基于ESSA-LSTM 的养殖工船水质溶解氧预测方法研究
2024-03-06洪永强谢永和刘鲁强董韶光李德堂王云杰姜旭阳张佳奇高炜鹏
洪永强,谢永和,刘鲁强,董韶光,李德堂,王云杰,姜旭阳,张佳奇,王 君,高炜鹏,陈 卿
1. 浙江海洋大学 a. 船舶与海运学院,b. 海洋工程装备学院,浙江 舟山 316022
2. 青岛国信发展 (集团) 有限公司,山东 青岛 266200
3. 中国水产科学研究院渔业机械仪器研究所,上海 200092
4. 国信中船 (青岛) 海洋科技有限公司,山东 青岛 266200
随着水产养殖业的迅速发展和养殖规模的不断扩大,精准预测和监测水质参数对于保障养殖效益[1]和生物健康变得至关重要。然而,现今水产养殖业面临着许多挑战,维持良好的水质环境便是其中之一。在养殖系统中,溶解氧[2]是一个非常重要的水质参数,溶解氧不足可能导致鱼类窒息、生长受限甚至死亡。传统的溶解氧测量方法需要采集水样在实验室进行分析,这种方法耗时久、成本高,且无法提供实时监测数据。随着养殖方式向深远海[3]养殖工船发展,对养殖水质的要求日趋严格,溶解氧的精准预测变得越来越重要。近年来,大数据和机器学习技术[4]为溶解氧预测提供了新的解决方案,可以利用历史监测数据和水质参数建立预测模型,准确预测溶解氧浓度。这些模型可以基于气象、水质、养殖方式和其他相关因素进行训练,能及时响应环境变化和养殖条件调整,以维持良好的水质环境,从而促进鱼类健康生长。
精准预测溶解氧对水产养殖意义重大。近年来,国内外学者对水质预测进行了广泛研究,并对提高预测精度的方法作了改进。沈时宇和陈明[5]采用一种Prophet 时序模型的方法来提高水质预测精度,但该方法存在模型训练欠拟合缺陷。Ren 等[6]选择基于深度信念网络的溶解氧预测模型,成功实现了溶解氧含量预测。Cao 等[7]提出了基于K均值聚类和GRU (Gate Recurrent Unit) 神经网络的池塘养殖溶解氧预测模型,该方法虽然提高了预测精度,但GRU 神经网络仍无法完全解决梯度消失问题,且随着数据量和模型规模的增加,效果不理想。此外,研究者还探索了其他方法。宦娟等[8]提出了一种基于集合经验模态分解、游程检测法重构、适宜的单项预测算法建模和BP 神经网络非线性叠加的组合预测模型,但在高频分量波动较大的情况下,该算法参数难以确定,预测效果不佳。林彬彬等[9]提出基于麻雀搜索算法 (Sparrow Search Algorithm, SSA)[10-11]和长短期记忆神经网络 (Long Short-Term Memory, LSTM)[12]的黄鳝 (Monopterus albus) 池塘溶解氧浓度预测模型,该模型具有良好的准确性和鲁棒性,但仍存在局部最优解问题,导致模型参数的准确性不高,进而降低了预测的准确性。
