基于深度学习的地震叠加速度谱自动拾取算法研究
2024-03-11朱四新孟凡可姜彤
朱四新, 孟凡可, 姜彤
华北水利水电大学地球科学与工程学院, 郑州 450053
0 引言
叠加速度分析是常规地震数据处理中的重要环节之一,其通过叠加多次反射波从而提高地震勘探数据的质量和信噪比,从而协助地质工作人员确定地下地质构造(韩明亮等,2021;Cao et al.,2021).由于近年来大面积三维地震勘探技术的逐步发展,处理数据时产生海量的速度谱拾取点需要具有丰富地震处理经验和地质学术背景的专业人员逐个鉴别.同时由于拾取叠加速度需要考虑地震噪声、多次波、绕射波和构造复杂区域等诸多因素的影响,这导致人工拾取速度谱的效率以及拾取的准确性问题尤为突出(戴晓峰等,2020).基于深度学习的地震速度谱自动拾取算法研究逐渐成为当前解决这一问题的研究方向之一(LeCun et al.,2015;Wu et al.,2020;潘海侠等,2023).
当前的速度谱拾取算法研究主要分为半自动的优化搜索方法和自动的深度学习拾取方法(董林平和何翔,1996;王立新,1999;张军华等,2009;彭冬冬等,2022).优化搜索方法利用最大相似度准则与最优化算法相结合,以及相应的约束条件通过反演来获得最优的层速度模型.主要包括共轭梯度法、蒙特卡洛法、路径积分优化法、非线性最优化法等方法(Toldi et al.,1989;David,1997;林年添等,2013;张建彬等,2016).但是基于这些最优化搜寻方法进行速度谱自动拾取存在着诸多问题.首先,相关算法都需要专业人员设定相关的先验约束条件和初始化模型(刘爱群等,2008;蒋润等,2023).其次,在地质情况较复杂的条件下,如探测范围内包含断层和褶皱等地下地质构造,则会导致相应算法计算结果准确率降低.
深度学习方法又细分为机器学习方法和人工神经网络组成神经网络算法,本文所主要构建的深度学习网络是基于人工神经模型组成的自动拾取算法.深度学习方法是利用人工神经网络组成目标拾取网络,通过提取叠加速度谱内的能量团高亮区域来实现地震速度谱的自动拾取过程(Fish and Kusuma,1994).基于深度学习的自动化速度谱拾取算法与半自动速度谱拾取算法相比,在处理地震勘探资料的叠加速度谱拾取阶段彻底脱离了人工参与过程,自动化程度高,且拾取点精度有较大提升(崔家豪等,2022).其次,基于深度学习的自动化速度谱拾取算法在经过大量地震数据集的训练下能够适应不同复杂度的工区场景,具有较强的泛化能力和鲁棒性(匡立春等,2021).
在相关的研究中,Huang和Yang(2015)提出利用霍普菲尔德神经网络选择地震速度,该算法将地震速度谱速度拾取转化为一个神经元多段线连接优化的问题.Biswas等(2018)提出使用循环神经网络进行堆叠速度估计,使用Adam优化算法训练神经元网络来估算地震的堆叠速度,并以此估计速度与正确的堆叠速度进行对比、更新权重.Park和Sacchi(2020)提出使用卷积神经网络与迁移学习结合来进行自动化速度分析,并将速度拾取的过程转换为图像分类问题.
但是在目前的算法研究中,大多数深度学习算法获取的拾取点对地层结构的序列特征信息考虑不充分,对于中深部能量团发散等区域的能量团不能有效处理,致使拾取点不够准确,甚至出现地质解释偏差(Hochreiter and Schmidhuber,1997;Girshick,2015;王迪等,2021).因此,本文以获取准确的拾取点为目标,针对如何识别并剔除位于拾取曲线之外的干扰能量团以及如何识别并拾取速度谱中深部能谱群发散部分的能量团点,使得这些自动拾取的点的准确性接近于人工拾取的效果等两个主要问题,研究具体算法的改进.在设计模型时,采用卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)模型相结合的方式(LeCun et al.,1989;Elman,1990).通过深度学习框架Pytorch混合目标拾取网络Faster R-CNN和长短期记忆模型(Long-Short Term Memory,LSTM)来构建本文的地震速度谱自动拾取算法模型VSAP(Velocity Spectrum Accurate Pickup)从而达到叠加速度谱的准确拾取以及限定区域精细化调整速度谱拾取点位置的目的.
