基于多特征融合的煤自燃温度深度预测模型
2024-03-08贾澎涛郭风景孙刘咏林开义
王 斌,贾澎涛,郭风景,孙刘咏,林开义
(1.陕西建新煤化有限责任公司,陕西 黄陵 727300;2.西安科技大学计算机科学与技术学院,陕西 西安 710054;3.陕西陕煤蒲白矿业有限公司,陕西 蒲城 715517)
0 引 言
煤矿火灾是影响煤矿生产的重大灾害之一,其中由于煤自燃引发的火灾占矿井火灾90%以上[1-3]。煤自燃是一个复杂的动态氧化过程,其发生具有隐蔽性、突变性的特点,一旦发生会严重威胁矿井生产安全和矿工生命安全[4-5]。因此,开展煤自燃的监测预测研究对防控煤自燃灾害发生具有重要意义[6]。
近年来,学者们围绕煤自燃预测相关问题提出多种预测方法,主要有测温法、自燃发火实验预测法和气体分析法等[7-9],其中气体分析法因规律性强、灵敏度高而被广泛使用[10-11]。在煤氧化升温进程中,会释放出标志性气体,通过分析这些气体的组成及含量变化情况,可以反演采空区煤炭氧化自燃程度,这类分析方法被称为气体分析法[12-14]。但是在利用多特征气体指标数据时,需要对煤自燃多特征数据进行关键特征提取融合,保障分析预测煤自燃危险性时用到的数据具有高可靠性。
近年来,学者们围绕数据融合开展了大量研究工作,所采用的方法主要有传统的数学分析法和基于机器学习的方法。数学分析方法主要有主成分分析法[15]、自适应加权平均法[16]、卡尔曼滤波法[17]、贝叶斯估计法[18]、D-S证据理论方法[19]、基于信息融合模型的广义多传感器数据融合模型[20]、基于张量的多传感器异构数据广义融合算法[21]等。基于机器学习的方法有基于卷积神经网络(Convolutional Neural Network,CNN)的多特征融合方法[22]、结合注意力机制的深度卷积神经网络方法[23]、双支卷积神经网络深度学习融合框架[24]等。这些方法在一些工业生产领域取得了较好的效果,但是在煤自燃预测领域还较少有人应用。
随着煤自燃预测技术研究的深入,采用机器学习算法预测煤自燃的状态已成为了研究的热点。机器学习方法依赖于数据的可靠性,但是因为煤自燃监测数据受井下复杂环境的影响,易存在缺失值、随机噪声和粗大噪声,直接通过多个特征进行煤自燃趋势的预测判断,会受到数据噪声和可信度差异的干扰,影响煤自燃预测精度。因此,本文提出基于多特征数据融合的煤自燃温度预测方法,选取与煤温相关性较强的O2、CO、CO2、CH4、C2H4作为煤温预测指标,通过降噪和多特征融合提升原始数据的有效性,从而提高煤自燃危险预测的精度。
1 模型构建
煤自燃标志性气体浓度变化趋势与煤温之间存在复杂的非线性关系[25],这种关系能预测出煤温的变化。为了准确地预测煤温变化,构建基于多特征融合的煤自燃温度深度预测模型,如图1所示。图1中的编码降噪层和CNN特征提取层完成了煤自燃数据的多特征融合;门限循环单元(Gate Recurrent Unit,GRU)神经网络层完成了煤自燃温度的预测;差分进化算法(Differential Evolution,DE)优化参数层采用差分进化算法对降噪自编码器和CNN的神经网络参数进行优化。

