基于跳聚集现象随机波动率短期利率模型的影响研究
2024-03-04张新军宋丽平
张新军, 江 良, 林 琦 宋丽平
(1.莆田学院 金融数学福建省高校重点实验室,莆田 351100;2.莆田学院福建省金融信息处理重点实验室,莆田 351100;3.莆田学院应用数学福建省高校重点实验室,莆田 351100)
0 引言
价格的跳跃是金融资产波动的一种重要特征,其归因于极端事件发生而产生的经济现象,如重大的政治事件、金融危机、中央银行的货币政策或一些自然灾害等外在因素,这种影响直接冲击标的物的价格呈现较大的波动。然而,极端事件在特定时间内发生的频率比较稀少,而且也是不可预测的,特别是因极端事件所产生累积风险(极端风险)在业界也是非常重要的课题。因此,研究极端事件发生的频率及其所产生的二次风险就显得非常有意义。
Merton[1]通过跳扩散模型来描述资产价格的跳跃现象,也就是极端事件发生通过跳的现象来描述,此时极端事件发生作为外生变量。虽然跳扩散模型能够度量极端事件发生的概率,也能描述金融数据的尖峰和厚尾特征[2]。虽然跳扩散模型能够显著地测度金融市场异常波动风险[3],但是应用跳扩散模型估计跳的频率较低,也不具有反馈效应[4],即重大极端事件不仅反映在当前价格的跳跃上,也会进一步影响次日或未来价格,从而导致预期资产价格产生跳跃的概率更高,而且在模拟跳的过程时会出现样本匮乏问题[5]。归咎于上述原因,应用跳扩散模型进行风险管理时可能无法有效地测度重大极端事件风险,进而导致缺乏有效的风险预警和防范措施。
对于具有跳的短期模型可追溯到Duffie 和Kan[6],他们讨论了跳对短期利率模型的影响,然而即使他们引入随机波动率模型,但是他们的模型无法描述跳的聚集现象,归因于常数跳的强度。近几年来,在跳扩散模型基础上,有大量研究者研究具有跳聚集现象的短期利率模型[7–10]。在这些文献中,跳的强度作为内生变量,依赖于短期率。因此,当短期利率较高时,强度也相应较大,在下一时刻具有较高的概率发生跳,反之,短期利率较低,跳发生的概率较小。这就有可能作为内生变量的跳强度在低短期利率时无法描述跳的聚集现象。Hainaut[11]引入Hawkes 过程研究具有跳聚集现象的高斯模型,其中跳是双指数跳,并通过设置阈值方法来度量大跳发生的可能从而给出极大似然估计。Rambaldi 等[12]通过Hawkes 过程研究外汇交易发现,引入Hawkes 过程能够很好地描述一些重大宏观事件对模型的冲击。张新军等[13]应用GMM(Gaussian Mixture Modeling)方法也引入Hawkes 过程研究短期利率模型,即使他们把强度作为外生变量,但是在他们模型中,波动率和跳的幅度是常数。近几年来,Hawkes 过程在许多领域得到广泛的应用归咎该过程具有自我激励机制跳的现象的性质[14],所谓自我激励机制跳是当跳发生时,相应的强度也发生跳,而且强度跳的概率和标的物跳的概率是一样的。即当估计到短期利率有一个大的跳跃发生时,相应跳的强度也有一个同样的概率发生跳,从而导致估计下一时刻跳的强度可能具有更高的概率,这就产生了跳的聚集现象。因此,本文将在随机波动率模型基础上,考虑具有自我激励机制跳的因素对于模型的冲击。
此外,国内少数学者也应用Hawkes 过程验证了不同金融市场之间风险传染性问题或协同跳跃现象[15–16]。马勇等[17]分析了我国股市异常波动(跳)的聚集现象,以及暴涨和暴跌相互作用的机制。陈淼鑫和徐亮[18]验证了基于Hawkes 过程所构建的模型能够更好地预测尾部风险问题,值得一提的是,他们也把期权作为辅助变量对跳的强度参数进行估计。上述文献实证研究的主要思路是在高频数据下应用结构化模型设定阈值分离出跳的样本数据,而后使用跳的数据独立地估计跳和跳的强度参数值,以此来分析因重大极端事件导致金融市场价格跳跃、传染性和协同跳跃问题。