当考虑到模型参数的后期优化时,通常会使用算法代替人工参数设置。为解决这一问题,本研究采用了两种启发式算法—麻雀搜索算法和海洋捕食算法 (Marine Predators Algorithm, MPA)[13],以及两种群体智能算法—灰狼优化算法 (Grey Wolf Optimizer, GWO) [14]和鲸鱼算法 (Whale Optimization Algorithm, WOA)[15]。这些算法在全局搜索和多模态问题的处理上均表现出色,并且在不同领域有成功的应用。基于这些算法的特点及其在应用领域的成功案例[16-19],本文比较了这些算法在LSTM模型中进行参数优化的效果,并通过优化模型参数实现既定目标。
为了提高溶解氧参数预测的准确性,本文提出了一种增强型麻雀搜索算法 (Enhance Sparrow Search Algorithm, ESSA) 用于优化LSTM 模型参数,更好地调整模型的结构和初始状态,以满足溶解氧参数的预测需求,从而提高预测结果的精确度。
1 材料与方法
1.1 数据来源
本文用于验证模型的数据来源于某养殖工船,其相关信息为:全长249.9 m,型宽14 m,型深21.5 m,排水量130 000 t,航速10.6 kn,养殖水体90 000 m3,单舱水体6 000 m3,定员3 人,年产量370 t,总投资4.5 亿元。该工船在福建宁德海域养殖大黄鱼 (Larimichthyscrocea),传感器布置于鱼舱内深度14 m 处,采集数据开始时间为2023-04-11 00:05:00,结束时间为2023-04-24 00:00:00。采集数据的步长为5 min。一共有3 745 组数据。选取MPS-400 多参数传感器进行数据采集,该传感器具有自清洗、多参数测量、信号输出协议为Modbus特点,安装传感器的方式为投入式。采集pH、温度 (℃)、盐度 (‰)、溶解氧 (mg·L−1) 4 类参数。本文中水质预测目标为溶氧,水质特征变量为pH、温度、盐度。表1 为养殖水质参数溶解氧的原始数据,图1、图2 分别为养殖工船场景和原始数据溶解氧的变化曲线。

图1 养殖工船内部Fig. 1 Inside aquaculture ship
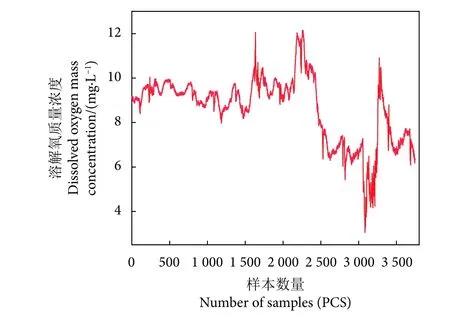
图2 原始数据溶解氧变化曲线Fig. 2 Change curve of dissolved oxygen in raw data

表1 养殖水质原始数据表Table 1 Raw data sheet for aquaculture water quality
1.2 研究方法
1.2.1 数据处理
1) 数据预处理。采集的数据,可能会因数据传输异常等导致丢失,需要对数据作预处理,对缺失的数值需要通过线性插值进行填补,公式如下:
