基于多特征深度子空间聚类的高光谱影像波段选择
2024-03-09何珂孙伟伟黄可陈镔捷杨刚
何珂,孙伟伟,黄可,陈镔捷,杨刚
宁波大学 地理与空间信息技术系,宁波 315211
1 引言
随着遥感技术的不断发展,卫星遥感进入了高光谱的时代。高光谱遥感通过数十个甚至上百个连续的窄波段对地物进行成像,从而能够得到地物连续且完整的光谱曲线(朱德辉 等,2020)。通过对所得到的光谱曲线进行分析,我们可以找到地物的诊断性光谱特征,这是其他影像所不具备的能力。因此,高光谱遥感被广泛应用于滨海湿地制图、农作物精细分类、水质评价等方面(Jiao等,2019)。然而,高光谱图像的相邻波段之间有强相关性,这意味着高光谱图像拥有大量的冗余数据(He等,2022)。此外,高光谱影像的数据量非常大,这会对处理过程造成很大的负担。同时,高光谱影像的高维特性可能会引起“维数灾难”问题的发生(苏红军,2022)。因此,有必要在高光谱图像应用之前对其进行降维。降维可分为波段选择和特征提取。波段选择可以充分保留高光谱影像原有的物理意义,这使其成为当前降维的重点研究领域。
波段选择方法可分为以下4种:基于排序,基于搜索,基于聚类以及基于稀疏(Sun和Du,2019)。基于排序的波段选择方法利用某种特定的准则对高光谱各个波段进行排序从而选择排名最高的波段组合,如基于分形维数的最佳波段指数(Su等,2008)以及增强的快速密度峰值聚类增强的快速密度峰值聚类E-FDPC(Enhanced Fast Density Peak-Based Clustering)(Jia 等,2016)。这种方式十分依赖于准则函数的选择。同时该方法独立判断每个波段的重要性,这样会导致选择的波段组合之间的相似性较高。基于搜索的方法通过搜索策略寻找合适的波段组合,使给定的准则函数达到最优,如线性预测LP(Linear Prediction)(Du和Yang,2008)和基于体积梯度的快速波段选择(Geng 等,2014)。该方式效果优于基于排序的方式,但是所需运行时间非常高。基于聚类的方法先将高光谱原始波段分为一定数量的簇,再从每个簇中挑选波段,如双聚类(Yuan等,2015)和最优聚类框架OCF(Optimal Clustering Framework)。基于聚类的方法无法保证波段的信息量且容易受到噪声影响。基于稀疏的方法将波段选择的过程视为稀疏约束的优化问题,如基于稀疏表示的波段选择SpaBS(Sparse Representation-Based Band Selection)(Chen 等,2011)和不相似加权稀疏表达模型(Sun 等,2016)。基于稀疏的方法生成稀疏系数的质量优劣十分依赖于优化方法且结果不够稳定(孙伟伟 等,2022)。
子空间聚类算法是一种经典的聚类算法。该算法通过假设高维数据近似地来自子空间的集合来寻找低维子空间的表示(Elhamifar 和Vidal,2013),典型的算法如改进的稀疏子空间聚类ISSC(Improved Sparse Subspace Clustering)(Sun 等,2015)和快速潜在的低秩子空间聚类FLLRSC(Fast And Latent Low-Rank Subspace Clustering)(Sun 等,2020)。但是,高光谱遥感影像具有非线性特征,基于线性假设的传统子空间聚类方法不能很好地表征高光谱影像。同时,这些方法均为浅层模型,无法提取高光谱影像中深层次的特征。