1 方法原理
地震叠加速度谱的拾取主要是以选择速度谱相应的能量团中能量较强的位置所在的“时间-速度”对,从而实现对应CMP(Common Middle Point)道集的动校正和信号叠加(王瑞林等,2021).因为能量团中心高亮点等同于能量极大值,如果速度值选取在这一极值点,一定程度上可将获取的结果作为有效的动校正速度,从而校正CMP道集.因此,对地震数据的动校正过程可等价于速度谱拾取问题.由于能量团具备获取速度参数的特征,而卷积神经网络具备提取图像特征的能力,速度谱浅层区域的拾取问题就可以转化为图像的分类识别问题.其次是这些“时间-速度”对在速度谱上存在着特定的空间关系,一般情况下叠加速度会随着时间的增加而增大,说明其具有明显的序列特征.这两个速度谱的基本特征为本文后续的算法设计提供了科学依据(张昊等,2019).
1.1 VSAP模型整体结构设计
首先,在叠加速度谱上半部分信噪比较高的区域,也就是能量团分布较为规律的区域,针对目前提出的深度学习算法中多次波等复杂的干扰信号导致的能量团拾取点不准确的问题,本文提出将目标检测模型中的典型代表Faster R-CNN算法作为综合目标检测网络VSAP中的前半部分,用于速度谱能量团的高亮区域拾取.由于速度谱拾取过程中存在的以上干扰问题,如果全部拾取这些能量团会使动校正过程出现错误,最终导致地质解释的偏差.因此,为避免以上问题造成的干扰情况,本文针对如图1所示人工拾取的地震速度谱在拾取过程中出现的几种需要判别的拾取情况,在进行能量团的目标拾取时,除了拾取基本能量团之外也要拾取图中所示的干扰能量团和中深部较为发散的区域,以便在后续运用LSTM模型来对相应的拾取目标进行进一步的调整,以期达到或者接近人工拾取的能力.

图1 地震叠加速度谱的能量团信息识别图(a) 包含复杂地质构造和多次波等信息的速度谱图像; (b) 包含中深部能谱群区域等信息的速度谱图像.
在拾取操作中,本文将图片特征提取的单分类任务(CNN模型每次只拾取一种类型的能量团,例如拥有高亮区域的单个能量团)转换成一个多分类任务(CNN模型每次拾取多种类型的能量团,例如除了在拾取时分辨出上述能量团之外还要将速度谱中多个高亮能量团组成的复杂信息区域作为整体的目标进行拾取),不再像之前的研究中只针对单一的能量团高亮区域进行拾取,而忽视了各种因素造成的干扰能量团如何拾取的问题.
其次,针对目前的卷积神经网络算法不能有效地拾取速度谱深部的能量团较为发散区域的拾取点的问题,本文提出使用卷积神经网络中的长短期记忆模型LSTM来精细化调整拾取点的合理位置,解决偏离能量团中心拾取点的问题.
在实际工程中,真实数据的拾取点并非全部位于能量团极大值,而是是以速度谱为参照,同相轴是否拉平为判断标准进行拾取的.因此,为解决上述问题,本文将VSAP的前半部分的卷积层输出作为后半部分LSTM的输入,学习拾取点的相关序列信息,从而进一步精细化调整速度谱拾取点的位置.在遇到图1所示的在常规人工拾取操作中需要判别的能量团排列情况也就是在一个干扰能量团拾取框或者中深部能谱群拾取框(后文简称为“多点框”)内同时出现两个及以上的能量团拾取框时,首先清空多点框内的所有能量团坐标,然后依据LSTM学习出的拾取序列以及与多点框紧挨着的上一个能量团拾取点的坐标预测出多点框内的预测值,再依照预测值与多点框内的能量团坐标相对比,从而判别出最优解作为最后的拾取点.以此实现将RNN与CNN模型相结合,同时也能够达到根据限定区域精细化调整速度谱拾取点位置的目标.
如图2所示为VSAP算法模型的整体结构框架,该模型主要由Backbone one和Backbone two两部分组成.其中,Input map为需要进行拾取的地震叠加速度谱原始图像,Pick coordinate为CNN模型初步拾取后的各拾取点坐标,Training set 1为人工拾取的地震叠加速度谱训练数据集,Training set 2为人工拾取的速度谱各能量团的坐标,Output map 1为CNN模型初次拾取的拾取结果(设计该模块的主要目的为和VSAP模型最终的拾取结果进行对比),Output map 2为VSAP模型最终输出的地震叠加速度谱拾取图像.在使用模型进行拾取时,首先将Input map输入到经由Training set 1训练出的Faster R-CNN模型中,模型会输出仅由计算机视觉模型识别出的Output map 1和拾取点Pick coordinate.在将相应需要预测的坐标输入给LSTM模型之前,删除视觉模型中多点框内所有点的坐标.然后把经过第一步识别并筛选后的能量团坐标输入由Training set 2训练出的LSTM模型内,并对其坐标进行逐点预测,最后输出限定区域精细化调整后的速度谱图像Output map 2.对于VSAP模型的具体效果评价详见第2节.
