增强依存结构表达的零样本跨语言事件论元角色分类*
2024-03-19张远洋贡正仙
张远洋,贡正仙,孔 芳
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
1 引言
自动事件抽取能快速定位与提取关键信息,是当今舆情追踪、信息推送等热点领域的核心技术之一。事件一般包括触发词(Trigger)和论元(Argument),其中,触发词标志着事件的发生和事件类型,论元是构成事件参与者的实体,拥有特定的角色。
如图1所示,文本“米洛舍维奇被迫逃离贝尔格勒”中的“逃离”一词为触发词,触发了“Movement-Transport”类型的事件,论元实体“米洛舍维奇”“贝尔格勒”作为该事件的参与者,对应着各自的角色:“Artifact” 和“Place”。

Figure 1 Instance of event text图1 事件文本实例
事件论元角色分类任务是对当前的事件文本,在给定触发词的情况下,判断在该触发词所代表的事件中候选论元实体所承担的角色。文本中事件的表述形式多变,其标注工作也较为复杂,比如 ACE2005事件标注语料将事件细分为了33种类型,论元分为了36种角色,其标注工作需要耗费大量人力。目前在语料资源较为丰富的英文上,事件论元角色分类已取得较好的性能[1-3],但其它更多的语言由于语料缺失,无法有效地完成有监督的模型训练。
跨语言事件论元角色分类是指模型在源语言事件文本中学习到语义和结构信息后,再对目标语言文本中包含的候选论元进行分类。根据目标语言可以提供的语料数量,跨语言一般会面对零样本(Zero-shot)和少样本(Few-shot)应用场景。本文研究零样本跨语言的处理方法在源语言事件文本中进行充分训练模型后,直接将模型应用于无标注资源的目标语言进行测试。
跨语言技术的核心是建立语言间特征的映射或者挖掘不同语言的特征表示并将其投射到统一空间中。前者一般通过双语对齐资源,例如平行语料和双语词典等,将源语言的相关特征迁移到目标语言[1,2];也可以通过机器翻译技术将2种语言转换成1种语言进行处理[3],但该方法受限于机器翻译的质量,翻译较差的文本会出现关键特征的部分甚至全部缺失,进而会影响模型的最终性能。对于后者,近年来蓬勃发展的多语言/跨语言预训练模型,例如mBERT(multilingual Bidirectional Encoder Representations from Transformers)[4]和XLM-R[5]可以将不同语言的文本投影到同一词汇语义空间,使得构建跨语言特征表示的方法得到越来越多的关注。如在跨语言文本分类任务中,徐月梅等[6]借助生成对抗网络构建带类别特征的双语词向量;施忆雪等[7]通过主题模型构建中越语言对应的主题关键词的类别特征。
上述工作主要依赖词汇语义表达来建模不同语言的类别相关性,在跨语言事件论元角色分类任务中,当前的研究主要基于文本的依存结构建模,用以消除不同语言间语序差异、文本长度差异等问题,构建相应的网络结构,如GCN(Graph Convolutional Network)[8]、Transformer[9]以及Transformer的变体GATE(Graph Attention Transformer Encoder)[9],然而这些模型依然存在相应的缺陷,GCN无法完成触发词到候选论元的长距离建模;一般Transformer编码无法建模结构性信息;GATE基于依存结构建模了长距离依赖但是缺少对触发词到候选论元路径的关注。
因此,本文提出基于增强依存结构表达的方法完成跨语言事件论元角色分类,从事件文本的语义依存树中构建触发词到候选论元依存节点路径,该路径反映了从触发词到候选论元的语义信息传递,且信息传递的平均距离小于序列层面的平均距离,更能缓解不同语言下文本长度的差异性,对路径信息进行建模后,可以对一般主流模型中的缺陷进行补足:(1)弥补了GCN无法建模触发词到候选论元的长距离结构信息;(2)较好地基于依存语义关系构建不同语言间的共性结构,弥补一般Transformer编码器缺少的结构信息;(3)对触发词到候选论元的依存路径进行了连续性建模,弥补了GATE缺少的关键路径信息。
本文实验在ACE2005数据集上进行,分别用英文、中文和阿拉伯文中的1种为源语言训练模型,以另外2种语言为目标语言进行测试。为了验证该方法的有效性和通用性,本文构建了多个主流模型并尝试将本文提出的方法与它们相联合。实验结果表明,本文方法可以有效提升跨语言事件论元角色分类的性能。
2 相关工作
2.1 单语言事件论元角色分类
事件论元角色分类工作是在给定事件触发词和事件类型情况下,对围绕该事件的待分类候选论元实体进行角色判断。在单语言下,该工作已获得了较深入的研究。Li等[10]针对中文论元角色分类,提出了基于事件相关性的全局论元推理模型,探索不同论元角色之间的语义关联。Wang等[11]针对不同的论元角色类型提出了高阶分层模型,在36种论元角色基础上,提出了8种更高阶的类别,在一定程度上对论元之间角色共性进行构建。Wei等[12]不再显式地将触发词融入模型,而以机器阅读理解的方式探寻论元和论元之间隐藏的相关性,能有效地实现对隐式论元的角色分类。Ma等[13]利用外部无标注数据构建伪标注事件抽取语料,扩充了训练数据,并在Transformer编码模块,根据输入文本词与词之间的语义依存情况,调整注意力机制的权重分数,增加关联性较强的词与词之间的交互,使得文本交互表达更具有语义关联性。Ye等[14]引入了自动学习问题模板的prompt模型,将问题模板同待处理事件文本相拼接,送入预训练模型后生成论元对应角色类别。

