科技文献创新内容的识别、组织与应用进展
2024-03-11徐雷张亚菲叶均玲
徐雷,张亚菲,叶均玲
(1. 武汉大学语义出版与知识服务实验室,武汉 430072;2. 武汉大学文化遗产智能计算实验室,武汉 430072)
0 引 言
科技文献是当前科学知识的主要载体以及科学交流的主要对象,其中蕴含的科学创新内容既是科学研究成果的集中体现,也是科学交流的具体对象,科研人员通过科学论证手段对科学创新内容进行叙事表达,形成科学论文,促进了科学知识的传播及新的科学创新进程。然而,随着科技文献的大量涌现,科研人员对科学创新内容的跟踪、理解、运用面临越来越大的压力,科学交流活动面临“知识过载”的危机,科学创新内容急需新的叙事手段,以有效地推动科学论证、科学评价等科学交流活动。科技文献是当前创新内容的主要载体,其通过不同的修辞论证结构对创新内容进行叙事表达,因此,当前主流实践主要采用从科技文献中识别抽取创新内容的方式来呈现创新内容本身。然而,这类实践以验证科学创新内容识别方法的性能为主,缺乏从宏观层面探索新的创新内容叙事方式以及基于这种叙事方式的科学交流机制的相关研究。
本文一方面梳理了科学创新相关概念的内涵,归纳总结了创新内容识别抽取的主流实践及主要问题;另一方面重点分析了当前创新内容结构化组织的主要数据模型及基于创新内容的应用场景,并从宏观层面上构建了基于创新内容这一核心要素的科学交流框架,探讨了实现该框架所面临的挑战。
1 科学创新与科学创新的表达
1.1 科学创新的内涵及其主要特征
科学创新可以简单地理解为创新的一种类型,既可以是指在科学领域从事的创造性活动,其具有动态性,强调科学发现的过程;也可以是指创新活动的成果,具有静态性,用于表达科学发现的结果。本文主要是指后一种类型。作为科学社会学代表人物之一,哥伦比亚大学社会学教授巴伯将科学创新定义为“人类对社会生活中已经存在的科学要素所作的富于想象力的结合”[1];Science杂志认为,科学创新是指对自然或理论提出新见解[2];国际权威创新调查指南《奥斯陆手册:创新数据的采集和解释指南》认为,科学创新是对已有的思想、技能、资源等的新组合[3]。从创新的过程来看,科学创新是指创新主体借助一定的方法产生创新成果,并创造出科学价值的过程。其中,创新主体是指创新实践的参与者,如科研人员、研究机构等;创新成果是指创新实践的产出,如发现新规律、产生新见解、发明新药物等创新内容;创新的科学价值是指创新成果所带来的潜在影响,主要体现在对科学发展本身的推进以及在生产生活中的应用。
作为科学交流活动的主要对象,科学创新本身具有一定的特征,如新颖性(novelty)[4]、独创性(originality)[5]、价值性[6]、简明性[7]等。其中,新颖性是科学创新最本质的特征,能够显示与其他科学创新的差异,这种差异既可以是“局部改进”式的渐进式创新,也可以是“全新”的突破式创新;独创性是指科学创新是由研究者独立创作而产生的,而不是对已有研究完全的或实质性的模仿;价值性反映科学创新成果可对相关领域产生的潜在积极影响;简明性是指在表达方式上,科学创新内容应当有易读性、“宣传”性等特点。
1.2 科学创新类型及其在科技文献中的表现
科学创新具有不同的类型,根据创新的程度,可以分为库恩科学范式下的渐进式创新和突破式创新[8];根据创新的价值属性不同,可以分为科学发现和技术发明[9]。其中,科学发现在于确定性科学知识的发掘,反映科学的求真过程,如探索各领域现象背后的规律,把尚不为人知的事物首次揭示出来等;技术发明强调科学创新的应用价值,依据科学知识创造出过去从来没有存在过的新事物,来促进相关领域的发展与进步。根据科学创新内容所在的科技文献篇章结构和内容特征,可以将其划分为研究问题创新、理论研究创新、研究方法创新、成果与应用创新[5,10]等类型。就当前的科学交流环境而言,无论何种类型的科学创新,都需要借助一定的载体进行表达传播和创新扩散。科技文献是当前创新内容的主要表达载体,具体的创新内容一般表现为论文结构化摘要中的结论句、作者提炼的创新点等内容,这些核心内容表达了科学创新的本质。
