一种面向微控制器上环境声音分类的DNN压缩方法
2024-03-05方维维路红英
孟 娜,方维维,路红英
(北京交通大学计算机与信息技术学院,北京 100044)
0 引 言
在日常环境中,人们被各种各样的环境声音所包围,如空调工作声、汽车喇叭声、自来水声等,这些自然或人为的声音都可以归类为环境声音[1]。现实生活中与环境声音分类(Environmental Sound Classification,ESC)相关的应用随处可见,例如通过户外传感系统中的数据信息识别来自不同物种的声音,助力于生物多样性评估工作[1];智能家居设施能够有效获取和分析家庭监控环境声音,可对老年人的突发情况进行实时反馈[2];此外还有噪声检测系统[3]等。在非语音音频分类任务中,ESC 是最重要的课题之一[4]。随着深度学习技术的飞速发展,深度神经网络(Deep Neural Network,DNN)[5]极大地提升了ESC任务的精度,DNN在ESC任务上的应用引起了人们广泛的关注[6-8]。
然而,DNN 在计算和内存方面开销巨大,给基于微控制器(Microcontroller Unit,MCU)的物联网(Internet-of-Things,IoT)应用带来巨大挑战[9]。如表1 所示,与传统的计算设备不同,微控制器是一种没有操作系统和动态随机存取存储器的微型计算机,在计算、内存和存储等各方面的资源都是极其受限的。以STM32F746ZG 为例,该设备是一个ARM Cortex-M7 MCU,其CPU 主频为216 MHz,存储空间仅有1 MB,而内存仅有320 kB。经典的DNN 模型ResNet-50 的部署需要占用102 MB 存储空间,对其进行8 位量化降为26 MB 后,虽然能应用到云GPU、CPU 等计算硬件上,但仍然无法部署到MCU 上。微型机器学习[10](TinyML)作为一个新的计算范式应运而生,即在IoT 设备的超低功耗微控制器上运行机器学习推理。与现有计算范式不同,TinyML 的目标设备资源非常低,需要对DNN进行更大幅度的压缩[11]。
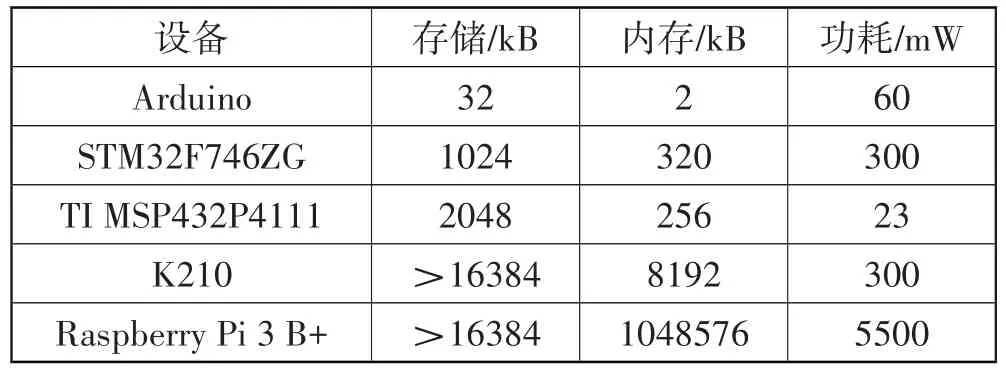
表1 嵌入式平台及其硬件能力
