基于特征复用机制的航拍图像小目标检测算法
2024-03-12邓天民程鑫鑫刘金凤张曦月
邓天民,程鑫鑫,刘金凤,张曦月
(重庆交通大学 交通运输学院,重庆 400074)
无人机(unmanned aerial vehicle,UAV)航拍图像相较于地面固定图像具有部署灵活、拍摄视野广的优点.目前,基于深度学习的航拍图像目标检测方法分为2类.第1类是基于候选区域的目标检测算法,基于这类算法许多学者提出了针对航拍图像的目标检测方法.例如:针对复杂环境下的航拍图像密集小目标检测问题,Zhang等[1]提出基于像素建议网络(pixel proposal network,PPN)的特征提取Faster R-CNN,通过自上而下的方法将低分辨率强语义特征与高分辨率弱语义特征相结合,构建全面的语义特征图,并使用双曲池化减少激活映射过程中的特征信息丢失,最后,根据数据集的特征,使用数据聚类,自适应地生成建议框.Huang等[2]在Cascade R-CNN算法的基础上,通过增加超类检测、融合回归置信度并修改损失函数,以提高目标检测能力.另一种策略是单级目标检测算法,基于此类算法Zhu等[3]提出TPH-YOLOv5算法,用Transformer检测头(TPH)代替原来的检测头,并通过增加一个额外的检测头,形成四尺度检测头,在航拍图像的高密度场景中准确定位目标,同时加入卷积注意力模块来搜寻密集场景下的注意力区域.Liu等[4]提出用于航空图像的轻型目标检测网络YOLOUAVlite,通过构建新的轻量级骨干网络来改进特征提取能力并减小模型大小,优化特征金字塔模型,减少特征图融合过程中的信息损失并降低模型权重,对定位损失函数修正,提高定位精度与边界框回归率.
为了在移动设备和嵌入式设备上进行高效计算机视觉任务,许多学者做出相应的研究.Howard等[5]在MobileNetV1中将标准卷积分解为深度可分离卷积(depthwise convolution,DWconv)和逐点卷积(pointwise convolution,PWconv),该模型大幅度减少了操作和参数量.ShuffleNetV1[6]在深度可分离卷积的基础上增加了分组卷积和通道混洗模块,计算量和检测时间都优于Mobile-NetV1的.ShuffleNetV2[7]提出设计轻量级网络的4个原则,并引入信道分割,拆分结构将Add操作替换为Concat操作,从而减少模型参数量.PPPicoDet[8]在轻量级网络ShuffleNetV2的基础上改进了网络结构,并提出以ESNet(enhanced Shuffle-Net)作为主干网络,其性能优于ShuffleNetV2主干网络.在本研究中,对ESNet网络基础模块进行改进,设计轻量化高效主干网络FS(function ShuffleNet),来提高航拍图像的目标检测效率.
大视场下的航拍图像目标分布稀疏不均,会增加搜索成本.航拍图像中待检测目标小、背景复杂、尺度差异大且密集排列,通用目标检测方法难以获得理想效果.UAV平台的计算资源是有限的,航空图像目标检测的应用场景有实时性和轻量化的要求.基于上述局限性,综合考虑航拍目标检测视角、检测精度和模型复杂度等问题,提出FS-YOLO(functional ShuffleNet YOLO)航拍图像轻量级检测方法,设计轻量化网络FS替换基准主干网络,降低颈部和头部的特征通道维数,引入内容感知特征重组模块(content-aware reassembly of features,CARAFE)[9]来替代基准模型中最近邻插值上采样.主要在以下2个方面展开研究:1)通过轻量化设计减小检测模型的尺寸;2)通过采用特征复用的方法利用冗余特征信息,提高小目标的检测精度.
1 FS-YOLO
1.1 整体结构
YOLOv8算法[10]是ultralytics公司提出的端到端无锚框通用目标检测网络.它建立在YOLOv5版本[11]的成功基础上,基于快速、准确和易于使用的理念设计,引入新的功能和改进.其中,头部改进较大,引入新的无锚框解耦头结构,避免锚框的超参数问题,同时引入新的损失函数来提升性能;主干结构与颈部改动较小,将C3结构换成了梯度更丰富的C2f结构,实现了网络的进一步轻量化.该网络检测精度高,结构灵活,注重速度、尺寸和准确性之间的平衡,是典型的无锚框目标检测网络.为了应对航拍图像环境的复杂多变及模型规模在无人机应用上的限制,须对特征提取和表示能力进一步提升,并进一步降低模型复杂度,因此选择YOLOv8s作为本研究航拍图像检测算法的基础网络进行改进.
所提出的无人机航拍图像轻量级检测算法FS-YOLO,其核心思想如下:在降低模型复杂度的同时,对冗余特征信息进行高效复用,实现更高的航拍图像目标检测效率,增强航拍图像目标检测实时检测性能.FS-YOLO算法的整体结构图如图1所示.首先,提出轻量高效主干网络结构FS,替换基准模型中的主干网络,主干网络FS由多组FS瓶颈层(FS Bottleneck)堆叠而成,包含2种FS Block模块,FS Block_1模块进行特征提取操作,通道数不变,FS Block_2模块利用stride=2的深度可分离卷积进行下采样操作,通道数增加.FS Block模块是在ESNet网络的基础模块上改进而得,能够在较少参数量下产生更多特征图,具有更高的效率,能有效提升网络的学习能力.为了与FS轻量化主干网络相匹配,须对通道维数进行相应的调整[12],将主干结构末端和检测头大尺寸分支的特征通道维数由512降低至256.最后,在颈部上采样操作中引入能够更好地传输语义信息的内容感知特征重组模块CARAFE模块来替代基准模型中最近邻插值上采样方式,实现对特征融合上采样过程中高层语义信息传输增益.FS-YOLO算法的参数细节如表1所示.表中,c1表示输入通道数,c2表示输出通道数,Size表示特征图尺寸,P表示模块参数量.
