基于时空长短时记忆神经网络的地基云图预测算法
2024-03-21吴现吐松江卡日王海龙马小晶李振恩邵罗
吴现,吐松江·卡日*,王海龙,马小晶,李振恩,邵罗
(1.新疆大学电气工程学院,新疆 乌鲁木齐 830049;2.北京智盟信通科技有限公司,北京 100053)
0 引言
随着人们对能源需求的不断增长,传统化石能源弊端日益显现,世界各国愈发重视能源清洁性问题。太阳能作为目前最有发展潜力的可再生能源之一,装机占比正在逐年提高,展现出了其广阔的应用前景。然而,光伏电站的发电功率因受诸多气象因子与环境因素的影响而表现出强波动性与随机性[1],在这种情况下大规模光伏电站接入电网会对电网稳定性带来冲击,危害电网安全甚至造成严重经济损失[2]。因此,实现准确的光伏功率预测不仅可以提高电网调度效率,而且对保证电网的安全稳定运行具有重要意义。
太阳辐照度是引起光伏电站发电功率变化的最主要因素,运动型不规则云团对太阳遮挡产生的“分钟级”波动使光伏电站输出功率也随之无规律地快速剧烈波动,然而这种“分钟级”波动难以在生产生活中被忽视。针对这一问题,国内外学者采用多种模型算法开展了太阳总水平辐射(GHI)的预测研究。传统的太阳辐照度预测通常使用数值天气预报(NWP)模型进行天气状况模拟,并以此来推断部分区域的云量变化[3],该模型目前能够实现对部分区域未来48 h 的太阳辐射预测,但是因其不易发掘太阳辐照度与气象信息之间的联系,并对短期GHI 变化不敏感,使得该模型较为适合中长期预测而非短期预测。此外,部分研究人员使用卫星图像进行太阳辐照度预测[4],卫星图像能够获取更多潜在气象信息[5]从而提高GHI 预测精确性,但是因其预测分辨率较大而不能实现对GHI 的短期预测。因此,使用地基云图进行GHI 预测的方式逐渐兴起,其能够有效反映特定区域上空云层分布状况变化,通过对云团运动轨迹进行分析从而达到精确预测的目的,弥补传统卫星图像在短期预测领域的劣势。文献[6]利用尺度不变特征转换(SIFT)对地基云图特征点进行匹配,实现对云运动轨迹的追踪识别,并在一段时间内进行太阳遮挡情况预测。文献[7]提出基于互相关云运动估计来预测短期太阳辐照度的方法,但该方法并不能直观反映预测到的云层状态,只能通过其他变量来描述,如云运动矢量等。
随着机器学习技术的发展,更多学者尝试使用深度学习算法来解决传统模型计算量大但精度不高的问题。相对来说,国内开展基于地基云图的研究主要在云团识别与云图像分类方面,在预测云运动趋势和形状变换方面的研究较少,但目前在其他领域已经开展了视频预测方面的研究。长短期记忆(LSTM)网络[8]在预测任务中应用广泛,文献[9]采用双阶段注意力机制与LSTM 相结合的方法来提升短期风电功率预测的准确性与稳定性,文献[10]针对位置预测任务中多数模型忽略时间与空间关联性的问题,利用时空LSTM 来增强模型的时空特征关联能力,提升位置预测精度。