在科学研究及相关实践中,除了“originality”“novelty”“creativity”“innovation”这些内涵宽泛的表述外,特指科技文献中的科学创新内容的词汇还有“创新点(innovation points)”“学术贡献(contribution)”“研究亮点(highlights)”“科学主张(claim)”“科学断言(assertion)”等表达,这些词汇都可用于指代科学创新的具体内容,在实际应用中会根据科学创新成果的使用环境来选择,本文统一使用“科学创新内容”来指称。其中,“创新点”是科学创新的最常见表达;“学术贡献”通常包含两层含义:科学创新的具体内容以及创新的意义与价值[11];“亮点”最早由爱思唯尔于2010年在其学术数据库中设计出来[7],从内容上讲,亮点是作者撰写的一组论文的核心发现,是一篇科技文献与其他论文相比较的新成果、新结论等内容的体现,通常表现为一组规范的、语义明确的3~5个短句[12];“主张”[13]和“断言”[14]的内涵相似,既可以是研究者对基本科学事实的论断,也可以是对科学创新内容的判定,其内容具体体现为科学事实、科学发现等知识单元。当前,科学创新内容主要以文本形式进行表达,即显性的文本知识,并通过科技文献这一载体进行科学论证。创新点、学术贡献、亮点等具体科学创新内容集中体现在科技文献的摘要、结论等部分[5,7,15-16],具有不同的文本粒度,可以是一个段落、若干句子或短语等。
科技文献作为当前科学创新的主要表达载体,在当前科学交流环境中发挥了巨大作用。然而,随着科学创新内容越来越多地隐藏于海量科技文献中,这一表达形态已逐渐不能满足科研人员高效获取创新知识的需求,于是出现了关于创新内容等知识元的识别抽取、长论文智能摘要、视频论文等实践及科学知识表现形态。本文重点围绕科学创新内容这一核心对象展开研究,从当前科学创新内容识别与抽取、结构化组织及基于结构化科学创新内容的应用场景3个维度进行系统归纳,基于此设计了在新的科学知识表达机制下的科学交流潜在场景及其实现框架。
2 科技文献中创新内容的识别与抽取
作为一种知识元类型,创新内容的识别与抽取是科学信息抽取(science information extraction,sci‐ence IE)任务之一。当前,科学创新内容的识别与抽取主要包括3类方法,分别为基于规则的创新内容识别与抽取、基于机器学习的创新内容识别与抽取以及基于深度学习的创新内容识别与抽取。
2.1 基于规则的创新内容识别与抽取
基于规则的科学创新内容识别与抽取方法,是通过对创新内容的语言特征进行分析,制定相应的抽取规则进行抽取。主要可以分为基于词汇和基于句法结构的识别抽取方法。
2.1.1 基于词汇的方法
基于词汇的科技文献创新内容抽取可以分为两类:一类基于触发词,另一类依赖于领域词汇。其中,触发词是能够充分表征科学创新的词汇,中文触发词有“突破”“解决”等,英文触发词有“novel”“present the first…”等;领域词汇作为一个学科领域的核心词汇,对创新内容的研究主题具有揭示作用。
已有研究表明,论文创新内容中由触发词引导的占比高达98.4%[17],为基于触发词的创新内容抽取的可行性提供了统计依据。基于触发词的抽取方法往往用于创新内容的初次筛选,在流程上可分两个步骤:触发词的选取和创新内容的抽取。
目前,触发词的选取主要依靠手工进行,涵盖名词、形容词、动词等多种词性。在触发词的基础上构建创新内容抽取规则,利用规则对科技文献句子集进行匹配,形成创新句候选集[5,7]。由于非创新内容的句子中也可能包含触发词,基于触发词对创新内容进行抽取的查全率高,但其查准率较低。因此,该方法往往用于创新内容的初次筛选,形成创新内容候选集,以便后续使用机器学习方法或更详细的抽取规则对创新内容做进一步的识别。
依赖领域词汇的创新内容识别方法,是借助领域词汇的近义词、同义词,以及领域本体的概念层级关系,最大限度地揭示句子研究的主题,确保抽取出的创新句子集与研究主题密切相关,提高抽取结果的准确度。因此,为了迅速、准确地识别科技文献中的创新内容,需要借助学科领域的词表或知识库辅助信息抽取工作。基于领域词表的创新内容抽取可分为3个步骤:领域词表或本体的构建、基于领域词表的文本自动语义标注和基于语义标注的创新内容抽取。在实践中,往往先自行构建领域词表或知识库,或以已有的领域词表或本体为基础,使用词表或知识库对科技文献进行全文内容的语义标引,最后结合创新内容的写作一般规律和此领域的主要研究内容,制定创新内容抽取规则,抽取出创新句子集[18-19]。
2.1.2 基于句法结构的方法
