基于邻域自注意力的钢铁表面缺陷分类算法
2024-03-11陆春月柴子凡
巩 克,陆春月,柴子凡
(中北大学机械工程学院,山西 太原 030051)
钢铁行业是经济产业的重要组成部分,钢铁表面缺陷不仅损害外观和内部品质,严重时甚至会危及安全。然而,随着生产水平的提高和需求量的增大,人工检测已不能满足钢铁表面缺陷检测的要求,因此采用智能化、自动化的方法解决缺陷检测问题已经是大势所趋。随着计算机视觉技术的发展,基于卷积神经网络的检测方法得到了广泛应用。但是钢铁缺陷图像成像模糊、分辨率较低,会导致网络学习到的特征出现信息丢失、特征模糊以及易混淆的问题。为此,本文提出基于邻域自注意力的钢铁表面缺陷分类算法,通过邻域自注意力模块与多尺度特征融合进一步提高了钢铁缺陷检测的正确率。
1 相关工作
1.1 钢铁缺陷分类
传统的钢铁表面缺陷识别方法主要使用小波变换、双阈值二值化和决策树等方法来分析和检测图像,但是适用性有限。近几年提出的一些方法往往使用卷积神经网络进行检测,例如Boikov等[1]使用合成数据来训练视觉任务的方法,在钢工件表面缺陷的分类和分割方面都取得了良好的效果。Hao等[2]使用基于生成对抗网络和注意力机制的方法来识别缺陷。Li等[3]提出了一种混合网络架构(CNN-T),该架构合并了卷积神经网络(CNN)和Transformer编码器,在NEU-CLS数据集上取得了显著的分类效果。
尽管上述方法在钢铁表面缺陷分类方面取得了不错的效果,但这些方法所针对的钢铁缺陷数据集分辨率较高(通常为224×224)。当输入图像为低分辨率时,由于低分辨率图像所包含的像素点数量较少,很多细节和信息都无法在图像中表现出来,因此信息有缺失。同时,由于像素点的数量较少,低分辨率图像的边缘和轮廓通常比较模糊,这会使得一些细微的特征难以识别和区分,从而导致神经网络所学到的特征模糊。
1.2 注意力机制
注意力机制的作用是让系统学会从大量信息中把注意力放在感兴趣或者高价值的地方,目前已经成功地应用于各种任务。例如,在2017年被应用于Transform模型中的自注意力机制[4],已成为大型模型发展的重要转折点。此外,Hu等[5]提出了一种用于图像分类的通道注意块,以提高网络的代表性。Wang等[6]则通过提出用于CNN的有效通道注意(ECA)模块,成功实现了跨通道交互,增强了SENet的策略。为了建立通道注意和空间注意的双重机制,Woo等[7]在SENet和ECANet的基础上进一步加强了注意力模块设计。在计算图像自相关性时,往往使用邻域相关性[8],但这种方法计算量大、模型复杂。而本文所提出的邻域自注意力模块通过简单的连接实现上下文特征感知,省去了许多冗余的参数。
2 算法内容
图1所示为网络的总体架构,图2所示为邻域自注意力模块的整体架构。邻域自注意力网络包括2个主要的可学习模块:自相关计算模块、上下文特征感知模块。
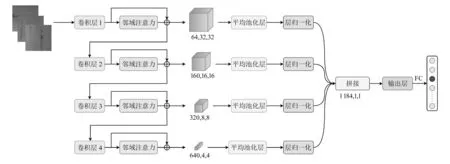
图1 基于邻域自注意力网络的总体架构

图2 邻域自注意力模块架构
2.1 网络总体架构
给定一组缺陷样本图像的情况下,使用卷积块(Conv)来提取基本特征Z,Z∈H×W×C,其中H和W分别为特征的高度和宽度,C为通道维度。接着,引入邻域自注意力模块来增强基础特征,并将增强后的特征与基础特征进行残差连接,得到自注意力特征A,A∈H×W×C。最后,将4个得到的特征进行多尺度特征融合,再经过输出卷积层来恢复通道数,并通过全连接层进行分类。
2.2 自相关计算
为了获取图像中邻域的自相似性,对基本特征Z,计算每个位置x处(x∈[1,H]×[1,W]及其邻域中的值)C维向量的哈达玛积,并将它们收集到自相关张量D中,D∈H×W×C。张量D可以表示为具有C1维向量输出的函数:
(1)
式中:p∈[-dU,dU]×[-dV,dV],对应于滑动窗口中的相对位置,即2dU+1=U和2dV+1=V,其中dU和dV分别为垂直和水平方向上的最大位移,U和V为滑动窗口的高度和宽度。这里D并没有保留U、V的维度,而把它看作通道特征的一部分,因此可以得到新的通道维度C1=U×V×C。
2.3 上下文特征感知
尽管自相关计算可以获取图像的自相似性,但它缺乏原始卷积特征所表示的局部语义线索。为了更好地捕捉语义对象的不同方面,对Z和D进行拼接,得到上下文语义特征G,G∈H×W×Cg,如下所示:
(2)
式中:G(i,j)为图像中特定位置(i,j)的上下文语义特征,它包含了原始语义信息和自相似语义信息的综合表达,能够更好地反映图像的语义特征。之后通过特征提取层来分析G中的上下文关系,并对提取出的特征张量进行再卷积操作,使用输出层将特征通道数降至输入通道数,得到更加紧凑的特征表示。上述两个卷积块的卷积核大小都为1×1,该卷积块h(·)在没有填充的情况下学习上下文关系,并聚集局部相关模式,从而将通道的维度恢复为C,使得输出h(G)具有与Z相同的大小。将这两种表示结合起来生成自注意力,表示为A∈H×W×C。