式中:xk表示需要填补的值;xf表示前一个非缺失数据点的值;xb表示后一个非缺失数据点的值;f和b分别表示前后非缺失数据点的索引。
数据归一化[20]是将不同特征的数据按照一定规则进行缩放,以消除特征之间的量纲差异,使得不同特征具有相同的尺度。本文使用Min-Max 归一化的具体表达式如下:
式中:xmax表示样本数据最大值;xmin表示样本数据最小值;xi表示样本数据中的第i个数据;xnor表示归一化后的数据。在经过归一化的训练和测试后,为了得到真实的预测结果,需要对预测值进行反归一化,将其重新映射回原始数据的范围。
2) 数据集的划分。首先将采集到的数据划分为训练集和测试集,本实验是将前12 d 的数据作为训练集,最后1 d 的数据作为测试集。使用训练集来训练模型,使用测试集评估模型在未见过的数据上的性能。
1.2.2 长短时记忆网络
为了有效捕捉具有长期依赖关系的序列数据,如连续时间上测得的溶解氧参数,传统的神经网络模型往往无法提供令人满意的结果。为解决该问题,长短时记忆网络被引入并广泛应用。LSTM 是一种特殊的循环神经网络 (Recurrent Neural Network, RNN)[21],专门设计用于处理序列数据。LSTM 与其他神经网络模型之间的区别在于独特的内部单元结构 (图3)。
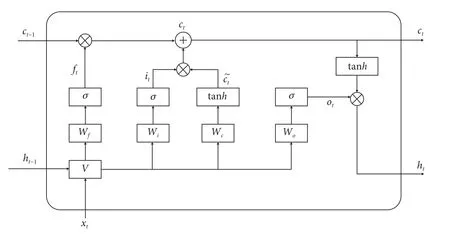
图3 LSTM 内部单元结构Fig. 3 Internal unit structure of LSTM model
图3 中,f、i、o分别表示遗忘门、输入门、输出门;σ表示全连接层。xt是t时刻的输入,ct−1和ct分别表示上一时刻和这一时刻的输出,˜ct为t时刻候选记忆细胞的信息,ht−1、ht分别表示为上一时刻和这一时刻隐藏状态的信息,tanh为激活函数。
3 个门的更新计算公式为:
式中:W和b分别表示网络的权重矩阵和偏置向量;σ(x)是Sigmoid 激励函数,为平滑的阶梯函数。它可以将任何值转化为0~1,此函数的输出介于0~1,代表具体有多少信息能够流过Sigmoid层,0 表示不能通过,1 表示能全部通过。
1.2.3 ESSA-LSTM 预测模型
水质参数溶解氧受多种因素的影响,由于数据采集于养殖工船,其空间特征是一定的,因此本文仅考虑水质中的pH、温度、盐度对溶解氧的影响。为了更好地预测溶解氧,引入长短时记忆网络,并针对该网络模型中存在的参数问题引入增强型麻雀搜索算法进行改进。在基本的LSTM 模型中,权重和偏置是通过矩阵乘法和加法来更新的,而在本文使用的LSTM 模型中,参数的更新是通过训练过程中的反向传播和优化算法来实现。增强型麻雀搜索算法优化LSTM 模型结构如图4 所示,模型流程如图5 所示。