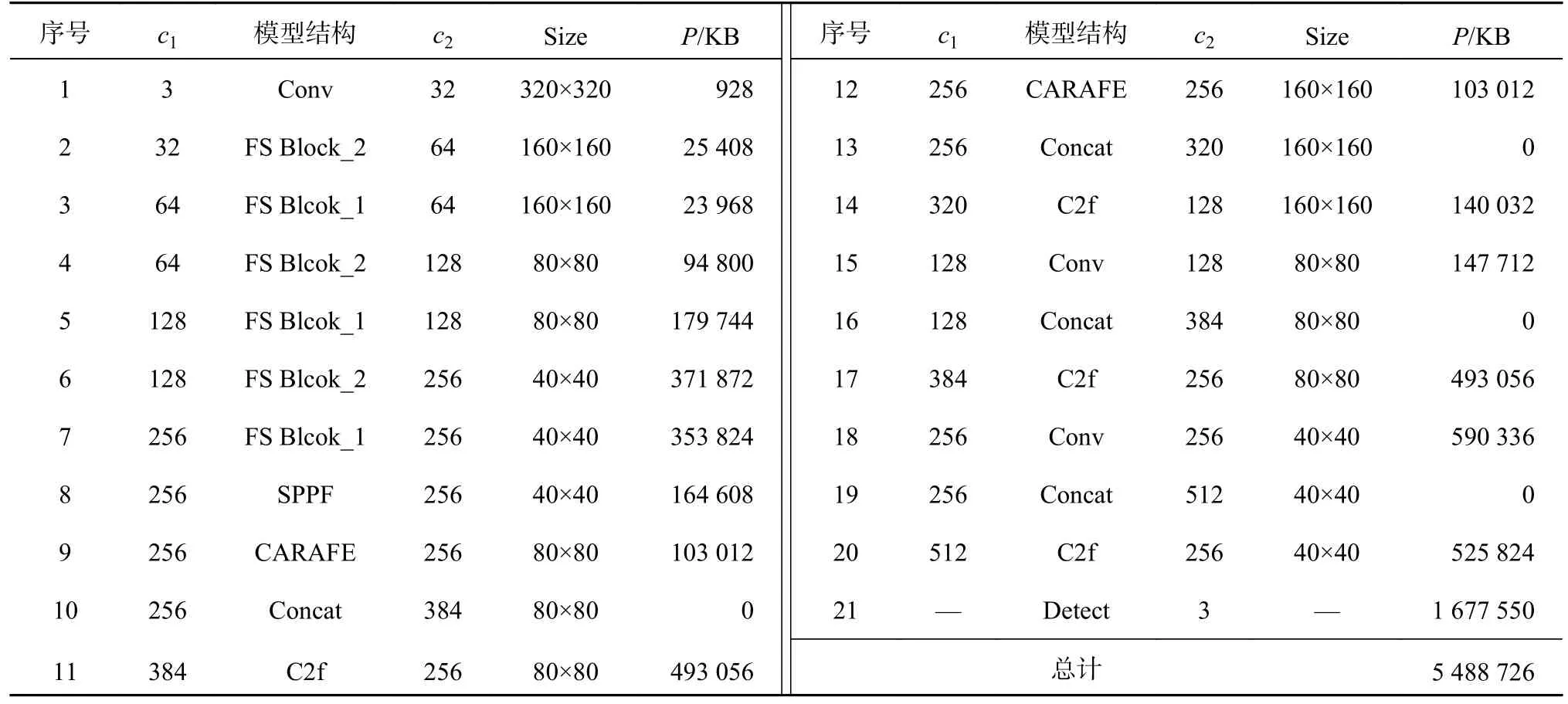
表1 FS-YOLO算法的参数细节Tab.1 Parameter details of FS-YOLO algorithm
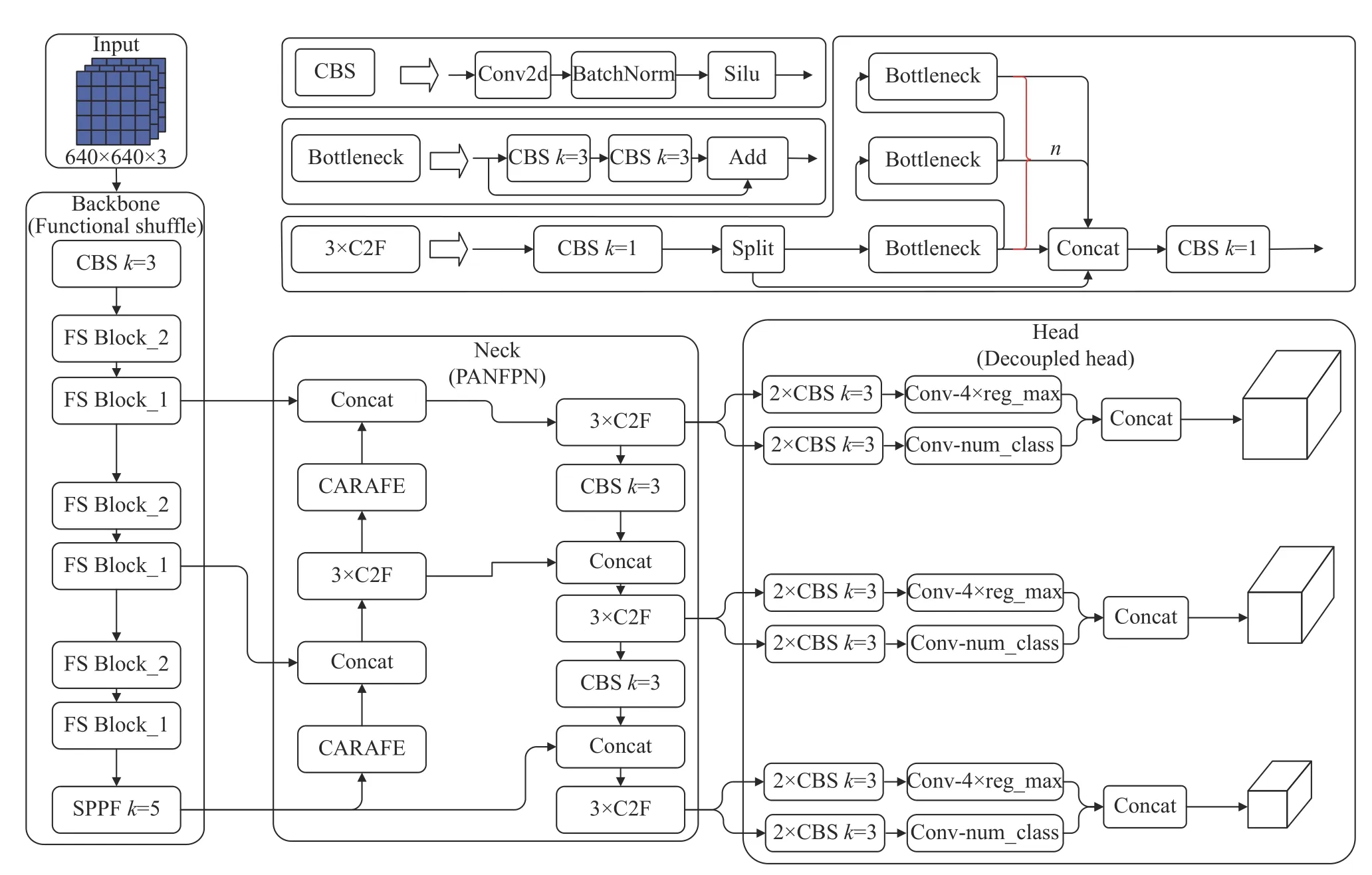
图1 基于FS-YOLO的航拍图像轻量级检测算法整体结构Fig.1 Overall structure of aerial image lightweight detection algorithm based on FS-YOLO
1.2 轻量化高效主干网络FS结构
ESNet是在ShuffleNetV2的基础上引入SE模块[13]和GhostNet[14]中的Ghost模块,并新增深度可分离卷积,对不同通道信息进行融合来提升模型精度.ESNet在常规物体分类和检测方面实现了在精度、速度上的提升,然而,为了适应航拍图像中复杂多变的检测环境,须进一步提高特征提取和表示能力,为此本研究提出改进的FS主干网络.FS主干网络的结构如图2所示,在FS Block_1的开头添 加通道分割模块,输入特征映射被分割为2个分支,每个分支的通道数是原来的一半.与标准卷积相比,幽灵卷积模块Ghost的参数更小,计算量更少,生成的特征图更多,从而减少了权值参数.坐标注意力模块(CoordAttention,CA)[15]能较好地权衡网络信道与空间特征之间的表达,获得更好的特征.在逐点卷积后,2个分支连接起来.当stride=2时,将输入特征图发送到2个分支进行卷积,特征图大小变成初始输入特征图的一半,特征拼接后通过T型特征感知卷积模块(Tshaped feature perception convolution,TFPC)对特征进行加权组合.最终输出特征映射的通道数量是初始输入特征映射的2倍.
