基于异质属性融合的危重疾病二阶段预测模型
2024-03-05詹少强张逸群孙鸿涛张小波
詹少强,曾 安,张逸群,孙鸿涛,张小波
(1.广东工业大学计算机学院,广东 广州 510006;2.广东省第二人民医院关节骨科科室,广东 广州 510317;3.广东工业大学自动化学院,广东 广州 510006)
0 引 言
目前,医疗资源短缺是一个具有普遍性、长期性、全球性等特征的问题[1]。随着医疗信息电子化技术的发展,人们对患者治疗过程中出现的临床数据信息的记录和保存的需求也日益上升,因此电子健康记录(Electronic Health Record,EHR)的概念就此诞生。美国卫生组织卫生标准7 (Health Level Seven,HL-7)对EHR 进行了如下定义:“EHR 是向每个个人提供的、一份具有安全保密性的、记录其在卫生体系中关于健康历史与服务的终身档案[2]。”EHR 是患者多种数据信息的总体集合,其中包含了病史、诊断、药物、治疗计划和放射图像等信息[3]。一名患者在进行治疗的过程中往往进行多个项目的检查,因此即使是单个患者的数据也可以提供丰富的信息。
电子健康记录的出现与应用引起了研究人员对EHR 所包含信息进行数据挖掘相关工作的兴趣。目前研究当中,基于机器学习和深度学习方法实现疾病预测的案例有不少。Desautels 等人[4]使用EHR 数据和机器学习的方法,提出一种名为Insight 模型,在数据集MIMIC-III中对ICU患者中是否存在脓毒症进行预测;Nemati等人[5]使用的机器学习算法是一种改进并正则化后的“威布尔-比例风险回归模型(Weilbull-Cox proportional hazards model)”,并在使用Emory Healthcare System 数据集上进行训练,使用MIMIC-III 数据集进行测试;Lipton 等人[6]从洛杉矶儿童医院EHR系统中提取出由13个生理指标和化验结果变量组成的多变量时间序列,基于LSTM 模型对128 种疾病进行预测,实验结果表明该模型在某些疾病上可以进行准确分类;Choi等人[7]提出了一种名为“Doctor AI”的疾病预测模型,该模型基于循环神经网络(Recurrent Neural Networks,RNN)并在MIMIC-II 数据集中进行实验;Esteban 等人[8]则基于RNN 和前馈神经网络分别对患者的历史特征序列和人口统计学信息进行处理,并在网络输出层前融合进行预测。
在现实的临床治疗中,患者除了要忍受疾病带来的痛苦,往往还要承担不小的经济负担。有研究指出,我国慢性阻塞性肺疾病(Acute Exacerbation of Chronic Obstructive Pulm-onary Disease,AECOPD)急性发作患者每年因AECOPD 入院治疗0.5~3.5 次,平均住院治疗费用高达11598 元/人次[9]。对于肺癌患者来说,早期诊断肺癌的有效方法不仅会明显提高治愈的可能性,延长患者的生存期,还能减少患者的经济负担[10]。可以说,研究一种能够对患者群体进行有效早期诊断的方法,对患者个人、家庭和社会均有重要意义。
