Personality Trait Detection via Transfer Learning
2024-03-13BasharAlshouhaJesusSerranoGuerreroFranciscoChiclanaFranciscoRomeroandJoseOlivas
Bashar Alshouha ,Jesus Serrano-Guerrero,⋆ ,Francisco Chiclana ,Francisco P.Romero and Jose A.Olivas
1Department of Information Technologies and Systems,University of Castilla-La Mancha,Ciudad Real,13071,Spain
2Institute of Artificial Intelligence,School of Computer Science and Informatics,De Montfort University,The Gateway,Leicester,LE1 9BH,UK
ABSTRACT Personality recognition plays a pivotal role when developing user-centric solutions such as recommender systems or decision support systems across various domains,including education,e-commerce,or human resources.Traditional machine learning techniques have been broadly employed for personality trait identification;nevertheless,the development of new technologies based on deep learning has led to new opportunities to improve their performance.This study focuses on the capabilities of pre-trained language models such as BERT,RoBERTa,ALBERT,ELECTRA,ERNIE,or XLNet,to deal with the task of personality recognition.These models are able to capture structural features from textual content and comprehend a multitude of language facets and complex features such as hierarchical relationships or long-term dependencies.This makes them suitable to classify multilabel personality traits from reviews while mitigating computational costs.The focus of this approach centers on developing an architecture based on different layers able to capture the semantic context and structural features from texts.Moreover,it is able to fine-tune the previous models using the MyPersonality dataset,which comprises 9,917 status updates contributed by 250 Facebook users.These status updates are categorized according to the well-known Big Five personality model,setting the stage for a comprehensive exploration of personality traits.To test the proposal,a set of experiments have been performed using different metrics such as the exact match ratio,hamming loss,zero-one-loss,precision,recall,F1-score,and weighted averages.The results reveal ERNIE is the topperforming model,achieving an exact match ratio of 72.32%,an accuracy rate of 87.17%,and 84.41% of F1-score.The findings demonstrate that the tested models substantially outperform other state-of-the-art studies,enhancing the accuracy by at least 3% and confirming them as powerful tools for personality recognition.These findings represent substantial advancements in personality recognition,making them appropriate for the development of user-centric applications.
KEYWORDS Personality trait detection;pre-trained language model;big five model;transfer learning
1 Introduction
Personality trait detection is a research field whose main goal is to identify and analyze an individual’s inherent psychological characteristics.These traits are typically categorized following personality models such as the Big Five [1] or the Myers-Briggs Type Indicator (MBTI) [2].The analysis of personality traits provides immense value across diverse domains such as psychology,human resources,digital marketing,and personalization[3].Moreover,it enables various applications such as user profiling [4],targeted content recommendations [5],and mental health assessments [6],among others.
The rapid development of Internet technologies has opened new opportunities for detecting personalities beyond the traditional costly mechanisms.Social networking sites have impelled individuals to share their opinions,ideas,and emotions with others,which reflects their behavior patterns,attitudes,and personality.There is a robust link between people’s temperament and behavior and their comments posted on social networks[7].For this reason,many researchers are currently interested in developing automatic personality classification systems from social networks.
Most of the current studies on personality trait prediction are based on classical machine learning techniques as well as new recent deep learning architectures,demonstrating their effectiveness in this domain.Most of these techniques are based on modeling lexical and linguistic features from text,and even adding extra features from social networks as it is described in detail in the literature section[8–12].Nonetheless,the accuracy of the achieved results is still improvable.One of the reasons is the limited availability of datasets for training the state-of-the-art techniques;furthermore,the used datasets are usually very small.These techniques also present some limitations such as the inability to capture nuanced and context-aware semantics of text going beyond traditional word embeddings such as Word2Vec and GloVe.This is essential for addressing challenges such as polysemy,where words have multiple meanings in different contexts,a factor that can introduce ambiguity in personality trait detection.Another limitation is the inability to deal with out-of-vocabulary terms,that is,terms not used when training the models.For that reason,to overcome these limitations,it is proposed the use of pre-trained language models(PLMs)which have undergone extensive pre-training on vast amounts of textual data employing different types of tasks,which empowers them to outperform traditional methods.This intensive pre-training provides PLMs with the ability to understand language intricacies at a deep level,which can be particularly beneficial when fine-tuning personality detection models.
Therefore,this study presents a new framework able to integrate and adapt different PLMs to detect multiple personality traits.Additionally,this research tests the proposal by introducing a robust set of evaluation metrics (exact match ratio,hamming loss,and the weighted average of precision,recall,and F1-score) to measure the efficiency and effectiveness of personality trait detection based on PLMs.This fact allows offering a more comprehensive and insightful evaluation of its results.
To sum up,the primary contributions of this study are:
• To study the capabilities of transfer learning applied to personality detection with the aim of improving the effectiveness of the current methods,especially,when the available datasets are small.
• To propose a general framework for fine-tuning different PLMs to detect multiple personality traits accurately.
• To study the effectiveness of the proposal against other recent state-of-the-art studies based on traditional machine learning techniques and deep learning architectures.
• To perform a deep analysis of the obtained results comparing the effectiveness of the different PLMs.
The remainder of the paper is organized as follows: Section 2 describes the most relevant studies on personality recognition and transfer learning whereas Section 3 explains in detail the proposed framework integrating the different PLMs.Section 4 describes the experimental setup and Section 5 presents the results of the performed experiments analyzing the achieved results.Finally,the conclusions reached are mentioned in the last Section.
2 Literature Review
2.1 Transfer Learning in Natural Language Processing
Transfer learning has emerged as a powerful technique for machine learning [13],particularly in the field of natural language processing (NLP),where it has demonstrated superior performance in text classification tasks regarding previous traditional techniques[14].Unlike traditional machine learning approaches,transfer learning allows the transmission of knowledge from a source domain to a target domain,even when the data in these domains may differ[15].
One of the key benefits of transfer learning in NLP is its ability to handle situations where the target domain has insufficient training data.By leveraging information from a different but related source domain,transfer learning enables predictions to be made on unseen instances in the target domain.This capability is especially valuable when there is limited data available for a specific problem,but there are many for a related problem[16].Transfer learning serves as a technique for improving the performance of a learner,such as a classifier,by transferring knowledge between two domains[17].
In NLP,transfer learning encompasses various types of learning such as domain adaptation[18],cross-lingual learning[19],or multi-task learning[20].The adaptation of pre-trained models to downstream tasks exemplifies a sequential transfer learning task,where tasks are learned sequentially,and the target task benefits from labeled data.Through this sequential transfer learning process,the knowledge acquired from the source task or domain is effectively adapted and applied to the target task or domain[21].
PLMs have transformed the landscape of NLP,particularly in the realm of text classification.Text classification relies on the accurate interpretation and categorization of textual data.In the context of text classification,PLMs provide several advantages.First,through pre-training,PLMs acquire universal language representations,enabling them to capture nuances and semantics across diverse contexts.This comprehensive understanding greatly enhances their performance in downstream tasks.Second,pre-training serves as a strong initialization for the models,expediting convergence and improving generalization.Lastly,pre-training acts as a form of regularization,mitigating overfitting risks in scenarios with limited training data.
One of the most well-known examples of the PLMs is BERT.BERT has garnered widespread adoption and utilization across diverse NLP tasks such as sentiment analysis[22],question answering[23] or text summarization [24].Nonetheless,BERT’s large model size presents challenges when it comes to training the model from scratch.To address this concern,researchers have devised optimized variants and compression techniques such as DistilBERT[25],ALBERT[26],or RoBERTa[27].These models offer efficient alternatives,efficiently reducing the model size and computational demands while preserving or even enhancing its performance.
Furthermore,self-supervised learning helps improve pre-trained models in different tasks for NLP as it is applied in[28].These methods are also becoming increasingly popular in computer vision.One example of is the Masked Autoencoders (MAE) framework [29].MAE was initially developed for image processing but has since evolved into a versatile tool that can handle a variety of data types such as video,audio,or temporal predictions[30,31].SemMAE[32]is a significant advancement in this field,introducing a new concept called Semantic-Guided Masking.
