基于容器化的快速射电暴搜寻GPU并行优化
2024-02-27王玉明吴开超牛晨辉张晓丽
王玉明,吴开超,牛晨辉,张晓丽
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
3.中国科学院国家天文台,北京 100101
引 言
近几年来,我国望远镜观测设备的开发研制取得了较大的进展。2016 年落成的FAST 是射电天文技术发展史上又一里程碑,同时意味着天文观测进入追求高性能、高速度的新时代[1]。FAST射电望远镜能够以极高的分辨率观测银河系中的中性原子氢(HI),利用射电天文学中前沿的无线电定位技术观测系外行星[2],使得关于脉冲星的观测有了长足的进步。FAST望远镜每秒采集的数据量最高可达38GB,每年观测产生的科学数据总量可达到15PB。海量数据处理已成为射电天文学的一个显著特点[3]。而与诸多无线电报源不同的是,快速射电暴仅存在数毫秒的持续时间,但几毫秒内产生的色散量远远超出银河系电离介质所能够导致的数值[4]。射电望远镜观测快速射电暴时产生的数据量巨大,将数据从观测站传输到计算机再对其进行处理,所需时间较长,传统的单脉冲方法搜寻过程复杂、速度较慢[5],为缩短处理数据时间和提高准确率,需要以人工成本更低、资源利用率更高且计算速率更快的方式,实现快速射电暴的搜寻任务。
1 相关工作
1.1 容器虚拟化
虚拟化技术是通过在宿主机上添加虚拟化监控(Virtual Machine Monitor, VMM)软件实现对宿主机系统在处理器、内存管理器等方面的虚拟化[6]。而容器化则是以容器引擎为基础,通过容器引擎对软件应用程序的基本依赖项打包,针对每个容器提供独立、隔离的环境[7]。相较于虚拟机而言,容器化技术在云计算、高性能计算和并行计算等方面具有优势,主要体现在:
(1)轻量级:通过提供轻量级的容器和镜像代替虚拟机全套操作系统;
(2)易移植性:资源占用量小且与宿主机操作系统的耦合度低;
(3)可扩展性:提供全局配置方案,不同实例可运行同一个容器,允许通过增加或减少副本数量进行容器和服务的扩展。
以FRB搜寻为代表的天文计算算法,大量依赖于像sigpyproc、PRESTO、heimdall 等开源软件,实际的天文数据处理往往基于开源软件做应用级定制开发,一般不会针对底层基础开源软件做源码级的修改和调整。通过容器化封装底层天文基础开源软件,可有效解决各类依赖库管理及版本冲突等问题。与虚拟化技术相比,容器化提供标准的镜像管理及应用加载,支持不同计算环境的分层配置管理,通过Linux提供的Cgroups和Namespace 实现容器与宿主机之间的环境隔离,与传统虚拟化相比更加轻量级且高效。
1.2 GPU虚拟化
为实现异构GPU 计算资源的解耦和算力共享,主要包括GPU 池化和GPU 虚拟化两种方案[8]。GPU 池化主要解决多节点资源远程访问的问题,利用虚拟化服务层维护不同的异构GPU资源池[9],提供细粒度的异构云端GPU 共享服务。GPU 池化的优点是支持客户端以远程调用方式访问其他节点GPU 资源,独立拥有资源池中的部分资源。