综上所述,本文将考虑Gifford Fong 等[19]具有自我激励机制跳的随机随机波动率模型。事实上,Litterman 等[20]通过实证方法论述引入随机波动率状态变量的必要性。由于Gifford Fong 等[19]模型具有仿射性结构(高斯模型),因此在风险测度和物理测度下具有形式上不变性,甚至对于债券价格定价也具有这种性质[21]。因此,我们将主要考虑该类模型作为研究对象。Duffie 等[22]研究具有跳性质的仿射性结构模型的衍生品显示解。Filipovi´c 等[23]推导了跳的仿射性结构模型转换密度函数的显示表达式,而后给出了可行的参数估计方法。郑挺国和刘金全[24]基于高斯和非高斯模型也给出具有跳扩散模型的参数及和统计推断,在他们的结论中随机波动率对短期利率影响比较大。然而上述的模型都无法刻画跳的聚集现象,因此有必要引入新的状态变量来度量跳的聚集现象问题。对于引入随机跳的强度是为了使模型能够刻画跳的聚集现象,虽然本文的模型可能产生负的利率(对于所有高斯的模型这种现象都是无法避免的),但是短期利率动态变化不需要任何约束条件,相应的离散格式无需考虑负值的出现甚至可能相应的衍生品价格具有显示解或半显示解,同时由于没有约束条件,参数估计也变得相对简单。基于本文所构建模型是在跳扩散模型基础上建立的,又因为跳扩散模型是一个Cadlag 过程,该过程具有有限次大跳(也可以描述无限可数小跳),因此相应的极大似然函数可能没有显示的解,而且极大似然估计方法需要有效且每一个具体的矩函数。根据Cont 和Tankov[25]论述广义矩方法具有鲁棒性和有效性,并且在矩函数有限的条件可保证收敛性。鉴于此,本文将基于条件期望、无穷小生成元及微分算子等理论,利用微分算子Taylor 展开到二阶项计算矩函数,而后应用GMM 方法给出模型的参数估计和统计推断。
本文主要的贡献为:
1) 本文模型延拓了张新军等[13]模型,考虑跳的幅度和波动率都是随机模型,因随机波动率是短期利率非常重要的特征;
2) 即使模型是三因子,但应用微分算子展开技巧,仍能精确地计算出矩函数,因此可使用经典数值计算方法提高其精度;
3) 实证结果表明,引入Hawkes 过程能更好地刻画数据跳的问题,同时也能够说明在一些重大事件发生时对短期利率的影响,而且也论证了比较跳的模型,本文的模型能够描述更多跳的次数。因此,本文的研究结果能够为化解和防范金融市场上极端风险提供理论和技术支撑。
1 自我激励机制跳的模型
首先,考虑下面随机波动率短期利率模型(FVJHJ)

根据Poisson 过程定义,有
其中λt表示跳的强度或表示在单位时间内跳的次数。这里忽略高阶项,即考虑在区间(t,t+dt]内只发生一次跳的概率事件。
注意引入跳的模型,主要原因是希望短期利率大的变动不仅是受到波动率而且也受到跳的影响。事实上,A¨ıt-Sahalia 等[26]已经说明单纯考虑扩散过程是无法刻画一些宏观经济现象对收益率所产生的影响,如金融危机等一些因素。另一方面,根据Eraker 等[2]的结果,若引入的跳的模型,Q-Q 图显示相应的残差更趋近于正态分布,而且A¨ıt-Sahalia[27]也提出,当使用高频数据时,跳可能性非常大,特别是每天交易的数据。因此,考虑跳的短期利率模型。
FVJHJ 模型的跳具有自我激励的机制跳,因为当短期利率有大的价格变化时,这种现象来自于一个大的波动率和一个大的跳相互影响。由于大的跳影响到一个大的跳的强度,从而预测下一次跳的可能性变的更大。而且根据自我激励的机制跳的性质,跳更有可能在一段时间内多次的发生,从而产生跳的聚集现象。注意若使用常数跳的强度这种现象是很难预测的[26],因为常数强度模型在整个时间段内跳的平均次数是一样的。
由于Litterman 等[20]和Durham[28]都通过实证说明,引入随机波动率模型不仅改善了模型的拟合效果,而且也能描述短期率期限结构的变化。因此,本文主要集中在随机波动率模型研究跳的问题。作为一个结果,在随机波动率基础上,当b= 0 时,模型记为FVJ,Das[29]已经研究了这个模型。
