基于特征重加权的小样本遥感图像目标检测算法
2024-02-29葛洪武
周 博,葛洪武,李 珩,李 旭
(中国电子科技集团公司 第54研究所,石家庄 050081)
0 引言
目标检测的任务是找出图像或视频中人们感兴趣的物体,并且同时检测出它们的位置和大小,目标检测不仅要解决分类问题,还要解决定位问题,作为计算机视觉的基本问题之一,目标检测构成了许多其他视觉任务的基础,例如实例分割、图像标注和目标跟踪等。目标检测算法可以分为一阶段目标检测算法以及二阶段目标检测算法,其中一阶段目标检测算法主要包含YOLO[1-3]、SSD[4]等算法;二阶段目标检测算法主要包括RCNN[5]、Fast RCNN[6]、Faster RCNN[7]等算法。一阶段目标检测算法减少了空间和时间的占用,速度有较大提升,但精度低于二阶段目标检测算法。上述算法的性能都依赖于大量的数据集,但是在某些场景下,往往难以收集到大量的数据集或者获取数据集的代价非常高。
受限于大规模的数据集,小样本目标检测算法在计算机视觉领域得到了广泛的研究;小样本目标检测算法旨在学习可转移的知识,将这些知识泛化到新类中,从而对只有少量样本的新类进行检测。Wang等人基于Faster RCNN提出了两阶段微调方法[8](TFA,two-stage fine-tuning approach),在保持整个特征提取器不变的情况下,只微调分类器和回归器,首次证明了简单的迁移学习方法在小样本目标检测任务上效果好于元学习方法。Sun等人提出了基于对比候选框编码的小样本目标检测算法[9](FSCE,few-shot object detection via contrastive proposal encoding),首次将对比学习引入到小样本目标检测方法。Li等人提出了基于类别特征均衡的小样本目标检测算法[10](CME,class margin equilibrium)方法来优化特征空间划分和新类表示,让模型更好地学习小样本的特征;Qiao等人提出了基于解耦Faster R-CNN的小样本目标检测算法[11](DeFRCN,decoupled faster r-CNN for few-shot object detection)方法,缓解了Faster RCNN中前景和背景的识别冲突问题,还提出了一个离线的分数校准模块,以缓解定位和回归之间的冲突,但是该模块增加了模型的计算量。Kang等人以YOLOv2为基础网络提出了元学习小样本目标检测算法(MetaYolo[12],few-shot object detection via feature reweighting),在此基础上引入了特征重加权提取器,用于强化对于检测新类有帮助的元特征,Li等人以YOLOv3为基础网络,提出了遥感小样本目标检测算法[13](FSODM,few-shot object detection model),通过引入多尺度的特征重加权提取器来提升模型对于不同尺度目标的检测性能。
