基于出行时段选择的节假日免费政策优化*
2024-03-07何永明张磊曹剑
何永明, 张磊, 曹剑
(东北林业大学 交通学院, 黑龙江 哈尔滨 150040)
2012年,国务院发布《国务院关于批转交通运输部等部门重大节假日免收小型客车通行费实施方案的通知》,规定在重要节假日期间(春节、清明节、“五一”国际劳动节和国庆节)对7座及以下小型车辆实行高速公路免费通行政策。该政策推动了更多出行者在重要节假日期间选择高速公路出行[1],造成严重的高速公路交通拥堵,与方便节假日城际出行的初衷相悖[2]。节假日城际出行与工作日出行相差较大,具有明显的集中出行和潮汐现象[3]。分析节假日期间出行特征,深入研究免费政策对出行选择的影响,对制定合理节假日免费政策、减少集中出行现象具有重要意义。
城际出行特征主要包括出行时间、出行方式和出行距离等,且在节假日期间较容易受免费政策的影响[4]。因此,不少学者针对节假日免费政策和出行特征的关系展开研究,通过动态调整免费政策使出行者分散出行。由于出行特征具有离散性和随机性,现有研究多通过在离散选择上表现良好的Logit模型来模拟出行选择过程[5]。马莹莹等在传统Logit模型的基础上关注不同出行特征之间的相关性,引入考虑出行者异质性的分层Logit模型[6]。现有研究主要对出行特征的离散性进行分析,并在传统Logit模型的基础上构建出行选择模型,缺少对其他离散选择模型的探索。决策树算法在处理离散特征上具有良好的拟合度,且在出行方式选择上具有更高的识别率[7]。鉴于此,本文参考文献[8],在考虑性别、年龄、家庭人均收入和出行目的等固有出行者属性的基础上,引入免费时段为扩展属性,利用决策树算法建立出行时段选择模型,并设计多种分时段免费场景,考察各场景下出行比例的变化,选择集中出行最少的场景作为节假日免费政策优化方案。
1 数据获取和特征描述
1.1 数据获取
节假日出行数据可以分为交通流数据和出行选择数据。其中交通流数据来源于各省高速公路联网数据库,具有种类全面、数据量大等优点,方便从整体把握城际间高速公路交通流特征的变化趋势。各省交通流数据统计标准不同,本文以2019年湖南省节假日期间交通流数据(见表1)为主要分析对象,其中包含机动车当量数、车型和车辆出入路径等信息,分析免费政策对交通量的影响。
同时通过问卷调查采集湖南省2019年“五一”期间出行选择数据,分析出行者属性和免费政策对出行选择的影响。问卷中出行者属性包括性别、年龄、家庭人均年可支配收入、是否拥有汽车、出行目的和出行方式,同时统计出发日期选择、出发时段选择、返程日期选择和返程时段选择[9]等出行选择属性。共收集有效调查问卷635份作为数据样本,出行者属性见表2。本次调查中拥有汽车的受访者高达73.43%,样本反映了节假日期间受免费政策影响的主要出行群体。

表1 交通流数据

表2 出行者属性
1.2 数据特征
2019年“五一”期间高速公路免费日期为5月1日0:00—5月4日24:00,为全面分析节假日出行时段选择特性,采集“五一”前后各3 d共6 d的出行选择数据,各日期出发和返程时段选择见图1、图2,将出行时段选择比例(该时段出行人数/总人数)作为评估参数,热度由低到高通过不同颜色表示。
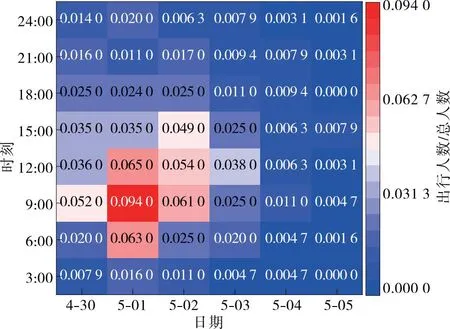
图1 出发时段选择热力图

图2 返程时段选择热力图
由图1、图2可知:“五一”出行具有明显的集中现象,出发时段集中于6:00—12:00,返程时段集中于9:00—15:00。出行选择受主观因素影响较大,可结合交通流数据进一步分析免费政策对节假日出行影响的显著性。
2 免费政策影响分析
2.1 分析步骤
单因素方差分析法常用于讨论被检测样本和参考样本之间的差异性[10],具体参数见表3。利用单因素方差分析法探究免费政策和出行时段选择的关系,只改变高速公路免费政策,其余因素在设计状态下保持不变。通过对比F值和其在概率值α下的分位数,判断免费政策的影响显著性[11]。