科技文献创新内容往往遵循特定的表达范式[20-21],因此,可以根据句法结构对创新内容进行识别。该抽取方法主要包括3个部分:预处理过程、规则的构建和基于规则的抽取[15,19]。预处理过程主要包括分句、分词和语义标注;规则的构建需要充分考虑创新句的语言特征和句法结构,需要领域专家的参与,可以采用正则表达式等进行表征;最后,基于规则抽取创新句,通过实验证明抽取效果。有些创新句子并不遵循创新内容的常用表达方式,针对此类创新内容,研究者往往为其制定专用的句子模板[22],通过模式识别进行抽取。基于常用表达方式构建的规则可视为基础规则,基于特殊表达方式构建的规则可视为扩展规则,二者可以相互补充,形成组合规则,优化抽取效果,丰富创新内容抽取的规则库。利用句法结构可以从科技文献中识别出揭示创新内容的句子,但还没有揭示创新句内部主题概念的关系。对创新句进行依存句法分析[23],可以实现创新内容的细粒度识别与分析,如识别创新内容的核心主题词、实体对及其语义关系、属性实例等。
通过主流实践的观察发现,在对创新内容进行抽取时,基于触发词的方法、基于领域词表的方法以及基于句法结构的方法,往往并不是单独使用某一种方法,而是采取多种方法的结合,相辅相成,其常见的结合方式如图1所示。科技文献中的文本信息可以表达科学创新。此外,科技文献中的图片、表格等可视化元素往往也能够反映创新成果,因此,有些研究基于规则和启发式的方法,对文献中的图表等可视化表示元素进行创新内容的识别[24]。

图1 基于规则的创新内容抽取方法一般流程
基于规则的方法,其优势在于可解释性及领域针对性强,不足之处在于查全率低、规则设计困难且移植性差。查全率低是由于仅凭人工经验制定的抽取规则具有局限性,选取的特征和制定的规则无法完全覆盖创新内容的所有语言学现象。规则设计困难是因为依赖于领域专家的参与,为保证查全率而设计足够多的规则时,难以保证各规则间不冲突、不冗余,学科领域间的差异使得不同领域之间的抽取规则难以直接移植复用。
2.2 基于机器学习的创新内容识别与抽取
此类方法通常将创新内容抽取问题转化为句子分类问题,如二分类问题[25]和多分类问题[23,26-28],主要是将表达科技创新内容的句子划分为事实、假设、问题、方法、结果、意义、目标等多个语义类型,再利用机器学习模型对全文进行句子语义类型的自动分类。Cagliero等[29]率先提出了一种基于回归技术的有监督方法,该方法可用于确定科技文献中与亮点相似性最高的K个句子,并以此对句子进行标注,形成训练集,将训练好的回归模型用于预测文献中句子与亮点之间的相似度,相似度越高的句子越有可能作为科技文献的亮点。
从机器学习的流程来看,主要包括以下几个步骤:获取数据、文本预处理、特征选取、模型训练与调优,以及评估。具体来看,数据集可以是科技文献的全文或摘要,主要来自生物医学[30-31]、材料化学[32-33]、信息科学[19,34]等写作风格较为统一、关键创新内容较为明确的理工科领域。文本预处理过程主要包括分词、分句或子句切分、标题划归和人工类型标注等[23]。其中,子句是文本中语义完整、不中断的区间[35],是一种介于句子和从句之间的粒度,子句切分可以用于更细粒度的创新内容识别与抽取。句子所在的章节与句子是否为创新内容具有相关性,创新内容更可能出现在摘要、研究结果和结论等章节[7],因此,需要进行标题划归,将所有标题都转换为“摘要”“引言”“相关研究工作”“研究方法”“研究结果”“结论”等标准章节标题中的一个,以便将宏观的结构信息结合到机器学习模型中。完成预处理后,主要选取以下特征:①词性;②词表;③时态,现在时的句子更可能是既有事实,过去时的句子更可能被预测为研究结果[36];④章节名称,创新内容更可能出现在摘要、研究结果和结论等章节[7];⑤引用,引用了其他文献的句子更可能是既有事实,而指向公式或图表的句子则更有可能是研究结果[37]。接下来,利用标注语料训练支持向量机、条件随机场、随机森林、梯度提升等多个机器学习分类器,并选择其中效果较好的一个分类器,或将多个效果较好的分类器进行集成,作为最终的模型对科技文献全文进行句子类别的识别,将创新内容抽取出来形成创新句子集。
2.3 基于深度学习的创新内容识别与抽取
相较于传统机器学习方法,深度学习更能够自动找出对分类很重要的特征。深度学习方法既可以从学术文本中抽取创新内容,也可以对创新内容做进一步的细粒度抽取。运用深度学习方法抽取创新内容时,由于当前创新内容数据集的缺乏,往往需要以科技文献全文本作为数据来源,自行构建创新内容数据集,在数据集上训练BERT(bidirectional encoder representations from transformers)、Trans‐former、RNN(recurrent neural network)等深度学习模型,并将训练好的模型用于识别表述学术论文创新内容的句子[38-41]。
