基于改进粒子群算法的LM神经网络模型预测爆破块度
2024-03-04马炳德张雄天赵尔丞
马炳德,张雄天,赵尔丞
(兰州有色冶金设计研究院有限公司,兰州 730000)
矿山开采过程中,不同性能的炸药和爆破设计参数的爆破过程和破碎效果会有很大差异。因此,爆破设计参数与岩石相对应的炸药及其装药量决定了矿山深孔爆破的效果[1]。矿岩爆破块度是定量评价爆破质量的重要指标,它直接影响到矿山各后续生产工序的效率和采矿生产的总成本[2]。国内矿山经常会进行深孔爆破,导致岩石破碎率高,因此有必要优化采场爆破参数。在参数优化过程中,若能预测爆破块度,不仅可以事先预估参数优化效果,还能排除不合理的优化方案,对深孔爆破参数优化方案具有重要的指导意义[3-5]。
矿岩爆破效果主要受到岩体力学特性和爆破设计参数的影响,这两者之间存在着复杂的非线性关系,因此很难通过函数关系计算来预测爆破效果。针对上述问题,论文选择了粒子群优化算法优化的爆破神经网络来预测爆破效果。
1 相关算法
1.1 PSO 算法
粒子群算法(Particle swarm optimization,PSO)由 Kennedy 等提出,是一种全局随机搜索算法,其模拟了鸟类觅食的行为[6-8]。算法用Xi=(xi1,xi2,xi3,…,xin)和Vi=(vi1,vi2,vi3,…,vin)来表示粒子i的信息,其中Xi为位置信息、Vi为速度信息。在迭代过程中,粒子会根据个体极值pbest和全局极值gbest不断更新自己的位置和速度。当粒子找到pbest和gbest后,便会按照式(1)、式(2)对其位置和速度进行迭代更新
(1)
(2)
