Energy-Efficient Traffic Offloading for RSMA-Based Hybrid Satellite Terrestrial Networks with Deep Reinforcement Learning
2024-03-11QingmiaoZhangLidongZhuYanyanChenShanJiang
Qingmiao Zhang ,Lidong Zhu,* ,Yanyan Chen ,Shan Jiang
1 National Key Laboratory of Science and Technology on Communications,University of Electronic Science and Technology of China,Chengdu 611731,China
2 The Higher Educational Key Laboratory for Flexible Manufacturing Equipment Integration of Fujian Province,Xiamen Institute of Technology,Xiamen 361021,China
3 China Mobile(Jiangxi)Communications Group Co.,Ltd,Yichun 336000,China
Abstract: As the demands of massive connections and vast coverage rapidly grow in the next wireless communication networks,rate splitting multiple access (RSMA) is considered to be the new promising access scheme since it can provide higher efficiency with limited spectrum resources.In this paper,combining spectrum splitting with rate splitting,we propose to allocate resources with traffic offloading in hybrid satellite terrestrial networks.A novel deep reinforcement learning method is adopted to solve this challenging non-convex problem.However,the neverending learning process could prohibit its practical implementation.Therefore,we introduce the switch mechanism to avoid unnecessary learning.Additionally,the QoS constraint in the scheme can rule out unsuccessful transmission.The simulation results validates the energy efficiency performance and the convergence speed of the proposed algorithm.
Keywords: deep reinforcement learning;energy efficiency;hybrid satellite terrestrial networks;rate splitting multiple access;traffic offloading
I.INTRODUCTION
In the next-gen communication system and the Internet of Things(IoT),the explosive growth of users and smart devices with the stringent needs of extensive coverage and continuous service present a challenging problem for terrestrial networks [1].Thanks to the development and advancement of satellites,satellite networks play a more important roles as the complement of terrestrial networks[2].Therefore,hybrid satellite terrestrial networks (HSTNs) are expected to be a promising solution for ubiquitous and reliable broadband communications[3].However,to accommodate the massive connection generated by the ever-increasing users and devices,new multiple access technologies are called for [4-6].Among them,rate splitting multiple access(RSMA),which innovatively divide transmission rate into two parts,has gained more and more attention because of its high capacity and low complexity comparing with non-orthogonal multiple access(NOMA),making it a potential candidate[7,8].Several literature have researched RSMA’s application in satellite communications.Reference[9]using deep unfolding learning approach in a HSTN to maximize the weighted sum rate.Multigroup ulticast and multibeam satellite systems adopting RSMA is investigated in[10].[11]uses proximal policy optimization(PPO)DRL method for optimization in 6G satellite communication system.
Another severe problem brought by the increased users and devices is the capacity challenge [12].To better tackle it,traffic offloading is a straightforward solution.Conventional schemes tend to deploy dense small cells like multiple layers of base stations (BSs) and low-powered access points (APs)for cooperation in heterogeneous networks [13,14].However,due to the densification limits,the improvements these schemes brought are restricted[13].Also with finite spectrum resources,the dense deployment would cause more intense competition and interference,which worsens the situation instead.In this scenario,satellite communications could improve the network capacity without being complex and lowefficient.Moreover,it is crucial to conserve energy since satellite is powered by the solar panels.Thus,energy efficiency problem in satellite network has become a great concern.In [15],the tasks are offloaded in a multilayer satellite terrestrial network,using D3QN learning algorithm to maximize the task number with minimizing the power consumption.Reference [16] presents a novel multiaccess edge computing (MEC) framework for terrestrial satellite IoT.By decomposing the problem into two layered subproblems,this work minimize the weighted sum energy consumption.Authors in [17] adopt Lyapunov optimization theory to solve the weighted sum energy consumption minimization problem.In [18],to investigate the computation offloading of vehicular edge computing,authors proposed a linearization based Branch and Bound algorithm and a closest rounding integer based algorithm for the problem.Authors in[19] designed robust latency optimization algorithm for computation offloading to minimize the latency in an Space-Air-Ground Integrated Networks.