遥感图像具有目标尺度差异大、目标模糊、背景复杂度高的特点,上述小样本目标检测算法大多基于日常生活中的常见物体开发,在遥感图像目标检测任务上精度仍然较低,并且大多基于二阶段的Faster RCNN算法,计算复杂度高,检测速度较慢。其中FSODM以一阶段的YOLOv3为基础,针对遥感图像提出了多尺度的特征重加权提取器,提高了不同尺度目标的检测精度,并且有较快的检测速度,但是FSODM提取到的图像的深层语义信息以及浅层定位信息仍然不够丰富。针对上述问题,以FSODM为基础,提出了一种新的特征重加权小样本目标检测算法(RE-FSOD,feature reweighting few-shot object detection),贡献主要如下:
1)将元特征提取器的骨干网络更换为CSPDarknet-53结构,在Neck部分加入路径聚合网络[14](PAN,path aggregation network)结构,CSPDarknet相对于初始的Darknet-53引入了交叉跨阶段网络[15](CSP,cross stage partial network)结构,并且将空间金字塔池化[16](SPP,spatial pyramid pooling)更换为快速空间金字塔池化(SPPF,spatial pyramid pooling fast),能够减少参数量以及计算复杂度,并且提供了更强大的特征表示能力。PAN结构能够将浅层丰富的定位信息传递到深层,增强对不同尺度检测目标的定位能力,使得在3-shot、5-shot、10-shot情况下分别提升了大约10%、3%、4%。
2)提出了结合注意力机制和残差结构的C2fSE模块,由压缩激励注意力机制[17](SE,suqueeze and excition)和带有残差结构[18]的通道到像素模块(C2f,channel to pixel)构成,将其添加到原始的特征重加权提取器卷积层后,增加网络的深度和感受野,提升网络的语义特征提取能力,使得在3-shot、5-shot、10-shot情况下分别提升了大约4%、3%、4%。
3)将定位损失函数替换为CIOU[19]损失函数,CIOU损失函数同时考虑了检测目标的大小、长宽比、纵横比等因素,加速模型的收敛,且提升了模型的定位性能,使得在3-shot、5-shot、10-shot情况下分别提升了大约6%、9%、3%。
1 RE-FSOD算法
1.1 小样本目标检测问题设置
小样本目标检测算法旨在从源数据集Di中学习通用的元知识,利用少量的目标数据集Do将元知识迁移到目标任务中,使得小样本目标检测算法在目标数据集上能够快速收敛。假设目标数据集中有N类样本,每类样本具有K个标签,称为N-way-K-shot[20]任务。