式中,w为惯性权重;c1、c2为学习因子;rand1、rand2为分布在[0,1]区间上的随机数;t为迭代次数。
由于 PSO 算法的全局寻优能力与收敛速度存在一定的局限性,为提高算法性能,论文对PSO的惯性权重w进行改进,建立改进的粒子群算法。在刚进入迭代时通过较大的权重扩大算法搜索范围,在迭代末期将权重减小来提高收敛精度,改进的惯性权重如式(3)所示。
(3)
式中,wmax、wmin分别为惯性权重最大值和最小值;t、T分别为当前迭代次数和最大迭代次数。此外,为防止迭代陷入局部最优解,引入变异思想,通过自适应变异概率对进行变异操作的粒子数量和变异尺度进行调整,即用概率值来控制粒子变异的频率。自适应变异概率函数如等式(4)~式(6)所示。
(4)
(5)
rand>β
(6)
式中,α为进行变异粒子的粒子数量;n为粒子总数;[x]表示取整;β为概率数值;rand为分布在[0,1]区间上的随机数,rand>β为自适应变异概率公式。通过自适应变异概率公式来控制变异粒子数量,这样处理不仅可以保持种群多样性,还能够对搜索范围进行不断修正,防止算法出现“早熟”问题。
1.2 LM神经网络
LM 算法综合了梯度下降算法及高斯-牛顿方法的优点,克服了传统基于BP(Back Propagation)神经元网络收敛速度慢且容易陷入局部最优的缺点。因此,针对BP神经元网络的不足,提出了一种改进的LM优化算法,更为准确地预测爆破设计参数与爆破粒径值之间的关系。该LM算法的神经网络模型包括输入层、隐含层、输出层。图1为最基本的LM算法神经网络结构[9]。

2 输入输出层及隐藏层神经元的节点数的选择
