基于奖励积分机制的高效拜占庭容错算法DIG-PBFT
2024-03-05吴言蓝雯飞王俊张潇谢元艾向鑫
吴言,蓝雯飞*,王俊,张潇,谢元艾, ,向鑫
(1 中南民族大学 计算机科学学院, 武汉 430074;2 香港教育大学 数学与资讯科技学系, 香港特别行政区 999077)
自从比特币问世以后,区块链技术在各个领域快速发展[1-4]. 以太坊的智能合约[5]和IBM 的Hyperledger Fabric[6]推动了区块链在企业领域的应用.而在如今区块链技术仍在不断发展[7],并且更加注重安全性、可扩展性和可编程性.
区块链是一种去中心化的分布式数据库技术[8].与传统的中心化系统相比,区块链技术不仅解决了安全和单点故障的问题,而且提升了交易速度和透明度.共识算法是区块链最核心的技术,解决了信任和一致性问题,是决定区块链系统性能的主要因素.目前按照区块链的类型,对共识算法可以分为三类:公有链共识,私有链共识和联盟链共识.其中公有链主要应用工作量证明(PoW),该算法的实用性较差[9];私有链主要采用分布式一致性算法Raft达成共识;联盟链主要使用PBFT算法.
文献[10]提出了一种匹配主从链结构的分层拜占庭容错算法HBFT.每一次的共识系统会根据参与节点属性的不同,分别执行HBFT 算法中速度快、开销小的简化共识算法SCA(Simplified Consensus Algorithm)和开销较大、容错能力强的拜占庭容错算法PBFT.文献[11]提出了SG-PBFT 算法,将所有节点进行分组,并初始化赋予积分,每次共识都会调整节点积分,一个时间周期结束根据积分调整分组,积分过低将不参与共识.文献[12]提出了一种PBFT 优化算法,依靠引入C4.5 和积分投票机制来确定主节点.文献[13]提出了一个弱化主节点的概念,优化整体的共识过程来提升性能.文献[14]引入选举投票机制,改变原本主节点的随机选择,通过投票机制选取主节点.文献[15]提出了QS-PBFT共识算法,优化了主节点选取.上述方案能够有效地提高共识的效率但是依然存在计算开销较大、主节点选取安全性低、恶意节点未被处理等问题.本文所提出的DIG-PBFT(Dynamic Integral Grouping PBFT)共识算法引入了奖励积分机制,在共识过程中网络中的节点会根据积分机制规则动态进行调整,信用度过低的节点会被加入候选集中并且禁止参与共识,从而大大提高了共识效率.本算法的核心是在共识过程中通过动态的思想筛选出拜占庭节点,使得安全性更高的节点参与到共识中,大大提高主节点选取的安全性,并且通过分组来控制参与共识的节点数量以及优化算法复杂的通信过程,来降低算法的时延,以提高算法性能.
1 共识机制
共识机制是一种在分布式系统中用于确定事实或状态的算法.在该机制下,参与者通过协作来达成一致并生成新的区块或更新现有的区块链.共识机制可以确保网络上的所有节点都同意最终的状态,并且防止任何一方篡改数据.一些常见的共识机制又可以分为证明类和拜占庭类[16].
1.1 证明类共识机制
证明类的共识机制主要会依据某一种条件来选择主节点.常见的证明类机制有工作量证明(Proof of Work,PoW)、股权证明(Proof of Stake,PoS)以及委托股权证明(Delegated Proof of Stake,DPoS)[17]等等. PoW依赖于计算机的计算能力来解决数学难题,以此来获得区块链网络中节点的信任和认可.在PoW 中,矿工需要通过计算哈希函数来查找一个特定的数字,使其满足预定的条件,这个过程被称为挖矿[18].矿工将自己的计算能力投入到网络中,竞争谁最先找到下一个合法区块,并且得到相应的奖励.由于挖矿需要大量的计算能力和电力支持,因此PoW 算法存在一些不足,例如,它对能源的需求可能导致对环境的不良影响,并且由于算力集中度较高,可能会出现中心化的问题;PoS 通过验证节点拥有的加密货币数量来选择下一个出块节点,而不是像PoW 一样通过计算能力的竞争,这是因为这些节点将会抵押一定数量的加密货币作为“股份”,以获得参与下一个出块节点的机会,与PoW 相比,PoS算法在节约能源方面具有优势,因为它不需要进行大量计算来解决数学难题,PoS 算法也存在一些不足,例如可能会出现寡头垄断、网络安全性问题等;DPoS 与PoW,PoS 都不相同,DPoS 并不选择出块节点,而是通过选举一组代表来管理网络.DPoS 算法主要解决了PoW 存在的能源浪费和PoS可能出现的中心化问题.然而,DPoS 也存在一些短处.例如,由少数代表管理网络可能导致中心化风险等.