In this paper,we aim to tackle the traffic offloading problem in a HSTN in an energy-efficient way.Satellite in this HSTN is scheduled to assist the macro base station (MBS) to improve capacity with lowest possible power.However,offloading problem is terribly difficult to solve using traditional method since it is non-convex and NP-hard.Also in real-life world,channels and network conditions change all the time,so the ability to learn and adapt is a fundamental requirement in the next-gen communications.Deep reinforcement learning(DRL)has explosively grown in recent years for it can quickly solve the non-convex problem without prior knowledge.DRL has been introduced into many fields of telecommunications.Literature [20,21] use deep learning techniques for beamforming.Route planning and decision are studied in [22,23].Recently,a state-of-art DRL algorithm called soft actor critic (SAC) has shown convergence speed and exploration advantages over famous DRL algorithms like deep deterministic policy gradient(DDPG)and deep Q-learning network(DQN)[24].It has been studied to be applied to arterial traffic signal control[25],trajectory design in unmanned aerial vehicle (UAV) network [24] and autonomous driving [26,27].For its excellent performence,we adopt it in our scheme.The contributions in this paper are summarized as follows.
•We formulate the Markov decision process(MDP) framework of the energy-efficient traffic offloading problem in the HSTN for SAC.
•We combine rate splitting with spectrum splitting in the design to jointly optimize precoders and spectrum resource allocation.
•To rule out unsuccessful transmission and avoid unnecessary frequent learning process,we introduce quality of service (QoS) constraint and switch mechanism in the algorithm.
The rest of this paper is organized as follows.Section II presents RSMA architecture and system model,followed by the problem formulation in Section III.Detailed process of the proposed scheme is given in Section IV.Section V provide the simulation results and analysis.Finally,Section VI concludes the paper.
II.SYSTEM MODEL
2.1 Rate Splitting Multiple Access
In SDMA,interference from other users will be treated as noise and totally discarded.That means some helpful information is also thrown away,though it is easy to recover the desired message.On the contrary,one user in NOMA has to fully decode all others’ interference,namely multiple successive interference cancellation (SIC),to extract its own message.This will cause exponentially growth of complexity in an massive access scenario.Users ordering and the distinct channel gain difference to achieve better performance make it more difficult and complicate as well.Therefore,RSMA comes up with a trade-off between these two schemes by partially discarding the interference and partially decoding them.In this way,it can extract useful information as much as possible while reduce the complexity,since it does not require ordering or significant discrepancy,and only needs one-time SIC for decoding.According to reference[6],the achievable rate region of RSMA,also known as the degree of freedom (DoF),is larger than SDMA and NOMA,which means RSMA could attain higher rate.This result shows that RSMA could utilize the interference to improve performance without causing too much complexity.
Figure 1 demonstrates thek-user one-layer RSMA architecture.All the users’messages are divided into two portions,the public oneand the private oneMpri k.Then the public messages from all users are combined together to getMpub,while all the private messages remain intact.After encoding the messages to signalsspub,s1,···,sk,they will be multiplied by their corresponding precoderswpub,w1,···,wk.Note thatwpubis shared by all users,but the others are private.The final transmitted signals for each user are the same
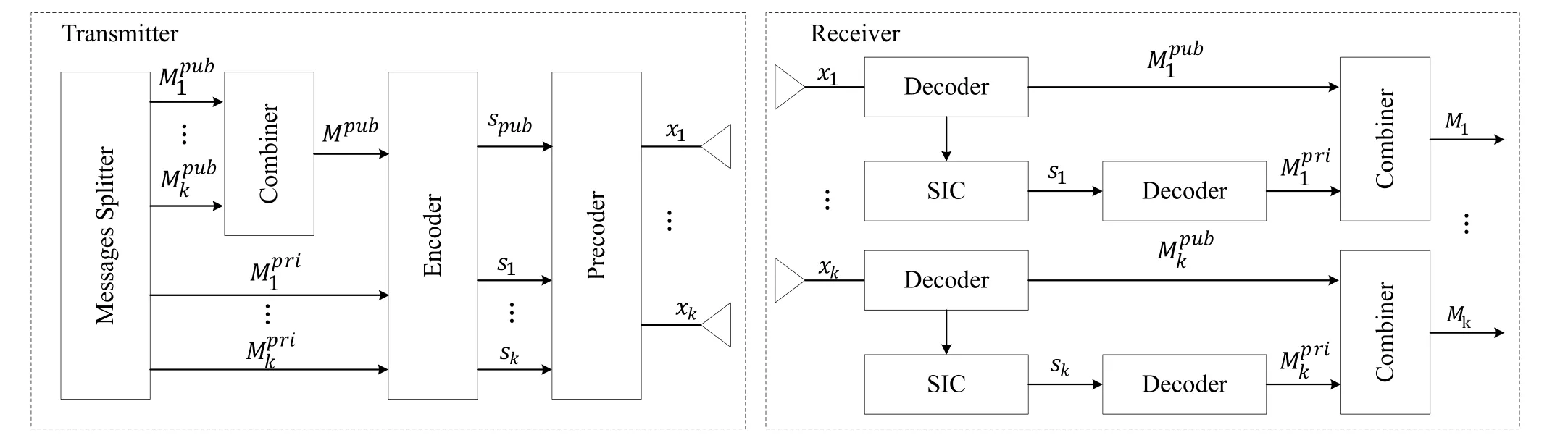
Figure 1.RSMA architecture.