GPU 虚拟化则主要是解决多进程访问GPU的问题[10]。以Nvidia的CUDA技术为例,主要分为CUDA 劫持和CUDA 聚合两种方案。典型的CUDA 劫持包括vCUDA 和rCUDA,通过劫持CUDA Driver API调用转发到相应的管理模块和GPU设备上,实现时间片共享。典型的CUDA聚合方案包括Nvidia MPS(多进程服务,Multi-Process Service)等,通过在CUDA Driver API 和Nvidia Driver 之间将多任务上下文合并实现资源空间上的共享。
在快速射电暴搜寻并行方案中,若采用GPU池化或CUDA 劫持的方案,需针对CUDA 层做侵入式编程,替换算法实现中的CUDA 调用,修改底层的基础开源软件,这种方式编程代价高,且需要对每个开源算法都做底层并行优化,不具有通用性。
2 FRB搜寻算法
快速射电暴FRB 搜寻通常是以开源天文软件heimdall、PRESTO等为基础开展研究,近年来,还出现了以机器学习为基础的FRB相关研究[11]。
基于heimdall 的FRB 搜寻是目前最常用的FRB 搜寻方法。该方法依据FRB 不确定性和随机性的特性,通过单脉冲搜索方式进行FRB 筛选[12]。从具体实现看,heimdall 是基于GPU 加速瞬态检测的单脉冲检测程序,主要过程中包括依赖时间间隔事件的规则事件搜索和巨脉冲不规则时间搜索等。计算程序的核心是通过数据文件记录的时间频率计算出消色散后,再对消色散后的时间序列进行单脉冲检测。heimdall的单脉冲搜索本质上是全扫描的搜寻方法,在完成多相滤波和偏振计算后,生成纪录搜寻结果的filterbank文件和cand文件,如图1所示。

图1 heimdall计算流程图Fig.1 heimdall calculation flow chart
图1 右侧为FRB 单脉冲搜寻的并行计算任务流程,包括屏蔽干扰、消色散、提取时间序列、归一化、匹配滤波、探测事件等,最后生成的cand文件记录候选体信息。
在FRB 搜寻过程中,CPU 和GPU 设备的处理时间并不均衡,只有在消色散计算环节才会产生集中的GPU计算,而消除干扰、提取时间序列等步骤在CPU 端同步阻塞地执行,从测试结果看,GPU 计算部分只占FRB 搜寻总运算时间的16%左右,GPU 资源利用率偏低。在FRB 搜寻中,涉及中间文件的转存、时间戳记录、提取基带信息排序等人工辅助、记录的过程,使得FRB搜寻任务自动化程度低,导致整体的计算效率偏低。
3 FRB搜寻并行优化
基于开源软件heimdall 的FRB 搜寻采用GPU来加速算法实现,但是针对heimdall的传统部署模式存在着GPU 资源利用率低、整体计算效率低等问题。为此需考虑对FRB 搜寻进行并行优化。考虑到对heimdall 底层代码重写实现重新的成本高,通用性不足,故本文拟采取以下优化方案:
(1)将heimdall 及应用级代码封装为容器,针对依赖环境分层封装,从而降低部署难度。屏蔽GPU调用细节,支持容器内部调用GPU,通过容器化解决GPU 聚合计算任务的资源隔离问题;
(2)针对计算容器采用多进程并行,通过GPU 聚合实现GPU 资源的共享复用,代替对底层算法的侵入式编程,提高GPU 资源利用率的同时,保证并行方案的通用性;
(3)设计进程级并行优化方法,通过计算步骤的流水线并行,减少数据交换和过程同步阻塞的操作,从而降低搜寻任务的总计算时间。
3.1 FRB搜寻模块的容器化封装
