基于多种评价法的磨盘山水库水质评价
2024-03-20陈振宙杨鹏辉许文博
陈振宙,杨 旭,杨鹏辉,许文博,张 弛
(1.黑龙江大学水利电力学院,黑龙江 哈尔滨 150080;2.哈尔滨市磨盘山水库管护中心,黑龙江 哈尔滨150080)
0 引言
水是生命之源,在人类的生产、生活中起着重要作用。随着人民生活水平不断提高以及思想的不断进步,对水的开发、利用以及保护的重视程度也显著提高,因此水质评价变得尤为重要。对水库的水质进行评价分析可以了解水库整体的水体质量状况,并为水库水资源开发、利用和保护提供技术支撑。
对水质评价的方法大体上有单因子评价法、综合指数评价法,模糊综合评价法,主成分分析法,神经网络评价法等。徐春霞[1]等人用单因子法和综合法对秦皇岛地下水质量进行了评价。梅学彬[2]对以往的模糊综合评价法中权重确定方法进行了改进,并用实例分析其可行性。马虹[3]用污染指数法和模糊数学法对哈尔滨医药集团公司地面水进行了评价。杜俊鹏[4]应用主成分分析法对长春市经济开发区河流水质进行了评价。郭新强[5]运用主成分分析法和综合水质标识指数法对福建某滨海地水质进行评价。张怡[6]等人利用BP神经网络模型对大庆市红旗泡水库进行水质的富营养化评价。许燕颖[7]利用BP神经网络和WPI评价法评价了桃江水质。本文以主成分分析法以及RBF神经网络法对磨盘山水库水质进行评价。
1 水库概况及数据来源
磨盘山水库位于五常市境内松花江一级支流,距离哈尔滨市约180 km,水源流域面积为1151 km2,多年平均径流量为5.75×108m3,是一座以城镇供水,农田灌溉为主,兼顾防洪,发电的综合利用水利枢纽工程[8]。
本文以2022年12个月的磨盘山水库监测数据为依据,选取溶解氧(DO),氨氮(NH3-N),化学需氧量(COD),总磷(TP),总氮(TN)的5个指标,按照地表水环境质量标准(GB 3838-2002)[9]中的对应标准限值,对水质进行评价。
2 主成分分析法
2.1 初始数据标准化
由于水质指标有不同量纲以及数量级,故在评价前先进行数据的无量纲化处理。
式中:tij为第i个评价对象的第j个指标;、Cj分别是第j个指标的样本均值和样本标准差,i=1,2,…,5, j=1,2,…12。
处理结果见表1。
2.2 指标相关性检验
由表2可知,氨氮与COD,总氮之间存在正相关,COD与总氮存在正相关,本文大多数指标存在较强的相关性,适合应用主成分分析法进行水质评价。

表2 水质指标间的pearson相关分析
从表3可知,KMO=0.618>0.6,Sig.=0.000<0.05,各水质指标间存在较强的相关性,运用主成分分析进行水质评价可以得到较为理想的结果。

表3 KMO与巴特利特校验
2.3 确定主成分及建立主成分得分表达式
将方差解释中特征值大于1且累计方差贡献率大于85%为标准确定为主成分。
建立主成分得分表达式,见式(2)。其中,表示主成分中各变量的权重,可以基于式(3)建立得分系数矩阵。
式中:F为综合得分;Cj为第i个主成分的方差贡献率。