1.2 拜占庭类共识机制
拜占庭类中一种常见的共识算法是Paxos[19],该算法主要用于解决分布式系统中的数据一致性问题,并被广泛地应用在分布式数据库、分布式文件系统和分布式共识算法中.Paxos算法主要适用于拜占庭容错(Byzantine Fault Tolerance,BFT)的环境中.该算法通过提议阶段、承诺阶段、提议接受阶段以及提议被接受阶段等多个阶段的消息交换,选出一个主节点并达成一致性,从而确保系统中的数据一致,然而该算法在性能方面存在一些问题,因为它需要进行多次信息交换和状态转换,这会增加系统的延迟并且带来额外的开销;另一个最常见的共识算法是PBFT[20],它可以允许存在最多f个恶意节点的情况下保证分布式系统的一致性和可行性.在PBFT中,所有节点按照一定的顺序轮流担任主节点,其他节点则作为备份节点.当一个客户端需要发送请求时,它将请求发送给当前的主节点,主节点将请求广播给其他备份节点,并等待至少f+1 个节点响应确认信息.如果主节点收到了足够数量的确认信息,就会执行请求并将结果广播给所有节点;否则,它会继续等待确认信息.每个节点都会维护一个日志来记录所有已处理的请求,以确保系统的一致性.PBFT 算法的优点在于其能够在容忍一定数量的恶意节点的同时保证系统的一致性,且在正常情况下具有较高的效率、低延迟.PBFT的3个阶段如图1所示.在图中C 表示发起请求的客户端,0 表示主节点,1、2、3为从节点,这里假设节点3为拜占庭节点.
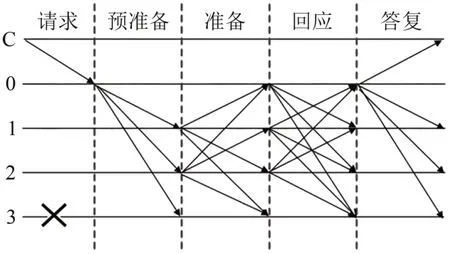
图1 PBFT共识算法的信息交换Fig.1 Information exchange of PBFT
2 目前共识算法存在的问题
共识机制具有较高的安全性、去中心化、较高的可扩展性、较强公平性等优势,使其能够更好地解决分布式环境下的数据同步和一致性问题.但是从现实中共识机制的应用不难发现其存在一些问题有待解决.
PBFT 算法主要用于解决分布式网络系统中存在的拜占庭将军问题,在一个分布式系统中,因为存在网络延迟、消息丢失等,节点之间可能会出现数据信息不一致的情况.PBFT 算法可以使各个节点在达成一致的同时,保证系统的安全性和可用性.PBFT算法是联盟链中常见的共识算法,依旧存在一些问题,如主节点的选取十分随机,对恶意节点没有进行处理,通信效率较低等.
2.1 主节点的选取
传统PBFT 算法中主节点的选取一般是通过轮流机制来实现的,每个节点按照一定的顺序依次担任主节点.具体来说,PBFT 算法中使用了一个叫做“视图”的概念来进行主节点的选择.在PBFT中,每个节点维护着一个叫做“视图号”的变量,用于记录当前节点所处的视图编号.当某个节点需要选出主节点时,它会向网络中广播一个包含当前视图号的消息,其他节点收到该消息后会将自己的视图号与之比较,如果发现自己的视图号较小,则更新自己的视图号,并等待当前视图的主节点发送下一个请求.最终主节点编号确定是通过视图编号和共识节点的数量进行模运算得出来的.基于以上原则,PBFT算法能够确保每个节点都有机会成为主节点,但是网络中存在恶意节点,在最坏的情况下,恶意节点成为主节点的概率将会有大约三分之一,这样高的概率在车联网系统中是不能存在的.总之,传统的PBFT算法在选择主节点方面是不合适的,恶意节点成为主节点的概率过大会导致系统面临较大的安全风险.