图5 预测模型流程Fig. 5 Flowchart of predictive modeling
在LSTM 模型中,隐藏层神经元个数是影响模型性能关键性的超参数。本文在LSTM 模型的训练模型中引入了Adam (Adaptive Moment Estimation)梯度下降[22]算法,为此,该算法的初始化学习速率也成为影响模型性能的关键。通过采用增强型麻雀搜索算法,来确定隐藏层的神经元个数和初始化学习速率。具体步骤如下:
1) 初始化参数,将数据进行归一化处理,并且将数据分为训练集和测试集。
2) 确定LSTM 模型的拓扑结构。
3) 通过增强型麻雀搜索算法对LSTM 模型参数进行优化。
4) 利用优化后的参数建立LSTM 模型和训练神经网络模型。
5) 将训练集和测试集数据来对建立好的模型进行实验和验证,并通过模型评价指标来评价模型的预测效果。
1.2.4 模型评价标准
通过平均绝对误差 (Mean Absolute Error,MAE)、平均绝对百分比误差 (Mean Absolute Percentage Error, MAPE)、均方根绝对误差 (Root Mean Square Error, RMSE)和决定系数 (Coefficient of Determination,又称R2值) 对各个模型的预测效果进行评判其表达式如式 (4)、 (5)、 (6) 和 (7) 所示:
式中:yi表示实际值;xi表示预测值;表示实际值的平均值;n表示样本个数。当MAE、MAPE和RMSE 越小时,所建模型的预测效果越好;R2值越接近1,表明模型对数据的拟合程度越高。
1.2.5 基本麻雀搜索算法
在麻雀[23-26]捕食过程中,分为侦察者和跟踪者两个群体。侦察者负责在整个区域进行觅食和引导跟踪者觅食的方向,而跟踪者负责追随侦察者进行觅食。当危险来临时,麻雀种群会做出反捕食行为。
在每次迭代的过程中,侦察者的位置更新如下:
式中:t表示迭代的次数;表示迭代t次时第i只麻雀的第j维数的值;表示迭代t+1 次时第i只麻雀的第j维数的值; itermax表示迭代次数最多的一个常数;α为介于0~1 的一个随机数;R2表示报警值,范围在 0~1;ST 表示安全阈值,范围在0.5~1;Q是一个服从正态分布的随机数;L表示1 ×d的矩阵,其中,d矩阵的元素全为1。
跟踪者的位置更新如下:
式中:Q是一个服从正态分布的随机数;Xp表示侦察者处于一个最佳的位置;是在迭代t+1 时点上的全局最优解;而表示当前处于全局最差的位置;A是一个1 ×d的矩阵,里面的元素随机分配为1 或−1,并且满足A+=AT(AAT)−1;n代表麻雀的数量,当i>n/2 表示适应值比较差的第i个跟踪者觅食能力低,捕获的食物比较少;otherwise代表其他情况。