具体来看,在科技文献创新内容抽取方面有更多实践将深度学习模型与基于规则的抽取方法、传统机器学习模型结合使用。深度学习和基于规则的方法相结合,既可以先利用集中体现文章核心创新内容的主题词和体现创新内容语言特征的触发词等制定抽取规则,对全文进行筛选,初步形成候选创新句子集,再利用深度学习模型从候选句子中识别出创新句[10];也可以先利用深度学习模型,判断是否包含科学创新相关表述,再制定规则对创新句进行细粒度的抽取[11,42],如进一步从创新内容中抽取出研究方法、研究成果、研究价值等要素。将机器特征和人工特征融合,可以有效提升抽取效果[43],因此,有学者利用“深度学习模型+传统机器学习模型”的方法,将来自篇章、句子、字词3个层面的26个人工特征指标与word2vec和one-hot等机器特征基于LSTM(long short-term memory)、CNN(convolutional neural networks)、BERT模型从横向、纵向进行特征融合,完成科技文献中实验设计因素[44]、论断句(claim sentence)[45]等创新要素的抽取。也有学者将在其数据集上表现最好的传统机器学习模型(深度森林模型)和深度学习模型(BERT模型)进行融合,融合后的模型表现优于先前独立的两个模型[27]。
上述方法均可用于从学术文本中抽取出创新内容,若需要对创新内容做进一步的细粒度挖掘,如挖掘出创新内容中的方法、结果、价值、论据等实体及其之间的因果、从属、比较、补充等关系,则需要对创新内容构建结构化语义模型,如Vogt等[46]提出的研究贡献模型(research contribu‐tion model,RCM)和Magnusson等[47]提出的科学主张图模式(graph schema),按照构建好的语义模型中定义的概念和概念间的关系对训练文档进行标注,通过标注好的大量文档对深度学习模型进行训练,利用深度学习模型实现对创新内容的细粒度挖掘,自动填充知识库,从而构建出细粒度的创新内容知识图谱,如开放研究知识图谱(open research knowledge graph,ORKG)[48]和科学主张数据集(SciClaim)[47]。
面向科学领域的信息抽取是图书情报领域的主流研究方向,当前围绕科学创新内容的识别与抽取的研究重点在于开发相关机器学习算法。这些研究通常以科技文献全文或摘要作为数据来源,在模型的选取上,主要采用统计机器学习模型与深度学习模型相结合的方法,已在若干领域取得了较好的效果。同时,该方法存在显著的学科差异,其应用集中在生物医学、材料化学及信息科学领域,部分研究将其应用于社会科学领域[47],但目前尚未有研究将其应用于艺术人文等学科,模型的泛化能力、算法的可移植性仍有待探索考证。
3 科技文献中创新内容的结构化组织
如果将抽取的创新内容以新的形式结构化组织起来,将促进科研人员或计算机对创新内容的理解与处理。将创新内容进行结构化组织,实现创新内容之间的关联,将有利于针对创新内容的细粒度检索、基于关联创新内容的知识发现,促进知识传播和科学交流。由于创新内容一般表现为若干句子的集合,目前已有的科技文献相关的结构化数据模型都具有不同程度的组织创新内容的能力,主要分为两类:通用数据模型和专有数据模型。通用数据模型本身并非专门针对创新内容而构建,但可以用于创新内容的结构化组织,如篇章结构模型[49]和纳米出版物模型[50]等;专有数据模型是专门针对创新内容而构建的,可以对创新内容中的细粒度科学概念、实体、关系等进行细粒度的组织。
3.1 通用数据模型对比
目前,通用数据模型主要有两类:论证结构模型和篇章结构模型。如表1所示,论证结构模型用于对科学论文的论证要素进行结构组织,主要包括图尔敏模型(the Toulmin model)[51]、论证模型本体(argument model ontology,AMO)[52]、SWAN(semantic web application sineuro medicine)本体[53]和微型出版物(micropublication)[54]等;篇章结构模型专门用于对论文中的研究目标、假设、论据、方法、实验及结论等体现科学创新内容的功能元素进行组织[55],经典的篇章结构模型主要有CISP(core information about scientific papers)本体模型[56]、核心科学概念框架(core scientific concepts)模型[57]和SPAR(semantic publishing and referencing)系列本体[58]等。

