面向GPU架构的CCFD-KSSolver组件设计和实现
2024-02-27张浩源马文鹏袁武张鉴陆忠华
张浩源,马文鹏,袁武,张鉴,陆忠华
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100049
3.信阳师范学院,河南 信阳 464000
引 言
计算流体力学(Computational Fluid Dynamics,CFD)的基本任务就是在给定初边值条件下,结合空间离散格式和时间推进方法数值求解Navier-Stokes 方程。根据控制方程的离散方式不同,时间推进方法分为显式和隐式两类,显式算法如多步Runge-Kutta[1]方法,具有实现简单、计算量小和精度较高等优点,但稳定性条件限制了时间步长,使显式算法的计算时间代价很大。因此,目前普遍采用隐式算法,该类算法又分为直接法和迭代法两种。直接法一般基于对系数矩阵的近似因子[2]分解,将复杂矩阵转化成易于求解的形式,如对角化方法、上下交替方向隐式法、上下对称高斯赛德尔法、对角并行上下松弛法等。迭代法包括基于矩阵分裂的定常迭代方法和非定常迭代方法[3],后者主要是Krylov 子空间方法。其中,针对对称矩阵比较有代表性的方法是共轭梯度法(Conjugate Gradient,CG),针对非对称矩阵有广义最小残差法(Generalized Minmal Residual Method,GMRES)。
CCFD系列软件是国家“863计划”“十一五”和“十二五”连续支持的高性能流体力学计算软件,到目前已经经历了3 个版本,其中,CCFD V3.0[4]由中国科学院计算机网络信息中心研发,主要针对国产超算平台神威-太湖之光的申威20610 处理器开发,从并行算法、访存模型、通信模式等多方面进行了优化,在高性能计算重点专项的百万核规模并行测试中并行效率达到了43%,实现了针对国产异构计算平台的良好适配。“十四五”期间,CCFD V3.0 的发展思路是组件化,即对若干典型算法环节进行抽象和封装,形成独立组件,以便能更专注于核心算法和热点函数在国产高性能环境的性能优化。
在组件化方案设计中,CCFD V3.0分解为功能组件、高性能组件和机器学习组件。线性方程求解是最重要的高性能组件之一,又分为基于近似因子分解法的AFSolver 组件和基于Krylov 子空间方法的KSSolver组件,这种划分是出于以下考量:在结构网格CFD求解器中,基于近似因子分解法的上下交替方向隐式法、上下对称高斯赛德尔等算法被广泛使用,和子空间方法需要显式提供矩阵不同,AF方法一般是Matrix-Free形式,即在迭代中实时计算每行方程的左端项,两者无法统一到同一个数据结构和外部接口,因此有必要分解成两个组件开发。
本文主要介绍CCFD 团队在KSSolver 组件研发取得的一些进展,包括组件的总体设计、若干适合CFD的算法以及适配GPU异构计算的预处理软构件,能够实现大规模线性系统的高效稳定求解。
1 研究背景
国际上普遍重视基础数学算法库的研究,长期以来形成了一系列著名的高性能算法库,有效支撑了应用软件的研发,显著缩短了软件研发周期与投入,大幅提升了软件的计算效能。本文主要关注稀疏线性代数方面,在科学计算中,高效的线性解法器扮演着“发动机”的关键角色,以计算流体力学为例,求解Ax=b的时间一般占整体计算任务的60%~80%。