现阶段已有部分学者针对MCU 上的ESC 任务提出压缩方案。Kumari 等[12]通过对L3-Net 进行剪枝减少网络参数得到紧凑的模型EdgeL3,产生良好的理论压缩比。但是,该方法导致了稀疏的参数矩阵,需要专用的硬件和软件支持。Cerutti 等[13]利用Google 在大型声音数据集Audioset 上训练的VGGish 模型参数,并基于启发式的方法设计了紧凑的模型结构,提出一种知识蒸馏方法提升小模型的精度,然而,该工作并未提供一个通用的轻量模型的获取方法。Mohaimenuzzaman 等[11]首先根据ESC 数据特点设计了一个DNN 模型ACDNet,然后通过剪枝和知识蒸馏等操作对其进行压缩获得Micro-ACDNet,但是该工作直接对模型进行量化部署,带来了精度损失。
针对已有工作中存在的问题,本文提出一种面向微控制器上环境声音分类的DNN 压缩方法。首先,由于规模较大的模型无法直接部署应用,本文提出使用剪枝方法对模型进行大幅压缩。接下来,针对压缩带来的精度损失问题,设计一种面向剪枝的知识蒸馏方法(Pruning-oriented Knowledge Distillation,PoKD)进行解决。最后,对压缩优化后的模型进行了量化部署。本文的主要工作有:
1)设计面向剪枝的知识蒸馏方法,通过在训练阶段对教师和学生网络的中间层增加辅助分类器,并结合注意力机制对多个教师中间层的输出信息进行融合,以指导学生网络的训练,实现更全面且具有不同侧重程度的知识转移。
2)基于STM32F746ZG 在广泛应用的数据集(UrbanSound8K[14]和ESC-50[15])上进行实验,结果表明本文方法能够在较小的精度损失内,获得较高的压缩率,提升推理速度。与已有的工作相比,在同等压缩程度的情况下,本文提出的方法精度更高。
1 相关研究工作
现阶段已有很多研究[16]致力于压缩和加速大规模参数的DNN,包括模型剪枝、知识蒸馏、模型量化和低秩近似等。本文主要关注前3个方面的压缩技术。
1.1 模型剪枝
模型剪枝是通过消除不重要的网络权重来降低参数规模的,方法分为非结构化[16-17]和结构化[18-19]2种形式。非结构化剪枝可以在DNN 中进行任意权重的修剪,产生高稀疏率的权重矩阵,但是运行时需要特定的硬件支持[18]。结构化剪枝通过移除整个滤波器或通道,产生非稀疏压缩,克服了非结构化剪枝中存在的问题[19],已成为近年来的研究热点。然而,在现有的通道剪枝方法中,如何确定最佳的层稀疏度一直是通道剪枝需要面临的关键挑战之一。Duggal等[20]提出了CUP 方法来解决此问题,利用输入和输出权值来计算表征滤波器的特征,对相似的滤波器进行聚类,从而完成删减操作。该方法只需引入一个超参数,便可实现各层根据其对剪枝敏感程度的不同进行不同程度的压缩,获得了更优的压缩率。本文提出使用剪枝方法CUP[20]作为DNN 压缩方法的第一步,构建一个紧凑的模型以适应硬件资源约束。