图1 基于多特征融合的煤自燃温度预测模型框架Fig.1 Prediction model framework of coal spontaneous combustion temperature based on multi-feature fusion
2 模型描述
2.1 煤自燃数据多特征融合
为了给煤自燃温度预测模型提供更可靠的特征数据,需要对煤自燃监测数据进行多特征数据动态融合,过程如图2所示。首先,采用降噪自编码器网络对煤自燃数据进行降噪;其次,采用多特征矩阵动态切片方法,将历史数据和当前数据相结合;最后,基于CNN进行特征提取与融合。具体介绍如下所述。

图2 煤自燃数据多特征融合过程Fig.2 Multi-feature fusion process of coal spontaneous combustion data
1)首先,为了增强数据的鲁棒性,对含有高噪声的煤自燃数据进行编码降噪。构造一个具有n个煤自燃监测数据样本的时间序列数据集合:X={X1,X2,...,Xn},X集合中,第i(i=1,2,...,n)元素Xi=[xtemp,xO2,xCO,xCO2,xCH4,xC2H4]分别表示第i时刻的煤自燃温度、O2、CO、CO2、CH4、C2H4气体浓度数据。
将特征样本数据中的噪声值看作异常值,然后基于降噪自编码器网络(Denoising Autoencoder,DAE),对数据集合X进行降噪处理。降噪自编码器网络结构如图3所示。

图3 降噪自编码器结构图Fig.3 Structure diagram of denoising autoencoder
DAE由编码解码过程两部分组成。编码过程(式(1))是将输入X通过隐藏层进行压缩操作,输出隐含特征向量Y;解码部分(式(2))对隐含特征向量Y进行解码重构,输出X',从而完成对高噪音数据的降噪处理。
式中:w1和w2分别为编码和解码的权重矩阵;b1和b2为偏移量;f和g为激活函数,通常使用ReLU函数、sigmoid函数、softmax函数等非线性激活函数。
2)传统煤自燃数据融合方式,通常仅对某一时刻的多特征样本数据进行特征融合,忽略了当前时刻煤温和气体浓度是相近尺度内的历史煤自燃温度和气体浓度不断累加变化的结果。为了特征融合时能包含更多历史煤自燃信息,采用数据矩阵动态切片的方法对数据进行重构。对煤自燃时间序列数据集合X以宽度为5的滑动窗口进行切片,切片过程如图4所示。
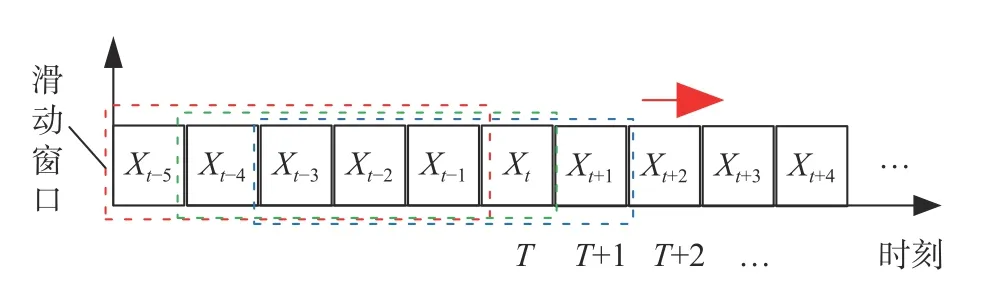
图4 煤自燃时间序列数据集合切片示意图Fig.4 Schematic diagram of time series data collection slicing of coal spontaneous combustion
3)采用CNN神经网络对矩阵切片中的重要信息进行提取。将这个全新的时间序列数据组成的特征切片作为CNN模型的输入,提取其数据特征并进行融合。
2.2 差分进化算法