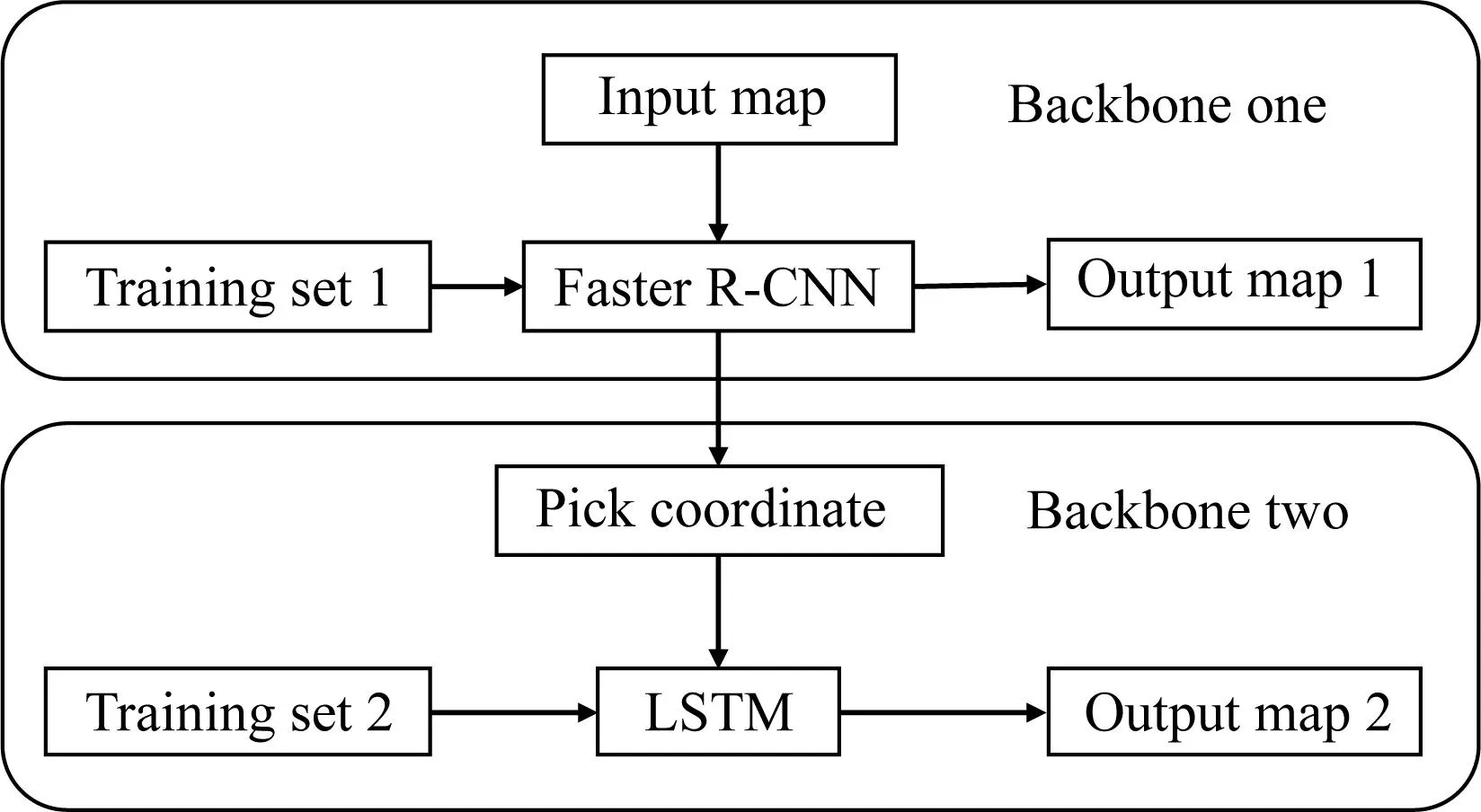
图2 VSAP模型结构图
1.2 Faster R-CNN模型结构与原理
在现有的研究领域中,应用较为广泛的目标检测网络有Faster R-CNN、YOLO(You OnlyLook Once)、SSD(Single Shot MultiBox Detector)、RetinaNet和Mask R-CNN等(Redmon et al.,2016;Liu et al.,2016;Lin et al.,2017;He et al.,2017).本文所要进行的目标拾取主要为小目标,而且整个拾取过程并不需要像汽车的自动驾驶一样进行快速的实时识别和检测,同时还考虑到Faster R-CNN作为一种经典的目标检测算法,可以实现比较高的准确率和相对较快的检测速度.所以最后综合对比各项算法模型的优劣,决定使用Two-Stage中最为经典的物体检测算法Faster R-CNN作为本文算法VSAP的前半部分来进行能量团的拾取工作.