当危险来临时,麻雀会做出预警行为,其预警者位置更新如下:
式中:β表示步长控制参数,是一个均值为0、方差为1 的正态随机分布;K是一个随机数,其范围是 −1~1,表示麻雀移动方向的步长控制系数;fi表示当前麻雀的适应值;fg则是当前全局的最佳适应值;fw表示当前全局的最差适应值;ε是一个极小的常数,避免分母出现0 的情况。
1.2.6 增强型麻雀搜索算法
1.2.6.1 Circle 混沌映射初始化种群
混沌映射[27]是指在非线性系统中产生混沌行为的一种数学映射,常见的混沌映射方法有Logistic 混沌映射、Henon 混沌映射、Tent 混沌映射和Circle 混沌映射,不同的混沌映射有其自身的特点,由于Circle 混沌[23]算法易于实现,且具有周期性和可控性,其表达式如下:
式中:mod 代表取余;xi表示当前迭代的值;xi+1表示下一个步骤迭代的值。基本的SSA 算法是采用随机生成的方式来初始化种群,这就导致了分布不均匀的问题,为此,可以使用Circle 混沌映射的方式来初始化种群。
1.2.6.2 正弦余弦算法对侦察者位置优化
麻雀搜索算法中侦察者位置更新主要依赖于个体之间的位置调整和信息共享,这也就导致了侦察者无法探索整个搜索空间,难以跳出局部最优解。针对该问题,引入了正弦余弦算法[28]对麻雀搜索算法中的侦察者位置进行更新,在该算法中,加入了非线性正弦学习因子如公式 (12) 所示,优化后的侦察者位置如公式 (13) 所示:
式中:ωmin和ωmax表示惯性权重的最小和最大值;ω表示适应权重值;itermax表示迭代次数最多的一个常数;r1为 0~2π 内的随机数;r2是 0~2 内的随机数;Xbest表示群体中最佳的位置; Xti,j表示迭代t次时第i个麻雀的第j维数的值。
1.2.6.3 Levy 飞行策略对跟踪者位置优化
由于在麻雀搜索算法中,跟踪者的位置更新主要依赖于当前最佳位置和全局最佳位置,使得算法在搜索空间中的多样性不足,从而限制了算法的全局搜索能力。并且当全局最佳位置附近存在较多的最优解时,算法容易陷入局部最优解而无法跳出。为此,本文提出通过引入Levy 策略[29-30]对跟踪者的位置进行更新,Levy[31]步长向量生成公式如下:
式中:S为飞行路径;Γ 为 gamma 函数;β取值为1.5;σ代表正态分布中的方差;u和v是符合正态分布的随机数,uN(0,σ2) ,vN(0,1),则跟踪者位置更新公式如下:
增强型麻雀搜索算法具体流程如下:
1) 设置参数:设置最大的迭代次数,麻雀的种群数量,每个维度上的变量最小值,每个维度上的变量最大值。
2) 初始化麻雀种群位置、优化全局最优个体和最优适应度,计算每个个体的适应度并且对其进行排序。
3) 在每次迭代的过程中,利用公式 (13) 更新侦察者的位置,实现对全局的搜索,并且进行边界检查。
