煤矿机电设备运行状态大数据管理平台设计
2024-03-19刘艳秋
刘艳秋
(安徽恒源煤电股份有限公司设备租赁分公司,安徽 宿州 235000)
煤矿机电设备是矿业生产中不可或缺的关键要素,其运行状态直接关系到生产效率、工人安全以及矿井整体经济效益。为了更好地实现机电设备的精细化管理,提高其运行效能,我们设计了一套煤矿机电设备运行状态大数据管理平台。该平台整合大数据技术,旨在全面监控、分析和优化煤矿机电设备的运行状态。
1 总体设计思路
在各种先进技术支持下,煤矿用机电设备种类不断增加、运行数据复杂繁琐,这均导致机电设备管理面临较大难度。基于此,文章以大数据技术为基础,基于Hadoop 构建煤矿机电设备运行状态管理平台。发挥大数据优势,实现运行数据智能化管理和自动化分析,从而实现企业设备资源整合和运行数据实时监测[1]。
2 煤矿机电设备运行状态大数据管理平台设计方案分析
2.1 平台架构
结合上文对总体设计思路的阐述,该管理平台大体由五个层级组成,按照从下往上的顺序依次为资源层、数据存储层、平台层、应用层和服务层。每一层级具备独立功能,彼此之间在逻辑上存在关联,共同提供智能化服务。具体来看,资源层是基础组成部分,是整体平台运行的保障,所需的运行数据均来自该层级,主要由硬件设备、人员体系和管理系统三个模块组成。数据存储层的主要目的是存储来自资源层的数据信息,借助PLM 数据库、历史数据库、分布式数据库、云端数据库等分门别类存储数据信息。平台层是机电设备运行状态大数据处理的关键部分,其主要由数据采集、数据预处理、分布式存储、数据挖掘和数据可视化几项功能组成,借助大数据技术,结合用户需求,可以智能分析数据。应用层是用户日常应用最广泛的区域,其包括设备运行状态监控、井下设备实时监控、在线设备数据监测、设备车间维修记录等功能模块,这种结构化设计,便于用户直观查找到所需内容,并且降低系统操作难度。服务层支持各种应用整合,确保平台各功能可以独立发挥作用,也可以协同发挥作用。且该层级可以基于实际需求调整应用组成部分,及时去除不必要的应用模块,增设新的功能,这对于提供贴心式服务,保证系统服务过程透明化有积极作用。
2.2 设计中涉及的关键技术
2.2.1 高通量数据管理技术
高通量数据管理技术是指针对大规模产生、采集和处理的数据,采用先进的管理方法和工具,以确保数据的高效存储、检索、处理和分析。文章应用HBase分布式数据库,并且应用RDF 数据存储模型作为基础。该技术应用过程中可以有效提升查询结果的准确度,并且在一定程度上提升查询效率。虽然煤矿机电设备运行状态大数据日益复杂、繁琐,但基于该技术,可以实现高效、准确检索和查询[2]。