深度学习网络具有多个不同级别的表征层,每一层通过非线性模块学习特征,通过多层级的堆叠可以学习到非常复杂的特征。因此,深度子空间聚类DSC(Deep Subspace Clustering)(Zeng等,2019)被提出来尝试解决传统子空间聚类方法的种种问题。然而,现有基于深度子空间聚类的方法存在以下几个问题。第一,现有基于深度子空间聚类的方法只关注单一尺度的特征,没有考虑不同尺度的特征,这可能会导致忽略具有不同空间尺度特定地物的诊断性波段,影响最终波段选择的结果(Sun 等,2022)。第二,现有方法没有考虑噪声的干扰,容易受到噪声的侵扰,造成后续生成自表达系数的准确度较低,进而无法得到满足分类应用需求的波段子集。
针对上述问题,本文提出了基于多特征深度子空间聚类MFDSC(Multi-Feature Deep Subspace Clustering)网络进行高光谱影像波段选择。MFDSC 将空间—波段注意力特征提取模块、多尺度特征提取模块与DSC 进行耦合来提取多种深层次特征提高后续自表达系数的表示能力。自表达层被嵌入到卷积自编码器中学习子空间自表达系数,这种方式用非线性的视角思考了波段间关系,实现空间信息和光谱信息之间的交互。空间—波段注意力模块可以自适应地捕捉像素之间的长距离依赖关系,能够在具有复杂结构的高光谱数据中挖掘出高区分度的特征。另外,空间—波段注意力模块同时考虑了单个像素的特征以及像素之间的相互关系可以减少冗余信息,从而提高波段选择的准确性。多尺度特征提取模块可以提高模型的表征能力,提升自表达系数学习的准确性,并且能够提高模型的鲁棒性,使得模型具有更强的泛化能力。此外,模型从多个尺度下提取信息,更好地考虑了空间的信息,可以避免误选噪声波段。
2 研究方法
高光谱影像可以看成是一个拥有高h、宽w、波段b的三维数据立方体,因此可以用X=∈Rh×w×b来表示。为了获取多特征进行深度子空间聚类,MFDSC(图1)通过以下的步骤进行:
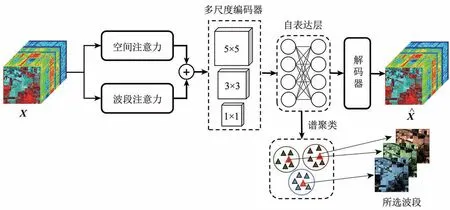
图1 MFDSC流程图Fig.1 Flow chat of MFDSC
(1)通过空间—波段注意力模块对原始高光谱进行加权,抑制噪声等无用信息,加强空间—光谱信息的表征学习(Fu等,2019)。
(2)利用卷积核大小分别为5、3、1的卷积操作提取不同尺度下的特征对高光谱影像进行编码,多尺度的特征能够提供更多的上下文信息,并且增强网络的非线性,有利于模型的优化。
(3)通过自表达层学习子空间表达系数,并使用解码器重建回原始的高光谱影像。
(4)通过谱聚类对子空间系数矩阵进行聚类,之后选取每个聚类中离聚类中心最近的波段作为代表波段。
2.1 空间—光谱注意力模块
本文方法中使用的双注意力模块分为空间注意力模块以及波段注意力模块分别对空间和波段信息进行加权。
2.1.1 空间注意力
首先,将高光谱影像X送入到卷积层中获得3 个新特征{P1,P2,P3},这3 个新特征中P1用来查询空间上的关键信息,表示要计算相似度的目标。P2用来计算与P1之间的相似度,表示要与P2进行比较的对象。P3是用来传递信息的向量,表示每个信息的权重,即注意力权重,用于计算加权和。通过卷积层的运算,这些特征包含了反射率或辐射值等信息。这些信息会被卷积层提取抽象形成高级别的语义特征,映射到这些特征中,用来计算不同像素之间的相似度,从而实现对不同空间信息的加权处理。这种加权处理可以使得模型更加关注重要的空间特征,从而提高模型的性能效果,并利用P1,P2计算空间注意力矩阵Qp:
式中,N为高光谱影像的像素数量,QP评估了不同空间位置的重要性。最后,利用QP与P3计算空间注意力图As:
式中,α表示初始化为0 的可训练参数,用来协助空间注意力的学习。
2.1.2 波段注意力
与空间注意力获取方式类似,首先将高光谱影像X送入到卷积层中获得3 个新特征{B1,B2,B3},利用这些特征对不同波段信息的加权处理。这种加权处理可以使得模型更加集中于重要的波段特征,从而提高波段的区分度,然后利用B1,B2计算波段注意力矩阵Qb:
最后,将Qb与B3进行矩阵相乘计算波段的注意力图Ab:
式中,β表示初始化为0 的可训练参数,它用来控制输入影像波段注意映射的重要性。
为了获得对空间—波段的注意力,通过逐元素相加的操作对上述两个注意模块生成的特征映射进行聚合,构建空间—波段注意力特征:
通过该模块提取得到的空间—波段注意力特征有助于提高特征识别能力,降低异常值对于波段选择的影响。
2.2 多尺度自编码器
传统的自编码器仅能获取单一尺度的特征,无法得到高光谱影像不同尺度下的信息,这限制了网络的表征能力。为此,MFDSC 应用多尺度自编码器克服这一问题。MFDSC 的编码器由3 个核大小不一的卷积块组成,其大小分别为1×1、3×3以及5×5:
式中,Conv1(·),Conv3(·),Conv5(·) 分别表示卷积核大小为1×1、3×3以及5×5的卷积操作,E1,E3,E5为上述卷积操作提取的特征,Concat(·) 为特征堆叠操作,E为编码器提取的多尺度潜在表示。MFDSC 的解码器部分使用反卷积操作重建原始输入。解码器部分可以表示为=D(E),其中表示为重建的结果。我们可以利用L2 损失来构建损失函数来优化其重建过程:
2.3 自表达层
MFDSC 将自表达层嵌入到多尺度自编码器的编码器和解码器之间来端到端的学习深层的子空间自表达系数。我们假设高光谱数据属于n个子空间的集合,即。n个子空间的维度分别为。子空间中的任意一样本x均能表示为X中除去x的线性组合,即为数据的“自表达”特性,其目标函数如下表示:
式中,C∈Rb×b为自表达系数矩阵;diag(C)=0约束C的对角线元素等于0,以避免平凡解;‖·‖2为L2范数,以避免高光谱影像波段高的相关性导致系数解“太稀疏”,λ为平衡系数。然后,MFDSC利用自表达系数构建相似度矩阵W=|C|+|C|T。通常情况下,相似度矩阵表现出块对角化的结构,这非常有利于后续的谱聚类处理(王卫卫 等,2015)。因此,研究者们多使用谱聚类算法对相似度矩阵聚类,获得最终聚类结果。
综上所述,结合多尺度自编码器和自表达层两者的损失函数,最终的目标函数表示为
式中,μ为平衡系数。
对于式(12)利用随机梯度下降方法进行训练。在模型训练完成之后,MFDSC 利用谱聚类对自表达系数矩阵进行聚类,得到最终聚类结果,计算每个聚类中的波段到该聚类中心的距离,选出每个聚类中最接近聚类中心的波段作为波段选择的结果,其具体流程如图1所示。
3 实验结果与分析
3.1 实验数据集
为了验证本文提出的波段选择方法的有效性,我们在Indian Pines 数据集以及PaviaU 数据集上与其他波段选择方法进行对比实验。
Indian Pines 数据集是由AVIRIS 传感器在美国印第安纳州西北部印度松试验点采集获得(https://engineering.purdue.edu/~biehl/MultiSpec/aviris_documentation.html [2023-05-30])(Sun 和Du,2018)。其影像大小为145 像素×145 像素,在200—2400 nm 的波长范围上拥有224 个光谱响应波段。由于水汽和噪声的影响,去除了24 个坏波段,剩余200个波段用于后续应用。该数据集共包含16 类地物,其假彩色合成图及地表真值图像见图2。