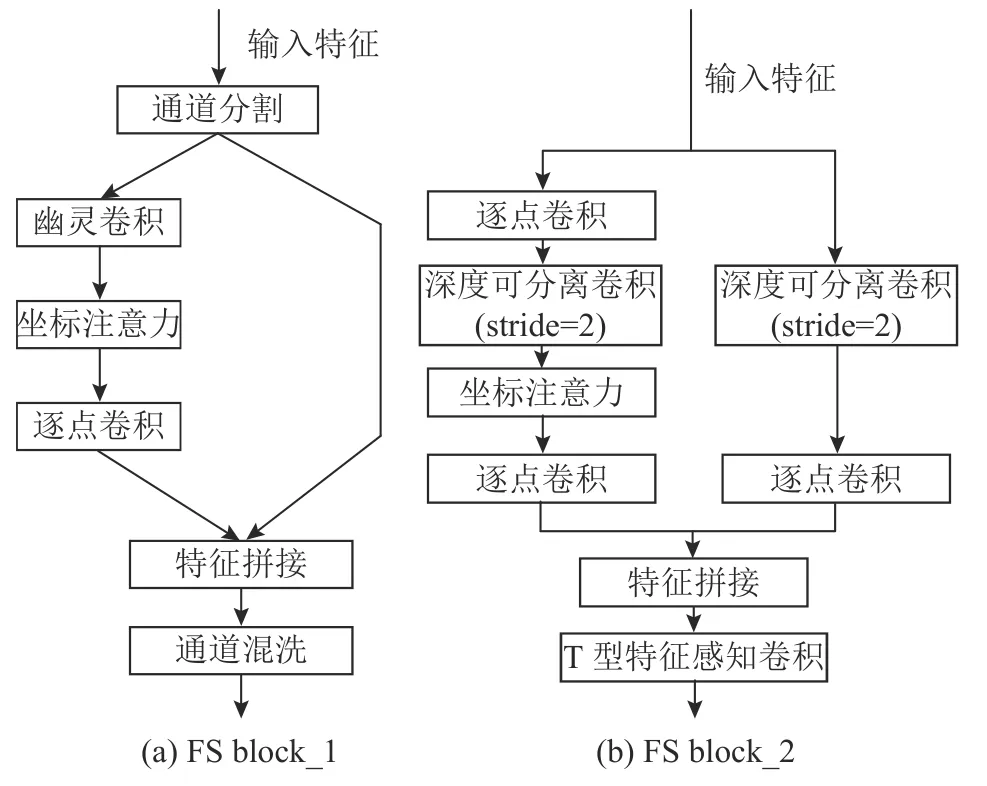
图2 FS瓶颈层的2种结构Fig.2 Two structures of FS bottleneck layer
1.2.1 T型特征感知卷积TFPC模块 在特征提取过程中,虽然深度可分离卷积DWconv(通常后跟逐点卷积PWconv)可以有效地减少模型复杂度,但无法在深度上对丰富的上下文信息充分利用,会导致较大的精度下降.为了有效利用不同通道的特征空间信息,设计T型特征感知卷积模块TFPC,通过局部卷积(partial convolution,PConv)[16]级联逐点卷积PWconv的方式来加权组合提取特征.TFPC的特征感知过程如图3所示.
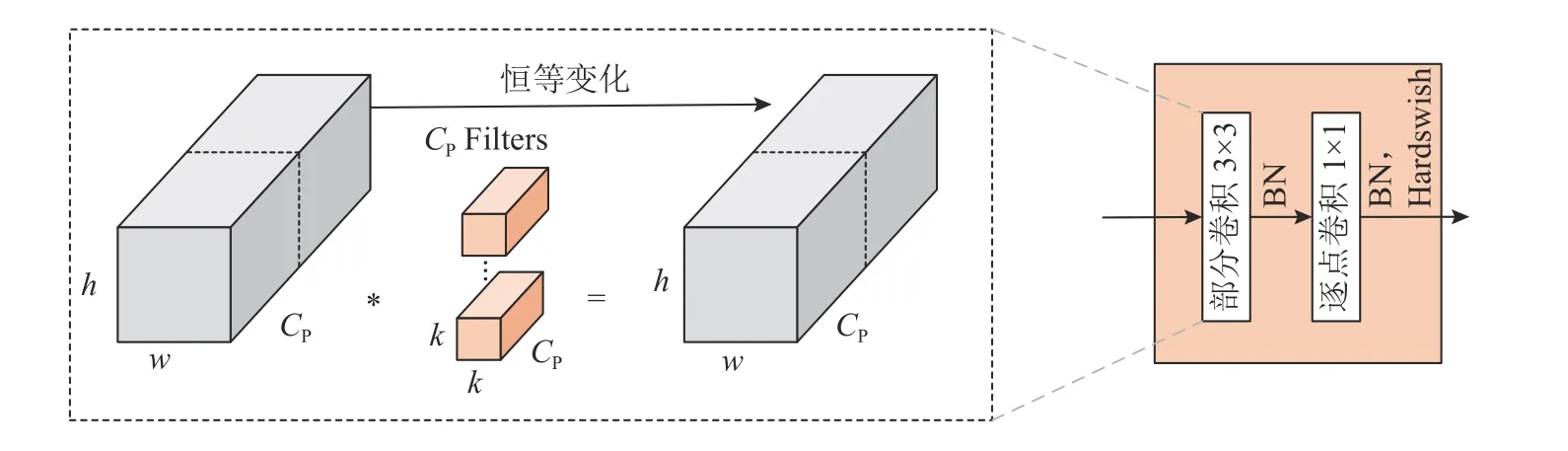
图3 T型特征感知卷积模块Fig.3 T-shaped feature perception convolution module
假定T型特征感知卷积模块TFPC的输入特征图为I=[x1,x2,···,xn]∈RC×H×W,通过split切片操作将输入的特征空间I的通道分为2个部分,切片后的通道数分别为CP和(C-CP),对特征空间X1进行卷积操作提取空间特征,保持X2的特征恒等变换,将卷积输出与未接触的特征映射进行Concat操作连接起来,经过批归一化后输入逐点卷积PWconv进行加权组合,最后通过批归一化和 h_swish激活函数得到输出特征图I′∈RC×H×W:
T型特征感知卷积模块以简单而有效的方式充分利用特征图在不同通道之间的相似特性,优化特征提取过程中的计算冗余和更多内存访问的情况.PConv通过通道分割对部分输入通道进行卷积提取空间特征,保持其余的通道特征恒等变化,而并非简单删除其余通道中特征信息,这些特性信息在后续的PWconv层中作用,该层允许特征信息在所有通道中流动,将这些特征图在深度方向上进行加权组合成新的特征图.局部卷积PConv与逐点卷积PWconv的组合在输入特征图上的有效接受野看起来像T型的结构,组合结构与常规卷积操作类似,可用来提取特征,并且相比于常规卷积操作,其参数量和运算成本较低,更关注中心位置.