小样本目标检测算法的数据集由支持集与查询集构成,给定一个k-shot任务,支持集Si= {(Ik,Mk)},其中Ik代表输入图像并且Ik∈Rh×w×3,Mk代表对应目标的掩膜,k= 1,2,3,…,K。查询集Qi包含Nq张图片,Nq为训练集或者测试集中所有图片的数目,同样包含有k类目标。RE-FOSD算法的一次迭代训练的输入为Ti={Qi,Si}。
1.2 FSODM介绍
FSODM算法是Li等人于2021年提出的第一个小样本遥感目标检测算法,FSODM算法基于YOLOv3目标检测算法进行开发,在此基础上引入了多尺度的特征重加权模块,用来调整特征图的特征,强化那些对于检测新类有帮助的特征,使得算法能够在少量样本下取得较好的检测精度。相较于其他流行的小样本目标检测算法TFA、FSCE等算法,FSODM结合了多尺度的特征重加权模块,能够更好地处理尺度多变的遥感目标,并且FSODM算法基于一阶段的YOLOv3算法开发,在推理阶段可以移除掉新增的特征重加权模块,具有较少的计算量以及更快的推理速度,但FSODM的检测精度仍然较低,为了能够更准确地识别遥感目标,仍需要对算法进一步改进,FSODM结构如图1所示。

图1 FSODM网络结构图
1.3 RE-FSOD整体结构
RE-FSOD算法以FSODM为基础,与FSODM有相同的架构,同样由元特征提取器、特征重加权提取器、预测模块3部分构成,整体架构如图2所示,详细结构如图3所示。

图2 RE-FSOD架构图

图3 RE-FSOD网络结构图

图4 CSP结构示意图
元特征提取器的输入为查询集中的图片,能够提取3个不同尺度的元特征图,特征重加权提取器为数据集中的所有目标类别生成3个尺度的特定类特征重加权向量,将对应尺度的特征重加权向量与元特征图进行1×1的通道卷积来调整元特征图的权重,强化对于检测新类有帮助的特征,将特征图输入到预测模块中生成(x,y,w,h,o,c),(x,y,w,h)代表边界框坐标,o代表置信度,c代表类别分数。
2 RE-FOSD关键技术
2.1 元特征提取器
元特征提取器旨在从查询集中提取到鲁棒的元特征,I为输入到元特征提取器的查询图片,I∈Rh×w×c,提取得到的元特征为Fi=ε(I)∈Rhi × wi × mi,用i代表3个尺度的序号,i=1,2,3。其中hi,wi,mi表示尺度i的特征图的大小。依照FSODM的设置,将特征提取器的图片输入设置为512×512,3个特征图的尺寸大小分别为16×16×1 024、32×32×512、64×64×256。
FSODM中元特征提取器由Darknet-53以及特征金字塔网络(FPN,feature pyramid network)构成。RE-FSOD将元特征提取器的骨干网络替换为CSPDarknet-53,并且在FPN的基础上添加了PAN结构。Darknet-53中存在大量的残差块,并且使用步长为2,卷积核大小为3×3的卷积层Conv2D代替池化层进行下采样,残差块可以增加网络的深度,使得网络能够提取更高级的语义特征,可以避免梯度的消失或者爆炸。