以开源软件heimdall 为基础的快速射电暴的搜寻模块,包括消除干扰、色散等GPU计算过程,其环境配置、软件依赖均不相同。因此,本文对FRB搜寻各个计算流程进行容器化封装,便于软件的灵活部署。以CentOS7镜像为基础镜像,在Docker 容器镜像分层构建的基础上,同时将不同过程的环境需求进行预封装。在实际部署的过程中支持从自主搭建的Docker Hub 中拉取对应版本的镜像进行分层构建,降低配置不同环境需匹配版本的复杂度,避免不同节点重复构建容器镜像。
容器化封装镜像结构如图2所示:
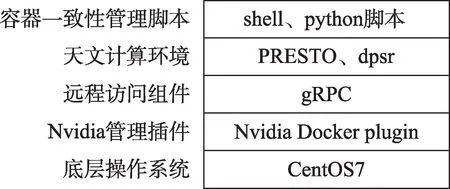
图2 FRB搜寻容器镜像的结构Fig.2 Structure of a container image FRB search
(1)计算容器以CentOS7镜像为基础镜像;
(2)nvidia- docker、nvdia- docker- plugin 等Nvidia Docker插件,实现驱动文件的调用和CUDA API的转发,将捕获的用户命令转发到Docker 守护进程,从而支持heimdall 计算程序从容器内部调用GPU设备;
(3)基于gRPC的Client端,支持数据库的一致性访问组件;
(4)天文开源软件的计算环境;
(5)环境变量配置、容器网络初始化、计算数据预读入和计算结果核验、持久化等一致性脚本。
3.2 GPU聚合的设计
GPU 设备通过时间片分片的调度方法调度不同的进程,实际上在某一时刻GPU 设备只运行单一的计算进程[13]。传统的GPU 多进程并行方案会导致单一进程绑定GPU设备的所有计算资源,从而引发多进程的阻塞,如图3左图所示。

图3 进程并行方案对比图Fig.3 Process parallel scheme comparison chart
如图3右图所示,以GPU聚合为基础的并行优化,则打破了不同进程GPU Context 之间的封闭性,统一维护GPU Context 支持资源共享,允许多个进程同时占用闲置的GPU 资源。针对CUDA的技术方案中,将所有的计算进程作为多进程服务(Multi-Process Service, MPS)的客户端,连接至服务控制进程。由该进程聚合产生全局统一的CUDA Context,并绑定到GPU 设备上。使得GPU 设备在进行时间片调度的过程中,是针对所有计算进程进行统一并行化的调度,实现多计算进程在同一GPU设备上的并行,提高单一GPU设备的资源利用率。基于容器化的多进程并行GPU应用的多线程并行通过框架中立的形式支持计算进程间的协同调度。在软件层面上允许多个进程同时加载任务到一个GPU上,实现计算指令的并发执行。传统多进程并行方法,随着绑定进程数的增加,加速比显著下降[14]。
传统GPU 应用多进程并行调度过程如图4所示。来自不同计算进程的GPU计算指令通过全局的GPU 时间切片调度器顺序处理,不能支持多进程并发执行。
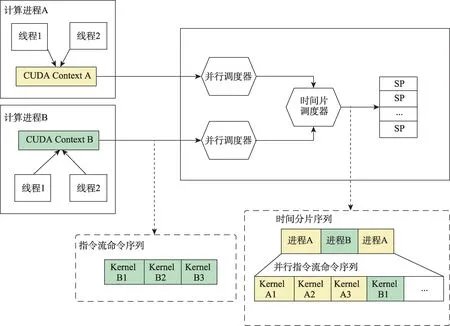
图4 优化前GPU应用多进程并行调度模型Fig.4 GPU process work scheduling without Optimization
在未优化情况下,不同进程上下文中占用的计算资源相互独立,如上图中某一时刻所有SP资源被单一进程独占。从执行顺序方面而言,不同进程在GPU 上被分配一个串行调度的时间片。故而,单个计算进程不能充分利用上下文中所有的计算资源,便会导致GPU 的计算资源利用率不足。