1.2.2 坐标注意力CA模块 通道注意力可以提高网络对关键信息的关注度,减少冗余信息的干扰,但忽略了位置信息,而位置信息对于生成空间选择性特征图非常重要.航拍图像检测目标中包含大量小目标,而随着网络的不断深入,卷积操作极易使小目标的特征信息被淹没,因此引入坐标注意力模块CA来替换ESNet主干网络中的通道注意力SE,使得模型对小目标及尺度变化大的目标具有更好的特征提取效果.
坐标注意力模块CA有2个主要步骤:坐标信息嵌入和坐标注意力生成,具体结构如图4所示.该模块优化了通道注意力使用全局池化导致的位置信息丢失问题,并且可以在增加感受野的同时避免大量计算开销.对于输入特征图M∈RC×H×W,使用大小为 (H,1) 和 (1,W) 的池化核分别沿水平和垂直方向进行一维的特征编码,增强每个通道的水平和垂直特征,高度为h与宽度为w的第c通道的输出公式分别如下:
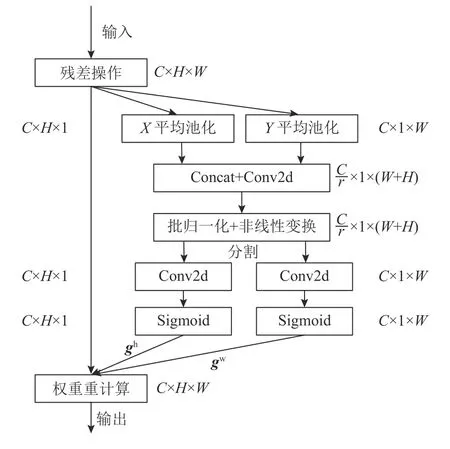
图4 坐标注意力模块结构Fig.4 Coordinate attention module structure
式中:δ 为sigmoid激活函数.
1.2.3 幽灵卷积模块 在深度学习网络模型中,特征图的学习对于模型精度的提升至关重要,特征图通过堆叠卷积层可以捕获丰富的特征信息,但往往会产生大量冗余信息,虽然该操作确保了网络对数据有更全面的理解,但它需要大量的卷积层计算,这增加了计算量和模型参数量.因此,幽灵卷积Ghost通过常规卷积操作提取丰富的特征信息,而对于冗余的特征信息,则利用更价廉的线性变换操作来生成,最终将不同的特征图Concat组合成新的输出,且输出的大小和传统卷积的输出大小一致,有效地降低模型所需的计算资源,幽灵卷积模块结构如图5所示.假定幽灵卷积模块的输入特征空间为X=[x1,x2,x3,···,xc]∈RC×H×W,其中C表示该输入特征的通道数,H×W表示输入特征的尺度大小.与常规卷积相比,首先,幽灵卷积采用尺寸为3×3的卷积核进行常规卷积操作得到特征通道较少的本征特征图(intrinsic feature maps)X1=[x1,x2,x3,···,x0.5m]∈R0.5×M×H×W,然后将X′中每一个通道的特征图xi用线性操作 Ψi来产生Ghost幽灵特征图,最后使用Concat操作将本征特征图与幽灵特征图特征拼接起来得到输出特征图为X′,X′=[x1,x2,x3,···,xm]∈RM×H×W.表达式如下:
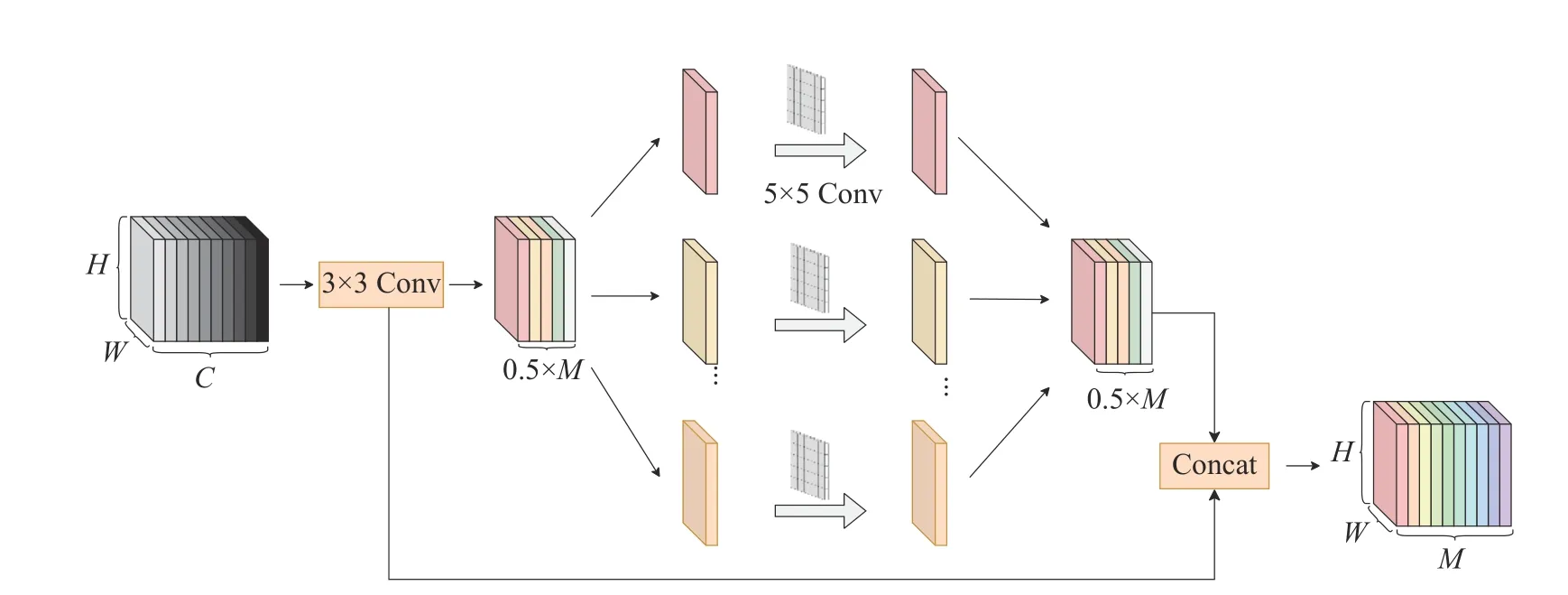
图5 幽灵卷积模块结构Fig.5 Ghost convolution module structure
式中:Ψi(xi) 表示X1中每一个通道的特征图xi用线性操作 Ψi进行特征映射,线性操作 Ψi采用卷积核为5×5的卷积深度可分离卷积DWconv来实现.本研究主要对幽灵卷积中常规卷积与线性操作中的卷积核尺寸大小进行调整.