图2 Indian Pines假彩色合成图及地表真值Fig.2 False color composite and ground truth of Indian Pines
PaviaU 数据集由ROSIS 传感器在意大利北部帕维亚上空的拍摄得到,空间分辨率为1.3 m(http://www.ehu.es/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes[2023-05-30])(Sun等,2017)。该影像在430—860 nm 的波长范围上拥有103 个光谱响应波段,包含9类地物。在采集中存在无信号像元的干扰,去除没有信号的一部分空间像元之后,其影像大小为610×340,为了方便实验进行,我们对影像进行了裁剪,裁剪范围为:[150—350,100—200](Cai 等,2021),裁剪后地物类别变为8类。其假彩色合成图及地表真值图像见图3。
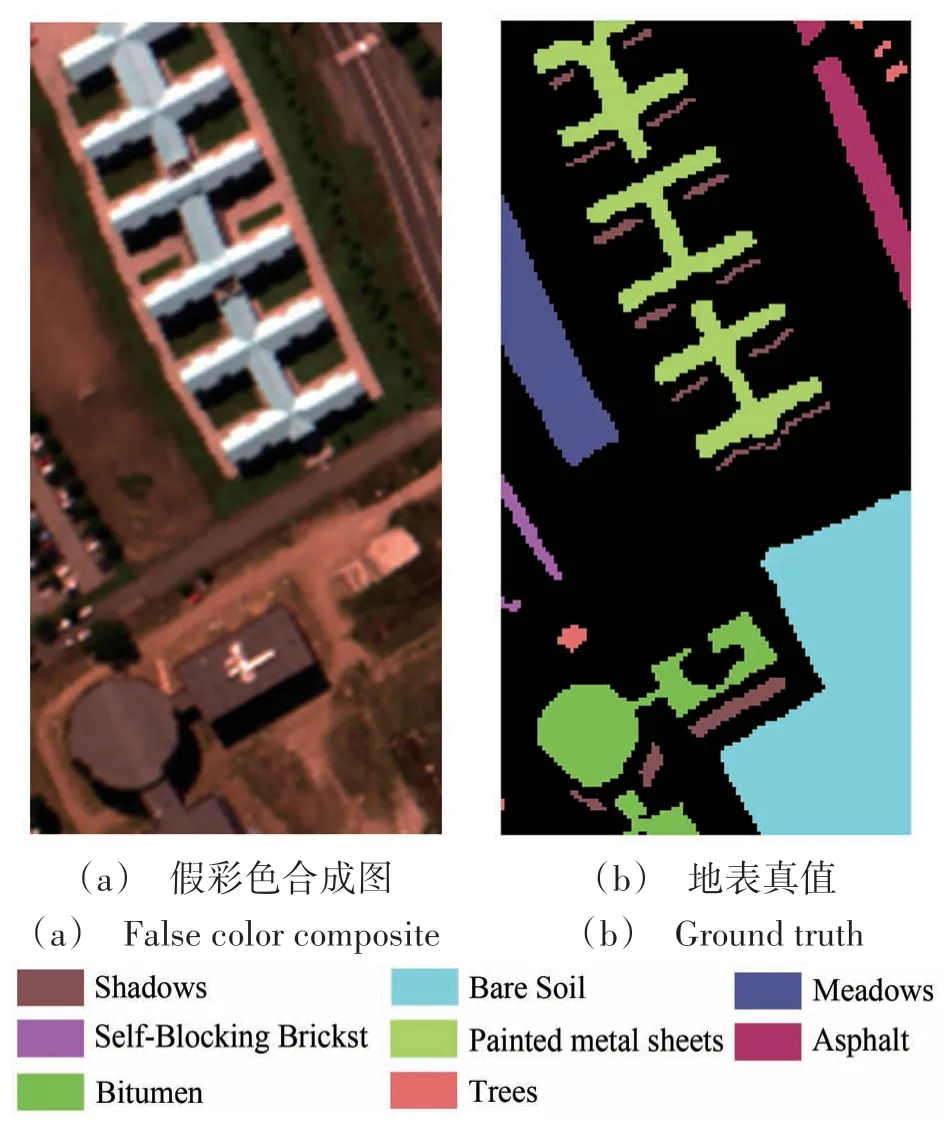
图3 PaviaU假彩色合成图及地表真值Fig.3 False color composite and ground truth of PaviaU
黄河三角洲数据集YRD(Yellow River Delta)是由国产高光谱遥感卫星ZY-102D(http://sasclouds.com/chinese/satellite/chinese/zy102d[2023-05-30])在山东省东营市黄河入海口附近拍摄。在去除受水和大气等影响的坏波段后,YRD 数据保留有119 个波段,影像大小为1147×1600。为了方便实验进行,对影像进行了裁剪,裁剪范围为[490—600,775—890],该范围内共包含3类地物,其假彩色合成图及地表真值图像见图4。

图4 YRD假彩色合成图及地表真值Fig.4 False color composite and ground truth of YRD
3.2 实验设置
将本文提出的MFDSC 与5 种主流的方法以及全波段进行比较。这5 种方法包括LP(基于搜索)、ISSC(基于稀疏)、E-FDPC(基于排序)、OCF(基于聚类)以及DARecNet(基于深度学习)(Roy 等,2021)。将ISSC 中的参数设为0.1,LP 中寻找最佳起始波段方法的迭代次数被设置为100。对比方法中的参数设置遵循其默认设置。
使用最常见的分类器SVM(Archibald 和Fann,2007)对不同数据集进行地物分类。SVM 以径向基函数作为核函数,其中用到的方差参数和惩罚因子根据三折交叉验证来确定。选择总体分类精度OA(Overall Accuracy)用于评价不同方法的分类表现。分别随机挑选Indian Pines 数据集中10%的标签样本作为SVM的训练样本。对于PaviaU数据集,将训练样本比例设置为5%。将YRD数据集1%,剩余的作为测试样本。所有的实验均重复10 次,并将得到的结果取平均作为最终结果。
本文所提出的方法以及基于深度学习方法运行的软件环境为Python 3.6。其他4 种传统方法在Matlab2018a 环境下运行。所有方法运行的硬件环境为:Intel Core i7-10700 2.90 GHz CPU以及NVIDIA GeForce RTX 3080。
3.3 实验结果