随着高性能计算的发展,国内外目前存在诸多知名的稀疏线性代数算法库。LAPACK[5]是一种采用底层并行优化的线性代数库,全称为Linear Algebra Package,可用于如多元线性方程式、线性系统方程的最小平方解、计算特征向量,用于计算矩阵QR 分解的Householder 转换以及奇异值分解等问题的求解。Intel MKL[6],全称Intel Math Kernel Library,是一款商用函数库,提供C、Fortran 和Fortran95 的支持,针对Intel 自家旗下的CPU 进行了深度调优。该算法库稳定性高、功能强大,支持常用的稀疏/稠密矩阵算法,用户可以方便调用多种稀疏线性系统解法器,比如CG 和GMRES 等算法。在CPU 优化方面,MKL库使用了SIMD、多线程和提高cache命中率多的优化方法。rocALUTION[7]是一个C++软件库,为稀疏线性系统提供迭代求解器,如不动点迭代、krylov子空间法、混合精度策略、切比雪夫迭代和多重网格,同时提供了丰富的预处理器,如雅可比、高斯赛德尔、不完全LU分解、近似逆、鞍点预处理和限制性加性Schwarz 方法,且允许所有的求解器作为其他求解器的预处理方案。它提供HIP、OpenMP和MPI计算后端,支持在多种平台上编译和运行。高性能预条件Hypre[8](High Performance Preconditioners)由美国加州大学和劳伦斯-利弗莫尔国家实验室(LLNL)应用科学计算中心(CASC)开发。该软件包主要用于在大规模并行计算机上求解大型稀疏线性方程,主要目的是为用户提供高级并行预条件。Hypre具有功能强大性、易用性、适应性和互动性等特点。Trilinos[9]是Sandia 国家实验室实施的一个大型数值软件项目,用来解决大规模、复杂物理工程中的科学计算问题。它广泛采用面向对象技术,大部分代码用C++编写,底层关键部分则用FORTRAN(主要是BLAS 和LAPACK 程序)、C实现。Trilinos能在串行、并行系统上求解线性、非线性方程和特征值问题,提供一致的数值应用程序接口以方便数值软件调用。PETSc[10]是由Argonne 国家实验室开发的可移植可扩展科学计算工具箱,主要用于在分布式存储环境高效求解偏微分方程及相关问题,它遵循面向对象设计的基本特征。包含3 个基本组件SLES、SNES 和TS,同时提供了大量的线性方程求解器,包括直接法求解和迭代法求解,支持基于Krylov 子空间方法和各种预条件的高效的迭代方法,并提供了其他通用程序和用户程序的接口。中国科学院计算技术研究所自主研发了面向国产异构众核超算系统的线性方程迭代解法器库X-Solver[11],集中于Krylov 子空间迭代求解算法和预处理加速收敛算法的实现与优化,可以高效支撑流体力学、电路模拟等一批典型应用的快速求解,对国产计算系统具有良好的适用性。中国石油大学的刘伟峰等人开发的PanguLU[12]是一个开源直接法软件包,它采用块稀疏结构求解线性系统Ax=b,使用稀疏矩阵块LU 分解算法,将稀疏矩阵分解为多个稀疏矩阵块,并在稀疏矩阵块之间使用无同步稀疏LU 分解、稀疏三角求解、稀疏矩阵乘等算子。该算法可准确高效地运行于异构分布式平台。
上述算法库都是针对一般性的线性代数问题设计,且大多是基于通用CPU 实现。考虑特定应用和加速器架构,实现软硬件融合,充分发挥高性能计算对某一类问题的支持能力,是本文工作的主要出发点。
2 KSSolver组件设计
2.1 总体设计
CCFD-KSSolver 组件设计的指导思想是面向CFD应用、基于GPU加速器架构,结合软件算法特点和硬件体系结构的Co-Design 设计,具体叙述如下:
(1)采用层次化的架构设计,遵循CCFD 的总体设计规范以及架构和接口定义,同时细化了组件内部各模型模块及数据接口。如图1所示,组件分为4个层次:应用层、功能层、算子层和资源层。应用层直接面向用户,屏蔽求解器的具体实现细节,可编译成被CCFD软件或外部CFD软件调用的Lib 库,以及可独立执行功能的Application。功能层提供定制和封装的子空间方法解法器和预条件,实现粗粒度的功能调用。算子层主要由小尺寸三角矩阵方程求解(Small Block Triangular System, SBTS[13])、稀疏矩阵向量乘(Sparse Matrix-Vector multiplication, SpMV[14])等细粒度的核心算子组成,并直接映射到高性能异构计算环境。资源层则是对软件的基础数据、通用算法、MPI 通信等进行封装,提供给用户简洁的接口。
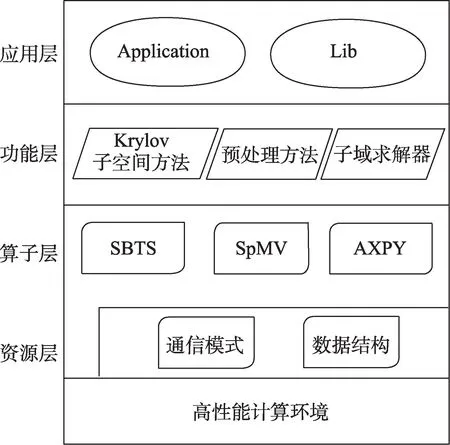
图1 KSSolver架构示意Fig.1 Diagram of KSSolver Architecture
(2)遵循“问题分离”(separation of concern)的设计思想,包含了两种问题分离的形式,其一是迭代法和预条件研究,其二是全局预条件和子域求解器研究。迭代法如GMRES、CG 等,算法较成熟,本文主要研究其在异构环境的适配和优化;预条件对线性解法器的效能影响很大,目前尚没有普适的预条件,因此结合算法和硬件架构特点开展Co-Design 设计,核心算子到异构处理器的映射,充分考虑了数据布局和处理器存储模型的匹配、线程并发设计、访存和指令优化等,以期充分发挥现代处理器性能。本文针对超算环境多层次的并行度,设计了如图2所示的全局预条件+子域求解器,在进程级方面,采用重叠型加性Schwarz[15]算法作为全局预条件,该算法由于其内在的并行性非常适合分布式计算,进而得以专注于在单GPU上设计子域求解器。

图2 全局预条件+子域求解器示意Fig.2 Diagram of global preconditioner+subdomain solver
(3)由于计算机技术和数值算法的快速发展,实际数值模拟应用的物理建模日益精细,多尺度多物理问题的模拟变得越来越普遍。对这类复杂应用,基于全隐式全耦合高阶离散的计算方法是保持高分辨率高精度数值模拟的关键。然而,由于多尺度效应、多物理耦合的影响,由此导出的大规模线性代数方程具有高度病态特性,通常采用基于物理预处理技术以达到理想的加速效果。KSSolver 针对多物理场中出现的特有的Point-block的矩阵模式[16-19],采用block的数据结构进行存储并设计一系列预处理算法,以此来保留多物理场变量间的耦合关系,更好地捕捉了实际应用中的局部物理特征,提高了迭代求解过程的数值稳定性和收敛速度。
2.2 功能设计
目前版本中,CCFD-KSSolver在Krylov子空间方法方面提供了Block-GMRES 迭代法模块;在基于限制加性Schwarz 预条件的构造方面,主要工作集中在子区域求解器的高效实现上,一方面提供了包括CPU 版本的Block-ILU(Incomplete LU factorization)分解以及基于cuSPARSE[20]的Block-ILU分解的两个功能模块;另一方面,在Block-GMRES 中的预条件步中,针对Block-ILU分解后需要求解的上、下三角矩阵线性系统,提供了基于forward-substitution 和backward-substitution CPU 版本的三角方程求解、基于cuSPARSE的GPU版本的三角方程求解以及基于块结构不完全近似稀疏逆的子区域求解模块。功能层接口设计如表1 所示。KSSolver 底层采用BCSR(Block Compressed Sparse Row)格式来存储块稀疏矩阵,并提供标量矩阵和块矩阵格式的灵活转换,同时兼容PETSc中的标量矩阵和块矩阵类型,方便与第三方开源库等功能对接。
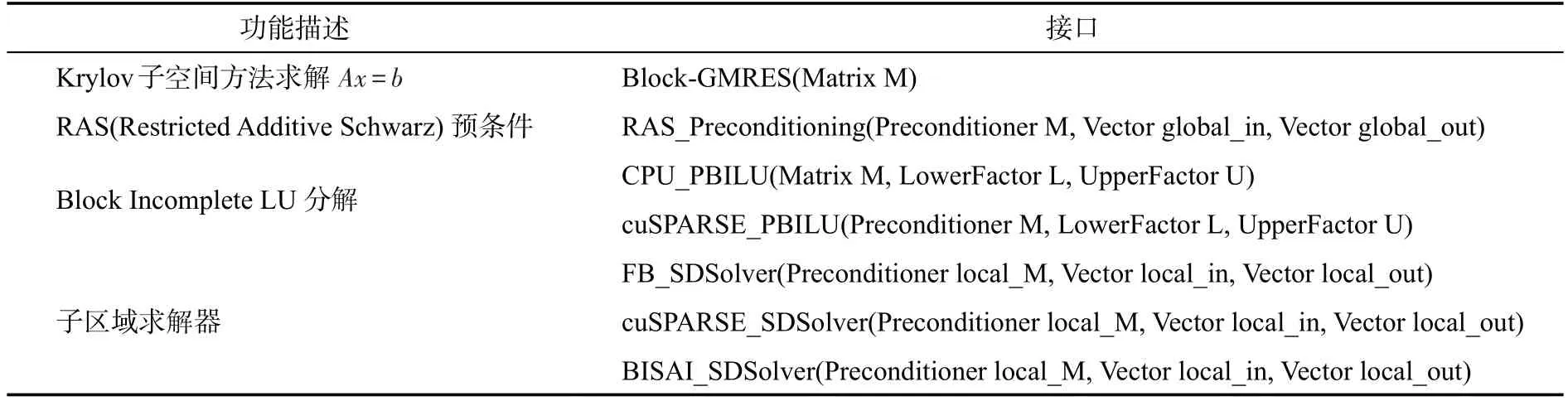
表1 KSSolver功能层接口Table 1 Interface design of KSSolver