CSPDarknet-53相比于Darknet-53网络在残差结构中引入了CSP结构,CSP将原输入分为两个分支,分别使用1×1的卷积进行特征变换,并且使特征图的通道数减半,其中一个分支的特征图经过N个BottleNeck模块,最后在通道维度上进行连接,CSP分流的结构可以减少计算量,有效地传递信息,使得网络能够更好地学习特征。
CSPDarknet-53使用了SPPF(最大池化特征金字塔)模块,原方法中在骨干网络中使用的方法为SPP,两者的作用都是实现局部特征与全局特征的融合,SPP存在4个分支,其中一个分支为卷积层,其余3个分支分别为卷积核为5,9,13的最大池化层,之后将4个分支的输出在通道维度上进行连接,将局部特征与全局特征融合进而提取到不同大小的目标特征,SPPF在SPP结构上进行了改进,复用了已有的特征图,并且将3个最大池化层的卷积核设置为5,大大提升了推理速度。
一般浅层的特征图具有更多定位信息和较少的语义信息,深层的特征图尺寸变得更小,维度变得更大,因此深层的特征图具有更多的语义信息和较少的定位信息。在FSODM元特征提取器使用了FPN结构,FPN是一个自顶向下的特征金字塔,把浅层的语义特征传递下来,对整个金字塔进行增强,它只增强了语义信息,但是没有对定位信息进行传递,PAN结构针对FPN的缺点,在FPN的基础上增加了一个自底向上的金字塔,对FPN进行补充,将定位特征传递上去,这样生成的特征图同时拥有了丰富的定位和语义信息,能够提升目标检测算法的精度。
2.2 特征重加权提取器
特征重加权提取器的输入是检测目标的感兴趣区域(ROI),如图1所示,包含各个类的图片以及对应类别目标的掩膜,一般输入图像会包含多个检测目标,为了使特征重加权提取能够识别特定类别的目标,因此只选取对应类别的一个目标,根据此目标位置将边界框内的区域像素设置为1并且将其余位置的像素点设置为0得到掩膜。将输入图像与掩膜拼接成4维向量输入到特征重加权提取器中,生成对应类别多个尺度的特征重加权向量,特征重加权向量与元特征图进行1×1的卷积来调整元特征图,强化对于检测新类有帮助的特征。
FSODM中使用卷积层与最大池化层构成特征重加权网络,为了使得特征重加权能够提取到更丰富的语义信息,提出了融合注意力机制的C2fSE模块,在此基础上将C2fSE模块融入到特征重加权提取器中,C2fSE模块由C2f模块以及SE模块构成,C2f模块的卷积层通过增加卷积核的大小和步幅来扩大感受野,使得模型能够在更大的区域内获取特征,同时C2f中的残差结构能够加深网络的层数,增强网络的特征提取能力。SE(Squeeze-and-Excitation)注意力机制首先通过压缩操作,将每个通道的二维特征压缩为1个实数,得到通道维度的全局特征,之后通过激励操作为每个通道生成一个权重,最后将得到的权重调整初始的特征图,SE通过挤压与激励的操作使模型更加关注信息量大的特征,从而抑制那些不重要的特征,进而提升特征重加权网络的特征提取能力。