文献[11-12]仅使用简洁的卷积神经网络作为特征提取模块来实现预测任务,文献[13]使用具有UNet 体系结构的Inception 模块多维度捕获时空演变潜在规律,但仅使用卷积不能完全捕获数据长期依赖关系,且云运动更加复杂多变,其轮廓和运动规律更难预测,这将导致模型预测效果较差。文献[14]引入一种名为TaylorNet 的双分支结构,将时序图像输入模型中并行提取时序特征,虽然该模型考虑到了提取多维特征的重要性,但是其特征提取模块对时空信息捕获能力较弱,提取到的特征时空关联性不足。
针对上述问题,本文提出一种基于时空长短时记忆(ST-LSTM)神经网络的地基云图预测模型。首先,去除地基云图中数据异常天数并重新设置图像尺寸;其次,建立双分支特征提取模型,使用时空长短时记忆神经网络与麦克劳林(Maclaurin)特征展开单元并行提取特征;然后,对支路提取得到的特征进行整合并经过解码器输出预测结果;最后,以瑙鲁岛某地区云图和公开的视频预测数据集Moving MNIST、Human 3.6M 为例,将本文所提模型与现有的TaylorNet、E3D-LSTM 等方法进行对比,以验证本文提出的双分支预测模型对视频预测的有效性与准确性。
1 模型框架
本文提出一种基于时空长短时记忆神经网络的视频预测模型,模型整体框架如图1 所示。
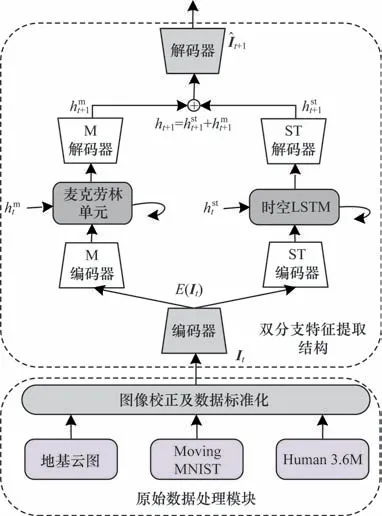
图1 麦克劳林双分支预测模型结构Fig.1 Structure of the Maclaurin two-branch prediction model
在本文麦克劳林双分支预测模型中:首先是原始数据处理模块,通过鱼眼图像校正算法对云图进行校正,还原成像仪上空云图的真实状态,提高数据实用性;然后将标准化后的数据输入编码网络,利用双分支特征提取模块获取更多细节特征,提升预测模型的信息获取能力;最后将不同特征进行融合后经过解码器输出预测图像,实现视频流的预测。
2 双分支预测模型MaclaurinNet
由于天气的混沌特性,导致地基云图特征信息易于混淆,多分支特征提取结构相比于单分支模型能够获取更多不同维度的特征。基于长短时记忆神经网络改进的时空长短时记忆神经网络在学习序列时空关联性上具有良好的性能。序列信息展开方法能够对序列内复杂特征进行解纠缠,便于提升模型的特征信息提取能力。因此,本文采用双分支结构作为网络模型框架,提出一个端到端的视频预测模型,利用麦克劳林单元与时空长短时记忆神经网络来并行提取特征,以提升模型的预测精度。
2.1 麦克劳林单元
本文在文献[14]所提Taylor单元的基础上提出麦克劳林单元,其中初始的Taylor单元结构如图2所示。
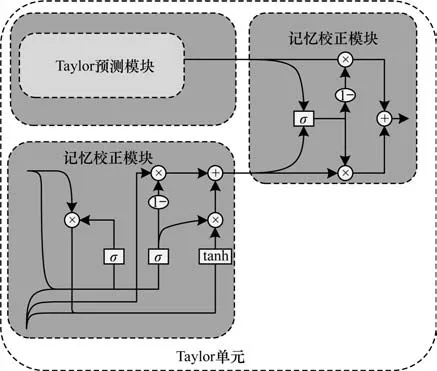
