基于多数据集深度学习的视觉传感图像目标增强识别*
2024-03-06杨宝华
董 涛,杨宝华
(辽东学院信息工程学院,辽宁 丹东 118000)
由视觉传感器获取的图像均可以称为视觉传感图像。视觉传感器是指通过对摄像机拍摄到的图像进行图像处理,来计算对象物的特征量(面积、重心、长度、位置等),并输出数据和判断结果的传感器。由于外界信号传输环境的影响,视觉传感图像受外部因素干扰,其中信道噪声对成像的干扰尤为严重,导致目标被弱化,无法准确识别。在深度学习被提出之前,目标识别主要是根据先验知识构建各类数学模型实现,常用的背景减除法、帧差法,是利用检测得到目标的某种数据特征构造数学模型,输入信息并对模型进行求解,获得识别结果。深度学习提出后,其成为传感图像、视觉领域中的主要解决方法之一,该方法可以增强细节信息,且算法的鲁棒性和实用性较强,是目前传感领域的研究热点及重点。相关学者也不断地提出一些较好的方法:
李亚娟[1]首先使用全局稀疏表示,总结出样本和训练类别间的相对表征能力,通过局部稀疏表示反映出针对测试样本各类别的绝对描述能力,随后采用D-S 证据理论将两种稀疏表示的决策矢量进行融合,获得识别结果。但是由于算法过于复杂,计算量较大,导致算法运行速度较慢;刘相云等[2]首先以RFB Net 模型为基础,构建特征金字塔网络,将特征信息和语义信息融合输入网络,进一步提高输出结果准确率。但是该方法在较为复杂的图像背景下识别精度会受到影响。Paul 等[3]提出了一种新的自适应限幅双直方图均衡方法来增强红外图像。使用对数幂过程改变输入直方图,对改变的直方图执行剪切操作后,重新分布剪切部分,以限制过度增强。通过直方图分离点方法细分修改后的直方图,实现红外图像子直方图独立均衡。但是该方法受温度影响较高,红外图像增强效果有待进一步优化。赵若晴等[4]在金文图像预处理的基础上,提取其结构特征和局部纹理特征。并将提取结果融合后作为样本,通过支持向量机识别金文图像。Li 等[5]针对卫星目标数据的流模式,采用流变分贝叶斯算法来初始化模型参数。使用计算机辅助设计模型生成的卫星目标的数据进行测试,测试结果表明,该方法可以精准识别卫星目标,避免了存储和重复计算导致的巨大存储负担问题。
深度学习技术不断成熟后革新了识别模式,学习特征更为丰富、特征表达能力更强,深度学习通过模拟人类视觉系统对接收到各类信息的处理过程,实现智能化分类,主要通过研究分析底层特征信息形成较为抽象的高层表示,获得数据的分布特征。深度学习主要强调了两个方面,分别为:明确模型的结构层数和突出特征学习过程。本文结合深度学习技术,以识别目标的多种特征为基础,提出了一种视觉传感图像目标增强识别方法。由于颜色特征不受形变、旋转方向以及运动速度等外界因素影响,因此本文首先采用颜色特征方法完成特征提取,随后根据识别目标的背景区域与目标本身区域纹理特征差异性,增强图像背景和目标间对比度,实现视觉传感图像增强的目标,并且为了提高计算速度,在增强的过程中将视觉传感图像的灰度级进行了降级运算。最后构建多特征参数卷积神经网络模型,并在连接层后接入Softmax 回归函数,完成分类识别。实验分析结果验证了所提方法的视觉传感图像增强和识别性能优势,所提方法能够准确地识别出不同场景下的火灾和车辆行驶情况,识别效率更高,具有一定的实际应用价值。