如图3所示,Relu为激活函数;Full connection为全连接层;Softmax为分类器;Bbox为网络预测的可能值;Feature map为卷积后的特征图像;Proposal的功能为选定拾取目标;Reshape的功能为重定义图片大小;在流程图中所有的conv层都是:kernel_size=3,pad=1,stride=1;所有的pooling层都是:kernel_size=2,pad=0,stride=2; ROI pooling的功能是收集输入的Feature map和Proposal,综合这些信息后送入后续全连接层判定目标类别;cls_prob的功能是获得检测框最终的精确位置.

图3 Faster R-CNN结构图
Faster R-CNN的整体流程是先将原始的地震速度谱图片输入由13个Conv层,13个Relu层和4个Pooling层共同组成的特征提取模块Conv layers,通过公式(1)、(2)的计算得到一个长和宽为原始输入图片1/16的Feature map,表达式为
(1)
(2)
式中height和width分别代表图片的高和宽,其中下标in代表输入,下标out代表输出,kernel代表卷积核的大小,padding代表充填,stride代表步长.
接下来利用RPN(Region Proposal Network,模块功能为筛选可能包含物体的区域)在Feature map上均匀的划分出K*H*W个区域(称为Anchor,K=9,H是Feature map的高度,W是宽度),通过比较计算得到Anchor(一组固定的框,它们以不同的大小以及宽高比放在整个图像当中)和Ground truth(人工标注的真实拾取框)间的重叠情况来确定前景和背景.同时为了得到更加精确的拾取框,我们可以通过公式(3)推导出公式(4)中的四个偏移量,用来训练RPN模块的识别能力,表达式为
(3)
(4)
在式(3)中,假设Anchor中心位置坐标是[Ax,Ay],长和高为Aw和Ah,对应Ground Truth的4个值为Gx,Gy,Gw,Gh.由此可得,公式(4)中dx(A),dy(A),dw(A),dh(A)就是Anchor与Ground truth之间的偏移量.为了能够在长和宽的差别较大时快速收敛,差别较小时缓慢收敛,在公式(4)中使用了对数的形式来保证计算的精度.最后利用RPN获取到的拾取框精确位置,从Feature map中取出要用于分类的目标拾取框,并使用Pooling模块固定其长度,从而得到最终的拾取结果.
在计算模型损失值时,由公式(5)、(6)可得到算法模型拾取能量团时相应的损失值:
(5)
(6)
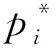
本文针对Faster R-CNN模型内在架构未进行除参数之外较大的更改.主要修改了目前的研究中仅仅只拾取单一能量团的单分类任务,将其变为一个能够同时识别单一能量团以及干扰能量团和中深部能谱群区域的多分类任务.为了使得卷积神经网络模型能够识别如此复杂的速度谱分类任务,分别对以上分类做出了详细的人工拾取规则,其具体规则如下:首先在人工准备数据集时,如图4所示,图4a中除了标注具有高亮区域的单一能量团EC(Energy Cluster)之外,还标注了拾取曲线之外的干扰能量团IEC(Interference Energy Cluster).在图4b中,除了标注EC之外,还标注了地震叠加速度谱中深部的能量团发散区MD(Medium-Deep Energy Dispersion Cluster).有别与其他研究仅仅只局限于运用目标拾取网络进行能量团的单分类拾取,本文将单一的单分类任务转变为一个多分类任务.其中,EC的人工拾取规则为图片中的高亮区域,IEC的人工拾取规则为横向并列的多个能量团,MD的人工拾取规则为速度谱底部无明显能量团的部分.经过目标拾取网络模型的拾取,模型基本能够拾取到每一个小能量团,并使得每个多点框内包含着至少两个小能量团.

图4 目标拾取网络拾取结果(a) 某一厂区的速度谱模型拾取结果; (b) 另一厂区的速度谱模型拾取结果.
1.3 LSTM模型结构与原理
现阶段地震速度谱自动拾取研究的难点不在于如何更加准确地识别能量团的高亮区域,而是在于如何在识别到所有的能量团之后对拾取点的判断和取舍,以及对速度谱下部无明显能量团部分拾取点的预测.鉴于地震叠加速度谱拾取的“时间-速度”对能量团存在着紧密的时序关系,以及当前主流的线性回归以及前馈神经网络等机器学习方法只局限于当时训练模型的数据集,也就是针对更复杂的拾取曲线不能有较好的泛化性和鲁棒性.于是在本文中选择循环神经网络中最为经典的LSTM模型作为VSAP算法的下半部分,用来对算法的前半部分Faster R-CNN拾取后的结果进行调整和预测.

