基于小样本下改进ChaosNet的轴承故障诊断*
2024-02-29李天昊李志星王衍学
李天昊,李志星,王衍学
(北京建筑大学a.机电与车辆工程学院;b.城市轨道交通车辆服役性能保障重点实验室,北京 100044)
0 引言
随着现代工业生产加工设备日趋复杂化、精细化,自动化水平显著提高,人们对生产系统持续性、稳定性和安全性需求日益强烈。然而,滚动轴承作为机床设备加工过程中的重要精密部件,持续发生因设计缺陷和恶劣工况导致设备故障或停机。在机床轴承失效期前及早进行故障排查和处理,能够避免故障恶化导致的安全事故和财产损失,具有重大社会经济价值。因此,对轴承故障智能诊断方法的研究至关重要。
得益于机器学习特别是深度学习在故障诊断领域的发展,基于智能优化算法和深度学习的智能故障诊断方法不断取得突破。何强等[1]使用两重训练方式,在小规模训练样本条件下能够准确进行故障分类。SHIFAT等[2]提出了一种基于每个IMF最大峰度值模态分量选择方法。SHAHRAKI等[3]将AdaBoost算法与决策树分类器结合使用,获得了更好的性能。神经混沌学习[4]受到生物神经网络的启发,是一种设计新颖的神经网络结构。提取的4个神经混沌特征:放电时间、放电速率、能量和熵用于训练支持向量机分类器(support vector machine,SVM)。然而由于SVM对数据集部分缺失的敏感度较高且对于大规模数据集需要较长的训练时间,因此该模型对小样本、不平衡数据集诊断效果较差。
基于上述问题,本文将NL与AdaBoost结合,用于轴承故障特征的提取和分类。首先使用时频域信号拼接合成样本的方法,对数据进行预处理;随后,使用广义Luroth级数(GLS神经元)从样本中提取非线性特征以解决分类任务;最后,使用线性核函数训练的集成学习分类器(AdaBoost)增强从单层GLS神经元提取的非线性特征,上述诊断方法的有效性在低训练样本条件下在实验中得到验证。
1 理论基础
1.1 ChaosNet
混沌行为是非线性系统中常见的非周期性运动形式。神经混沌学习(NL)架构由生物神经元放电过程获得启发,将神经混沌理论和经典机器学习算法相结合,ChaosNet(ChaosFEX+SVM)[5]是这一理论用于分类任务的理想实例。ChaosNet利用个体神经元的混沌行为产生的生物神经特性,可以在较少训练样本的情况下,表现出比传统人工神经网络更好的分类性能。该结构如图1所示,是一个由混沌神经元为基本单位组成的神经网络结构。每个GLS神经元具有2个主要参数-神经活动初始状态x0和用于特征提取时的判别阈值a。神经元在接受刺激(输入数据)时被激活,根据神经活动初始状态x0以周期性或者混沌的方式输出放电轨迹。
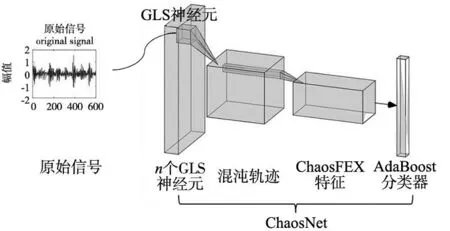
图1 混沌神经网络结构
广义Luroth[6]级数(generalized luroth series,GLS)是一个分段线性的一维混沌映射,其常用的映射方式为帐篷映射(Tent Map)[7],图2为斜帐篷函数映射图,本文使用Tent Map作为混沌神经元,数学表达式为:
(1)