目前的研究中,数据属性的来源可以划分为3类:人口统计学信息、生理指标以及实验室检查。前2 种属性的数据获取难度和成本都比第3 种属性要低,一个患者往往会拥有这3 种属性,并导致出现数据类型混合的结果。原始的EHR 数据往往是异质类型的[11],即原始数据类型中既有数值型的属性,也有非数值型的属性,且一般为类别型的属性。对类别型属性普遍的处理方法是简单进行编码,但这样会损失不同患者群体之间隐含的其他信息[12]。而对于类别型属性可以继续细分为2 类:定类型和定序型[13-14]。两者之间的区别在于定类型属性的每个可能值之间不可进行排序,定序型属性的每个可能值之间是可以进行一定程度的排序。
针对前面所述的异质属性处理信息丢失问题,同时为了更好地挖掘EHR 异质数据的信息,本文引入基于熵的距离度量方法(Entropy-based Distance Metric,EBDM)算法[15]对数据本身存在的混合类型属性进行处理,对数值型属性和类别型属性进行统一处理;然后,在模型的一阶段对非时序状态且仅包含部分属性的数据样本进行初次筛选;最后,经过第一阶段模型筛选后的数据样本,根据全时序且包含全属性的数据样本进行第二阶段模型的再预测。整体二阶段模型的方法框架如图1所示。
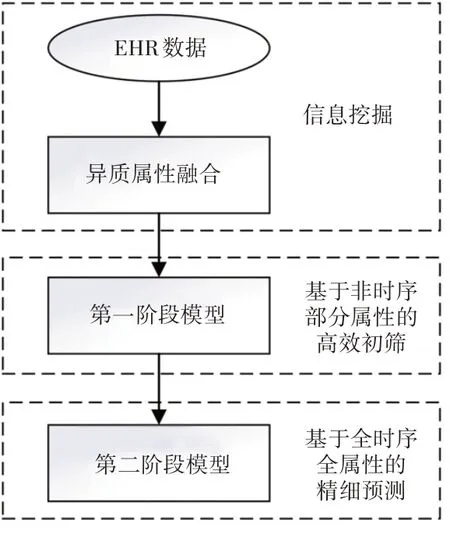
图1 二阶段模型整体框架
本文主要工作如下:
1)相较现有数据预处理和表征方法,本文没有强行进行取值转换,也不进行非可解释编码,而是用了统一度量来表示样本之间的相似性关系,在一定程度上确保了异构属性的信息不被曲解和丢失。
2)考虑到在实际环境中疾病预测的紧迫性,在模型的第一阶段对非时序状态且仅包含部分属性的数据样本进行初次筛选,该筛选的目的是尽量筛选出数据样本的阴性样本(非患病样本),让部分患者不用进行后续其他的检查项目,减轻患者的经济负担。
3)第二阶段模型对第一阶段模型进行初筛后的数据样本使用全属性全时序的格式进行精细预测,充分利用时序与非时序格式数据的各自隐含的信息。
4)通过大量实验验证,确定第一阶段和第二阶段的最佳算法模型组合,并且在真实大规模医疗数据集上进行了有效性验证和参数选择评估。
1 预备知识
在二阶段模型的框架中,异质属性的表征方法在挖掘数据属性的信息中起到重要作用;而第一、第二阶段根据其实现的功能和输入数据格式的不同,可以分为非时间序列的初筛模型和时间序列的预测模型。本章对异质属性的表征方法和2 类模型中与本文方法高度相关的模型进行述评。
1.1 异质数据表征方法