表3 方差分析参数
总样本共有r个水平,各出行者可抽象成相同分布的样本xij。每一水平下样本个数为n个,对不同水平下样本观测值进行计算,得总离差平方和SSST、组间平均离差平方和SSSA和组内平均离差平方和SSSE如下[12]:
(1)
(2)
SSSE=SSST-SSSA
(3)
SMSA、SMSE表示各状态下样本的均方和,其值为:
SMSA=SSSA/(r-1)
(4)
SMSE=SSSE/(n-r)
(5)
F值按式(6)计算。如果观测值满足F≥F(1-α)(r-1,n-r),则免费政策的影响显著。
F=SMSA/SMSE
(6)
2.2 分析结果
结合采集的交通流数据,选择春节、清明节、“五一”国际劳动节和国庆节4个法定节假日中5个不同日期交通量作为观测样本,以正常收费下工作日交通量作为参照样本,则水平数r=5。各样本中数据项数量ni为5,交通量分布见表4。

表4 样本交通量分布 单位:万辆/d
将表4中各样本交通量代入式(1)~(6),利用SPSS软件对不同样本下交通量进行方差分析,结果见表5。
表5描述了各样本交通量之间的差异性,其中组间平方和反映每组均值与总均值之间的离差,由免费政策变化所引起;组内平方和又称误差平方和,由随机误差所引起。查询F检验临界值表,F=12.856时显著性水平远小于0.05,表明免费政策对节假日交通量分布具有显著影响。因此,有必要在建立出行时段选择模型时添加免费政策作为特征参数。
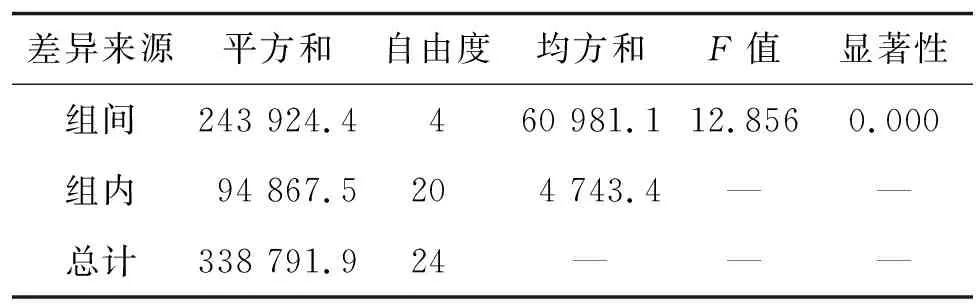
表5 方差分析结果
3 模型构建
3.1 模型结构
决策树算法是一种不断逼近离散函数值的方法,在处理数据后归纳特征生成可见决策树,然后使用决策树对新的测试样本进行分类[13]。选择决策树算法作为出行时段选择模型的理论框架,对不同决策属性赋予对应权重,根据权重大小确定关键属性,再对关键属性的不同特征值下其他决策属性的权重重新赋值。将上述决策过程通过树状图表示,生成图3所示决策树结构。

图3 决策树结构图
由图3可知决策树结构具有以下特点:1) 决策树由节点和有向边组成,节点为关键决策属性,有向边代表各属性的特征;2) 节点有内部节点和叶子节点两种形式,内部节点为决策属性,叶子节点为最终决策类别,即所选择的出行时段;3) 各属性在一条决策路径中只出现一次;4) 每条决策路径的属性个数不确定,可为1~n中任一数值[14]。
根据决策树结构,构建出行时段选择模型须解决3个关键问题:1) 变量划分,即确定决策属性和特征值;2) 决策路径生成,即确定关键属性和路径划分函数;3) 模型优化,即对决策树剪枝,提高模型的拟合优度。
3.2 变量划分
构建模型所需的决策属性包括免费政策、出行者属性和出行选择属性。其中:免费政策作为扩展属性可多次改变;出行者属性与表2中各属性的数据描述一致,可作为观测值反映决策路径变化;出行选择属性为出行选择时段,以3 h为时间间隔,时间分布与“五一”期间出行选择数据一致。为避免模型将特征值较多的属性识别为连续变量,对出行者属性和免费政策进行哑变量处理,结果见表6。
3.3 决策路径生成
决策路径生成的主要任务是选择各属性的不同特征进行分类,并确定下一层次属性值。利用Python编程语言导入样本数据,并通过Sklearn模块中DecisionTreeClassifier类构建决策树,重要参数的默认设置见表7。
基尼指数G是确定关键属性和划分路径的重要指标,其原理见式(7)。基尼指数越小,分类结果越好,指数值最小的特征可作为决策路径,并用于确定下一层次关键属性。
(7)
式中:n为出行者数量;pk为关键属性k选择某条决策路径的概率。
最小不纯度K是一种阈值,可限制决策树的增长,若不纯度高于最小不纯度,则继续划分下一路径,反之停止增长。不纯度可由信息熵表示,计算过程见式(8)。属性k的不纯度越低,信息熵越大。利用信息熵限定决策树的增长,可以减少干扰路径,使出行时段划分更准确。
(8)
式中:i表示关键属性k的具体特征;I为包含该属性的所有特征值。
将出行时段以3 h为间隔划分成8组,对拥有多个属性的出行者X,通过迭代计算基尼指数和最小不纯度K确定路径决策顺序Q={q1,q2,q3,…,qm},生成一棵最大深度≤m的二叉树,流程见图4。
决策树中节点数量由基尼指数和最小不纯度K共同决定,除叶子节点外,每层节点均对应两个不同的下级属性。先利用基尼指数确定属性名称,再对比属性值和最小不纯度K的大小;若属性值大于K,则计算该属性权重,并继续获取下一个属性;反之保持K值不变,重新选取基尼指数最小的属性。决策树中叶子节点为可选择的出行时段J,J={j1,j2,j3,…,jn},每个出行者最终只选择一个出行时段。
3.4 模型优化