图2 斜帐篷映射图
式中:x∈[0,1),a∈(0,1)。
结合图2可以得出:Tent Map作为一个基于其自身的不可逆变换,鉴别阈值a决定了GLS图的偏斜度。变换之后的函数自变量范围分为线性区间[0,a]和[a,1],左分支斜率为1/a∈(1,+∞),右分支斜率为1/(1-a)∈(1,+∞)。
Lyaponuv(李雅普诺夫)指数[8]常被用来判定一个系统的混沌性,通过图像可以直观地看出某个系统或者映射是否是混沌系统或映射,计算公式为:
(2)
式中:f′(x)表示x点的导数,即λ量化了两条轨迹在[0,k]时间间隔内彼此发散λ>0或收敛λ<0时的平均速率。本文基于此证明Tent Map的混沌特性。
假定Lyaponuv指数用λ来表示,判别依据如下:
当λ>0时,系统运动进入混沌状态,且对初始条件敏感,对应映射称为混沌映射;当λ<0时,系统运动状态趋于稳定且此时对系统的初始状态不敏感,即此时的映射对初始值不敏感;当λ=0时,系统处于稳定状态。
设a=0.32,计算Tent Map的李雅普诺夫指数。对于式(1),于函数图像左半支,|f′[x(j)]|为1/a,λ>0;于函数图像右半支,|f′[x(j)]|为1/(1-a),λ>0。由此证明Tent Map具有混沌状态。
1.2 ChaosFEX
在NL架构中,使用混沌神经元的特征提取步骤称为ChaosFEX[9],NL从混沌神经网络中提取ChaosFEX特征,该网络在不同层上具有同质和异质的混沌神经元。输入层中的所有GLS神经元具有q个单位的初始神经活动,GLS图的偏斜度由鉴别阈值(a)控制。
通过改变a,混沌神经元可以根据李雅普诺夫指数分别表现出弱混沌和强混沌。
在单个混沌神经元的放电轨迹中,提取构成ChaosFEX特征的放电时间、放电速率、能量和熵,然后将这些特征馈送到AdaBoost进行分类。特征具体含义如下:
(1)放电时间:混沌轨迹识别刺激所需的时间。
(2)放电速率:混沌轨迹高于区分阈值以便识别刺激的时间段。
(3)能量:混沌轨迹x(t)的能量,计算方法为:
(3)
(4)熵:首先对混沌轨迹x(t)定义如下的符号序列:
(4)
式中:i表示放电时间序列号,计算以上符号序列的香农熵:
H(St)=-(1-Pt)log2(1-Pt)-Ptlog(Pt)
2 NL-AdaBoost的故障诊断模型
基于GLS的拓扑传递性-符号序列算法和AdaBoost实现故障特征提取、训练、分类和测试的完整流程。
2.1 网络模型框架
ChaosNet的单层混沌神经元结构由一个输入层和一个输出层组成。输入层由n个GLS神经元(C1,C2,…,Cn)组成,用于从输入样本中提取特征模型。整个输入数据样本表示为m×n维矩阵X,ChaosNet输入层神经元个数等于输入数据样本数,其中m表示样本数量,n表示每个样本中的采样点数。输出层节点O1,O2,…,OS存储对应于s个故障类别中的表示向量。

(5)

图3 拓扑传递性-符号序列特征提取

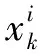
(2)特征向量处理。假设一个s类故障分类问题,故障类由L1,L2,…,Ls表示,对应的标签分别为1,2,…,s。定义m×n的归一化矩阵U1,U2,…,US,分别代表L1,L2,…,Ls的数据。使用TT-SS算法训练从第一步提取来的特征,从而产生特征向量V1,V2,…,VS。接下来计算跨行的平均值,计算公式为:
(6)
式中:M1,M2,…,Ms是对应于s个类的平均表示向量,随着越来越多的样本输入,均值表示向量将持续更新,将更新后的均值表示向量分别存储在输出层节点O1,O2,…Os中。
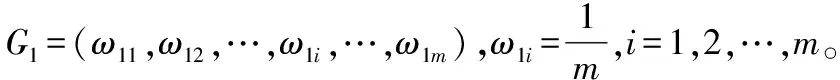
对于每个基分类器:
①分别划分样本空间为Z1,Z2,…,Zr;
②计算权重Gv;
③计算误分类率如式(7)所示。
(7)
最终,获得增强分类器,表达式如下:
ψ(z)=argmaxf(zi,yi)
(8)