1.2 知识蒸馏
知识蒸馏(Knowledge Distillation,KD)最早由Hinton等[21]提出,使用大型而复杂网络(教师网络)的输出概率作为软标签来传递知识,提高规模小但是精度较低的网络(学生网络)的性能。之后进一步探索了如何从教师网络的中间层提取表征信息。Romero等[22]提出了FitNet,直接匹配师生网络的中间特征图,改进学生模型的训练。受此方法启发,各种间接匹配特征图的方法[23-27]被陆续提出。Zagoruyko等[23]提出将注意力作为一种知识从教师网络转移到学生网络。Wang 等[24]设计了MHKD,通过对模型引入辅助分类器,提出匹配师生网络中间层的分类信息。Yang 等[25]结合自监督对比学习,提出分层的自我监督的增强知识蒸馏方法。然而上述方法中,师生模型的中间特征对应关系均为一对一的映射关系,并没有充分利用到其他网络层的信息。为解决此问题,Chen 等[26]设计的SemCKD 方法和Passban 等[27]设计的ALP-KD 方法都使用所有教师网络中间层的特征作为知识信息,二者主要的区别在于注意力权重的计算方式不同。但是,直接基于师生网络中间层信息中执行蒸馏的方式缺乏明确的理论证明其如何工作的原理[28]。本文的方法受Wang 等[24]方法启发,结合注意力机制将多个教师中间层的分类信息融合输出,以指导学生训练,有效解决了上述工作中存在的问题。
1.3 模型量化
量化是指通过用更少位数的数据类型来近似表示32 位有限范围浮点数据,从而实现降低占用的存储空间和加快模型推理速度的目标[29]。根据量化位数可以分为低位量化(1 比特[30-31]、2 比特[32]、4 比特[33-34])和普通量化(8 比特[35-36]等)。Courbariaux等[31]提出在网络前向传播中使用二进制权值训练一个DNN,并通过简单的加减法替换乘法操作。Choi等[32]通过引入0 状态,使用2 比特存储权值参数,可以在模型大小和推理精度之间实现良好的权衡。但是,这种二进制或者三元量化会面临不可忽视的精度损失问题,尤其是对于大规模参数的模型。