1.3 内容感知特征重组模块
大多数网络使用经典的最近邻或者双线性插值来实现特征上采样,但这2种方式只考虑局部亚像素区域的领域像素,忽略全局内容信息,导致它们无法有效捕捉密集检测任务中必需的语义信息,这将导致航拍图像中密集分布且特征微小的目标在空间上存在信息损失风险,从而可能导致漏检增多.为了解决这一问题,在路径聚合网络(path aggregation network,PANet)上采样特征融合分支中使用内容感知特征重组模块来实现内容感知层面上的特征重组上采样,该模块具有较大的感受野与轻量化的特性,在引入少量参数的情况下可以更好地利用感知特征图中显著语义信息,增强对小目标特征的关注,提高特征传输效益.内容感知重组模块CARAFE的实现方式如图6所示.
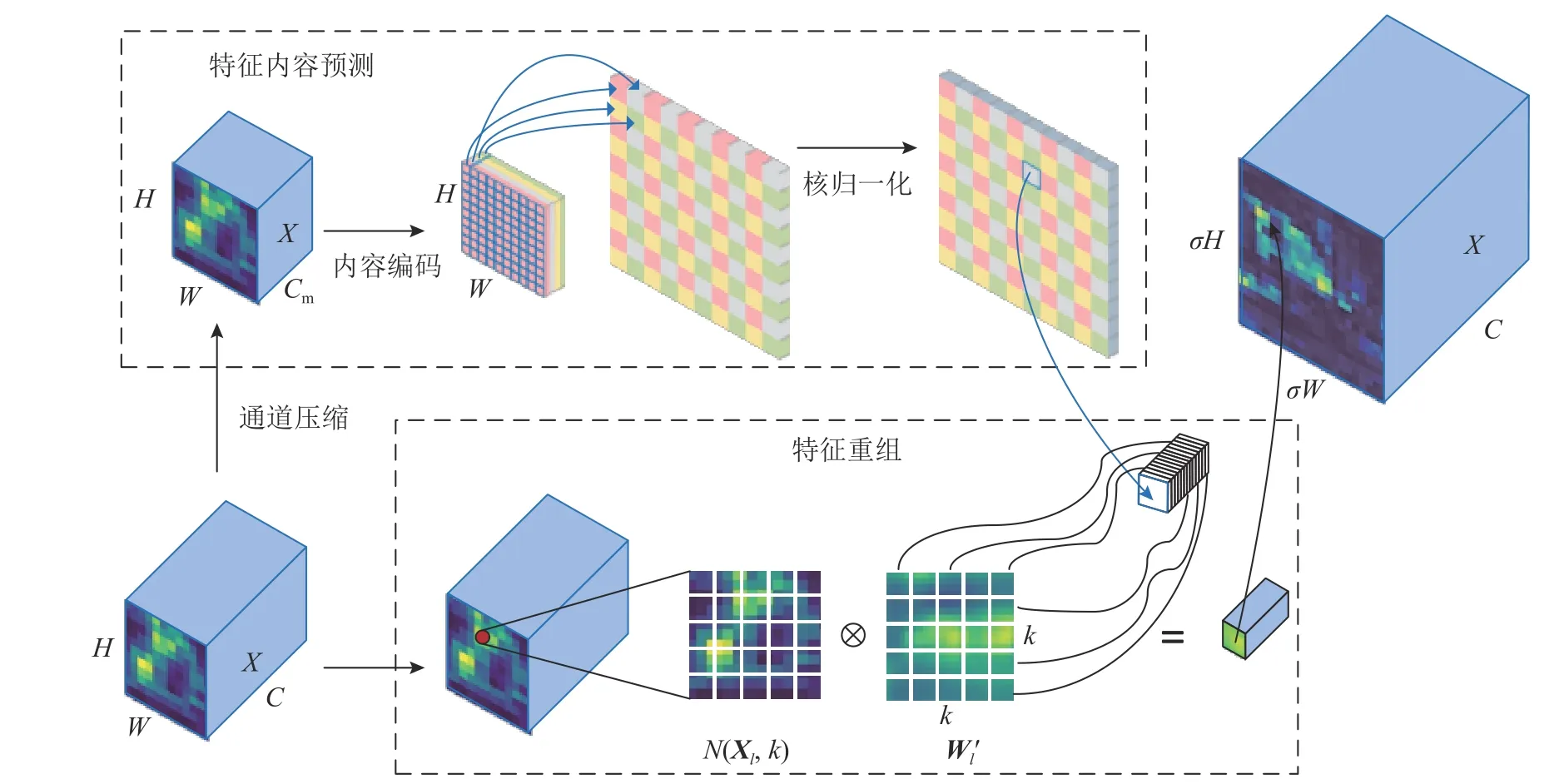
图6 内容感知特征重组模块Fig.6 Module of content-aware feature reassembly
假定内容感知特征重组模块CARAFE的输入特征图X∈RC×H×W,上采样 比例为σ,σ 为整数,CARAFE将生成尺寸为C×σH×σW的新特征图X′.该过程包括特征内容预测和特征重组2个步骤,第1步是根据每个目标位置的内容预测一个重组核,第2步是用预测的内核对特征进行重组.
特征内容预测首先对输入特征图进行通道压缩,用1×1的卷积将它的通道数压缩到Cm,操作的目的是减少后续步骤的参数和计算成本,提高CARAFE效率.其次进行内容编码,对于第1步中压缩后的输入特征图,利用一个k×k的卷积层来预测上采样核,输入、输出通道数分别为Cm、σ2×k2,然后将通道维在空间维展开,得到形状为σH×σW×k2的上采样核,最后核归一化,使得卷积核权重和为1,最终产生自适应特征重组核Wl.上述过程可以表示为
式中:fcompressor(·) 表示通 道压缩操作,fencode(·)表示内容编码操作,softmax 表示核归一化操作.
特征重组过程则是对于输出特征图中的每个位置,将其映射回输入特征图,取出以l=(i,j) 为中心的k×k区域N(Xl,k),和预测出的该点的上采样核作逐像素相乘,得到输出值.同一空间位置的不同特征图通道共享一个上采样核.特征重组的输出计算公式为
2 实验结果与分析
2.1 数据集
实验数据采用由中国天津大学发布的Vis-Drone数据集[17],数据由不同型号的无人机在不同场景以及各种天气和光照情况下收集,共有图片8 599张,训练集、验证集、测试集分别包含6 471、548、1 580张图片,图片像素尺寸为2 000×1 500,包括行人、人、自行车、汽车、面包车、卡车、三轮车、遮阳蓬三轮车、巴士及摩托车共10个类别.
2.2 实验环境及参数设置
所使用的硬件配置如下:处理器为Inter core i5 12400F,内存为32 G,显卡为NVIDIA GeForce RTX3060,显存为12 G,采用CUDA 11.7、CUDNN v8.6.0作为显卡加速库.软件环境采用Pytorch深度学习框架,操作系统为Windows11.训练设置采用随机梯度下降法(stochastic gradient descent,SGD),初始学习率为0.01,权重衰退为0.000 5,动量为0.937,输入图片大小固定为640×640像素,batch size设置为2,迭代次数为150次,在最后10次迭代关闭马赛克数据增强,在网络的训练过程中加入早停机制以防止过拟合,早停的等待轮数patience设置成50.