下文简要介绍在KSSolver 中发展的一些特色算法和功能模块。
(1)Block-GMRES迭代法
GMRES 由于其高效性和良好的数值稳定性,在包含非对称线性系统的工程应用中被广泛使用。现有GMRES 算法大多是针对标量矩阵设计的,即算法中涉及到的矩阵及预条件操作均以标量计算为单位。为了耦合求解多尺度多物理问题模型,发展了一种基于块矩阵的多GPU上的Block-GMRES 软构件,该构件调用算子层中以块为单位在GPU平台上设计的若干算子函数,一方面能够在功能层上保持多物理场间变量的耦合关系,另一方面充分发挥了块结构数据局部性强的优势。由于众多复杂工程问题会导致具有病态特性的矩阵,事实上,带预条件的Block-GMRES更为常见和实用。Block-GMRES选用具有天然并行性的限制加性Schwarz 算法作为全局预条件,支持多GPU 平台,并利用GPU-Direct 技术实现了子区域间的数据通信。在预条件步骤中的各子区域求解方面,Block-GMRES可以和多种块形式的子区域求解算法[21]灵活组合,使得KSSolver具有很强的处理复杂线性问题的鲁棒性和扩展性。
(2)基于cuSPARSE的子区域求解器
本文将cuSPARSE库中提供的BCSR格式的高效三角矩阵方程求解器集成到了KSSolver中。cuSPARSE库利用level-scheduling算法从矩阵的稀疏模式中提取可能的并行性,这种方法使用层次遍历处理稀疏矩阵对应的有向图,保证每一层的节点间没有依赖关系,这样同一层内的所有未知量可以并行更新。相比于传统的高度串行的forward/backward-substitution 算法,这一做法提高了求解三角矩阵方程时的并行度,提升了求解效率。
但是level-scheduling 算法[22]一方面比较依赖矩阵的非零元的分布,另一方面有时在分析依赖关系,提取并行度的操作上会耗费过多时间。对于不同应用问题,子区域的求解算法的选择和适用性也不尽相同。因此,该模块仅作为子区域求解模块之一提供给用户,用户可通过命令行参数选择该模块以做正确性验证和预处理性能对比分析。
(3)基于block 不完全近稀疏逆的子区域求解器
KSSolver 针对block 结构的矩阵,根据GPU硬件调度单位warp 设计了一种基于block 不完全近似稀疏逆[23]的子区域求解器。与求解上下三角方程不同的是,该求解模块通过直接显示预估上/下三角矩阵的逆将预条件在子区域上的计算转化为可高度并行的稀疏矩阵向量乘操作。同时,计算上/下三角的不完全近似逆的过程也可高度并行,且可以通过引入稠密因子对近似逆的精确程度加以控制。近似计算的步骤增加了子区域求解的并行性,但也会因此在一定程度上削弱预处理的效果。这样往往使得Krylov 子空间方法的整体迭代步数增加,但由于花费在每一步的预条件时间大大降低,该求解模块能够在并行性和迭代步数之间寻求最大的平衡,通过控制逆的精确性寻求求解的最优墙上时间。
3 核心算子的GPU实现
3.1 块稀疏矩阵存储
在耦合求解多物理场问题时,由于计算域上每个网格格点(或网格单元)包含多个物理量需要求解,这种物理问题对应的矩阵会具有块状分布的特性,被成为point-block矩阵。这种形式的矩阵在全局范围上仍是稀疏矩阵,但在块内具有稠密的特性。对于这种块稀疏矩阵的存储格式有很多种,例如PETSc[10]和cuSPARSE[20]中的块压缩稀疏行(Block Compressed Sparse Rows, BCSR)和块压缩稀疏列(Block Compressed Sparse Columns,BCSC)。与存储标量值的CSR 格式不同,BCSR 格式将每个块视为一个单元,并逐块存储所有非零项,如图3 所示,在二维不可压流场中,每个网格点包含两个速度变量和一个压力变量,因此得到的矩阵具有3×3 大小的块结构,每个块中的值以列主序连续存储。通过对具有局部稠密特性的Point-block 矩阵采用逐块存储的方式,可以充分发挥GPU 平台融合访存的特点,提升块状矩阵在异构平台的计算效率。