A=h(G)+Z
(3)
通过邻域自注意力模块对基本特征进行增强,有助于定位目标对象的重要区域并增强特征的可识别性。
2.4 多尺度特征融合
经过邻域自注意力模块可以得到4个加强的特征,它们分别代表不同尺度的自注意力特征。为了使特征图信息完整并得到更好的嵌入特征,采用平均池化层和层归一化进行特征处理,从而进一步提高特征的表达能力。
ai=LayerNorm(AvgPool(Ai))
(4)
式中:ai为处理后的特征,Ai为经过邻域注意力处理后的加强特征。随后,进行多尺度特征融合,将不同尺度的特征信息进行融合,以提高模型的分类准确性。最后,通过输出卷积层恢复通道数,并后接全连接层进行分类。
a=concat(a1,a2,a3,a4)
(5)
y=FC(conv(a))
(6)
式中:a为融合后的特征,y为最终的分类结果,a1、a2、a3、a4为经过平均池化和层归一化后的输出特征,concat为拼接操作,FC为全连接层,conv为卷积层。使用多尺度特征融合可以进一步增强模型的表达能力,使其能够更准确地进行分类。
3 实验分析
3.1 数据集介绍
本文所用钢铁缺陷样本图像均来源于东北大学(NEU)表面缺陷数据库中的NEU-CLS-64[9],该数据集收集了热轧钢带的9种典型表面缺陷,即轧入氧化皮(RS)、斑块(Pa)、裂纹(Cr)、麻面(PS)、夹杂物(In)、划痕(Sc)、油污(Sp)、坑洼(Gg)和锈蚀(Rp)。NEU-CLS-64数据集中共有7 226张图片且每个类别图片数量不等,例如夹杂物(In)775张、坑洼(Gg)296张、油污(Sp)438张,但这些图片的分辨率全部是64×64,这种低分辨率图片无疑会给网络正确分类带来很大的难度。
3.2 实验环境与设置
实验使用基于NVIDIA 2080Ti GPU和Intel i7 9700K CPU的环境,采用PyTorch 1.8深度学习框架。训练集与测试集之间的划分比例为8∶2,即80%的数据用于训练,而剩余20%的数据则用于验证。在实验中,所输入的图片分辨率为64×64,并采用大小为3×3的卷积核来构建Conv卷积块,同时各个Conv卷积块的通道数C按照64—160—320—640的顺序递增。为获得具有更佳语义信息的特征图,在邻域自注意力模块中全部采用点卷积技术。在优化器方面,使用SGD优化器,设置动量为0.9,学习率从0.01开始,衰减因子为0.05。在NEU-CLS-64数据集上进行了100次epoch训练,每批次训练的样本数量为64。在第80个和90个epoch之后,采用学习率下降策略,将学习率减少0.1个因子。
3.3 算法对比分析
在实验设置相同的情况下,对本文所提模型与其他神经网络方法进行了比较,结果见表1。从实验结果中可以看出,本文所提的邻域自注意力网络具有最好的分类性能。相比于ViT-B/16[10]、Swin_t[11]、ResNet50[12]、MobileNet_v3_small[13]、DenseNet121[14]和EfficientNet_b2[15]分别在准确率上高出9.39%、5.11%、4.83%、3.30%、3.24%和2.97%。此外,在运行时间方面,邻域自注意力网络也是最快的,这意味着本文模型能够在相同时间内处理更多的图像,并且保持最佳准确率。在实验过程中发现,最新的ViT-B/16和Swin_t取得了最差的效果。这两个模型不仅计算量大、参数较复杂,而且性能表现较差。这是因为输入图像尺寸较小时,划分出来的图像块会比较小,每个图像块中包含的信息量有限,导致分类器无法捕捉到足够的信息,从而影响模型的性能。

表1 与其他方法在NEU-CLS-64数据集上的比较结果
3.4 可视化分析
图3呈现了各个模型的热力图可视化结果。从图中可以看出,ViT-B/16和Swin_t权重的关注点比较混乱,而邻域自注意力网络可以过滤掉其中一些不相关的区域,并将注意力集中在更重要的图像特征上。尤其是在Cr、In、Pa、Rp和RS这些缺陷上,相较于其他方法,本文方法能更精确地定位缺陷位置。同时,邻域自注意力网络融合了不同尺度的特征,使得它更有可能在复杂环境中学习到有用的特征。
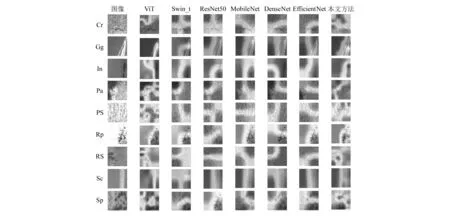
图3 不同模型可视化的结果
4 结束语
本文提出了一种基于邻域自注意力的钢铁表面缺陷分类算法,通过邻域自注意力模块定位目标对象的重要区域并增强特征的可识别性。为了保持特征图信息完整,使用多尺度特征融合的方法融合4种不同尺度的自注意力特征并用轧入氧化皮(RS)、斑块(Pa)、裂纹(Cr)、麻面(PS)、夹杂物(In)、划痕(Sc)、油污(Sp)、坑洼(Gg)和锈蚀(Rp)9类钢铁缺陷图像进行了测试。实验结果表明,本文所提模型在低分辨的钢铁缺陷图像中具有良好分类性能,可进一步获取缺陷的位置信息,对钢铁表面缺陷分类具有重要的实际应用意义。