2.3 损失函数
FSODM损失函数由定位损失、类别损失及置信度损失构成,相较于FSODM,RE-FSOD将定位损失由均方误差损失更换为CIOU损失。
FSODM均方误差损失公式如式(1)所示:
(1)

(2)
式中,A为预测框的面积,B为真实框的面积。
CIOU损失函数宽高比惩罚项如式(3)所示:
(3)
式中,wgt与hgt是真实框的宽和高,w和h是预测框的宽和高。
CIOU中心点距离惩罚项由式(4)、式(5)定义:
(4)
d=ρ2(Actr,Bctr)
(5)
式中,Actr,Bctr分别是真实框与预测框的中心点,ρ2(·)代表两点间的欧式距离,c是真实框A与预测框B的最大外接矩形的对角线,d为A与B的中心点的距离。
其中:α为权重系数,如式(6)所示:
(6)
CIOU损失函数最终定义如式(7)所示:
(7)
正样本置信度损失如式(8)所示:
(8)
式中,p0为预测的置信度o,o为预测框中存在物体的可能性,pt为真实框的值,有目标为1,没有目标时为0。
负样本置信度损失如式(9)所示:
(9)
式中,neg代表所有负样本。
总置信度损失如式(10)所示:
Lo=Lobj·wobj+Lnobj·wnobj
(10)
式中,wobj和wnobj是正样本和负样本损失的权重,用来平衡正负样本损失。类别损失如式(11)所示:
(11)
式中,cpt是真实类别分数,cpj是预测类别分数,已经使用置信度来判断预测框中是否存在目标,因此分类损失中忽略了负样本。
RE-FSOD总的损失函数表示为:
L=Lciou+Lobj+Lc
(12)
2.4 预测模块
预测模块与YOLOv3类似,依据YOLOv3的设置,采用基于anchor(锚框)的方法,anchor对应大物体尺寸设置为(116×90)、(156×198)、(373×326),对中等物体尺寸设置为(30×61)、(62×45)、(59×119),对小物体尺寸设置为(10×13)、(16×30)、(33×23)。将3个尺度的特征图输入到预测模块中,生成(x,y,w,h,o,c),(x,y,w,h)代表边界框坐标,o代表置信度,c代表类别分数。与YOLOv3预测模块相比,只有类别预测不同,YOLOv3每个预测框生成k个类别分数,由于RE-FSOD对每个类都有一个类特征图,每个预测框只预测一个类别分数c,对应于输入图像的同一位置的一组预测框称为cpi(I= 1,2,…,K),每个预测框类别的最终概率为:
(13)
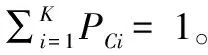
2.5 训练和推理流程