影响爆破块度分布的因素众多,且他们之间难有数学表达式建立起关系。如何从众多影响因素中选择主要影响因素,在保证数据可靠的基础上尽量地简化模型又不降低模型预测的精度是建立模型前要慎重考虑的问题[10]。论文对模型进行了以下简化:
1)在爆破工艺和爆破参数上,结合矿山现有设备,该模型只考虑了规则布孔、均匀装药、用导爆索微差起爆的简单爆破工艺,同时也是矿山常见的爆破工艺。
2)对于装药时炸药是否和爆破岩体耦合、能否充分利用爆破能没有充分的考虑全面;同时,在施工进行的过程中,很多人为因素和设备因素的不确定性也很难完全考虑到。
输入层神经元参数的选择:台阶高度、钻孔直径、孔距、排距、最小抵抗线、阻塞长度、炸药单耗共7个因素作为神经网络模型的输入层,所以输入层共有7个神经元。输入数据如表1所示。
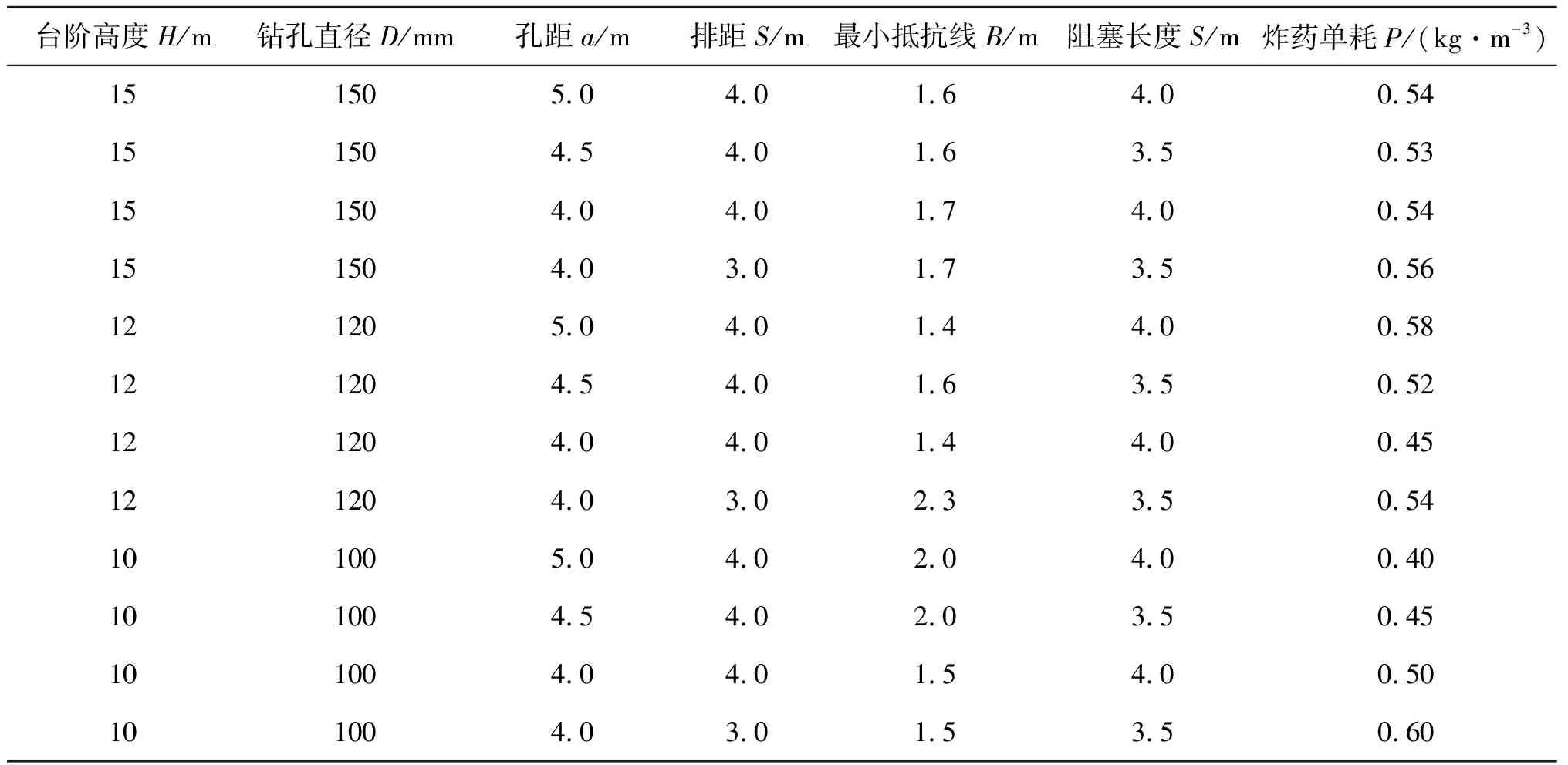
表1 模型输入数据
输出层神经元参数的选择:输出层设定一个神经元,即大块率。
隐含层神经元参数的选择:确定隐含层节点数在神经网络设计中是一个非常重要的步骤。神经网络具有三个层,且隐含层节点数目无限的神经网络可以构建任何其他类型的神经网络。在选择隐含层节点数目时需注意,如果隐含层节点数目过少,神经网络将无法建立复杂的映射关系,从而导致网络的预测误差较大。但是,如果节点数量过多,神经网络的学习时间将会增加,并可能导致出现“过拟合”现象,即对训练样本的预测准确,而对于其他样本的预测误差较大。
目前还没有理论上的隐含层神经元计算公式,实际使用的过程中一般先根据经验公式(7)。
(7)
式中,n为输入层节点数;l为隐含层节点数;m为输出层节点数;a为0~10之间的常数,这里n为7,m为1。