图2 Taylor 单元的内部细节结构Fig.2 Internal detailed structure of Taylor unit
Taylor 单元中记忆修正模块是基于卡尔曼滤波算法所设计的,实现对预测特征的误差修正。卡尔曼滤波具有适用范围广、滤波效果好等特点,但是卡尔曼滤波仅能够对线性过程进行较为精准的估计,在非线性任务中往往不能达到最优的估计效果[15],而视频预测任务往往都是非线性的。为了解决此问题,本文提出麦克劳林单元。麦克劳林单元是一种基于门控机制的特征提取模块,由麦克劳林信息展开模块与记忆融合模块2 个部分组成,具体结构如图3 所示。
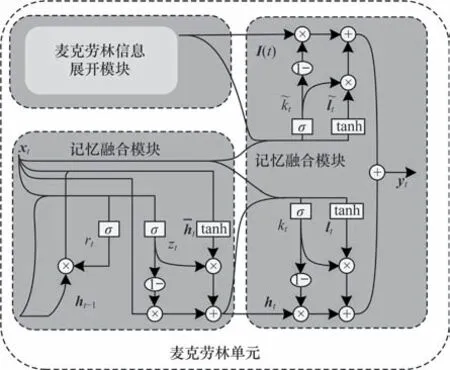
图3 麦克劳林单元结构Fig.3 Structure of Maclaurin unit
2.1.1 麦克劳林信息展开模块
麦克劳林信息展开模块将编码后的特征图像进行解纠缠,以便于获取更多深层时空特征。信息展开模块由多层偏微分(PDE)模块[16]堆叠构成,将不同维度的特征信息进行融合以获取尽可能多的细节信息。麦克劳林信息展开模块具体结构如图4 所示。
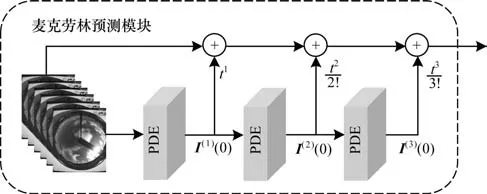
图4 麦克劳林信息展开模块Fig.4 Maclaurin information expansion module
本文将麦克劳林展开式的信息定义为:
其中:I(t)表示经过预测后输出的特征图像;I(k)(0)表示输入图像的k阶时间导数是通过k层PDE 模块而得到的。
通用线性PDE 模型中包含了各种经典的物理方程,如运动方程、波动方程、热方程等,从而能够实现图像的深度挖掘。PDE 模块表达式如下:
在设计模型时,为防止误差在迭代过程中不断累积,模型仅针对图像序列原始帧信息进行麦克劳林展开,令式(1)中变量t值为1,以防止计算量过大使得模型难以训练。
2.1.2 记忆融合模块
麦克劳林信息展开模块会存在如下2 个问题:首先,本文使用的麦克劳林展开式只使用第1 帧信息为后续帧提供特征信息,模型会丢失部分中长期预测能力;其次,视频预测任务中结构信息变化趋势较为复杂且多为非线性变化,使用基础模型中的卡尔曼滤波算法对此无法实现精确估计与校正。针对上述问题,本文提出一种基于门控机制的记忆融合模块。记忆融合模块首先将当前帧图像信息输入改进的门控循环单元(GRU)中,以增强帧间时空关联性。改进的GRU 内部状态转移公式为:
其中:xt为当前时刻的输入向量;ht-1为t-1时刻的隐藏 状态、ht分别表示t时的GRU 候选隐藏状态和隐藏状态;σ为激活函数;*为卷积运算符。
为实现特征信息的相互补充,后续的门控单元将当前隐藏状态ht与信息展开项I(t)进行融合与更新,最后输出预测的特征图像。上述过程计算公式如下:
其中:kt、为向量经过更新门后的特征信息;lt、为t时刻的支路候选隐藏状态;yt为麦克劳林单元最终预测出的特征图像。
2.2 时空长短时记忆神经网络
ST-LSTM 由多层神经网络单元堆叠形成。STLSTM 与LSTM 都采用门控机制,但由于双记忆状态转移机制的引入使得ST-LSTM 的结构相对更加复杂,也拥有更强的时空捕获能力。ST-LSTM 包含时间记忆单元和空间记忆单元2 个记忆模块。第n层的时间记忆单元负责横向时间流的传递,空间记忆单元负责层与层之间空间记忆的纵向传递。输出时将2 个记忆单元的特征进行融合,并通过1×1卷积层进行降维,保证融合后记忆状态维度与、一致。ST-LSTM 内部结构如图5 所示。
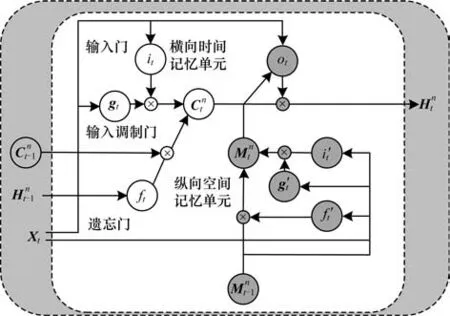
图5 ST-LSTM 内部结构Fig.5 Internal structure of ST-LSTM
模型通过输入到状态和状态到状态转换的卷积运算,利用相邻输入和历史状态来预测未来状态。ST-LSTM 单元内部状态转移公式为:
其中:it、gt、ft分别为第1 组的输入门、输入调制门、遗忘门分别为第2 组的输入门、输入调制门、遗忘门;Xt为输入状态分别为时间记忆状态、空间记忆状态;ω、ω′为权重矩阵;b、b′为偏差矩阵;⊙表示Hadamard 积。
2.3 网络模型训练及损失函数
在本文实验中,通过滑动窗口的方法设置图像序列Hinput=[h0,h1,…,ht-2,ht-1]作为输入,接下来N帧真实序列为Houtput=[ht,ht+1,…,ht+N-2,ht+N-1],在预测任务中,通过不断减小预测出的动作序列与真实序列之间的损失,使模型逐渐收敛。
L2损失在视频预测任务中使用广泛且能够取得较好的效果,本文模型在训练时采用L2损失作为训练的损失函数,为了使模型预测得到的图像更加接近原始数据,本文将目标函数设置为:
其中:w代表模型中所有的参数;wP表示PDE 模型中的参数。
3 实验与结果分析
为了客观评估本文模型的有效性,在Moving MNIST、Human 3.6M、地基云图3 个不同的公开数据集上进行实验,并为每个数据集单独训练一个预测模型与流行基准预测算法进行定量对比分析。在此基础上,实验探究不同预测帧数对模型预测性能的影响,然后通过可视化结果定性评估本文MaclaurinNet 模型的性能,最后通过消融实验探究模型中不同模块对模型预测性能的影响。
本实验使用的图形工作站配置如下:内存大小为43 GB,CPU 型号为Intel Xeon Platinum 8255C,GPU 型号为RTX 3080,10 GB 显存,通过PyTorch 框架与Adam 优化算法实现本文预测方法。实验参数设置如表1 所示。