2.2 恶意节点的处理
传统的PBFT 算法中没有任何的方案对恶意节点进行处理.那么当恶意节点成为主节点时,系统会因为无法按时达成共识而触发视图转换来重新选择主节点,这个过程需要消耗额外的时间和资源,并且会延长整个共识过程的时间.根据视图转换规则,这个被替换的恶意节点在之后的共识过程中依然有机会再次成为主节点,然后还会触发视图转换,那么不处理恶意节点,有可能导致系统进入恶意循环.如果恶意节点的数量超过了算法所能容忍的范围,那么就无法保证系统的安全性和正确性.
2.3 通信效率
第一点,因为PBFT 未能对恶意节点进行处理,当恶意节点成为主节点后又要进行视图转换,并且恶意节点仍有机会成为主节点,使得系统不得不多次进行视图转换,这大大增加了系统的通信开销;第二点,PBFT 在执行共识过程中经历3 个阶段:预准备、准备和提交.其中,预准备阶段和提交阶段都需要所有节点向其他节点发送请求消息,以确定进入下一阶段所需的最小数量的准备消息.这个过程需要所有节点之间进行通信,并且必须等待所有节点都完成后才能进入下一阶段,这使得通信复杂度达到了Ο(n2)级别.然而车联网对通信效率的要求很高,那么执行传统的共识算法,运行效率可能会偏低.
3 DIG-PBFT算法模型
3.1 PBFT共识算法设计
针对共识算法存在的问题,为了能够更好地贴合实际应用,本文在PBFT 算法的基础上做出一些改进,引入了奖励积分分组机制,提出了DIG-PBFT(Dynamic Integral Grouping PBFT),具体的改进如下:
(1)本方案会将所有的节点分为共识节点集和候选节点集,初始化时所有的节点会被分配初始的积分以及信用度,并且在一开始所有的节点都将分配到共识节点集中.共识节点集中的节点将会进行共识过程,而候选节点集中的节点只是被迫接受共识结果并保存,并且等待处理.
(2)在不断共识过程中,节点的积分以及信用度会根据奖励积分机制变化.每一次共识结束后会对节点进行判断,当节点的节分或者信用度低于阈值时,该节点将会被加入候选节点集等待系统对其进行检查处理.这一点体现了该算法的动态分组特性.并且积分机制会使得积分和信用度高的节点被划分到共识节点集中参与共识,而可能的恶意节点将大概率被划分到候选节点集中.积分机制有效地提升了算法的安全性,并且即便是攻击者想要控制积分较高的节点,那么他需要付出相对更多代价才行.换而言之,引入了奖励积分机制后,在不断的共识过程中可以使得安全性更高的节点有更大的几率当选主节点.
(3)改变主节点的选取方式.本方案的主节点选取将只在共识节点集中进行.每次选取主节点时,将对共识节点集中的节点进行随机编号,之后以节点的积分和信用度分别作为一级和二级评判依据,选取最优节点作为主节点.
(4)对PBFT 的通信过程进行了简化.将“回应阶段”的广播过程进行简化,能够在一定程度上降低通信复杂度,使得共识算法的效率有所提高.DIGPBFT 算法通信五阶段如图2 所示,图中C 表示客户端,0表示主节点,1、2、3、4表示从节点,其中模拟节点3为拜占庭节点,4为候选节点.
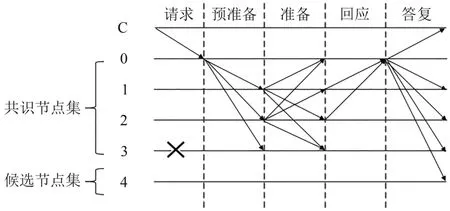
图2 DIG-PBFT共识算法的信息交换Fig.2 Information exchange of DIG-PBFT
DIG-PBFT算法的核心如图3所示.