图3 包含4个非零块的Point-block矩阵,块大小为3×3,采用BCSR格式存储Fig.3 A Point-block matrix containing four non-zero blocks with block sizes of 3×3 is stored in BCSR format
进一步地,为实现在多GPU 系统中分布式存储数据,对Point-block矩阵和向量按行进行划分,具体的数据分布策略如下:假设GPU集群上共有N张GPU卡,将以BCSR格式存储的矩阵A的连续的ri行存放在第ith号GPU 上,记为Ai。在预处理阶段,预处理矩阵Mi单独存储在第ith号GPU 上,如图4 所示。最直接的构造Mi的方法是对每个进程中所存储的矩阵的对角线部分进行不完全LU 分解,形如D(Ai)≈LiUi=Mi,其中D(Ai)为Ai的主对角块部分,Li和Ui是对主对角部分进行ILU分解后的结果。

图4 矩阵划分和预条件的构造过程Fig.4 Matrix partitioning and the construction of preconditions
3.2 SBTS高效算法
不完全稀疏近似逆(Incomplete Sparse Approximate Inverse, ISAI)[24]的主要思想是避免求解稀疏近似逆(Sparse Approximate Inverse,SAI)[25]方法中出现的最小二乘问题,转而求解一系列的尺寸较小的三角矩阵方程。本文在GPU平台上将ISAI 算法推广到了block 矩阵结构并给出了高效的实现,作为KSSolver组件中的高效算子之一,供功能层调用。
在预条件步骤中,各子区域面临求解(LU)-1v=z这一问题。ISAI 的算法思想是在给定Linv和Uinv的非零元的位置的前提下,显式求解L和U的逆。从而将问题转化为更为高效的矩阵向量乘。以LLinv=I作为约束条件,按照矩阵列分块的形式,可近似将求解Linv的每一列写成(如不做特殊说明,以下公式中的矩阵均是块矩阵):
式中,Linv为下三角矩阵L的近似逆矩阵,Ricol为Linv的第icolth列的非零项的行索引的集合,Iicol是把单位矩阵I的第icolth的列中Rth行提取出来所形成的列向量。因为L(Ricol,Ricol)为方阵,则上式等价于:
和求解全局矩阵A所对应三角矩阵方程[26]不同,在不完全稀疏近似逆(ISAI)中所形成的这些小尺寸块三角矩阵方程相互解耦,可并行求解。图5展示了小尺寸三角矩阵方程的建立过程,Linv(Uinv)矩阵的每一列都对应一个需要求解的小尺寸块下(上)三角矩阵方程(SBTS,Small Block Triangular System),因此需要求解的SBTS 个数等于Linv(Uinv)的行(列)数。

图5 小尺寸三角矩阵方程的建立过程Fig.5 The process of establishing small size triangular matrix equations