表1 3 个数据集的图像大小及训练参数设置Table 1 Image size and training parameters setting of three datasets
3.1 数据集
地基云图数据集来源于Nauru Island 的全天空成像仪(TSI),可以从Atmospheric Radiation Measurement facility 下载。数据集时间跨度为2002 年11 月—2013 年9 月,每个连 续图像 的时间间隔为30 s,原始图像大小为352×288 像素,本文使用2002 年的9 271 张晴天云图,经过文献[17]提出的图像校正算法对数据进行校正处理并重新定义图像尺寸。
Moving MNIST 是目前视频预测任务中使用最广泛的公共数据集之一,其通过传统的手写体数据集合成得到,图像序列由2 个在64×64 网格内独立移动并能够实现从边界回弹的数字组成,每张图片的通道数为1。
Human 3.6M[18]是一个 在室内 环境中利用MoCap 系统获取的大规模数据集,包含11 名专业演员的360 万张3D 人体姿态图像,每张图像的通道数为3,大小为128×128 像素。本文将S1、S5、S6、S7 和S8 划分为训练集,将S9 和S11 划分为测试集。
3 个数据集部分示例图像如图6 所示。

图6 数据集图像示例Fig.6 Datasets image examples
3.2 评价指标
本文采用均方误差(MSE)、平均绝对误差(MAE)、结构相似性(SSIM)[19]与峰值 信噪比(PSNR)[20]4 种评价指标对模型的性能进行定量评估。PSNR 通常用来衡量2 张图像间的相似度,SSIM分别从亮度、对比度和结构3 个方面衡量2 张图像的结构相似性,较低的MSE、MAE 和较高的SSIM、PSNR 表示模型具有较好的性能。4 种评价指标具体计算公式如下:
其中:xi,j和分别表示第i组图像序列的第j帧与其所对应的预测结果;M和N分别表示真实序列与预测序列的样本数量;μx和μy分别表示x和y的平均值分别是x和y的方差;δxy是x和y的协方差;c1和c2是用来维持稳定的常数;n为每个采样值的比特数。
3.3 短期预测对比实验
3.3.1 Moving MNIST 数据集
本文将所提模型与ConvLSTM、E3D-LSTM、CrevNet+ConvLSTM、CrevNet+ST-LSTM、PredRNN[21]、Causal LSTM[22]、MIM[23]、PhyDNet[24]、PhyDNet-dual[25]和TaylorNet 在Moving MNIST 数据集上进行对比,定量结果如表2 所示,加粗表示最优数据。
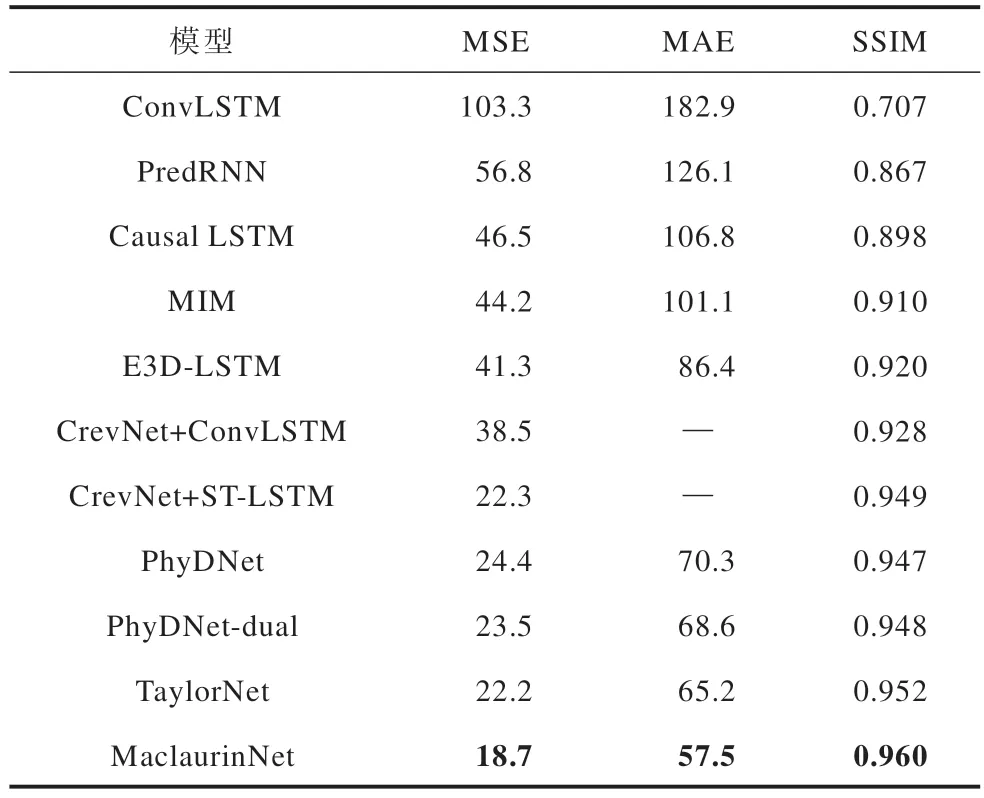
表2 Moving MNIST 数据集上的定量对比结果Table 2 Quantitative comparison results on the Moving MNIST dataset