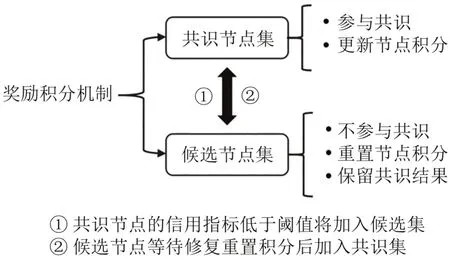
图3 DIG-PBFT算法核心Fig.3 The core of DIG-PBFT
总结而言,将积分机制引入PBFT 算法,从而设计出的DIG-PBFT 算法能对传统算法的短处如主节点的选取十分随机、对恶意节点没有进行处理、通信效率较低等提供相应的解决方案,能够满足车联网高吞吐量和低网络通信量的需求.
3.2 DIG-PBFT算法流程
DIG-PBFT算法的流程图如图4所示.
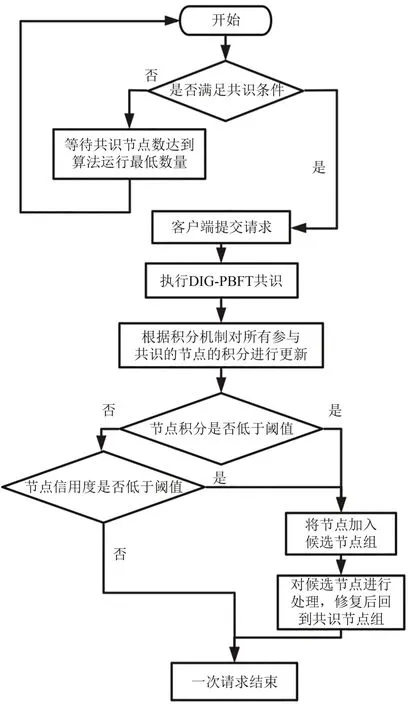
图4 DIG-PBFT算法流程Fig.4 The process of DIG-PBFT
算法的具体流程描述如下:
(1)首先根据积分机制对所有节点进行积分的初始化,将所有节点先加入共识节点集中.根据选取主节点的规则选出主节点;
(2)判断系统是否满足共识条件,将共识节点集中的节点占总节点的比率作为判断依据,当该值不小于规定的阈值时,系统可以继续进行共识,倘若小于阈值系统将进行等待;
(3)客户端向主节点发起共识请求;
(4)主节点开始执行共识信息交换;
(5)共识结束后,根据积分机制对所有参与共识的节点的积分以及信用度进行更新;
(6)判断节点的积分或信用度是否低于阈值,如果节点的积分或信用度有一个低于对应的阈值,该节点将会被加入候选节点集中,遍历所有共识节点集中的节点;
(7)对于加入候选节点集的所有节点,都会接受系统的检查和处理,等待处理完成后重新赋予初始积分,并重新添加到共识节点集中;
(8)一次请求结束.
算法的伪代码如Algorithm 1所示.

4 实验结果与分析
在实验部分,本文使用Python3.9 编程实现PBFT、HBFT 以及DIG-PBFT 等算法,在本地开启多个节点用来模拟各个算法的共识过程,并记录算法的吞吐量和共识时延.仿真实验所使用的电脑CPU型号为I5-12400F,主频为4.4 GHz,内存32 G,显卡型号为RTX3070.
4.1 共识时延
共识时延是用来评估共识算法性能的主要指标之一,是指客户端提出请求到共识结束的时间差.实验中,将网络中的节点数设定为20,共识轮数设定为60,在同一条件下分别记录每一种算法的共识时延,实验结果如图5 所示.在图5 中PBFT,HBFT以及DIG-PBFT 算法的平均时延分别为3.46 ms,2.56 ms,1.96 ms,从图像可以看出DIG-PBFT 时延明显低于PBFT 算法,在前期的共识中HBFT 算法和DIG-PBFT算法的时延差距不大,但是在后期能够展现出DIG-PBFT 算法的优势.主要原因在于共识过程中不断筛选出拜占庭节点并进行处理,使得安全性更高的节点参与共识,从而提高了达成共识的效率.随后的实验将共识轮数定为100轮,测试在不同节点数下,每一种共识算法的平均共识时延,实验结果如图6 所示.从图6 能够看出随着节点数的增加,算法的共识时延增长速率越来越快,然而DIGPBFT算法的性能要明显优于其他算法.