2.2 Personality Detection
Artificial intelligence has gained visibility across various domains due to its capability to address complex problems through advanced data analysis and predictive capabilities.Some recent applications showcasing its significance can be,for instance,automated language translation [33],image recognition [34],groundwater storage change forecasting [35],climate change forecasting [36],or environmental change analysis[37],among many others.
Personality prediction is another area that is gaining momentum.Numerous studies have been recently conducted,especially,using traditional machine learning algorithms and applying different feature selection techniques to construct feature vectors [38–41].Many studies indicate that there is a high correlation between textual features and personality traits.For instance,Tadesse et al.[11]studied the relationship between linguistic features and personality behavior using different classifiers.According to the results,the XGBoost classifier using social network analysis (SNA) features outperformed the other models.In another study,Amirhosseini et al.[42] developed a new method also based on XGBoost to predict personality according to the MBTI types.Azucar et al.[43]investigated the correlation between the Big Five personality traits and negative textual information.Han et al.[44] proposed an interpretable personality detection model based on a personality priorknowledge lexicon,that studied the relationship between term semantic categories and personality traits.Kumar et al.[45] extracted features using the global vectors for word representation (GloVe)model and TF-IDF to feed an ensemble model integrating SVM and extreme gradient boosting(XGBoost)as classifiers.In this case,the absence of demographic data,such as age and gender,limits its ability to provide nuanced and context-aware personality predictions.
Apart from traditional machine learning techniques,the development of new deep learning architectures has allowed researchers to improve the results of the task of personality trait categorization.For instance,Majumder et al.[46] utilized a convolutional neural network (CNN) to extract semantic features integrated with document-level stylistic features to classify personality traits.Sun et al.[47] proposed the concept of latent sentence to present the abstract feature integration,which was integrated into a bidirectional long short-term memory(Bi-LSTM)-CNN architecture.In[48],a hybrid deep learning model integrating CNN with the LSTM was developed to identify eight personality traits.Tandera et al.[9]tested different machine learning and deep learning algorithms to classify personality traits based on the Big Five personality model.Furthermore,they utilized different feature selection and resampling techniques to improve their performance.
Rahman et al.[49]investigated the impacts of various activation functions in CNNs.Xue et al.[50]proposed a personality classification model based on an attention mechanism applied to a recurrent conventional neural network(RCNN)combined with a CNN,which is eligible for learning intricate and hidden semantic features from textual content.Other research studied the correlation between personality traits and emotion[12].
Zhao et al.[51] introduced an innovative method using an attention-based LSTM model,leveraging users’theme preferences and text sentiment features as attention information to improve the accuracy of the results.Moreover,Wang et al.[52]presented a hierarchical hybrid model,HMAttn-ECBiL,which integrates self-attention,CNN,and BiLSTM modules to capture word-level and postlevel contributions to personality information and dependencies between scattered posts.
In other recent studies,researchers have harnessed the power of machine learning and deep learning models to predict personality traits from a variety of data sources.Ren et al.[53]explored a novel multi-label personality detection model,incorporating emotional and semantic features from user-generated texts.Anari et al.[54] proposed a lightweight deep convolutional neural network for personality trait prediction based on Persian handwriting,demonstrating reasonable results for various traits.Furthermore,William et al.[55] provided insights into the connection between personality traits and entrepreneurial success,emphasizing the significant impact of the different personalities detected.Kamalesh et al.[56] delved into predicting personality traits based on social media interactions,employing a Binary-Partitioning Transformer with the Term Frequency and Inverse Gravity Moment approach,which enhances trait prediction.Ramezani et al.[57]proposed five new methods,including deep learning-based approaches,to enhance the accuracy through ensemble modeling and hierarchical attention networks.Lastly,Suman et al.[58]combined data from various modalities such as text,facial features,and audio,revealing the potential of deep learning-based personality prediction across multiple dimensions.
Focusing on different applications of transfer learning,El-Demerdash et al.[59] proposed the use of the Universal Language Model Fine-tuning(ULMFiT)to detect personality traits.The results indicate that the use of ULMFiT improves accuracy by about 1%in comparison with the most recent methods.Aslan et al.[60] also addressed the problem of categorizing personality traits from videos by leveraging embeddings from language models to construct a multimodal framework to classify personality traits.Mehta et al.created a model using contextualized embeddings and psycholinguistic features[61].The results demonstrate that the language model features from BERT[62]combined with an MLP outperform traditional psycholinguistics features.In another study,El-Demerdash et al.[10]proposed a new deep learning model that takes advantage of PLMs such as Elmo,ULMFiT,and BERT,using both classifiers and data-level fusion.Among the limitations found,the incorporation of emotion and slang-based features,as well as the recognition of personality traits in multimedia content can be mentioned.
3 Proposal
The goal of this study is to detect multiple personality traits over texts taking advantage of diverse transfer learning technologies.For that reason,the proposed architecture has been designed to integrate different PLMs which will have been fine-tuned to recognize the personality traits following the Big Five model.The effectiveness of the selected models has been demonstrated in NLP tasks:
•BERT(Bidirectional Encoder Representations from Transformers)is a language representation model that was first presented in[62].It is a bidirectional transformer model pre-trained on a huge unannotated dataset,which can be adapted for a large variety of downstream NLP tasks.BERT uses the masked language model(MLM)and next sentence prediction(NSP)to achieve language comprehension.The“bert-base-uncased”1https://huggingface.co/bert-base-uncasedversion has been used in the experimental section,which makes no distinction between lowercase and uppercase terms.
•RoBERTa (Robustly Optimized BERT-Pretraining Approach)is an enhanced version of the BERT model.It is derived from BERT’s MLM strategy adjusting its critical hyperparameters.It eliminates the NSP task,provides dynamic token masking during the training phase,and can enhance the performance on many downstream tasks because it is trained with additional batch size and learning rate[27].For the experiments,the“roberta-base”2https://huggingface.co/roberta-baseversion has been utilized.
•ALBERT (A Lite BERT)is a transformer model that has been self-supervised and trained on a significant corpus of English data.It is a lite BERT that minimizes BERT’s parameters integrating two-parameter reduction techniques,which enables the model to share parameters between layers,operates as a stabilizing factor when training,and assists in generalization.It uses factorized embedding parameterization and cross-layer parameter[26].In the experimental section,the“albert-base-v1”3https://huggingface.co/albert-base-v1uncased version has been used.
•XLNetis a PLM based on transformers.Instead of MLM and NSP,it employs an autoregressive approach to learning bidirectional contexts by predicting tokens in a given sequence in a random order,which helps the model capture a more accurate relation between tokens in a particular sequence[63].The“xlnet-base-cased”4https://huggingface.co/xlnet-base-casedversion has been selected for the experiments.
•ELECTRAis another pre-training method whose fundamental goal is to detect replaced tokens in input sentences using two transformer models: the generator and the discriminator.The generator function is used to create tokens to replace some of the original tokens,whereas the discriminator attempts to determine which tokens in the sequence were replaced by the generator [64].The“google/electra-small-discriminator”5https://huggingface.co/google/electra-small-discriminatorversion has been assessed in the experimental setup.
•ERNIE(Enhanced Representation through kNowledge IntEgration)acquires language representations utilizing knowledge masking techniques[65].It is a continuous pre-training system that incorporates lexical,syntactic,and semantic information through massive data via multi-task learning,consequently boosting its existing knowledge base.In the experimental setup,the“nghuyong/ernie-2.0-en”6https://huggingface.co/nghuyong/ernie-2.0-enversion has been used.
3.1 Architecture of the Proposal
The workflow diagram depicted in Fig.1 consists of several crucial functional blocks,each one playing a unique role in the architecture of PLMs.First,the“Masking Techniques for Input”block preprocesses the input text data by masking specific tokens within the sequence,creating a partially observed context for training token prediction.Next,the“Embedding Layer’’translates tokens into high-dimensional vectors for semantic understanding.The heart of the model lies in the“Transformer Layers (1–12)’’,where the multi-head attention and feedforward networks enable context representation.The“Pooler Layer(CLS)’’aggregates sequence information into a single[CLS]vector for downstream tasks.A“Dense Layer’’enhances feature extraction,while“Normalization’’and“Dropout’’layers ensure stable training and regularization.Finally,the“Tanh Function’’captures nonlinear relationships.