Figure 2 Semantic dependency tree for event text图2 事件文本语义依存树
2.2 跨语言事件论元角色分类
单语言下事件论元角色分类的研究已有多种有效方法,但跨语言事件论元角色分类的研究还处于探索阶段。2019年Subburathinam等[8]首次探索了深度学习框架下的零样本跨语言事件论元角色分类任务。该项研究工作不仅利用现成的词性标注特征和多语言词嵌入表示,还按照依存树形成的邻接矩阵,使用图卷积网络来建模词汇之间存在的某种关系。2020年Lu等[15]基于依存树以Tree-LSTM(Tree Long Short-Term Memory)模型实现文本结构化交互,同时以Transformer编码模型对文本进行序列化交互,分别获得文本的结构信息和序列信息下的表达,增加不同语言之间的一致性。2021年Nguyen等[16]进一步考虑依存结构中的关系类型,在图卷积神经网络中加入依存关系类型的向量映射矩阵作为词汇节点交互时的信息补充,避免卷积时粗糙地将子节点信息进行聚合。然而基于依存结构建模的图神经网络在实现跨语言迁移时也存在一定的缺陷,即在长距离依存路径下无法有效地完成信息的多跳传递。如在阿拉伯语中,触发词和论元的平均依存距离为12,在图卷积网络中二者作为事件的关键构成元素,却难以实现信息交互。同年,Ahmad等[9]提出GATE模型,与上述方法不同,该工作仅使用Transformer[17]编码,该编码模块在词汇节点的交互阶段保证了所有的信息传递不受距离限制,以词汇间的依存距离调整相互之间的注意力权重,使得词汇的交互仅限于依存距离阈值以内,实现了结构的交互和长距离下信息的传递。
综上所述,不同语言间的结构特征对跨语言事件论元抽取任务非常重要。在上述研究基础上,本文通过分析不同语言的论元和事件触发词在依存结构上的分布规律,提出对触发词到候选论元的依存路径进行额外编码的方法,从而进一步提高跨语言事件候选论元角色分类的性能。
3 增强依存结构表达的跨语言事件论元角色分类
3.1 依存结构对跨语言任务的重要性分析
Subburathinam等[8]研究表明依存分析结构树可以避免不同语言下序列表达的不一致性,缓解主宾谓、主谓宾等语序差异。特别地,在事件论元角色分类任务中,由于事件论元和触发词共同组成一个事件,其相互之间语义关联性非常高,使得二者在序列表达距离较远的情况下,仍能在依存结构中距离较近。
不仅如此,不同语言事件文本的表达在依存结构层面还具有相似性。如图2所示,中英文的事件文本实例均为“meet”类事件,中文实例中事件触发词“见”对应的事件中,论元“他”和“丈夫”均为“Person”角色;英文事例中事件触发词“meeting”所对应的事件中,论元“President Bush”和“several Arab leaders”也都是“Person”角色。
综上所述,将依存结构表示融合到跨语言事件论元角色分类模型中是必要的。
3.2 基于依存结构的跨语言事件论元角色分类模型
本文提出的基于增强依存结构的跨语言事件论元角色分类模型的框架如图3所示,主要包含文本编码器模块、角色分类器以及事件依存路径编码模块。具体工作可细分为以下5个过程:

Figure 3 Framework for cross-lingual event argument role classfication model based on enhanced dependency structure representation图3 基于增强依存结构的跨语言事件论元角色分类模型框架
(1)将不同语言的词汇映射到同一向量空间:本文模型使用冻结参数的mBERT预训练模型直接对包含n个词的事件文本进行编码,得到每个词汇的稠密向量嵌入表示。若mBERT分词模块把词汇划分为多个子词时,则将多个子词输出的平均池化作为原词汇表示hw。
(2)语言学特征拼接:本文利用UDPipe[18]语言学解析工具( https://ufal.mff.cuni.cz/udpipe),获得每个词的词性hp、实体类型he和依存关系类型hd3类语言学特征,并联合事件类型特征ht,将它们的嵌入表示(初始随机,后随模型训练进行学习)与(1)中的词汇表示hw相拼接得到联合嵌入表示ha。
(3)文本编码器:编码器接受长度可变的序列,并将其转换为具有固定维度的输出。在端到端的学习过程中,编码器会自动调整参数使得网络关注关键特征的表示。为了验证(4)中事件依存路径信息编码器的有效性和通用性,本文构建了适合跨语言迁移任务的3种主流模型(参见2.2节相关研究部分),包括GCN、Transformer以及GATE模型。本部分内容的详细描述见3.3节。
(4)事件依存路径编码:与(3)中关注句子全局特征表示的文本编码器不同,此处采用BiGRU(Bidirectional Gated Recurrent Unit)网络对触发词和候选论元在依存结构树上的路径信息进行额外编码,最终通过与(3)的联合来增益角色分类的判断。这是本文的工作重点,详细描述见3.4节。
(5)角色分类器:基于编码后的文本及事件依存路径信息表示对候选论元角色进行分类。
3.3 文本编码器
根据前文相关工作的调研结果,本文选取了3个有代表性的跨语言事件论元角色分类工作中使用的文本编码模型。这3个代表性模型因为采用的网络不同,对文本中词汇之间关联信息的编码方法也各不相同。
3.3.1 GCN文本结构化编码

(1)
节点邻接矩阵为An×n,第i个词和第j个词在依存树中相互邻接时Aij=1,反之Aij=0。Wl表示第l层可学习参数矩阵,b(l)表示可学习偏置,di表示第i个节点的度数。最终输出带依存结构信息的编码表示。
3.3.2 Transformer文本序列编码
Transformer[17]编码器,每层包括自注意力模块、前馈神经网络及标准化层。Transformer编码器接收输入序列的向量表示h∈Rn×d,其中,n表示序列长度,d表示向量维度,将H={h}映射到Q,V,K后进行自注意力计算。Q=hWQ,V=hWV,K=hWK,其中,WQ,WK,WV均为属于Rd×dk的可学习参数矩阵,dk为超参数,实验时dk=64。自注意力编码如式(2)所示:
(2)
自注意力编码层的输出x进一步输入到前馈神经网络层,如式(3)所示:
FFN(x)=max(0,xW1+b1)W2+b2
(3)
其中,W1,W2,b1,b2分别表示可学习的参数,W1∈Rd×dff,W2∈Rdff×d,b1∈Rdff,b2∈Rd,dff表示高维映射维度。
3.3.3 GATE文本结构化编码
GATE[9]是以Transformer编码器为核心框架的跨语言迁移模型,其核心注意力模块的输入与式(2)一致,但最大的不同之处在于,其计算模块中额外加入了词与词之间在依存结构下的距离偏置M,公式调整如式(4)所示:
(4)
其中,F(·)表示归一化函数;M∈Rn×n决定2个词之间是否相互关注。M的取值如式(5)所示:
(5)
其中,δ表示距离阈值,Dij表示输入文本中词汇节点i和词汇节点j在依存树中的距离。
3.4 BiGRU事件依存路径信息编码
前文描述的GCN图神经网络或者Transformer编码器按照依存结构中词与词的连接进行编码,能够有效地对依存关系进行表示。但是,上述工作对所有词汇间存在的依存关系都一视同仁地进行编码,虽然某些模型后期有调整,比如GATE通过依存距离矩阵屏蔽了一些无关的依存节点,从而在注意力模块使得每个词能关注更加重要(有限的距离范围内)的依存节点,在此过程中,没有区别对待触发词/论元和其它词。然而根据依存树限制了词汇节点的交互距离,也造成了触发词和论元在依存树上完整关联路径信息的缺失。因为直观上,触发词和论元都是事件的重要组成元素,相互的语义关联度更高,且二者之间的依存路径也会包含与事件信息较为相关的词汇节点。因此,若对触发词和论元之间的路径直接建模,将为事件论元角色的分类提供重要帮助。
如表1所示的ACE2005数据集中的事件文本实例,触发词“见”到论元“丈夫”,以及“meeting”到“President Bush”,考虑对如上依存路径信息的利用,或将增加不同语言的事件论元角色判断在依存结构上的统一性,有利于事件论元角色分类。于是,本文提出一种改进的跨语言事件论元角色分类方法,在基于依存结构的一般跨语言模型结构上,加入BiGRU网络建模事件触发词到候选论元的依存路径节点信息,增加对事件候选论元的关注,在依存结构上构建不同语言共有的事件表达特征。
3.4.1 BiGRU网络
BiGRU是双向的GRU[20]网络,其中GRU网络是循环神经网络RNN(Recurrent Neural Network)的一种变体,有效地缓解了RNN的反向传播时梯度消失的问题,且相较于LSTM又有着更少的参数量,不易发生过拟合,适合当前小规模事件文本的训练。网络中包含更新门“z”和重置门“r”。在t-1时刻输出为ht-1,在t时刻BiGRU更新状态如式(6)~式(8)所示:
rt=δ(Weret+Whrht-1+br)
(6)
zt=δ(Wezet+Whh(rt·ht-1)+bz)
(7)
(8)
(9)
(10)


