行描绘;③特征要具备代表性,减少冗余特征的使用。
基于词汇的URL特征,在能够取得较好检测效果的同时又可以保证“轻量级”。在提取特征时,一条URL可以被分成域名、路径、查询参数、锚点4大部分,每个部分又分别是由数字、字母以及特殊符号构成的,根据特殊字符(例如“/”,“.”,“?”,“=”等)将URL切分为不同的token,就可以将一条URL看作是由一组token组成的向量,从而获取到更加具体的特征。
针对URL整体以及它的每个部分,分为基于URL整体的特征、基于域名的特征、基于路径的特征、基于查询参数的特征以及基于锚点的特征。其中的“恶意词出现次数”特征所统计的恶意词是根据malwaredomains.com下载的恶意域数据集统计出现次数较多的词。流行网站名是根据Alexa排名前500名的网站数据集进行统计得到,因为很多恶意待遇网站会通过模仿知名网站来迷惑用户。所有特征见表1。

表1 URL词汇特征
3 基于欠采样和多层集成学习的恶意网页识别
3.1 总体架构
本文提出了一个在不平衡数据集上基于欠采样和多层集成学习的恶意网页识别方法,通过欠采样、阈值调整和多层集成学习等方法,针对存在不平衡的网页数据集进行研究分类。实验的整体架构由网页采集、数据处理、特征提取、模型训练4个环节构成。整体框架如图1所示。
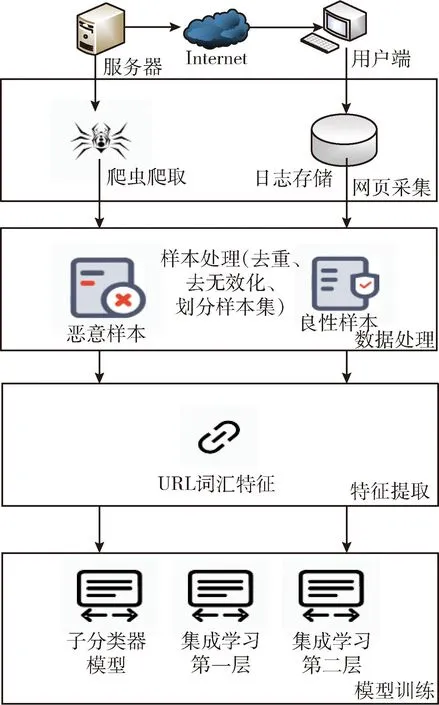
图1 整体框架
具体步骤可以分为:第一步,数据获取,系统通过爬虫模块将需要的样本进行获取;第二步,对大量数据进行汇总处理并对样本做好标签,之后对处理完的数据按比例划分成训练集,验证集以及测试集;第三步,对样本进行特征提取和计算;第四步,训练子分类器以及构建两层集成学习分类器模型。
图2是整体架构中的第四步,模型训练过程的详细展示:第一步,将处理过的数据集(去重、做标签等操作)划分为训练集、验证集以及测试集,其中测试集和验证集根据欠采样的采样方法划分为5份;第二步,在每份数据集上对5种常规的基分类器(KNN、SVM、逻辑回归、朴素贝叶斯、决策树)进行模型训练;第三步,将训练好的模型在验证集上进行测试,对5个基分类器的测试结果(精确度、准确度、F1等评价标准)分别计算权重并以文件的形式进行保存,留待后续的集成学习使用;第四步,对测试集进行预测,进行第一次集成学习,根据第三步保存的各基分类器以评价标准计算出的权重进行集成,通过调整阈值对测试集进行初步的预测;第五步,将上一步5组集成学习的预测结果通过Bagging投票的方式进行再次集成并输出最终预测结果。
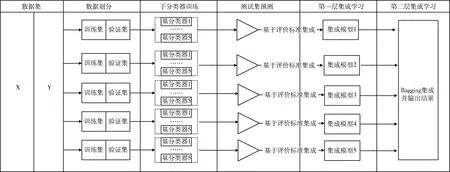
图2 基于欠采样和多层集成学习的恶意网页检测模型框架
3.2 欠采样集成学习算法
集成学习的主要思路是将多个弱分类器通过某种继承策略进行组合形成一个集合多个弱分类器的优点的强分类器。欠采样方法能有效避免样本不平衡带来的分类结果的偏移[15],缺点是若随机丢弃反例,可能会丢失一些重要信息,存在过拟合的问题。集成学习可以有效解决欠采样存在的问题,两者结合,能大大提升模型的分类效果。
欠采样集成学习步骤分为:①根据少类样本划分数据集。多数类欠采样分成多组,少类样本与其进行组合,形成多个训练集样本;②将分类器模型在每组样本集上进行训练;③使用集成学习方法进行集成。目前集成学习方法有Bagging、Boosting和Stacking等,本文采用Bagging方法集成,算法步骤如下。
欠采样集成学习算法