1 传感图像的目标增强
由于识别目标的背景区域与目标本身区域纹理特征有很大不同,因此可以通过图像的纹理特征,增强图像背景和目标之间的对比度,实现图像增强的目的。
1.1 基于颜色特征方法的传感图像特征提取
本文采用颜色特征法提取包含目标的传感图像的特征。颜色特征是视觉传感图像的特征之一,而颜色是众多目标中,人眼可以直接感受到的特征,与其他种类特征相比,颜色特征不受形变、运动速度、旋转方向等因素影响,是一种更具鲁棒性的特征表达。以颜色特征法提取的视觉传感图像目标特征为基础,减少目标增强识别时目标自身和周边颜色的影响。
本文采用色彩直方图完成图像目标提取,能够通过图像中的颜色量化分布,由于视觉传感图像中目标的不同,其颜色特征也不同,因此给出某一色彩占图像中所有颜色的比例,如式(1)所示:
式中:K为图像像素中的某个颜色特征,nk为该特征所对应的像素数量,N表示图像所有像素点的数量。
1.2 基于灰度值共生矩阵的目标增强
根据灰度共生矩阵可获取视觉传感图像目标的纹理特征,结合1.1 部分提取的目标颜色特征,可实现视觉传感图像目标增强。
给定一个位移矢量d=(dx,dy),且元素P(i,j)表示灰度级为i和j的两个像素对之间的相对频率。通过加窗法在给定大小的窗口中计算图像像素的全部像素灰度值共生矩阵与纹理特征。定义M×N窗口、角度θ(θ=0°,45°,90°,135°,180°)、距离d以及灰度共生矩阵元素Pij如式(2)所示:
式中:I(k,l)、I(m,n)表示相邻的两个像素。若图像的灰度级为256 级,其灰度共生矩阵则为256×256,计算量较大。因此在实际操作过程中将其降级为64 或32 来提升运算效率,且距离、角度和窗口大小也可以根据图像的纹理复杂程度决定。correlation 方法能够保证分析结果的客观性,因此,采用correlation 方法获取纹理特征,如式(3)所示:
式中:μx、μy为灰度均值,可通过式(4)进行计算:
σx、σy为灰度标准方差,可通过式(5)进行计算:
随后将图像灰度从256 级降到64 级,识别目标越小,则选择的窗口和距离也越小。针对目标图像中的所有像素I(x,y),计算其窗口大小M×N邻域的灰度共生矩阵,再通过式(3)计算出该区域的纹理特征correlation(x,y),最后将窗口内的每个像素点的correlation(x,y)设置于256 级灰度上,获得增强后图像。
2 实现传感图像目标识别
根据1.2 部分获取了增强后的传感图像,考虑到图像中被识别目标包含多类型特征,为了优化目标识别结果,利用多数据集学习和卷积神经网络方法估计目标区域,实现传感图像目标增强识别。