Upon receiving,each user will obtainspubby dumping all the private streams as noise.Then a one-time SIC will be executed to get its own private stream,i.e.userkeliminatespubfrom the received signals by SIC and recoverskby casting aways1,···,sk-1.Combining the public portion and the private portion,each user fully recover the original message.
2.2 Network Model
The network we investigate,as illustrated in Figure 2.Multiple users are served in it.The MBS in this scenario is incapable to provide sufficient capacity for cell users(CUs)to guarantee the QoS.Therefore,a satellite equipped with multiple antenna servicing as a replay is introduced to offload the traffic.During this process,cached contents like popular information or service are first transmitted from MBS to the satellite and then broadcast to each CU.To achieve highest possible rate,we adopt RSMA in our scheme.

Figure 2.Network model.
Satellite is seriously energy-limited since it is powered by solar panels.Maximizing its energy efficiency can help alleviate this situation.According to the definition,energy efficiency is the ratio of rate and power.So it is reasonable to adopting RSMA for its capacity advantage.Moreover,we need to take into account the finite spectrum resource of CU.A reasonable scheme design is to combine the frequency band allocation with RSMA’s precoder design,that is,spectrum splitting with rate splitting.
Considering the fading in terrestrial network are mainly small-scale and large-scale,we model the channel between MBS and CU-kas
whereξk~CN(0,1) is the Rayleigh fading coefficient,dtis the distance between CU and MBS,αis the free space path loss exponent.
While the line-of-sight channel in satellite network is often modeled as mostly free sapce path loss but little small-scale fading,so the channel between CU-kand satellite is given by
whereζk~CN(0,1) is also the small-scale fading andl(ds)=λ/4πdsis the free space path loss.λ,ds,GtandGrdenote wavelength,the distance between CU and satellite,antenna gain at satellite and CU,subsequently.
In this network,we assume that satellite and MBS operate on different frequency band,therefore there is no intra-interference between them.By exploiting the orthogonal spectrum resource,the capacity of this network could be improved.
III.PROBLEM FORMULATION
Based on the description in 2.1,the broadcasting signal is
wherewpub,wk ∈CK×1.The received signal at CUkis given by
wherehk ∈CK×1is either terrestrial or satellite channel coefficient.Without loss of generality,we assume the power ofs=[spub,s1,···,sk] andnk,the Additive White Gaussian Noise (AWGN) at CU-k,are normalized for convenience.
First we deduce the capacity of terrestrial network.The signal to interference plus noise ratios (SINR) at CU-kcan be expressed as
We assume the frequency band resource for each CU isfk,which consists of the terrestrial partftkand the satellite partfsk.By this design we can jointly optimize the spectrum and precoder resources.Note that to ensure successful transmission,the public stream rate needs to be the minimum one amongKCUs.So we have the public and private stream rate as
So the rate of CU-kfor terrestrial network is
Similarly,the SINRs and rates of CU-kfor satellite network will be
Finally,the total rate of CU-kwill be
Consequentially,the energy efficiency of this HSTN is established by
wherePCis consumed circuit power of the network.
Our objective is maximize the energy efficiency of the network,that is gaining highest possible transmission rate with lowest possible power consumption.So the optimization problem is defined as
Constraint(17b)is the power limit,wherePtis total transmission power.Constraint(17c)sets a threshold to guarantee the quality of service(QoS).At last,constraint (17d) is the spectrum splitting requirement.It can be satisfied simply by limiting the range offtkto[0,fk].