根据以上经验公式,通过不断的尝试,最后确定了隐含层节点数为10时,网络预测效果最理想。LM神经网络模型结构如图2所示。
LM算法对深孔爆破块度进行预测分析主要包括数据预处理、LM算法的神经元结构确定、PSO-LM深孔爆破块度预测分析等,具体步骤如下:
使用正交试验表2中的1~12组数据作为模型的训练样本集,试验因素作为网络输入因子,结果作为输出因子。同时,将表3中3组数据作为测试样本集,以验证模型的准确性。
不同因子的数值差异较大,因此为了防止神经网络出现过度拟合的现象,需要对提供的12组输入数据根据式(8)进行预处理,处理之后数值取值在[1,-1]之间。
x′=xmax-xmin
(8)
式中,x′代表处理之后的数据,值在[-1,1]之间;x、xmin、xmax分别代表初始的数据,输出数据中的最小值,输出数据中的最大值。
归一化处理后的训练集数据见表2,测试集数据如表3所示。
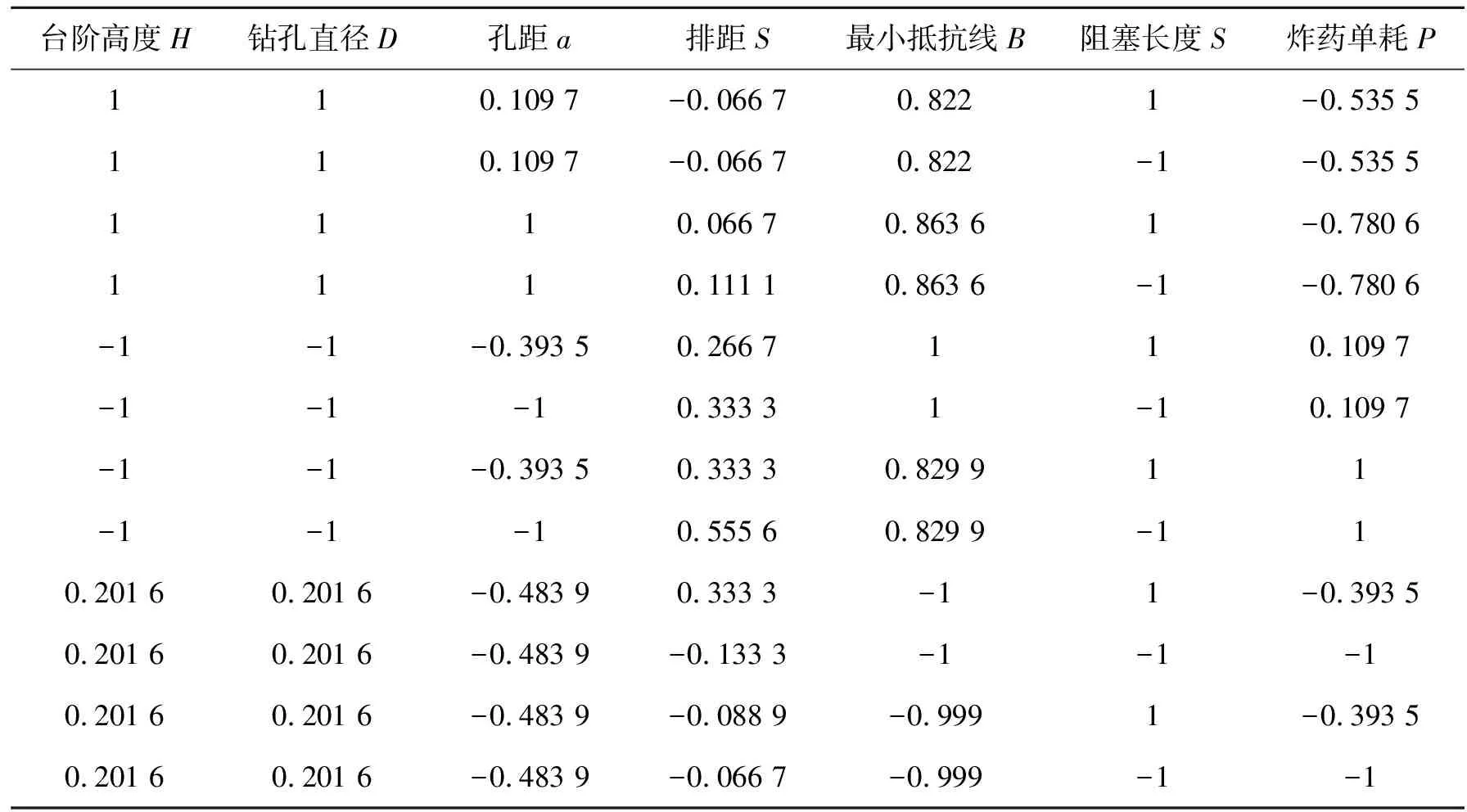
表2 训练集数据归一化处理

表3 测试集数据归一化处理
3)确定深孔爆破块度预测模型的LM神经网络结构。根据LM神经网络确定粒子在空间的初始位置和速度,设定粒子群优化的终止条件、迭代次数N、种群规模、惯性权重初值ω、加速因子初值c1、c2等,根据式(4)计算粒子的F(i),根据F(i)更新PiBest、PgBest,根据式(9)和式(10)更新粒子位置和速度,计算粒子新位置F(i),如果F(i)>PiBest,则F(i)替换PiBest,优化群体极值PgBest,每次迭代中根据式(9)和式(10)更新粒子的速度和位置,判断是否到达最小误差,如果满足误差要求则PSO优化终止。PSO优化终止之后,输出全局最优的粒子位置,获得最优的形变预测LM网络初始权值、阈值,开始进行公路平面竖向形变LM网络训练[11-13]。