实际上,已有研究表明,使用8位整数(INT8)来量化权重可以实现相对较低的精度损失[35]。因此,INT8 量化得到了深度学习框架的广泛支持,例如TensorFlow Lite Micro、NVIDIA TensorRT 等。本文使用的量化方法是面向INT8 量化实现的,从而满足了在微控制器上模型部署的需求。
2 压缩方法设计
2.1 整体框架
图1 展示了本文提出的压缩方法的整体流程。步骤①使用声音特征训练模型,获得性能优异的原始DNN 模型MOri。但是该模型参数规模过大,无法直接部署到资源高度受限的MCU 上。基于1.1 节的方法描述和实验测试,在步骤②中提出使用CUP[20]剪枝方法去除冗余参数,产生满足设备资源要求的小模型MPru。然而,MPru是经过深度压缩得到的,推理精度略低。针对此问题,设计了新的知识蒸馏方法PoKD,结合步骤①和步骤②的结果,通过步骤③得到MPoKD。在MCU 上进行模型部署前,往往需要对神经网络进行量化,即完成步骤④,得到可以部署在MCU 上的高性能轻量级模型MQua。
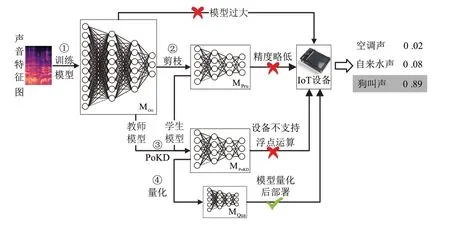
图1 DNN压缩方法概述
下面将在2.2节和2.3节对设计的蒸馏方法PoKD和量化方法进行具体介绍。
2.2 PoKD蒸馏方法
本文提出的PoKD 框架如图2 所示,在模型训练阶段,对教师和学生模型不同的网络单元(同一单元中的网络层具有相同维度的特征图)都增加了辅助分类器。在测试阶段,使用移除所有辅助分类器后的网络进行推理计算。在具体实现中,由于对模型增加了辅助分类器,因此与传统的训练流程有所不同。以下首先介绍基于交叉熵和KL 散度的损失函数,接着分别对师生网络的训练损失函数进行具体描述。
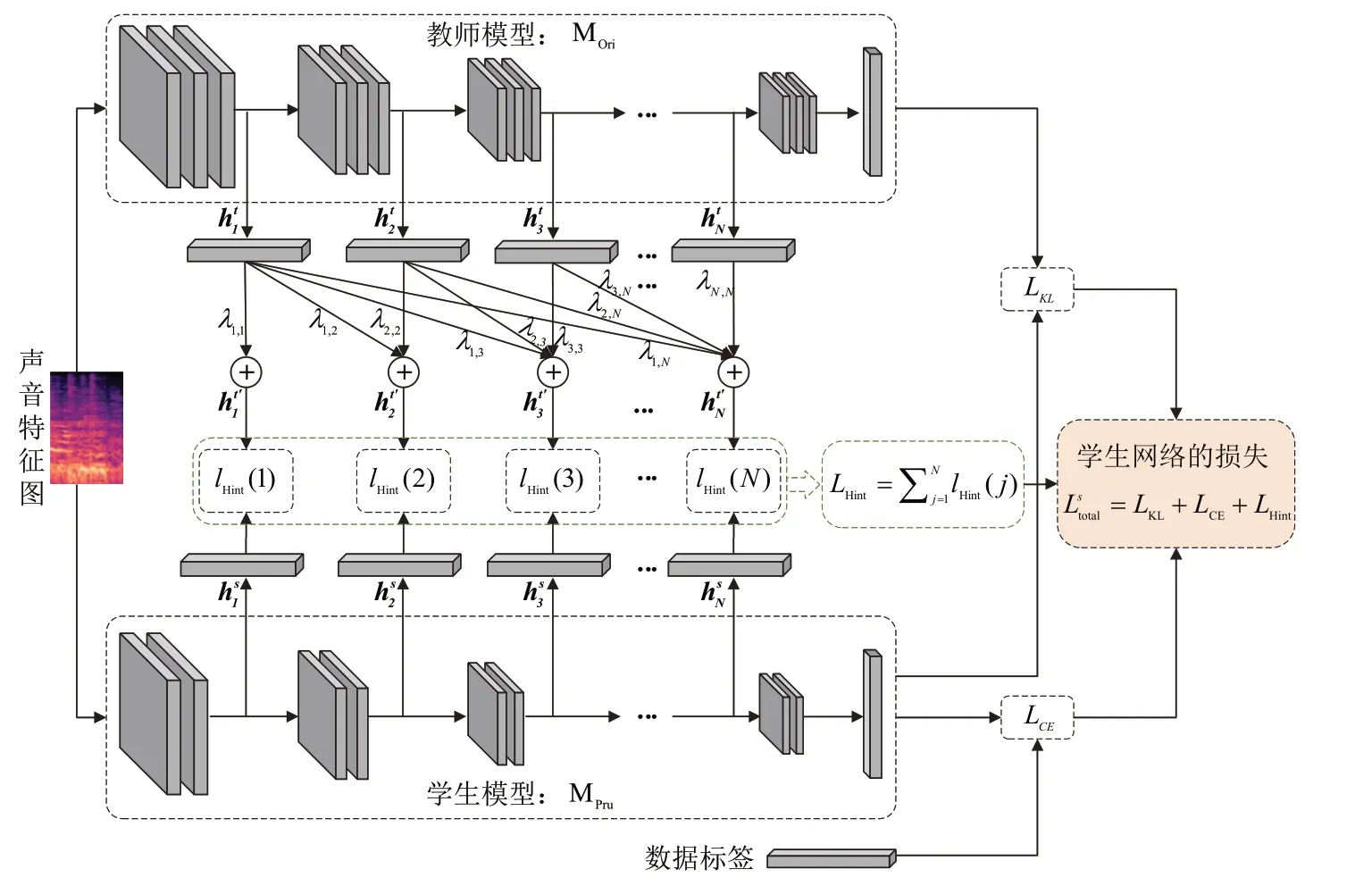
图2 PoKD方法框架
将参与模型训练的数据集合表示为{x,y},其中,x表示输入数据,y表示真实标签。对网络得到的所有输出分布,利用Softmax 层进行归一化,将得到相应的概率分布称为硬标签信息。同时,引入温度系数T用来平滑所有的输出分布,将得到的结果称为软目标,如式(1)所示:
式中:pi(x,T)是将样本x预测为第i个类别的概率,通过合并所有类别可以形成p(x,T);zi和zj分别表示最后一层神经元对第i和j个类别的输出结果;K为样本的类别总数;当T值为1 时,得到的结果即为硬标签信息。