3.3.1 分类精度对比
为了揭示MFDSC方法所选波段组合的有效性,我们设计了分类实验。该实验通过改变所选波段数量来分析不同方法的性能。不同方法在5—50的范围内以5为步长选择波段进行分类结果比较。图5展示了不同方法在不同波段子集大小下分类曲线图。图6—图8 展示了6 种方法在波段子集大小为30 时所得到的分类结果图。对于Indian Pines 数据集,图5 表明本文提出的MFDSC 性能优于其他方法以及全波段的结果。当选择波段较少时,MFDSC 就能够取得不错的分类精度。在选择波段达到一定数量时,提出的方法超越了全波段的分类结果,这说明MFDSC 能够选择出代表性的波段子集。基于深度学习的方法同样表现十分出色,能够胜过全波段的分类精度。基于稀疏策略的ISSC 次于基于深度学习的方法,但在传统方法中表现较好且相对稳定的。OCF 的分类精度随着波段数量增加出现了轻微下降的现象。从图6中也能发现MFDSC的地块均质性及连续性更好。

图5 不同波段数量下不同方法的总体精度Fig.5 OCAs of different methods with different number of bands

图6 不同方法所选波段的Indian Pines分类结果图Fig.6 Classification results of Indian Pines using bands selected by different methods

图7 不同方法所选波段的PaviaU分类结果图Fig.7 Classification results of PaviaU using bands selected by different methods

图8 不同方法所选波段的YRD分类结果图Fig.8 Classification results of YRD using bands selected by different methods
从图5 可以明显发现,对于PaviaU 数据集来说,MFDSC 的分类结果表现最佳,并且相比其他方法更具有稳定性。虽然DARecNet 在Indian Pines数据集表现优异,但是在PaviaU 数据集上的总体分类精度不佳,略低于ISSC。OCF 虽然在所选波段为10 和35 时分类精度最佳,但是不够稳定。E-FDPC 与其他方法相比具有较大差距。当波段数量增大到一定数量时,不同方法的分类精度逐渐接近。在PaviaU 数据集上,所有方法的OCA 曲线均远低于全波段,这可能是由于PaviaU 数据集自身具有较高的影像质量。
对于YRD数据集来说,由于样本量较少,6种实验方法的总体精度都起伏比较大。相对来说MFDSC和DARecnet的起伏波动较小,证明相比其他方法鲁棒性较好的。LP的表现与MFDSC和DARecnet接近。OCF和ISSC则出现了“维数灾难”现象。
3.3.2 所选波段定量分析
本实验中我们利用平均信息熵AIE(Average Information Entropy)、平均相对熵ARE(Average Relative Entropy)(Sun 等,2016)和平均信噪比ASNR(Average Signal-to-Noise Ratio)对不同方法所选的20 个波段进行定量分析。AIE 越大表明所选波段子集包含的信息量越大。ARE 的值越大表示波段组合间的分离度越大冗余度越小。ASNR 的值越大表示所选的波段所含噪声越少有用信息越多,两个数据集的结果如表1—3 所示,黑体加粗结果表示该方法表现最佳。