为了获得更好的预测效果,采用差分进化算法(Differential Evolution,DE)对降噪自编码器和CNN的神经网络参数进行优化。DE是一种基于群体差异的模拟生物进化算法,通过对随机初始种群进行迭代的变异、交叉和选择等操作,保存适应环境的优秀个体,淘汰劣势个体,从而获得最优的神经网络参数组合。对于煤自燃数据来说,在训练降噪自编码器和CNN神经网络时,采用DE算法进行参数优化,对神经网络的初始组合参数(随机初始种群)进行迭代的变异、交叉和选择等操作,保存神经网络的输出值更贴近真实煤自燃数据特征的较优参数组合(适应环境的优秀个体),淘汰较差的参数组合,从而获得最优的神经网络参数组合。差分进化算法的操作步骤如下所述。
1)变异操作。变异操作通过差异化思想来完成个体的变异,即在种群中任意选择三个互不相同的个体向量,将其中两个个体向量的差加权后与剩下的第三个个体向量求和,通过式(3)完成变异操作。
式中:Vi(t+1)为变异个体;μ为变异因子,用于调整差分向量占比情况;Xr1(t)、Xr2(t)、Xr3(t)为t代种群中的个体矢量;r1、r2、r3为互不相同的随机正整数,且r1≠r2≠r3;Xr1(t)-Xr2(t)为差分向量差。
2)交叉操作。交叉过程就是变异个体与父代个体按照交叉概率部分交换,形成新个体的过程。将第t代种群中的每一个个体矢量Xij与变异个体Vi(t+1)根 据 式(4)进 行 交 叉,得 到 新 个 体Ui(t+1)。
式中:i或j以及k均为大于等于1的随机整数;random(j)为随机数取值范围为[0,1];Cr为交叉率,其大小控制着父子及中间体间信息交换的程度。
3)选择操作。依据个体适应环境的能力强弱,根据式(5)选择下一代更优秀个体Xi(t+1)。
式中:f为适应度函数;f(Ui(t+1))为个体Ui(t+1)对应的适应度值。
经过交叉、变异和选择操作后,得到了降噪自编码器和CNN神经网络的最优参数,从而提取到了最优的煤自燃数据特征和最好的融合效果。
为了验证融合后的数据对于煤自燃温度预测的有效性,建立煤自燃温度GRU预测模型。分别把未融合和融合后的数据输入GRU预测模型,通过预测结果的平均绝对误差来判断融合效果。
3 实验与结果分析
3.1 实验数据
实验选取陕西省某矿煤样的程序升温实验采集的指标气体(O2、CO、CO2、CH4、C2H4)和温度数据共625组。制备装煤总质量1 kg、装煤高度17 cm、平均粒径4 mm的混合煤样,升温速率为0.3 ℃/min,供风量为120 mL/min,采集频率10 min。利用程序升温装置进行加热,测定气体产物,当温度升高到预定温度437 ℃时停止加热。实验数据的缺失值采用拉格朗日插值法补足。
3.2 实验环境
实验环境配置:CPU型号为i5-6500、GPU型号为RTX1080Ti、内存容量为16 GB、操作系统为Windows、编程语言为Python-3.6、编程平台为PyCharm 2018.3.7、集成环境管理为Anaconda Navigator-1.3.1、深度学习框架为PyTorch-1.6。
3.3 结果与分析
采用降噪自编码器网络对煤自燃数据进行降噪处理,各个属性数据处理前后的对比图如图5所示。由图5可知,降噪前数据具有较强的噪声,经过降噪后,各个特征指标噪声明显降低,无毛刺现象且曲线更加平滑,符合指标气体出现的规律,更有利于煤温的预测。数据降噪后,煤温与其他指标属性之间的关系如图6所示。由图6可知,O2浓度呈现随煤温升高而逐渐减小的趋势,符合煤自燃耗氧的特性;CO和CH4浓度呈现随着煤温升高而上升的趋势由缓慢增加变至急剧增加;CO2和C2H4的浓度在煤温100 ℃以前没有明显变化,而在煤温达到100 ℃以后,气体产物浓度变化趋势陡增明显,能够用于反映煤温超过100 ℃时的剧烈氧化程度。