The proposed framework includes two primary phases whose goal is to exploit and integrate the advantages of all previous models to detect personality traits following the Big Five model:
Phase 1.Data preprocessing
First,a tokenizer divides the text into different tokens following a limited set of rules.Then,the tokens are transformed into numbers,which are fed into the model to construct tensors.One of the limitations is that the input lengths for PLMs are often constrained;for that reason,padding and truncation strategies have been utilized to address this problem,inserting special padding tokens into the sequences having fewer tokens or truncating the longest sequences.This process ensures the tensors have fixed length vectors representing the sentences.In the experiments,all PLMs have been utilized with their associated pre-trained tokenizer,which assures that the text is divided in the same manner as a pre-training corpus and that the same vocabulary is used when pre-training.
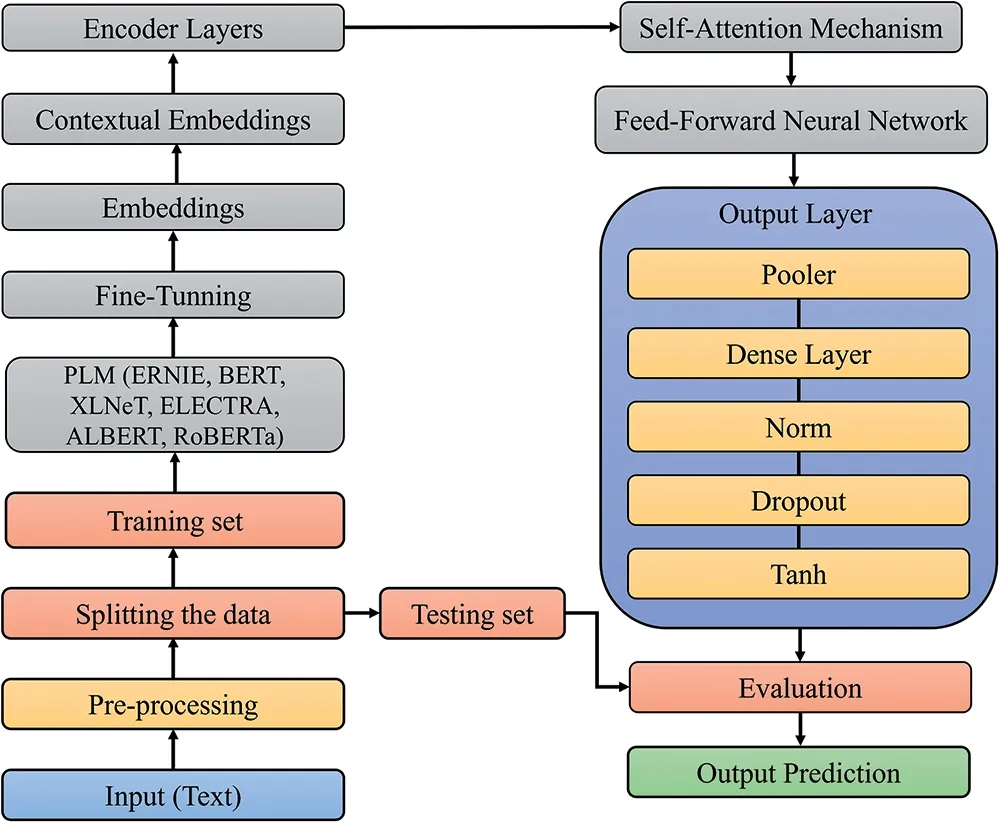
Figure 1:Workflow diagram for PLMs
Phase 2.Fine-tuning framework
Transfer learning consists in adapting the knowledge gained from a basic task to a target task,even for new domains.In this research,the PLMs have been adapted to classify multi-label personality traits from reviews.PLMs significantly reduce computation costs,capture structural features from texts,and apprehend plentiful facets of language relevant to downstream tasks,such as hierarchical relations,long-term dependencies,and sentiments.Therefore,the previous knowledge from the PLMs has been fine-tuned for the task of personality trait categorization.To do so,the last layer of all PLMs has been selected as an adaptation layer due to its simplicity and effectiveness.
In this approach,a deviation from the traditional use of the [CLS] token solely for fine-tuning and probability distribution prediction was implemented.Instead,it was integrated with additional classification head layers,namely a dense layer,normalization layer,dropout layer,andtanhactivation function.This customized classification head facilitated accurate predictions of the five personality traits.Through this adaptation,the sequence classification capabilities inherent in all PLMs were utilized,thus tailoring the model to effectively capture the necessary information for personality trait prediction.In this manner,the linear layer weights from various PLMs have been reconfigured following the personality trait classification task.Fig.2 illustrates the necessary phases to identify different personality traits by fine-tuning the mentioned PLMs.
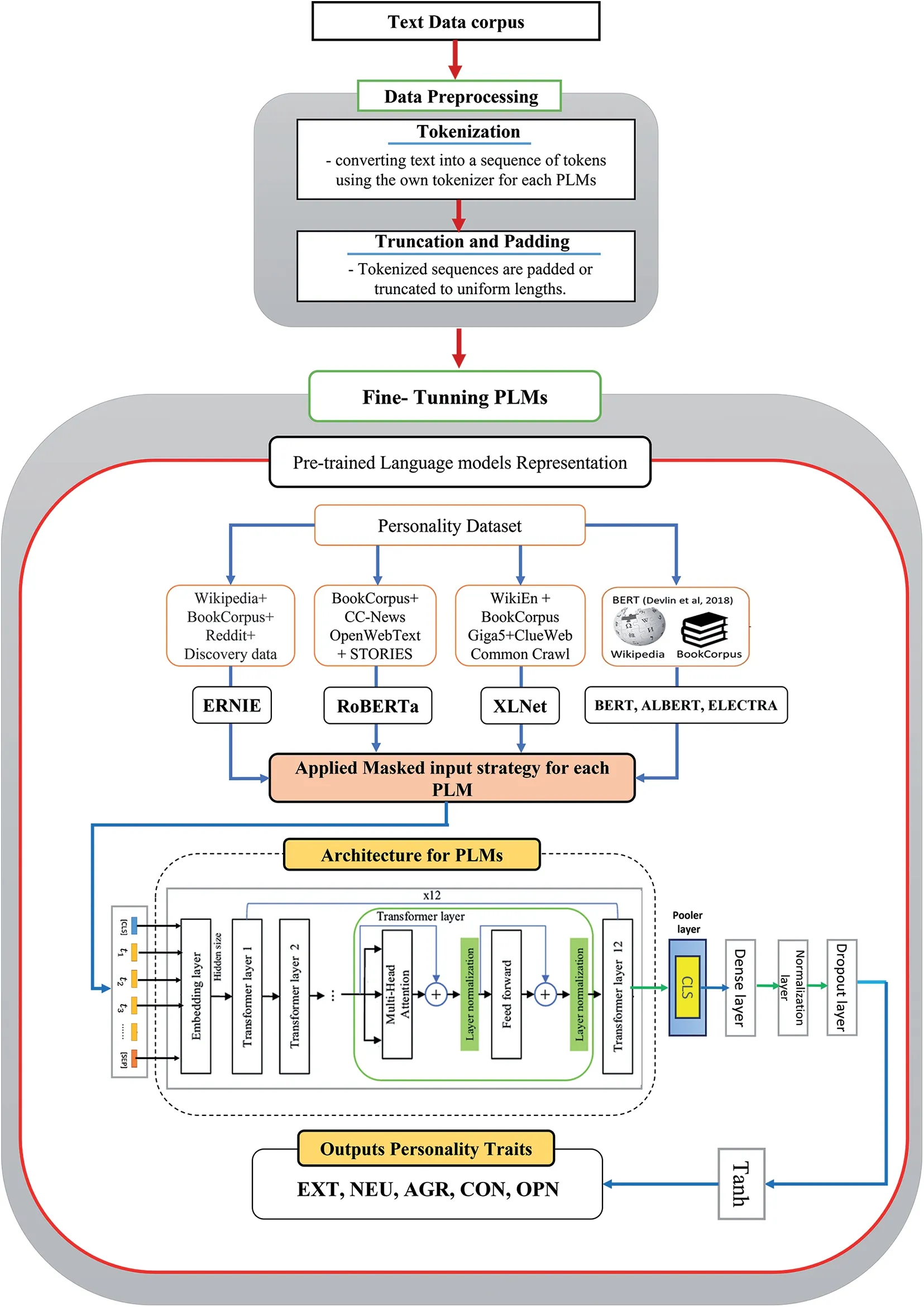
Figure 2:Framework followed to fine-tune the PLMs
3.2 Detailed Implementation of the Architecture
To adapt PLMs such as BERT,RoBERTa,ALBERT,ELECTRA,ERNIE,and XLNet for personality trait classification,the following steps were performed.These steps highlight the main differences and contributions made in comparison to other architectures[66–70].