表1 不同方法在Indian Pines上所选波段子集的比较Table 1 Comparison of selected band subsets by different methods on the Indian Pines dataset

表2 不同方法在PaviaU上所选波段子集的比较Table 2 Comparison of selected band subsets by different methods on the PaviaU dataset
从表1—表3 中可以发现,在Indian Pines 数据集中,E-FDPC 拥有最高的ASNR,而其AIE 则是对比方法中最差的,这导致其分类精度不理想。LP 具有最高的AIE,但是其ASNR和ARE却是最低的,这也解释了为什么LP 的分类表现较差。MFDSC拥有最高的ARE值,这也说明MFDSC所选的波段冗余度较低。AIE 以及ASNR 与ISSC 的值相近,同其他方法对比也具有一定的竞争力。在PaviaU 数据集中,MFDSC 的AIE 值仅比最高的DARecnet 低0.01,其ASNR 也仅比最高的低0.03,是唯二ASNR值超过2的,这也保证了MFDSC能够得到出色的分类结果。DARecNet 的ASNR 和ARE值均表现欠佳,导致了其分类精度不如另一个数据集的表现。在YRD 数据集中,OCF 拥有最高的ASNR,但是其ARE和AIE是最低的,这导致了其分类表现不佳。MFDSC的ARE 值比其他方法高出接近一倍,这可能是因为使用了空间—光谱注意力增强了特征的区分度。
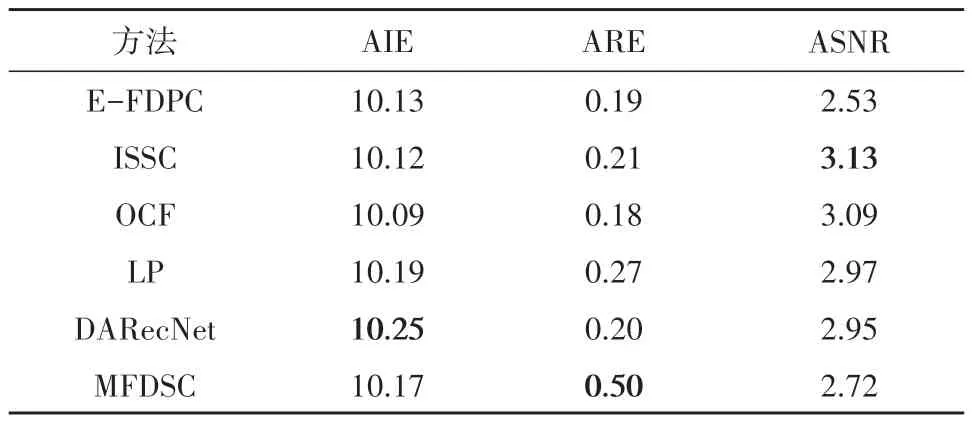
表3 不同方法在YRD上所选波段子集的比较Table 3 Comparison of selected band subsets by different methods on the YRD dataset
3.3.3 计算效率对比
本实验将MFDSC 与其他5 种方法进行了计算效率的对比。表4 为不同方法选择Indian Pines 数据集、PaviaU 数据集和YRD 数据集30 个波段所需的时间对比。

表4 不同方法计算时间对比Table 4 Computational time of different methods /s
从表4 可以看出,E-FDPC、ISSC 以及OCF 方法所用时间较少。基于深度学习的DARecnet 方法计算效率最低,与其他方法的计算效率差距非常大。MFDSC 和LP 的计算时间虽然相较其他方法具有一定劣势,但总体在可接受程度内。同时结合分类精度和实验效果分析,MFDSC 的综合表现最好,能够为后续高光谱影像处理应用提供较好的支持。
4 结论
本文提出了基于多特征深度子空间聚类的高光谱波段选择网络MFDSC。首先,模型中加入了空间—波段注意力模块降低噪声及异常值对于子空间聚类自表达性能的影响,增强提取特征的区分度。其次,本文提出了一种多尺度自编码器,在不加深网络层数的情况下来学习数据在不同尺度视角下的潜在表征,防止出现网络退化现象,同时解决传统波段选择方法难以从非线性的角度考虑高光谱影像波段间关系的问题。自表达层被嵌入在编码器和解码器之间来获取子空间表达系数矩阵,并采用谱聚类来获得最终波段子集。多个实验结果表明,MFDSC 在可接受的计算时间内能够选择更优秀的波段子集。但是,由于自表达层的限制,MFDSC 对内存的需求较大。因此,后续研究工作的重点将围绕改进自表达层算法开展,进一步降低其对内存的依赖。