2 参数估计
为了给出FVJHJ 模型的参数估计,首先假设
其中λ∗是λt的无条件期望值,相应精确的表达式将在下面部分给出。式(1)可转化为
随机微分方程(5)变成了由三部分组成,即常数项、纯粹的扩散和跳的过程。此时,关于dyt的无条件期望为零,即Edyt= 0。因此,对于参数估计可以采用两步估计:第一步,先通过样本给出了漂移项的参数θ∗= (aθ+µ0λ∗)和a的估计;第二步,给定第一步所获得参数估计、估计扩散和跳的参数,而且这个估计过程是相容的。通过短期利率rt的样本数据,应用最二乘法可以获得(θ∗,a)的估计值。事实上,当给定参数(a,µ0,λ∗)估计值时,估计θ∗等同于估计θ。因此,参数估计问题集中处理关于参数(µ0,σ0,α,β,κ,µ,b)的估计问题。事实上,Ruiz[30]也使用该思想估计随机波动率模型的参数问题。
通过线性的转化相应的模型(5)完全等价于A¨ıt-Sahalia 等[26]所论述模型。虽然,A¨ıt-Sahalia 等[26]通过协方差密度函数给出相应的高阶近似表达式,然而当扩散项是非线性时,相应协方差密度函数不一定有精确的表达式。因此,本文将通过随机微分Taylor 展开给出相应高阶近似。
为了给出参数的估计值,本文将选择GMM 方法给出模型的参数估计和统计推断。由于GMM 只需要给出精确的矩函数,相应的参数估计是相容的。事实上,也不难看出,如果使用极大似然估计方法很难给出似然函数显示表达式,归因于似然函数需要对隐含状态变量积分,而且极大似然方法一个重要的假设是边界分布为正态分布,而在我们的模型中这个假设可能不成立,归因于跳的过程。因此,选择GMM 算法做为估计的方法。
2.1 矩函数表达式
根据GMM 估计方法,要使参数估计值具有相容性性质,一个必要的假设是正交条件,这就需要对矩函数给出精确的表达式。因此,下面将给出矩函数的具体表达式。
首先根据A¨ıt-Sahalia[27]论述,引入算子
其中P(·)表示跳幅度的概率测度。根据Stanton[31]论述,所有矩函数可以通过算子展开计算。设At=(yt,Vt,λt),有
其中Et[·]表示在给定At条件下的期望。注意当没有扩散项和跳时,式(6)是标准的多维Taylor 展开。若只保持一阶项,式(6)可写成
根据式(7),直接可得
显然,从式(8)矩函数可知,若使用一阶近似,随机波动率的一些参数以及随机跳的强度参数是无法估计的。进一步计算峰度
当不考虑跳模型,应用一阶近似计算峰度为零,这和现实不符。当应用式(14)二阶展开,仍然不考虑跳时,相应的峰度为3,为高斯模型的峰度。这些结果说明,考虑一阶近似不仅一些参数无法估计,而且可能也会失去一些样本的统计信息,因此有必要考虑算子的二次展开。
为了解决上面问题,先给出Vt、λt的条件期望。
定理1 假设λt是平稳的随机过程,有
其中λ∗=(κµ)/(κ −b)。相应的二阶矩为
注1 这里忽略定理的证明,详细的证明方法可参考文献[10]。关于λt非条件期望为E[λt]=λ∗。当b=0,即跳的强度没有跳时,式(3)变成跳扩散模型。λt的无条件二阶矩为
现在考虑式(8)的二阶近似。根据式(6),需要二次的展开,即
式(11)成立的条件是算子的高阶展开是有界的。为了简化,设δ= Δt,假设在时间段δ内只发生一次的跳。根据式(7)和式(11),有下面的定理。
定理2 假设随机过程λt和Vt是平稳的过程。矩函数(8)有下列精确的表达式
证明 为了证明式(12),设f(y)=(y −yt)2,因此有
根据式(7),有
现在考虑算子的二次展开。设gt=Lf(yt)δ,根据式(7)相应的二次展开为
上面最后一个等式成立是通过设f1(y,λ) =λ(y −yt),然后应用式(7)获得。最后,再根据式(11)和随机过程Vt、λt的平稳性,可得
应用定理1,式(12)直接获得。
为了证明式(13),设f(y)=(y −yt)3,则有
对于二次算子,有
根据上面的推导,三阶矩相应的无条件期望为