数据集使用公开的NWPU VHR-10十分类遥感数据集,选择船舶、储罐、篮球场、棒球场、汽车、地面轨道、港口为基类,飞机、棒球场、网球场为新类。训练策略依据FSODM中的设置,训练过程分为两阶段:第一阶段在具有充足标签的基类上进行训练,称为基类训练;第二阶段使用第一阶段生成的模型在小样本数据集上进行微调。基类训练的数据集Dtrain中包括640张图片,共包括7类目标,其中包含船舶目标240个、储罐目标524个、篮球场目标127个、地面轨道目标130目标个、港口目标180个、桥梁目标99个、汽车目标472个。在k-shot任务下,微调阶段的小样本数据集Dtest包括10类目标,从基类数据集中的图片随机选取,直至选取的图片包含所有类的k个的目标。依据1.1中的设置,每次迭代的输入为Ti={Qi,Si}。一张查询图像对应一组支持图像,支持图像由图像及其对应目标类别的掩膜构成如图9所示,一轮训练中,查询图像就是训练集的所有图像,其所对应的支持图像由训练集中的图像随机组合生成。
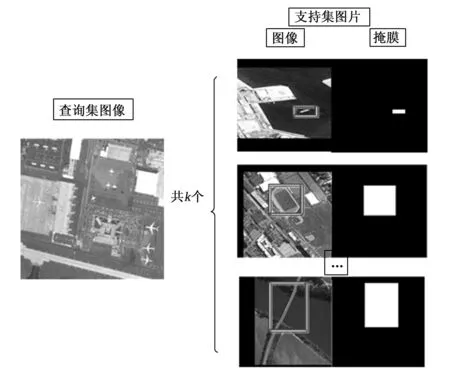
图9 查询图像与支持图像示意图
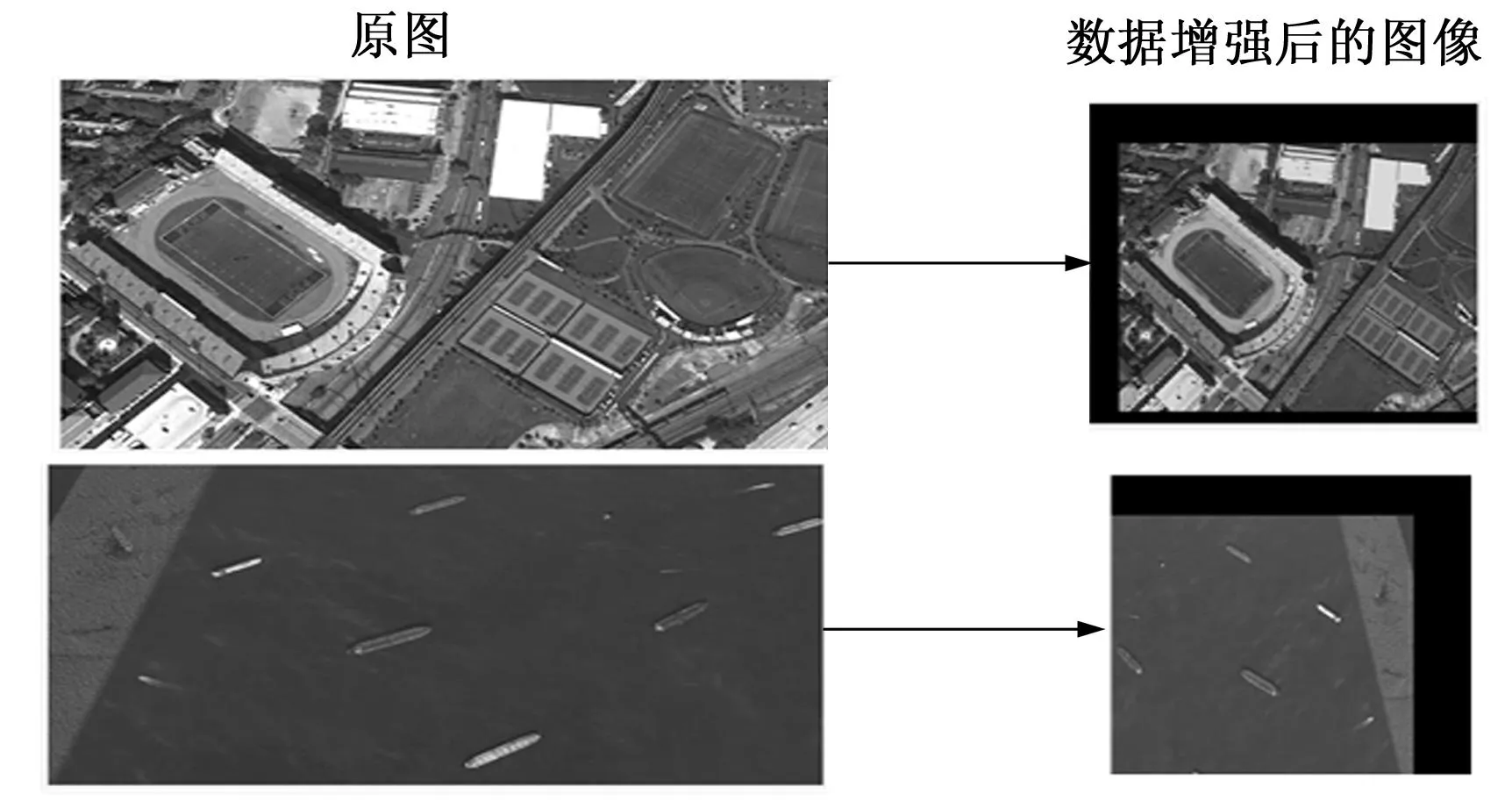
图10 数据增强示意图
训练以及推理流程如下:
1)生成基类训练集Dtrain以及推理所用的小样本数据集Dtest。
2)初始化特征提取器、特征重加权网络、预测模块的网络权重。
3)将Dtrain中数据输入到网络中训练900轮,保存模型。
4)加载步骤3)中的模型,利用Dtest训练10轮进行微调,生成最后的模型。
5)利用Dtest中的数据集,将支持集输入到特征重加权网络中生成重加权向量。
6)将查询图像输入到网络中生成元特征图,利用重加权向量与元特征图进行1×1的通道卷积生成调整后的元特征图,将其输入到预测模块进行解码生成最后的预测结果。解码过程只有类别预测与YOLOv3不同,其余均相同。
3 实验与结果分析
3.1 实验环境
CPU为intel Xeon○RGold 6310,GPU为V100-32 GB,24 G运行内存,Ubuntu20.04操作系统,Pytorch版本为0.3.1,计算架构为CUDA8。
超参数说明:训练图像的分辨率设置为512×512,批次大小设置为16,使用SGD优化器,基类训练阶段学习率为0.01,微调阶段学习率设置为0.001,优化器权重衰减设置为0.000 5,动量因子设置为0.937,在基类训练阶段训练900轮,在微调阶段训练10轮,训练集与测试集以8∶2的比例进行划分,其中训练集640张图片,测试集160张图片。
3.2 实验评价指标
RE-FSOD通过mAP(mean Average Precision)平均精度均值以及AP(Average Precision)平均精度来评价小样本目标检测算法的性能。
(14)
(15)
(16)
式中,P代表预测出真实正例占所有预测为正确的比例,R代表预测出的真实正例占所有预测为正例的比例,用来反映漏检情况,在式(16)中,n是代表类别数,根据P和R利用式(16)计算得出mAP。实验采用mAP50作为评价指标。