Since(17a)is a non-convex and NP-hard problem,it is very challenging to solve it using traditional convex optimization.In real-world environment,channel condition and network change all the time,making it more difficult to tackle with.Moreover,next-gen communications views the ability to learn as a fundamental and crucial requirement.Thus,it is reasonable to introduce deep reinforcement learning as the solution.
IV.SOFT ACTOR CRITIC-BASED ALGORITHM
Reinforcement learning (RL),as a main field of machine learning (ML),is a decision making procedure for MDP,which gathers information about an unknown environment by continuing interacting with it and updating the policy.Thus,prior knowledge about the environment is not required by this model-free method[28].A general RL problem could be defined by a turple(S,A,P,r),in whichSis the state space,Ais the action space,Pis the transition probability andr(s,a)is the reward.
At timestampt,an actionatis chosen by agent based on the policyπ(at|st) and applied to the environment.Then the next statest+1and a rewardrt+1are returned from the transition probabilityPand the reward function accordingly.When the expected discounted returnis maximized,the optimal policy is learned.
Recently,a maximum entropy reinforcement learning called soft actor critic(SAC)becomes famous for its outstanding exploration performance[24].It learns the optimal policy by maximizing the expected sum of entropy augmented reward,which is given by
whereβis the temperature parameter that regulates the relative importance of the entropy,which is defined below,against the reward.
Normally,the variance of policy distribution is small and its center is close to the action that can bring high return.The entropy in SAC,however,increases its variance so that more actions could be chosen.This results in more exploration during the learning procedure.
We first establish the MDP framework for the energy efficiency problem.The state space is defined asThese SINR feedbacks contain the channel state information,thus the dynamic change of the network could be learned.Since the resources allocation are implemented by the spectrum and rate spliting,the action space is given asA={w,ft},wherew=[wpub,wk]andft=[ftk].
For the reward function,we wish to incorporate constraint (17c) in the design to guarantee the transmission.Any CU that violates this condition will be penalized.So we could get the reward at timestampt,which is
ηtis the penalty for actionatwhich has the form
where indication functionΩis
As for (17b),this global power constraint demonstrates that any CU at anytime must obey it.By the projection operation given below,it could be easily satisfied.
The policy gradient SAC utilizes five deep neural networks(DNNs)to finish the task: a soft state value networkVψ(st) with a target networkV¯ψ(st),a policy networkπϕ(at|st)and two soft Q-value networksQθ1,2(st,at).In these networks,two value functions,namely soft state value and soft Q-value,are used to evaluate the received return in the future.Their definitions are presented as
The parameters in policy network could be learned by minimizing the expected Kullback-Leibler(KL)divergence between the policy and soft Q-value.Therefore the objective function of policy network will be
The parameters in soft value network could be learned by minimizing the mean square error between soft state value and its approximation.The target network with it is to improve learning stability.The objective function will be
Finally,the parameters in soft Q-value network could be learned by minimizing the soft Bellman residual.In addition,the technique adopting two networks is to avoid overestimation.Thus,the objective function will be
Considering that an ever-learning DRL algorithm will consume too much resources and prohibit the practical implementation,especially in a large network,we introduce a switch mechanism to activate the learning procedure.Specifically,if the discrepancy of state between current timestamp and previous one is under the threshold,we will take last action instead of learning a new one.The proposed SAC-based algorithm is shown below and its architecture is illustrated in Figure 3.

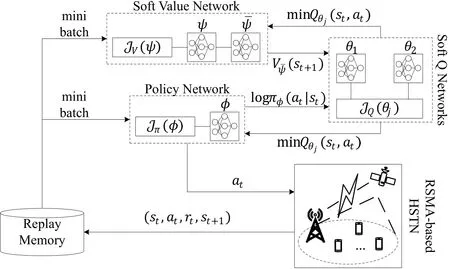
Figure 3.Architecture of SAC-based algorithm.
V.SIMULATION RESULTS
We evaluate the proposed algorithm by presenting some simulation results.We consider a HSTN with 3 CUs.For the terrestrial part,the path loss exponent isα=3 and the radius of MBS is 500 m.For the satellite part,its height is 1000 km with transmission powerPt=50 dBm and frequencyf=12 GHz.The gains at transmitter and receiver ends areGt=35 dB andGr=10 dB,respectively.Bandwidth for CU is 5 MHz while the consumed circuit power isPC=10 W.QoS constraint for CU isRth=0.1 bps/Hz.