2.2 故障诊断流程图
针对小样本条件下的轴承故障诊断问题,本文提出了基于NL-AdaBoost的诊断方法。诊断流程共分为3个主要环节,如图4所示。
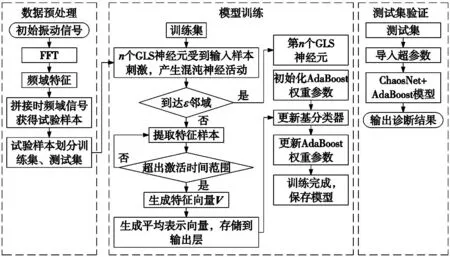
图4 ChaosNet-AdaBoost轴承故障诊断流程
3 轴承诊断实验与结果分析
本文基于以下2个实验验证NL-AdaBoost在2种轴承故障数据集和小样本条件下的分类性能。在实验1中,首先通过充足数量的训练样本进行k折交叉验证,确定模型最优超参数;进而使用训练后的模型对测试集数据验证故障诊断能力,使用宏观F1分数(Macro F1 Score)[10]评价分类模型综合性能。实验2在实验室自采轴承数据上进行,ChaosNet三个超参数与实验1一致,每类故障的训练样本数量由1~64渐进,在每种情况下执行100次随机训练实验;测试集数量与实验一保持一致。最后分别使用原生ChaosNet(ChaosFEX+SVM)、K最近邻分类算法(KNN)[11]、SVM、朴素贝叶斯分类器(Naive Bayes)[12]共4种深度学习算法在此数据集上进行分类测试,比较几种模型的分类性能。
3.1 实验数据描述
实验1的数据来自机械故障预防技术学会(MFPT),轴承型号NICE,滚珠直径0.235 cm,滚珠数量8个,故障类型如图5所示,数据集包括内圈故障和外圈故障。此数据集包含实际故障数据和来自实验室轴承实验台故障数据,每类故障具体描述如表1所示。分别在不同负载的内、外圈故障中各选取3个故障和正常工况组成实验数据集,如表2所示,共10类故障类型。从每类故障样本中选取80组实验样本,共800组,每组样本采样点2048个,训练集占比80%,测试集占比20%。

表1 MFPT故障描述

表2 测试集诊断结果

图5 轴承内、外圈故障实物图
实验2使用实验室自采轴承数据,试验台如图6所示。轴承型号为FLURO ER12K宽内圈球轴承。使用3个通道(正上方、左侧、右侧)加速度传感器,以5000 Hz的采样频率采集轴承振动信号,持续时间10 s,转速500 r/min,振动信号样本包括正常工况、内圈故障、外圈故障、保持架故障、滚动体故障5种状态。从每类故障样本中选取80组实验样本,共800组,在训练集中,每类故障的训练样本由1,2,…,16组递增,测试集数量与实验一保持一致。
3.2 实验数据预处理
本文通过FFT将长度为2048的时域信号转换为频域信号,拼接时频域信号得到单个样本,处理过程如图7所示。这一处理方法不仅保留信号的原始特征信息,而且保留了信号的一维特性。