First,the PLM and its specific tokenizer were loaded along with the dataset to ensure compatibility between the selected model architecture and the tokenized dataset.Then,the only used dataset,MyPersonality,was preprocessed,involving tasks such as tokenization,truncation,and padding.Tokenization was performed using the respective tokenizer,breaking the input texts into individual tokens and incorporating special tokens such as[CLS]and[SEP].In those cases where the input length exceeded the maximum token limit of the model,truncation was applied to trim the text,and padding was added to match the maximum length.
In the tokenization step,a percentage of tokens in the input text were randomly selected and replaced with a special[MASK]token,implementing the masked input strategy.This strategy enables the model to learn how to predict the masked tokens during training and capture bidirectional contextual information.This masked input strategy is an essential part of the pre-training process for these adapted models.
After tokenizing,the tokens were converted into numerical representations using the tokenizer’s vocabulary,which assigns a unique numerical ID to each token.The tokenizer also handled the conversion of the special tokens into their corresponding IDs.Finally,the tokenizer returned tensors representing the tokenized input texts that would be fed into the model for further processing.
Next,the PLM was instantiated,maintaining the base layers responsible for capturing linguistic features and the transformer layers.The weights in the base layers,including the embedding layer and transformer layers,were kept retaining the already learned representations and ensuring they were not modified during the fine-tuning process.
The architecture of the classification head layers was then customized to match the requirements of the personality classification task.This customization involved the addition of several layers,namely a dense layer,a normalization layer,a dropout layer,and atanhactivation function.The dense layer introduces non-linearity,the normalization layer enhances stability,the dropout layer prevents overfitting,and thetanhactivation function captures nuanced characteristics.These layers collectively contribute to improving the model’s performance and adaptability.The inclusion of these layers enhances the model’s capability to capture intricate patterns and relationships relevant to personality trait prediction.
In addition to the customization of the classification head layers,an output layer was added to the model to classify the input text into the Big Five personality traits:neuroticism(NEU),extraversion(EXT),conscientiousness(CON),agreeableness(AGR),and openness(OPN).This specialized output layer is responsible for making predictions.
The adapted model was subsequently trained on the preprocessed training set,with only the weights in the classification head layers updated.This fine-tuning process allowed the model to learn task-specific features while leveraging the pre-trained base layers’language understanding capabilities.The Trainer API7https://huggingface.co/docs/transformers/main_classes/trainer,with its various training options and features,including logging,gradient accumulation,and mixed precision,was utilized to simplify the training process and finetune hyperparameters such as the learning rate,batch size,and regularization techniques to optimize the model performance.
To sum up,most of the conventional model architectures in the field of personality trait prediction are employed for inference and transfer learning;nonetheless,this approach involves fine-tuning the model and adapting it specifically for the classification of multi-label personality traits from the reviews.To do so,the goal of this architecture was to fine-tune the model classification head,which includes a dense layer,normalization layer,dropout layer,andtanhactivation function.These additional head layers were added to improve the model’s ability to capture complex patterns in personality trait prediction.Customizing the architecture with these extra head layers,along with the utilization of specialized tokens such as the[CLS]token,the model was optimized to effectively capture and leverage essential information for precise personality trait prediction.The network topology diagram(see Fig.3)provides an insightful visualization of the architecture shared by the PLMs used in this study.
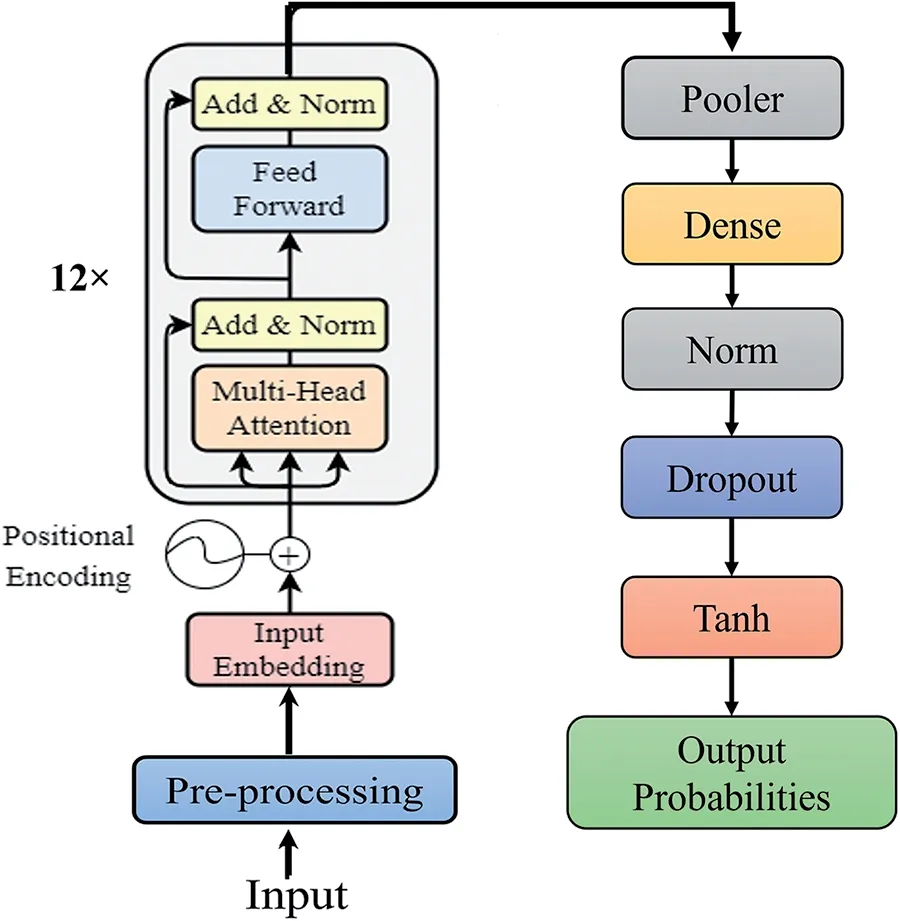
Figure 3:Network topology diagram of the PLMs
4 Experimental Setup
To assess the proposed framework,the MyPersonality8https://web.archive.org/web/20170313202822/http:/mypersonality.org/wiki/lib/exe/fetch.php?media=wiki:mypersonality_final.zipdataset has been selected.This dataset comprises 9,917 textual statuses authored by 250 users,categorized according to the Big Five personality model[71].The distribution of the Big Five personality traits,i.e.,neuroticism(NEU),extraversion(EXT),conscientiousness(CON),agreeableness(AGR),and openness(OPN)is presented in Table 1.
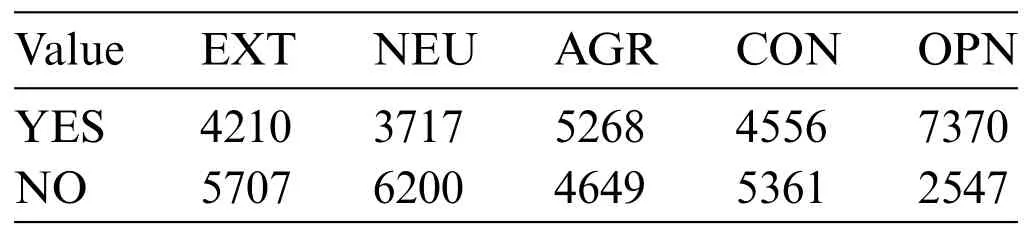
Table 1:Dataset distribution according to the personality traits
To ensure the data quality and address ethical concerns,the MyPersonality dataset underwent a careful curation process.During the data selection,any external information was removed preserving the user’s privacy.The original data collection was collected via a Facebook application that explicitly sought the users’consent for research purposes.Although inherent biases are common in social mediaderived datasets,measures were taken to ensure diversity and representation,leveraging the diversity of Facebook users[71].