通过表2 的实验数据可以得出,针对Moving MNIST 这一数据集,本文提出的MaclaurinNet 在3 个不同指标下都实现了最佳的性能表现。相较于同样使 用 ST-LSTM 模块的 PredRNN 模 型,MaclaurinNet 预测能力有了显著提升,MSE 值从56.8 降低至18.7,MAE 值 从126.1 降低至57.5,同 时SSIM 值从0.867 提升至0.960。与同样拥有双分支结构的TaylorNet 预测模型相比,改进后模型的MSE值降低了约15.8%,MAE 值降低了约11.8%,SSIM 值则提升了0.8%。图7 显示模型预测的可视化结果,从中能够看出,MaclaurinNet 的预测图像在整体结构上与真实值更为相似,图中数字的边界更为清晰,能展示出更多的细节特征,验证了本文所建模型的有效性与准确性。
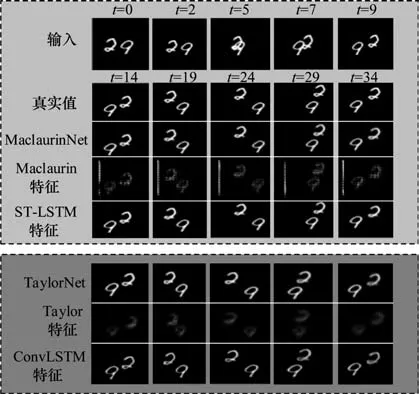
图7 Moving MNIST 数据集上的可视化结果Fig.7 Visualization results on the Moving MNIST dataset
3.3.2 Human 3.6M 数据集
为进一步评估模型的性能表现,使用同样方法在复杂的真实人体姿态数据集Human 3.6M 上进行实验。将数据集输入模型并进行训练和评估,预测的可视化结果如图8 所示,定量实验结果如表3 所示。与Moving MNIST 相 比,Human 3.6M 的图像 具有更多的细节特征,对图像预测模型而言,在该预测场景下保持同样的预测性能将是一项较大的挑战,从表3 可以看出,本文模型仍然表现出了较强的优势。MaclaurinNet 的MAE 值为1 650,性能表现仅次于TaylorNet,且两者的差值较小,仅为40;PredRNN、E3D-LSTM 和TaylorNet 预测模型的MSE值依次 为484、464、374,而本文 模型的MSE 值 为361,较其他3 种预测模型误差更低。从图8 可知,本文模型预测出的图像呈现出了与真实值较为接近的人物姿态与人体细节,表明本文模型在复杂人体姿态数据集上也具有明显优势。
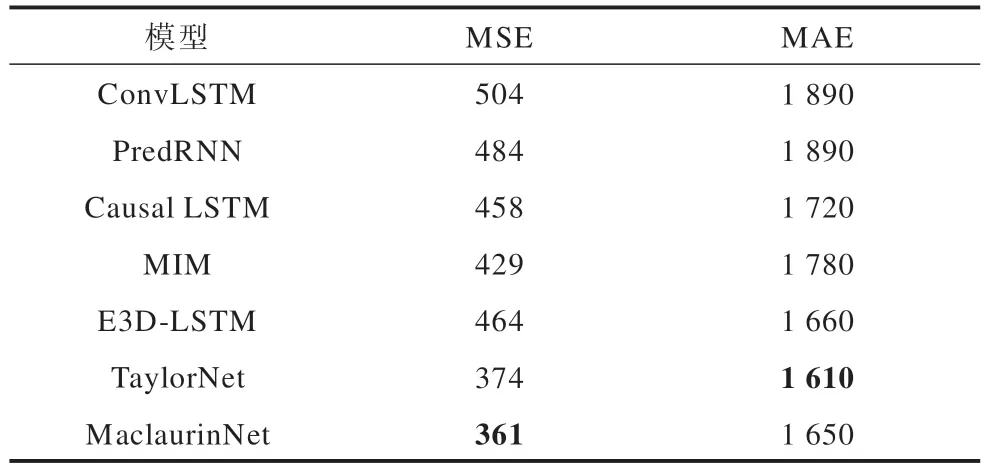
表3 Human 3.6M 数据集上的定量对比结果Table 3 Quantitative comparison results on the Human 3.6M dataset

图8 Human 3.6M 数据集上的可视化结果Fig.8 Visualization results on the Human 3.6M dataset
3.4 中长期预测学习对比