应用定理1,式(13)直接可得。
最后,证明四阶矩函数,设f(y)=(y −yt)4,有
相应的二次展开为
根据定理1 的结果,直接可得式(14)。
注意到,由定理2 可知,使用高阶矩(三阶和四阶)可以估计随机波动率的波动率,而且也可估计跳的参数。这个结论和A¨ıt-Sahalia[27]所论述的结果是一样的。在他的文章,作者建议使用高价矩来估计跳的参数,而低阶矩是估计扩散的参数。
基于GMM 算法,定理2 所给的矩函数的个数仍小于参数的个数。因此,将引入协方差矩。由于EΔyt=EΔyt+τ=0,自协方差函数
定理3 若定理2 的假设条件满足,进一步假设τ ≥δ >0,有下面自协方差矩函数
证明 首先考虑下面的矩函数
根据式(17)结果可得,现在我们回到计算自协方差
最后,根据定理1,定理3 结论成立。
为了给出平方的协方差,首先需要考虑下面的二阶矩函数
类似有
又因为
结论成立。
根据定理3 的结论,显然自协方差刻画了随机强度的参数。但如果跳的幅度均值为零,即EJt= 0,此时需要平方协方差矩来刻画随机强度的参数。而且也发现,平方协方差矩函数把跳强度和随机波动率的参数分离出来,意味着平方协方差函数能够作为识别波动率和自我激励机制跳的重要参考指标。当波动率是确定而非随机过程时,此时自协方差和平方协方差矩完全描述了自我激励机制跳的过程,因此高阶矩函数可以描述跳的过程。
2.2 GMM 估计方法
为了简化,设Θ= (µ0,σ0,α,β,κ,µ,b)为模型的参数向量,且Θ ∈Ω,其中Ω表示参数向量的可行域。考虑M维的矩列向量g(y,δ,Θ),且M ≥dim(Θ)。众所周知,GMM算法一个重要假设是正交条件,即若Θ0是真实的解,其一定满足E[g(yn,δ,Θ0)] = 0。由于在定理2 和定理3 中已经给出了矩函数的精确表达式,只需要把定理2 和定理3 中的矩函数等式右端移到等式的左端,此时正交条件即可满足。
接下来,我们将简明扼要地给出GMM 算法过程。设ˆg(yn,δ,Θ)为样本矩函数的平均值,即
基于GMM 算法对于参数向量的估计为
其中WN是权重函数且是M×M正定矩阵。关于最小化(19)解一阶必要条件(正交条件)为
其中D′(Θ)是关于ˆg(yn,δ,Θ)的Jacobian 矩阵,注意这里WN事先给定。
沿着A¨ıt–Sahalia 等[26]、Newey 和West[32]的思想,假设S是一个渐进协方差矩阵,定义为
进一步,假设S−1是WN的相容性估计,而ˆS是S的相容性估计,可设WN= ˆS−1作为最优选择的权重函数。协方差函数定义为
众所周知,对于S一个有效相容性的估计为Newey-West 估计方法[32],即
其中k是一个给定的数值,ˆSj为
根据有效估计ˆS,相应关于参数ˆΘ最优估计值的渐进协方差矩阵为
协方差矩阵C(ˆΘ)对角元素是用来测试所得参数估计值稳定性,并且计算每个参数的T 统计量。
为了判断模型的有效性,引入了似然率(Likelihood Ratio, LR)的统计测试。根据Hayashi[33]论述,关于GMM 方法全参数模型的似然率比为
其中υ是约束条件的个数,ˆΘ表示非约束条件下的参数估计值,˜Θ表述在约束条件下参数估计值。通过式(22)的数值与相应的χ2分布的临界值比较,可以判断是否拒绝给定的约束条件假设。
现在我们回到给出有效GMM 算法估计:
步骤1 选择WN=I,隐含所有的矩的权重是等同的,求优化问题(19)给出估计Θ;
步骤2 根据步骤1 的结果,计算式(21);
步骤3 然后应用步骤3 的计算结果,重新求优化问题(19)给出估计Θ。
如果假设所有的结果满足Hayashi[33]中的正则性假设,那么上面估计算法给出来的结果是有效的GMM 估计。
3 实证结果