为解决单进程计算任务量不足以使GPU 负载饱和时,使多计算进程共享剩余的计算资源,在问题规模没有调整的基础上,变相的使得同一时刻计算进程可占用的计算资源量上升。多进程并行方案下,进程工作状态如图5所示。
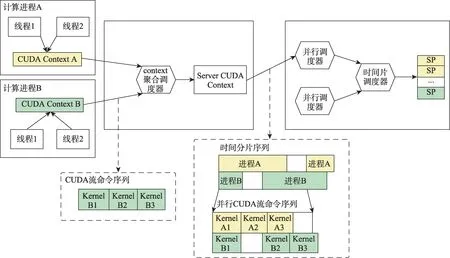
图5 优化后的GPU应用多进程并行调度模型Fig.5 GPU process work scheduling model with Optimization
图5 反映了多进程并行方案下,heimdall 计算指令可能的执行顺序。为解决不同进程资源管理独立的问题,通过聚合调度器对不同进程上下文聚合,提供统一的GPU连接服务,从而允许SP 资源队列中运行不同计算进程,实现不同进程计算任务在时间上的重叠,达到计算错峰的目的。同时,通过GPU聚合,允许不同进程的计算指令并发发射,从而避免对底层代码的侵入式编程。最终在计算资源方面,实现多进程并行。
将单个计算进程作为多进程服务的客户端封装成单个容器,屏蔽计算进程单独与GPU 设备绑定细节,同时保证容器内开源软件算法的独立性。在容器中修改内置Runtime,实现heimdall进程在容器内部与GPU设备绑定。
同时,容器环境初始化时绑定容器输出日志,以便排查MPS的运行异常。封装后heimdall计算程序从容器内部以nvidia-docker的方式连接到GPU上,解决因上下文聚合带来的资源隔离性较差的问题。当单个计算容器计算异常时,通过容器内的异常检测促使容器自身退出,避免传统单客户端异常导致整个聚合服务崩溃的问题。
4 实验与分析
测试用例主要对于不同文件大小FAST巡天数据的filterbank文件、不同计算参数和不同并行数目(1、2、3…6)进行分组测试,进而得出在多进程环境下的并行优化参数。设计单进程资源利用率测试、64MB 小样本filterbank 文件、256MB大样本filterbank文件的并行搜索,测试在不同场景下的并行效率。
4.1 实验环境
本次实验使用基于docker 的容器化测试环境,具体软硬件配置如表1所示。

表1 软硬件配置表Table 1 Hardware and software configuration table
4.2 并行计算优化参数
实验首先针对heimdall 计算程序在不同色散量参数指标下,对样本计算数据量和资源占用情况如表2所示。
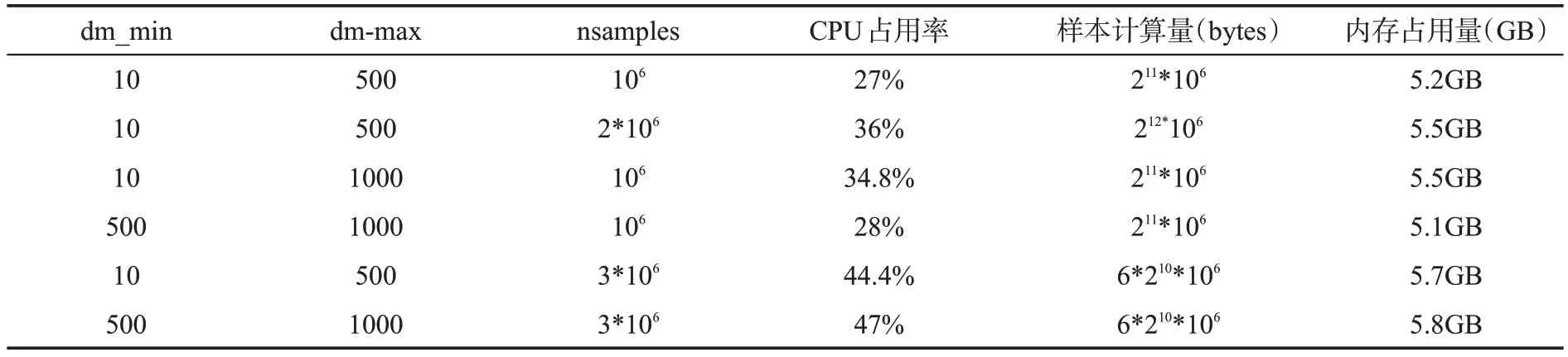
表2 样本计算数据量和资源占用情况表Table 2 Sample size and resource occupancy
增加样本点可提升筛选精度,而在数据迁移和分配内存等过程中则会占据更多CPU 资源,经分析进程对内存需求与filterbank 文件的样本量成正比,与dm 色散时间跨度和nsamples 样本计算量正相关。经回归分析,在单批次样本量可覆盖filterbank文件采样点时,优化后的内存量为:
式中,M表示所需的内存量,单位GB;p表示并行度;dm 表示heimdall 的消色散区间;n 表示单批次的样本量。
4.3 并行效率测试结果分析
并行程序性能评价标准主要包括三项指标:并行加速比、并行效率和可扩展性。其中可扩展性是用来评价并行架构对计算规模扩展的适应能力的非量化指标。