表1 创新内容结构化组织的通用数据模型
3.2 专有数据模型对比
相较于通用数据模型,专门针对创新内容构建的结构化表征模型数量更多,如表2所示。有些模型将创新句拆分为若干个相互关联的核心概念,如研究贡献模型(RCM)[46]、文摘创新内容语义模型[6]等。篇章结构中的结论要素是创新性研究成果的总结,能够表示科技文献中的关键创新内容。有研究提出了基于纳米出版物的结论型知识元语义描述模型[60]和涉及科技文献结论的知识元本体[2],并对结论部分进行结构化组织。科技文献创新内容的形式语义较为复杂,有学者在三元组的基础上,提出了用于表示不确定性知识(即带有假设性、推测性或互相矛盾的科学创新内容)的四元组[61]、用于表示科学主张的super pattern五元组[62]。科学数据集构建的过程中会使用相应的数据模型,比如,在构建科学主张数据集(SciClaim)的过程中,提出了用于指导标引工作的图模式,该模式可用于创新内容的结构化组织[47]。此外,有些创新内容分类模型,如自然语言处理(natural language processing,NLP)领域研究贡献模型[63]和研究贡献分类模型[64]等,将科技文献划分为研究问题、方法、结果等具有学科特色的篇章类型,而创新内容则在形式化后被赋予上述特定类别。
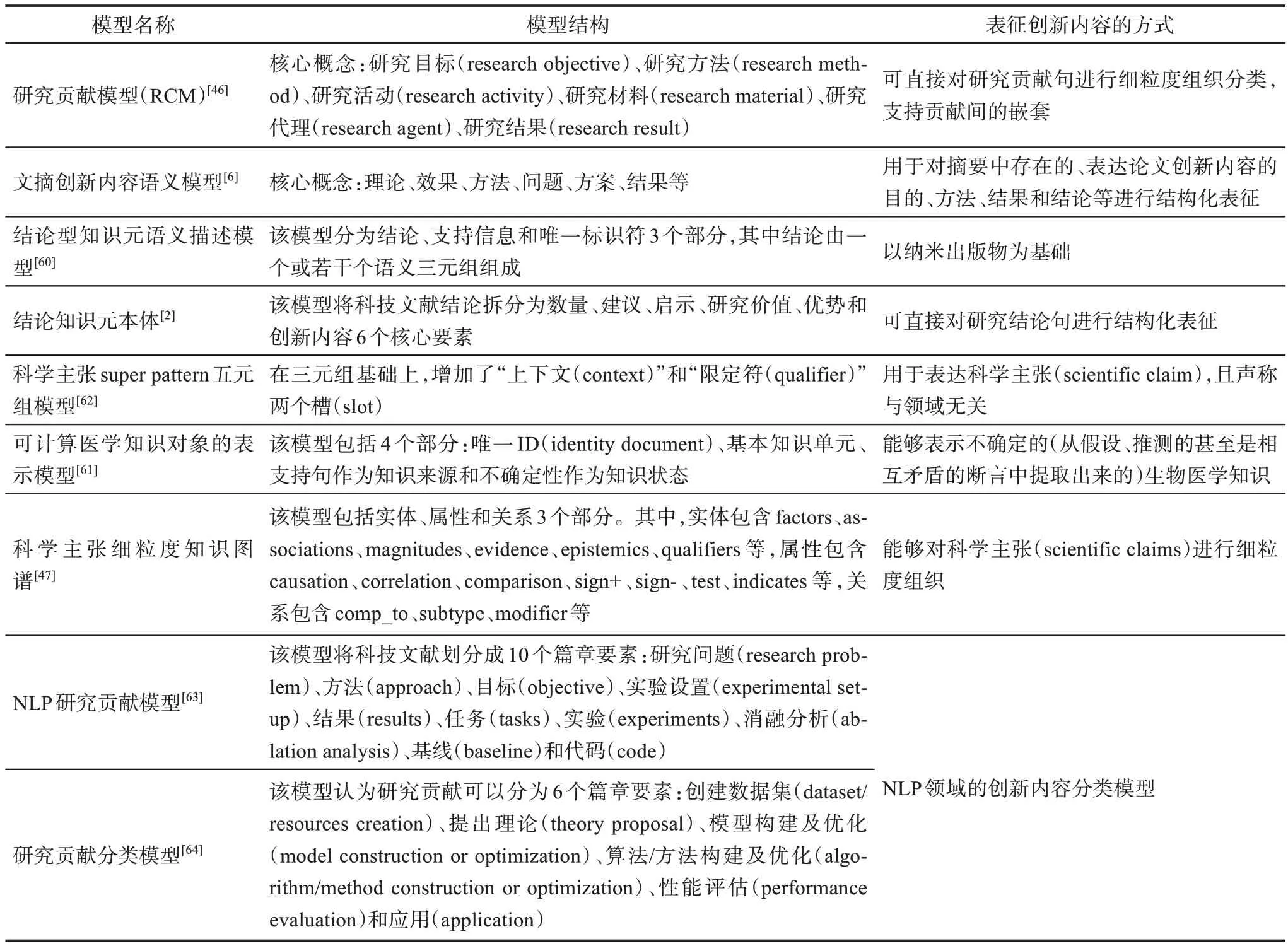
表2 创新内容结构化表征的专有模型
通过综合对比分析发现,首先,目前对创新内容进行结构化表征的模型通常以语义技术为基础,从数据来源上看,仍以理工科文献为主。其次,绝大多数已有模型都是对单篇科技文献的单个创新内容进行结构化组织,而科学创新通常是相对于以往的科学实践而言,对科学创新的表征应具备和相关的科学实践发生关联的能力,以支持不同科学创新之间的语义互操作,这种关联机制还有待深入探索。最后,已有模型通常致力于创新内容本身的结构化,如果能够将研究人员、贡献的大小、研究的价值等科学创新要素及特性关联起来,那么可以在科学交流系统中发挥更大的作用。此外,目前众多模型对创新内容的认知及表征的粒度都有较大差异,有些模型适用于创新内容的细粒度论证,有些适用于创新内容的篇章类型组织,有些模型可对创新内容进一步细粒度化到概念、词汇级别,有些模型则只表征到句子级别。
3.3 科技文献创新内容相关数据资源
数据模型是对创新内容特征及其关系的抽象,而创新内容数据集和知识库包含了科学创新内容的具体描述,数据资源的质量在一定程度上反映了数据模型的质量;反过来,数据资源又可以对模型的合理性、适用性进行有效的检验。目前,与科技文献创新内容相关的数据资源主要分为两类:机器学习数据集和语义知识库。
3.3.1 创新内容相关的机器学习数据集
运用机器学习方法对创新内容进行抽取或结构化组织时,一般需要有数据集对模型进行训练和测试。科技文献创新内容机器学习数据集可细分为两类,如表3所示。一类是以科技文献全文或摘要作为数据来源进行创新句判断、标注所构建的数据集,目的在于创新内容的识别。例如,CSPubSum基准数据集[39]、SciARG数据集[65]分别从计算机科学和生物医学文献中标注了其中的创新句和创新主张。另一类是对创新内容中的论证结构、实体关系、创新内容类型等进行细粒度的标注,以帮助实现科技文献创新内容自动结构化表征,如捕捉实体间关系(如因果、比较、统计、比例)的SciClaim数据集[47]、对研究贡献进行分类的研究贡献数据集[64]和NLPContributions数据集[63]等。
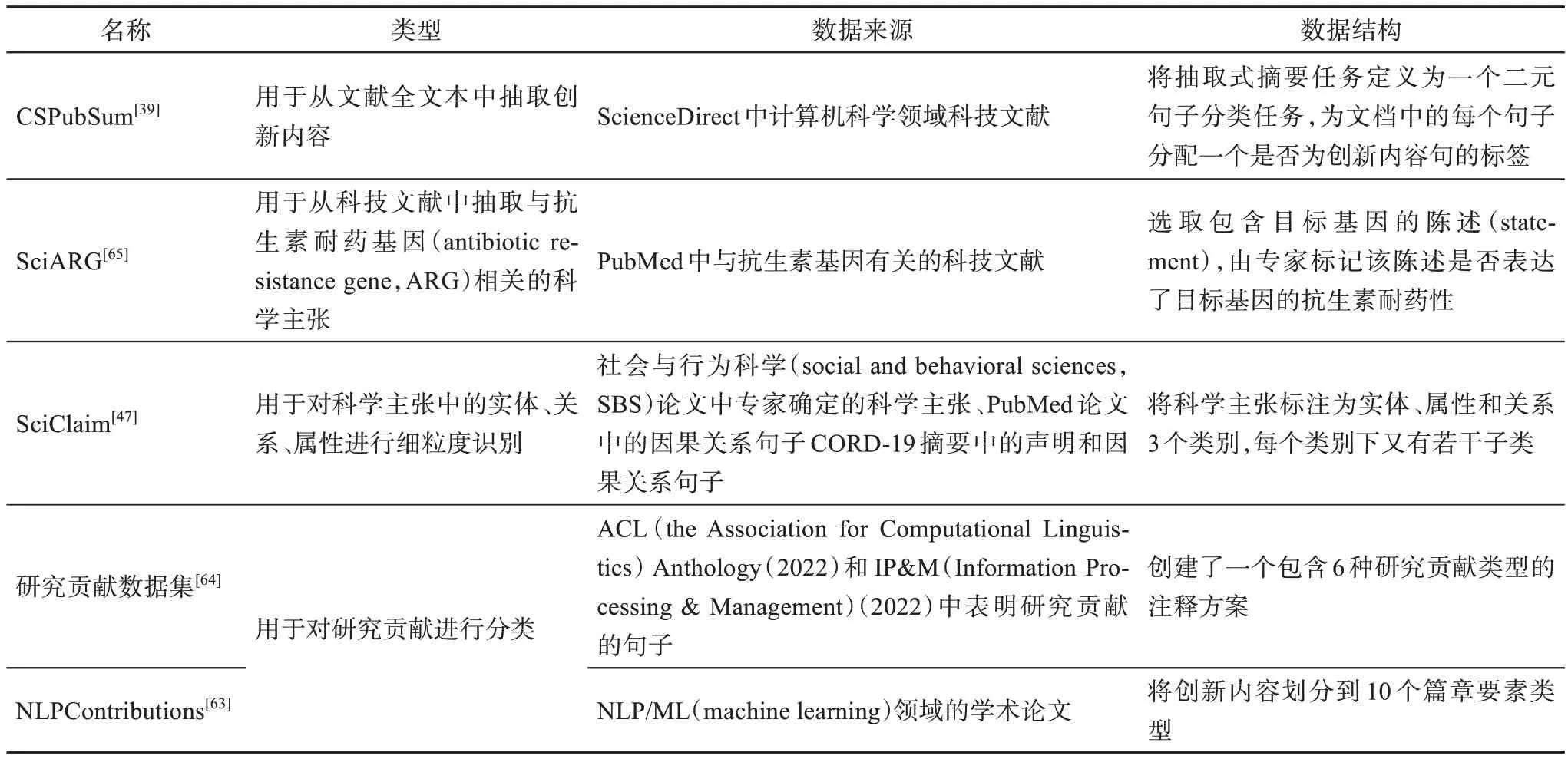
表3 科技文献创新内容机器学习数据集
除上述公开发布的数据集外,还有很多研究临时构建创新内容数据集。这些数据集往往针对于某一特定信息抽取任务,由若干名相关领域人员标注完成,数据集体量较小且并不公开,标注的一致性较低,其质量无从考究。大规模、高质量的开源数据集较少,主要集中于计算机、生物医学等学科领域,构建科技文献创新内容的大型基准数据集是亟待解决的问题之一。
3.3.2 创新内容相关的语义知识库