图6描述了基于warp的SBTS算子的主要流程,基本思想是使用一个warp来求解Linv的一列,即求解如图5所示的一个SBTS。算法的基本原则是:单个线程负责计算一个block中的单个元素,且一个warp中32个线程要能够覆盖整数个完整的block。图示中的一个Thread Block 共包含128 个线程,在CUDA 线程调度时被分为4 个warp。每个warp中的32个线程协同求解块大小为3×3 的一个SBTS。在求解三角方程组时,一个warp以列为单位遍历SBTS,将一个线程映射到一个3×3 的块单元中的一个元素上。具体地,以图6中warp1为例,首先启用0-8号线程来计算下三角方阵L(R1,R1)第一列列首块单元的逆,并将逆矩阵乘到右端项,即I1的列首块单元上,此时,代求的解向量Linv(R1,1)中的第一个分量已被解出。将L(R1,R1)中第一列其余块单元与求解得到的解向量Linv(R1,1)中的第一个分量相乘,并累积到对应右端项I1上。此处的累积过程分成两步:首先是0~26号线程并行完成3个对应块单元的累积过程;第二步是0~8号线程完成剩余一个块单元的累计过程,剩余27~31线程将处于非活跃状态,不执行任何操作。上述过程结束后,解向量第一个分量计算得出且右端项I1中各分量均被更新。用相同的方法处理L(R1,R1)的第二列,得到解向量Linv(R1,1)中的第二个分量,以此类推,直到解向量中的所有分量由上至下依次解出。上述是一个warp执行逻辑,在GPU并行执行中,每个warp独立求解Linv中的一列,增强了算法的扩展性。
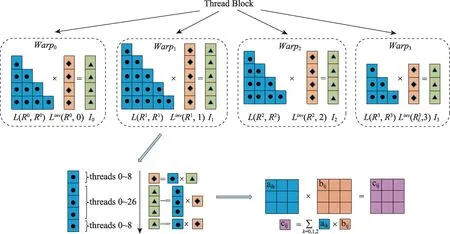
图6 基于warp的SBTS算法示意Fig.6 Illustration of warp-based algorithm for solving SBTS
通过块结构算法的设计,引入图6 右下角所示的矩阵乘,这是SBTS算法中密集出现的操作,可以充分发挥GPU 上细粒度并行的特性,也是block算法相比于标量算法的优势。在实际实现中,将待乘的矩阵存储在共享内存中,来提升访存带宽,提高计算效率。
3.3 BSpMV高效算法
块稀疏矩阵向量乘法(BSpMV)是Block-GMRES迭代法求解稀疏线性系统的核心运算之一。由于异构计算资源的计算特征和计算能力不尽相同,要发挥BSpMV 在CPU+GPU 异构平台上的计算性能,就必须充分利用其计算资源,关键是如何分割计算任务进行并行处理。为此,将全局矩阵A按行分配到各个进程上形成局部矩阵Ai,并将Ai划分到两个单独的结构中,如图7 所示,一个结构是局部矩阵Ai的主对角部分,另一个是局部矩阵Ai非对角部分。对应地,将与本地进程上的局部矩阵相乘的向量划分为Xlocal和Xhalo两部分。

图7 块稀疏矩阵的存储策略Fig.7 Storage strategies for block sparse matrices
这种将主对角部分(MDP)与非对角部分(ODP)分开存储的策略可以在执行BSpMV时实现计算与通信重叠。具体地,由于ODP 在做BSpMV 操作时,需要的向量信息并不存储在本地,因此需要从其他GPU 中通过MPI 通信获取Xhalo,而主对角部分(MDP)的运算并不依赖于Xhalo,因此可以在与邻居进行通信来获取Xhalo的同时来完成主对角部分(MDP)与Xlocal乘积的计算,当点对点通信完成后,再进行非对角部分(ODP)与Xhalo乘积的计算。因为Xhalo表示界面结点数据,因此所需通信的向量的数据量通常比内部向量Xlocal小得多。从这个意义上讲,MPI通信更新向量的操作时间以及CPU和GPU之间的数据传输可以(至少部分)隐藏在主对角部分矩阵(MDP)向量的计算之中,可以有效提升矩阵向量乘的效率。
4 数值实验
4.1 实验配置
本节在Tesla V100 GPU 上对KSSolver 中的Point-block 不完全稀疏近似逆软构件进行测试。表2给出了V100 GPU的详细配置。

表2 Tesla V100 的主要参数Table 2 The main parameters of Tesla V100 GPUs