To properly evaluate the performance of PLMs integrated into the proposed architecture,the dataset has been split into a training and testing set.80% of the status posts have been utilized for training the PLMs,whereas 20%have been utilized to evaluate the performance of customized models.A 10-fold cross-validation strategy has been followed.
In this research,the hyperparameter tuning strategy for all the models was conducted following a meticulous and systematic process to optimize the accuracy of personality trait detection.A series of experiments were executed to explore various hyperparameter combinations,especially considering critical factors such as the number of training epochs,batch sizes,optimizer choices,learning rates,and dropout rates.The approach involved searching through a predefined hyperparameter space,examining different values for key parameters such as the number of epochs(e.g.,3,4,5,6,7),batch sizes(e.g.,8,16,24,32,64),optimizer choices(e.g.,Adam,SGD),learning rates(e.g.,1e-5,2e-5,1e-3),and various dropout rates(e.g.,0.1,0.3,0.5).After numerous experiments,the optimal combination of hyperparameters for each model was identified.These best hyperparameters included the use of the Adam optimizer with a learning rate of 1e-5,a batch size of 8,and a training process spanning 5 epochs,with a dropout rate of 0.3.
The implementation of the PLMs was carried out using the Huggingface library [72].In the context of architectural parameters,the choice of the model versions and configurations was driven by their effectiveness in NLP tasks,considering factors such as architectural complexity and representation capabilities.This aspect underscored the parameter selection process,which encompassed tokenization,embedding dimension,and sequence length standardization to maintain a consistent setup across all models.Furthermore,model-specific tokenizers from Huggingface were employed to ensure model-specific adaptability.The loss function,Binary Cross-Entropy with Logits(BCEWith-LogitsLoss),was also selected to perform the classification task.
The experiments were conducted using Google Colab,a cloud-based platform that provided access to T4 GPUs,essential for the effective training of deep learning models.The training times for each model reflected computational complexity.Notably,the RoBERTa model needed the highest training time,requiring approximately 16 h to complete the process.The XLNet model took around 14 h,while both ERNIE and ELECTRA needed around 12 and 11 h,respectively.In contrast,the BERT and ALBERT models had relatively shorter training times,each one taking approximately 8 h.The longest training times for some specific models were primarily due to their more extensive network architectures,which demanded additional computational resources for optimization.
4.1 Evaluation Metrics
To assess the results,the measures precision,recall,F1-score,weighted averages(P-weighted and R-weighted and F1-weighted),and accuracy,have been implemented as described in[73]:
•Exact Match Ratio(EMR)assesses the proportion of cases where all of their labels are classified correctly:
wherenis the number of cases,Iis the indicator function,yiis the number of true labels for thei-thcases,andthe number of correctly predicted labels for thei-thcase.
•Zero-One Loss:This metric measures the proportion of cases where the predicted value differs from the actual value:
•Hamming Loss(HL)calculates the ratio of incorrectly predicted traits to the total number of traits:
•Precision(P)computes the proportion of correctly recognized labels over the total number of predicted labels,averaged over all cases:
wherenis the number of cases/status,yiis the number of actual labels/traits fori-thcase,andis the number of successfully predicted labels fori-thcase.
•Recall(R)is the proportion of correctly recognized labels to the total number of expected labels,averaged over all cases:
•F1-score(F1)is the harmonic mean of precision and recall:
•Weighted averageconsiders the number of cases in each label and can yield a value of Fweighted that is not between P-weighted and R-weighted.The following equations can be used to compute the P-weighted,R-weighted,and F-weighted:
•Accuracy(ACC)computes the proportion of correctly classified traits over the total number of traits:
5 Results and Discussion
This section summarizes the findings and contributions made after assessing the effectiveness of the different PLMs tuned for detecting multiple personality traits in the dataset.
As presented in Table 2,ERNIE demonstrated outstanding results,achieving an accuracy of 87.17%,an F1-score of 84.41%,and an EMR of 73.32%.ERNIE’s performance surpasses the other models,underlining its accuracy in predicting personality traits.The high EMR value is particularly noteworthy,as it indicates that ERNIE consistently classifies all personality traits correctly for a significant proportion of cases.This consistency underscores ERNIE’s robustness and reliability for this task.
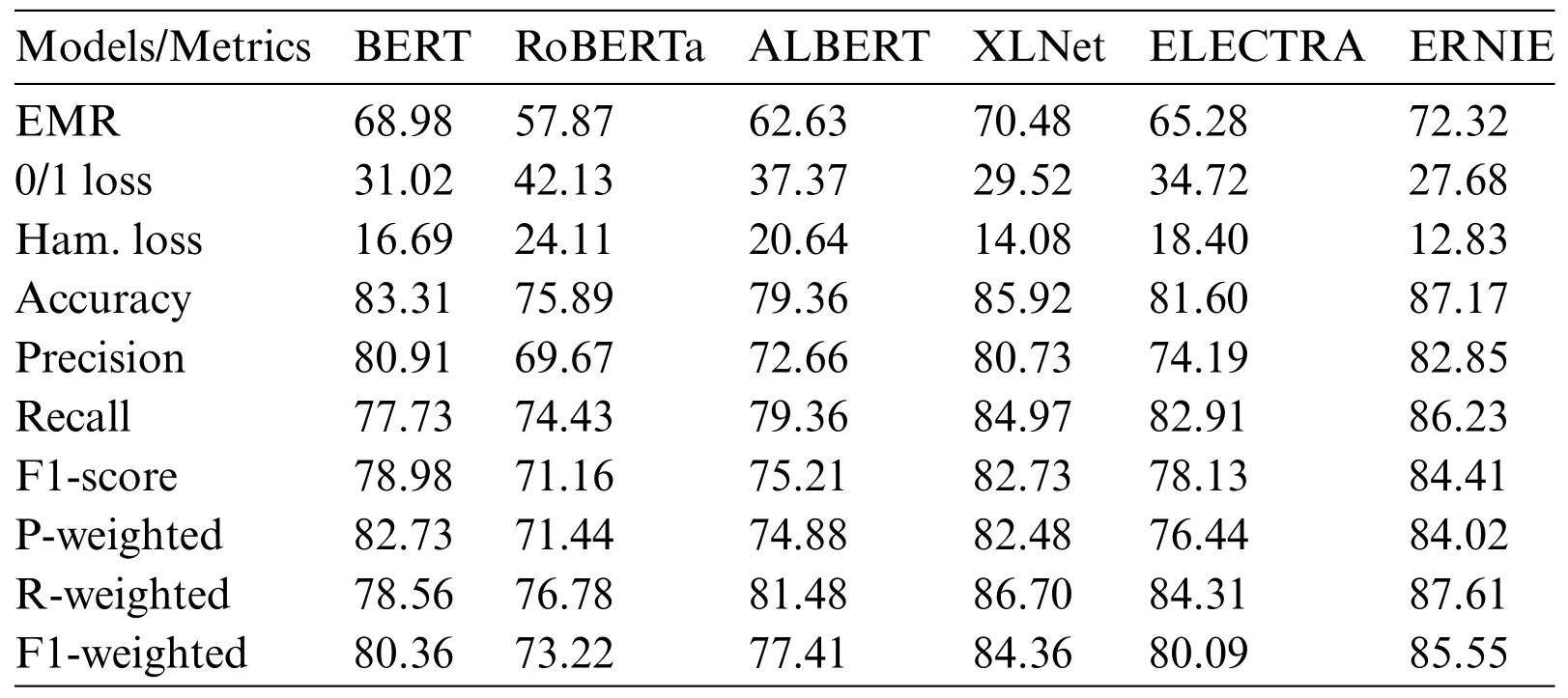
Table 2:Performance results for the PLMs
ERNIE’s performance can be attributed to its unique strengths,which stem from diverse pretraining tasks,including masked language modeling,next-sentence prediction,and sentiment analysis.Unlike many other PLMs that rely on a single pre-training task,ERNIE’s multifaceted training process enables it to attain a more comprehensive understanding of the English language.These results demonstrate that ERNIE excels,not only in particular individual trait prediction but also,in ensuring the accuracy of multiple personality trait detection.