Table 1 Dependency path of trigger word to argument in event text表1 事件文本中触发词到论元的依存路径
3.4.2 事件依存路径信息编码

{gt,gp1,…,gpk-1,ga}=BiGRU(ρ)
(11)
(12)
其中,BiGRU为双向GRU网络,FFNN为前馈神经网络。
如图4所示,抽取“President Bush is going to be meeting with several Arab leaders”中触发词“meeting”到候选论元“Bush President”的依存路径得到“meeting going Bush President”,之后将其表示拼接语言学特征后输入到BiGRU网络。构建依存路径的算法如算法1所示。

算法1 构建从触发词到候选论元的依存路径Input:List,L={li}ni=1,consisting of n word nodes,li is parent position of i-th word node,触发词位置Pt,候选论元位置Pa。Output:触发词到候选论元的依存路径L_t2a。 1.在L中,从触发词位置Pt向上逐个遍历其祖先节点,并保存到列表ancestors_t中。 2.在L中,从候选论元位置Pa向上逐个遍历其祖先节点,并保存到列表ancestors_a中。 3.取ancestors_t 和ancestors_a 交集得到触发词到候选论元的公共祖先节点,并将其保存到集合ances-tors_c 中。 4.依据公共祖先节点集合ancestors_c 建立其中的每个节点的父子关系,形成字典c_p_dict,其中键为当前节点位置,值为当前节点的子节点位置 。 5.遍历字典c_p_dict,遍历到当前节点时,如果其在c_p_dict对应的子节点位置为空,则当前节点为触发词和候选论元的最近公共祖先节点记作lca。 6.在L 中从触发词位置Pt向上遍历到lca,期间经过的节点位置保存列表 L_t2lca中。 7.在L 中从候选论元位置Pa向上遍历到lca,期间经过的节点位置保存列表 L_a2lca中。 8.删除 L_t2lca中的最后一个节点,逆转L_a2lca的顺序,将二者前后合并得到从触发词到候选论元的依存路径节点L_t2a。Return:L_t2a
4 实验与结果分析
4.1 数据集与评价指标
实验基于ACE2005的事件标注数据集,包含了中文、英文和阿拉伯文3种语言,定义了33种事件类型及围绕这些事件类型的36种论元角色(包含1种非论元角色),如表2所示。为了证明本文模型的有效性,采取了与之前工作一致的数据划分[8,9],同样在给定事件触发词和候选论元的情况下,判断候选论元在触发词所代表事件中的角色。建模阶段所用的语言学特征由UDPipe工具解析得到,包含9种实体类型、16种词性类型和35种依存关系类型。
评价标准与一般事件抽取任务相同,当候选论元所对应的事件类型、位置以及分类角色都与语料标注一致时,该候选论元角色分类才算正确。计算精确率和召回率后得到F1值,代表模型的性能。