3.3 数据集介绍及数据增强
数据增强流程:
1)在图像输入到特征提取网络之前,首先将图像向左右、上下两个方向随机平移,平移的距离不过图像尺度的20%。
2)裁剪平移后的图像,使用HSV进行数据增强,以0.5的概率将图像随机进行翻转,最后使用多尺度策略将图像放缩,输入到网络当中。
将图像进行翻转、平移使检测目标在图像中的位置发生变化,进行HSV数据增强调整图像的色彩,使得输入到重加权模块的每张图片都是不同的,两种方法大大丰富了样本的多样性,可以使模型提取到更加鲁棒的特征表示,提升模型的泛化能力。
3.4 消融实验
为了评估RE-FSOD模型在小样本场景下的检测性能,将数据集分为两部分,其中以飞机、棒球场、网球场作为新类,其余类别作为基类。并且进行了3-shot、5-shot、10-shot实验。
改进1 为使用CSPDarknet-53骨干网络,并且添加PAN结构以及SPPF结构,改进2为将定位损失函数替换为CIOU损失函数,改进3为在特征重加权提取器中添加C2fSE结构。同时为了验证改进的有效性,进行消融实验,实验结果如表1所示,使用改进1之后,即使用CSPDarknet-53作为骨干网络,并且添加PAN结构后,在3-shot、5-shot、10-shot情况下mAP分别提升了10%、2.8%、3.9%,证明改进1能够有效地提升的目标检测算法精度,并且在3-shot实验中,mAP有大幅提升,说明改进1在样本极少的情况性能更加出色。在改进1的基础上添加改进2,将定位损失函数更换为CIOU损失,在3-shot、5-shot、10-shot的情况下分别提升了6.3%、9.6%、3%,验证了改进2的有效性,说明CIOU损失函数相比于均方误差损失函数能够提升模型的定位精度。在此基础上引入C2fSE模块,在3-shot、10-shot情况下分别提升了3%、1.1%,5-shot情况下基本持平,证明了改进3的有效性。并且在不同样本条件下进行了3个改进模块两两组合的实验,相较于只改进1个模块,均有不同程度的提高,说明改进模块具有较好的独立性。
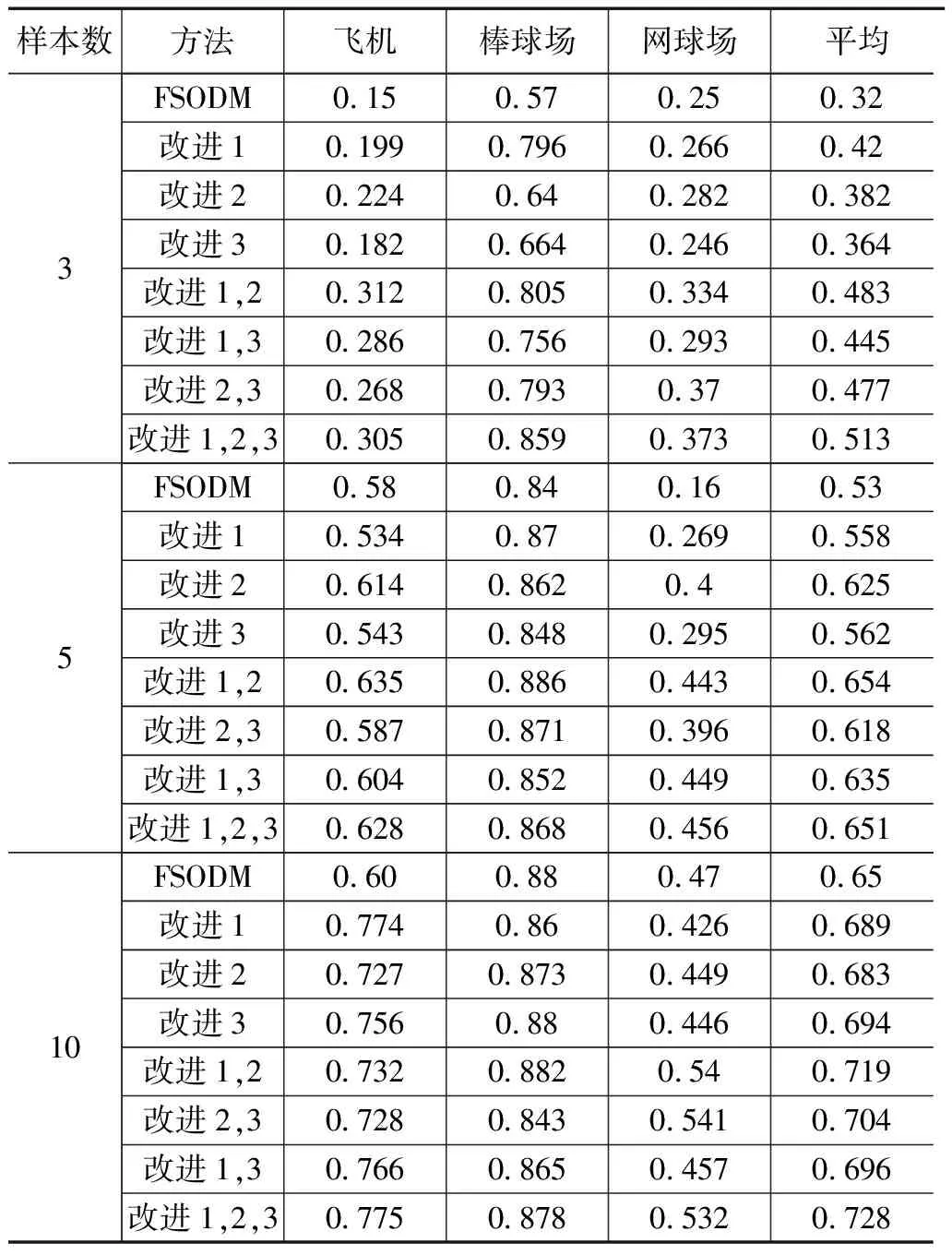
表1 消融实验结果mAP50
RE-FSOD算法相较于FSODM算法在3-shot、5-shot、10-shot情况下的mAP分别提升了19%、11%、8%。并且样本越少提升效果越明显,说明RE-FSOD相比于FSODM在小样本条件下检测遥感图像目标具有明显优势。
3.5 不同算法对比实验结果
为验证RE-FSOD算法的性能,与当前流行的小样本目标检测算法FSODM、TFA、FSCE、PAMS-Det进行了对比实验,结果如表2所示,RE-FSOD相较于性能最好的PAMS-Det算法在3-shot、5-shot、10-shot的情况下mAP提升了14%、10%、7%。