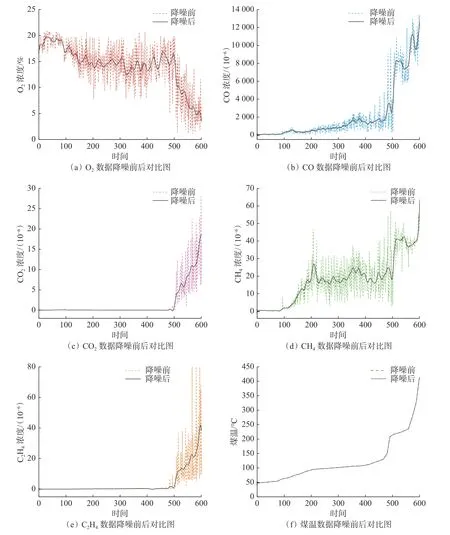
图5 编码降噪前后各个属性对比效果图Fig.5 Comparison of various attributes before and after coding denoised
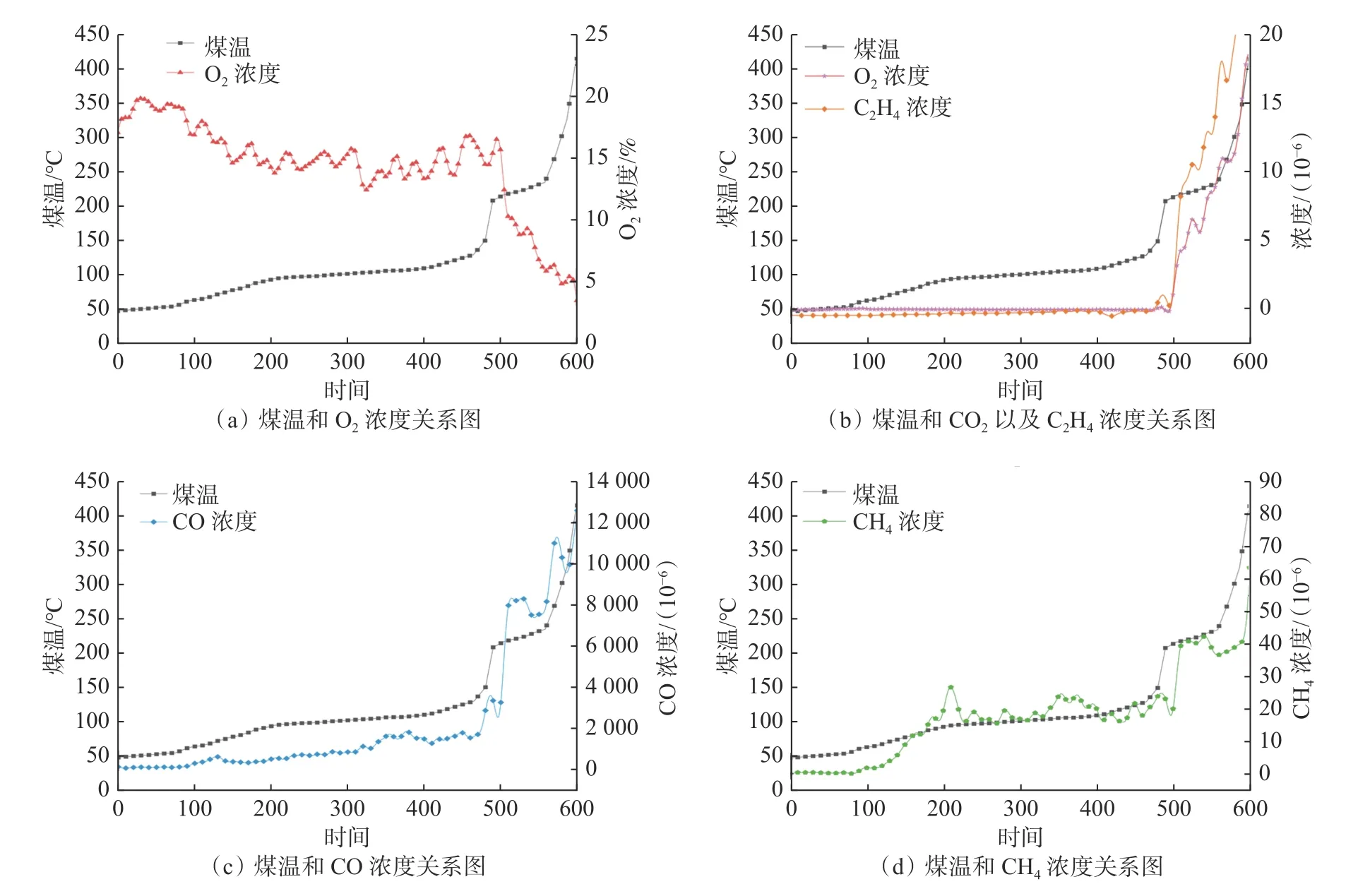
图6 煤温与其他指标性气体之间的关系Fig.6 Relationship between coal temperature and other indicator gases
为了验证基于深度学习的煤自燃多特征指标数据动态融合模型的有效性,将降噪前和降噪后多特征数据、CNN融合后的多特征数据与本文方法进行性能比较。将各组数据按照7∶3的比例划分训练集和测试集,采用GRU预测模型来验证三组数据所表征出来的特征情况,并采用平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和决定系数(R-Square,R2)等指标对预测值的结果进行评价。GRU模型的超参数:窗口大小为4,隐层数为32,损失函数选择MSELoss函数,优化器选择Adam,学习率0.001,epoch为25。数据在不同处理方式下预测误差对比见表1。

表1 数据在不同处理方式下预测误差对比Table 1 Comparison of prediction errors of data under different processing methods
由表1可知,经过降噪和本文提出的降噪融合方法处理后的数据,在同一预测模型结构情况下,预测精度有一定提升。降噪后和本文融合方法融合后的数据预测结果的MAE误差比未降噪的预测误差分别降低6.55%和69.26%,RMSE误差分别降低13.23%和63.49%,说明经过编码器降噪处理后能够提升煤自燃多特征数据的可靠性和有效性。本文融合方法融合后的数据在MAE误差和RMSE误差分别比仅作降噪处理的数据降低67.11%和57.92%,说明融合后的数据有效性进一步提高。相较于采用CNN融合数据,本文融合方法MAE误差降低了56.70%、RMSE误差降低了51.21%,说明本文融合方法融合数据好于CNN融合方法。同时在四组数据中,本文融合方法的R2值最大,说明本文融合方法融合后的数据增强了模型预测的拟合效果,提升了数据的鲁棒性。
4 结 论
针对复杂的煤自燃温度预测问题,本文提出了基于多特征融合的煤自燃温度深度预测模型,结论如下所述。
1)经过编码降噪和多特征处理后的数据,在相同预测模型结构情况下,相较于原始数据,预测精度有较大提升,说明数据经过编码器降噪处理和多特征数据融合后能够提升煤自燃数据预测的可靠性和有效性。
2)本文提出的差分进化优化的多特征融合模型,相较于未优化的多特征融合模型CNN,预测精度有一定的提升,进一步说明本文提出模型的有效性。