类别型属性是指没有明确数字含义的定性值,在机器学习和数据分析任务中非常常见,与数值型属性不同,类别型属性并不能进行常规算术计算,且没有明确定义的相似性空间。为了挖掘类别型属性的信息,现有的方法可以分为2 类:1)基于表征,将类别型属性表征为数值型属性;2)基于相似性度量:直接定义类别型属性的相似性。
基于表征的方法中,One-Hot 编码是最常见的方法,它把数据中的类别型属性表征为对应的布尔向量,各个属性可能值之间相互独立,而这并没有考虑到在数据样本进行互相比较时,不同属性对不同可能值所造成的影响是不同的。在基于相似性度量的方法中,传统方法为汉明距离,它直接将不同值记为1,相同值记为0,以此来度量2 个分布之间的相似性。然而这种方法并没有考虑到不同属性之间的依赖关系,在进行挖掘时容易发生信息丢失。
为了进一步考虑属性的相互依赖性,以及挖掘出属性间更多的隐含信息,需要一种基于熵的距离度量方法[15]利用不同属性、不同可能值之间的信息熵对类别型属性进行更为准确的相似性度量,确保原本异质属性数据中的信息进行有效融合,并最大程度地保留异质属性的信息,降低异质属性融合过程中的信息丢失程度,为后续模型的预测提供一种更好的异质属性处理方法。
1.2 非时间序列初筛模型
常见机器学习的非时间序列分类器可分为单一分类算法和集成分类算法[16],前者所包含的经典模型有K近邻分类、决策树分类和支持向量机分类;后者的代表模型有随机森林和XGBoost,其中XGBoost在多种分类任务中取得较为不错的效果。近年来,以深度神经网络为主要模型方法的深度学习技术发展迅速,其中包含在计算机视觉和自然语言处理领域中广泛使用的多层感知机(Multilayer Perceptron,MLP)、卷积神经网络[17](Convolutional Neural Network,CNN)以及以图神经网络模型为基础的图卷积神经网络[18](Graph Convolutional Network,GCN)和图注意力网络[19](Graph Attention Networks,GAT)。由于本文二阶段模型经过实验验证,发现XGBoost 作为一阶段模型效果更好,所以此处着重介绍XGBoost的技术细节。XGBoost[20]是一种使用集成学习方法的 模 型,在GBDT[21](Gradient Boosting Decision Tree)的基础上利用二阶导函数计算目标函数和添加正则化项的方法进行改进。
根据XGBoost 算法的思想,可以把疾病预测模型的目标函数定义为:
其中,yi表示样本的实际标签表示模型的预测标签表示损失函数,Ω(f)表示决策树的复杂度:
其中,T代表当前决策树中叶子节点的个数,‖ω‖2代表每个叶子节点的权重的L2 正则化。经过t次迭代后,模型的预测结果可以表示为决策树所有预测结果的加权和,并且将目标函数进行二阶泰勒公式展开,并删除常数项:
其中gi、hi分别为预测误差对当前模型的一阶导数和二阶导数:
此时,令式(4)的导函数为0,可得到目标函数的最小值,以及各叶子节点的最佳值:
1.3 时间序列预测模型
时间序列格式的数据在各个时间点的属性间往往会存在一定的依赖关系,如何捕获其中的隐含的关系是处理时间序列数据的关键。近年来,机器学习模型中的深度神经网络在相关领域得到广泛应用,其中循环神经网络(Recurrent Neural Network,RNN)、长短期记忆(Long Short-Term Memory,LSTM)网络被用于对复杂序列数据进行建模[22]。目前疾病预测相关研究表明[6,23-24],使用LSTM 对时序格式数据的处理能够起到较好的效果,另外也有其他研究指出Transformer 在时序任务中的表现良好[25]。但本文的二阶段模型涉及2 个风格迥异模型的匹配,综合考量后选取更为基础的功能模块、更少更为纯净的LSTM。因此本文采用长短期记忆网络来处理长时间序列下的模型预测。LSTM是基于循环神经网络改进后的深度神经网络模型,用于处理相对较长时间间隔的序列数据[23]。一个LSTM 结构在当前状态为t时包含以下元素:输入信息xt、隐藏状态ht、细胞状态ct、输入门it、输出门ot和遗忘门ft,图2 为LSTM 单个神经元结构。3 个门、细胞状态以及隐藏状态的计算过程分别如式(7)~式(11)所示:
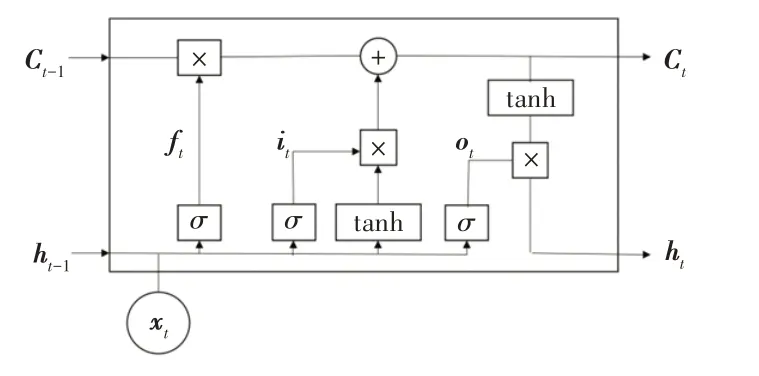
图2 LSTM单个神经元结构
其中,W和b分别为各单元结构的待训练参数矩阵和偏置项;σ为Sigmoid 函数;ht-1和ct-1为上一时刻的记忆体和细胞状态。
2 基于异质属性融合的疾病二阶段模型框架
如前所述,EHR 数据来源广泛,直接对类别型属性进行数值转换则会丢失信息,因此如何处理数值型属性和类别型属性组合形成的混合类型属性成为关键问题。
在进行疾病预测时,本文引入EBDM 算法对数据本身存在的混合类型属性进行处理,为数值型属性和类别型属性统一处理;考虑到不同属性在获取难度和成本的不同,在进行完整的细粒度模型预测之前,根据部分时间点数据和较易获取属性在模型的第一阶段对数据样本进行初次筛选,目的是尽量筛选出数据样本的阴性样本(非患病样本),让部分患者不用进行后续其他的检查项目,减轻患者的经济负担;然后,经过第一阶段模型筛选后的数据样本,则进入第二阶段模型进行再预测,尽量提高对患者预测的针对性。整体二阶段模型的具体方法框架如图3所示。

图3 二阶段模型具体框架图
2.1 基于熵的距离度量与异质属性融合算法
设有数值型属性和类别型属性混合的数据集X={x1,x2,…,xN},其中xi表示第i条数据,d表示数据集中所有的属性,且假定在全部的类别型属性中,定序型属性在前,定类型属性在后,分别由Aord和Anom表示,而数值型属性表示为Anum,因此显然d=Anum+Aord+Anom成立。