Andersen 和Lund[34]研究结果说明了每天交易三个月到期美国国债收益率可以非常好地近似无风险利率。Chapman 等[35]提供实证的证据说明了基于高斯模型(仿射性结构模型)应用1 个月或3 个月到期美国国债所获得参数估计误差是可忽略的。同时,Johannes[8]说明了债券收益率流动比较强,而且收益率不会受到收盘价和开盘价之间的价差影响,因此可以把该收益率当做无风险利率。另一方面,虽然作者无法使用获得本国短期债券每天交易数据,但根据Ball 和Torous[36]研究结果,在使用不同国家债券数据时,对于随机波动率模型所获得结论没有显著的差异。基于这些原因,本文将使用1 个月到期美国国债收益率每天交易数据当做无风险利率(数据来源于http://research.stlouisfed.org/),时间步长为δ= 1/262,时间从1954 年1 月4 日到2016 年12 月30 日,数据剔除了各个周末和节假日。
首先根据第2 部分论述,先估计漂移项。表1 给出了一些基本统计量,包括高斯数据(Δˆy),这个详细论述将在下面给出。Δy通过式(5),基于最小二乘法估计获得,参数估计值(θ∗/a,a)=(4.318 70,0.098 83)和T 统计量为(4.371 2×103,1.364 4),相应的统计分析和推断见文献[13]。基于表1 中数据,通过转化后,峰度已超过了35,这个值反应了Δy是非标准正态分布。图1 和图2 描述美国国债三个月到期每天交易数据,相应转化后的短期利率变化规律。在给出随机波动率和跳的参数估计值之前,根据文献[26]等结果,在参数估计过程中,自协方差和平方自协方差矩各自使用50 个。

图1 一个月到期每天交易美国国债收益率

图2 基于最小二乘法而得dyt 的变化
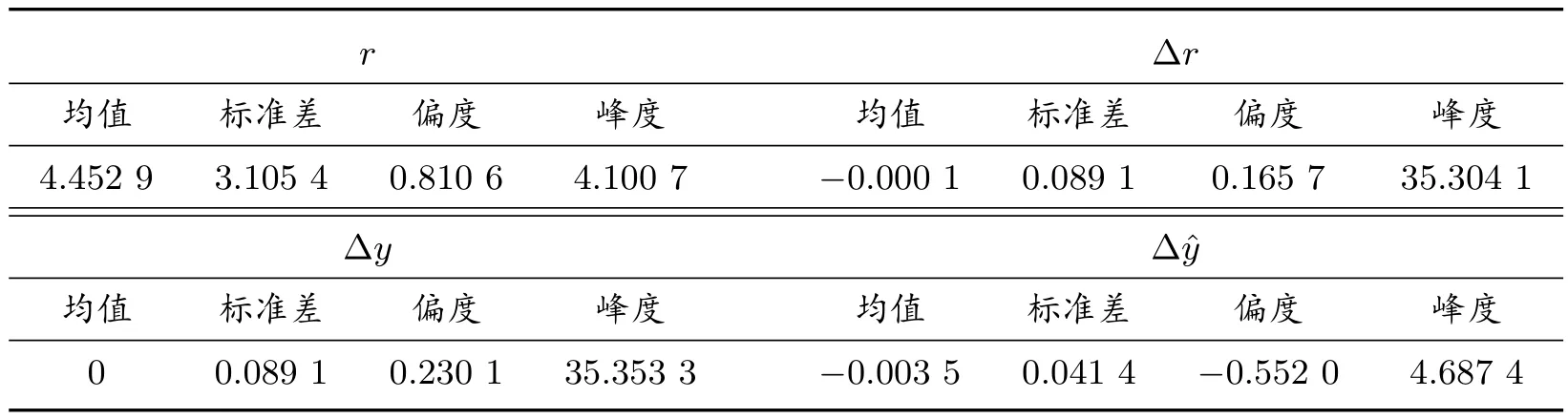
表1 一些统计量
3.1 随机波动率参数估计
为了描述跳的问题,A¨ıt-Sahalia 等[26]提出了通过截断数据把跳和连续部分(扩散部分)分离出来,也就是当dyt大于某个阈值时,表现为跳的发生,此时数据为跳的数据;当dyt小于该阈值时,表示连续部分,这部分数据描述了扩散动态行为,或称为高斯数据。因此,可通过两步估计方法对模型进行参数估计,先通过高斯数据估计随机波动率模型,而后再根据跳的数据估计具有跳的模型。沿着这个思路,在实际估计过程中,由于我们集中描述跳对短期利率模型的影响,因此参数估计过程将分成两步估计过程:第一步估计连续部分(扩散过程),即估计参数(α,β,η,ρ),此时模型中不发生跳;第二步估计跳的部分,估计参数(µ0,σ0,κ,µ,b)。在第二步过程中,保留着第一步估计所获得参数值,实际上,在第一步过程中,FVJHJ 模型退化为随机波动率模型[19],也就是不含有跳的模型。此时,在定理2 和定理3 中的矩函数就变得相对简单,而此估计过程仍然使用GMM 估计方法。关于数据分离方法所的参数估计的渐进性以及相容性问题,可以参考文献[37]。
A¨ıt-Sahalia 和Jacod[37–37]描述通过具体的阈值分离出高斯数据和跳的数据,即

图3 给出了通过阈值选取的跳的数据,从图形可以看出,显然在上个世纪80 年代出现跳的聚集现象,而且在2008 年也出现跳的聚集现象。因此,需要考虑自我激励机制跳的问题。
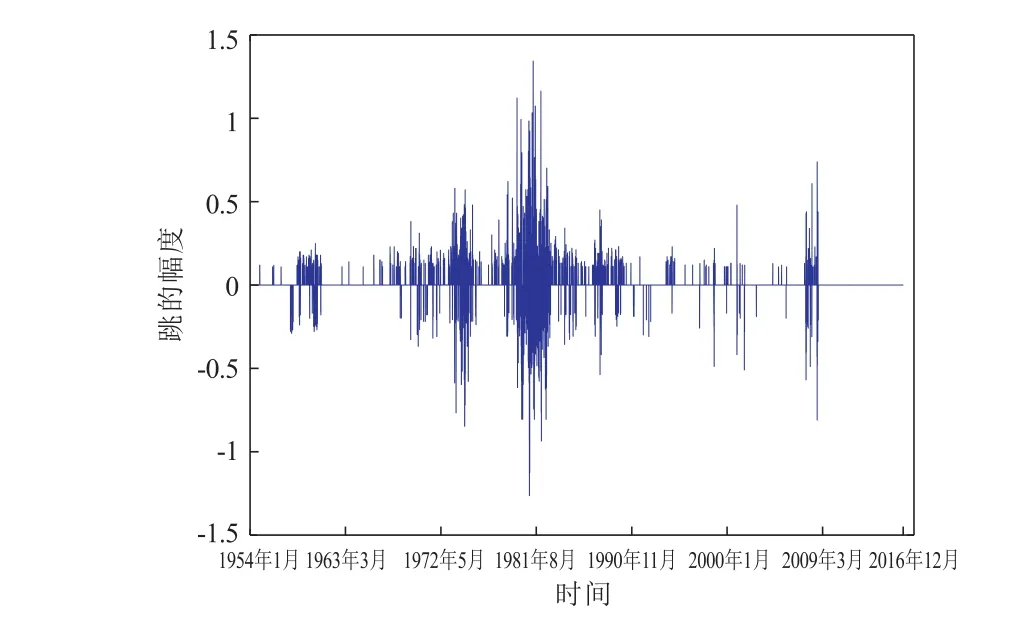
图3 跳的数据
根据表1 中的数据,通过数据分离,Δy和Δˆy,统计量都发生了变化。对于高斯数据,此时均值变成小于零,而且相应分布是左偏的,特别是峰度,从超过35 下降到4.6。根据正态分布的性质,显然分离出来的数据也不是正态分布随机数。事实上,Johannes[8]已论述了样本数据的峰度不能作为检验样本数据是否满足连续扩散模型的指标,特别是扩散项系数会改变模型的峰度。进一步通过Q-Q 图测试数据是否满足正态分布随机数,图4 给出高斯数据和原始数据的Q-Q 图。显然,基于图4 的结果,无法说明这两个样本数据都不满足正态分布随机数的特征。后面将会给出通过两个分位数阈值分离数据,高斯数据是满足连续扩散模型。