The five deep neural networks in SAC all consist of 3 hidden layers with 64 neurons.Adopting the parameters setting in[24,29],learning rate is 0.01,discount factor is 0.9,entropy temperature is 0.2,replay memory size is 200,batch size is 32 and episode is 5000 with 200 timestamps.
Figure 4 shows the average energy efficiency of four deep reinforcement learning algorithms.Among them,SAC,deep deterministic policy gradient(DDPG) and REINFORCE could tackle continuous action/state space tasks.But deep Q-learning (DQN)could only deal with discrete action/state space problems.DQN finishes the job By dividing the action/state space and maintaining a Q-value table.However,this will also introduce much loss comparing with other three.Therefore,DQN has the poorest performance.SAC,on the other hand,outperforms the others.Due to its exploration advantage,it has the fastest convergence speed.Though DDPG has relatively high energy efficiency,it is very unstable in the first 1800 episodes.REINFORCE and DQN perform poorly with slow convergence speed.Figure 5 is the illustration of average loss.
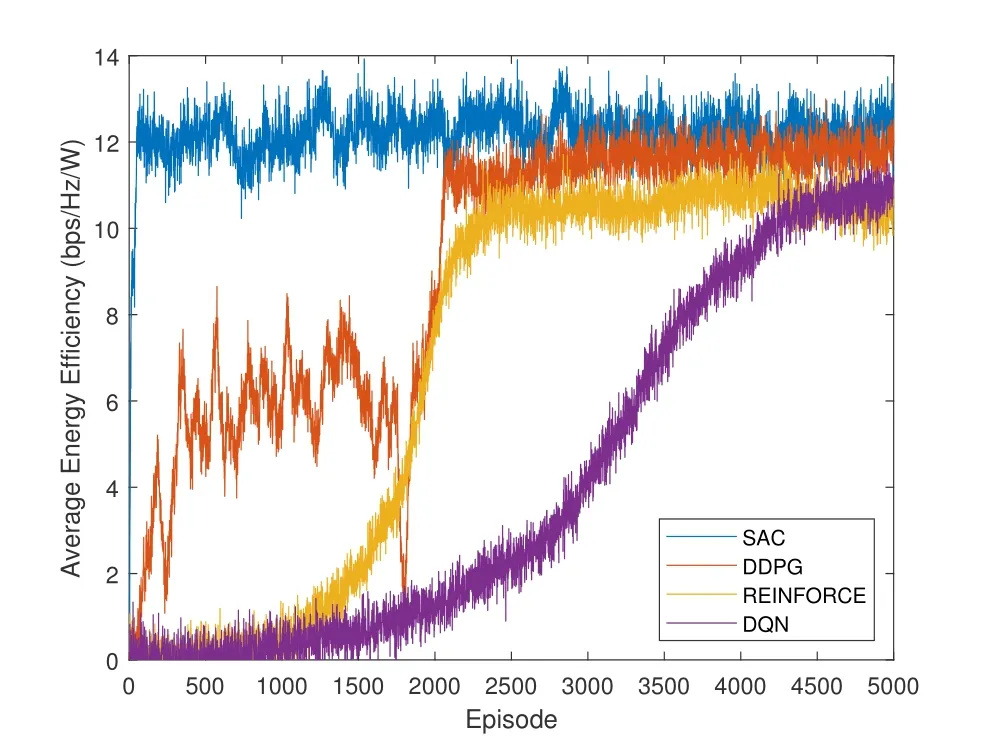
Figure 4.Average energy efficiency.

Figure 5.Average loss.
We vary the QoS requirement to evaluate the performance as shown in Figure 6.As the QoS constraint increase,more CUs will be penalized for not satisfying the requirement.Thus,all four algorithms manifest downward trend.But SAC still stands out.
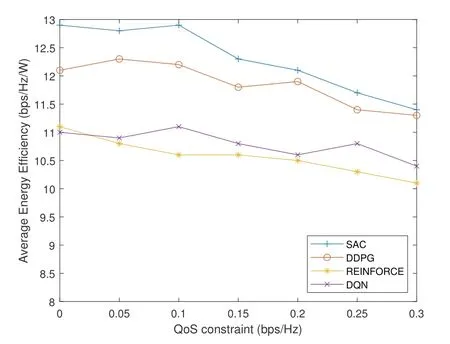
Figure 6.Average energy efficiency under different QoS constraints.