为了评估本实验所提算法的有效性,选用模型规模M和参数数量P以及每秒传输速度F来衡量模型的复杂程度和检测速度.同时,采用IoU阈值为0.5时所有目标类别的平均均值精度mAP0.5、IoU阈值0.50~0.95(步长为0.05)的10个阈值下的检测精度的平均值mAP0.5:0.95以及召回率R来综合评估模型的性能,采用平均精度AP来评价模型对单个目标类别的检测性能.
2.3 消融实验结果与分析
为了验证T型特征感知卷积模块TFPC、坐标注意力模块CA、幽灵卷积模块Ghost对FS主干网络的贡献,在Visdrone数据集上进行9组消融实验,实验对比结果如表2所示.表中,Case(a)表示使用ESNet主干网络替换YOLOv8s主干网络,Case(b)、(c)、(d)表示在Case(a)的基础上分别引入TFPC模块、CA模块、Ghost模块,Case(e)、(f)表示在Case(b)的基础上分别引入CA模块、Ghost模块,Case(g)表示在Case(c)的基础上引入Ghost模块,Case(h)是完整的FS主干网络.如表2所示,由Case(a)到Case(b),使用T型特征感知卷积模块TFPC改进ESNet模块,mAP0.5从45.2%提升到45.9%,mAP0.5:0.95从27.5%提升到28.1%,R从43.3%提升到43.4%,算法模型的参数量和模型规模只增加了0.42 M和1.6 M,速度下降可以忽略不计,T型特征感知卷积模块TFPC可以在增加有限的模型复杂度情况下,改善模型的特征提取与表达能力,提高航拍图像检测的精度.由Case(a)到Case(c),在引入坐标注意力模块CA后,mAP0.5从45.2 %提升到45.4 %,R从43.3 %提升到43.7 %,模型的参数量没有变化,检测速度略有下降,坐标注意力模块用于改善模型的特征表达能力,增强模型对小目标及尺度变化大的目标的重点位置特征的关注度.值得一提的是Case(a)到Case(d),在引入改进的Ghost模块后,mAP0.5下降了0.1%,但是Case(g)、(h)引入改进的Ghost模块,相较于Case(c)、(e),mAP0.5分别上涨了0.3%和0.1%,主要是因为本研究对Ghost的中常规卷积与线性操作中的卷积核尺寸大小进行调整,该模块拥有了更大的感受野,使得后续的坐标注意力模块CA能够更好地捕捉目标物体的特征.总的来说,TFPC模块、CA模块和改进的Ghost模块可以有效提高网络的性能和表达能力,FS主干网络比基准网络提升了5.3%的mAP0.5,并且mAP0.5:0.95与召回率分别上涨了3.7%、5.2%,模型参数量降低了52.6%.
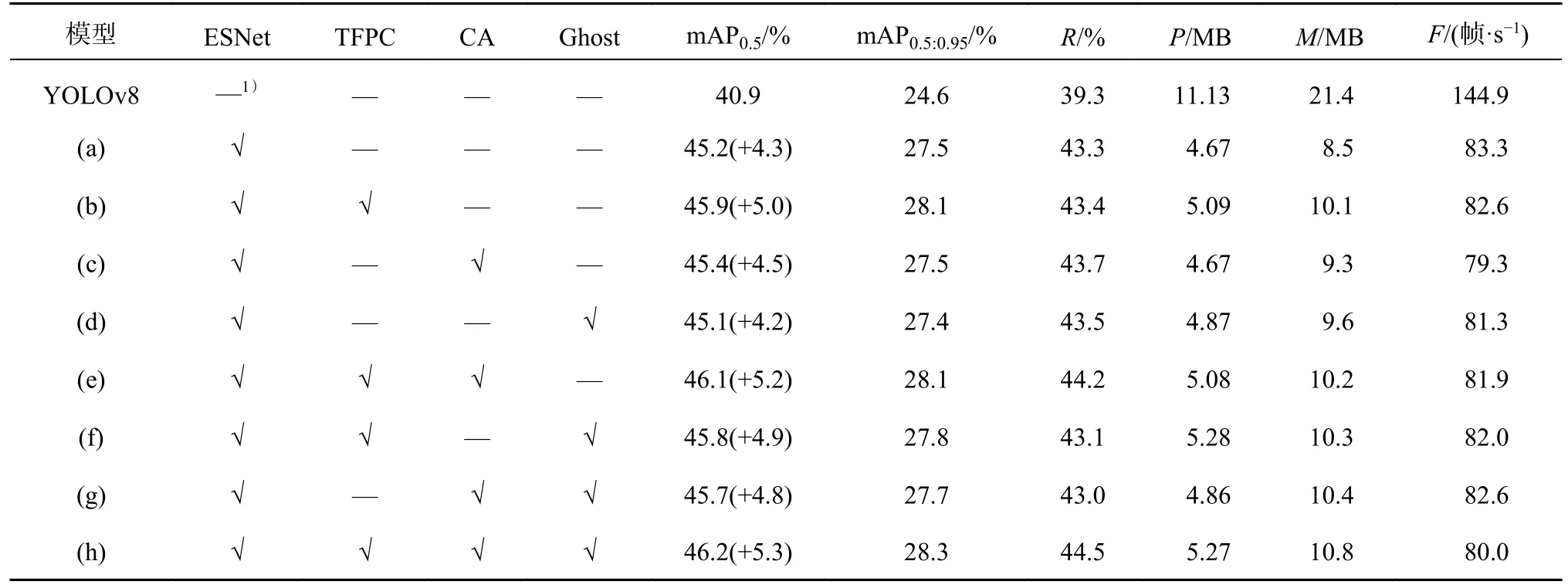
表2 主干网络消融实验的检测性能结果对比Tab.2 Comparison of detection performance results of Backbone ablation experiment
在引入FS主干网络的基础上,进行消融实验验证在特征融合上采样过程中,CARAFE模块放置在不同位置时对网络的贡献,结果如表3所示.CARAFE(a)表示在表1中的第9层单独引入一个内容感知特征重组模块替换最近邻上采样.CARAFE(b)表示在第12层,引入一个内容感知特征重组模块,mAP0.5提升了0.3 %.CARAFE(c)表示同时引入2个内容感知特征重组模块,在引入内容感知特征重组模块后,mAP0.5从46.2%提升到47.0%,mAP0.5:0.95从28.3%提升到28.8%,召回率R从44.5%到47.7%,由此可知,同时引入2个内容感知特征重组模块的效果更优,虽然模型参数量增加了0.21 M,但是在小幅增加成本的情况下,检测速度仍然达到68.0 帧/s,满足实时性要求.