数据集中的具体类别型属性Ar的可能值用一个类别集Pr={Pr( 1 ),Pr( 2 ),…,Pr(οr)}来表示,其中οr表示属性Ar的具体类别个数。
对于一个合理的定序型数据进行距离度量,数据之间的距离应该与一个定序型属性的有序类别之间的顺序关系一致。在进行距离度量时,每个定序型属性的具体可能值数量不同会影响到自身与其他数据样本之间的距离度量。因此,进行2 个样本之间的距离度量可以转化为2个样本的具体属性的可能值之间的距离度量。从信息论的角度考虑,熵值越高代表信息量越高,用熵值来度量属性之间的距离是合适的。
对于定序型属性,在度量属性不同可能值之间的距离时,要考虑位于当前可能值排序之间的其他可能值的距离;对于定类型属性,由于每个类别之间都是相对独立的,则只考虑当前可能值之间的距离。
综上所述,给定一个只具有d个类别型属性的数据集X,2 个类别属性Pr(i)和Pr(j)之间的距离dist 由式(12)所示:
其中,w代表的是属性在参与距离度量时的权重,由属性Ar的可靠性RAr于全体属性中的可靠性占比决定,可靠性越高的属性,提供的权重就越大:
可靠性RAr则表示属性Ar所包含的最大信息的百分比,由属性Ar所有可能值的信息熵之和EAr可能值个数οr所决定:
CAr(s)为属性Ar的具体可能值s对应个数,N为全体样本个数。式(12)展示2 个类别属性之间的距离,而2个只含类别型属性样本之间的距离则由下式表示:
由式(16)可以看出,EBDM 算法采用距离度量的形式,可将类别型属性转化为数值型属性的过程中丢失的信息保留下来。此时将数值型属性加入式(16)中,即可得到异质属性融合的距离:
异质属性融合方法将带有异质属性的数据样本中隐含的信息进行更进一步地挖掘,有利于提升后续模型预测精度。
2.2 基于非时序数据的第一阶段模型
第一阶段模型的主要功能为在只提供部分属性和部分时间点数据信息的情况下,提高模型对于正样本的敏感性。如果样本在第一阶段模型中被错误排除,在实际情况中将导致至少一位可能的病患无法得到后续及时的治疗。因此,第一阶段模型的功能要保证模型对于正样本有更高的敏感性,且也要具有一定的筛选分流效果。为了提高模型对正样本的筛选能力,即使得模型在预测时对正样本更为敏感,本文从模型的损失函数上对待预测的正负样本类型权重进行调整。
对于一个二分类任务,其单个样本对应的损失函数如公式(18)所示:
其中,y为样本对应的真实标签̂为模型经过Sigmoid函数映射输出的结果,λ为正样本在参与损失函数计算过程中的权重。
此时,令公式(18)对̂分别求一阶偏导和二阶偏导,结果如公式(19)、公式(20)所示:
从公式(18)~公式(20)可以得出,模型对于正样本在计算损失函数的梯度和二阶导函数从1 调整为λ,使得模型对于正样本预测结果具有一定可调节性,而这从另一方面可以保证模型对于预测为阴性的结果具有更高的谨慎度,尽量降低第一阶段模型对于正样本的误判结果。因此,通过调整λ 来控制模型对相应样本的筛选能力。