Table 2 Event distribution of three languages表2 3种语言的事件分布
4.2 实验设置
为证明事件依存路径信息编码模块的有效性,本文选取了当前在跨语言事件论元角色分类任务上性能较高的模型作为对比基线模型,在其基础上添加本文提出的事件依存路径信息编码模块加以比较。这些基线模型输入的文本及特征的嵌入表示是一致的(参见3.2节),但在网络结构参数上存在一些差异,具体如下:
CL_GCN[9]:该模型以图卷积网络为编码框架,隐藏层维度为200,编码层数为2。在源语言上进行训练,在目标语言上进行测试。
Transformer编码器:使用传统的多头注意力结构对文本进行序列层面的交互,隐藏层维度为512,编码层数为1。在源语言上进行训练,在目标语言上进行测试。
GATE:当前跨语言事件论元角色分类的任务上的SOTA(State-Of-The-Art)模型,该模型将借助依存树为Transformer 编码层的注意力分数计算添加依存距离偏置,隐藏层维度为512,编码层数为1,注意力头数为8,其中受依存距离改动的注意力头数为4,依存距离的阈值为1,1,2,2。在源语言上进行训练,在目标语言上进行测试。
BiGRU:本文编码依存路径的网络结构,输入维度为512,隐藏层维度为200。
4.3 主要结果及分析
4.3.1 跨语言性能比较
表3中A2B表示模型在A语言上训练后,在B语言上测试。En、Zh、Ar分别表示英文、中文和阿拉伯文,CL_GCN、Transformer和GATE表示3个基准模型,GATE表现最好,平均性能达到了61.3%。没有基于依存结构的Transformer编码模型超过了CL_GCN,平均性能达到55.6%。本文认为CL_GCN模型虽能根据依存结构中词汇节点的邻接矩阵建立结构相似性,但是缺少建模长距离依赖的能力;而Transformer模型已被大量的研究证明具有长距离建模的能力。GATE模型是建立在Transformer编码基础上的,既具有长距离建模能力,又通过依存结构的距离调整了注意力权重,筛除了一些无关的节点,所以相较于一般Transformer编码模型,平均性能提升了5.7%,这一结果显示出基于依存结构特征表示对跨语言迁移的重要性,与前文3.1节中的分析一致。
表3中的实验结果也表明,加入事件依存路径编码信息之后,3个改进的基准模型(模型名称后加path标识的)的平均性能均得到提高,其中,提升最明显的是Transformer编码模型,平均提升了5.9%,特别是对于阿拉伯文到中文的跨语言迁移(Ar2Zh),甚至超出了最好的GATE模型;其次是CL_GCN模型的平均性能提升了5.5%;即使对于此前达到SOTA性能的GATE模型,也将其性能平均提升了1.3%。
4.3.2 性能提升分析
为了进一步解释性能提升的原因,本文展示基准模型加入path后准确率P和召回率R的提升率,并加以分析。如表4所示,可以观察到,从触发词到论元的依存平均距离小于序列距离,且Ar>Zh>En。
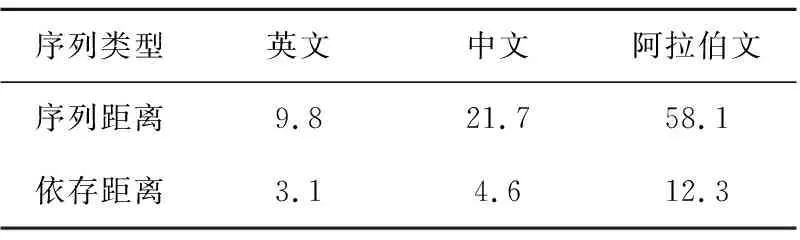
Table 4 Average sequence distance and averagedependency distance from trigger to argument表4 触发词到论元的序列和依存距离的平均值