使用交叉熵计算模型的硬标签与真实标签之间的差异如式(2)所示:
其中,p和q分别表示2 个网络的软标签,基于KL 散度实现的损失函数如式(3)所示:
对教师网络,以pt(x,T)表示最后一层的输出信息表示辅助分类器的输出信息,N为辅助分类器个数。教师网络的损失函数由2 个部分组成,包括最后一层和所有辅助分类器的输出分别与真实标签间的交叉熵损失,如公式(4)所示:
对学生网络,以ps(x,T)表示最后一层的输出信息表示辅助分类器输出的输出信息。学生网络的损失函数由3 个部分组成,包括最后一层输出的硬标签与真实标签间的交叉熵损失LCE、基于师生网络最后一层输出的软标签间的蒸馏损失LKL以及基于师生网络中间层表征信息间的蒸馏损失LHint,如公式(5)所示:
其中,LHint是基于辅助分类器的输出信息结合注意力机制计算而来的。对学生的每个辅助分类器,计算多个教师网络辅助分类器的加权输出分布,用于知识蒸馏训练。其中,用于求和的权值是使用向量点积计算师生辅助分类器输出间的相似性,接下来使用Softmax 进行归一化。具体地,对于学生网络第j个辅助分类器,计算其对教师网络第i个辅助分类器的注意力权值,如式(6)所示:
结合教师网络前j个辅助分类器计算得到融合输出,作为指导学生第j个辅助分类器训练的知识信息,如式(7)所示:
学生网络第j个辅助分类器的蒸馏损失如式(8)所示:
使用所有辅助分类器的蒸馏损失,计算得到学生网络中间层的损失如下:
2.3 量化方法
由于MCU 上的模型部署要求进行浮点(FP32)参数到整型(INT8)参数的转换[13],因此需要对通过PoKD方法得到的模型进行量化,如图3所示。

图3 量化方法示意图
为将网络的浮点数值量化为整型数值,采用广泛应用的线性变换方式[29]。以S表示缩放因子,Z表示浮点数0.对应的整型参数,以r和q分别表示模型在量化前后的浮点和整型参数,r∈[rmin,rmax],q∈[qmin,qmax]。S的计算公式如式(10)所示:
由S的值可以计算Z的数值,如式(11)所示:
将模型参数从FP32转为INT8,如式(12)所示:
3 实验结果与分析
3.1 实验设置
3.1.1 数据集
本文在2 个广泛应用的环境声音分类数据集UrbanSound8K[14]和ESC-50[15]上对方法进行测试。