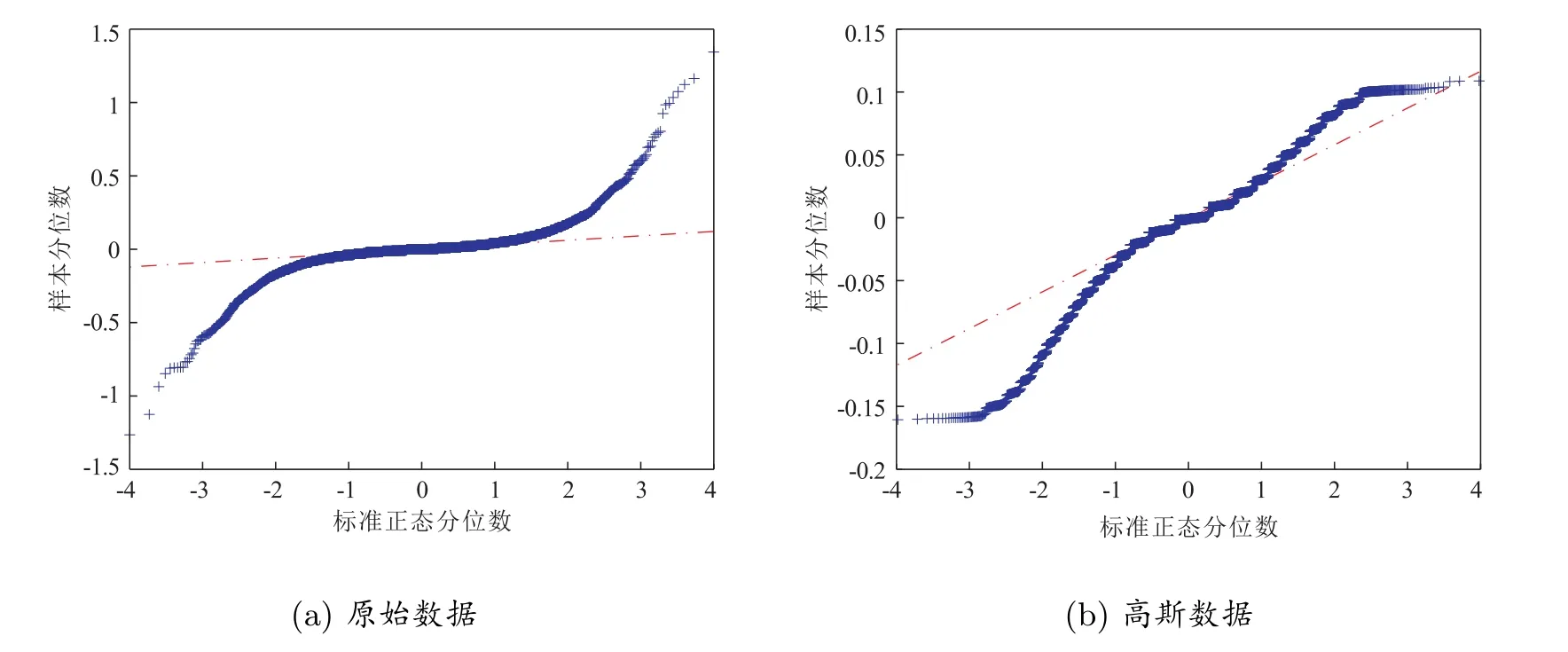
图4 描述原始数据和高斯数据的Q-Q 图
表2 基于高斯数据和原始数据给出随机波动率模型的参数,从表2 中数据可以看出,使用原始数据和高斯数据所得参数估计量没有明显的不同,而不同结果在于统计量的估计值。当使用原始数据时,大部分参数估计标准方差比较大,特别是相关系数,相应标准方差高达41,隐含着这个变量的估计是不稳定的。而且除了β之外,在统计意义上,接受了零的假设。观察高斯数据的估计量,比较应用原始数据所得估计量,整体上参数估计方差改变比较大,同时相应的值也比较小,因此通过数据分离后,相应的参数估计也比较稳定,而且年化标准差非常接近样本的年化标准差0.027 1■= 0.438 7。进一步观察发现,除了对于相关系数ρ,其它参数T 统计量数值都超过6,因此具有非常高的概率拒绝H0,接受H1的假设,即参数非零的假设,但是关于相关系数,在统计意义上接受零的假设,即可以设置ρ= 0,也就是在实践过程中可以考虑波动率和短期利率相互独立的模型。根据相关系数(ρ)T 的统计量,显然是无法拒接零的假设。事实上,Eraker 等[2]也论述了当引入跳的因素时,相关系数的在统计意义上估计是比较困难的。关于η估计值,这个值是用来来识别波动率是否具有随机性的重要指标。根据表2 中所得η的估计值和相应T 统计量,当使用原始数据,即使估计值非零,但在统计意义上,接受零假设而拒绝非零假设。通过数据的分离,应用高斯数据,相应η的T 统计量超过6,可以说明Δˆy具有非常高的概率接受η非零的假设,即具有随机波动率性质。这些结果说明,跳对随机波动率影响比较大。因为分离出跳的数据时,相应参数估计值和统计量都表明模型具有随机波动率性质,而不分离跳的数据时,模型的参数估计结果拒绝了随机波动率的性质。

表2 参数估计
接着,根据Kitagawa[40]研究结果,使用重度采样粒子滤波方法(Sampling Importance Resampling, SIR)给出了随机波动率估计。图5 描述了高斯数据和原始数据的过滤波动率值,从图形可以看出,当使用完全数据时,波动率非常好地描述了样本波动现象。但是根据A¨ıt-Sahalia 等[26]的论述,若不考虑跳的现象,所得波动率估计值可能是由真实的波动率和跳的因素组合而成。因此,在图5 中,高波动率值不仅包含了真实的波动率而且也包含了跳的过程,意味着高的Δy值是由波动率和跳的因数相互组合而成的。我们进一步观察截断数据的估计值,显然当剔除掉跳的过程时,整体上改变波动率的形态。因此,进一步说明所得估计可能需要考虑跳的因素,否则波动率可能被高估。
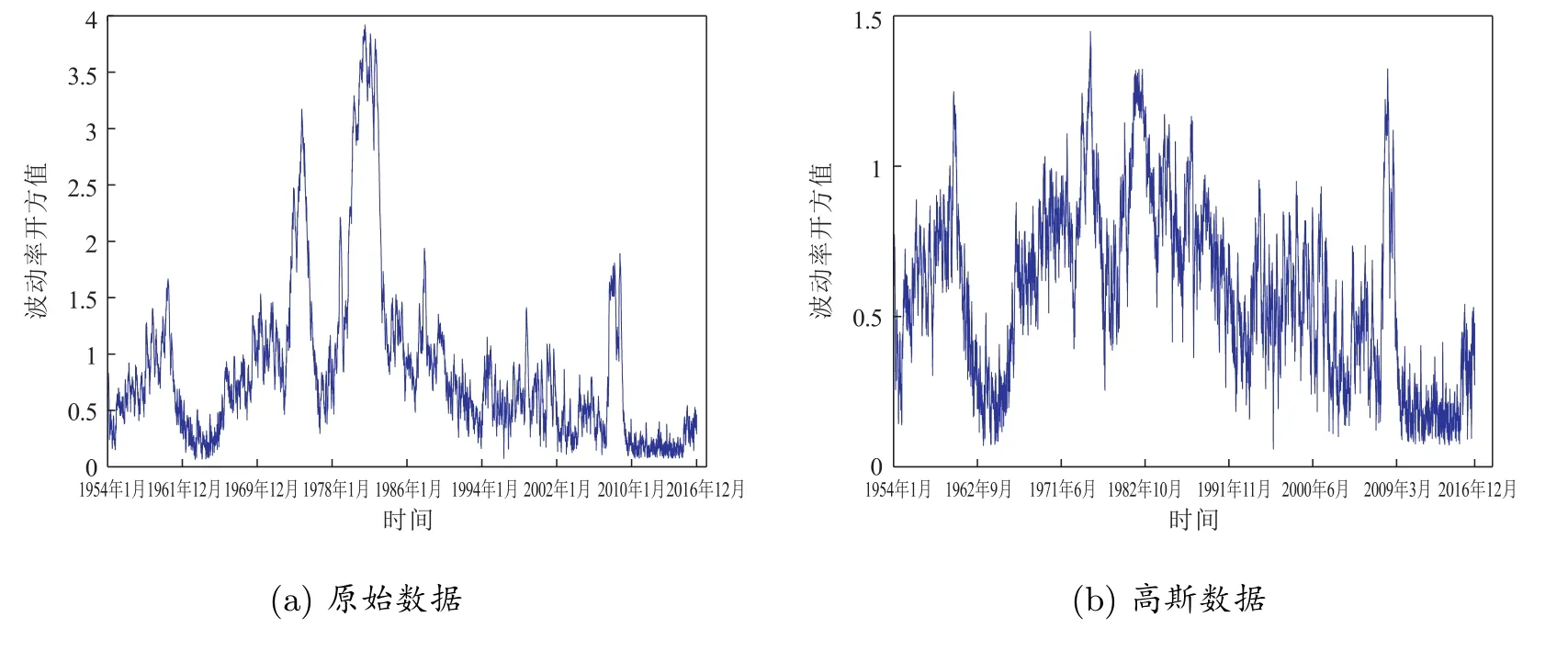
图5 基于原始数据和高斯数据,通过过滤方法给出随机波动的估计
图6 应用随机波动率模型给出原始数据和高斯数据的Q-Q 图,显然包含跳数据时,Q-Q 图显示残差非标准正态分布。因此,说明了引入扩散系数样本数据还是满足不了连续扩散模型,这就隐含着可能需要引入其它的状态变量,而一旦根据阈值剔除掉跳的样本数据,相应残差Q-Q 图显示样本的残差和正态分布随机数拟合的非常好,意味着高斯数据满足连续扩散模型。比较图4 中关于高斯数据的Q-Q 图像,显然扩散系数会影响到残差的变化。即使在表2 中,关于高斯数据统计量说明样本数据密度函数具有向左偏离,同时具有厚尾性质,但是在模型扩散项引入随机波动率Vt,相应残差的Q-Q 图测试表明满足正态分布。可见,偏度和峰度不能作为统计量来测试样本数据是否满足连续扩散模型。
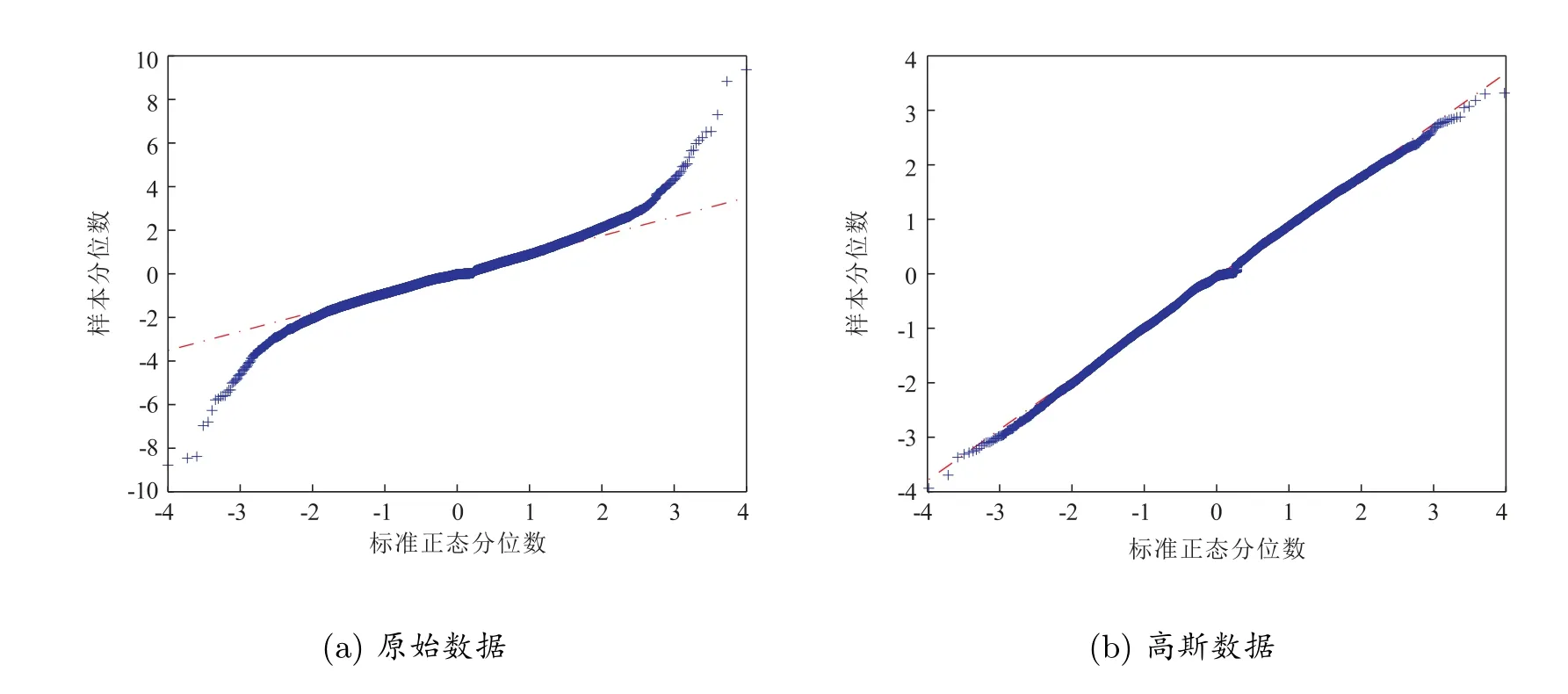
图6 基于随机波动率模型,描述原始数据和高斯数据的Q-Q 图
3.2 跳的参数估计
在给出跳的参数估计值之前,首先需要给出跳的幅度矩函数
根据这些矩函数,结合定理2 和定理3 应用GMM 方法,给出跳的参数估计值。