图5 LSTM网络的循环单元结构
由图5可得,LSTM的整体流程是将原始图片中人工筛选的能量团拾取点坐标作为模型的输入序列X∈RB*L*M.其中B为批大小,L为序列长度,M为输入特征维度.循环单元从左到右依次扫描序列,并同时计算更新每一刻内的单元内部状态Ct∈RB*D和输出状态Ht∈RB*D.
首先在时刻t,LSTM的循环单元将当前时刻的输入Xt∈RB*M与上一时刻的输出状态Ht-1∈RB*D进行计算.由公式(7)、(8)、(9)计算可以得到输入门It,遗忘门Ft,和输出门Ot,表达式为
It=σ(XtWi+Ht-1Ui+bi)∈RB*D,
(7)
Ft=σ(XtWf+Ht-1Uf+bf)∈RB*D,
(8)
Ot=σ(XtWO+Ht-1Uo+bo)∈RB*D.
(9)
然后通过公式(10)、(11)分别计算候选内部状态以及t时刻单元的内部状态:
(10)
(11)
式中,Wc∈RM*D,Uc∈RD*D,bc∈RD为可学习的参数,⊙为逐元素积.最后由公式(11)、(12)计算一个循环单元结束之后的输出状态向量Ct和Ht的值,并将其作为下一次循环的输入.式(12)为
Ht=Ot⊙tanh(Ct).
(12)
LSTM循环单元结构的输入是t-1时刻内部状态向量Ct-1∈RB*D和隐状态向量Ht-1∈RB*D,输出是当前时刻t的状态向量Ct∈RB*D和隐状态Ht∈RB*D.综上所述,通过LSTM循环单元,整个网络可以建立较长距离的时序依赖关系,从而能更好的调整和预测地震速度谱能量团的拾取点.
在获取了卷积神经网络模型的拾取结果后,接下来重点要考虑的就是如何对这些众多种类的拾取目标进行更进一步的取舍和微调,这也是本文提出的为解决目前的速度谱自动拾取算法所面临的对于复杂地质情况不能准确高效识别这一问题的解决方案.
首先,在构建Faster R-CNN模型的数据集时,不光得到了速度谱图像的人工拾取结果,同样得到了每张速度谱上人工拾取的能量团的坐标.同时本文内所有图表内出现的各坐标点的坐标系建立规则为,以每张速度谱图像的左上角作为坐标原点,横轴为x轴,纵轴为y轴建立相应坐标系.
然后将各速度谱内人工拾取点的坐标作为后半部分LSTM模型的数据集进行学习.使得循环神经网络模型学习到各个拾取点坐标间相应的时序关系.
最后,在使用人工标注的数据训练完模型的卷积和循环神经网络两部分之后,使用需要预测的原始速度谱图片输入Faster R-CNN模型,运用训练好的模型对图片进行多分类拾取.在得到模型初步拾取后的拾取框坐标后,对初步拾取的拾取框坐标进行分类.其分类规则为:(1)保留EC框内能量团坐标;(2)删除IEC框内所有能量团坐标;(3)删除MD框内所有能量团坐标.分类结束后,将剩余的EC框的中心坐标输入训练好的LSTM模型内,利用各拾取点间存在的时序关系,预测出IEC和MD等多点框内点的坐标.在最后得到保留点和预测点的总体坐标后,输出在最开始需要拾取的原始速度谱上,得到模型最后的拾取结果.具体各点的取舍和微调情况如下一节表格内所示.
为了体现出本文根据LSTM模型为基础所设计的VSAP模型的后半段对于拾取点的调整能力,使用不同的方式分别对本文所建立的数据集内随机挑选的几张包含不同信息的速度谱图片进行拾取操作.为了便于观察,将坐标系横放,令原先定义的x轴和y轴交换位置,同时设定每一个拾取点的坐标为图片上像素点的坐标(没有单位),后文表格内的坐标格式同样按照此规定获取.