Table 3 Performance of different models after adding event dependency path module表3 加入事件依存路径模块后不同模型的性能 %
从图5中可以看出,对于基于依存结构编码的模型CL_GCN,从平均距离较短的语言迁移到平均距离较长的语言时(En2Ar,Ez2Zh,Zh2Ar),召回率R提升率更高。容易理解,由于引入path模块后延长了触发词和候选论元的建模距离,从而能召回更多的论元。而模型从平均距离较长的语言迁移到平均距离较短的语言时(Zh2En,Ar2Zh,Ar2En),准确率P的提升率更高。同样,这是由于path模块增强了来自于依存结构的信息表达,使得信息能连续地从触发词到候选论元传递,模型对于触发词和候选论元相距较近时的角色判断更为准确。
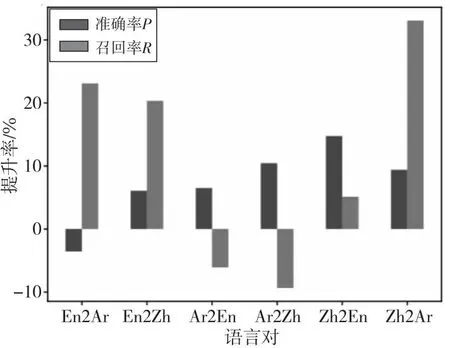
Figure 5 Improvement rate of precision P and recall R of CL_GCN after adding path module图5 加入path后CL_GCN的 准确率P和召回率R的提升率
从图6中可以看出,对于基于依存结构编码的模型GATE,在Ar2En和Ar2Eh上召回率R提升更高,是因为GATE可以通过其部分正常的注意力机制进行长距离建模,适应阿拉伯文,但是受限于距离阈值的注意力模块使得模型只能关注到部分距离以内的词,因此加入path模块后可以召回更多论元,提升召回率R。而Zh2Ar的准确率P提高,则是因为GATE已经结合结构信息和序列信息具有了长距离编码的能力,加入path后可以提高论元角色判断的准确率。
对于没有基于依存结构编码的Transformer编码器,加入path模块后较高地提升了从短距离语言到长距离语言En2Ar和Zh2Ar的召回率R,如图7所示。这是由于触发词到候选论元的距离通常小于序列层面的距离,而path模块恰好为Transformer编码器提供了从依存结构层面的编码信息,从而召回更多的论元。对于准确率P的提升,则是较好地结合了不同语言在依存结构表现出的事件共性,论元角色的判断更准确。En2Zh的准确率和召回率提升相近,主要是依存结构起到了对论元的召回和准确识别角色的作用。Ar2Zh,Ar2En和Zh2En的准确率P提升较多的原因则是相符于CL_GCN中更容易帮助模型获得短距离依存结构信息的能力;Zh2Ar和En2Ar则是体现通过依存路径缩短信息交互距离,召回更多的论元,提升召回率R。
因此,本文认为事件依存路径编码模块path具有建模不同语言间的依存结构共性和事件共性的能力,缓解了不同语言的序列表达差异性,从而更好地将源语言中的事件论元信息迁移到目标语言。
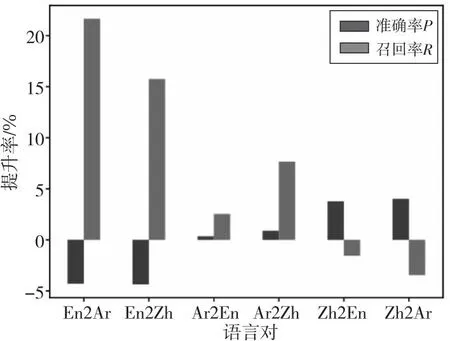
Figure 6 Improvement rate of precision P and recall R of GATE after adding path module图6 加入path后GATE的准确率P 和召回率R的提升率

Figure 7 Improvement rate of precision and recall of Transformr encoder after adding path module图7 加入path后Transformer编码模型的 准确率P和召回率R的提升率
4.3.3 单语言下的性能比较
本文分别对3种语言进行单语言下的性能对比实验,进一步验证事件依存路径模块对事件论元角色判断的有效性。
表5中的实验结果显示,3种基准模型在单语言下训练和测试时,加入path模块,其性能仍然提升明显。这说明基于依存结构的跨语言模型在事件信息的表征上仍然存在不足,而事件依存路径信息模块(path)可以一定程度上弥补,使之更充分地学习到依存路径节点中蕴含的重要事件信息。

Table 5 Performance of different models after adding event dependency path module in single language表5 单语言上加入事件依存路径模块后不同模型的性能 %
5 结束语
本文提出了围绕事件依存路径建模的跨语言事件论元角色分类方法,其中事件依存路径是指从触发词到候选论元的依存路径,对此建模不仅能体现事件文本在不同语言表达下的依存结构共性,还能将触发词到候选论元的依存节点进行连续性建模,能更好地帮助候选论元的角色分类。此外,该方法能够灵活地与一般文本编码模型进行结合,在SOTA模型GATE上分类F1值平均提升了1.3%。
本文虽然从依存结构层面建模不同语言在事件文本表达上的共性,但不同语言的事件文本对应的依存树仍然存在较大差异。例如,在ACE2005语料中,英文事件文本较短,其依存树的宽度和深度也较小;而阿拉伯文的事件文本较长,其依存树的宽度和深度较大,这也导致二者对应的依存结构具有较大差异。在未来将会考虑根据依存关系对依存树进行启发式修剪,进一步增加不同语言在依存结构上的相似性,争取再次提高跨语言事件论元角色分类的性能。