图4 决策路径生成流程
(9)
决策树最大深度线性增加时,R2的变化见图5。由图5可知:随着决策树最大深度的增加,拟合优度R2呈上升趋势。决策树最大深度增加至14时,决策树的叶子节点为单一出行时段,不再继续生成决策树,R2停止增长。此时出发时段选择拟合优度为0.417,返程时段选择拟合优度为0.324,表明该模型对出行时段选择具有较好的拟合效果。
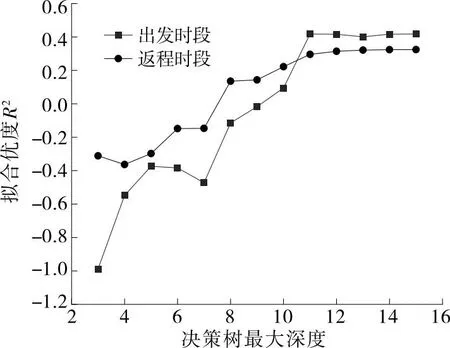
图5 R2-决策树最大深度折线图
针对上述出行时段选择模型,通过对决策树进行剪枝避免出现过拟合现象。将样本数据按7∶3的比例划分为训练集和测试集,采用后剪枝方法,在建立决策树后由下而上提高模型稳健性。剪枝后评估标准包含精确度Mprecision、召回率Rrecall及F1分数。假设测试集中出行时段可分为时段A和时段B,则出行时段分类评估参数见表8,其中:TS与TO代表算法预测时段与实际出行时段一致,分别为A类和B类;FO代表算法预测时段为B,实际出行时段为A;FS代表算法预测时段为A,实际出行时段为B。TS、FO、FS、TO共同决定剪枝后模型的评估标准。