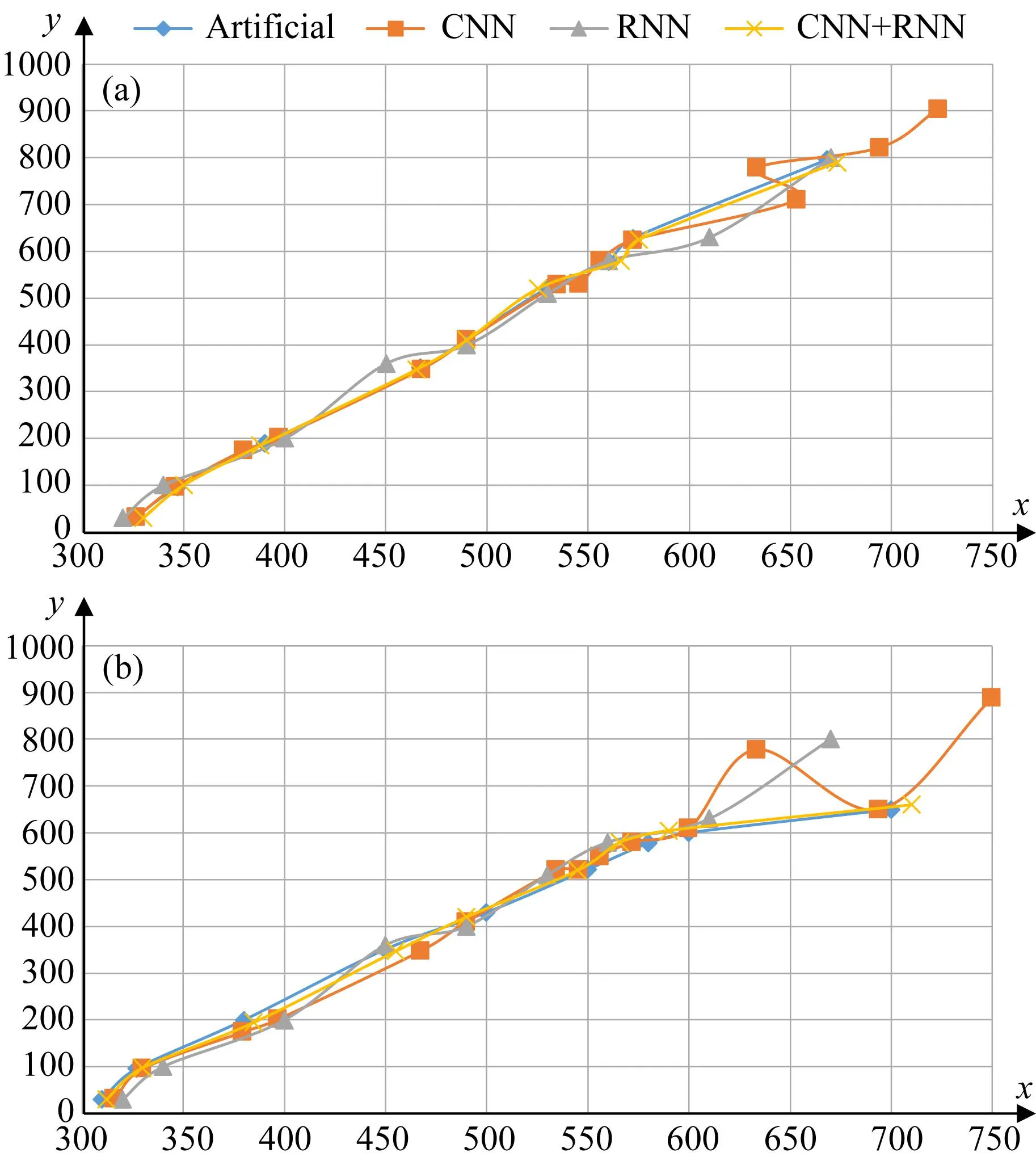
图6 不同拾取方式在速度谱内的拾取表现(a) 数据集内随机一张速度谱的拾取坐标(包含断层和多次波等信息); (b) 数据集内随机一张速度谱的拾取坐标(包含断层、多次波和复杂地质构造区域等信息).
如图6所示,如果单纯的使用CNN模型,则只能拾取所有的能量团目标,而不能分辨出速度谱图像中所体现出来的复杂信息;如果不使用CNN对目标进行拾取操作,同时没有根据前文所说的相应步骤使用RNN对应该预测的拾取点进行有选择的预测,就只是单纯的使用LSTM进行对速度谱的预测的话,就只能得到一条和线性回归等其他非深度学习方法一样的一条固定的拾取曲线;但是如果我们按照本文中所提出的相应步骤,以CNN和RNN相结合的方式进行对速度谱的拾取操作,我们就能在不同的信息条件下拾取到和人工相近的拾取点和拾取曲线.
2 实验与结果分析
2.1 建立数据集
为验证模型自动拾取速度谱的能力以及在训练中尽可能地提高模型的准确性和泛化性.本文选择了三个不同的厂区作为数据采集场地,使用428XL地震采集系统进行数据采集.该采集系统的采样间隔为0.5 ms,记录长度3 s,扫描长度16 s,扫描次数3次.以此标准,本次采样共采集了5条总长度为12 km地震剖面,累计获得了包含2400张速度谱图像的数据集.将该数据集以8∶1∶1的形式分成训练集,验证集和测试集三部分,并使用Labelimg软件为速度谱图片打标签,人工打标签的规则如第1.2节所示.