4) 使用公式 (16) 更新跟踪者位置,使得跟踪者不断靠近侦察者位置。
5) 如果预警者发现危险,则通过公式远离危险位置。
6) 在麻雀搜索食物之后,对麻雀个体的最优适应度值进行排序。
7) 更新全局最优解和最佳适应度。
8) 进入循环迭代,转至步骤3)。
9) 判断是否符合中止条件,若符合,则输出全局最优解和最佳适应度。若不符合,回到步骤3) 重新开始计算。
2 实验与分析
2.1 基准函数优化性能测试
为了验证增强型麻雀搜索算法在求解优化过程中的可行性和优越性,将ESSA 与SSA、GWO、MPA、WOA 算法在5 种基准函数上进行测试对比。
使用Matlab 2019b 软件对5 种不同的算法进行对比实验,为了避免实验出现的偶然性造成误差,并增加实验的准确性,选取5 种基准测试函数分别独立运行30 次,取平均值和标准差作为实验的评价标准。实验采用的基准测试函数如表2 所示,F1和F2为高维单峰函数,F3和F4为高维多峰函数,F5为低维多峰函数。种群大小为40 个,最大迭代次数为100 次。实验结果如表3 所示,优化测试函数收敛曲线对比如图6 所示。

图6 优化测试函数收敛曲线对比Fig. 6 Comparison of convergence curves for improved test functions
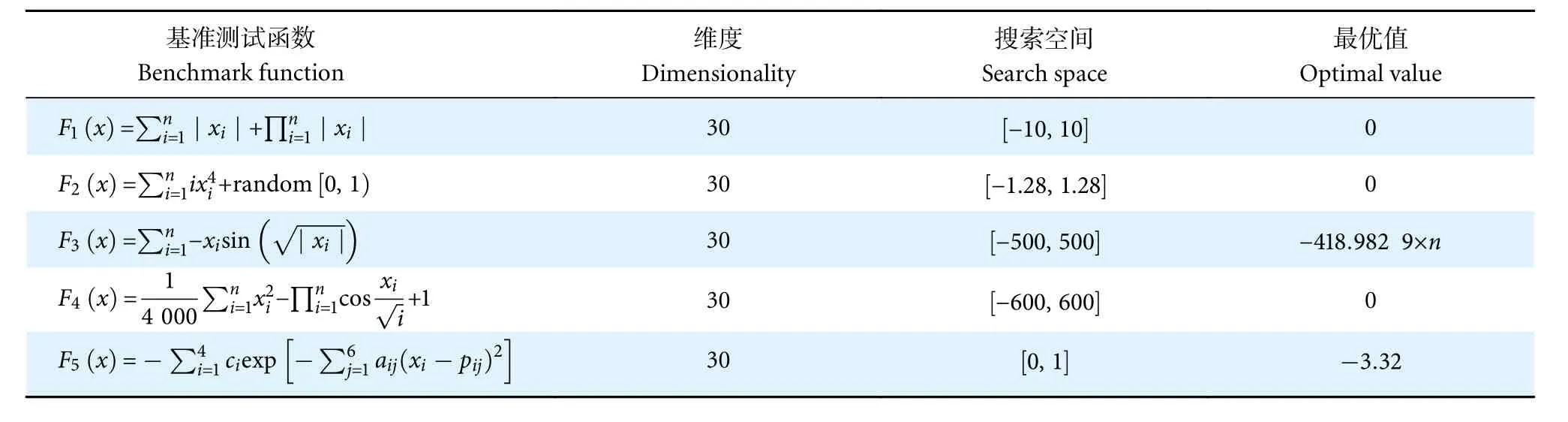
表2 基准测试函数Table 2 Process of benchmarking
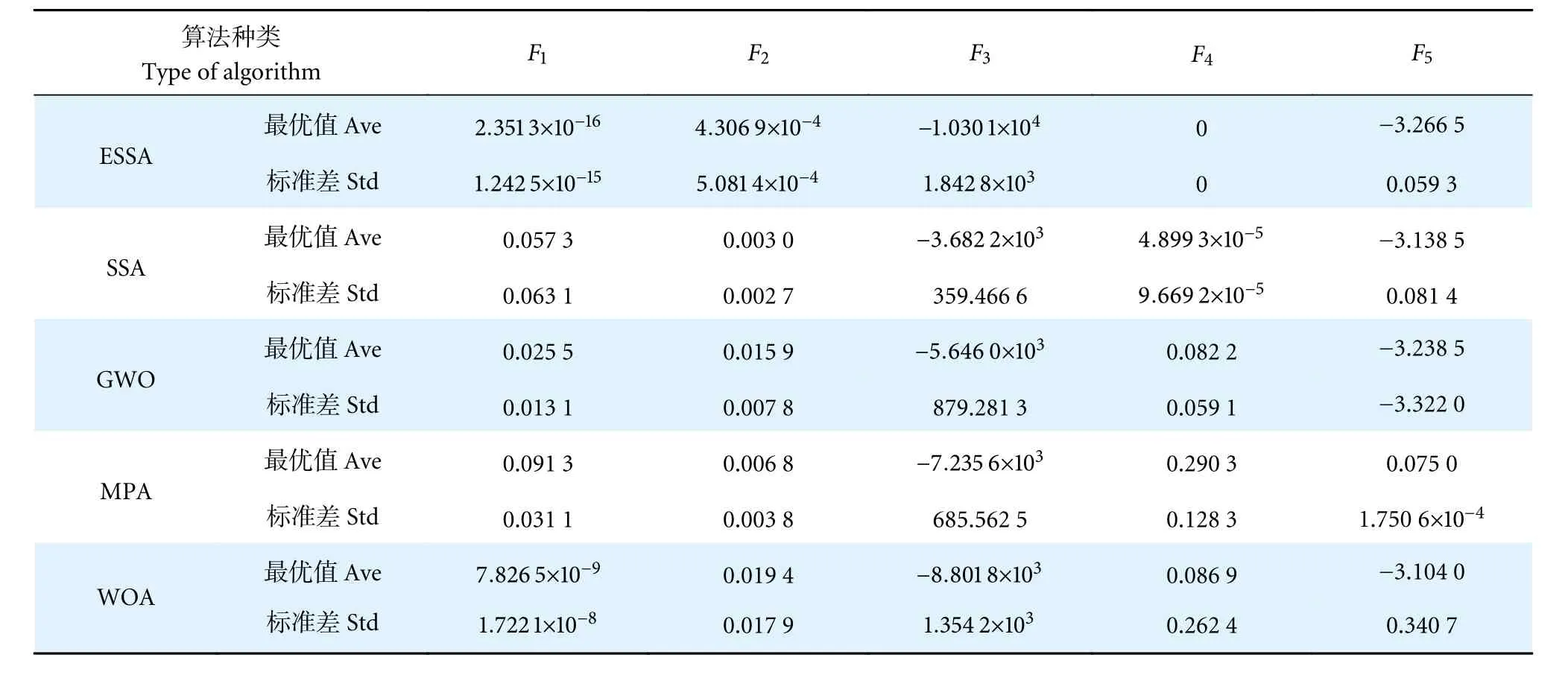
表3 基准函数优化结果对比Table 3 Comparison of benchmark function optimization results
根据表2 中各种算法的最优值 (Ave) 和标准差(Std) ,可以看出ESSA 算法尽管在低维多峰函数上的性能差异和其他算法相差无几,但是在高维单峰、高维多峰函数上的性能均优于其他算法。由图6 也可以明显看出,ESSA 算法在收敛性和优化结果方面比其他4 种算法的表现更佳。针对F1和F2高维单峰函数的收敛情况,不论迭代次数增加到何种程度,使用ESSA 算法获得的最优值始终优于其他算法。此外,在经过100 次迭代后,ESSA算法获得的最优值数量级明显高于其他算法。对于F3和F4高维多峰函数而言,ESSA 算法的最优值优于WOA 和MPA 算法,且最优值几乎是后两种算法的2 倍。这表明ESSA 算法在处理高维多峰函数时优势明显。在F5低维多峰函数中,虽然ESSA 算法的最优值相对于其他算法没有明显的优越性,但仍取得了显著的改进效果。
综上,可以得出ESSA 算法在收敛结果和优化效果方面比其他算法表现出色,为进一步研究和应用ESSA 算法提供了有力的支持。