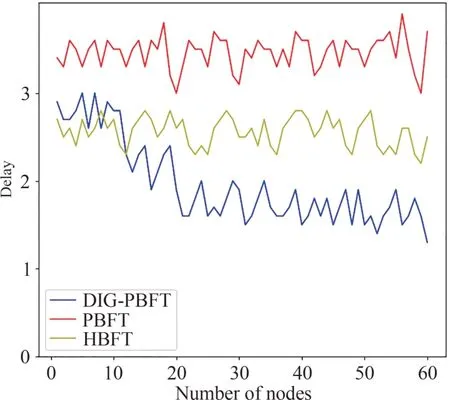
图5 共识时延结果对比Fig.5 Comparison of consensus delay results
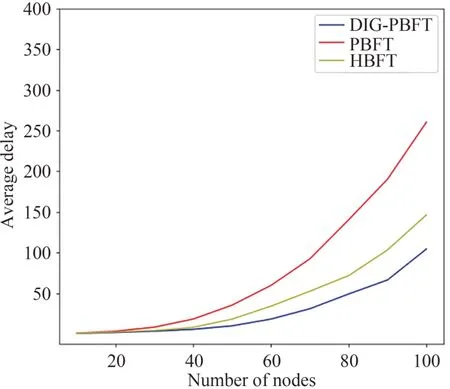
图6 平均共识时延对比Fig.6 Comparison of average consensus delay
4.2 吞吐量
吞吐量也是用来评估共识算法性能的主要指标之一.是指一个系统或网络在单位时间内可以处理的数据量.在高性能计算领域,吞吐量也可以用于描述系统在单位时间内可以执行的操作数或计算量.在本文的实验中,吞吐量TPS表现为单位时间系统完成共识的数量,在不同节点数下,实验中设置客户端发送1000次共识请求,并记录每一秒完成的共识数量.实验结果如图7 所示.可以看出,各个算法的吞吐量随着节点数的增加而减少.显然DIGPBFT算法达到了更好的效果.因为该算法通过动态积分分组在大量的共识过程中有着更高的效率,也就使得共识所消耗的时间更短,同等的时间内能够处理更多的共识请求.
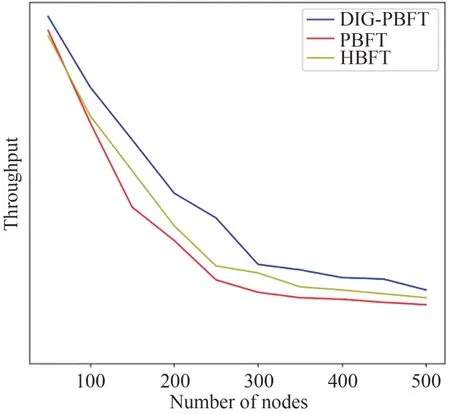
图7 吞吐量对比Fig.7 Throughput comparison
4.3 安全性分析
DIG-PBFT算法在主节点的选择上与PBFT算法的视图转换技术不同,采用了选择共识节点组中信用度更高的节点作为主节点的方案,该方案大大降低了PBFT算法选取主节点的不可靠性和低安全性.
本文中主节点的选取方案主要依赖节点的信用度.在节点参与共识的过程中,节点的积分和信用度会根据节点的行为进行调整改变,安全诚实节点的积分和信用度会增加,恶意节点的积分和信用度会降低,每次共识结束后,积分或者信用度低于阈值的节点将会被认定为恶意节点,并被加入候选节点组,同时禁止其参与共识,等待处理.这样做保证了能使绝大部分安全诚实节点有更多的机会当选主节点并参与共识.总体来看DIG-PBFT 算法能在保证容错性不变的基础上,通过动态地调整参与共识的节点,提高了系统的共识效率和安全性.
5 总结
本文通过分析PBFT 算法所存在的问题(如主节点的选取十分随机、对恶意节点没有进行处理、通信效率较低等),提出了DIG-PBFT 算法.文中将动态积分分组机制引入算法,通过该机制,可以在共识过程中动态地筛选出拜占庭节点并禁止其参与共识,使得安全性更高的节点最大可能地参与到共识过程中,极大地提高了共识效率.仿真实验结果证明了DIG-PBFT 算法的吞吐量更大、时延更低.同时通过实验结果也能发现当网络中节点数量大量增加,对算法的影响非常大.在未来的工作中,将进一步研究在网络中存在大量节点的情况下,如何提高算法的性能.