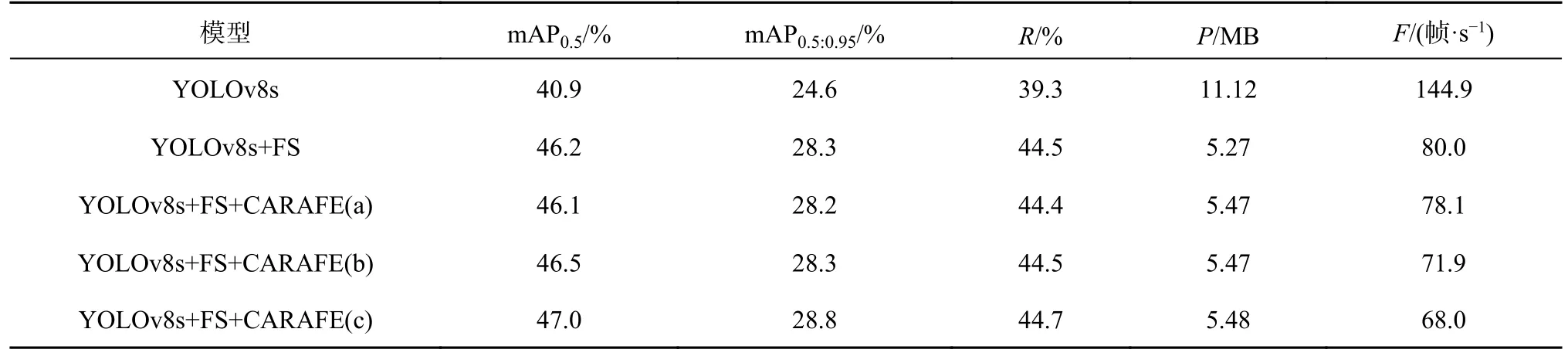
表3 颈部消融实验的检测性能结果对比Tab.3 Comparison of detection performance results of neck ablation experiment
2.4 对比实验
为了进一步验证FS-YOLO算法在航拍图像各类目标检测中的性能,在保证算法的训练环境和数据集相同的条件下,在VisDrone数据集上与其他先进的航拍图像检测算法进行比较分析.如表4所示为VisDrone数据集上10类目标在各种先进算法上的AP、mAP以及每种算法的参数量.可以看出,对比其他算法,FS-YOLO算法在人、汽车、面包车、摩托车等目标类别的检测性能方面表现最优,AP分别为43.6%、85.0%、51.4%和54.9%.对于行人、卡车、三轮车、巴士等横纵较大且实例个数较少的类别,该算法同样表现出不错的检测性能,AP分别为53.1%、41.3%、35.3%和66.0%,较优.这说明该算法在各种目标场景下都有着相当不错的检测表现.FS-YOLO航拍图像检测算法不仅在各类目标检测性能上超越了其他算法,还成功减小了模型参数量.值得一提的是,FSYOLO算法的参数量只有5.48 M,在mAP0.5检测精度上超过了参数量为43.69 M的YOLOv8l算法.所提出的FS-YOLO算法在处理航拍图像目标检测任务时能够发挥出较大优势,特别在目标实例数量较少的情形下,该算法可以充分利用目标实例的冗余特征信息.因此,相比其他算法,FSYOLO算法在这种情况下的表现更加出色.
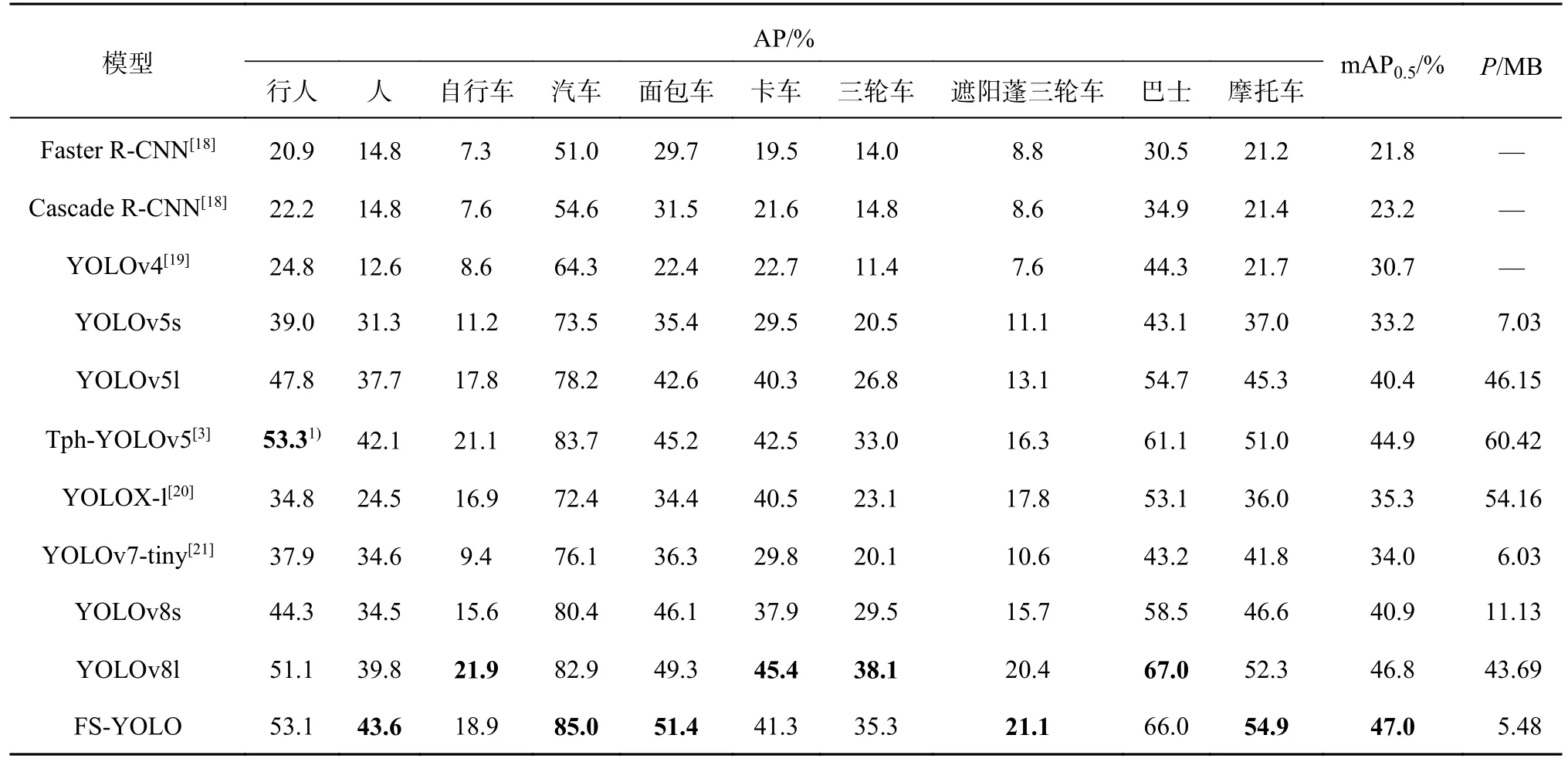
表4 不同算法在VisDrone数据集上的平均精度和参数量对比结果Tab.4 Comparative results of different algorithms in average precision and parameters on VisDrone dataset
2.5 可视化分析
为了充分验证FS-YOLO算法在不同图像场景中的适用性,还从VisDrone数据集中挑选了一些具有光线变化、高空视野、夜间环境、密集遮挡等复杂场景以及暗光密集极端场景的航拍图像样本进行测试,检测结果如图7所示,由样例(a)、(b)对比分析,在光线明暗变化较大的场景下,FS-YOLO模型相较于基准模型具有更好的鲁棒性.通过样例(c)、(d)对比分析,高空视野下FS-YOLO模型的整体检测率高于基准算法,能够更加关注目标的中心位置,抑制背景噪声信息干扰并保留对目标决策更具重要性的特征信息,在背景的复杂航拍视角场景中表现出更好的目标检测能力.通过样例(e)、(f)对比分析,在夜间环境中FSYOLO算法相较于基准算法的漏检率更低,可以在高重叠的对象簇中更准确地检测到实际对象,特别是在远距离视图下,依然可以正确检测到更多的汽车.通过样例(g)、(h)对比可以看出,FSYOLO可以在密集遮挡的场景下,准确检测出远视距下的行人小目标.通过样例(i)、(j)可以看出,在暗光并且小目标密集的场景中,相较于基准算法,FS-YOLO对摩托车、行人小目标有着更高的检测准确率.总的来说,FS-YOLO模型在复杂场景特别是远视距下检测性能有着较大的提升.

