基于深度学习的用气趋势预测与管网气量调配算法
——以中国石油西南油气田公司为例
2024-03-15吴玙欣周钦宇杨云杰邓启志赵咏谭卓邓觅
吴玙欣 周钦宇 杨云杰 邓启志 赵咏 谭卓 邓觅
(1.中国石油西南油气田公司川西北气矿,四川 江油 621700;2.中国石油西南油气田公司数字智能技术分公司,四川 成都 610051)
0 引言
随着两化融合(信息化和工业化的高层次深度结合)的不断加深,为了更好地降本增效,提高企业运营效率,各大油气企业加快了各类信息系统建设的脚步[1]。其中,生产实时数据的采集、分析与应用可支撑生产过程的自动化控制,保障油气田生产运行的可靠性和安全性[2]。中国石油天然气股份有限公司西南油气田分公司(以下简称西南油气田)现已实现天然气生产实时数据的采集、传输和存储,通过现场层(单井和阀室RTU)、监控层(SCS 站控、RCC区域控制中心)、调度层(气矿调度中心)和应用层(生产数据平台、生产运行管理平台、生产指挥管理系统、A2等应用系统)的数据互联,实现了生产数据自动采集、远程集中监控、关键阀门远程控制、远程视频监控等应用[3]。但目前,利用人工智能等算法技术对实时数据进行挖掘、分析和应用的程度还不够,依靠传统经验的生产决策不能较好地支撑业务管理[4]。因此,研究如何使用实时数据支撑业务管理和生产决策,进一步提升油气田智能化建设水平,显得尤为关键。
为深化数据利用,西南油气田某气矿接入pSpace 实时数据与A2 系统生产数据,构建一套应用系统,研究利用深度学习神经网络对终端用户的用气量进行趋势预测,实现市场需求变化的提前感知,支撑生产运行计划的制订。同时研究一种管网气量调配的算法,从最少调配次数和最接近标定产能两种角度提供井口产量的调配建议,有效减少了井口产量调整的时间与人工成本。
1 异常值检测
为使获取的数据真实有效,需要对数据进行异常值检测和数据筛选,该功能模块集成了基于分布的异常值检测N-Sigma、基于聚类的异常值检测DBSCAN[5],实现了异常检测结果的在线可视化分析。图1 展示了2023 年4 月13-14 日双探3 井的历史数据通过DBSCAN 异常值检测后的正常运行区间和可视化结果。通过异常值检测,去除数据中可能存在的异常值,对数据进行清洗,保证使用数据的准确性,可生成工艺参数的正常运行区间,减少人为分析工艺运行情况的工作量。

图1 双探3井DBSCAN异常值检测结果
2 用气量趋势预测
2.1 时间序列预测技术
时间序列是一组按时间变化而变化的随机变量,它通常是在相等间隔的时间段内依照给定的采样率对某种潜在过程进行观测的结果[6]。时间序列数据本质上反映的是某个或者某些随机变量随时间不断变化的趋势,而时间序列预测的核心就是从历史的序列数据中挖掘出变化规律,并利用该规律对后续时间对应的数据做出预估[7]。针对不同场景,时间序列预测目标可以分成点估计、概率预测和区间预测三种不同类型。其中,点估计方法认为时间序列预测模型输出的是预测值;概率预测方法认为时间序列本身就是一组随机过程,因此更倾向于估计出时间序列在未来的分布;区间预测则描述预测值可能的上下限[8]。
传统时间序列预测方法主要是在确定时间序列参数模型的基础上,求解出模型参数,并利用求解出的模型完成未来预测工作。典型的方法有自回归综合移动平均模型(Auto Regressive Integrated Moving Averages,ARIMA)[9]、可捕捉季节性的Holt-Winters 法[10]。基于机器学习的方法中,具有代表性的有支持向量回归(Support Vector Regression,SVR)[11]、梯度渐进回归树(Gradient Boosting Regression Tree,GBRT)[12]、隐马尔可夫模型(Hidden Markov Model,HMM)[13]。基于深度学习的方法通过多个非线性层来构建以往时间序列的特征表示,从而学习时间序列内部变化规律。
2.2 用气量趋势预测模型
用气量趋势预测即为根据现场持续采集并累积的用气量实时数据,对未来一段时间内的用气量变化趋势进行预估。在滚动预测窗口大小固定条件下,给定模型输入序列,期望预测序列[14],基于深度学习进行用气量趋势预测。深度学习能够更好地进行高维数据表征,从而减少对手动特征工程和模型设计的需求,并通过定义损失函数,可以更加便捷地进行端到端的训练。具体选用的模型为Informer[15]。
Informer 是一类基于自注意力神经网络的模型,通过Transformer 捕获长时间序列的依赖关系。其网络结构如图2 所示,网络主体由编码器和解码器组成,两者均使用了ProbSparse注意力层来减少注意力计算的时间复杂度,编码器中采用了自相关蒸馏操作来缩短每一层的输入序列长度,而在解码器中使用了生成式的推理可通过单轮计算获得序列预测结果。Informer将输入序列Xt划分为编码器输入Xen和解码器输入Xde,并在解码器输入的后端用0 值填补,通过多层自注意力的计算建立时间序列的依赖关系,最后通过全连接层计算预测序列中每个时间点位对应的值。