表3 基于GMM 算法给出不同模型参数估计值和相应的一些统计量。首先观察表格中的数据卡方统计量,由于本文使用103 个矩函数,因此对于FVJHJ 和FVJ 模型相应的p值都接近1,这意味着两个模型对数据的拟合效果都非常的好。但是比较两个模型的卡方统计量,在统计意义上,无法通过似然率的检验来测试FVJHJ 模型更加有效。鉴于此,定理3 说明了可通过通过参数的估计值来判断跳的强度是否是具有随机性[26]。

表3 模型参数估计值和统计量
为了给出表3 中对于参数估计的T 统计量的检验,首先需给出T 统计量的临界值。由于使用50 个滞后数据进行估计,有效的样本数为15 690,所以对T 统计量的自由度为15 689,相应地,相应单边99%概率(p= 0.01)临界值为2.326 6。根据该临界值,结合表3 中的T 统计量,显然对参数向量(σ0,κ,µ,b)大于零的假设在统计意义上是有意义的,即超过99%接受了备择的假设,隐含着在模型中需要这些参数都不能设置为零。值得注意的是,关于µ0的统计检验需要双边检验,显然此时p值为0.00 5,相应T 的临界值也为2.576 1。因此,也超过99%接受了非零的假设。
值得一提的是,关于参数向量(σ0,µ)和(κ,b)的统计检验,前者说明在模型中需要引入跳的过程,后者说明了在模型中需要考虑跳的强度是随机的。根据表3 中关于这些参数高T 统计量表明跳的幅度是随机的,且跳的强度也是随机的。因此,即使似然率无法测试模型的有效性,但是通过参数T 统计量的检验表明模型需要引入跳的过程,同时也需要考虑跳的强度是随机的。综上所述,构建短期率模型时需要引入跳且也具有很强自我激励机制跳的现象,也就是模型中不能拒绝引入跳的因素并需要考虑跳的聚集现象。
进一步,根据表3 中κ、µ、b的数值结果,通过计算可得FVJHJ 和FVJ 模型平均每年发生跳的次数大约为99.9 和2.2 次。虽然基于FVJ 模型平均次数低于样本跳的平均值4.5 次,但是A¨ıt-Sahalia 等[26]论述了基于跳的模型所得跳的年平均次数约1~2 次。因此,基于FVJ 模型所得平均跳的次数是可接受的。根据跳的平均次数估计,FVJ 模型确实无法刻画跳的次数,也意味着引入跳的模型还是不足与描述样本跳的属性。基于FVJHJ 模型相应年平均跳的次数远高于样本跳的平均次数,说明了考虑跳的强度具有自我激励机制性质,会增加跳发生的概率,而且将进一步改善因为跳发生频率太少所导致估计跳的过程所产生的样本匮乏问题。
3.3 跳的幅度和跳的强度过滤估计
在金融领域中,一般做市场压力测试是通基于波动率指标(或称恐慌指数)。事实上,A¨ıt-Sahalia 等[26]说明了通过波动率作为压力测试是不足的,应该考虑样本数据的跳的现象来做压力测试。Eraker 等[2]也使用跳的过程作为压力测试指标。因此,在这一部分将给出跳的过程估计,包括跳的强度。根据前面所得参数估计结果,基于过滤方法给出了隐含状态变量跳的强度,跳的幅度和跳的发生估计,即估计(λt,Jt,It)。近几年来,过滤方法在金融领域中已经得到广泛地应用[41–43],不仅用来估计参数而且也被应用于隐含状态变量的参数估计。虽然重度采样粒子滤波方法[40]简单而且能够比较容易添加一些新的状态变量,然而Johannes 等[5]说明了SIR 算法在估计跳的模型时候可能会产生样本匮乏现象。因此,本文将使用辅助粒子滤波器(Auxiliary Particle Filter, APF)方法给出跳的强度估计,该方法可参考Pitt 等[44],这种方法主要思想是在估计过程中考虑新的观察数据。因此,本文将沿着Johannes 等[5]思路,使用APF 算法给出状态变量的估计,详细的步骤如下。

步骤1 基于SIR 算法,计算权重
根据权重函数,重新抽样指标函数
上面算法详细可以参考文献[5]。注意在算法第2 步中,重新抽样粒子时,引入新的观察数据Δyn+1。因此,当估计样本较少的状态变量所得粒子不会出现匮乏的问题。