One of ERNIE’s notable attributes is its sequential learning capability,allowing it to accumulate knowledge progressively.This sequential learning enables ERNIE to manage complicated tasks,such as natural language inference,by continually building on its previously acquired knowledge.Moreover,ERNIE distinguishes itself thanks to its larger model size in comparison to other PLMs.This increased model size equips ERNIE with an enhanced capacity to learn and represent complex relationships within the data,contributing to its outstanding performance in personality trait prediction from the text[74].
XLNet achieved comparable results to the ERNIE model,outperforming the other PLMs(BERT,ALBERT,ELECTRA,and RoBERTa).One of the main reasons is that it can obtain a bidirectional context representation of a term by training an autoregressive model overall potential permutations of terms in a sentence,and it has no sequence length limit,unlike BERT,overcoming some problems of the BERT model.On the contrary,ALBERT and RoBERTa obtained the lowest results;their accuracy was improved by ERNIE by 7.81% and 11.28%,respectively.
Compared with previous studies using the same gold standard,the results(see Table 3)show that all the tested PLMs significantly outperform the state-of-the-art studies in terms of accuracy.This is the primary metric used in these studies,for that reason,it is used for comparison.
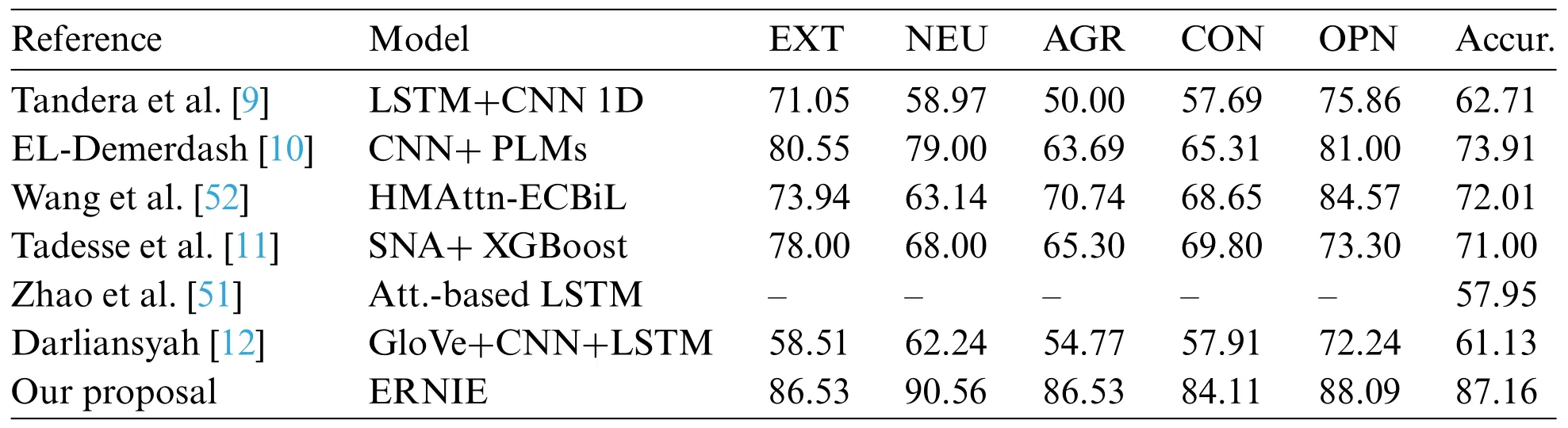
Table 3:Comparison of this approach with other state-of-the-art models
The techniques used by these previous studies(see Table 3)are primarily based on classic machine learning models and deep learning architectures,word embeddings,and attention mechanisms,trained on the proposed dataset.These techniques might require a huge amount of data to accurately tune all their parameters,especially for a complicated task such as multi-label classification.Nevertheless,since the PLMs have been trained on huge previous collections over different tasks,the tuning process might be simpler,even though the dataset is small because a great number of lexical,syntactic,and structural features over different tasks have been already learned by the models.
These results corroborate that using transfer learning has a significant impact when there is not available enough data in the target domain,but there is a suitable dataset for the source domain.Hence,transfer learning can be used to adapt models across different tasks,in this case,multiple personality traits detection,increasing the accuracy by at least 10% regarding the previous studies.
To discuss the capabilities of each PLM,the individual personality traits have been broken down in Table 4.ERNIE achieved the best statistics for the F1-score for all traits,except for OPN,where XLNet obtained the best performance.As the F1-score is the harmonic mean of precision and recall,it could be thought that the best results could be also computed by ERNIE;nonetheless,it achieves the best balance between them,but not necessarily the best individual results.Thus,BERT,ALBERT,and XLNet achieved the highest precision scores for AGR,CON,and OPN,respectively;and regarding the recall score,ERNIE also achieved the highest score for EXT and AGR,whereas BERT,XLNet,and ALBERT achieved the highest recall scores for NEU,CON,and OPN,respectively.Finally,according to the F1-score,XLNet just achieved the highest performance score for OPN,whereas ERNIE did for the rest of the personality traits,which makes it the most appropriate model for detecting traits.
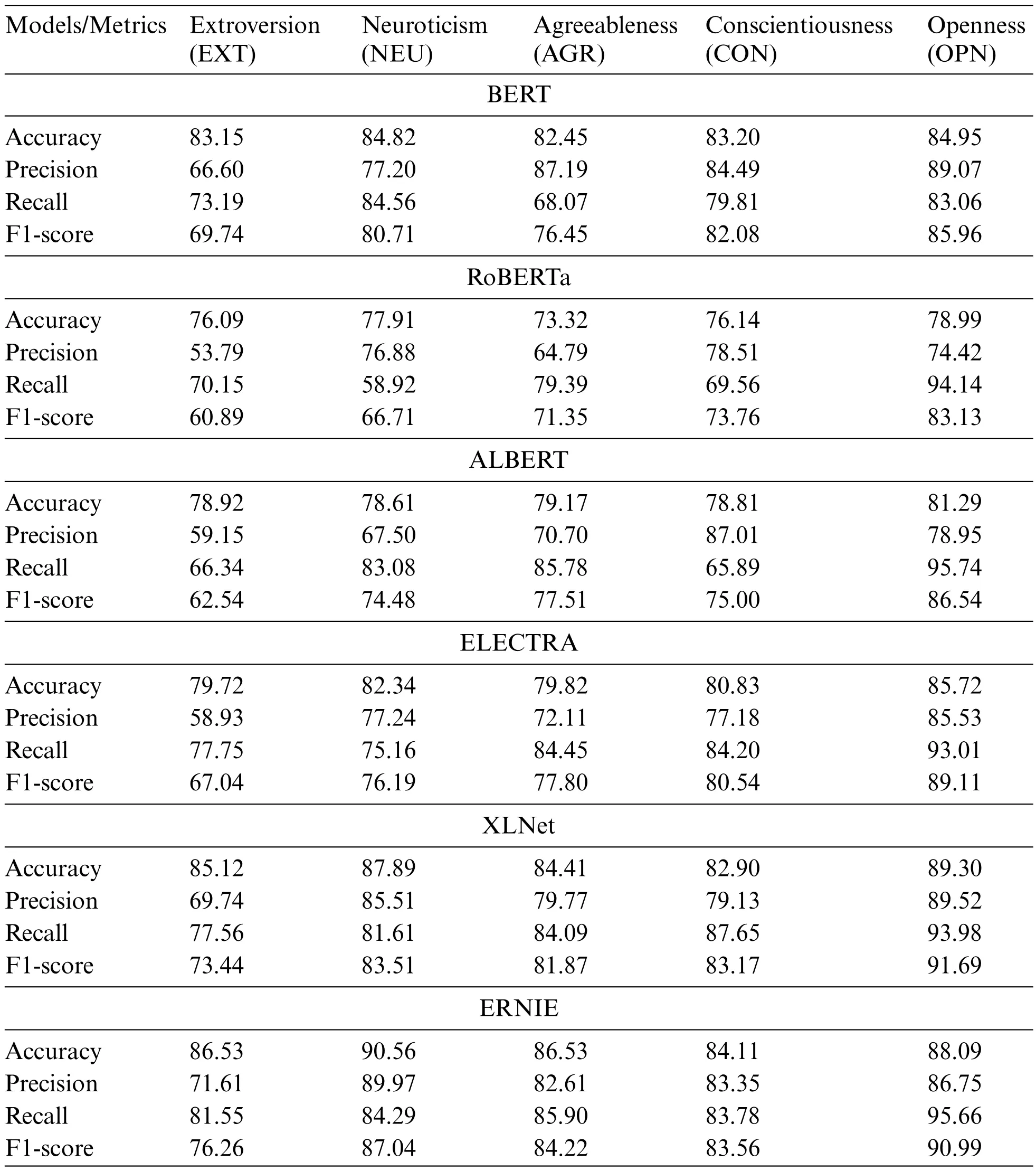
Table 4:Assessment for each trait
To illustrate practical variances in personality trait label predictions among different models and emphasize the importance of the EMR metric in assessing their performance,let us see the results for the following post from the dataset: ‘‘just spent the last hour looking at photos from junior abroad in London and is dying to go back.’’ERNIE and XLNet demonstrated their proficiency by accurately predicting all five personality trait labels correctly.These models excelled in comprehending the nuances of the text and making precise judgments.In contrast,the BERT and ELECTRA models exhibited limitations,struggling to predict the CON label accurately,indicating a potential challenge in understanding this specific personality trait in the given context.On the other hand,both ALBERT and RoBERTa models encountered difficulties in accurately predicting NEU and CON,implying that these traits may be particularly challenging to identify from the post.