由表4可知成分1和成分2的特征值分别为3.383和1.054,对应的方差平方和分别为67.656%,19.071%。成分1和成分2的特征值均大于1,而且累计方差平方和高达86.728%,表明前两个成分可以解释数据的86.728%的信息,因此,可以选择成分1、成分2作为主成分进行水质评价。
表5为成分矩阵,主要反映各个水质指标在主成分1和主成分2上荷载的分布情况,由表4和表5综合分析可得,主成分1的贡献率为67.656%,COD、氨氮、总氮、总磷在主成分1中占有较高的载荷,表明主成分1对水质状况的影响较大,且主要反映水库受有机物污染。

表5 成分矩阵
由表6可得出主成分1和主成分2的表达式分别为:
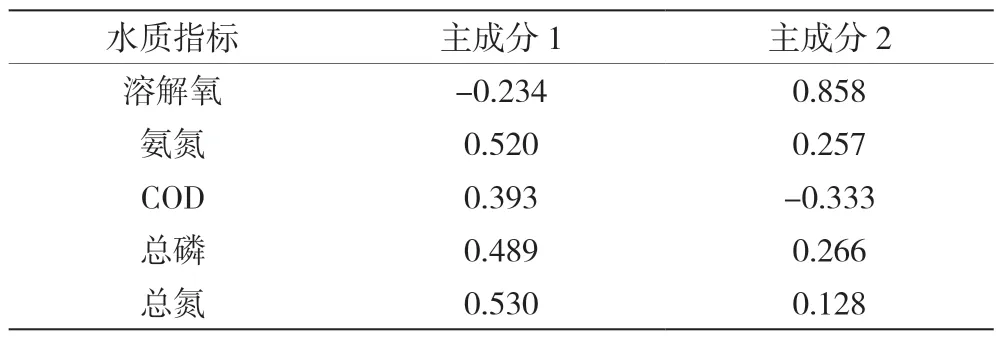
表6 得分系数矩阵
2.4 水质分析评价
基于式 (4)(5)(6),计算出磨盘山水库1月~12月与地表水环境质量标准中规定的五类水质的综合得分,并基于地表水环境质量标准中五类水质的综合得分判定水库各月份的水体质量状况。从表7中可以看出,基于主成分分析法清晰的反映出水库各月份的水体质量状况:水质达到Ⅰ类水标准有1月、2月、3月、4月、6月,共5个月;5月、7月、8月、9月、10月、11月、12月水质状况均为Ⅱ类。
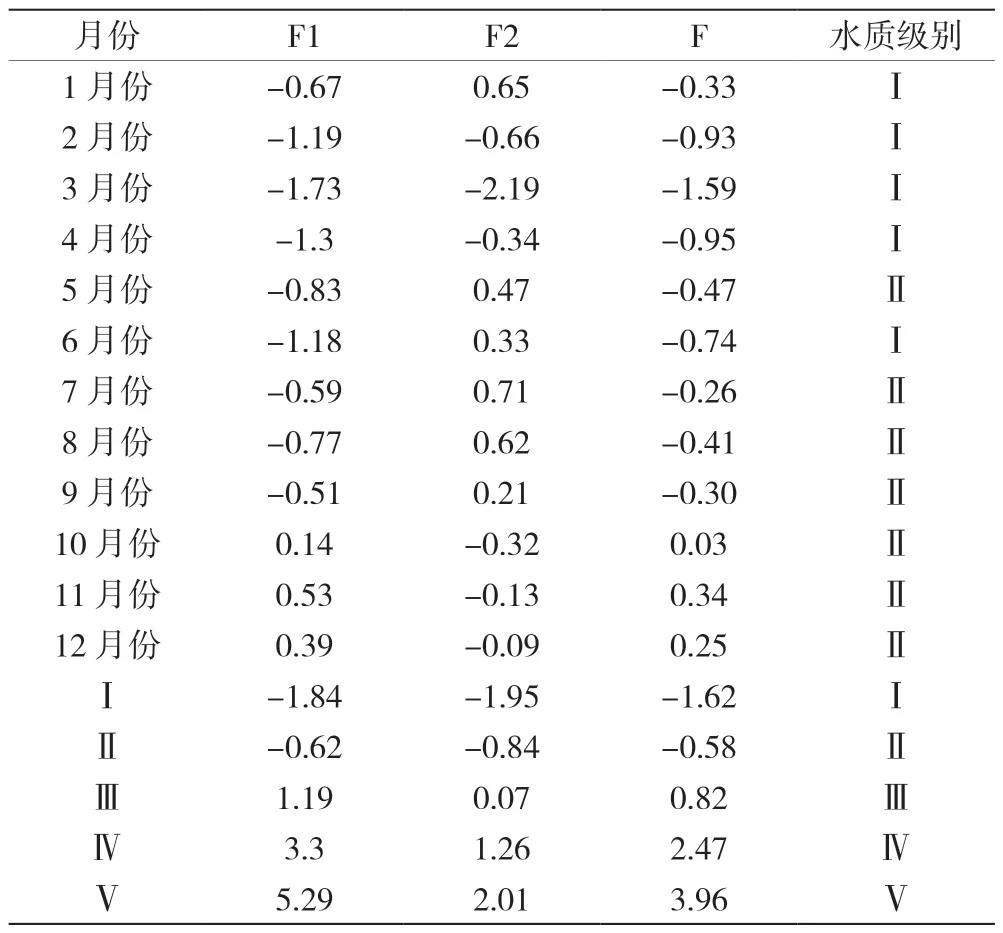
表7 主成分分析水质评价结果汇总
3 RBF神经网络评价法
RBF神经网络的核心是函数逼近理论,是一种具有较强全局能力的前馈式神经网络。RBF神经网络主要由输入层(input),输出层(output)以及隐含层(implicit layer)三部分组成。结构见图1。
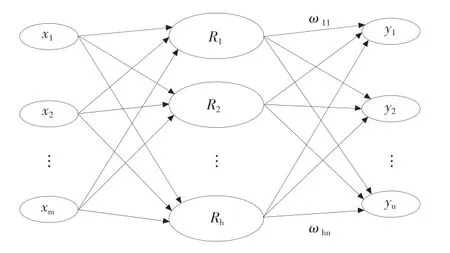
图1 RBF神经网络示意图
以RBF网络建立水质评价模型,网络的输入x为某水样中参与评价的种水质指标实测值的集合,输出为该水样的水质级别。同其它所有利用RBF网络解决问题一样,问题的关键集中在网络结构的选择、可调参数的优化方法、学习样本的代表性上。
3.1 可调参数的优化方法
典型的RBF网络中有3个可调参数:隐含层基函数中心t、方差σ,以及输出单元的权值ω。
本文用聚类方法选择基函数,可以各聚类中心作为基函数中心,而以各类样本的方差的某一函数作为各个基函数的宽度参数。隐含层到输出层的权值用最小二乘法求得,分级聚类可以看成是将N个样本划分成c个类的划分序列。第一个划分是把样本分成N个类,每类包含一个样本;第二个划分是把样本分成N-1个类,依此类推,直到第N个划分时把样本仅分成一个类。如果类数c=N-K+1,则称这个划分处于K水平。这种划分序列具有如下性质:只要在K水平时样本被归入同一类后,在进行更高水平的划分时,它们也永远属于同一类。这种分类方法较稳定,只要确定了类数,分类结果就是唯一的[10,11]。
3.2 学习样本的代表性