2.2 预测准确率优化实验
2.2.1 实验设置
为了验证ESSA 算法对LSTM 模型参数改进的效果最佳,选取基本的SSA 算法、GWO 算法、MPA算法、WOA 算法分别对LSTM 模型改进进行对比。为了保证实验的准确性和算法对比结果的可信度,实验均采用Matlab 2019b 软件进行,几种算法的实验参数一致,且每种算法的仿真实验独立运行10 次然后取平均值。在实验过程中,每种算法中寻找最优解隐藏层的神经个数范围均设置为0~100,初始速率范围设置为 0~0.2。
2.2.2 优化对比
表4 是实验设置的主要参数,各算法独立运行10 次优化后的平均预测率结果对比如表5 所示。各算法实验得出的平均绝对误差 、均方根误差、平均绝对百分比误差和决定系数的评价指标如图7 所示。根据实验所得的平均绝对百分比误差,得到ESSA、SSA、GWO、MPA 和WOA 算法优化的预测率收敛曲线如图8 所示。

图7 模型评价指标Fig. 7 Indicators for model evaluation

表4 参数设置Table 4 Settings of parameters
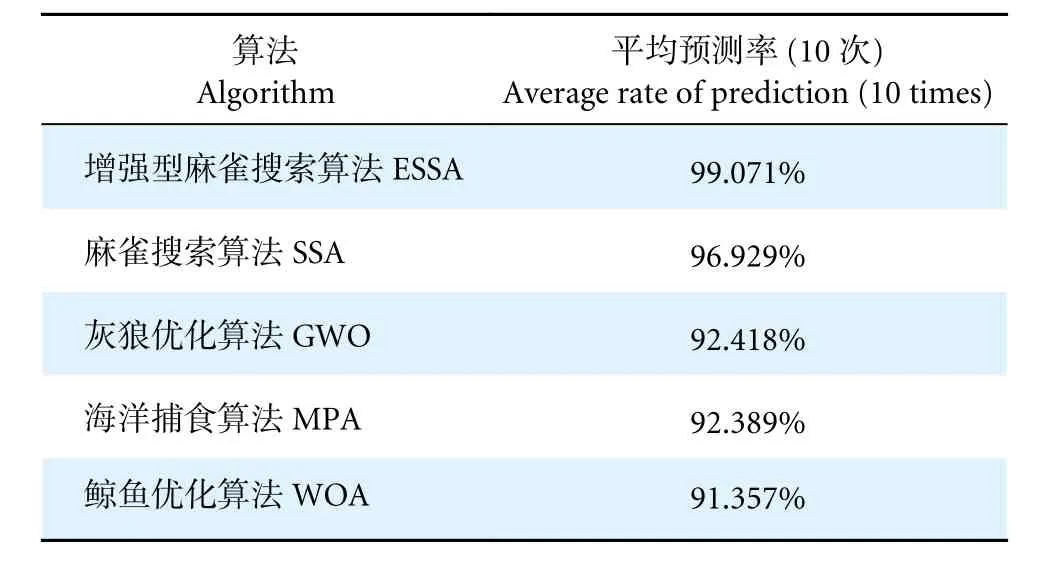
表5 预测率结果对比Table 5 Comparison of predicted rate
从表5 可以直观的看出,在同样的实验环境和参数下,ESSA 算法对于优化改进LSTM 模型参数得出来的预测率具有明显的效果。ESSA 算法优化改进效果略好于基本的SSA 算法,但是由ESSA 算法改进得出的预测率准确性远远大于GWO、MPA 和WOA 算法所改进的。
从图7 可以清晰地看出,ESSA 算法在MAE、RMSE 和MAPE 指标方面均表现出优于其他4 种算法的结果。此外,虽然SSA 拟合的效果所对应的R2值也接近1,但是稍逊于ESSA,这进一步说明了ESSA 算法在预测准确率方面表现出卓越的效果,即ESSA 算法具有最佳的预测性能。
由图8 可以看出,ESSA 算法在初始迭代阶段就避免了陷入局部最优解的问题,因为在初始迭代时预测准确率显著提高,且在大约10 次迭代后便达到最优解。相比之下,SSA 算法在初始迭代时的预测准确率虽然远高于MPA 算法,但在第80 次迭代时已经陷入了局部最优解。从GWO 算法的结果可以看出,随着迭代次数的增加,预测准确率趋于稳定,约70 次迭代后达到稳定效果。然而,与ESSA 和SSA 算法相比,GWO 算法的最终结果并不理想。WOA 算法在初始迭代阶段的预测效果较差,但随着迭代次数的增加也趋于稳定,明显可以观察到该算法的最终效果低于其他算法。
通过ESSA 算法对LSTM 模型参数寻优,可以得到隐藏层的神经个数为17,初始学习速率为0.008 6。多种算法优化曲线对比如图9-a 和图9-b所示。