1)UrbanSound8K。该数据集是用于自动城市环境声分类研究的数据集,共有8732 条已标注的声音片段,采样率不同,最大长度为4 s。该数据集包含10 个分类,例如空调声、汽车鸣笛声、狗叫声等。与ESC-50 不同,UrbanSound8K 的数据量更大,声音片段的时间长度不同。
2)ESC-50。该数据集是2000 条环境录音的集合,同样常用于环境声音分类的基准测试。其中,每条音频记录时长为5 s,以16 kHz 和44.1 kHz 采样,这些样本均匀分布在50 个平衡的不相交类别上(每个类别40 个音频样本)。与UrbanSound8K 相比,ESC-50覆盖了更多的声音类别,所有音频时长相同。
3.1.2 DNN模型
与图像分类任务不同,由于2 个声音数据集的样本量较少,故使用流行的DNN[4]中深度较浅的模型来对所提压缩方法进行测试,包括VGG-11和ResNet-18。
1)VGG-11。网络主要由8 个卷积层和3 个全连接层组成,每个卷积层后都是一个批量归一化层和ReLU 激活函数。在模型训练阶段,将辅助分类器添加在网络的第1、2、4和6个卷积层后。
2)ResNet-18。由17个卷积层和1个全连接层构成,第一个卷积层用于输入数据的预处理,后面是4个相互堆叠的残差块,每个残差块有2 个卷积层,输出通道的数量相同。此外,网络有跳过连接,可以跳过这2 个卷积操作,并在最终的ReLU 激活函数之前直接添加输入。在模型训练阶段,将辅助分类器添加在网络第1、2和3个残差块后。
3.1.3 实验环境
模型训练是在GPU 深度神经网络集成计算平台上进行的,使用的GPU 为NVIDIA GeForce RTX 2080Ti,实现神经网络模型采用的深度神经网络框架是PyTorch。在模型部署阶段,使用的MCU 设备为STM32F746ZG。以ONNX作为中介,将训练好的神经网络转换为Tensorflow 格式,使用TensorFlow Lite Micro[37]框架工具进行部署。
3.1.4 实验参数
在模型训练阶段,对师生网络的中间层引入的辅助分类器由1 个卷积层和1 个全连接层组成,卷积层后有1 个批量归一化层和1 个ReLU 激活函数。实验过程中,对在2 个数据集上训练的模型均采用自适应矩估计(Adaptive Moment Estimation,Adam)方法进行优化。数据批量大小设置为64,学习率设置为0.001,权重衰减系数为0.0005,训练迭代次数设置为100,50,5,50。