Considering just the individual labels,it can be noted that the OPN obtained the best results in terms of F1-score in comparison with the other labels.The availability of a larger number of cases for this label in the dataset may be one of the fundamental reasons for explaining these data.In contrast,EXT and NEU comprise the lowest number of cases,being 16.75%and 14.79%of the dataset,respectively.Therefore,the F1-score for them was the lowest value for most of the PLMs.Thus,this corroborates that the greater the number of cases is,the better the identification of traits is.
Focusing on the ERNIE model,the confusion matrices demonstrate that the number of mislabeled instances is low (see Fig.4).As it can be seen over the principal diagonal,the number of perfectly classified items(the true positives in blue and the true negatives in green)is greater than the number of incorrectly classified ones,i.e.,the off-diagonal items(the false negatives in red and the false positives in yellow).Conscientiousness is the trait showing more difficulty in being classified.

Figure 4:ERNIE’s confusion matrices for each personality trait
It is also interesting to analyze the percentage of misclassified personality traits.As it can be seen in Table 5,the percentage is very low for the three superior PLMs(ERNIE,XLNet,BERT),12.83%,14.08%,and 16.69%,respectively.OPN is the most easily classified label by most of the models,possibly as it was explained above because there are more instances in the dataset.Nonetheless,CON and AGR present more errors,in general,for most of the models,although EXT and NEU have fewer instances in the dataset.
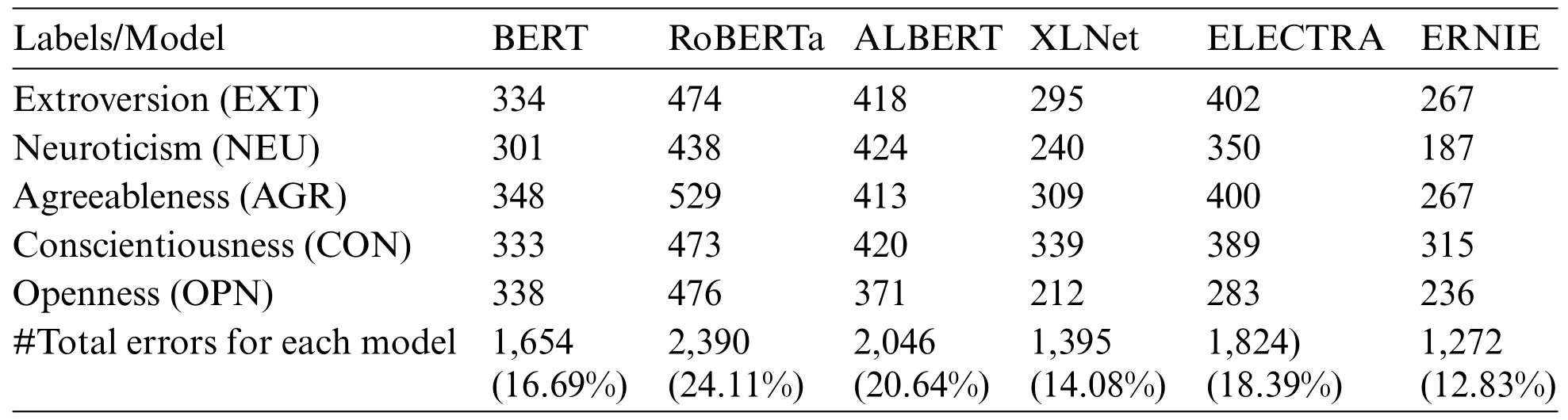
Table 5:Mislabeled instances per personality trait
Another variable that can influence the performance of the models could be the vocabulary coverage of the libraries used.In this case,most of the models share the same vocabulary(see Table 6);therefore,this factor is not very remarkable to explain the good performance of some models.

Table 6:Terms from the PLMs included in the MyPersonality dataset
Nevertheless,this aspect can explain the weak performance of the RoBERTa model.Despite being larger than the other models (50,265 terms),it just shares 3,053 (18.09%) terms with the evaluation dataset.Therefore,the goodness of the ERNIE model is not just based on the vocabulary,but also on the tasks followed to develop the model and the size of the datasets used to train it.
The average training and validation loss was also monitored to study the performance of the PLMs.A consistent pattern was observed,marked by substantial reductions in both training and validation losses up to the fifth epoch(see Fig.5).
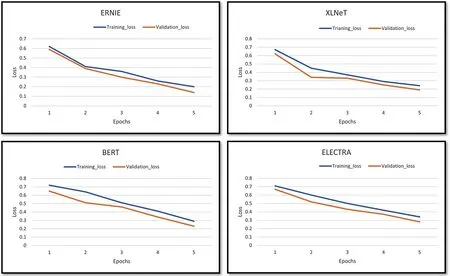
Figure 5:(Continued)
Beyond this threshold,the losses exhibited fluctuations,leading to the establishment of a predefined number of training epochs(5)as a preventive measure against overfitting.The minimal gap between training and validation losses served as additional assurance of the robustness of the model’s training process [75].ERNIE,with the lowest training and validation losses among the evaluated models,clearly demonstrated a remarkable performance,underlining the significant impact of its low loss values on its overall effectiveness.
The complexity of ERNIE’s architecture allows carrying out word-aware tasks,structure-aware tasks,and semantic-aware tasks from massive data sources and the multi-task continual learning stage allows learning lexical,syntactic,and semantic information from different tasks.Unlike the other methods which usually only train the model over one specific task forgetting the previously learned knowledge,ERNIE can keep the knowledge through the entire learning process thanks to the multitask continual learning strategy.This is one of the major ERNIE’s key points,not even the huge datasets used for training the model can be considered fundamental because RoBERTa uses similar datasets(see Table 7)but is not able to achieve its results.