语义出版技术的出现为科技文献组织与发布方式提供了新的思路[66],在科技文献的语义化过程中,产生了大量的语义数据,形成了一些科技文献语义关联知识库,即科学知识图谱(scientific knowledge graph,SKG),该类知识图谱目前通常包含科技文献的元数据,如作者、机构、引文等内容,但文献的内容仍表示为非结构化文本。近年来,出现了一些对科技文献中科学知识进行结构化表征的知识图谱实践,如描述生物医学领域的科学知识内容中的实体、属性及关系的KnowLife[67],对COVID-19病理生理学科学知识内容进行结构化表达的COVID-19知识图谱[68],涵盖中医养生的人物、思想、原则、方法和应用等科学知识的中医养生知识图谱[69],用于描述计算机领域的任务(task)、方法(method)、指标(metric)、材料(material)和其他实体(other entity)五类科学实体及其关系,并能够进行语义查询的CS-KG(computer science knowledge graph)[70]等。其中不乏一些与科学创新内容相关的研究成果,具体如表4所示。开放研究知识图谱(ORKG)直接针对研究贡献进行知识图谱构建,可用于比较同一研究主题下不同文献的研究贡献差异[71]。纳米出版物在生物医学领域得到了广泛的应用,其断言(assertion)部分以三元组的形式表征科学主张,描述了生物医学领域的药物疗效、蛋白质相互作用等关键科学创新内容,目前已经发布了超过1000万个三元组,成为研究生命科学领域和关联异构数据的宝贵资源[72]。

表4 科技文献创新内容语义知识库
目前,主流的科学知识图谱仍聚焦于科技文献元数据,基于创新内容的科学知识图谱尚处于初期阶段[73],且表现出严重的学科间不均衡现象,大量集中在计算机科学、生物医学领域。从数据体量上看,纳米出版物和CS-KG是两个大规模的数据集,其余数据集的规模较小。另外,这些数据资源主要针对广泛的科学知识,而创新内容只是科学知识的一个子集,这就意味着数据集中包含着大量的科学常识、科学定理等内容。有时科学创新和科学常识这两种知识类型的界限并不明显,科学创新经过实践检验和时间沉淀后,会成为科学社区认可的科学事实和常识。
4 基于科技文献创新内容的应用
4.1 科学创新内容的语言特征分析与新型呈现
科学创新内容在科技文献中往往以创新点的方式出现,特定领域科学创新内容具有一定的领域语言特征。曹树金等[5]分析了中外情报学领域各两本期刊的论文在创新对象、主题、类别、语言表达等方面的差异;同样是针对情报学领域,除了语言学方面的分析,索传军等[7]还对研究亮点进行了位置分布特征的分析;温浩[34]则分析了计算机领域两本期刊的论文摘要中创新点的词汇语义分布、谓语动词语义理解等维度上的特征。这类研究实践一般会借助人工标引、现有算法工具来识别创新内容,通过常见的统计图表形式呈现并归纳特定领域中创新内容在语言规则表示层面的分布及其差异,并将分析所得的规则模式应用于科学创新内容的自动化识别过程。
除了统计图表外,学术出版领域出现了一些对科学创新内容进行新型呈现的有益尝试。例如,爱思唯尔在传统科技文献的基础上先后提出了亮点[29](highlight)和图形化摘要(graphic abstract)的呈现方式。包含研究成果、研究方法的亮点有利于提升科学创新的可发现性,同时,简短的亮点内容对读者友好,能够快速获取全文的关键创新内容。而图形化摘要是对论文主要发现的简洁的可视化总结[6],已日渐被国际期刊所采纳,其呈现的内容主要包括文章概述、关键结果、研究过程或方法等内容[74]。有研究表明,图形化摘要对文章观点的表达以及文章在社交媒体上的提及度都有正面作用[75]。
4.2 基于科学创新内容的知识服务
基于科技文献创新内容语义知识库的智能检索也正在逐步发展[76]。医学领域科技文献的语义化研究较多,已有较为丰富的大规模知识主张抽取、存储与查询应用。Open PHACTS(open pharmaceuti‐cal triple store)项目[77]以及由美国国家医学图书馆(The United States National Library of Medicine,NLM)开发的SemRep工具[78]、SemMedDB知识库[79]都是从生物医学文献中提取三元组的典型代表,可用于科学知识的表征,实现大规模科学创新内容知识单元的抽取、存储和查询,支持二次知识发现(literature based discovery,LBD)[80],如辅助药物发明、支持各种临床决策和应用等。也有研究针对情报学领域构建了创新内容知识图谱[81],并在此基础上初步搭建了智能化检索平台[38],用户能够以创新对象和创新维度为线索进行检索。