3.2 压缩方法实验
本节基于在UrbanSound8K 和ESC-50 数据集训练得到的VGG-11和ResNet-18对提出的压缩方法进行实验。首先,使用剪枝方法CUP[20]获得适当的压缩率,使得既能大幅降低参数至满足硬件资源的规模,又能保持一定的精度。接下来,通过将压缩前后的2 个模型分别作为师生模型,对提出的PoKD 方法与已有的蒸馏方法进行对比,结果表明PoKD 能够在同等压缩程度下实现更高的精度。最后,对模型进行了量化。
3.2.1 剪枝实验结果
将剪枝方法CUP[20]应用于在2 个数据集上训练的VGG-11 和ResNet-18,图4 展示了模型参数的降低比例及压缩后的精度变化。在ESC任务中,轻度的压缩(压缩率<85%)能够提高模型的精度。而进一步增大压缩率时,当参数规模降低超过97%后,精度损失3个百分点~8个百分点。
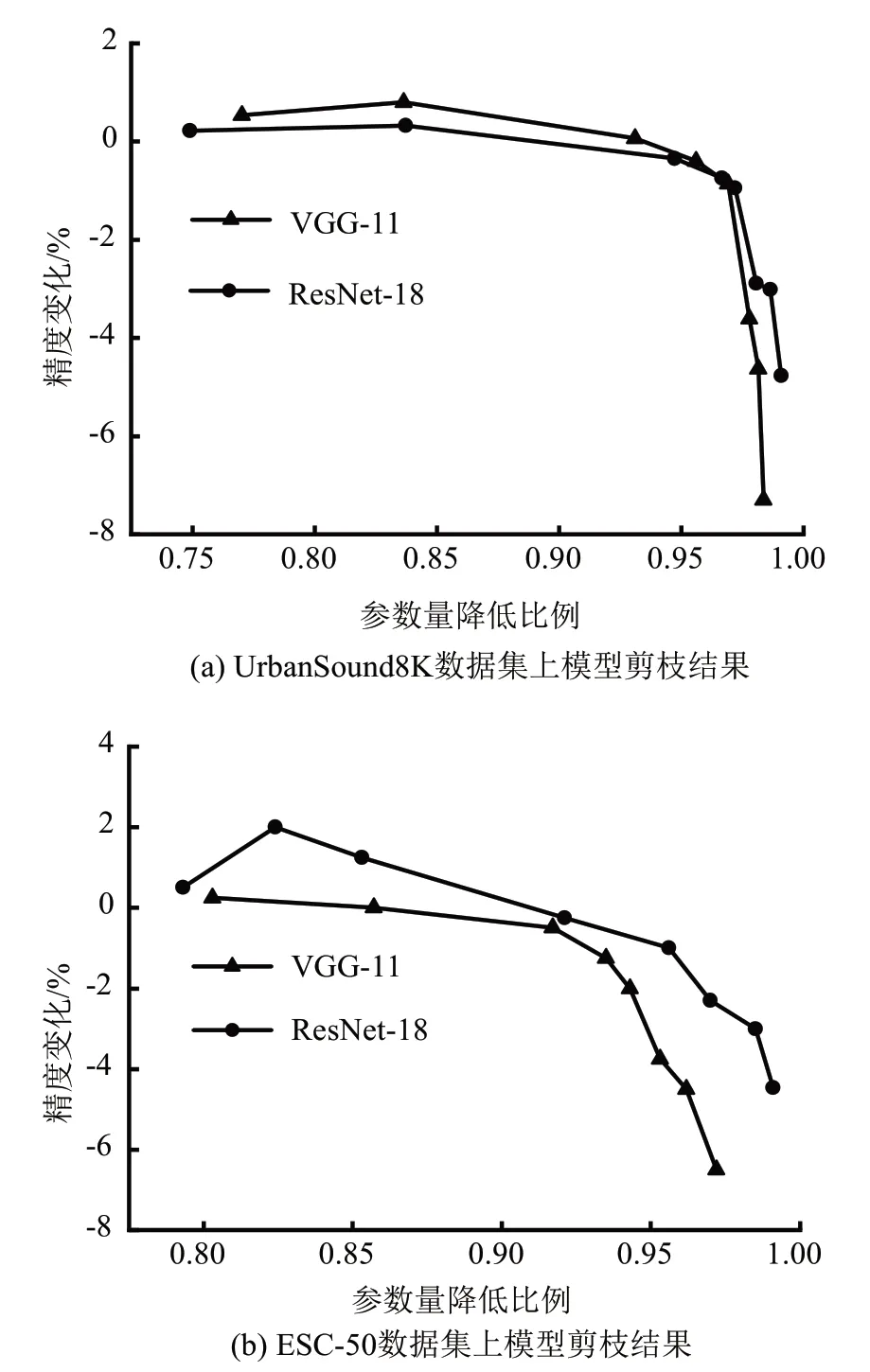
图4 对2个模型剪枝的结果
3.2.2 PoKD实验结果
以未压缩的模型作为教师网络,剪枝97%参数后的小模型作为学生网络,对不同的知识蒸馏方法进行对比实验,表2展示了蒸馏前后模型的精度。
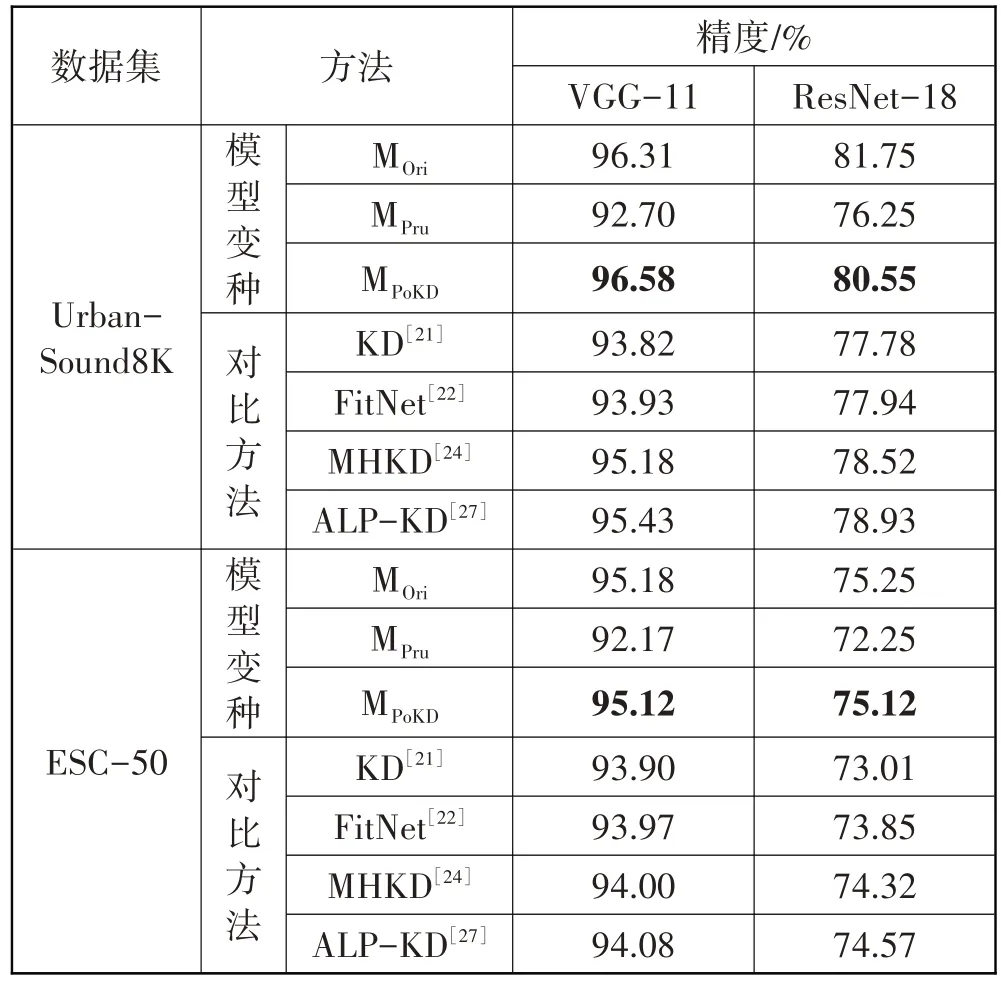
表2 知识蒸馏方法的对比实验
表2 数据表明,对模型大幅压缩后的精度损失为3 个百分点~5 个百分点。只是基于网络输出层和中间层知识蒸馏方式是有效的,但是效果较差,最高能对精度提升1.69 个百分点。在间接匹配师生网络中间层的表征信息的方式中,MHKD[24]仅对师生的中间层进行一对一的指导,知识信息量相对较少,未能达到很好的效果。ALP-KD[27]使用所有的教师网络的中间层信息对学生进行指导训练,但由于压缩后的模型过小,浅层网络学习能力较低,不具备更深度的表征能力,实现的结果略优于MHKD。而PoKD 方法兼顾了以上2 种情况,与对比方法中最好的结果相比,PoKD将模型精度提高了0.5个百分点~2个百分点。
3.2.3 量化实验结果
表3 展示了模型经过量化后的推理精度,直接对压缩后的轻量模型进行量化会在一定程度上损伤模型性能,精度降低了2.5个百分点~5个百分点。
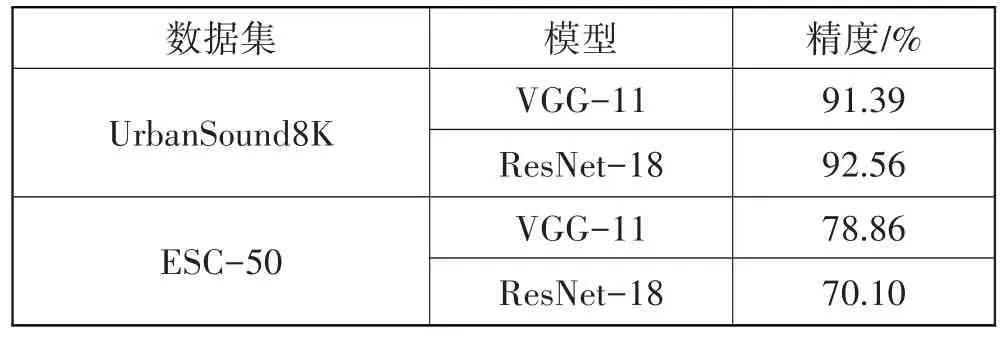
表3 量化方法实验结果
3.3 对比实验