并行加速比Sp是用于衡量并行程序性能的基本指标,被定义为:
其中Ts是同规模下串行化执行时间;Tp是p 个处理单元的并行处理时间。
并行效率Ep反映并行加速比在计算规模改变时的变化幅度,被定义为:
其中Sp是并行加速比,P 则是并行处理单元数量,本文中P指虚拟GPU数。
4.3.1 FRB搜寻的资源利用分析
快速射电暴搜寻中消色散计算流程主要可以分为数据迁移、分配内存地址、消色散、寻找样本点、分析候选体等关键部分[15],实际的计算时间分布情况如表3所示,资源利用率情况如图6所示。

表3 FRB搜寻计算时间分布情况Table 3 FRB search time distribution
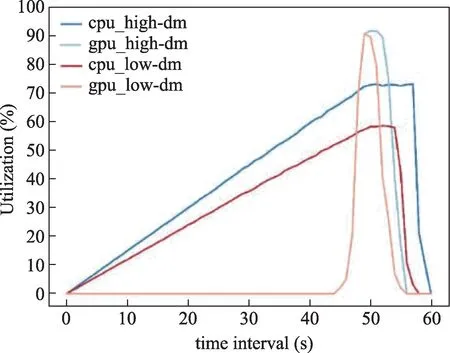
图6 单进程不同色散下的资源率情况Fig.6 Resource rates at different DMs
从计算进程运行时间的角度出发,heimdall计算程序在内存分配的时间是候选体分析时间的6 倍左右,且CPU 和GPU 的占用时间不均匀,仅当CPU 数据准备工作完成迁移至GPU 后,射电暴计算任务才开始计算且整体GPU的负载均值不高。
4.3.2 小样本filterbank文件并行效率
在多进程并行效率实验中,实验参数均采用高色散区间和高样本量(dm_min=10,dm_max=5000,nsamples=107),实验数据选择32个64M天文数据filterbank 文件和合并后的32 个256M 天文数据filterbank 文件,heimdall 进程均采用容器化封装,由进程调度模块进行同时调度,并保证一致的最大资源分配量,比较heimdall计算进程在不同并行方案下的并行加速比、并行效率和平均计算时间。
从图7 中可以看出,单进程运行情况下,64M filterbank 文件的平均计算时间为35s,而传统6 个计算进程并行仅能将平均时间缩短至65%。并行优化后,根据FRB 小样本中色散量少、需提取的时间序列短,单进程资源占用量小的特点,并行加速比基本上呈现线性增加至原本计算能力的5.4 倍左右,表明未优化情况下多进程未实现GPU 计算资源的并行,单进程消色散过程独占GPU造成并行效率低下。

图7 64M*32数据并行情况对比图Fig.7 64M*32 data parallel performance comparison char
4.3.3 大样本filterbank文件并行效率
选取256M合并文件的实验目的是测试更大单进程计算需求时,两者并行性能的差距。
如图8 所示,单进程256M filterbank 文件的计算时间约为152s,约为64M filterbank 文件的4.4 倍。由于heimdall 计算进程中,消除干扰、色散、提取时间序列等过程在GPU 过程内同步阻塞的执行,单进程独占GPU设备时间突增,单纯增加绑定进程数目致使长进程堵塞在任务队列中,最终如图8 所示,原始未开启MPS 下的平均计算时间在后期逐渐上升。
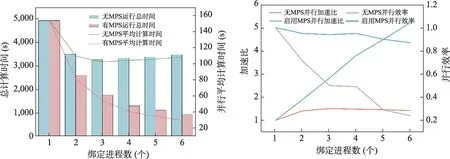
图8 256M*32数据并行情况对比图Fig.8 256M*32 data parallel performance comparison chart