此外,科学创新内容是科技文献的本质与核心,将领域内文献的科学创新内容按照一定的过滤和排序规则进行整合,可高效地获取相应领域的学科进展综述。开放研究知识图谱(ORKG)[48]是一个旨在获取、发布和处理科技文献中发表的结构化学术知识的系统,利用ORKG不仅可以自动识别论文中使用的方法、材料及结果,还可以比较相关文献的研究贡献,从而辅助高效的科学文献综述任务。同时,对创新内容的结构化表征有助于识别领域内有矛盾或争议性的知识主张[82],为潜在变革性研究发现提供新思路。
4.3 基于科学创新内容的学术评价
目前,基于文献计量指标的科技评价服务使用文献网络代替知识网络,使用各类文献指标表示科学创新程度,这是一种非直接的科学创新表示与度量手段。对科学创新及贡献进行本质的直接表达,在应用过程中可以克服传统计量方法对科学创新性的计量偏差,提供更全面、客观的科学贡献评价等科技服务,有助于建立以创新贡献为导向的学术评价氛围,对“破五唯”起到积极推动作用,促进科学交流活动向科学价值创造上的回归。目前,已出现了基于科学创新内容的学术评价探索,如基于论文内容语义网络的评估方法[83],基于创新句或研究问题、方法、结论等创新要素的测评方法[84]等,但在具体学术评价实践活动中仍没有出现被普遍采纳的服务形态。
总体来看,目前基于科学创新内容的大规模落地应用还比较少,现有应用主要聚焦于若干典型领域。在实践中面临如下困难:一是底层数据集构建工作量较大,需要对学科领域存量论文进行大规模的结构化处理;二是创新内容结构化表征面临的学科差异问题尚未解决,运用已有的模型能否对全学科科技文献创新内容进行结构化组织、效果如何,尚未有深入探索;三是科学创新内容抽取的研究重点在于算法开发与优化,其研究主体和创新知识的组织及领域建模等领域存在差异,各个实践主体往往着眼于具体的创新内容识别与组织任务,缺乏宏观的协同意识,各个任务之间往往没有形成良好的衔接。
5 基于新型科学创新表达的科学交流及其挑战
5.1 科学交流实践框架
由图2可以看出,当前科研人员通过科学实验、论文写作发表、同行评议等一系列科学交流活动进行科学创新成果的生产传播与消费,并通过科技文献这一主要载体进行创新内容表达,形成显性知识。当前科学交流体系中的科学基础设施和科技知识服务基本都围绕科技文献而展开,如各类学术数据库、学术搜索引擎等平台。科学创新内容既是科学交流的主要对象,也是科学进步的基石,在学术大数据的环境下,基于科技文献的科学交流机制已难以满足科研人员快速获取、跟踪和理解科学创新内容的需求,并带来了基于科技文献相关计量指标的学术评价活动的繁荣。基于科技文献而不是基于科学贡献的评价机制已经受到来自学术共同体的诟病,科学界亟须探索出一种新的科学交流模式,以解决当前科学交流过程中存在的种种问题。
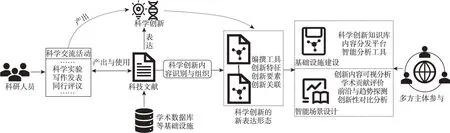
图2 基于新型科学创新表达的科学交流实践框架
目前主要有两条实践路径。一条路径如上文所述,通过对海量科技文献中的包括科学创新内容在内的各类知识元进行识别抽取、结构化组织,使用新的表达机制来表征科学创新内容,形成各类科学知识图谱等知识库,为各类智能科技知识服务提供支撑,这是一种渐进型方案;另一条即图2中由“科学创新”指向“科学创新的新表达形态”这一路径,其直接对科学创新或创新内容进行新的表达,而不一定通过“科技文献”这一传统中介,可以避免因科技文献的处理算法性能的限制而造成的对科学创新内容识别不精确等问题,同时也可解决科学创新内容的可信任性及溯源等问题,这是一种突破型方案。在科学创新的新表达机制下,开展相关科学基础设施的建设以及相应智能场景的设计,无疑需要科研人员、内容编辑、出版商、技术服务商等多方主体的参与,甚至会催生出新的科学交流参与主体。
5.2 未来发展建议
无论是渐进型方案还是突破型方案,基于新型科学创新表达的科学交流过程都需要解决相关的核心问题,重点围绕科学创新内容的新表达形态设计、科学创新内容基础设施建设以及基于科学创新的智能场景设计等方面开展研究与实践。
(1)科学创新内容的新表达形态设计。在新的表达形态下,科研人员可以利用用户友好的语义编辑工具,直接对科学创新本身进行结构化的表达,如SciKGTeX[85]、RASH(research articles in simpli‐fied HTML)[86]等工具。这些编辑器的语义组件既可以对科学创新内容等知识元进行语义化编撰,支持研究人员在传统的“科技文献”这一载体类型的论文写作过程中,用形式语义对科学创新内容进行标注[87-89];也可以不依赖于科技文献这一表达载体,进行全新的关于科学创新内容的写作表达,形成新型学术出版物类型,如纳米出版物等形态。由于科学创新内容一经发布便是结构化的,不需要特意对其进行识别和抽取。对科学创新内容进行新的表达设计及实现,需要考虑科学创新的创作主体、创作时间、创新内容的特征、创新内容组成要素及其关联、不同创新内容的关联机制等信息,以实现对科学创新内容的有效管理、溯源及应用。