在本节中,与典型压缩方案Micro-VGGish[13]、Micro-ACDNet[11]进行了对比。
首先,与Micro-VGGish 生成初步的紧凑模型结构的方法进行对比,结果如表4 所示。其中,CUP-31k 和CUP-27k 分别表示使用剪枝方法CUP[20]将模型参数压缩至31 k 和27 k。由表4 可知,与未经压缩的VGGish 模型相比,无论是使用剪枝方法还是基于启发式的压缩方法将模型参数量从72.1 M 降低至0.031 M,都会有很高的精度损失。但是,使用剪枝方法CUP-31k得到的与Micro-VGGish 同等规模的轻量级模型,前者的推理精度更高。继续压缩至更小的模型,使用剪枝方法仍然能得到更高的精度。在浮点运算方面,由于未对原始网络层的配置进行修改优化,得到的结果略高。
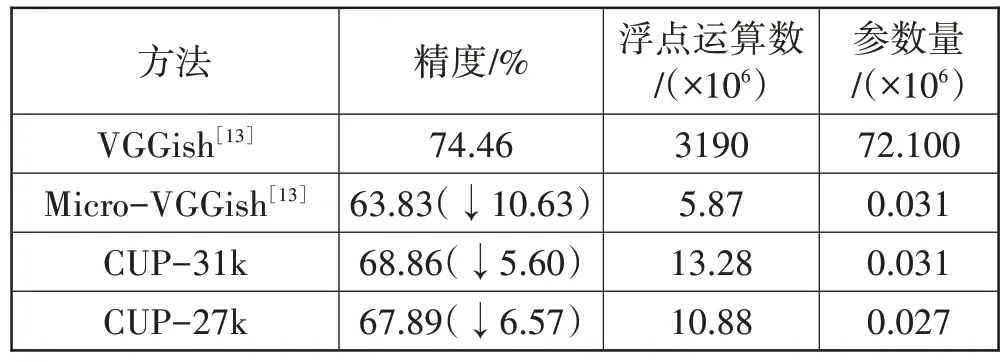
表4 与Micro-VGGish的对比
表5 展示了所提知识蒸馏方法的对比结果。在同样的压缩程度下,与TKD 相比,PoKD 能将精度提高1.48 个百分点。同时使用CUP-27k 和PoKD 对模型进一步压缩,将参数量降低为27.14×103时,仍然能够获得具有竞争力的精度。

表5 与Micro-VGGish的知识蒸馏方法的对比
最后,与Micro-ACDNet[11]进行了对比。表6 展示了Micro-ACDNet 与本文方法在压缩后的模型精度、参数量、浮点运算数以及在设备上的推理时延。与Micro-ACDNet 相比,本文的压缩方法实现了更高的压缩率,推理精度提高了0.43个百分点。将模型部署到推理设备上后,由于本方法将模型压缩至更小的规模,获得的模型推理时延更低。

表6 与Micro-ACDNet的对比
4 结束语
本文针对MCU 上的环境声音分类模型部署困难的问题,提出了一种完整的DNN 压缩方法。针对使用剪枝方法对模型进行大幅压缩带来的精度损失问题,提出了一种面向剪枝的知识蒸馏方法进行解决,之后将量化后的模型部署到MCU 上进行测试。通过在经典的DNN 模型和广泛使用的数据集上进行实验,获得了97%以上的压缩率,而精度下降在2 个百分点以内。与已有的方案对比,在同等压缩程度下,将精度提高了1 个百分点~2 个百分点。在未来的工作中,将持续关注与ESC 相关的其他数据集和模型,继续在MCU 上进行测试,提高本文方法的性能,并研究其他可以应用于MCU上的压缩方案。