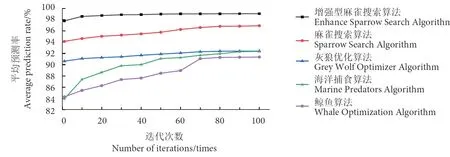
图8 预测率收敛曲线Fig. 8 Convergence curve of prediction rate
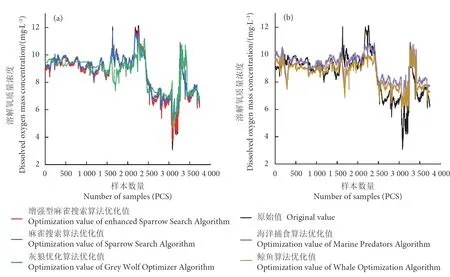
图9 多种算法优化曲线对比Fig. 9 Comparison of optimization curves for multiple algorithms
根据各种算法的仿真实验结果,可以看出ESSA 算法具有收敛速度快、强大的跳出局部最优解的能力等特点。通过对比各种算法对LSTM 模型优化后的曲线,可以发现ESSA 算法优于其他算法,因此,将ESSA 算法用于LSTM 模型参数改进,不仅能很好地获得具体的参数值,而且能实现最佳的优化效果。这种方法避免了在模型中盲目设定参数而耗费大量时间和精力,并且当模型中特征向量的维度和数据量发生变化时,运用该算法对模型进行优化,可以迅速、准确地获取具体的模型参数,无需根据人工经验进行多次实验得出参数值再进行比较。将ESSA 算法与LSTM 模型相结合,可充分发挥两者的优势,实现更精确的预测。这种方法不仅能提高预测的准确率,还减少了参数调整的复杂性,使得模型的优化过程更加高效。对溶氧预测优化研究,不仅适用于养殖工船场景,也适用于如预测某水域某个水质参数的其他场景,可为其他领域的相关研究提供参考。
3 结论
针对养殖工船水质参数溶解氧预测及其精确性,本文提出了一种利用ESSA 算法对LSTM模型参数作优化改进的方法,以实现高效的预测效果。首先,该算法在基本的麻雀算法中加入了Circle 混沌映射进行种群初始化,加入正弦余弦算法和Levy 飞行策略分别对侦察者位置、跟踪者位置更新,提升了算法的全局探索和局部优化问题;然后,与其他改进算法对不同形态的基准函数进行优化求解,验证了ESSA 算法在搜索能力、收敛性、稳定性等方面均具有明显的优势;最后,在相同的实验条件和参数下,将ESSA 算法与其他算法进行对比实验。结果显示ESSA 算法优化模型后的预测精度优于其他算法,能很快跳出局部最优,具有很好的稳定性。
采用ESSA 算法对LSTM 模型进行参数优化,明显缩减了参数设置的盲目性和时间成本,提高了优化效率和预测准确率。这种方法结合了现代优化算法与深度学习模型的优势,实现了对LSTM 模型参数的寻优。在实验过程中,该算法在全局探索和局部优化方面均表现出色,达到了实验目的。不过,该算法在应用于特定类型数据方面的实验时存在一定的缺陷,后期需进一步考虑算法的通用性,以确保其在不同数据分布和特性下的鲁棒性;此外,还发现在获取实验结果过程中需要较长时间取得最优解,后续将持续优化算法,以提高计算效率,减少时间成本。