图7 实验样本预处理
3.3 超参数确定
神经网络的模型参数和超参数对于最终的回归和分类结果准确度具有至关重要的作用。NL-AdaBoost的特征表示向量M1,M2,…,MS是模型训练时需要学习的参数,共有3个超参数:初始神经活动(q)、辨别阈值(a)和神经刺激的epsilon邻域(ε)。本文采用k折交叉验证法确定模型最优参数。固定一组超参数(初始神经活动q=0.31,辨别阈值a=0.92),ε以0.000 1为一个单位由0.15递增至0.16,即以不同ε参数在训练集做共100次模型训练。最后计算每个样本集的宏观F1分数。这一方法的优势在于可以全面评定模型和超参数的整体表现,相比固定单一训练集,这一方法在交叉验证中每个样本都将作为训练集和验证集,最终所得结果可靠性更高。
选用兼顾分类模型精确率和召回率的macro F1-score(宏观F1分数)作为分类指标。macro F1-score可以看作是模型精确率和召回率的加权平均,适用于衡量不平衡数据的精度,其计算方法如下,取值范围[0,1]。
①根据式(9)计算每个类的F1-scorei。
(9)
②计算每个类的macro F1-scorei。
(10)
经过100次训练之后,超参数调整对应的宏观F1评分变化如图8所示。F1分数在0.153~0.157的范围内达到1.00,因此本文得到最终的最优超参数为q=0.31,a=0.92,ε=0.155。

图8 超参数调整中的宏观F1分数变化
3.4 模型性能验证
本文选用的深度学习框架为基于Python语言的Sklearn(Scikit-Learn)[13],封装了包括回归、降维、分类、聚类4种主要算法。为验证故障诊断模型有效性,在测试集验证NL-AdaBoost基于第3.3节所述最优超参数的分类能力,进行10次重复实验取每个故障类型的精准度、召回率和F1评价分数的平均值。测试集包括10种故障类型,每类16组,共160组数据。训练集上macro F1-score的变化曲线如图9所示。

图9 训练集macro F1-score变化曲线
在测试集上根据公式计算每个故障类型的平均精准度、召回率和F1评价指标如表2所示,整个测试集的F1评价指标为0.975,证明本文所述模型对于轴承故障数据具有较好的分类效果。为了直观展示故障分类情况,挑选一次试验结果,绘制测试集上的故障诊断结果混淆矩阵如图10所示,可以看出除类型4、类型7和类型9分别有1个和2个判断错误以外,其余都准确识别出故障类型。
3.5 与常见分类算法效果对比
为进一步验证本文所述模型在小样本训练集情况下的分类性能和泛化能力,基于上述实验方案在实验室自采轴承故障数据集上,将4种深度学习算法包括原生ChaosNet(ChaosFEX+SVM)、K最近邻分类算法(KNN)、SVM、朴素贝叶斯分类器(Naive Bayes)与之做对比试验。在训练过程中,为了分析训练集样本数量与模型诊断准确率之间的关系,使每类故障的训练样本数量分别为1,2,…,16,然后在测试集验证模型泛化能力,分别计算每种情况的平均宏观F1分数,图11为16种情况下每类深度学习算法的平均宏观F1分数变化曲线。

图11 5种诊断模型的平均宏观F1分数
由图11可知,随着训练样本数量的增加,5种算法的故障诊断准确率均呈逐渐升高的趋势。其中,朴素贝叶斯分类器故障诊断准确率最低,在训练样本达到9组的情况下,宏观F1评分仅为0.39;当模型诊断准确率趋于稳定时,其余4种算法的宏观F1评分均大于0.8。当训练样本不足时,原生ChaosNet(ChaosFEX+SVM)和NL-AdaBoost(ChaosFEX+Adaboost)表现出了良好的分类性能,宏观F1评分均大于0.9。即本文提出的基于改进神经混沌学习的轴承故障诊断模型具有较好的稳定性、准确率和泛化能力。
4 结论
(1)提出的基于改进神经混沌学习的轴承故障诊断新方法,具有创新性的输入特征提取方式,在不同工况下可以准确识别出轴承的多种故障类型。
(2)AdaBoost分类器在多次迭代训练任务中逐渐提升前一轮预测错误样本的权重,最终实现通过加权所有基分类器的训练结果得到分类标签。
(3)通过与常见分类模型的实验对比,证明了本文提出的NL-AdaBoost模型能够有效提升故障诊断结果。