本文以卷积神经网络模型为基础完成目标识别,模型的上层由卷积层和池化层组成,下层则为连接层,在连接层后接入Softmax 回归函数,使得模型具有分类功能。本文构建的卷积神经网络模型中,卷积层和池化层分别有4 个、连接层有1 个,如图1 所示。

图1 卷积神经网络结构图
图1 所示的4 个卷积层负责完成图像中各类特征的识别工作,池化层负责使各特征在尺度空间中[6]仍能保持一定的层次性,连接层负责完成特征的分类,而后接入的Softmax 回归函数则主要起到输出连接层分类结果的作用。但是由于类内变化过大导致的聚类中的各特征变得分散,集群也可能出现重叠,因此采用指数Laplace 损失函数[7]降低类内特征的变化幅度,调整不同类中心的特征间距离。
设Lc为损失函数,对其进行定义,如式(6)所示:
式中:xa、ya为第a个对象从全连接层中获得的视觉传感图像目标的输入和输出特征量,cya表示ya特征量的中心,k表示聚类过程中的对象总量,该数值由视觉传感图像目标数量和卷积核数量决定。在数据逆向传播时,根据式(7)计算xa的偏导数中心:
在迭代过程中更新聚类中心为式(8):
将式(8) 中的δ(ya,a) 定义为δ(ya,a)=,为充分利用多数据集特征信息(包括目标的颜色、轮廓、特殊动作等),设某一样本与其余聚类中心的距离为LMT,如式(9)所示:
式中:λ为边界参数,为降低计算量采用随机梯度下降法[8]更新参数,并通过多数据集的LMT值计算出模型的损失函数,完成模型的构建,如式(10)所示:
学习模型构建后,将多数据集学习与卷积神经网络模型相结合识别图像目标,在模型的不同区域中共享同一个问题的信息,使得模型中每一个卷积层和池化层中均拥有同一个任务数据,首先构建深度学习迭代式,如式(11)所示:
式中:Gij(x,y)表示以(xij,yij)为研究目标的深度学习灰度像素值。对目标区域作自适应分块标记处理,获得识别图像,如式(12)所示:
式中:Oij(x,y)表示提取出的特征点集,则可得目标边缘轮廓点的信息,如式(13)所示:
式中:t=0,1,…,k,通过模板匹配法[9]分割目标区域,获得角点扫描结果,如式(14)所示:
通过角点检测[10-11]获得目标区域的空间分布矩阵,如式(15)所示:
式中:Lxx(x,σ)表示梯度方向的目标轮廓,Lxy、Lyy表示匹配轮廓与二值化匹配参数,随后确定子相关系数,如式(16)所示:
通过深度学习模型[12]将目标与整个图像的像素进行分离[13],提取在子相关系数(k|k)附近的目标像素点,如式(17)所示:
则目标区域的估计结果,如式(18)所示:
至此实现视觉传感图像中的目标增强识别。根据上述内容,可将此次基于多数据集深度学习的视觉传感图像目标增强识别流程总结为图2。

图2 视觉传感图像目标增强识别流程
3 实验与结果分析
3.1 实验准备
为保证实验的真实性及准确性,本文测试过程主要在MATLAB 平台上完成,数据编译软件为MATLAB2019 款商业数学软件,用于原始图像处理及视觉信息计算等工作。同时,在实验中设置构建的卷积神经网络模型输入为城市道路视觉传感图像,图像1 为异常火情、图像2 为异常驾驶行为。其中异常驾驶行为的驾驶人员颜色、动作、轮廓等特征为:右手举着手机,身穿白色上衣,戴着墨镜。