图7 VisDrone数据集上的复杂场景目标检测效果对比Fig.7 Comparison of target detection effectiveness in complex scenes on VisDrone Dataset
2.6 泛化性实验
采用由西北工业大学于2019年发布的DIOR遥感数据集(http://www.escience.cn/people/gongcheng/DIOR.html)进行泛化性对比验证,以全面验证本研究方法的有效性和鲁棒性.该数据集是大规模公开可用的光学遥感图像数据集,包含各种成像条件、气候下的图像.图像的像素尺寸为800×800,涵盖了20个目标类别,包含23 463张图像,共计192 472个实例,数据集具有尺度差异性大和背景复杂的特点,适合用来进行泛化性实验验证本研究算法的有效性和泛化能力.遵循DIOR数据集官方提供的数据划分建议,训练集、验证集、测试集中图片数目分别为5 862、5 863、11 738张,并按照默认设置使用FS-YOLO网络在该数据集上进行了150个轮次的模型训练.
实验结果如表5所示,在航拍数据集DIOR上,所提出的FS-YOLO模型相对于YOLOv8s模型,在检测精度上取得了2.1%的提升,达到了74.3%,明显优于基于两阶段算法的Faster R-CNN.通过图8中展示的部分DIOR数据集检测实例分析可得,所提出的模型在漏报率和密集目标检测精确率上优于YOLOv8s模型.实验表明,本研究算法在处理小目标众多、密集遮挡以及尺度差异大的数据集时具有不错的鲁棒性和泛化能力.
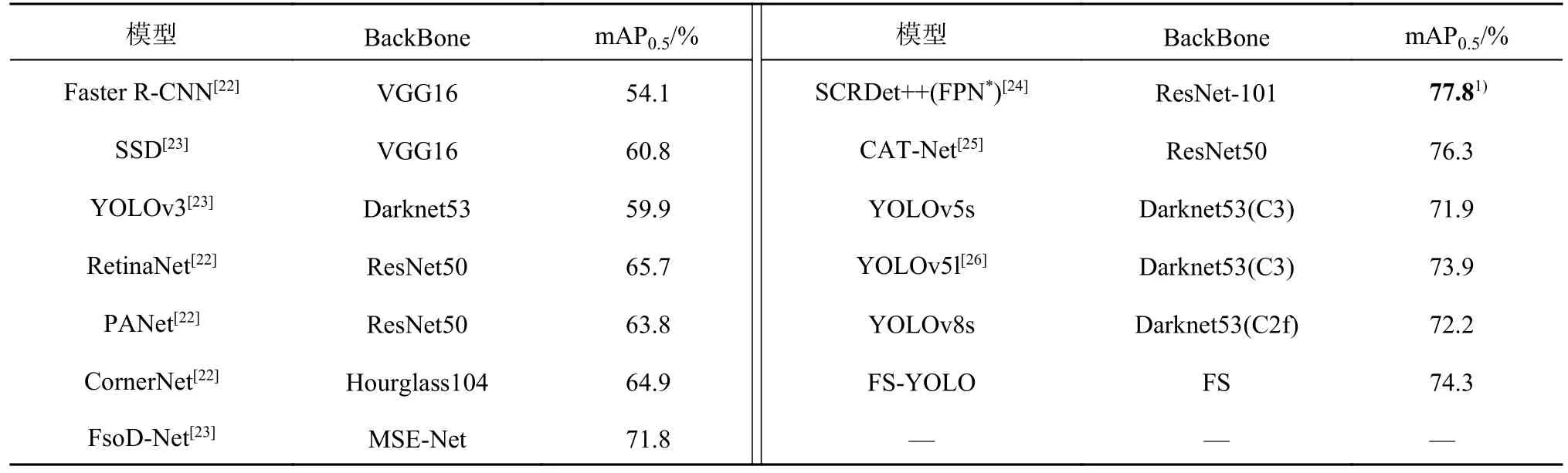
表5 不同算法在DIOR数据集上的对比结果Tab.5 Comparison results of different algorithms on DIOR dataset

图8 DIOR数据集上的检测效果对比Fig.8 Comparison of detection effects on DIOR data set
3 结语
提出轻量高效航拍图像检测算法FS-YOLO.在特征提取方面,提出改进的轻量化特征提取网络FS,在FS基础模块中加入T型特征感知卷积,提高对待测目标中心位置的感知,引入坐标注意力模块,优化检测网络对目标区域定位与识别的精准性.在特征融合方面,引入内容感知特征重组模块替换原本的最近邻上采样,该模块在上采样时具有更大的感受野,增强了网络对周围相关语义信息的特征感知同时优化了上下文语义信息之间的联系,从而增强了小目标的细节特征信息的表征能力.在VisDrone数据集上进行实验,结果表明,在模型参数量仅为5.48 M的情况下,mAP0.5达到了47.0%,比基准算法YOLOv8s的参数量降低了50.7%,精度提升了6.1%;FS-YOLO对航拍图像有较好的整体检测效果,在DIOR数据集上的泛化性实验表明,其精度相较于YOLOv8s提升了2.1%,验证了FS-YOLO模型的有效性,能较好地应对无人机图像目标检测任务.
FS-YOLO的检测效果在目标像素点个数极少、特征不明显且背景复杂的极端情况下仍有改进空间.未来研究可以从2个方面展开:一方面,考虑到航拍图像中目标角度多样性的特点,通过引入多模态数据融合的方法,利用不同模态之间的互补信息来优化检测算法,以进一步提高航拍图像的检测精度;另一方面,通过采用模型剪枝或者知识蒸馏的方式,着手研究如何提升检测速度,以满足无人机平台算力有限的情况下实际测试部署的需求.