图7 基于APF 过滤方法给出了跳的强度(λt)、跳的概率、跳的幅度(Jt)和随机波动率(Vt)的估计。观察图7 中的左图,显然跳的强度λt的估计值比较大,最低值大约为30 左右,而最大的值接近210 左右,意味具有高的概率发生跳,相应跳的概率在图7 中的中间图。比较图6 中的右图关于跳的幅度值和图5 跳的数据,我们发现在特定时间区间内跳的幅度很好地描述跳的数据。例如,从1972 年至1973 年跳的聚集因素现象归因能源的危机;上个世纪80 年代初左右跳的聚集现象最为明显,在这段时间内发了海湾战争、伊朗政治危机、美联储货币政策等一些极端事件导致短期利率产生跳的集聚现象[8];1987 年黑色星期五;2000 年至2002 年网络经济泡沫;2008 年的金融危机。因此,可得出基于FVJHJ 模型很好地描述这些区域极端事件所产生跳的现象。

图7 基于FVJHJ 模型,跳的强度、跳的概率估计、跳的幅度估计
图8 基于FVJ 模型给出了跳的概率和跳的幅度估计值。比较图7 和图8 关于跳的概率和跳的幅度估计值,显然当跳的强度为随机时,相应跳的概率更加密集,意味着FVJHJ 模型具有更多的概率发生跳。进一步,比较FVJ 和FVJHJ 模型关于跳的幅度,即使FVJ 模型也能够刻画一些特定时期极端事件发生,但是FVJHJ 模型所描述的跳的幅度更加接近跳的数据。因此,也说明FVJHJ 更好的刻画市场数据跳的动态行为。虽然表3 中似然率无法推断FVJHJ 模型和FVJ 模型的有效性,但是从描述样本数据跳的现象角度考虑,有理由接受FVJHJ 模型而拒绝FVJ 模型。比较张新军等[13]结果,即使他们考虑跳的强度是随机的(波动率是确定的值),但是FVJ 模型描述的更多数据的跳,这也说明随机波动率对跳的估计影响也非常的大。

图8 基于FVJ 模型,跳的概率估计和跳的幅度估计
最后,图9 给出了FVJHJ 和FVJ 模型的波动率估计值。很显然,基于FVJ 模型的所的随机波动率值比较大。事实上,虽然不考虑挑的因素,波动率将会被高估[2,26],但基于图9 的结果,若不考虑跳聚集现象,重大极端事件持续性也会导致波动率被高估,这将导致其衍生定价错误,从而影响到风险管理水平。因此,由于FVJHJ 描述更多的跳,从而导致更低的随机波动率值。
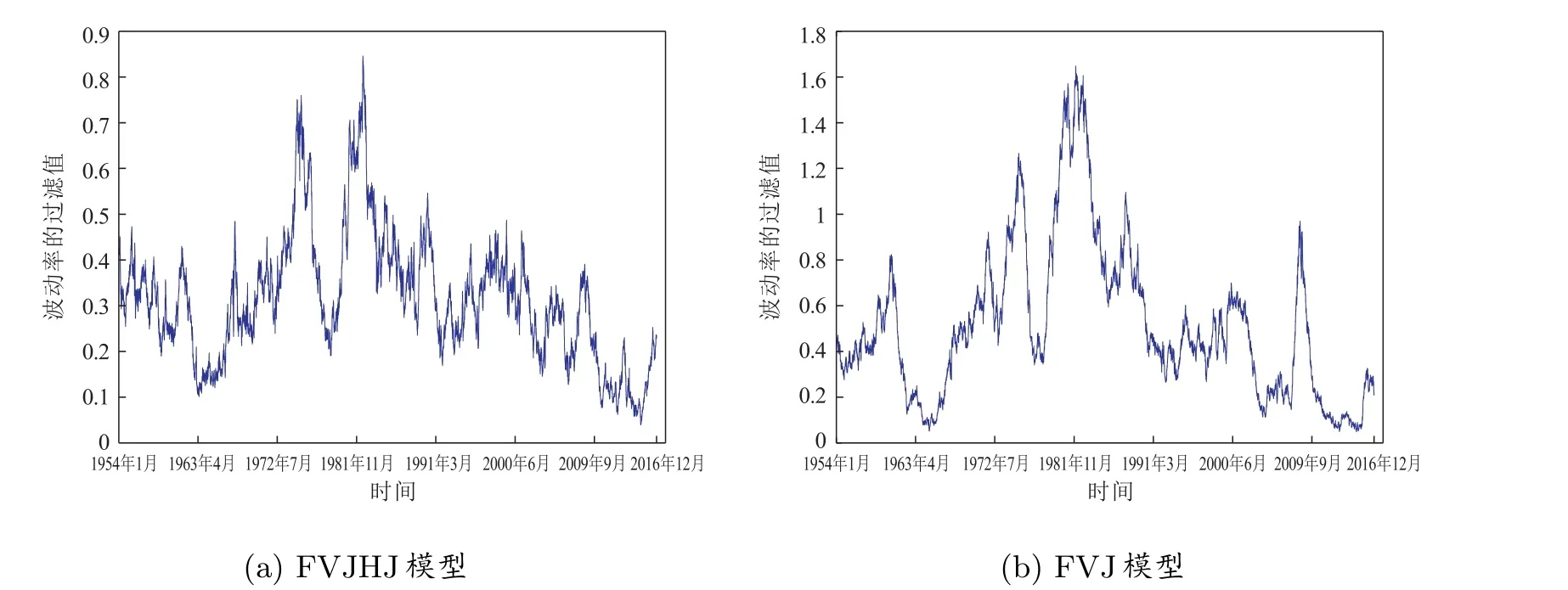
图9 基于不同模型随机波动率估计值
4 结论
本文构建具有自我激励机制跳的随机波动率短期利率模型(FVJHJ)。在FVJHJ 模型中,跳的强度满足Hawkes 过程,同时波动率满足CIR 过程,因此所构建模型是三因子模型。根据GMM 方法的收敛性和必要条件(正交条件),基于条件期望算子定义,应用微分算子Taylor 展开,推导了矩函数精确表达式,包括了自协方差矩和平方协方差矩函数,进一步应用GMM 方法给出了模型的参数估计和统计推断,最后也应用APF 算法给出随机波动率、跳的幅度、跳的概率及跳的强度估计值。
应用美国国债一个月到期收益率每天交易数据做实证的研究。为了给出实证的结果,应用截断函数技巧对原始数据分离出高斯数据和跳的数据,前者应用于随机波动率模型参数估计,后者应用于估计跳的模型。实证结果表明应用截断函数技巧很好地分离出跳的数据。基于数据的分离结果,通过模型参数T 统计量检验发现,在统计意义上,接受跳的强度是随机过程。此外,通过对跳的幅度估计值和样本跳的数据比较,FVJHJ 模型更好地描述数据的跳,特别是在一些特定时间段内,如上个世纪80 年代初一系列政治事件和经济事件对模型产生的冲击,本世纪初的网络泡沫和2008 年的金融危机等极端事件。综上所述,研究短期利率动态行为过程时,需要考虑自我激励机制跳的模型。
虽然FVJHJ 模型在统计意义上能够很好地描述样本数据问题,但是仍然有一些问题值得进一步研究,例如非参检验自我激励机制跳的有效性及其对短期利率衍生品的冲击。