The same situation happens when we change the switch threshold.Depicted in Figure 7,as the threshold increases,all four algorithms has decreasing energy efficiency.Also the average running time per execution is investigated to evaluate the time cost.However,in Figure 8,by applying switch mechanism,the computation time of SAC,DDPG and REINFORCE decrease,which means unnecessary learning is avoided when the environment does not change that much.

Figure 7.Average energy efficiency under different switch thresholds.
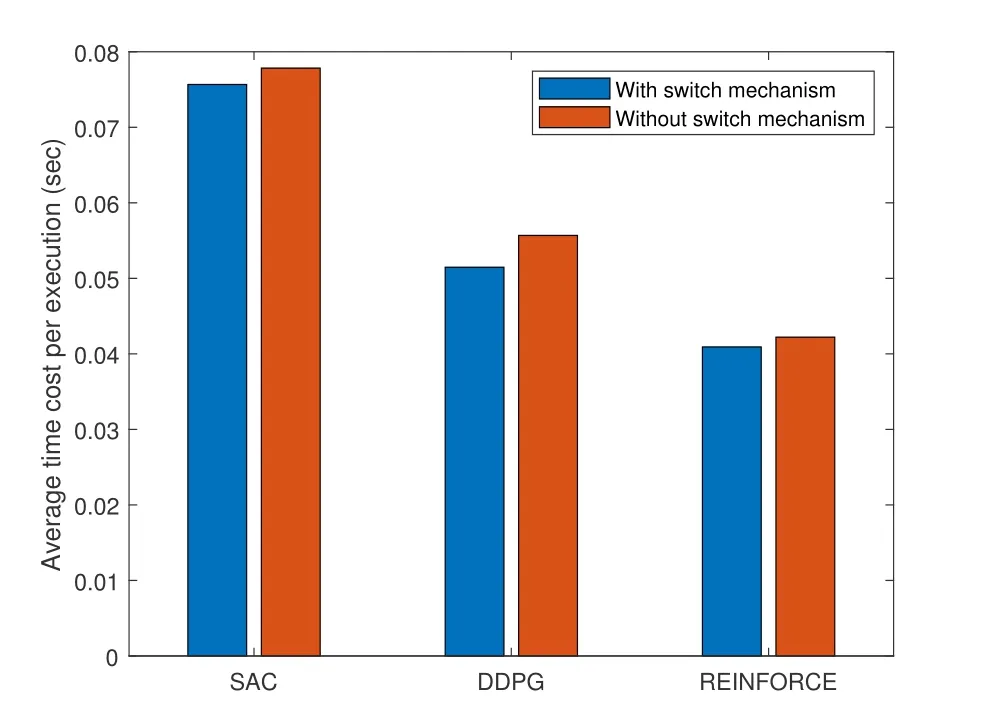
Figure 8.Network model.
VI.CONCLUSION
In this paper,the traffic offloading in a hybrid satellite terrestrial network to maximize the energy efficiency is studied.To jointly optimize the precoder and spectrum resources allocation,we combine rate splitting and spectrum splitting.The Markov decision process framework is used to formulate this problem,using the soft actor critic DRL algorithm to solve the problem.We also introduce QoS constraint and a switch mechanism to avoid unsuccessful transmission and unnecessary frequent learning process.The simulation results validate the performance of our scheme,which has fast convergence speed and high energy efficiency.
杂志排行

China Communications的其它文章
- An Efficient Approach to Escalate the Speed of Training Convolution Neural Networks
- Reliability Assessment of a New General Matching Composed Network
- Cooperative User-Scheduling and Resource Allocation Optimization for Intelligent Reflecting Surface Enhanced LEO Satellite Communication
- Flight Time Minimization of UAV for Cooperative Data Collection in Probabilistic LoS Channel
- Joint Optimization of Resource Allocation and Trajectory Based on User Trajectory for UAV-Assisted Backscatter Communication System
- Cooperative Anti-Jamming and Interference Mitigation for UAV Networks: A Local Altruistic Game Approach