以UAS 数据集(数据集来源于https://github.com/yuxiaoz/SGSN)中的256×256 城市道路视觉传感图像为仿真对象,进行具体火情测试。图3所示为日间原始城市道路发生异常火情的视觉传感图像。

图3 原始图像
以图3 为基础,从视觉传感图像增强效果、目标识别效果、识别效率三个方面进行分析。
3.2 视觉传感图像增强效果
为验证视觉传感图像增强的有效性,分别采用本文方法、文献[2]的RFB Net 遥感影像目标识别方法和文献[3]的自适应限幅双直方图均衡方法对图3 所示的原始视觉传感图像做增强处理,结果如图4 所示。

图4 不同方法增强效果图
图4 中,黑色边缘线为日间城市道路发生异常火情的覆盖范围。从图4 中可以看出,以RFB Net遥感影像目标识别方法和自适应限幅双直方图均衡方法处理,进行视觉传感图像增强后,图像边缘出现不同程度的缺失,而本文方法处理后的视觉传感图像成像效果最好,且边缘保留较为完整,有效解决了由于高斯噪声等外界因素导致的视觉传感图像模糊的问题。
为了进一步测试本文方法对于视觉传感图像的增强效果,采用平均梯度信息作为评价指标进行客观测试。平均梯度信息指视觉传感图像的边界两侧附近灰度有明显差异,即灰度变化率大,该变化率越大,视觉传感图像增强效果越好。以图3 为例,获取三种方法在不同图像大小下,随着噪声的逐渐增加的增强效果,如表1 所示。
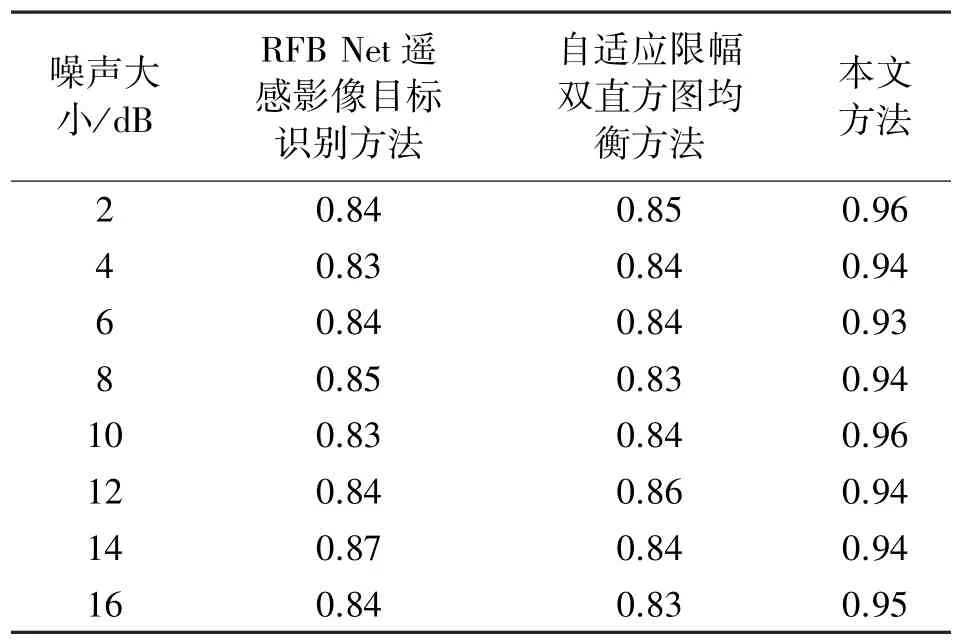
表1 平均梯度信息测试结果
对表1 进行分析后得出:随着图像中噪声的逐渐增加,本文方法对于图3 视觉传感图像的增强效果较好,并且增强后视觉传感图像的平均梯度信息高于0.93,受噪声影响较小,增强效果好。
3.3 目标识别效果
由于卷积核的数量会直接影响识别性能,因此首先需要确定卷积神经网络模型中,各卷积层中卷积核数量。一般情况下在使用深度学习对视觉传感图像目标进行识别的过程中,后一层卷积层中包含的卷积核数量往往为前一层的2 倍,即若第一层中包含s个卷积核,则第n(n≥2)层的卷积层中就包含2k-1×s个卷积核。根据该策略本文分别使用不同数量的卷积核进行识别,根据第一层卷积核数量,获取剩余4 层的卷积核数量。由此得到识别率与第一层卷积核数量间关系,如图5 所示。
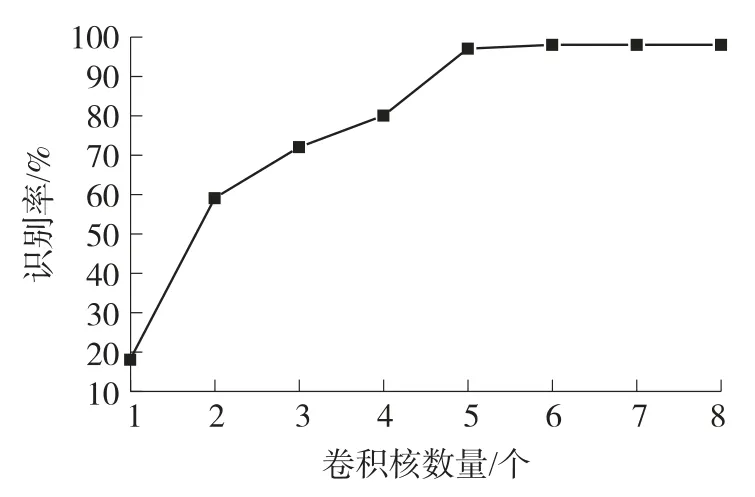
图5 第一层卷积核数量与识别率之间关系
根据图5 可以看出,第一层卷积核的数量会严重影响识别效果,在第一层卷积核数量为0 个-5 个时,随着数量的增多,识别率直线上升,但是当第一层卷积核超过5 个时,识别率升高速率变得较为缓慢,甚至几乎没有变化,这就表明过多的卷积核对提升识别性能帮助较小且还会使计算量增大,影响识别效率,因此本文选择第一层卷积核数量为5 个,随后依次计算其余层卷积核数量即可。