(9)
D=(n+m)k+k+m

(10)
式中,n为输出节点数;yi为神经网络第i个节点的期望输出;oi为第i个节点的预测输出;k为系数。
4)输入深孔爆破块度预测训练样本,计算LM各层输出及误差,达到终止条件之后,获得深孔爆破块度预测模型。
3 工程案例分析
临江冷堡子硅石矿位于文县东北约32.5 km处,行政区划隶属文县临江镇管辖,从文县到矿区有212国道直达,交通十分方便。矿区地处南秦岭山地,海拔900~1 300 m之间,地形起伏较大,地貌类型属侵蚀构造中山区,山体坡度一般均在35°以上。经过对露天矿中小型设备的高强度开采技术进行系统分析和经验总结,发现优化孔距参数试验可以指导爆破效果与开采和装填设备相协调,从而达到爆破综合效果的最优化,进而追求经济效益的最大化。以下是探寻适合临江冷堡子硅石矿矿情条件下展开的工程试验[14]。
通过爆破试验,获得开挖爆破试验粒径筛分结果,并根据现场爆破设计参数,通过建立的神经网络模型,预测爆破块度平均值,并与实测值分析比较。具体试验参数如表4所示。
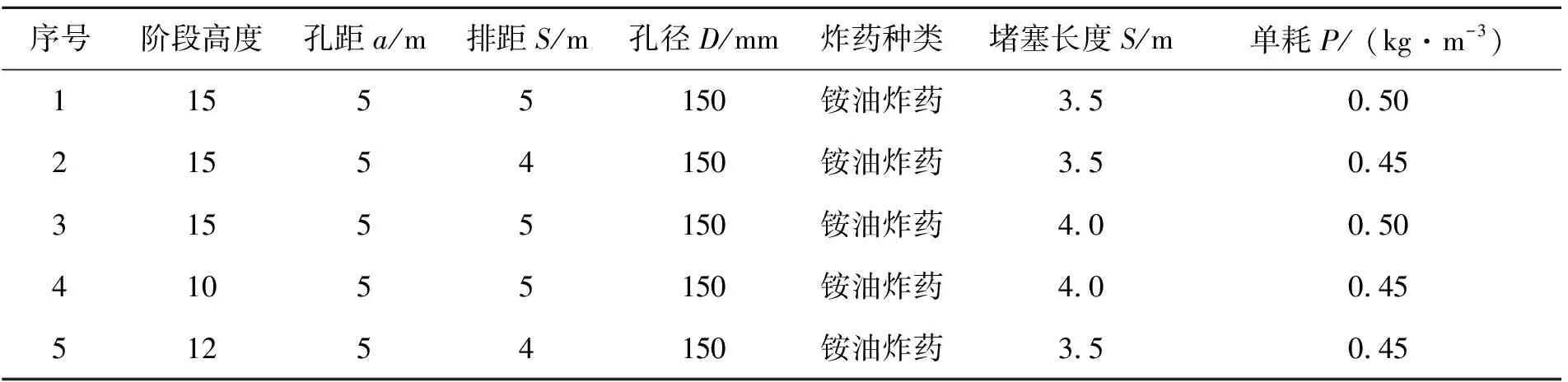
表4 爆破试验参数
根据冷堡子硅石矿开挖爆破试验粒径筛分结果,可得五组爆破试验的平均块度值分别为0.250 m、0.162 m、0.087 m、0.111 m、0.136 m。并由爆破试验参数,确定神经网络模型输入层的5个参数,如表5所示。通过对爆破训练样本集的爆破参数与爆破块度值进行回归分析,可知其爆破设计参数与爆破块度大小呈正相关,即爆破块度大小随爆破设计参数增大而增大;而炸药参数与爆破块度大小呈负相关,即爆破块度大小随炸药参数增大而减小。