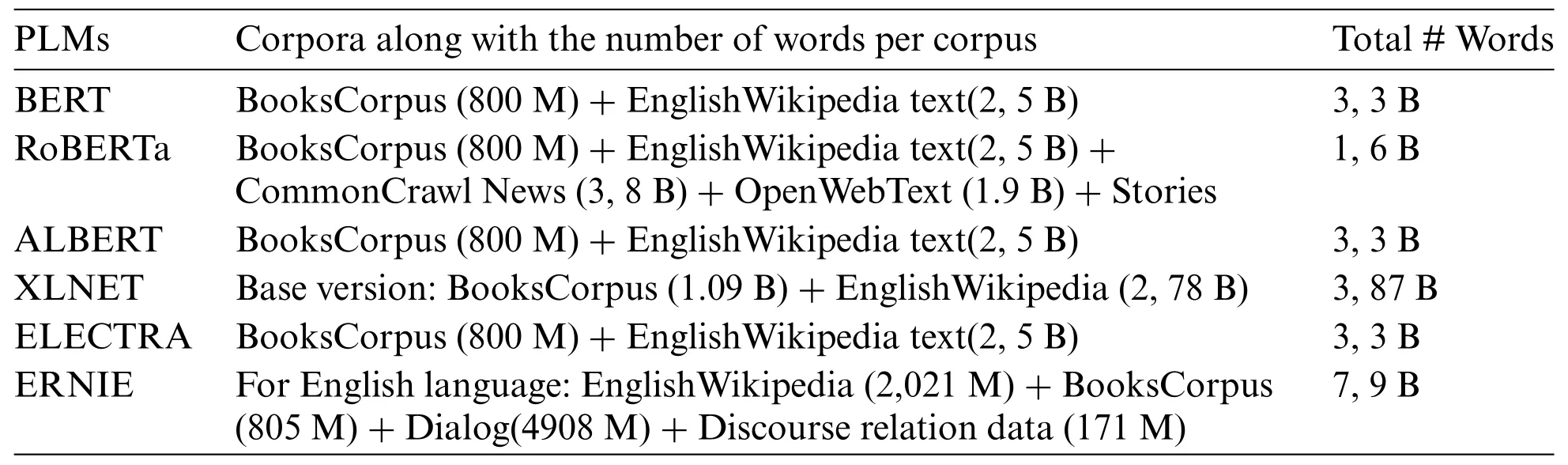
Table 7:Size of the text corpora used for each implemented PLM
In Table 7,a summary of the datasets used for each PLM can be seen.ERNIE used the largest corpora (the Chinese corpora are not included in the used version) along with RoBERTa,whereas BERT,ALBERT,and ELECTRA used the same corpora,obtaining different results.Consequently,the vocabulary of the PLMs seems to be an important aspect to analyze the performance of the PLMs;nonetheless,the datasets and especially,the tasks used to train the different PLMs,clearly determine the goodness of the models.
Finally,it is necessary to remark that the used dataset has 15,470 unique terms and the average length of each opinion is 8.01 terms,for that reason,it is difficult to measure the effect of several features such as the token CLS over the long opinions in this case.Furthermore,since the used dataset does not provide very specific terms,the issue of out-of-vocabulary terms has not been faced.
Among the practical implications of the proposal,it is necessary to highlight that this framework can help developers focus on designing solutions and applications that need to compute the preferences and characteristics of individual users such as recommender systems or customized decision support systems.These systems can be interesting in different domains such as marketing and advertising for personalizing services according to the different customer personalities,or in healthcare for detecting illnesses such as depression or anxiety which can be related to the different personality features.Furthermore,the capability of detecting personality traits in such a precise manner can reduce the need for interaction with experts such as psychologists or psychiatrists in many studies and developments,being replaced by frameworks like the one here presented.
Nonetheless,this framework also presents some limitations.First,the proposal does not quantify the output,i.e.,the intensity of the traits.It just classifies the user as extrovert or introvert but not to what extent.Second,there are other limitations closely related to the nature of PLMs.For instance,these models show computational complexities that limit their ability to handle extended sequences.These complexities can be especially challenging when dealing with sequences that surpass the typical 512-token limit due to GPU memory constraints.Finding more efficient model architectures to capture longer-range contextual information is necessary to deal with long texts.Furthermore,finetuning can be parameter-inefficient,as each task often requires its own set of fine-tuned parameters.Improving efficiency involves exploring alternatives where core PLM parameters remain fixed,with small,fine-tunable adaptation modules introduced for specific tasks,thus allowing shared PLMs to serve multiple downstream applications.Moreover,this approach needs substantial computational resources they require for optimal performance,which may be a limitation in resource-constrained environments.Another limitation is the lack of datasets accordingly labeled for personality traits.
6 Conclusions and Future Work
Personality detection is a relevant task whose results can be applied to many other areas such as healthcare,e-commerce,recruitment processes,etc.;for that reason,its results must be accurate.In this sense,this research has introduced a comprehensive framework for multi-trait personality classification,which encompasses the adaptation and evaluation of multiple PLMs to fulfill this complex task,revealing promising results.
The meticulous customization and fine-tuning of the specific model components distinguished the methodology here presented.The precise customization and fine-tuning of specific model components were carefully tailored,introducing a dense layer,normalization layer,dropout layer,and tanh activation function.These additional layers enhanced the model’s ability to capture complex patterns and relationships over the data,which were crucial for predicting accurately.Furthermore,a specialized output layer was integrated to classify the input text into the Big Five personality traits,ensuring precise and task-specific predictions.The fine-tuning process struck a balance between taskspecific feature learning and leveraged the language understanding capabilities of the pre-trained base layers,aided by the Trainer API for streamlined training and hyperparameter optimization,ultimately resulting in an enhanced model performance.Furthermore,the high accuracy of the obtained results guarantees the correct applicability of the proposed framework in other systems that need information about the user’s personality.
Regarding future work,from a practical perspective,it is necessary to assess how the proposed framework can help real applications(recommender systems,decision support systems,expert systems,etc.) to improve their results and to what extent.For that reason,the next step the adaptation of previous recommender systems developed by the authors is proposed,including personality traits as a new variable for customizing the recommendations[76,77].Moreover,although the performance has been good,it is necessary to study how good the performance of the proposal is on other personality models aside from the Big Five model.For that reason,it is proposed to adapt the framework to detect personality characteristics according to the MBTI model.To do so,the MyPersonality dataset will be first accordingly labeled.And finally,it is necessary to mention that this framework only considers the PLMs working individually;nonetheless,the consideration of all the results can provide a new perspective,therefore,it is planned to group the individual models under the architecture of an ensemble to improve the current results.
Acknowledgement:The authors acknowledge the support of the Spanish Ministry of Economy and Competition,General Subdirection for Gambling Regulation of the Spanish Consumption Ministry and Science and Innovation Ministry.
Funding Statement:This work has been partially supported by FEDER and the State Research Agency (AEI) of the Spanish Ministry of Economy and Competition under Grant SAFER:PID2019-104735RB-C42 (AEI/FEDER,UE),the General Subdirection for Gambling Regulation of the Spanish Consumption Ministry under the Grant Detec-EMO:SUBV23/00010,and the Project PLEC2021-007681 funded by MCIN/AEI/10.13039/501100011033 and by the European Union NextGenerationEU/PRTR.
Author Contributions:Conceptualization: Jesus Serrano-Guerrero,Bashar Alshouha and Jose A.Olivas;Investigation:Jesus Serrano-Guerrero,Francisco P.Romero and Francisco Chiclana;Formal analysis:Jesus Serrano-Guerrero,Jose A.Olivas and Francisco Chiclana;Writing-original draft:Jesus Serrano-Guerrero,Bashar Alshouha and Francisco P.Romero;Supervision:Jesus Serrano-Guerrero,Jose A.Olivas and Francisco Chiclana;Implementation:Bashar Alshouha and Francisco P.Romero;Writing-review&editing:Jesus Serrano-Guerrero and Francisco Chiclana;Funding acquisition:Jose A.Olivas and Francisco P.Romero.
Availability of Data and Materials:The used data are accessible on https://web.archive.org/web/201703 13202822/http:/mypersonality.org/wiki/lib/exe/fetch.php?media=wiki:mypersonality_final.zip.
Conflicts of Interest:The author declares that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- ASLP-DL—A Novel Approach Employing Lightweight Deep Learning Framework for Optimizing Accident Severity Level Prediction
- A Normalizing Flow-Based Bidirectional Mapping Residual Network for Unsupervised Defect Detection
- Improved Data Stream Clustering Method:Incorporating KD-Tree for Typicality and Eccentricity-Based Approach
- MCWOA Scheduler:Modified Chimp-Whale Optimization Algorithm for Task Scheduling in Cloud Computing
- A Review of the Application of Artificial Intelligence in Orthopedic Diseases
- IR-YOLO:Real-Time Infrared Vehicle and Pedestrian Detection