(2)科学创新内容基础设施建设。科学创新内容基础设施是相关智能应用场景的基础,其中科学创新知识库是核心资产,可通过渐进型和突破型方法来构建,其关键在于相关智能算法及编撰工具的支撑。创新内容分发平台则为用户提供了关于具体科学创新内容的提交、审核、发表、传播等机制及统一入口,辅助科学创新过程的高效开展。智能分析工具可为用户提供如创新内容检索与推送、学科前沿主题分析等基础学术服务。
(3)基于科学创新的智能场景设计。由于新的表达机制相对于传统的“科技文献”可以更为简明、直接地反映创新性科学成果,可以提供精准的科学知识获取等服务,有效缓解当前学术大数据环境下的知识获取困境,从而成为科学交流的新媒介。基于科学创新的新表达方式,能够催生一批新的智慧应用,如科学创新内容的论证与演化关系、推翻与支撑关系、改进与突破关系的可视分析、基于科学创新内容的科学前沿识别与趋势探测、竞争性科学发现挖掘与对比,以及学术贡献评价等。当然,以上应用场景只是结合当前科学交流体系而产生的有限的构想,新的科学交流机制可能还会催生前所未有的产品和服务形态。
5.3 面临的挑战
虽然基于科学创新的新表达形态的科学交流机制能够弥补现有科学交流机制的短板、解决目前科学交流过程中存在的诸多问题,但是将基于科学创新内容的科学交流机制广泛应用于实践还面临着重重挑战。
(1)基于大规模科技文献的科学创新内容识别抽取的效果仍有待提升。基于科技文献创新内容识别抽取的渐进型方案作为当前的主流实践,目前主要聚焦于若干典型学科,相关算法存在领域移植困难、不能完全无监督执行、识别结果准确度不高、缺乏大规模的训练数据集等问题,对后续的智能应用将产生不利影响。大语言模型(large language model)技术的出现与流行,为科技文献创新内容的识别抽取带来了性能提升[40],然而在算法结果的可解释性以及细粒度的创新要素的识别与关联效果上仍有待进一步探索与改善。
(2)基于全学科领域的科学创新内容的组织及具体实现仍有待探索。不同学科领域的科学创新内容,其语言风格、表达方式、创新类型迥异,现有的科学创新数据模型通常来源于理工科领域,艺术人文学科的创新内容是否可以被形式化、现有的模式是否适用、是否存在符合全学科的科学创新内容组织模式等问题都需要进一步探索,且新的组织模型如何大规模应用、相关工具生态及实践机制的设计仍是具有挑战性的任务。
(3)相关智能场景设计过程的多学科、多主体协作有待加强。正如上文所述,科学创新内容等知识元的识别抽取等实践仍以算法开发为主,形成的相关科学创新数据集只是作为验证算法性能的副产品,并没有有效地对接到实际的应用场景。同时,对于科学创新内容的识别、组织及应用的不同环节,其实践主体通常由计算机领域、图书情报学科以及知识服务提供商等各自开展,缺乏围绕科学创新内容识别及应用等全流程的宏观协同机制与实践意识。这一过程对多方参与主体提出了新的要求,如科研人员的语义编辑技能、技术人员的知识图谱构建等,同时,新的商业模式、产品与服务形态以及利益分配方案都需要再思考。
6 总 结
基于科技文献的科学交流机制已经日渐不能满足科研人员快速获取科研信息的需求,并且带来了基于科技文献计量指标的科学评价形式。构建基于科学创新内容的科学交流机制是弥补现有科学交流机制短板、解决现存问题的有效途径之一。本文对国内外相关研究实践进行了系统调研和分析,阐述了科学创新的概念内涵及特征,梳理了科技文献创新内容识别抽取的主要方法,归纳了创新内容结构化组织的数据模型,并分析了基于科学创新内容的智能应用。最后,提出了一种基于新型科学创新表达形态的科学交流实践框架,以及该框架的实践建议和可能面临的挑战。纵观当前实践,科学创新内容的相关研究及实践的重要性尚未受到科研人员足够的关注,未来新的科学交流机制的构建仍面临很多挑战,科学创新的类型及学科差异仍有待梳理,科学创新内容识别抽取的自动化、通用化仍需要加强,全学科的科学创新语义组织及实践仍需要持续探索,新的科学交流机制的落地应用仍需要大量的跨界合作,以打破现有科学交流机制环境中知识获取与传播的困境、更好地支持科学知识获取与同行评议等科学交流活动。