为了验证所建立的改进粒子群算法的LM 神经网络模型的准确性,对其进行了测试,结果表明测试样本集的预测值与实测值误差很小(见表6)。
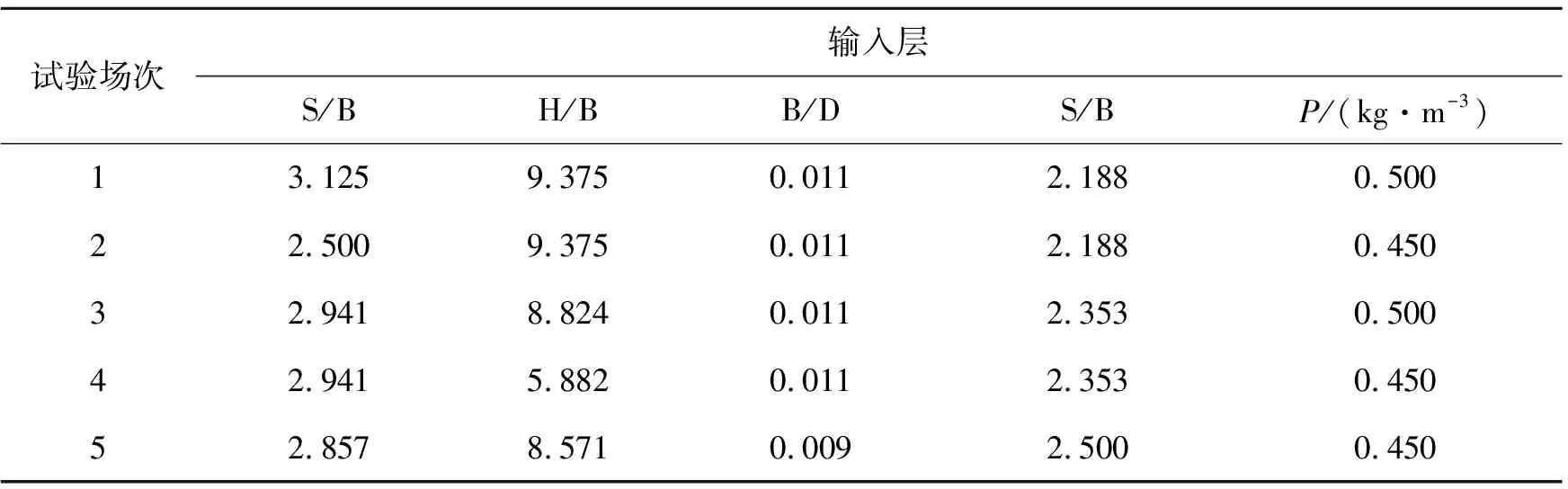
表5 神经网络模型输入层参数
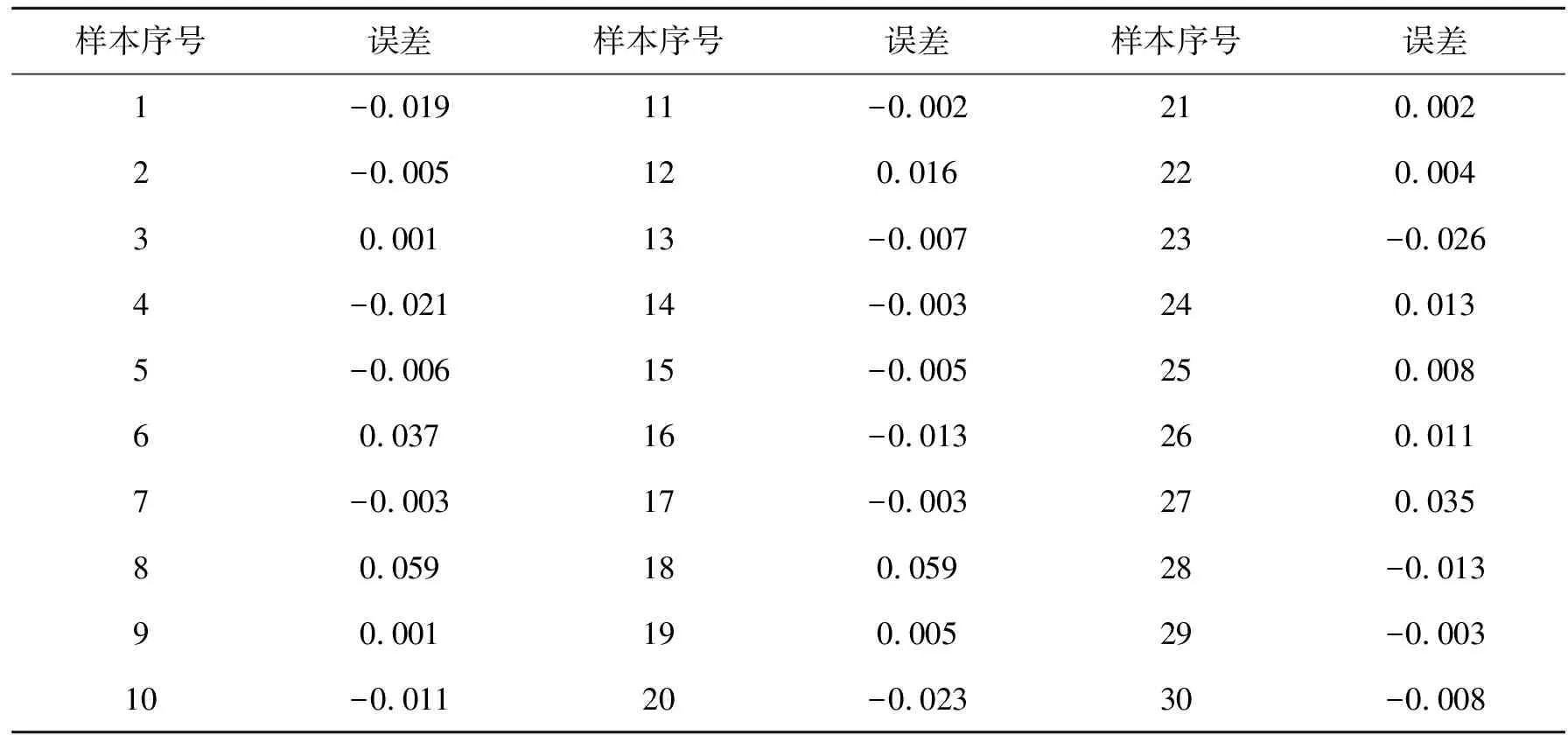
表6 LM 算法模型的测试样本集实测值与预测值的误差
由表6可知,改进粒子群算法的LM神经网络的测试样本集的预测值与实测值的最大误差绝对值为0.059 m,最小误差绝对值为0.001 m,测试样本集预测平均误差值为0.014 m,方差值为0.001;同时,测试样本集的最大误差百分比绝对值为21.13%,最小误差百分比绝对值为0.30%,平均误差百分比为4.12%,方差值为0.09%,其均方根误差为0.031。
4 结 语
改进粒子群算法的LM神经网络模型具有较高的准确性。所建立的神经网络模型通过爆破参数与爆破块度之间的定量关系,可准确地预测出爆破块度的大小值。通过调整其爆破参数,指导露天矿山高效节能开采,对工程爆破具有实践意义。
对临江冷堡子硅石矿现场爆破设计参数展开工程试验,分析改进粒子群算法的 LM 神经网络模型的测试样本集的预测值与实测值的误差,可得到真实值和利用粒子群优化LM神经网络算法得到的预测值之间误差很小。说明算法具有可行性,可以用来进行深孔爆破块度预测。