2.2.2 多源数据融合技术
多源数据融合技术是在面对来自不同数据源的多样化数据时,将这些数据整合为一个一体化的数据集,以提供更全面、准确的信息。这涉及数据清洗、对齐、特征融合、模型融合等关键步骤。文章借助该技术,确保中间数据库实现智能化整合,也就是借助中间数据库的对应接口表,确保平台可以从多层次采集设备运行状态,例如结合物料表结构确定设备状态、结合环境因素确定设备运行状态等。基于该技术可以实现数据和企业核心语义结构物理对象结点兼容,也就是进一步展现数据整合优势,避免出现信息孤岛现象。同时,该技术的应用使得平台可以更为准确、详细描述资源,围绕设备运行状态更为全面定义数据资源集,从而确保查询、检索过程中,可以基于表征实现高效筛选,并关联展示设备的各项参数信息。
2.2.3 并行化数据处理技术
并行化数据处理技术是通过同时处理数据的不同部分,以提高数据处理速度和效率的技术。文章在平台设计过程中,引入机器学习算法,构建数据清洗模型和数据预警分析模型,发挥智能技术确保数据自动进行预处理,不仅可以更为高效地识别各种类型设备的运行状态,及时获取大数据信息,还可以依据一定特征对数据进行分类。同时,该技术可以在一定程度上修复异常值,提升平台容错率,避免由于系统故障影响管理效果。另外,在设计数据清洗模型时,借助MapReduce 技术,足以保证数据清洗具备智能化特点[3]。
2.2.4 数据可视化技术
数据可视化技术是将抽象的数据通过图形化的方式呈现,使人能够更直观、清晰地理解数据的含义。文章在思考管理平台设计过程中,借助setOption方法、Sjax 技术等,确保数据信息可以自动化生成图表,如此更便于用户查看信息数据。
2.3 功能模块阐述
结合上文阐述,煤矿机电设备大数据管理平台中,为了实现预期目标,充分发挥结构化优势,确保数据采集模块、数据预处理模块、分布式存储模块、数据挖掘模块等充分发挥效用是关键。数据采集模块主要发挥采集信息源的作用,其可以收集来自传感器、企业设备、历史数据及企业其他系统中的相关信息,从而为数据分析和示警等功能实现奠定坚实的基础。数据预处理模式的主要目的是为平台提供便于计算、分析且格式统一的数据基础,该模块通过设备监控数据建造约简化处理、元数据提取、数据转换等,确保最终结果系统平台内部模型格式,可以完成分析。分布式存储模块是信息存储的主要场所,该部分包含多个数据库,例如分布式数据库、历史数据库等,可以分门别类存储相关信息,且该模块还具备备份功能,可以有效预防信息丢失问题发生。数据挖掘模块主要作用是借助机器学习算法等,智能化依据需求完成数据分析。数据可视化模块包括三方面内容,其中企业运行可视化是展现煤矿企业机电设备信息的渠道,设备运行状态可视化是展示机电设备实时运行数据的主要途径,设备健康状态展示是示警信息展示载体。上述五大模块中又基于具体功能细化为多个子模块,这些模块协同运行、有效衔接,共同组成管理平台[4]。