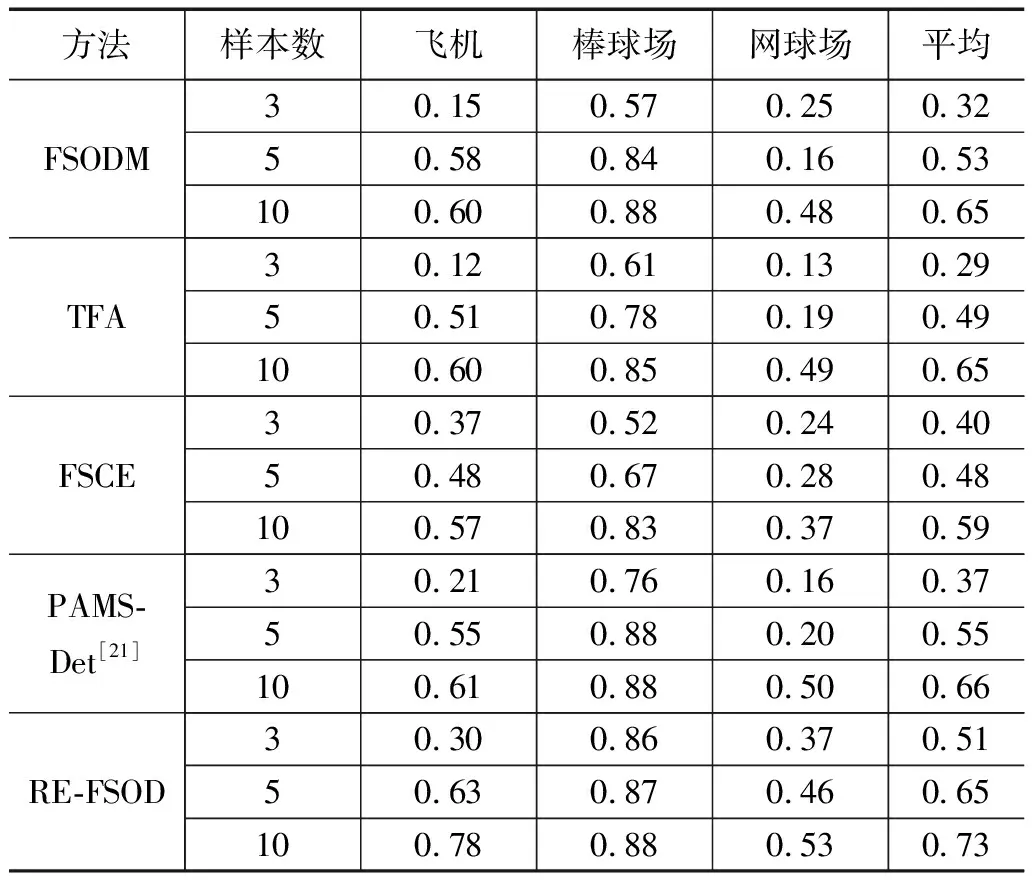
表2 不同算法实验结果mAP50
RE-FSOD以FSODM算法为基础进行改进,为验证RE-FSOD改进模块的性能,进行如图11所示的实验,在10-shot场景下,RE-FSOD相较于FSODM算法能够减少错分漏分的情况,验证了改进模块的优越性。

图11 实验结果对比图
3.6 特征重加权向量评估
为了验证特征重加权模块的效果,高维向量难以可视化,使用T-SNE模块对其进行降维,T-SNE算法中,高维向量的分布与降维后向量的分布是比较接近的,但是如果在高维向量中本来有一段距离,降维后的向量距离就会被拉大,直观地说,如果原来在高维空间中距离很近,降维后距离仍然很近,但是如果在高维空间有距离,降维后距离就会被拉大,这样的特性有利于对1 024维、512维、256维的高纬特征重加权进行降维,并进行可视化。
从基类训练集的支持集中随机选取了共140张图片输入到特征重加权模块生成重加权向量,每类20张,使用T-SNE将高维数据降到2维,进行可视化。得到结果如图12所示。

图12 不同维度重加权向量对比
不同的点代表不同类别的特征重加权向量,可以见到相同类别的重加权向量聚集在一起,这表明重加权模块通过梯度下降后能够成功地表示来自原始输入图片的类别信息。并且使用样本点到中心点的欧式距离对聚类效果进行了评估,公式如下:
(17)
式中,(xmean,ymean)是类中心点的坐标,(x1,y1)是样本点的坐标。
计算所有样本点到其类中心点的欧式距离的平均值,得到256维的平均欧式距离为785,512维平均欧式距离为689,1 024维平均欧式距离为627,说明1 024维的特征重加权向量聚类结果比512维以及256维的特征重加权向量聚类结果更好,说明维度更高的特征重加权向量承载了更多信息,因此具有更高维度的特征重加权向量能够更好地表示支持样本中的类别信息。
4 结束语
RE-FSOD以FSODM方法为基础,在元特征提取器中使用CSPDarknet-53作为骨干网络,并且添加了PAN结构以及SPPF结构,能够提取更加鲁棒的元特征,在特征重加权提取器中引入结合注意力机制与残差结构的C2fSE模块,能够提取到更丰富的语义信息,并且使用CIOU作为定位损失函数,提升定位精度并加速算法的收敛。经过实验证明,特定重加权向量的维度越高,提取到特定类别重加权向量的语义信息越丰富,RE-FSDO相较于FSODM提出的3个改进方法均能有效地提升算法的检测精度,并且相较于其他先进小样本目标检测方法具有明显的优势,说明该方法能够更好的处理尺度多变、背景复杂、目标模糊的遥感图像。目前RE-FOSD在推理速度、计算量、占用内存等方面仍然有待于进一步提升,后续计划通过利用剪枝、量化等方法对模型进行轻量化,在保证模型精度的同时降低模型的参数量并且提升模型的推理速度。