为了训练VSAP模型后半部分的LSTM模型,先要人工对数据集内的速度谱图片进行一一的拾取.每张速度谱内都有10~15个数量不等的能量团,将这些能量团的坐标进行整理,作为LSTM模型的数据集进行模型的训练,使得模型学习坐标内部存在的时间序列关系,为下一步的能量团拾取点精细化调整做准备.数据集内随机挑选的一张速度谱的拾取框坐标格式如表1所示,其中X1、Y1表示的是拾取框的左上角的坐标,X2、Y2表示的是拾取框的右下角坐标,可根据这四个坐标数据求取相应能量团高亮区域的具体坐标X和Y.

表1 速度谱在数据集内的格式Table 1 Format of velocity spectra within the data set
2.2 模型评价
目标检测网络在对数据集进行训练时,输入的数据集格式为VOC格式,主干网络使用Resnet50,先验框大小设计为[4,16,32],优化器选择Adam,学习率设计为10-4,并使用GPU对训练过程进行加速,不进行冻结训练.以此标准,在训练了500个Epoch之后,得到了如图7所示的关于模型的各项评价指标.
在图7中,横坐标为训练轮次,统一为500轮,纵坐标为各项指标的得分,也就是各张图片的图名(没有单位).图7a指的是目标检测loss均值,其训练的结果越小目标检测越准;图7b指的是分类loss均值,同样也是越小分类越准确.图7c指的是精度,其具体定义也就是模型中分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例;图7d指的是召回率,含义为分类器认为是正类并且确实是正类的部分占所有确实是正类的比例;图7e、f指的是验证集的目标检测均值和分类loss均值;图7g、h指的就是mAP,mAP这种评价指标是用Precision和Recall作为两轴作图后围成的面积,其中m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5∶0.05∶0.95后取均值.一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)然后观察mAP@0.5 &mAP@0.5∶0.95 评价训练结果.经过训练,本模型的mAP值能够达到0.94,对于目标的拾取有着较高的准确度.
在目标检测模型识别出速度谱相关的信息之后,需要将这些信息作为LSTM模型的输入,对其进行进一步的筛选、调整和预测.在对LSTM模型进行训练时,输入的训练集格式如表1所示,模型层数设计为两层,隐层设计为10层,学习步长设计为50,学习率为0.01,训练轮次5000次,并使用GPU对训练过程进行加速.
由表2可得模型对于坐标数据的预测能力,例如在清空IEC框内的两个能量团之后LSTM模型在该多点框内的预测坐标为(391,190),而人工的拾取结果为(390,190);又或者在清空MD框内的五个能量团之后模型预测了(574,625)和(670,800)两个坐标,而人工在此中深部能量团发散区域拾取的两个坐标为(572,625)和(668,796).由此可见,模型预测的坐标和人工拾取的坐标误差范围区间很小,只有1%~2%左右.同时因为人工在拾取时也会不可避免的存在一定的误差,所以模型存在的像素级别的误差基本可以忽略不计.我们由此可以判断出LSTM模型对于地震速度谱的拾取坐标的调整与预测已经基本与人工拾取的结果一致.

图7 目标检测模型的各项评价指标(a) 目标检测损失均值; (b) 分类损失均值; (c) 精度; (d) 召回率; (e) 验证集损失均值; (f) 验证集分类损失均值; (g) 阈值取0.5的mAP值; (h) 阈值取0.5∶0.05∶0.95的mAP值.

表2 人工拾取点坐标与模型预测坐标Table 2 Manual pickup point coordinates and model predicted coordinates
2.3 模型验证
为了进一步验证该模型的准确性以及鲁棒性,本文选取了某一厂区的原始地震勘探数据,对数据进行了各项处理操作,仅在拾取速度谱阶段有人工操作与模型自动拾取的区别.从图8a可以看出传统的CNN方法能够识别相应能量团信息,但是其不能够识别哪些能量团是应该拾取的,哪些是应该舍弃的.由图8b可得人工在对这张速度谱图像进行拾取操作时所得到的拾取曲线,借此可以与其他拾取方式得到的拾取曲线进行对比.由图8c可得单纯的RNN模型仅仅只是针对特定的数据集图像可以进行较为准确地预测,但是其泛化能力非常差,不能解决不同工况所形成的不同速度谱图像的拾取.由图8d可以看出模型对于数据集内在的序列关系学习的很好,能够对多点框内的能量团坐标一一识别和调整.同时可以从图中看出模型分辨出了位于上部右侧的干扰能量团和图片中部较为明显的竖向排列的多次波能量团,并在自动拾取时将其筛选出去;同时模型也识别出了中深部能量团发散区域的图像特征,筛选并修正了能量团群内的应拾取点,预测了深部无明显能量团处的一处拾取点,其整体拾取效果接近于人工拾取.