表8 出行时刻分类评估参数
精确度反映预测结果中预测正确的比例,按式(10)计算。召回率反映原样本数据中被正确预测的比例,按式(11)计算。F1分数用于平衡精确度与召回率,按式(12)计算,F1越接近1,模型的稳健性越强。
(10)
(11)
(12)
式中:QTS、QTO为算法预测时段与实际出行时段一致的样本数;QFO为算法预测时段为B,实际出行时段为A的样本数;QFS为算法预测时段为A,实际出行时段为B的样本数。
利用剪枝后的决策树模型重新训练测试集,得到表9所示出行时段选择。由表9可知:剪枝后的决策树模型拟合精确度和召回率的加权平均值均不小于0.70,且F1分数分别为0.70、0.71,表明该模型可以平稳预测出行时段选择,且精确度较高。
4 免费场景仿真分析
4.1 分时段免费场景设计
调整高速公路免费政策,将全天免费改为分时段免费,收费标准与既有政策一致。采用场景仿真法设计不同收费组合并进行仿真分析,对比不同场景下各时段出行比例的变化。考虑到出行的连续性和时段划分的一致性,将每日以3 h为一时间段分成8组,并依据日升、日中、日落划分6种免费时段。免费场景设计如下:场景1为在节假日期间对所有时段均收费;场景2、场景3分别表示在白天和夜间收费;场景4、场景5、场景6在场景2的基础上对时段进行进一步划分,分别在6:00—12:00、9:00—15:00、12:00—18:00 3个时段收费(见图6)。
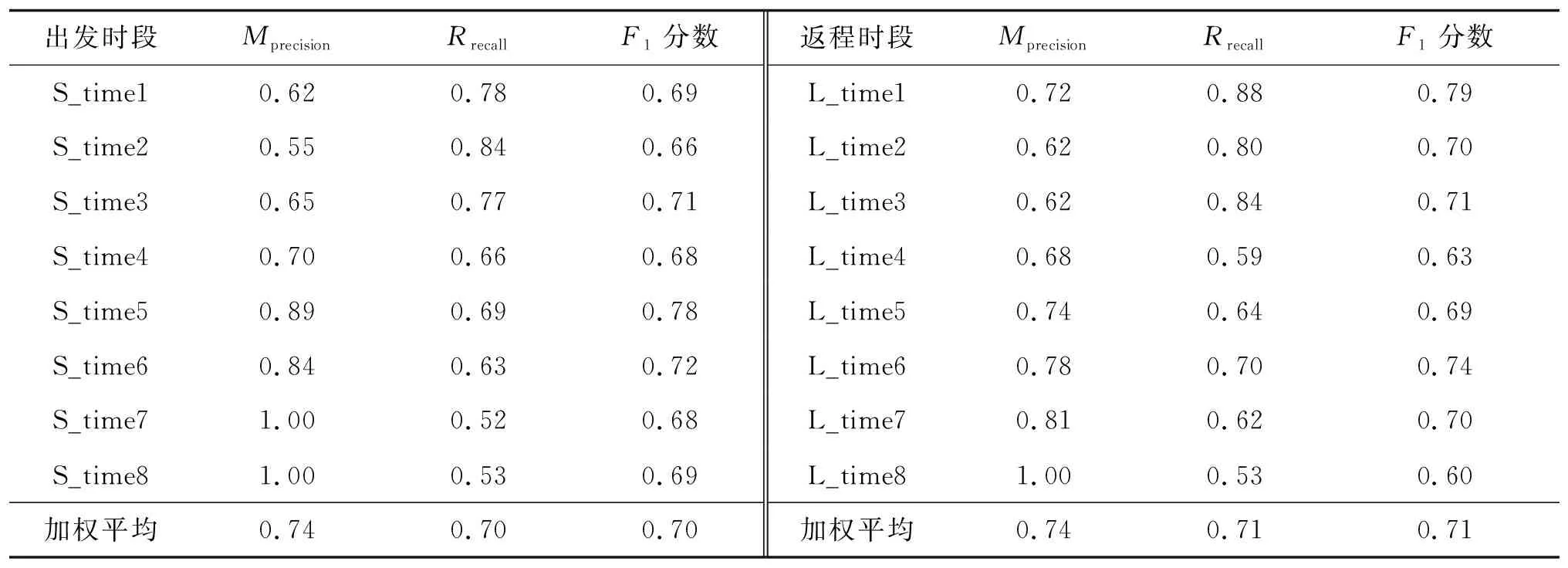
表9 剪枝决策树分类结果

图6 免费场景设计
4.2 场景仿真结果
根据模型优化结果,选择拟合优度较高且最大深度为14的剪枝后决策树模型,以既有节假日政策为参考场景,结合图6中各免费场景,改变模型属性即免费政策的特征值进行仿真分析。根据仿真结果统计不同场景各时段出行比例,通过最大出行比例反映集中出行状况,结果见表10。
最大比例可反映对应场景的集中出行状况。由表10可知:不同收费时段的影响不同,单一的免费政策无法确保减少最大出行比例。例如在场景6中对12:00—18:00时段(组合5、6)收费,更多的出行者选择在其他时段出行,导致最大出行比例增加。综合出发和返程场景下最大出行比例,场景2下集中出行现象最少。

表10 不同场景下最大出行比例
结合图1、图2,选择集中出行人数最多的5月1日和5月3日对场景2各时段出行比例进行统计,结果见图7。

图7 场景2出行时段选择比例
由图7可知:出行选择比例最大的时段为6:00—9:00。与参考场景相比,由于白天对高速公路车辆进行收费,选择夜间出行的人数增多,高峰小时出行比例下降。因此,节假日期间在6:00—18:00时段对高速公路进行收费,并对夜间其余时段免费通行,可有效缓解因集中出行导致的交通拥堵。
5 结论
把握出行时段选择特征是制定和评价节假日高速公路免费通行政策的重要前提。本文通过构建基于决策树算法的出行时段选择模型,利用场景仿真法讨论不同免费时段对集中出行的影响。结果表明,节假日高速公路免费通行政策对出行选择具有显著影响,导致高速公路交通量增加和潮汐出行;基于决策树的出行时段选择模型可以综合考虑免费政策、出行者属性和出行选择属性,较好地拟合出行决策;不同收费时段的影响差异较大,在6:00—18:00时段对高速公路进行收费可以有效减少集中出行。
该模型主要对免费时段进行讨论,缺少对交通方式及出行距离的联合分析。可综合考虑不同里程收费对交通方式分担率的影响,更全面地分析节假日高速公路免费通行政策的优化方向。