2.3 基于时序数据的第二阶段模型
第二阶段模型的功能为对第一阶段模型进行筛选后剩余的疑似患者进行更为准确的模型预测。
经典的深度神经网络,如MLP、CNN 等网络模型,是无法记忆之前时间步状态的。因为本文的输入数据是多变量时间序列数据,所以首先考虑利用RNN,它是具有反馈连接循环网络,可以记忆一定的顺序模式。RNN 与经典深度前馈神经网络的最大区别在于它是可以学习时间依赖行为的记忆模型。然而,由于梯度消失的原因,RNN 虽然能够学习到数据中短期信息,但依然难以捕获到数据中的长期记忆。因此,LSTM 作为以RNN 为基础的更优模型,可以捕获到不同时间点之间隐含的信息。
设经过异质属性融合后的全时序数据集为,显然有是fusion,表示异质属性融合,tN为输入数据的最大步长。此时数据格式为具有tN个时间步的全属性样本,假设单个时间步的经过异质属性融合后的维度为d,数据集大小为N,此时整体数据集格式为[N,tN,d]。设LSTM 的步长为tN,输入维度为d,图4 为第二阶段模型的运行示意图,其中FC为全连接层,取模型最后一个时间点的输出作为预测结果。

图4 第二阶段模型的运作
2.4 算法整体描述
综合上述二阶段模型的伪代码以及异质属性融合方法的具体算法步骤如下所示:
输入:带有N个时间步的异质结构数据集XtN,对于每个时间点t,其数据样本按照数值型和类别型属性可以分为和。
1)选取时间节点k,将t1到tk对应的数据集Xt1,…,Xtk中数值型属性取平均值,类别型属性取出现频率最高的可能值,构建新的数据集Xs,Xs为全体数据集合XtN的前k个时间点中只拥有人口统计学信息和生理指标属性的子集。
2)分别把Xs和XtN中每个时间点进行经过异质属性融合处理,将其转变为对应异质属性融合后的数据集。其中,Xs将转化成异质属性融合后的数据集,单个时间点的数据集Xt转化成异质属性融合后的数据集
3)将输入第一阶段的XGBoost模型进行训练,同时调整正样本的权重以提高XGBoost 模型对正样本的筛选能力,得到第一阶段模型的初筛结果
4)根据第一阶段模型的输出结果,对其中预测为正的样本(即患病样本)进行细粒度的预测,将其对应在数据集中的样本提取出来,输入到LSTM 模型进行预测,预测结果为
3 实 验
3.1 实验数据集来源
本文使用的数据集是重症监护医疗信息市场(MIMIC-III)数据库[26]的1.4 版本。MIMIC-III 数据库为研究危重疾病的主流公开数据库之一,该数据库由2001年—2012年间马萨诸塞州波士顿贝斯以色列女执事医疗中心的53423 份ICU 记录(16 岁及以上)组成。数据库中含有丰富的异质属性,对于每个ICU病例记录,平均记录4579个生命体征和380个实验室测量数据。作为ICU 危重疾病之一的脓毒症,其病因复杂,且确诊需要耗费不少时间,而通过及时干预的方法,可以在患病早期挽救患者的生命[27]。本文根据脓毒症3.0 的定义筛选出11325 条第一次进入ICU的病人24 h 内的样本数据[28],其中患有脓毒症样本5778条,非脓毒症患者5547条。