图8 人工拾取速度谱与模型拾取速度谱的对比(a) 传统CNN方法拾取的速度谱图像; (b) 人工拾取的速度谱图像; (c) 传统RNN方法拾取的速度谱图像; (d) VSAP模型自动拾取的速度谱图像.

图9 人工拾取与模型拾取对CMP道集的动校正效果对比(a) VSAP模型Backbone one组件的拾取图像; (b) 人工拾取的速度谱图像; (c) VSAP模型拾取的速度谱图像; (d) CMP1200道集; (e) 人工拾取速度动校正; (f) VSAP模型拾取速度动校正.
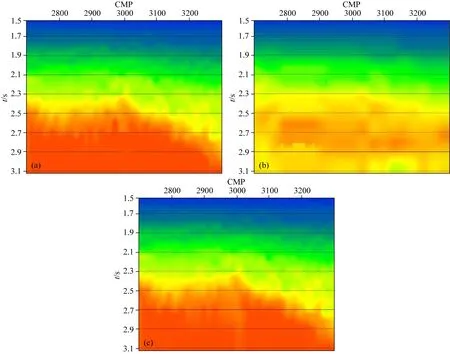
图10 实际厂区的地震资料叠加速度场(a) 人工拾取并处理的地震叠加速度场; (b) 传统CNN方法拾取后处理的地震叠加速度场; (c) VSAP模型自动拾取后处理的地震叠加速度场.

图11 实际厂区的地震资料叠加剖面(a) 人工拾取并处理的地震叠加剖面; (b) 传统CNN方法拾取后处理的地震叠加剖面; (c) VSAP模型自动拾取后处理的地震叠加剖面.
如图9所示为人工拾取与模型拾取对CMP道集的动校正效果对比.通过图9a可以看出本文所提出的VSAP模型Backbone one组件识别出了19个普通能量团,其中包含干扰能量团以及中深部能量团发散区域.该组件已经基本上能够提取出速度谱上的所有能量团信息;从图9b可以得知在进行人工拾取速度谱操作时剔除了多余的干扰能量团信息以及中深部能量团发散区域的干扰,只有12个拾取点;由图9c可以看出经过VSAP模型对速度谱进行目标识别和坐标调整之后能够得到非常接近人工拾取的12个拾取点组成的拾取曲线;图9d为数据集内CMP1200道集,使用其未校正的状态进行对比;图9e、f分别为人工拾取速度动校正结果和VSAP模型拾取速度动校正结果,从以上结果可以更加直观的展示出本文提出的VSAP模型对于更加复杂的速度谱图像的自动拾取能力.如图10所示速度场图片,将人工拾取的叠加速度场图 10a与传统CNN方法得到的叠加速度场图10b以及本文模型自动拾取方法得到的速度场图10c进行对比.如图11所示实际厂区的地震资料叠加剖面的人工处理结果与模型处理结果的对比.由此可得本文所提出的VSAP算法模型在多次波、复杂地质构造区域的干扰中自动拾取速度谱的能力已经基本与人工拾取的结果相似.
3 结论
本文利用目标拾取网络模型Faster R-CNN构建的多分类拾取任务,对地震速度谱内的一般能量团、干扰能量团和中深部的发散能量团等区域形成的能量团进行特征提取.再将初步得到的拾取点坐标按照相应的拾取规则进行筛选和调整,然后由循环神经网络中的长短期记忆模型LSTM学习到的拾取点之间的序列关系来对拾取坐标进行进一步的预测和调整.最终得到了和人工拾取结果接近的基于深度学习的地震速度谱拾取算法模型VSAP.通过实际厂区的数据验证,本文得到了如下结论:
(1)本文运用Faster R-CNN模型提取图片特征时运用到的多分类任务提取方式,使得算法能够获取全局与局部的联系,降低冗余信息对于图像的影响,使网络关注于拾取点及其临近点的相关信息.
(2)本文运用LSTM模型学习拾取点坐标的相关序列信息,并且能够准确地输出限定区域精细化调整后的速度谱图像.其准确性更是接近人工识别并拾取速度谱能量团相关信息的能力.
(3)本文构建的VSAP深度学习模型可以在较短的时间内对大量的速度谱图像进行精准识别并输出拾取图像.相对于传统的人工拾取方式,极大地提高了速度谱拾取的效率和拾取精度.
在构建模型时,本文所使用的数据集数量和多样性还不够,这对模型的泛化能力造成了一定的影响,使得模型对于更加复杂的地质构造所体现出来的能量团信息识别能力不足.在实际的应用中,可以通过增加训练集的广度和深度以及迁移学习等方式来提高模型在面对各种各样的复杂情况时的鲁棒性.