输入:
样本集:D={d0,d1},d1为恶意样本集,d0为良性样本集;
训练样本集:T={t0,t1},t1为恶意训练样本集,t0为良性样本训练集;
验证样本集:V={v0,v1};
待测试样本:c
子样本集数量s;
子样本集Di;
良性训练样本子集t0i;
流程:
(1)Start
(2)初始化样本集t1=d1*0.7,t0=d0*0.7,v1=d1*0.15,v0=d0*0.15;
(3)根据恶意样本训练集计算子样本集个数s=t0/t1;
(4)构建子样本集Di=t1+t0i,0 (5)在每组子样本集上训练5个传统机器学习模型; (6)考察并保存模型在验证集上的表现accji,preji,F1ji,0 (7)计算每个机器学习模型在各自样本上的权重αji,0 (8)计算出每组子样本的集成学习预测结果predictj,0 (9)Bagging判定每个样本c的最终结果 (10)if ∑0 (11) doc←d1 (12)else (13) doc←d0 (14)End 实验提出一种基于欠采样和集成学习相结合的算法。在欠采样集成学习模块,利用欠采样处理数据样本的思想,将多数样本按少数样本数量分成多份,与少数样本构成多组数据集,以供不同基分类器学习。该模块实现了数据集上的局部平衡,之后通过下一层基于投票的集成学习保证全局信息的完整性。整个模型在保证不丢失重要信息的基础上消除了不平衡数据集对预测结果的影响。 传统机器学习检测模型各有优缺点,应对的场景也存在不同,例如逻辑回归容易欠拟合,准确率较低;朴素贝叶斯更适合小规模数据;决策树容易过拟合。单一的机器学习模型难以胜任当下变化多样的恶意网页检测,而集成学习可以通过联合多个弱分类器达到强分类器的效果,“博采众长”,弥补单分类器的缺陷。实验提出了一种基于评价标准和阈值调整的集成学习算法,将5种传统机器学习模型根据在验证集上的表现进行集成,之后通过调整阈值来控制输出结果。 实验将5种传统机器学习模型(逻辑回归、KNN、SVM、决策树、随机森林)进行集成,集成思想是在训练完成后的验证阶段通过计算评价标准(准确率、召回率、F1等评价标准)在每个模型训练集上十折交叉验证的分数,然后把该分数相加得到总分数,最后将每个分类器的分数与总分数相比,得到单个分类器的权值αji(其中j表示第几组子样本,i表示该组中的第几个分类器)并进行保存,留待集成学习模型使用。 下面是计算公式,以acc(准确率)作为计算权重的标准为例 (6) (7) 其中,αj1,αj2,αj3,αj4,αj5分别代表第j组样本中逻辑回归、KNN、SVM、决策树、朴素贝叶斯的权重,accji,precisionji,F1ji,recallji表示第j组中某个模型的准确率、精确率、F1值以及召回率。通过式(6)计算出5个基分类器的权重,基分类器的检测效果越好,权重越大。式(7)为预测某个样本的计算公式,其中第j个样本预测结果等于每个模型的权值乘上该模型对该样本的预测结果,最终所有测试样本都会得到一个介于0~1之间的数值,将其保存留待后续通过设置一个合适的阈值来得出检测结果 D∈y1,predictj>λ (8) D∈y0,predictj≤λ (9) 如式(8)、式(9)所示,实验可以控制这个阈值λ,当predictj>λ时判定为恶意。后续会对不同λ取值做消融实验,来确定一个效果最好的λ值。 综上所述,本文提出的基于欠采样多层机器学习模型在不平衡的数据集上通过欠采样和多层集成学习与传统机器学习相比显著提升了检测效果,使之更加符合当前恶意样本和良性样本严重失衡的使用环境。 (1)硬件环境 CPU:Intel(R) Core i5-8300H;内存:DDR4 16 G;硬盘:1 T,7200转/秒。 (2)开发环境 开发操作系统:Windows 10旗舰版(64 bit);机器学习开源框架:Scikit-learn;开发语言及工具:Python3.8、STL标准模板库、Visual Studio2016、PyCharm。 4.2.1 用于特征提取的数据集 从malwaredomains.com等恶意域数据集收集了26 251条恶意域URL,用来提取出现频率较高的恶意词,作为后续的数据特征。 从Alexa获取了世界排名前500的网站,提取出现过的网站名称,用来统计数据集中的URL出现流行网站名次数。 4.2.2 训练集、验证集、测试集 从kdnuggets上收集到了带标签(good/bad)的URL数据集,共416 350条,用作集成学习模型的训练和测试数据,其中异常数据(bad)71 556条,占比17.19%;正常数据(good)344 794条,占比82.81%。 将全体数据划分为训练集(70%)、验证集(15%)和测试集(15%),采用随机不放回取样,并且保证每个集合中恶意和良性样本占比例相同。标签为“1”表示恶意URL,标签为“0”表示该URL为良性。 4.2.3 实验样本不平衡情况 本文使用kdnuggets上带标签的URL数据集,对其进行统计分析后,发现样本存在数据不平衡问题,对恶意网页识别分类具有一定的负面影响,良性样本大约是恶意样本的5倍,具体分布情况见表2,而这种样本分布不平衡的现象在恶意网页检测领域是广泛存在的。 表2 数据集分布情况 为了能说明一个系统的检测效果,需要一些评判指标,对于二分类问题实验使用TP(真正例)、FP(假正例)、FN(假反例)、TN(真反例)这4个指标进行评估具体见表3。 表3 评估标准 实验还需要使用以下几个指标来全面衡量恶意网页检测系统的性能,取值0~1之间。公式为 (10) (11) (12) 本文提出的基于欠采样的多层集成学习分类算法在基分类器上依赖5个传统的机器学习模型,实验设计了如下方法选出最优的集成学习参数以及比较分类效果,找出最合理的处理不平衡数据分类的方法。 (1)欠采样+多层集成学习分类算法(找最优阈值):对多类良性网页样本欠采样出5组,与恶意网页样本组成新的数据集,每组数据都对第一层集成学习的5个传统机器学习模型进行训练,调整第一层集成学习的阈值,找到最优的阈值λ。 (2)完全采样+多层集成学习分类算法:将所有数据作为训练样本和测试样本分成5组样本,第一层集成学习的基分类器为5个传统机器学习模型。 (3)欠采样+多层集成学习分类算法:对多类样本(良性网页)欠采样出5组样本,与少类样本组成新的数据集,每组数据都对第一层集成学习的5个传统机器学习模型进行训练。 (4)过采样+多层集成学习分类算法:对少类样本(恶意网页)过采样,复制样本数量达到与多类样本平衡的效果,再对第一层集成学习的5个传统机器学习模型进行训练。 (5)欠采样+单层集成学习分类算法:欠采样出5组样本,通过Bagging得到集成的模型。 (6)欠采样+传统机器学习模型:欠采样出5组样本,对5个传统机器学习模型进行训练。 第一组实验由上述方法(1)完成,该组实验目的是找到第一层集成学习的最优阈值。实验分别从准 确 率(acc)、精准率(precision)和召回率(recall)这3个维度对不同分类算法的分类性能进行衡量,效果如表4和图3所示。 