图2 Informer网络结构[15]
2.3 数据处理
在构造训练数据时选取18 个供气用户共8 个月的历史用气量数据,按分钟为间隔单位划分序列,对单位时间内存在的多个值做平均处理。作为训练数据x,对x进行标准归一化处理,使其均值μ=0、方差σ=1。xt为归一化之后的数据,其计算方式如下:
除了使用气量时间序列数据外,还考虑了时间本身向量化后的值作为额外输入特征,对年、月、日、小时、分的特征F分别进行归一化,Ft为归一化后的时间特征,根据最小值Fmin和最大值Fmax归一化至[-0.5,0.5]区间内[16]。归一化时间特征Ft的计算方式为:
2.4 模型训练
训练模型采用的损失函数为均方误差(Mean Square Error,MSE):其计算方式可写为:
其中,n为训练时单步迭代使用的数据量,Yi为真实序列,为模型的预测序列。为实现1 小时长度的序列预测,在模型训练时使用的输入序列长度Lx为360,其中前240项数据作为编码器的输入,120项数据作为解码器的输入;预测序列的长度Ly为60;单步迭代使用数据量n为32;数据集迭代轮次为6;训练集和测试集按7∶3划分。
2.5 结果分析
该用气量预测模型在测试集上的预测平均绝对误差MAE=0.165 9、均方误差MSE=0.082 1。图3展示了某用户用气量真实序列与模型预测序列的对比,数据进行了归一化的处理,横轴为序列长度。由结果可知,该用气量预测模型能在较低的误差下预测未来一段时间内的用气量变化。

图3 基于Informer实现的小时用气量预测结果
3 管网气量调配
3.1 气量调配算法
为进一步辅助生产决策,构建了一套基于管网汇总气量的井口产量调配算法,从最少调整次数与最接近标定产能这两种角度提供调配建议。
基于给定的井列表从A2 读取标定产能,并统计每口井的历史日产数据,获得日产量的上限与下限,同时根据实时数据点位获得当前瞬时流量。本方法定义井产量的可能值存在于0(关井状态)或最小值与最大值的闭区间(开井状态)。因此,在下调产量时,为实现最少调整井数,每口井的下调值可能为当前产量(关井时)、当前产量减最小产量、总产量与目标值的差值。在上调产量时,每口井的上调值为最大产量减当前产量、总产量与目标值的差值。同时,为实现最接近产能标定值调配,本方法采用产能标定值的百分比来定义井当前产量与标定产能间的距离,计算公式为:(当前产量-标定产能)/标定产能。若越接近0 则代表越接近产能标定值。在进行调整时,每口井的下调值为当前产量、当前产量减最小产量或标定产能的百分之十、总产量与目标值的差值。在上调产量时,每口井的上调值为最大产量减当前产量或标定产能的百分之十、总产量与目标值的差值。具体计算的流程如图4 所示。两种调配算法均优先考虑不进行关井减产,在关井时则通过递归查找确保调配方案为最优。若目标产量落在0与最小值区间内或大于所有井最大产量的累计,在上述约束条件下则无法完成调配方案的生成,此时算法会将当前得到的近似解作为结果返回。
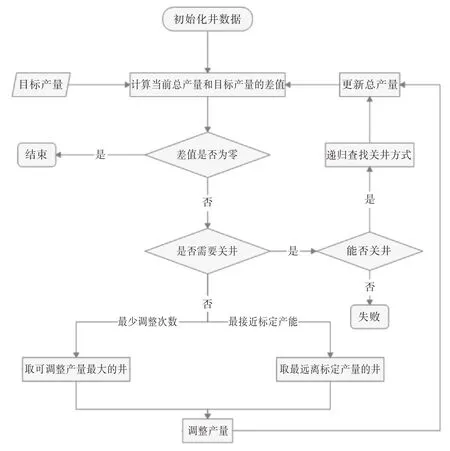
图4 气量调配算法流程
3.2 气量调配应用系统
为实现气量调配算法的实时应用,基于B/S 架构开发了一套气量智能调配分析系统,后端采用Flask 框架、前端采用Element UI,其基础的功能模块包含井列表管理、气量调配。
列表管理可实现井的增删和属性修改,该系统通过绑定井名和实时数据点位获取A2系统的日产数据与pSpace 实时数据。新增井后,每口井的当前产量采用定时任务从pSpace中读取。
气量调配时需选中井列表中对应的井名,输入目标产量并选择调配方式,可使用最接近标定产能调节和最小调整次数分别获取的调配建议。
4 结论
1)生产实时数据是油气生产的重要资产,目前主要用于生产场景监测、报表数据生成等方面,数据深化应用有很大的挖掘空间,对气田精细管理、效益提升具有重要意义。
2)通过对生产历史数据的处理,可对异常值进行分析和过滤,从而获取能使用分析的数据,并且能生成参数的正常运行区间,对有效数据提取、指导工艺参数运行范围具有重要意义。
3)通过神经网络进行用户用气量小时趋势的预测,能较好地捕获未来一段时间内的用气量变化趋势,从而实现需求变化的提前感知。
4)通过构建最少调整次数和最接近标定产能两种基于管网汇总气量的井口产量调整算法,可以实现气井生产管网调配方案的自动计算,减少人工计算分析管网气量调配的工作量。
5)用气趋势预测与管网气量调配算法和模型仍存在改进的空间,采用的时序预测模型为单变量预测单变量,输入的特征维度有限,在一定程度上限制了模型的训练效果,未来可从多变量预测单变量、多变量预测多变量两种角度出发不断将算法模型进行迭代;该管网气量调配算法只考虑了实时产量,压差、温度、管网结构、地质条件等因素未涉及在内,可考虑通过全面的管网建模进行更为准确的仿真计算。