3.2 实验预处理
本文按照人口统计学信息、生理指标、实验室测量结果3 个方面选取属性。每个样本均有24 个时间点,对于数值型属性,取1 h 内的该属性的平均值代替在当前时间点的值。而类别型属性,则取出现频率最高的可能值,然后删除缺失值过多的属性。剩余属性的缺失值采取以下处理方法:首先使用前向填充的方法进行填充,填充后仍有缺失值的,如果是数值型属性,则根据所有时间点的平均值进行填充;类别型属性则使用后向填充的方法进行填充,进行上述步骤后完成数据清洗。数据清洗后共有28 个属性,各属性情况如表1 所示。考虑到实验室测量指标比生理指标的缺失情况要更为严重,因此只保留进入ICU 的病人24 h 内含全部生理指标且至少出现记录一次的样本,最终筛选出10417 条样本,其中患脓毒症样本5192条,非脓毒症样本5225条,总体上正负样本的分布接近1:1,数据清洗前后样本分布如表2所示。
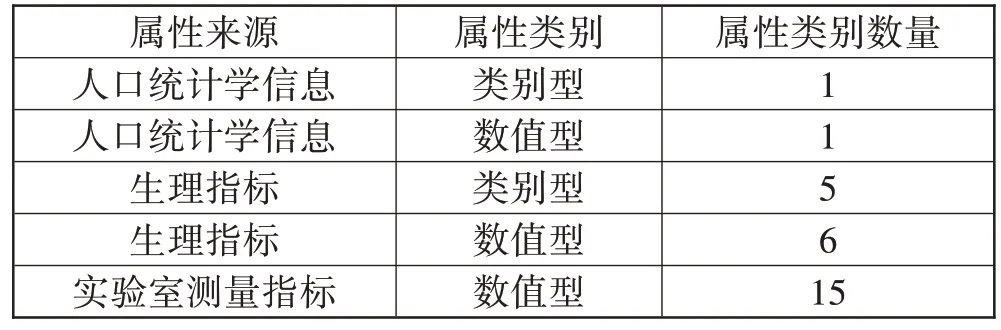
表1 样本属性信息
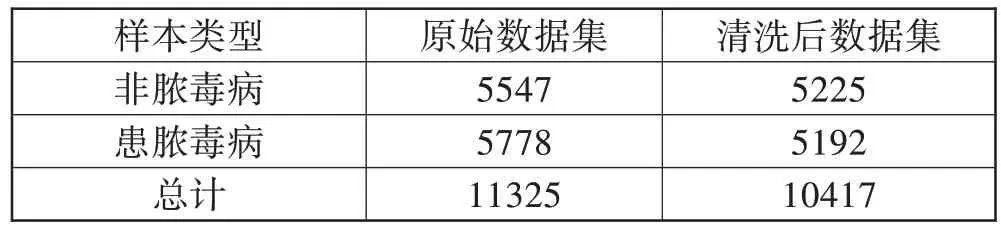
表2 样本分布
3.3 运行环境
实验使用的主要工具版本为Python3.8.5、Pytorch1.9.0、 Numpy1.20.2、 Pandas1.2.5、 Scikitlearn1.1.1。 Linux 服 务 器 硬 件 信 息:CPU 为AMD7386,GPU为RTX3090,内存为24 GB。
3.4 评价指标
本文使用10 折交叉验证的方法,且评估模型性能所使用的性能指标包括:ACC、AUC(Area Under Roc Curve)和F1-Score,实验结果取10折的平均值表示。另外,为了评估第一阶段模型起到的初筛能力的强弱,初筛能力由公式(21)所定义。
其中,Xneg为第一阶段模型预测结果中预测为负的样本数量,N为参与预测的所有样本数量。第一阶段模型所筛选出的阴性样本越多,则认为模型的初筛能力越强。
3.5 实验设计
本文主要设置3 类核心实验:1)通过不同非时序模型与异质属性融合方法的组合进行实验,验证异质属性融合方法与XGBoost 模型结合的有效性;2)基于XGBoost_Fusion 作为第一阶段模型,比较Transformer与LSTM 模型的实验结果,调整该模型的正样本类型权重,研究模型在筛选能力与预测精度之间的整体最优情况;3)以不同时间点构造第一阶段模型的输入数据,用于说明选取前6 个时间点构造的非时序数据可以较好兼顾模型的需求。
3.6 非时序模型实验结果
选取前6个时间点构造非时序数据集。表3为非时序模型实验结果,可以得出XGBoost+Fusion 组合的AUC指标可以达到最优的情况。