标模案例选取了顶盖驱动流,它是计算流体力学应用中常见的验证基准。在CPU+GPU 的异构平台上进行性能测试和对比分析。顶盖驱动流控制方程如下:
其中(u,v)为速度,ω是涡度。对于速度场应用Dirichlet边界条件,在方形区域的上面设置为恒定速度,其他面设置为静止;对于涡度,边界条件为
雷诺数设为1。此问题是典型的多物理场的非线性问题,在每一个非线性迭代步中,雅克比矩阵具有3×3 的块状结构,使用KSSolver 中的GMRES(30)求解对应的线性系统。采用1200×1200 的计算网格,雅克比矩阵为4320000×4320000 的稀疏矩阵,非零元(标量)个数为116,510,436。全局采用重叠层为1 的加性Schwarz预条件,在每个子区域中,通过block ILU分解得到上下三角因子,使用KSSolver中提供的3 种子区域求解器来求解子区域,对比它们所对应的Krylov子空间方法的迭代步数和计算效率。
4.2 Block-ISAI性能测试及对比
第一种子区域算法是在纯CPU 平台上使用forward-substitution 和backward-substitution 求解子区域的上、下三角方程组;第二种子区域算法是在GPU 平台上使用cuSPARSE 库中的levelscheduling 算法并行求解上、下三角方程组;第三种子区域算法是在GPU 平台上近似高并行求解上下三角因子的逆(Block-ISAI, Block Incomplete Sparse Approximate Inverses),将上下三角方程求解问题转化为高可并行的矩阵向量乘问题。
实验结果如表3所示,基于近似稀疏逆的预条件算法虽然由于近似求解逆的过程中损失一部分预条件的精确性,但是在整体的Krylov迭代时间方面有明显优势。在子区域数目为2(N=2)的情况下,cuSPARSE 子区域求解算法相比于CPU平台取得了9.03倍的加速比,Block-ISAI相比于CPU平台和cuSPARSE分别取得了19.27倍和2.13 倍的加速比;在子区域数目为4 时,分别取得了23.37 倍和3.53 倍的加速比;在子区域数目为8 时,取得了20.09 倍和3.34 倍的加速比。可以观察到,Block-ISAI较前两种子区域求解器具有更优的扩展性,这是因为其在构建和应用阶段都具有很高的并行度。对于百万阶规模的矩阵,3 种子区域求解器的并行效率(8MPI 相对于2MPI,或者8 个GPU 相对于2 个GPU)分别为83.8%,55.7%,87.4%。

表3 使用KSSolver求解第一个非线性步中的线性系统Table 3 Solving the linear system in the first nonlinear step with KSSolver
5 总结与展望
KSSolver 是CCFD 团队自主研发的线性解法器组件,在GPU 架构下求解CFD 应用产生的稀疏线性代数问题。KSSolver 组件设计了有良好扩展性的分层架构,核心算子层直接映射到GPU环境;采用了问题分离的设计思想,专注于子域求解器的开发和高性能优化。结合CFD耦合求解多物理问题的特点,重点基于块矩阵结构设计了一系列功能模块和核心算子。针对核心算子在GPU 上的性能优化,充分考虑了数据布局和处理器存储模型的匹配、线程并发设计、访存和指令优化等,以期充分发挥现代处理器性能。
未来研究中,将进一步丰富CCFD-KSSolver中的预处理算法,增加基于物理的预条件、多重网格预条件,算法和硬件匹配的混合精度[27]计算方法等。此外,针对国产类GPU 架构的适配和优化,也是CCFD-KSSolver的重要研究方向。
利益冲突声明
所有作者声明不存在利益冲突关系。