由于TaylorNet 拥有与MaclaurinNet 相类似的双分支结构,且在2 种数据集下所表现出的性能远优于其他模型,为多方面评估本文模型的预测能力,实验针对上述2 种模型进行中长期预测能力的对比评估,分析预测帧数从10 帧逐步提升至90 帧后对模型预测性能的影响,定量实验结果如表4 所示,评价指标变化趋势如图9 所示。

表4 在Moving MNIST 数据集上不同预测帧数对模型预测效果的影响Table 4 Effect of different prediction frames on model prediction effect on the Moving MNIST dataset
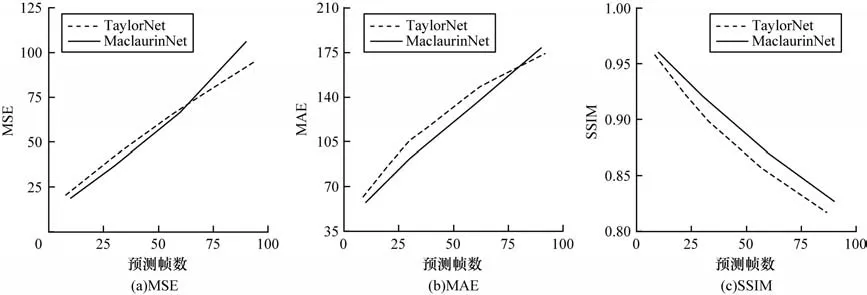
图9 在Moving MNIST 数据集上MaclaurinNet 与TaylorNet 的短期与中长期预测性能对比Fig.9 Comparison of short -and medium -to long term predictive performance between MaclaurinNet and TaylorNet on the Moving MNIST dataset
实验结果显示,随着预测帧数的增加,图像中的像素值与真实值误差将会变大,导致各项性能指标下降。当帧数在60 帧以内时,本文模型的各项性能表现均优于基准模型TaylorNet,在帧数超过60 帧后本文模型MSE 与MAE 值首先出现性能下降的情况,但结构相似性评价指标SSIM 在90 帧时的性能表现依然优于基准模型,其主要原因是在模型设计时为了满足模型实际使用需求并防止误差在计算迭代时不断增大,本文模型仅针对序列的第1 帧图像进行信息展开,增强了模型短期的图像预测性能,使预测结果保留了更多的结构相似性,同时更高的空间结构相似性意味着预测结果与真实值有更紧密的时空对应关系,如图7 所示,其可视化结果也能够呈现出更加清楚的图像轮廓与更精确的图像定位。但是,由于缺乏对后续帧信息的利用,本文模型丢失了部分对长期时空信息的捕获能力,从而弱化了模型的中长期预测性能。因此,相较于基准模型,本文模型在超短期与短期预测时表现出了更好的图像预测能力。由于模型结构的改进设计,在较长期预测场景下尽管部分性能指标出现了下降趋势,但是在关键的结构相似性指标下模型依然保持着良好性能。
3.5 云图消融实验
将MaclaurinNet 与拥有良好预测性能的TaylorNet在地基云图数据集上进行定性与定量评估,以验证MaclaurinNet 对地基云图的预测精确性,并在此基础上进行一系列的消融实验,以验证麦克劳林记忆融合模块和ST-LSTM 模块的有效性。相关实验结果如表5所示。实验可视化结果如图10 所示。
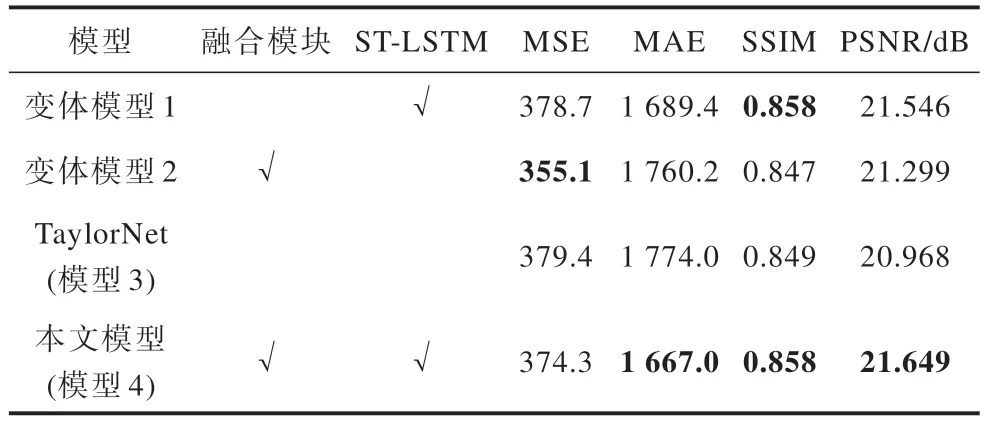