图3 不同λ取值下集成学习检测效果 表4 不同阈值λ下集成学习检测效果 表4是基于URL词汇特征的集成学习检测效果表(αji依据acc计算获得),通过调节不同的λ阈值,可以得到不同的检测效果,实验中共选取了4个阈值进行了实验比较,通过图3可以看出,随着阈值变大,模型的Precision是越来越低的,而Recall则越来越高,ACC在λ=0.4时表现最好,之后慢慢下降,这是因为阈值越大,越不容易被判定为恶意。当阈值λ=0.4时集成学习的综合性能最好,虽然Recall略低于λ=0.3,Precision低于λ=0.5和λ=0.6,但是具有更好的准确率,综合性能也是最好的,所以整个系统选取λ=0.4作为后续实验中集成学习的阈值。 第二组实验由上述方法的(2)~(4)组成,针对不平衡数据集验证欠采样在集成学习上的有效性。实验分别通过完全采样、欠采样和过采样3种不同处理数据的方法对相同的集成学习模型进行恶意网页分类研究,对比3种情境下集成学习的分类效果,得出最优的处理不平衡数据集的数据处理方法。表5的数据对比可以看出,欠采样方法的分类效果在准确率和召回率上要远优于完全采样和过采样,召回率达到94.88%,相较于完全采样和过采样的83.86%和81.93%,有着巨大的提升。其原因在于,完全采样和过采样的分类效果更偏向于多数类,导致检测的召回率不尽人意。本实验设计的欠采样和多层分类器结合的模型能在保证全局信息完整的基础上平衡数据集,大大提高检测模型的召回率,从而提升模型检测的准确率。 表5 不同采样方式检测效果 第三组实验由上述方法(2)、方法(3)、方法(5)、方法(6)组成,该组实验用来比较多层集成学习模型与单层Bagging集成学习模型以及传统机器学习模型在检测效果上的优劣,数据采集上都使用欠采样进行处理,如表6所示,本文提出的恶意网页检测方法在检测效果上相较于单层Bagging集成学习模型表现更好,准确率、精确率和召回率都要优于Bagging集成学习模型,这是因为本实验的基分类器在数据集上进行了平衡,能更好检出恶意网页。 表6 不同模型检测效果对比 表6中5种传统机器学习模型,表现最好的为决策树,但由于数据的不平衡性,在召回率上表现一般。5种机器学习模型作为基分类器在各种参数上要低于集成学习也符合预期,进一步说明了本文提出的集成学习模型的有效性。 通过上面多组实验效果对比,可以得出结论:针对不平衡数据集,使用欠采样与集成学习相结合的方法要比传统单分类机器学习方法性能上要高;采样方法相同的情况下,多层集成方法的检测效果要优于单层集成学习以及传统的机器学习方法。本文提出的欠采样多层集成学习模型能够较好处理数据不平衡的恶意网页检测问题。 本文提出了一种基于欠采样的多层集成学习分类方法,来处理恶意网页识别研究中数据不平衡问题。方法中先采用欠采样数据处理方法得到多组训练样本,之后将传统的5种机器学习模型在验证集上的表现作为权重构建第一层集成学习模型,最后通过Bagging投票方式对这多个集成结果进一步集成得到最终的检测结果。最终的检测结果表明,该模型是行之有效的,能够有效处理不平衡数据以及恶意网页识别问题。3.3 基于权重和阈值调整的集成学习算法
4 系统实验测评
4.1 实验环境
4.2 实验样本划分及不平衡情况

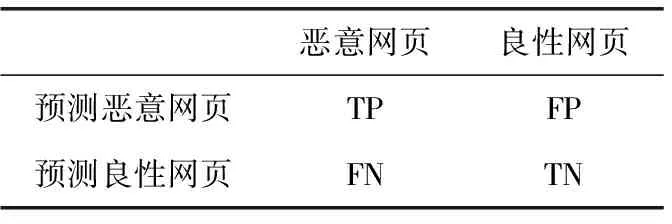
4.3 评价标准
4.4 实验结果与分析




5 结束语