通过允许不同heimdall进程在内核操作和内存复制的流水线操作,实现不同heimdall计算过程错峰流水线并行,当单GPU绑定6个进程时,优化后的平均计算时间最小值仅有29.5s,是原始情况下的25%左右。同时,原始状态下多进程并行效率下降迅速,相较于小样本计算时能够快速使后续进程让进让出,大样本计算进程长期独占GPU,导致计算进程阻塞严重加剧。表明未优化情况下在处理大文件复杂计算场景基本不具备扩展性。
4.4 实验小结
根据FRB 计算样本特点及FRB 搜寻任务要求,不同样本规模及不同并行优化方案下的性能对比,如表4所示。

表4 并行性能对比汇总表Table 4 Parallel performance comparison summary table
未优化情况下,进程长期独占GPU,导致计算进程严重阻塞,不具备并行扩展能力。实验结果表明,基于GPU聚合的并行优化方案,通过实现GPU 资源闲时复用,能有效提升多进程并行能力。同时优化方案通过计算流程错峰,6 进程并行时,平均计算时间缩短为初始的19%,在大样本、高精度的FRB搜寻需求下更具备性能和扩展优势。
不同并行优化方案下GPU 资源利用率对比情况图9 所示,即使计算大样本情况下,单进程GPU平均计算需求量较低约为17%,消色散计算峰值较高,同步操作等待时间较长。随着计算样本量和绑定进程数目的增加,未优化情况下,进程长期独占GPU,导致计算进程严重阻塞,GPU平均利用率低下。

图9 并行GPU资源利用率对比图Fig.9 Parallel GPU resource utilization comparison chart
实验证明,本文基于进程级并行的设计思想,通过搜寻任务流水线并行,实现降低数据交换和过程同步阻塞的时间,能有效提高GPU 工作负载饱和度和整体平均资源利用率。但是受限于heimdall进程并非计算密集型程序,且数据迁移任务较多,过度增加并行数目,容易导致内存增长需求量远大于GPU利用率的增长量。实验总结在处理大样本FRB 计算进程时,单GPU设备绑定6 个进程,稳定提供5.4 倍的并行加速比,缩短计算时间至初始时间的19.5%,具备良好的并行扩展性。在实际计算环境中,并行优化后单计算容器数据处理速率8.4MB/s,单计算节点数据处理速率35.5MB/s,容器化平台平均每秒处理数390MB。通过容器化部署,平台1天可自动完成550GB filterbank 文件的快速射电暴的搜寻任务。
5 结论与展望
快速射电暴FRB 搜寻是FAST 射电望远镜的重要科学目标之一,限于应用特点及开源实现,当前基于heimdall的FRB搜寻处理流水线存在GPU利用率低、人工依赖性高等问题,导致计算过程的整体效率偏低。本文分析了GPU资源复用的方法,提出利用GPU 聚合支持FRB 搜寻并行化,在不修改算法模块源码的前提下实现GPU应用的并行,提高GPU利用率,该方法具有良好的通用性;文中还通过容器化对算法模块封装以更有效地支持自动化计算过程;通过组织多个计算步骤的流水线并行,提升系统整体效率。通过实验,优化FRB 搜寻的并行化参数,实现对同一GPU 资源的闲时复用和计算错峰,在单GPU 设备绑定6 个进程情况下,可提供5.3 倍加速比,并将并行效率维持在0.88,具备良好的扩展性和并行度。
利益冲突声明
所有作者声明不存在利益冲突关系。