为进一步验证所提方法的有效性,将确定卷积核数量的深度学习模型应用于行车驾驶人员异常行为检测实例中。选取UAS 数据集中包含驾驶人员异常行为(拨打电话)的某台车辆为识别目标,该驾驶人员右手举着手机,身穿白色上衣,戴着墨镜,将以上数据作为识别特征,分别采用三种方法对目标图像进行识别,识别结果如图6 所示。

图6 不同场景识别结果图
从图6 中可以看出,本文方法可以准确识别出白色轿车中拨打电话的驾驶人员,人脸较清晰。相较于RFB Net 遥感影像目标识别方法和自适应限幅双直方图均衡方法的目标增强效果更好,因此,本文方法能够准确地完成行车驾驶人员异常行为检测,即可识别视觉传感图像中的目标,使用卷积神经网络模型的目标增强效果较好,实用价值较高。
以视觉传感图像清晰度为指标,分析视觉传感图像质量。清晰度指视觉传感图像各细部影纹及其边界的清晰程度,清晰程度越高,表明视觉传感图像质量越好。检测三种方法对视觉传感图像增强后的图像目标质量,统计结果如表2 所示。
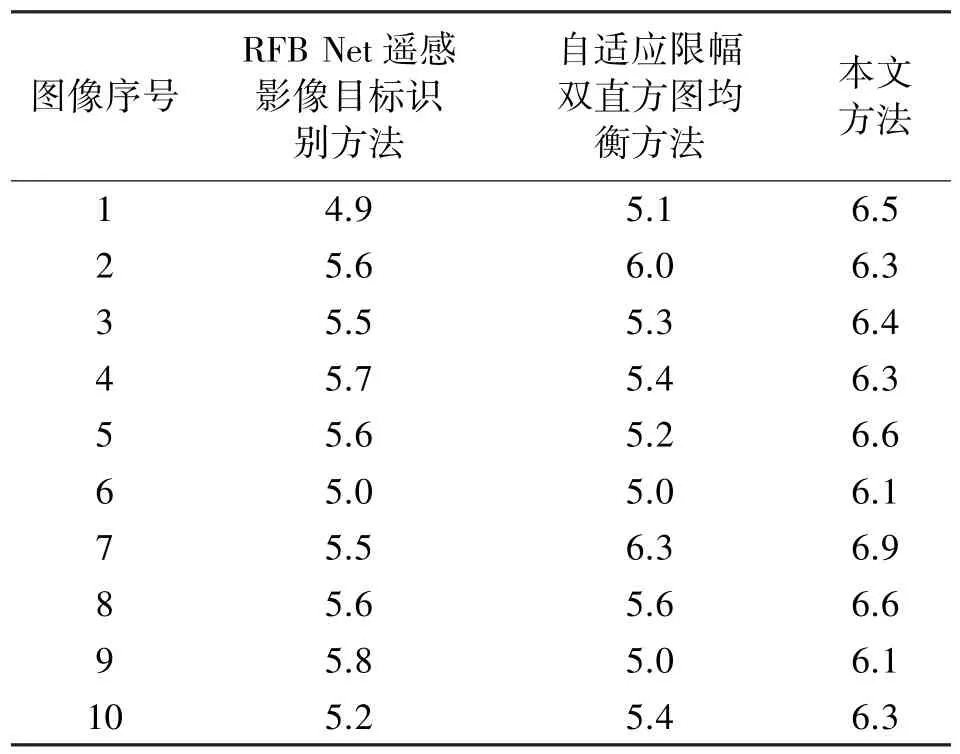
表2 不同方法优化后图像清晰度对比
由表2 对比结果可以看出,采用本文方法优化后的视觉传感图像清晰度均高于6.1;采用RFB Net遥感影像目标识别方法和自适应限幅双直方图均衡方法优化后的视觉传感图像清晰度均低于6.1。对比结果可以看出,本文方法优化后视觉传感图像具有较高的清晰度,优化后视觉传感图像目标质量较高,验证本文方法具有较高的优化效果,提高了目标识别效果。
4.4 识别效率验证
为进一步证明所提方法的识别效率是否符合实际应用需求,分别测试三种方法对40 张行车道路图像的识别完成时间,测试结果如图7 所示。
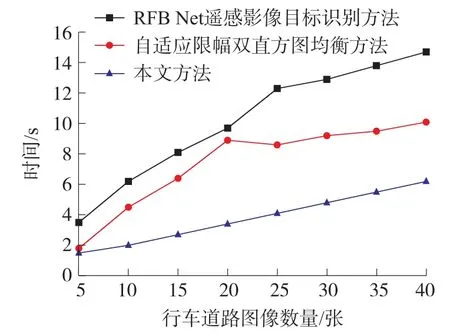
图7 不同方法识别耗时对比
根据图7 可知,在识别对象数量相同的条件下,RFB Net 遥感影像目标识别方法的耗时最长,最大耗时为14.7 s,自适应限幅双直方图均衡方法次之,最大耗时为10.1 s。相比之下,本文方法的用时最短,最大耗时为6.2 s,这是由于在视觉传感图像增强的过程中对灰度级进行了降级,且选择了合适的卷积核数量降低了算法的计算速度。另一方面,从图7 中还可得出,随着识别对象数量的增加,所提方法所用时间呈线性增长,且增长速度较慢,这就表明本文方法受待识别目标数量的影响较小,在计算量较大情况下,所提方法仍能保持较理想的稳定性。
5 结论
深度学习能够对包含多数据特征的目标进行识别,因此本文结合深度学习技术提出了一种基于多数据集深度学习的视觉传感图像目标增强识别。在仿真分析中将不同方法应用在道路图像增强和目标识别实例中。测试结果表明,所提方法能够有效增强火情图像边缘、根据驾驶人员的多种特征给出准确异常驾驶行为识别结果,且识别速度较快。在下一步研究过程中还可以深入识别目标的其他特征信息,使得识别所得结果更为具体,进一步减少相关人员的工作量。