训练样本一般为实测的或通过计算得到的一系列一一对应的(x,y), x为输入,y为输出。然而对于水质评价,目的就是根据一定的水质判别标准建立一种评价方法,从而对水质的优劣做出合理的评价。这样就不能通过前述两种方法获取训练样本,因为实测数据只有水质指标的数值,没有对应的水质级别;如果通过某种方法计算得到一系列输入x对应的输出y值,经过神经网络学习后得到的网络结构就变成对这种方法的模仿,那就失去了应用神经网络进行评价的意义。所以对于水质评价训练样本数据只能从水质标准中获取[10]。
以地面水环境质量标准为例,首先随机产生一个1~5之间的整数,1代表水质类别为Ⅰ类,2代表水质类别为Ⅱ类,依此类推,5代表水质指标为Ⅴ类水标准。然后根据水环境质量标准在该水质类别的范围为各水质指标随机产生数值。
3.3 算法概述
3.3.1 数据标准化处理
使用MATLAB的zscore函数对训练数据进行标准化处理,以便每个特征的均值为0,方差为1。z-score 标准化(正太标准化)是基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将原始值x使用z-score标准化到x'。
3.3.2 建立训练模型及预测
本文使用MATLAB的newrb函数训练了一个RBF神经网络,训练输出为trainY。我们对trainY进行了四舍五入操作,以便将其转换为整数类型的标签trainPred。然后,我们计算了训练准确率trainAcc、平均绝对误差trainMae、均方根误差trainRmse和F1分数trainF1。
最后,使用训练好的RBF神经网络对测试数据进行预测,得到测试输出testY。我们对testY进行了四舍五入操作,以便将其转换为整数类型的标签testPred。然后计算测试准确率testAcc、平均绝对误差testMae、均方根误差testRmse和F1分数testF1。
3.3.3 评价结果
利用上述模型进行评价,结果见表8。从表8中可以看出,基于主成分分析法清晰的反映出水库各月份的水体质量状况:水质达到Ⅰ类水标准有1月、3月、4月、6月、7月共5个月;2月、5月、8月、9月、10月、11月、12月水质状况均为Ⅱ类。

表8 RBF神经网络水质评价结果汇总
3.4 对比分析
由表7和表8分析可知,两种方法在2月份以及7月份出现差异,造成此差异的原因在于两者在评价过程中侧重点不太一致。主成分分析法可以真实客观地分析当地水库水质,为水库改进完善提供一定参考。RBF神经网络只需要按照水质的各个分级标准传造出所需的训练样本,用训练完善的计算模型进行水质评价比较容易。该方法简单,具有很好的实用性。两种方法评价结果与实际结果相差不大,此研究可用作其他地区参考。
4 结论
本文应用两种评价方法对磨盘山水库进行了水质评价并对结果进行了比较,结果表明:
(1)主成分分析法相比于RBF神经网络评价法可以直观地反映水库水质问题,为水库改善提供一定参考。
(2)RBF神经网络创建训练样本较为简单,用训练完善的样本进行评价,结果更为准确,实用性也更好。
(3)水环境情况比较复杂多变,其评价方法种类丰富,因而评价结果也不尽相同。故需按照自身需求,结合当地情况,有针对性地选择方法对水质进行评价。