表5 在地基云图数据集中的消融实验结果Table 5 Results of ablation experiments in the groundbased cloud map dataset

图10 地基云图数据集上的可视化结果Fig.10 Visualization results on the ground-based cloud map dataset
变体模型1 是在基准模型3 的基础上使用STLSTM 替换其中的ConvLSTM 模块,以此来探究STLSTM 对模型预测性能的影响。由表5 可知,STLSTM 的加入使模型在4 个评价指标上都获得了提升,MSE 值从379.4 降低至378.7,降低了0.2%,MAE值从1 774.0 降低为1 689.4,降低了4.8%,且SSIM 值从0.849 提升至0.858,提升约1.1%,同时PSNR 值从20.968 提升到21.546,提升了2.8%。实验结果证明ST-LSTM 的加入提升了模型对时间、空间信息的捕获能力,增强了模型预测性能。
变体模型2 是在基准模型3 的基础上将原本的Taylor 替换为记忆融合模块,目的是分析改进的麦克劳林记忆融合模块对云图预测任务所作的贡献。由表5 可以得出,添加记忆融合模块后模型性能在3 个评价指标上都获得了提升,MSE 值从379.4 降低至355.1,降低了6.4%,MAE 值 从1 774.0 降低至1 760.2,降低了0.8%,同时PSNR 值从20.968 提升至21.299,提升了1.6%。实验结果证明,改进后的记忆融合模块能够有效提升模型预测能力,保持输出特征的时空一致性。
4 结束语
针对当前云图预测模型中存在的细节缺失和预测精度差的问题,本文提出一种基于时空长短时记忆神经网络的地基云图预测模型MaclaurinNet。针对单一预测模型在应对复杂云图数据时难以完全获取数据间时空关联性的问题,提出基于双分支结构的预测模型,其结合ST-LSTM 在时空信息获取中的优势以及麦克劳林单元对特征分离和记忆融合的优势,解决传统云图预测模型时空特征提取不足的问题,提高了预测模型对历史数据的敏感度。针对基准模型中卡尔曼滤波算法在非线性任务中性能降低的问题,引入门控机制网络替代卡尔曼滤波模块,提高模型的预测精确性。实验结果表明,基于门控机制的记忆融合模块能够提升模型的预测性能,预测出的图像序列保留了更多的细节信息,MaclaurinNet在不同任务场景中都具有较好的性能表现和适用性。
本文基于时空长短时记忆神经网络和信息预测校正模块的地基云图预测算法为地基云图预测场景提供了一种解决方案,提升了云图预测任务的精度。但是本文只考虑改进模型的短期预测能力,未考虑中长期预测任务应用场景,下一步将基于现有工作开展针对中长期预测任务的研究,以提升模型的总体预测能力。