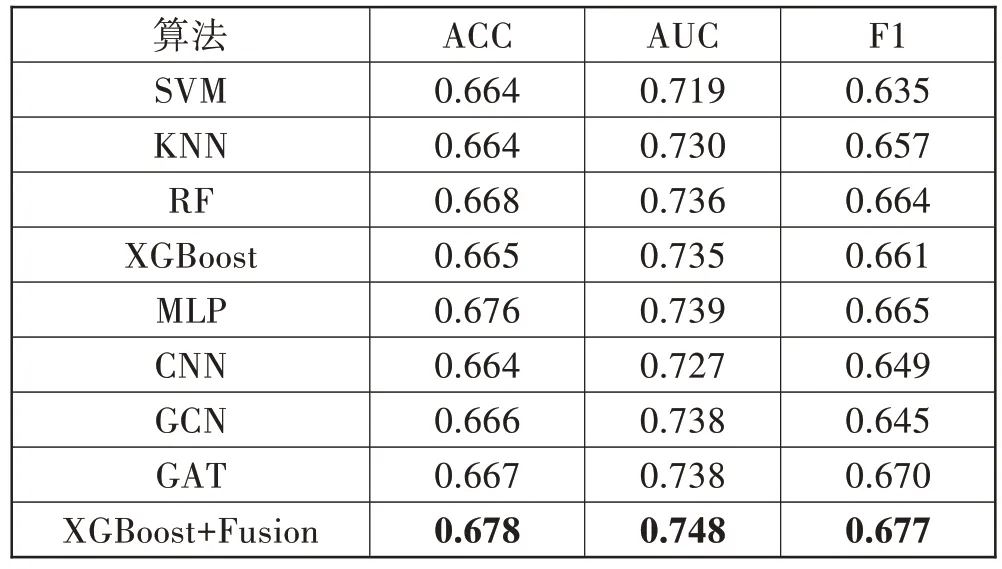
表3 非时序模型实验结果
3.7 整体模型实验结果
根据3.6 节的非时序模型的实验结果,本节实验选取XGBoost 与异质属性融合的组合作为第一阶段模型的输入,并比较第二阶段模型分别为Transformer与LSTM 时的预测结果。第一阶段模型的输入同样取前6 个时间点的数据构造的非时序数据,实验结果如表4所示。
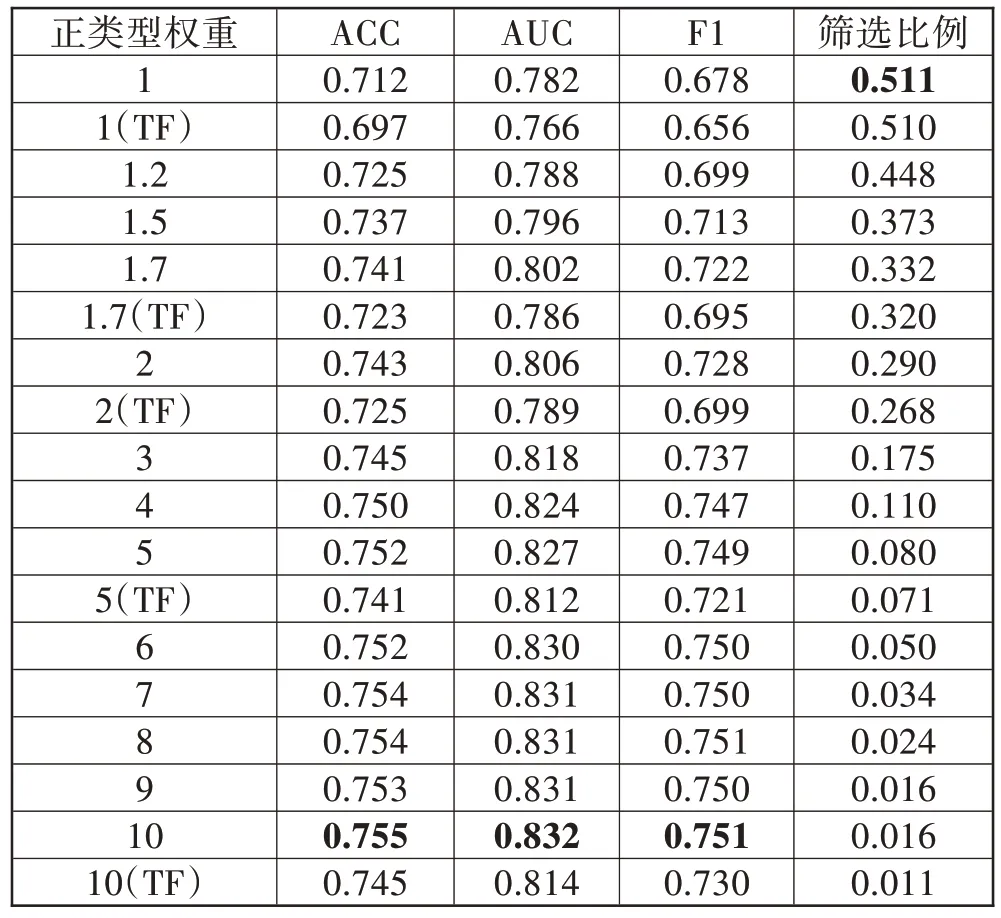
表4 不同正样本类型权重下模型实验结果
可以看出,Transformer 模型与LSTM 模型结果存在一定的差距。随着正样本类型权重的提高,导致模型对于正样本的挑选能力在上升,模型的筛选比例在下降,说明第一阶段模型筛选样本能力下降,进入第二阶段模型的样本在增多;而随着进入第二阶段模型的样本数量增多,模型训练接受的样本也随之增多,其预测精度也有所上升。为了衡量模型的整体性能,本文使用公式(22)来表示整体模型的效能。
其中,prop表示模型的筛选比例,α、β以及ψ分别是模型精度、筛选比例各自对应的权重以及两者与权重结合的综合评价的指标。考虑到模型精度的要求在一般情况下要更为重要,以及部分医生的参考意见,本文取α和β分别为0.9 以及0.1,并按照此参数设置进行实验。图5、图6、图7分别为预测精度变化曲线、筛选比例变化曲线以及综合指标变化曲线。从图7 可以得知,当正样本类型权重取1.7 左右时,ψ达到最大值0.7127,此时模型可以通过第一阶段的初筛结果筛选出33.2%的病人。

图5 预测精度变化曲线

图6 筛选比例变化曲线
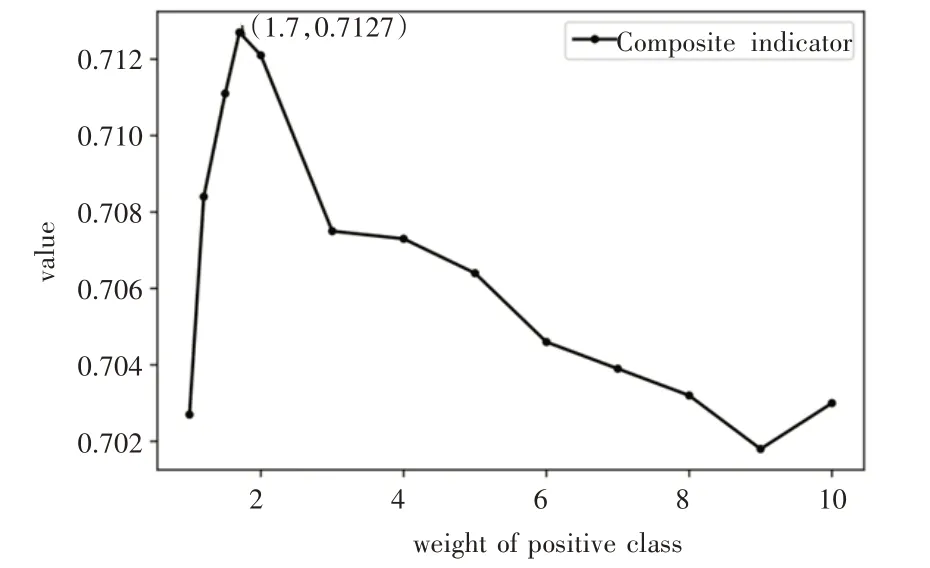
图7 综合指标变化曲线
3.8 一阶段不同时间点取值实验
选取前k个时间点构造非时序数据集,验证时间点选取对模型的影响,实验结果如表5所示。k=24时与k=6 的实验结果相差较小,考虑到非时序数据的构造需要一定的提前性,可以认为取k=6 以保证模型对疾病预测有一定的提前性。

表5 不同时间点构造的非时序数据的实验结果
4 结束语
针对医疗资源稀缺和EHR数据中广泛存在异质数据类型的特点,本文提出一种基于异质属性融合的二阶段模型框架对脓毒症病人进行提前初筛和预测。该方法结合基于熵的距离方法来实现异质属性之间的信息融合,同时通过部分属性以及部分时间点数据和调整正样本的权重方式,使得模型能够提前筛选掉较低概率是患者的样本,也使得部分样本不用进行后续的检查项目,降低患者的经济负担;然后对于剩下的样本,则进行全时序全属性的预测。二阶段模型的框架综合考虑疾病诊断中的患者的经济负担和预测精度,在面对一些需要耗费高成本来诊断的疾病时可以兼具多个方面的需求,在实际应用环境中存在一定的研究价值。