3 系统测试分析
为了直观验证文章提出的机电设备运行状态大数据管理平台设计方案的科学性和实用性,文章在此营造测试环境,通过模拟现实应用场景,验证该平台的各项功能,以直观化数据证明该平台的优越性。
3.1 测试平台搭建
在此应用IBM-S822LC 服务器,搭建Hadoop 集群。并且设置1 台虚拟机作为主节点,再设置2 台虚拟机作为从节点。测试环境硬件配置见表1 所示。而虚拟机的软件配置见表2 所示。
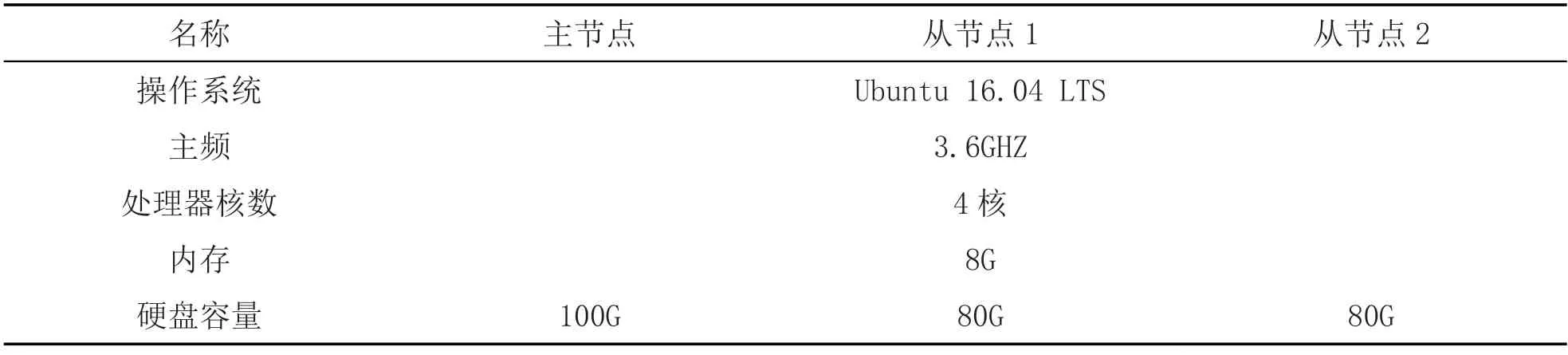
表1 平台集群硬件配置总结表

表2 虚拟机软件配置总结表
3.2 RDF 数据存储模型试验验证
为了验证RDF 数据存储模型的实用性能,在此应用文章提出的平台架构方案,搭建管理平台,应用平台加载、解析大量RDF 数据。涉及的数据来自经过设备运行状态大数据平台处理后的RDF 数据[5]。为了直观展示存储性能,在此以传统的基于Oracle 集群的平台为对照组进行对比试验,最终所得结果如图1 所示。
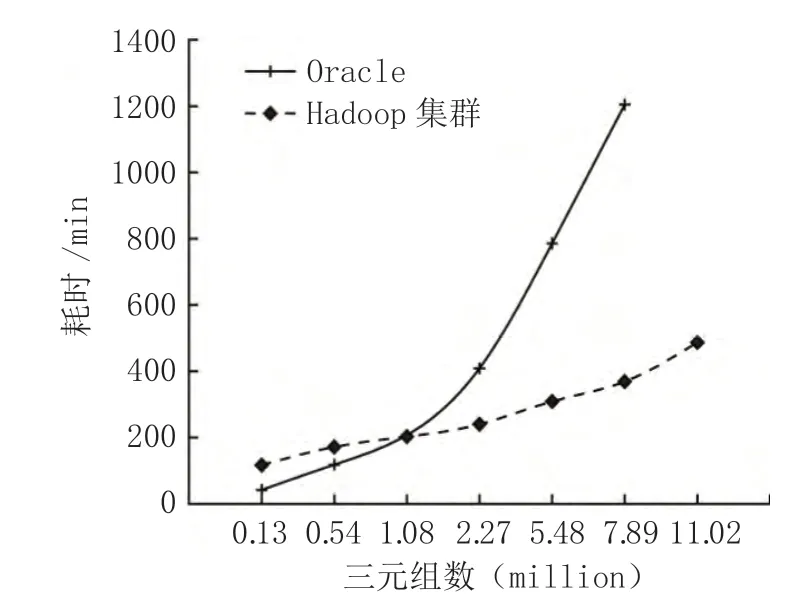
图1 RDF 数据解析和加载时间对比图示
结合图1 可知,虽然在三元组成低于1.08 百万时,Oracle 系统更具有优势,效率更高,但当三元组数据量超过1.08 百万时,文章提出的方法具备明显优势,且随着数据量增大优势更为明显。
3.3 并行化数据处理模型试验验证
在此借助搭建的测试环境,对提出的管理平台并行化数据处理效果进行检验。通过在搭建的平台上对设备运行状态大数据进行清洗、降噪和缺失值修复,验证相关模型的应用性能[6]。将基于时间序列的清理模型设为对照组,从而直观展示模型价值。最终所得结果如图2 所示。
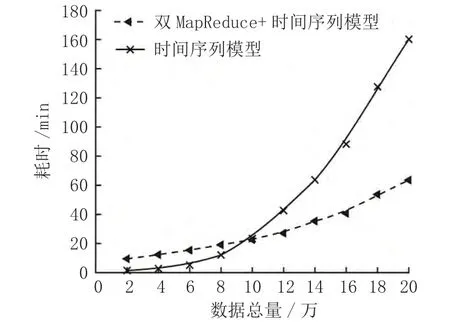
图2 数据清洗时间对比图示
结合图2 来看,在数据量低于10 万时,基于时间序列的模型更具备优势,但随着数据量增加,文章提出的模型优势日益明显。
4 结语
文章结合实际需求,基于Hadoop 搭建煤矿机电设备运行状态大数据管理平台,该平台采用结构化设计模式,通过细化功能模块,确保各功能划分合理且便于用户应用。
最后,为了验证文章提出设计方案的应用价值,通过搭建测试环境的方法,采取对比验证模式对系统功能进行检测。
结果证明,该方案可以大幅度提升数据管理能力和管理效率,最大限度地避免出现由于机电设备故障导致的安全事故。
